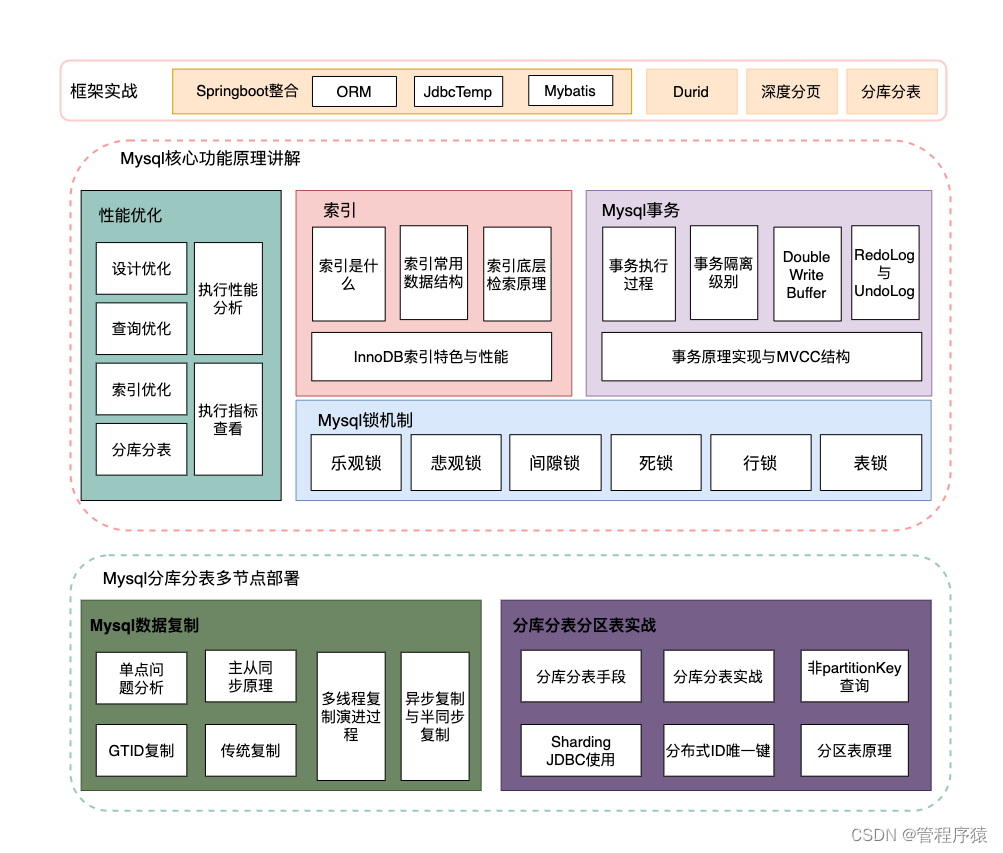
Mysql_实战_从入门到高级
文章目录
- Mysql_实战_从入门到高级
- 第二章 基于SpringBoot+MySQL实战案例
- 第1集 SpringBoot项目搭建
- 第2集 ORM关系对象映射做了什么?
- 第3集 Mysql与Java实战之JdbcTemplate整合方式
- 第4集 Mysql与JdbcTemplate增删改查
- 第5集 HTTP应用增删改查协议剖析
- 第6集 JdbcTemplate存在问题与Mybatis的引入
- 第三章 基于Mybatis的mysql数据实战
- 第1集 Mybatis+SpringBoot整合方式
- 第2集 Mybatis Gennerator的使用
- 第3集 基于Mybatis自定义SQL
- 第4集 Mybatis执行原理源码解析
- 第5集 高级面试题之Mybatis自定义拦截器
- 第四章 MySQL性能优化分析
- 第1集 基于Durid分析Mysql执行性能
- 第2集 浅谈Durid数据指标
- 第3集 Mysql数据库索引性能分析实战
- 第4集 高级面试题之谈谈你对MYSQL优化的理解
- 第5集 高级面试题之Mysql千万级别数据如何做分页?
- 第五章 高性能索引讲解
- 第1集 索引是什么?
- 磁盘IO与预读
- 第2集 索引底层实现方案解析
- 第3集 B+Tree数据结构解析
- 第4集 InnoDB索引的结构是怎样的
- 第5集 innodb索引与myIsam索引对比
- 第6集 Mysql为什么会选错索引
- 第7 集 高级面试题之唯一索引与普通索引的区别
- 第8集 高级面试题之innodb和myIsam的区别在哪里?
- 第六章 带你剖析Mysql事务
- 第1集 重温mysql事务特性
- 第2集 Mysql事务隔离级别
- 第3集 Mysql脏读幻读不可重复读
- 第4集 Mysql数据执行过程剖析
- 第5集 Mysql RedoLog与UndoLog日志
- 第6集 Mysql事务MVCC结构
- 第7集 InnoDB doublewrite缓冲区
- 第七章 进阶知识Mysql锁机制
- 第1集 初窥InnoDB锁分类
- 第2集 行锁与表锁的比较
- 第3集 附加技能之InnoDB死锁案例分析
- 第4集 如何避免死锁
- 第5集 大厂面试题之间隙锁
- 第6集 浅谈mysql大表性能问题
- 第八章 Mysql数据复制同步
- 第1集 分析Mysql单点存在的问题
- 第2集 Mysql主从数据同步搭建
- 第3集 Mysql主从同步原理讲解
- 第4集 常常说Binlog,你知道本质上是什么吗?
- 第5集 对于多种复制模式,他们有什么区别呢?
- 第6集 传统复制与基于GTID复制
- 第7集 GTID的生命周期
- 第8集 Mysql异步复制与半同步复制
- 第9集 Mysql多线程复制演进过程
- 第10集 浅谈基于LOGICAL_CLOCK的多线程复制
- 第11集 mysql复制高级工程师面试题
- 第九章 高级篇之分库分表实战讲解
- 第1集 分库分表分区分别是什么?为什么这么做
- 第2集 分库分表常见手段分析
- 第3集 分库分表实战环境准备
- 第4集 基于springboot实战分库分表搭建
- 第5集 shardingJDBC实战使用
- 第6集 分布式场景怎么保证ID唯一性?
- 第7集 分库分表ID唯一性实现手段
- 第8集 mysql分库分表非partition key检索
- 第9集 mysql分区是什么?
- 第10集 mysql分区原理和优劣势分析
- 第十章 课程总结
- 第1集 MySQL高级篇课程总结
第二章 基于SpringBoot+MySQL实战案例
第1集 SpringBoot项目搭建
简介:微服务springboot服务从0开始搭建
-
5分钟可以做什么?springboot服务搭建
- 打开https://start.spring.io/
- 输入maven project的group和artifact值
- 选择archeType模板 web项目+mysql引擎
- 点击项目生成
-
启动项目
- 打开项目进行mvn clean==》mvn install
- 启动web端口
- 查看端口是否启动成功
第2集 ORM关系对象映射做了什么?
简介:关系对象映射讲解
-
思考题:Mysql与springboot整合的流程步骤是怎样的?
-
对象关系映射,是一种规范,调节目前面向对象的程序设计与主流的关系型数据库之间发展不同步的问题,
关系到对象的映射
让编程时可以全身心的用面向对象的设计思想去编程,用对象映射关系数据表,在持久化时,可以直接操作对象进行持久化
- ORM关系对象映射图
表user user_id user_name==》User.java Long userId;String userName
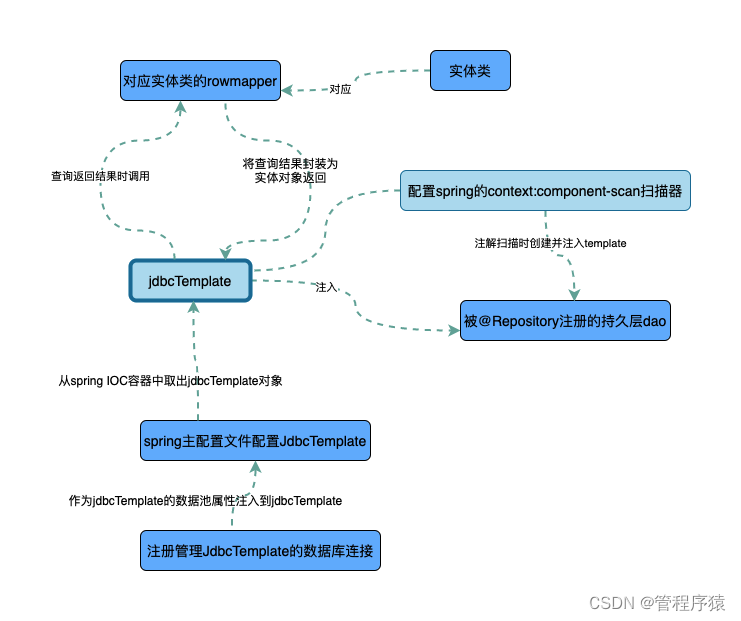
第3集 Mysql与Java实战之JdbcTemplate整合方式
简介: Mysql+springboot项目整合实战
-
什么是jdbc?
- Java数据库连接,(Java Database Connectivity,简称JDBC)是Java语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法
-
什么是jdbcTemplate?
- Spring 的 JDBC Templet 是 Spring 对 JDBC 使用的一个基本的封装。他主要是帮助程序员实现了数据库连接的管理,其余的使用方式和直接使用 JDBC 没有什么大的区别。
-
环境准备
- 在linux或者mac安装MySql5.7版本并打开MySql服务
- 建表语句:
create database xdclass_mysql; create table user (id bigint auto_increment comment '自增id',name varchar(64) default '' not null comment '用户名称', primary key (id)) default charset=utf8mb4; grant all privileges on xdclass_mysql.* to 'xdclass'@'%' identified by 'xdclass'; flush privileges;- 配置数据源
#通用数据源配置 spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/xdclass_mysql?charset=utf8mb4&useSSL=false spring.datasource.username=xdclass spring.datasource.password=xdclass # Hikari 数据源专用配置 spring.datasource.hikari.maximum-pool-size=20 spring.datasource.hikari.minimum-idle=5-
引入web项目依赖和jdbc对应jar包的maven依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>6.0.6</version> </dependency>
第4集 Mysql与JdbcTemplate增删改查
简介: Mysql+springboot项目整合实战
-
jdbcTemplate增删改查实战
- 从controller层出发jdbc增删改查对数据操作
-
返回结果封装
public class RestItemResult<T> {
private String result;
private String message;
private T item;
public String getResult() {
return result;
}
public void setResult(String result) {
this.result = result;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public T getItem() {
return item;
}
public void setItem(T item) {
this.item = item;
}
}
第5集 HTTP应用增删改查协议剖析
简介:HTTP应用增删改查协议剖析
-
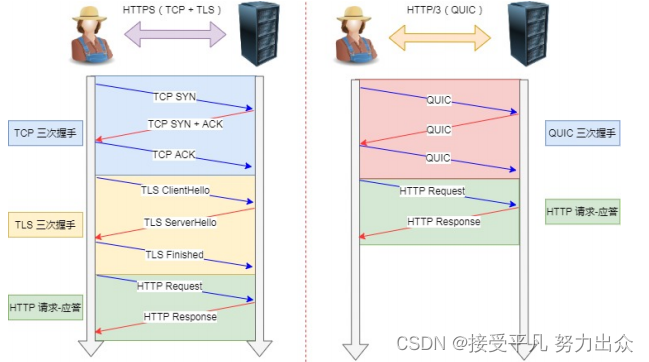
HTTP协议简介
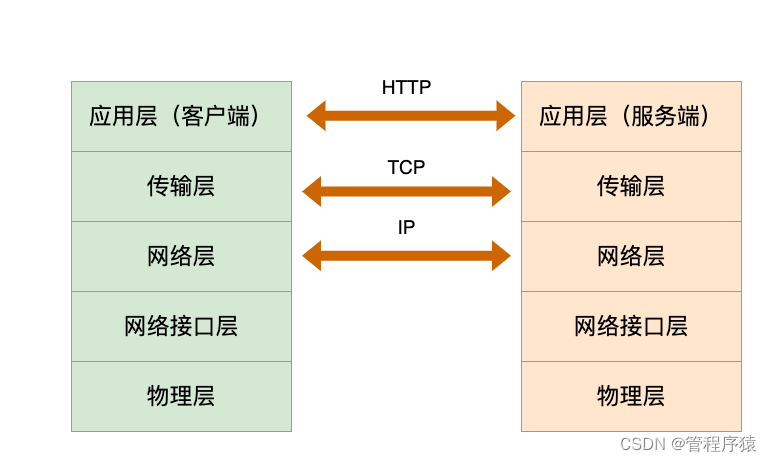
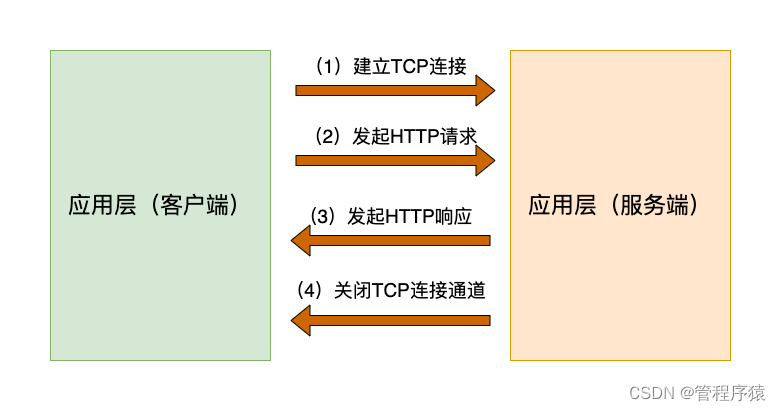
- HTTP 协议(Hypertext Transfer Protocol,超级文本传输协议),顾名思义,是关于如何在网络上传输超级文本(即 HTML 文档)的协议。HTTP 协议规定了 Web的基本 运作过程,以及浏览器与Web服务器之间的通信细节。HTTP协议采用客户/服务器通信模式,服务器端为 HTTP 服务器,它也称做 Web 服务器;客户端为 HTTP 客户程序,浏览器是最常见的 HTTP客户程序。
- 如图所示,在分层的网络体系结构中,HTTP协议位于应用层,建立在 TCP/IP 协议的基础上。HTTP 协议使用可靠的 TCP 连接,默认端口是 80 端口
-
当用户在浏览器中输入一个指向特定网页的 URL 地址时,浏览器就会生成一个 HTTP 请求,建立与远程 HTTP 服务器的 TCP 连接,然后把 HTTP 请求发送给远程 HTTP 服务器,HTTP 服务器再返回包含相应网页数据的 HTTP 响应,最后浏览器把这个网页显示出来。当浏览器与服务器之间的数据交换完毕,就会断开连接。
-
JAVA socket套接字创建监听请求实战
-
查看端口占用 mac/linux:lsof -i:8080, windows: netstat -aon|findstr “8080”
-
http 0.9==>http1.0==>http1.1==>http2==>http3(后续发展趋势是quic)
- 1.0 POST、DELETE、PUT、HEADER
- 1.1长连接 管道化
- 2.0 二进制分祯 多路复用:在共享TCP链接的基础上同时发送请求和响应
第6集 JdbcTemplate存在问题与Mybatis的引入
简介:JdbcTemplate的痛点问题与Mybatis工具的引入
-
思考jdbcTemplate的缺点
- 将sql语句硬编码到java代码中,如果sql语句修改,需要重新编译java代码,不利于系统维护
- 在向statement中设置参数,对站位符位置和设置参数数值,硬编码到java代码中
- 从result结果集中遍历数据时,存在硬编码
-
解决方案
- 把sql语句定义到xml配置文件里
- 将结果集自动映射成java对象 UserInfo List int count
-
现成工具MyBatis
- MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
-
工作原理
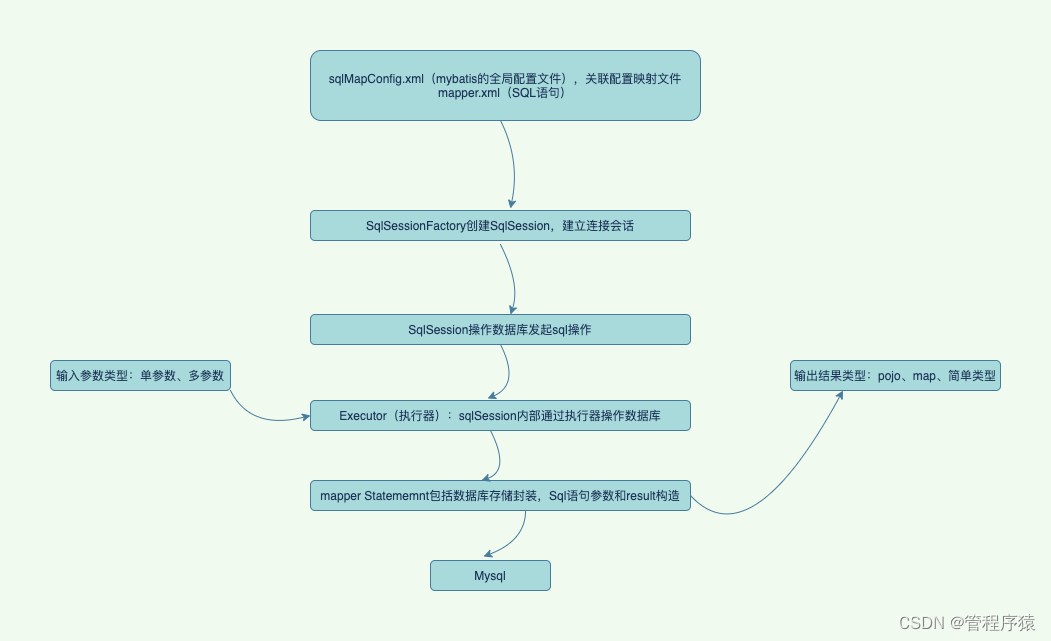
第三章 基于Mybatis的mysql数据实战
第1集 Mybatis+SpringBoot整合方式
简介:Mybatis+SpringBoot整合方式
-
引入pom依赖
<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.3.2</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.4</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.datatype</groupId> <artifactId>jackson-datatype-joda</artifactId> </dependency> <dependency> <groupId>com.fasterxml.jackson.module</groupId> <artifactId>jackson-module-parameter-names</artifactId> </dependency> <!-- 分页插件 --> <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper-spring-boot-starter</artifactId> <version>1.2.5</version> </dependency> <!-- alibaba的druid数据库连接池 --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.9</version> </dependency> -
使用idea工具将properties转成yml
- 在plugin marketplace搜索Properties to YAML Converter工具
-
yml配置
spring:
datasource:
name: mysql_test
type: com.alibaba.druid.pool.DruidDataSource
#druid相关配置
druid:
#监控统计拦截的filters
filters: stat
driver-class-name: com.mysql.jdbc.Driver
#基本属性
url: jdbc:mysql://localhost:3306/xdclass_mysql?charset=utf8mb4&useSSL=false
username: xdclass
password: xdclass
#配置初始化大小/最小/最大
initial-size: 1
min-idle: 1
max-active: 20
#获取连接等待超时时间
max-wait: 60000
#间隔多久进行一次检测,检测需要关闭的空闲连接
time-between-eviction-runs-millis: 60000
#一个连接在池中最小生存的时间
min-evictable-idle-time-millis: 300000
validation-query: SELECT 'x'
test-while-idle: true
test-on-borrow: false
test-on-return: false
#打开PSCache,并指定每个连接上PSCache的大小。oracle设为true,mysql设为false。分库分表较多推荐设置为false
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 20
mybatis:
type-aliases-package: com.xdclass.mysql.persist
config-location: classpath:mybatis-config.xml
mapper-locations: classpath*:mappers/**/*Mapper.xml
#pagehelper
pagehelper:
helperDialect: mysql
reasonable: true
supportMethodsArguments: true
params: count=countSql
returnPageInfo: check
- 使用自动plugin插件自动生成sql xml文件配置
<build>
<plugins>
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.7</version>
<configuration>
<configurationFile>tools/generatorConfig-xdclass.xml</configurationFile>
<verbose>true</verbose>
<overwrite>true</overwrite>
</configuration>
<executions>
<execution>
<id>Generate MyBatis Artifacts</id>
<phase>none</phase>
<goals>
<goal>generate</goal>
</goals>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-core</artifactId>
<version>1.3.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.24</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
第2集 Mybatis Gennerator的使用
简介:Mybatis自动生成工具的使用
-
定义:MyBatis Generator 是 MyBatis 提供的一个代码生成工具。可以帮我们生成表对应的持久化对象(po)、操作数据库的接口(dao)、CRUD sql的xml(mapper)
-
自动生成增删改查SQL
-
配置项
- 配置context,id : 随便填,保证多个 context id 不重复就行
- jdbcConnection:MyBatis Generator 需要链接数据库,所以需要配置jdbcConnection
- javaTypeResolver:javaTypeResolver 是配置 JDBC 与 java 的类型转换规则,或者你也可以不用配置,使用它默认的转换规则
- sqlMapGenerator:xml生成的目录
- javaClientGenerator:java代码生成的目录
-
配置样例
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE generatorConfiguration PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN" "http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd" > <generatorConfiguration> <context id="xdclass" targetRuntime="MyBatis3"> <!-- 用反引号`包裹,默认是双引号"--> <property name="autoDelimitKeywords" value="true"/> <property name="beginningDelimiter" value="`"/> <property name="endingDelimiter" value="`"/> <property name="javaFileEncoding" value="UTF-8"/> <plugin type="org.mybatis.generator.plugins.EqualsHashCodePlugin"/> <plugin type="org.mybatis.generator.plugins.ToStringPlugin"/> <plugin type="org.mybatis.generator.plugins.MapperAnnotationPlugin"/> <plugin type="org.mybatis.generator.plugins.UnmergeableXmlMappersPlugin"/> <jdbcConnection driverClass="com.mysql.jdbc.Driver" connectionURL="jdbc:mysql://localhost:3306/xdclass_mysql?useUnicode=true&characterEncoding=UTF-8" userId="xdclass" password="xdclass"> </jdbcConnection> <!-- java type resolver --> <javaTypeResolver> <property name="forceBigDecimals" value="false"/> <property name="useJSR310Types" value="true"/> </javaTypeResolver> <!-- gem entity --> <javaModelGenerator targetPackage="com.xdclass.mysql.model" targetProject="./src/main/java"> <property name="enableSubPackages" value="true"/> <property name="trimStrings" value="false"/> </javaModelGenerator> <!-- gem sql map --> <sqlMapGenerator targetPackage="mappers/xdclass/generated" targetProject="./src/main/resources/"> <property name="enableSubPackages" value="true"/> </sqlMapGenerator> <!-- gem mapper --> <javaClientGenerator type="XMLMAPPER" targetPackage="com.xdclass.mysql.persist.mapper.generated" targetProject="./src/main/java"> <property name="enableSubPackages" value="true"/> </javaClientGenerator> <table tableName="user" domainObjectName="User" mapperName="UserMapper" enableCountByExample="false" enableUpdateByExample="false" enableDeleteByExample="false" enableSelectByExample="false" selectByExampleQueryId="false" enableDeleteByPrimaryKey="true" enableInsert="true" enableSelectByPrimaryKey="true" enableUpdateByPrimaryKey="true"> <columnOverride column="is_default_type" property="defaultType" javaType="java.lang.Boolean" jdbcType="TINYINT"/> </table> </context> </generatorConfiguration>
第3集 基于Mybatis自定义SQL
简介:基于Mybatis自定义SQL*
-
新建mappes.xdclass.custom包用于存储自定义XML定义信息
- 指定resultMap和返回列sql
-
新建mapper.custom用于存储自定义mapper接口
- 加入@Mapper接口
-
进行自定义mapper查询接口测试案例
第4集 Mybatis执行原理源码解析
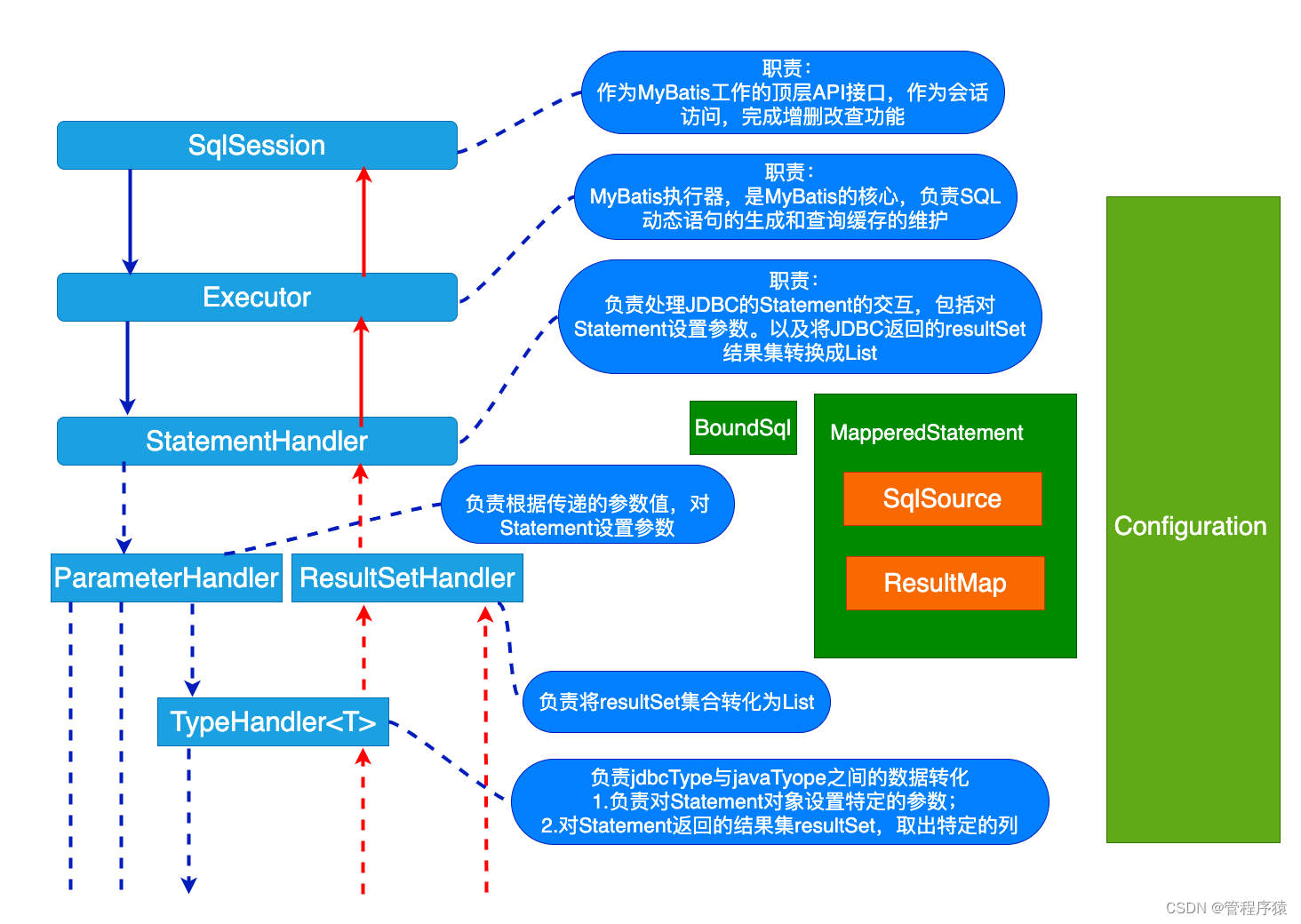
简介:Mybatis Executor执行过程解析
- 关于Executor解析过程中的流程分析
-
解读源码的学习习惯
- **理论先行。**阅读某一个模块时,先搜索它的理论支撑
- **巧用调试。**关于IDEA中debug的使用方式
- **业务为先。**如果一个类太过庞大,则先将其中的方法按功能归类,捋清大致的执行流程,接下来再逐个功能地去攻克
- **不求甚解。**有些方法不需要搞清楚实现过程,只需要了解它的作用
第5集 高级面试题之Mybatis自定义拦截器
简介:经典面试题之Mybatis自定义拦截器
-
拦截器作用:拦截某些方法的调用,我们可以选择在这些被拦截的方法执行前后加上某些逻辑,也可以在执行这些被拦截的方法时执行自己的逻辑而不再执行被拦截的方法。
-
对于实现自己的 Interceptor 而言有两个很重要的注解,一个是 @Intercepts,其值是一个@Signature 数组。@Intercepts 用于表明当前的对象是一个 Interceptor,而 @Signature则表明要拦截的接口、方法以及对应的参数类型
-
@Signature 的参数:
- type:要拦截的接口
- method:需要拦截的方法,存在于要拦截的接口之中
- args:被拦截的方法所需要的参数
-
步骤:
- 实现org.apache.ibatis.plugin.Interceptor
- 重载intercept方法实现逻辑
- 将拦截器注入到config配置中
第四章 MySQL性能优化分析
第1集 基于Durid分析Mysql执行性能
简介:怎么观察Mysql数据库执行性能
-
配置Durid打开SQL执行监控
@Configuration public class DruidConfig { @Value("${druid.login.user_name}") private String userName; @Value("${druid.login.password}") private String password; /** * 必须配置数据源,不然无法获取到sql监控,与sql防火墙监控 */ @ConfigurationProperties(prefix = "spring.datasource") public DataSource druidDataSource() { return new DruidDataSource(); } @Bean public ServletRegistrationBean druidServlet() { ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(); servletRegistrationBean.setServlet(new StatViewServlet()); servletRegistrationBean.addUrlMappings("/druid/*"); Map<String, String> initParameters = new HashMap<>(); initParameters.put("loginUsername", userName);// 用户名 initParameters.put("loginPassword", password);// 密码 initParameters.put("resetEnable", "false");// 禁用HTML页面上的“Reset All”功能 servletRegistrationBean.setInitParameters(initParameters); return servletRegistrationBean; } @Bean public FilterRegistrationBean filterRegistrationBean() { FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(); filterRegistrationBean.setFilter(new WebStatFilter()); filterRegistrationBean.addUrlPatterns("/*"); filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"); return filterRegistrationBean; } } -
在项目运行成功之后访问地址 127.0.0.1:8080/druid/login.html,输入账号名称和密码
-
数据源:项目中管理的所有数据源配置的详细情况
-
SQL监控 : 所执行sql语句数量、时长、执行时间分布
-
SQL防火墙 :druid提供了黑白名单的访问,可以清楚的看到sql防护情况。
-
Web应用 :目前运行的web程序的详细信息
-
URI监控 :监控到所有的请求路径的请求次数、请求时间等其他参数。
-
Session监控 : 当前的session状况,创建时间、最后活跃时间、请求次数、请求时间等详细参数
第2集 浅谈Durid数据指标
简介:Durid指标讲解与实战
-
基于durid对比查询效果
-
batchInsert代码用例编写
-
xml mapper编写
<insert id="batchInsert" parameterType="java.util.List"> insert into user (`name`, company ) VALUES <foreach collection="userList" item="item" separator=","> (#{item.name},#{item.company}) </foreach> </insert> -
分批插入service逻辑编写
int num = 50; List<User> userList = new ArrayList<>(); for (int i = 0; i < num; i++) { User u = new User(); u.setName("daniel"+i); u.setCompany("xdclass"+i); userList.add(u); } List<List<User>> partition = Lists.partition(userList, 10); partition.forEach(users -> customMapper.batchInsert(users));
-
-
对比有无索引的请求差异化
- 10万条数据,根据name查询数据记录
- 课堂作业,往数据库插入1000万条数据
第3集 Mysql数据库索引性能分析实战
简介:怎么好查,Mysql数据库查询索引性能实战
-
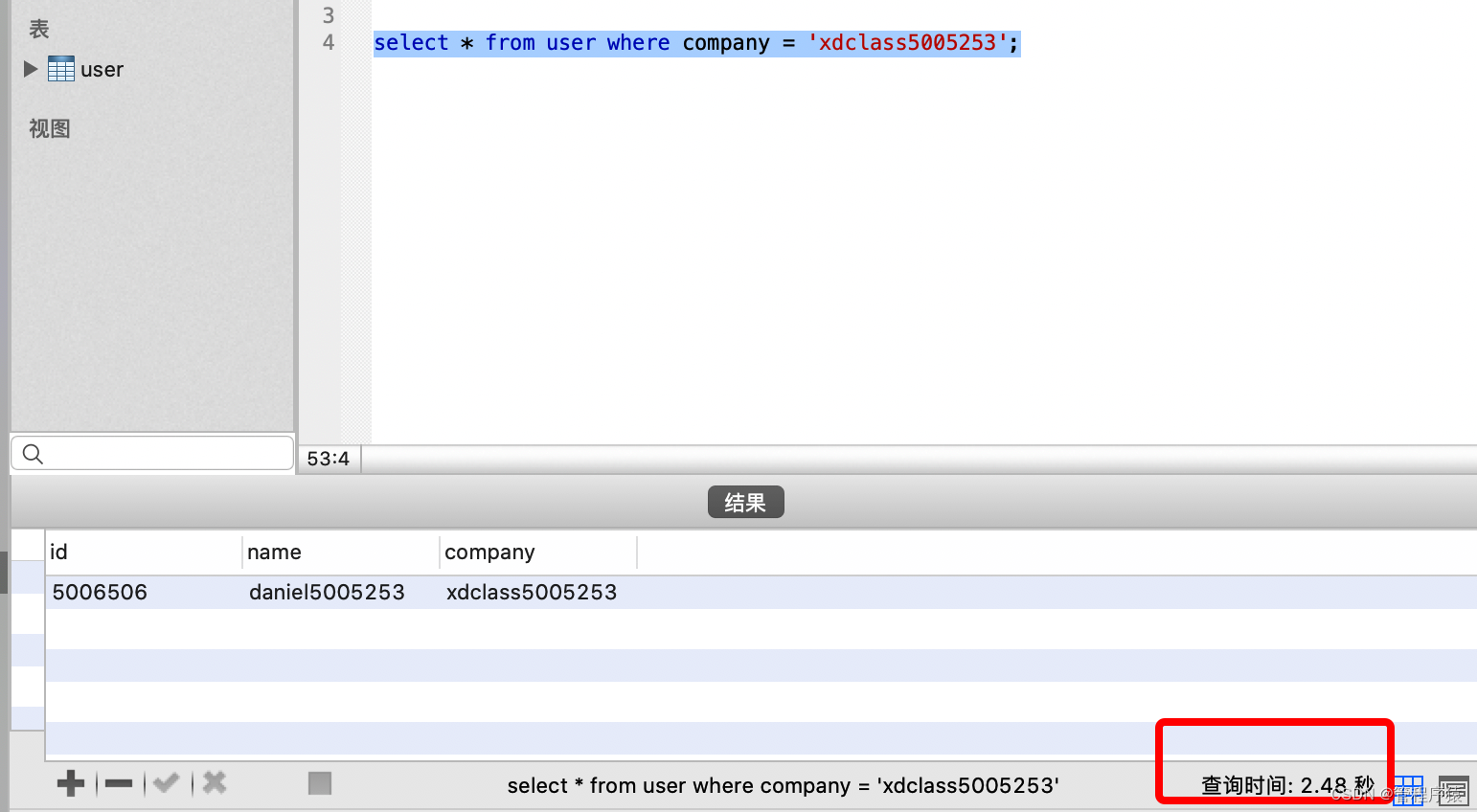
在数据量1000w的表里面对比是否采用索引数据对照组,查询使用索引前面性能对比
-
使用索引前的执行情况
- 使用索引后的执行情况
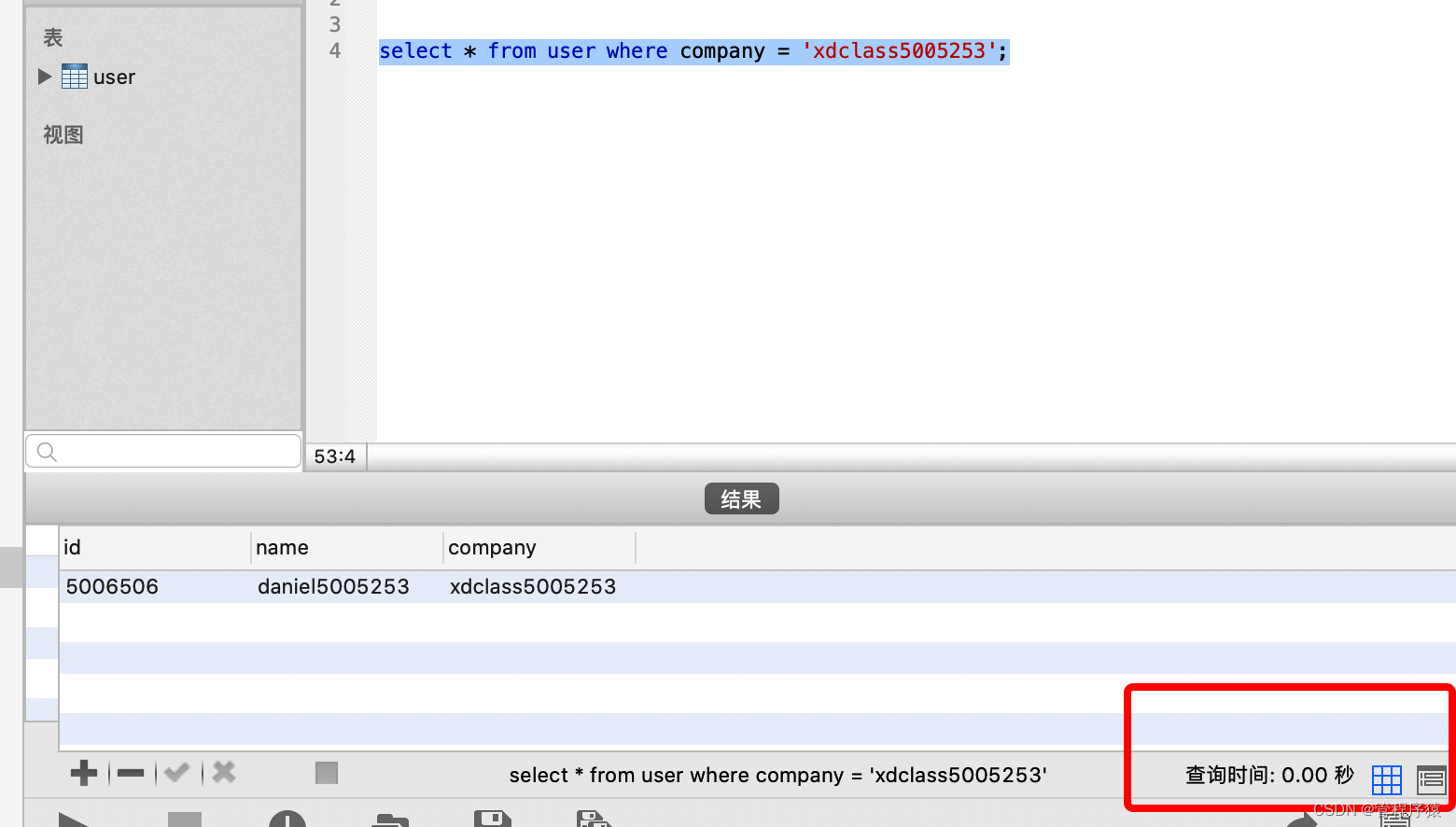
-
不适合用索引的场景
-
不适合键值较少的列(重复数据较多的列)
-
索引无法存储null值
-
-
索引失效的经典场景
- 如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因),要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- 对于多列索引,不是使用的第一部分,则不会使用索引
- like查询以%开头
- 类型强转情况下不走索引,如varchar类型用long传参来查
- hash索引不支持范围检索
第4集 高级面试题之谈谈你对MYSQL优化的理解
简介:谈谈你对SQL优化的理解
-
SQL优化可分为两个部分,一个是设计阶段,另一个是查询阶段
-
设计阶段运用到的优化
- 使用适当的数据库列类型和大小
- 尽量从设计上采用单表查询解决业务问题
- 在适当字段加入索引,能用唯一索引用唯一索引
-
查询阶段涉及的优化
- 尽可能不用
select *:让优化器无法完成索引覆盖扫描这类优化,而且还会增加额外的I/O、内存和CPU的消耗 - 慎用
join操作:单张表查询可以减少锁的竞争,更容易应对业务的发展,方便对数据库进行拆分 - 慎用子查询和临时表:未带索引的字段上的
group by操作,UNION查询,部分order by操作,例如distinct函数和order by一起使用且distinct和order by同一个字段 - 尽量不适用limit,部分场景可改用bewteen and
- 尽可能不用
第5集 高级面试题之Mysql千万级别数据如何做分页?
简介:谈谈你对SQL优化的理解
- 后端开发中为了防止一次性加载太多数据导致内存、磁盘IO都开销过大,经常需要分页展示,这个时候就需要用到MySQL的LIMIT关键字。但你以为LIMIT分页就万事大吉了么,LIMIT在数据量大的时候极可能造成深度分页问题
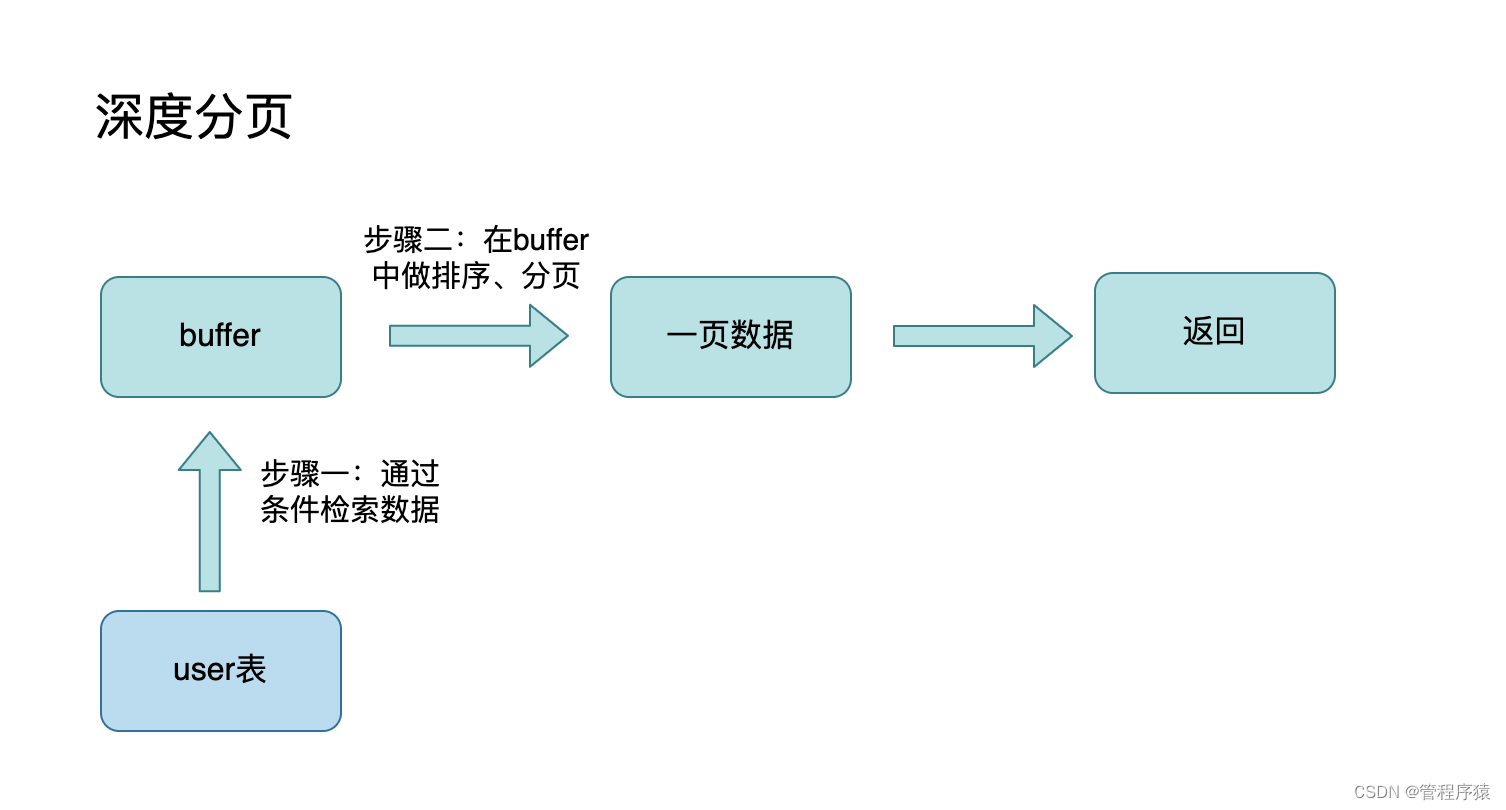
-
通过explain分析深度分页查询问题 explain select * from user where age>10 and age<90000000 order by age desc limit 8000000,10000;
-
执行计划Extra列可能出现的值及含义:
- Using where:表示优化器需要通过索引回表查询数据。
- Using index:即覆盖索引,表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表,通常是通过将待查询字段建立联合索引实现。
- Using index condition:在5.6版本后加入的新特性,即大名鼎鼎的索引下推,是MySQL关于
减少回表次数的重大优化。 - Using filesort:文件排序,这个一般在ORDER BY时候,数据量过大,MySQL会将所有数据召回内存中排序,比较消耗资源。
-
解决方案
-
通过主键索引优化
- 在查询条件中带上主键索引 explain select * from user where id>{maxId} age>10 and age<90000000 order by age desc limit 8000000,10000;
-
Elastic Search搜索引擎优化(倒排索引)
-
实际上类似于淘宝这样的电商基本上都是把所有商品放进ES搜索引擎里的(那么海量的数据,放进MySQL是不可能的,放进Redis也不现实)。但即使用了ES搜索引擎,也还是有可能发生深度分页的问题的,这时怎么办呢?答案是通过游标scroll
-
第五章 高性能索引讲解
第1集 索引是什么?
简介:介绍索引是什么?为什么要引入索引
-
索引的概念:索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度
-
索引的作用:索引的目的在于提高查询效率,使原始的随机全表扫描变成快速顺序锁定数据
-
常用索引的分类:
- 普通索引:这是最基本的索引,它没有任何限制
- 唯一索引:引列的值必须唯一,但允许有空值(注意和主键不同)
- 组合索引:多个数据列组成的索引,遵守最左匹配原则
-
索引高性能保证:
-
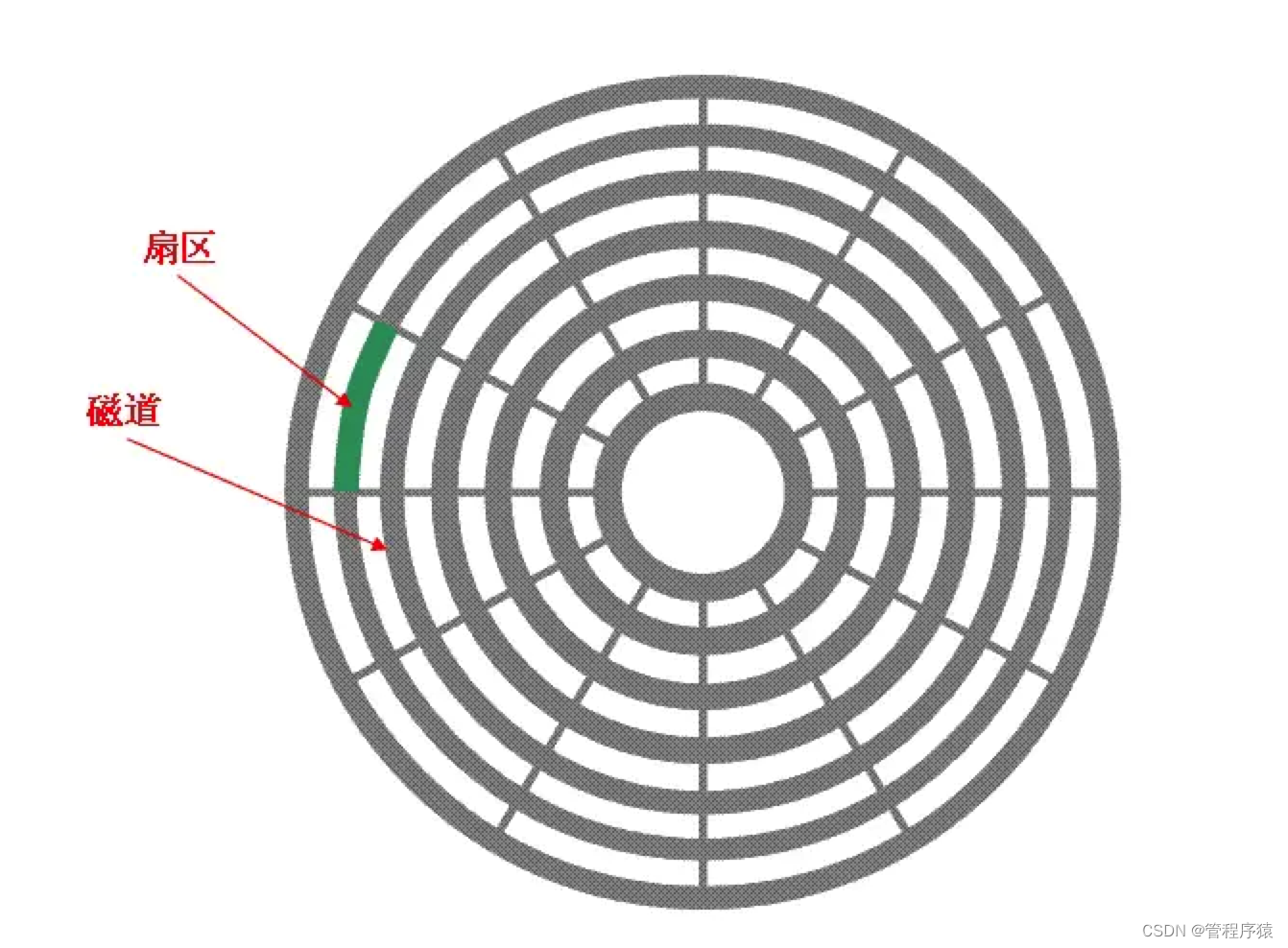
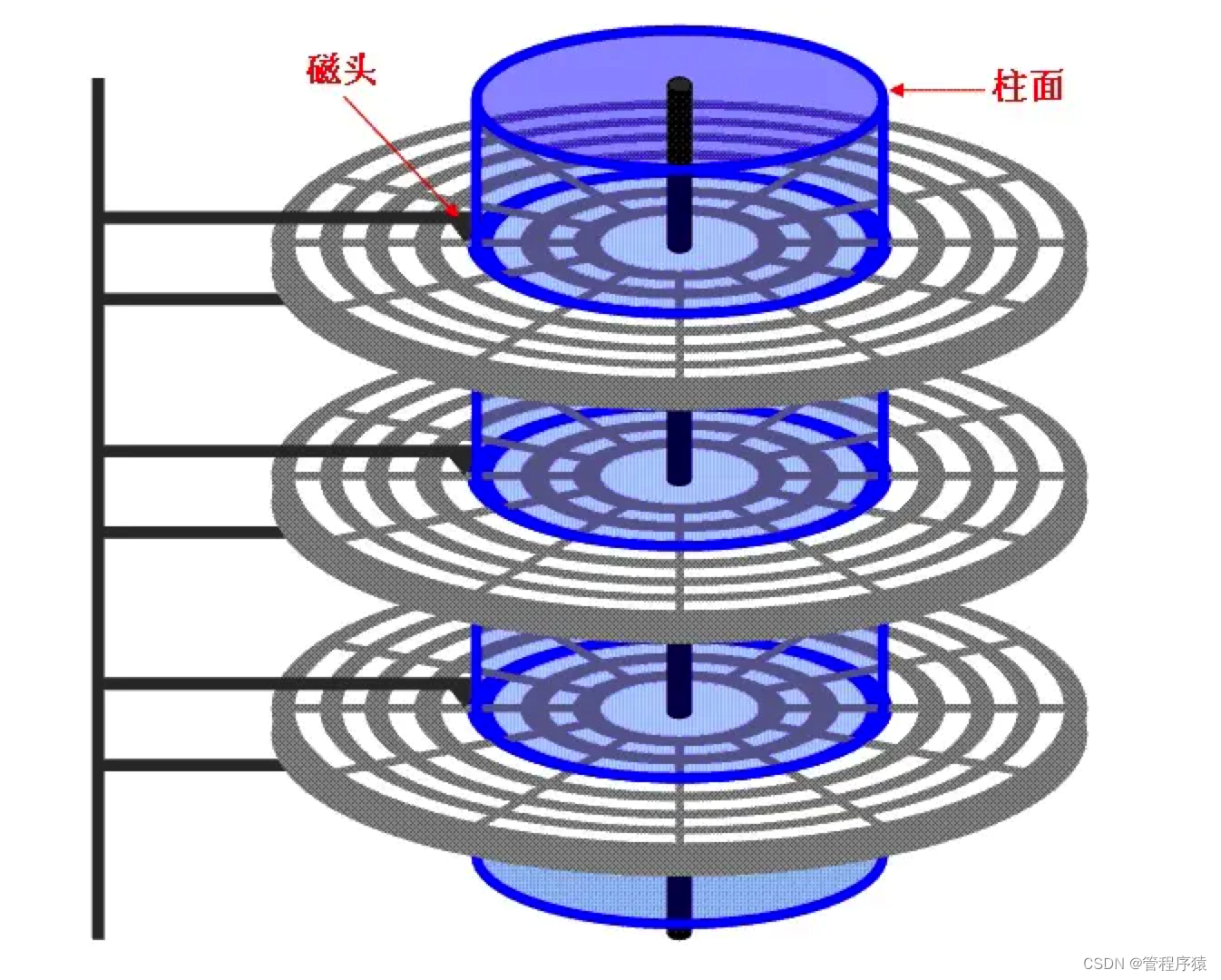
扩展话题:为什么磁盘读取数据很慢:
- 与主存不同,磁盘I/O存在机械运动耗费,因此磁盘I/O的时间消耗是巨大的
- 磁盘读取时间 = 寻道时间 + 旋转时间 + 传输时间
- 当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间
第2集 索引底层实现方案解析
简介:索引底层实现原理
-
索引的目的:提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql
-
索引设计难度:
- 查询要求:等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)
- 数据量:超过一千万数据通过索引查询,查询性能保证
-
常见检索方案分析:
- 顺序检索:最基本的查询算法-复杂度O(n),大数据量此算法效率糟糕
- 二叉树查找(binary tree search): O(log2n),单层节点所能存储数据量较少,需要遍历多层才能定位到数据,总结点数k与高度h的关系为,k =
[
- hash索引 无法满足范围查找,优点:等值检索快,hash值==》物理地址 x018,范围检索
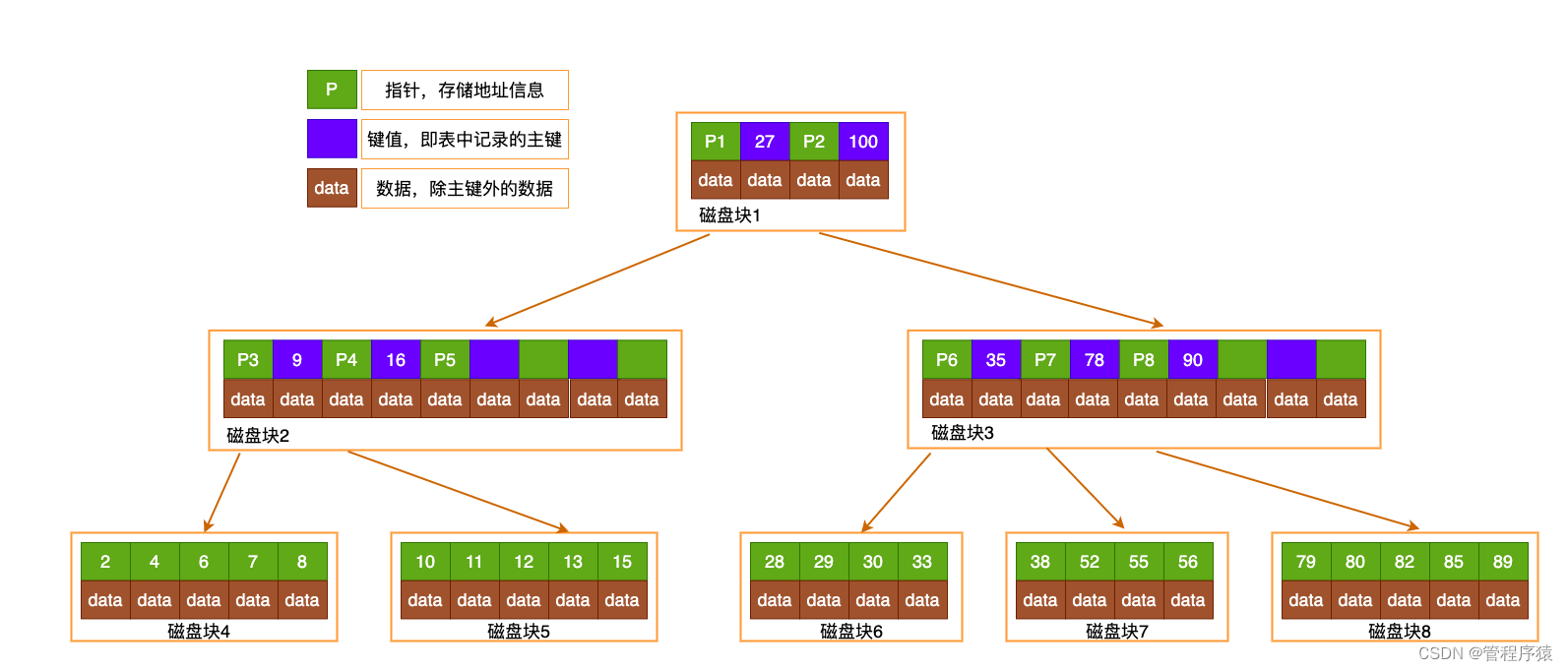
- B-TREE 每个节点都是一个二元数组: [key, data],所有节点都可以存储数据。key为索引key,data为除key之外的数据
第3集 B+Tree数据结构解析
简介: B+Tree结构解析高性能分析
-
B-Tree的缺点:插入删除新的数据记录会破坏B-Tree的性质,因此在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质。造成IO操作频繁。区间查找可能需要返回上层节点重复遍历,IO操作繁琐
-
B+Tree的改进:非叶子节点不存储data,只存储索引key;只有叶子节点才存储data
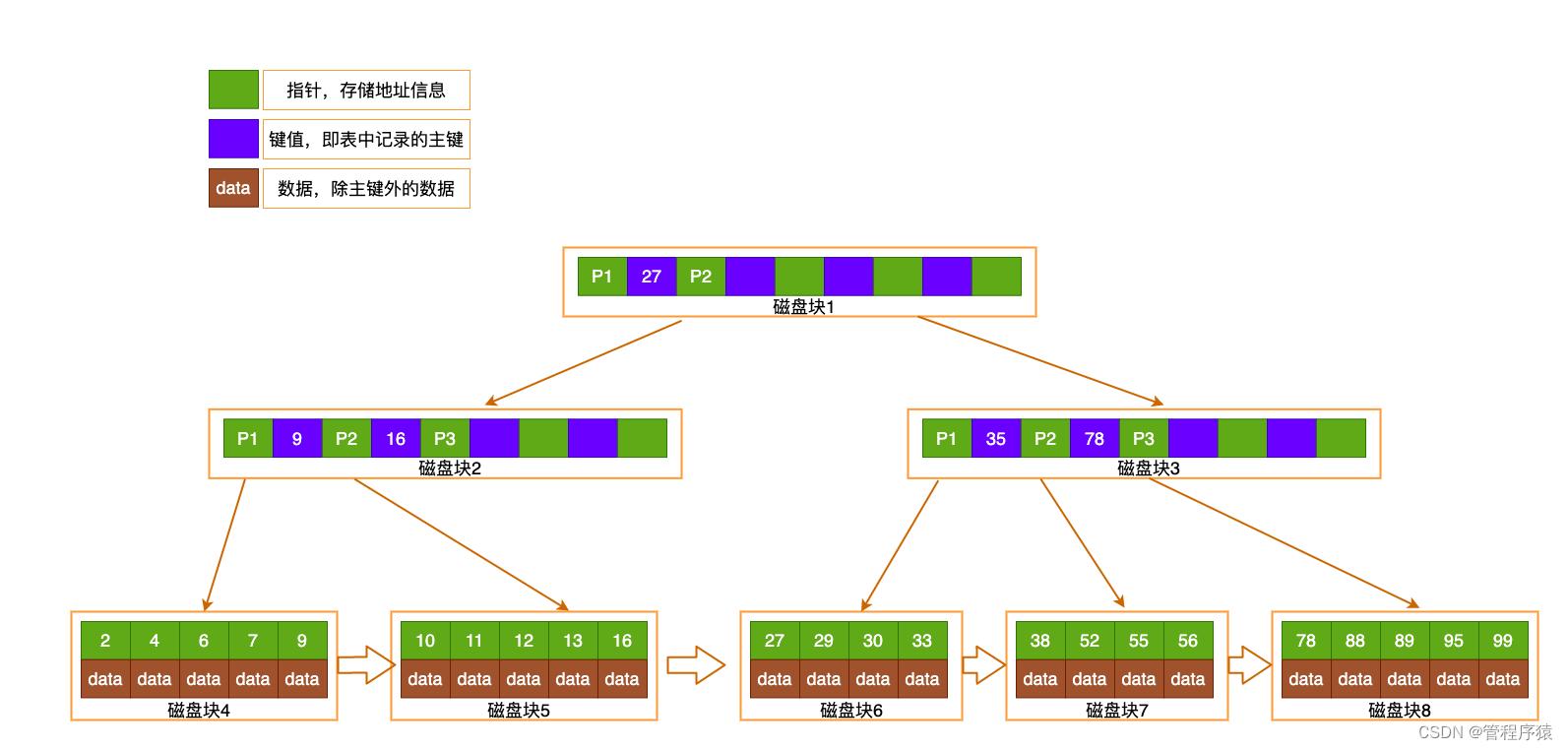
-
高性能保证:
- 3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高
- 在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,就形成了带有顺序访问指针的B+Tree
- B+TREE 只在叶子节点存储数据 & 所有叶子结点包含一个链指针 & 其他内层非叶子节点只存储索引数据。只利用索引快速定位数据索引范围,先定位索引再通过索引高效快速定位数据。
第4集 InnoDB索引的结构是怎样的
简介:InnoDB索引结构
- InnoDB的存储结构是怎样的?
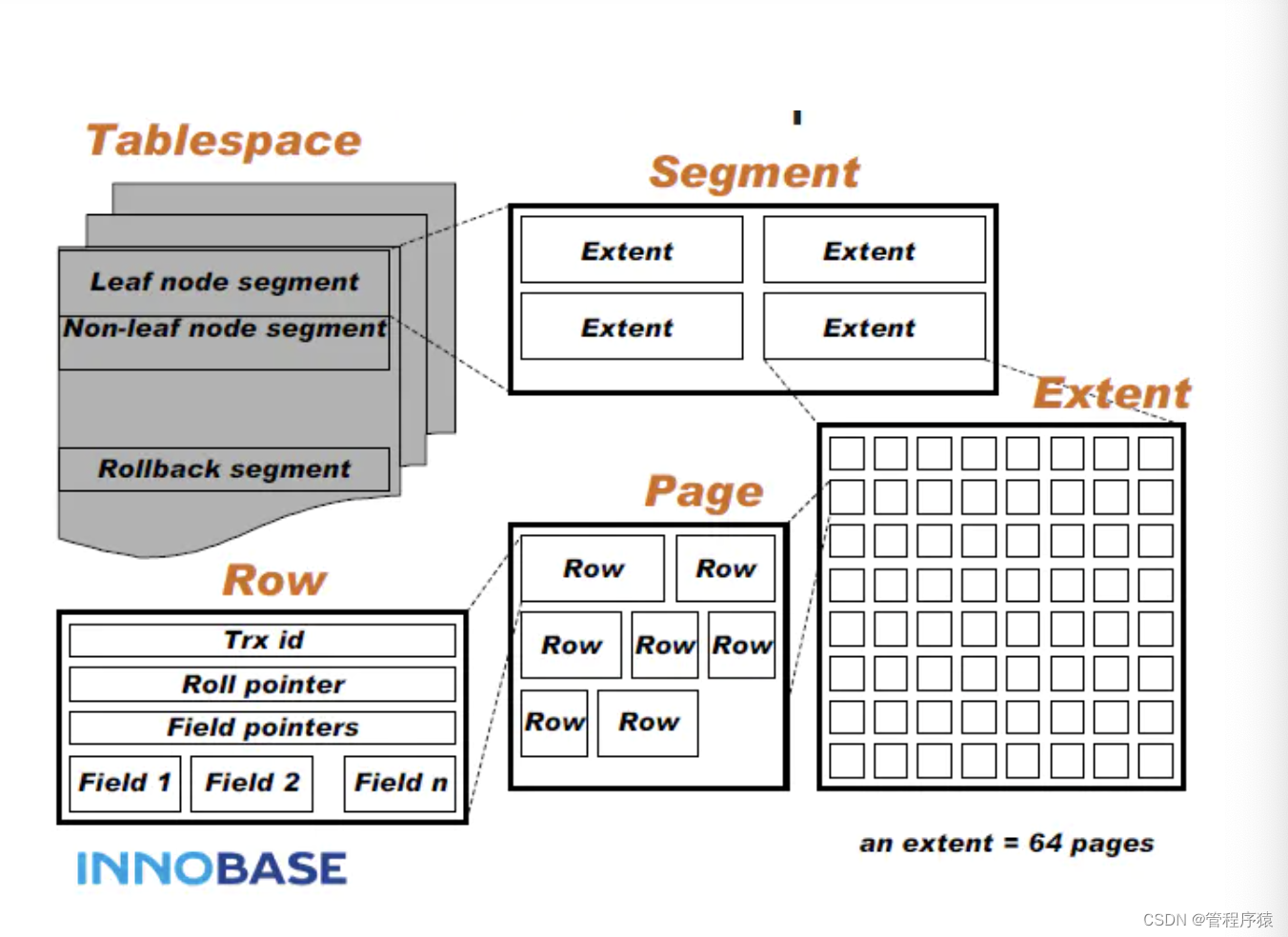
-
InnoDB物理存储结构分析
- InnoDB以表空间Tablespace(idb文件)结构进行组织,每个Tablespace 包含多个Segment段,每个段(分为2种段:叶子节点Segment&非叶子节点Segment), 一个Segment段包含多个Extent,一个Extent占用1M空间包含64个Page(每个Page 16k),InnoDB B+Tree 一个逻辑节点就分配一个物理Page,一个节点一次IO操作。,一个Page里包含很多有序数据Row行数据,Row行数据中包含Filed属性数据等信息
-
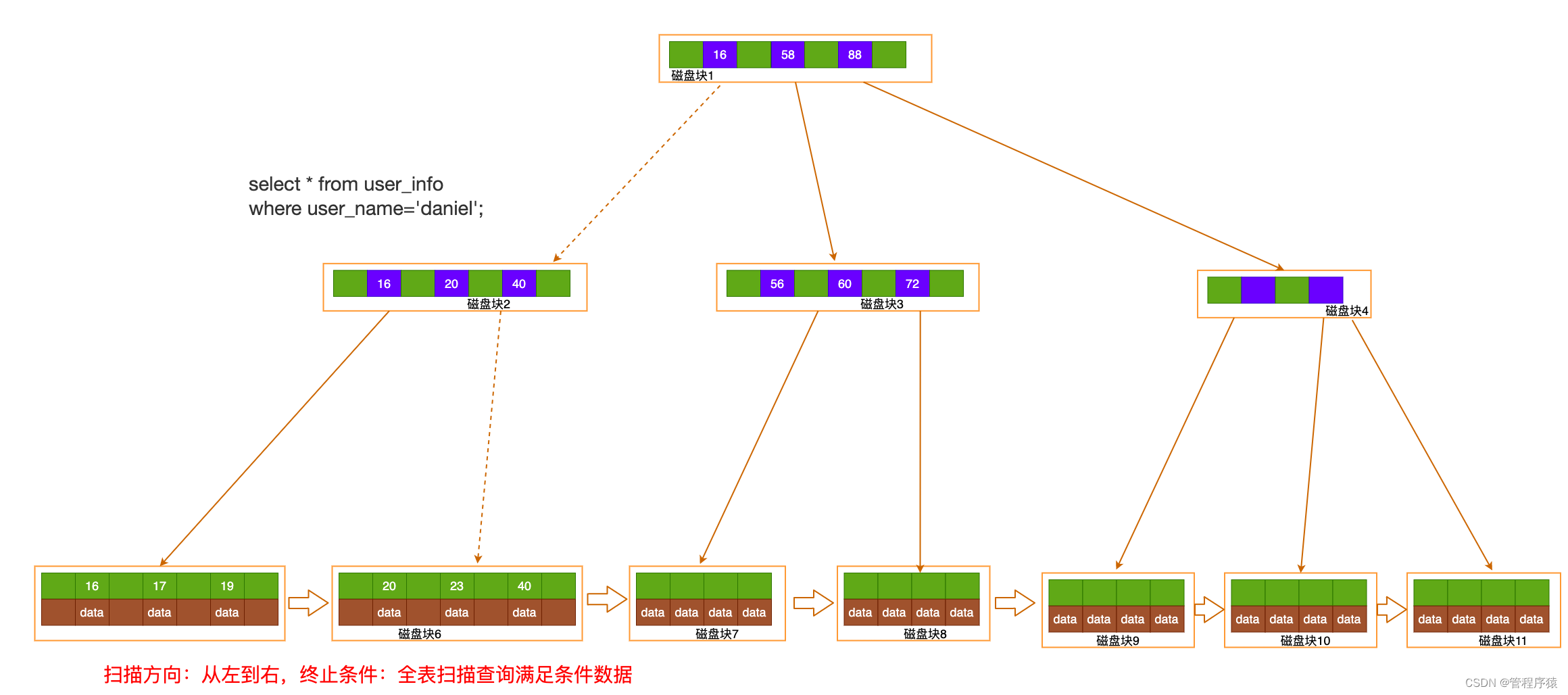
索引值匹配检索过程:确定定位条件, 找到根节点Page No, 根节点读到内存, 逐层向下查找, 读取叶子节点Page,通过 二分查找找到记录或未命中。(select * from user_info where id = 23) 查询类接口一般在30ms~50ms 插入、修改一般在50ms~100ms
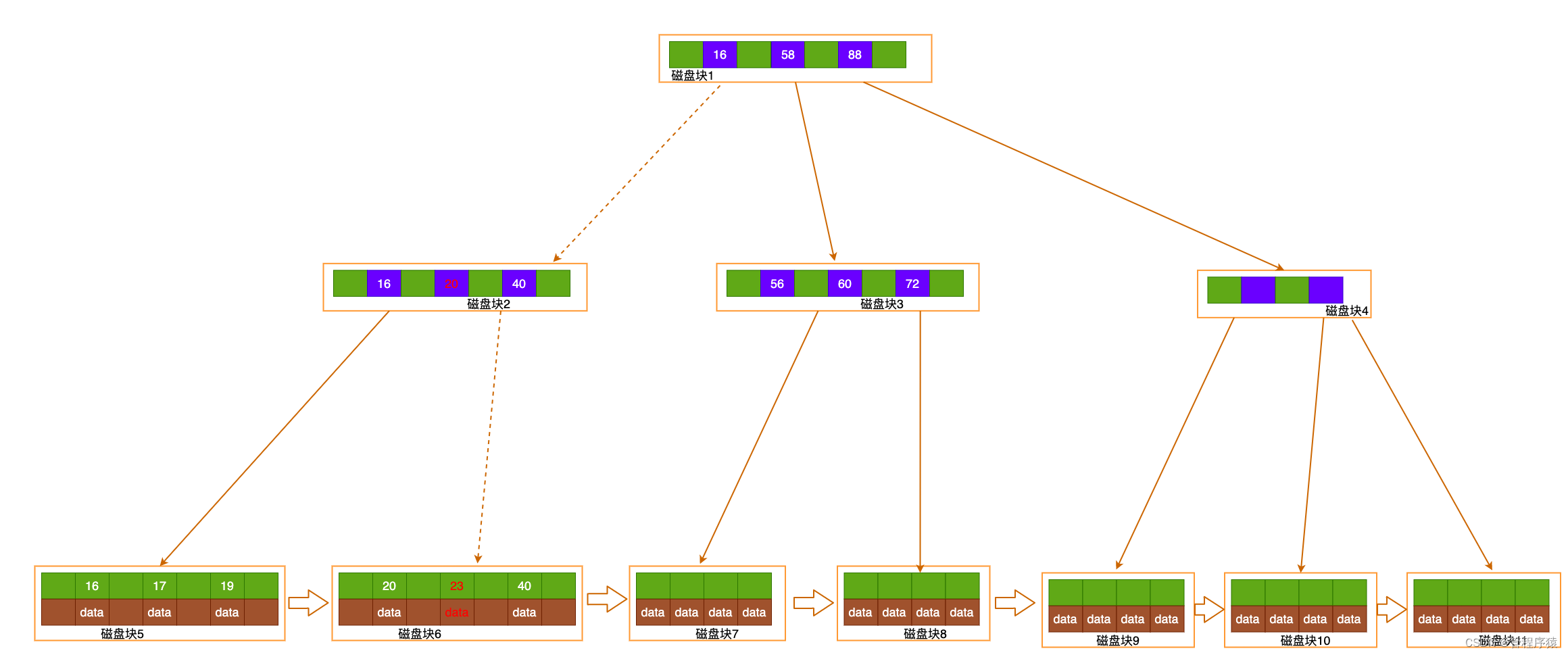
-
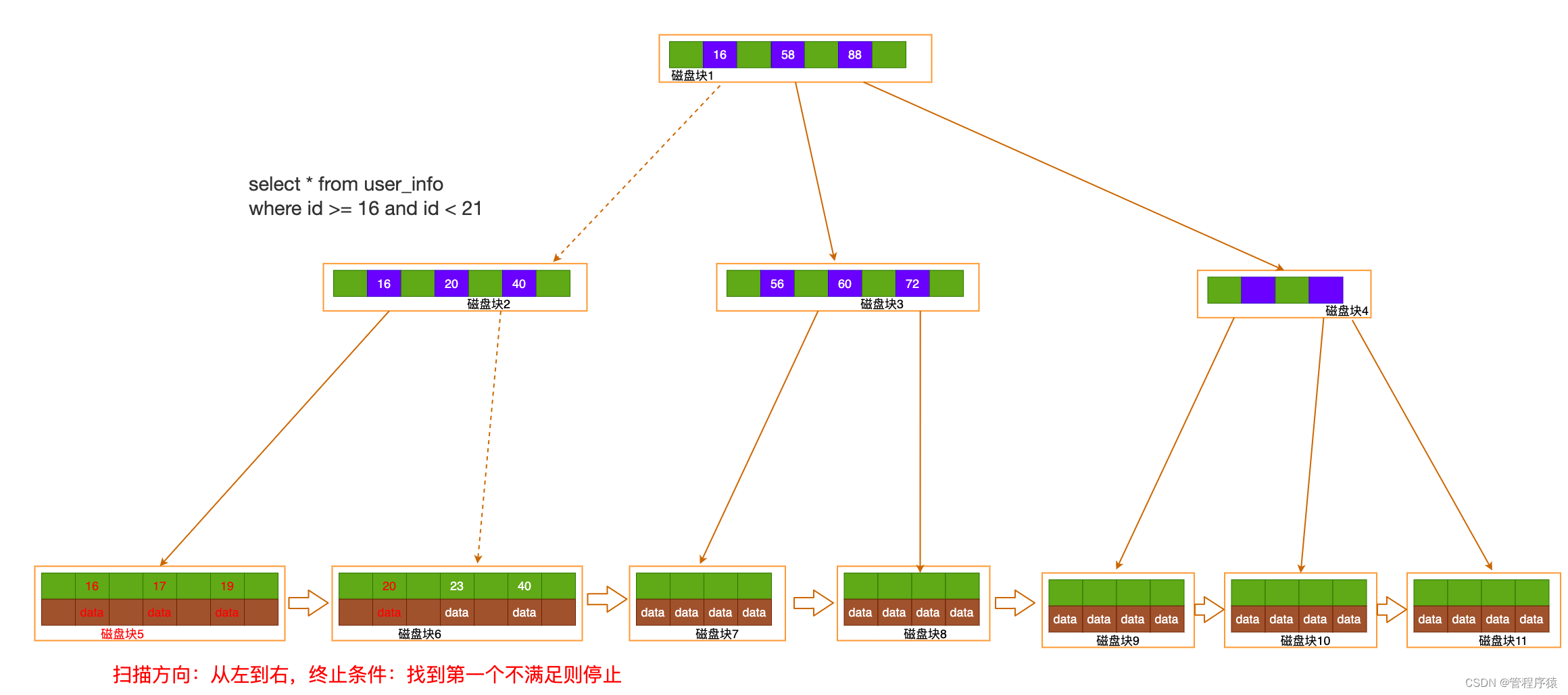
索引范围查找:读取根节点至内存, 确定索引定位条件id=18, 找到满足条件第一个叶节点
, 顺序扫描所有结果, 直到终止条件满足id >=21 (select * from user_info where id >= 16 and id < 21)
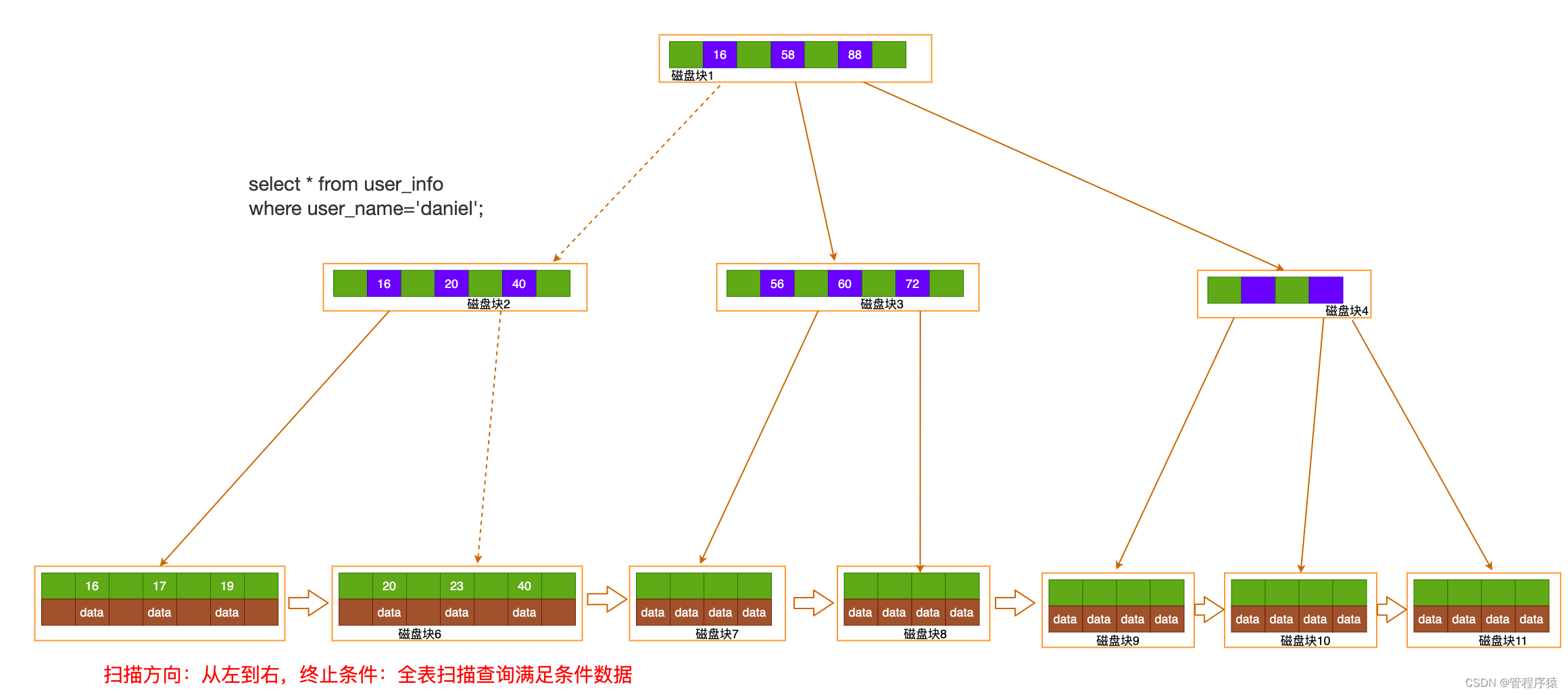
- 全表扫描:直接读取叶节点头结点, 顺序扫描, 返回符合条件记录, 到最终节点结束(select * from user_info where user_name = ‘daniel’)
第5集 innodb索引与myIsam索引对比
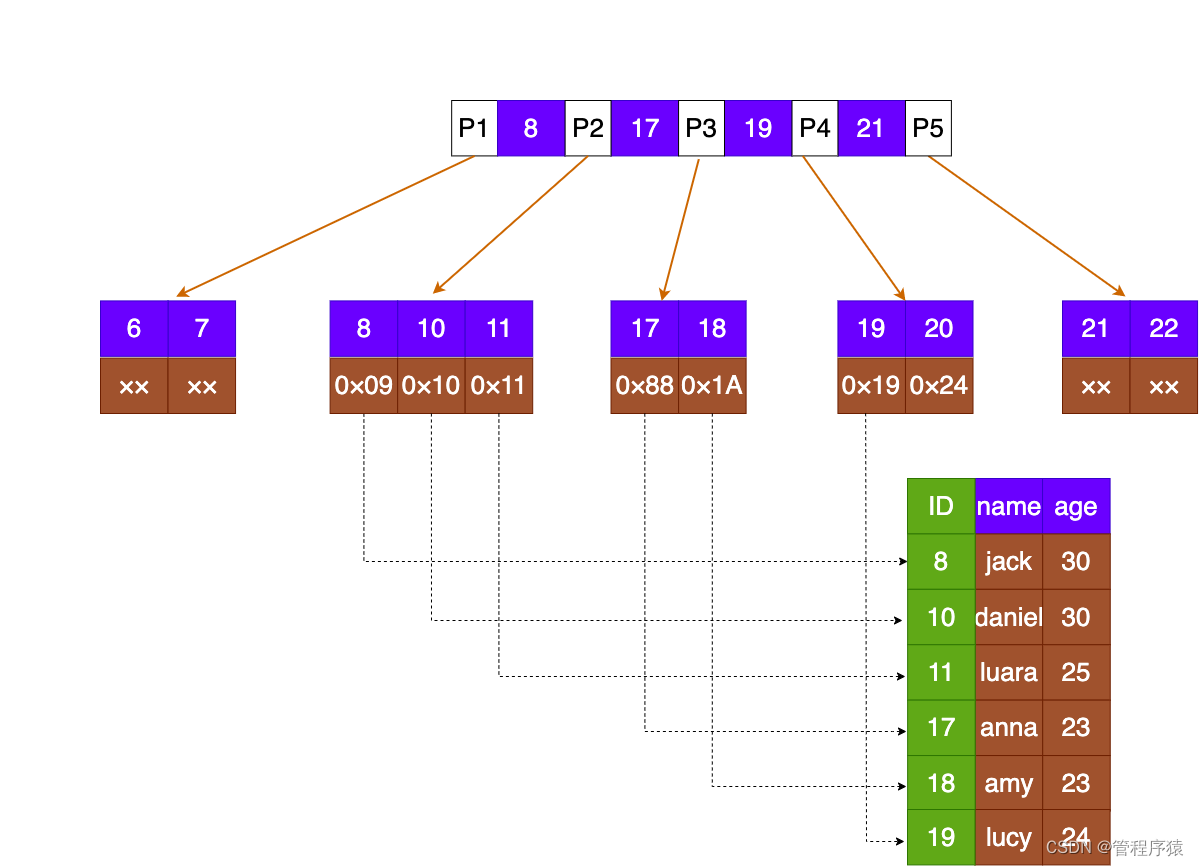
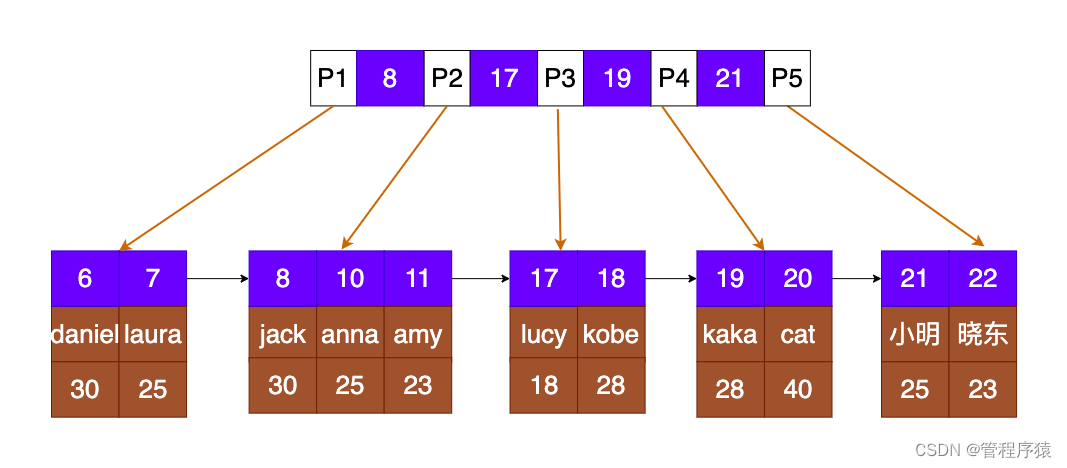
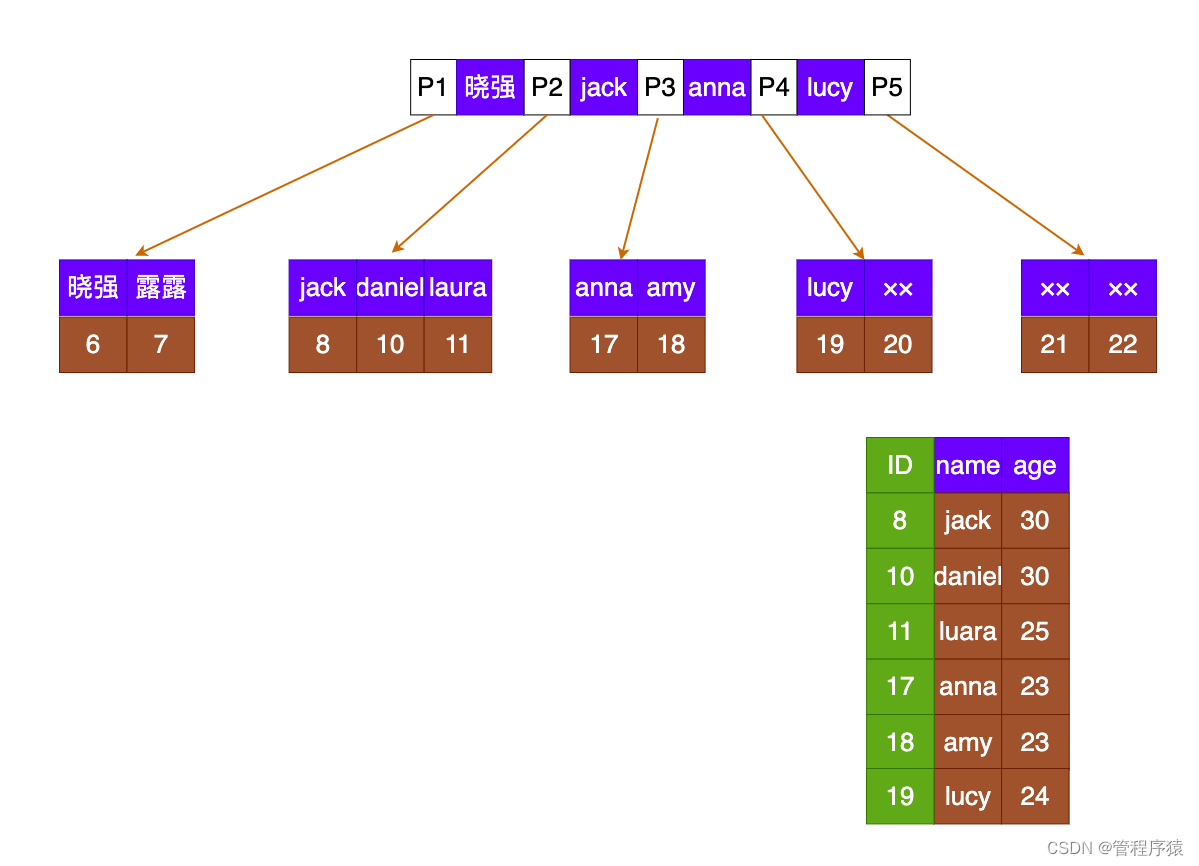
简介:innoDB索引和myIsam索引对比
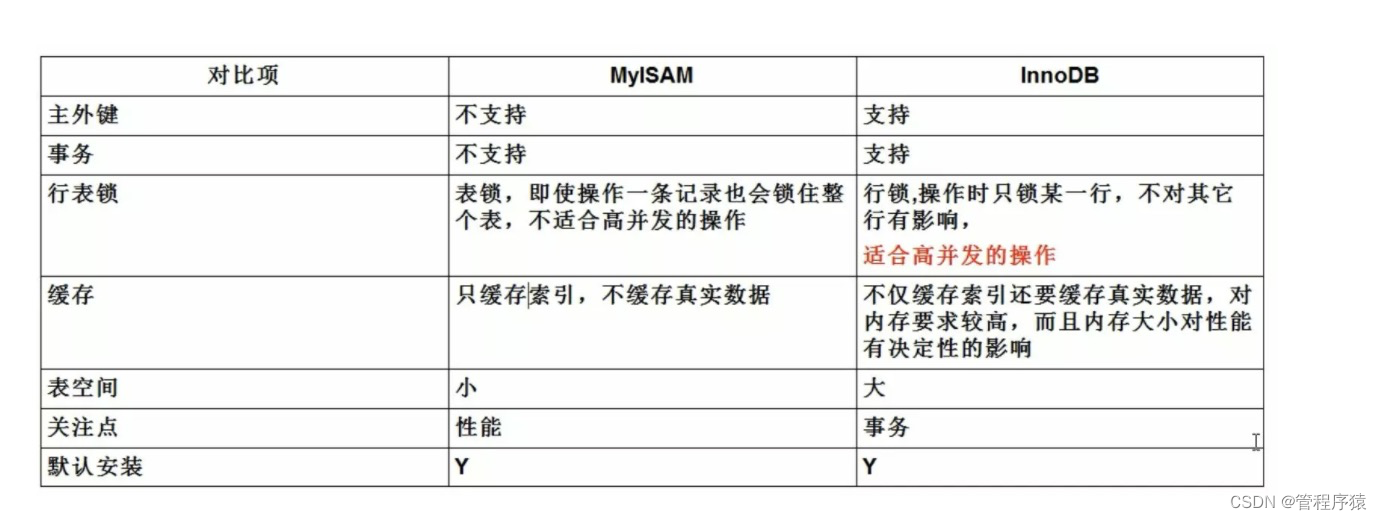
- innoDB索引与myIsam索引的区别
- MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址,MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复
- 在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引
- 第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域
myIsam索引:
InnoDB主键索引:
InnoDB非主键索引:
第6集 Mysql为什么会选错索引
简介:Mysql为什么会选错索引
-
场景分析
CREATE TABLE `test` ( `id` int(11) NOT NULL, `a` int(11) NOT NULL default 0, `b` int(11) NOT NULL default 0, PRIMARY KEY (`id`), KEY `a` (`a`), KEY `b` (`b`) ) ENGINE=InnoDB; delimiter ;; create procedure xddata() begin declare i int; set i=1; while(i<=100000)do insert into test values(i, i, i); set i=i+1; end while; end;; delimiter ; call xddata(); explain select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1; -
原因分析:
- 在多个索引的情况下,优化器一般会通过比较扫描行数、是否需要临时表以及是否需要排序等,来作为选择索引的判断依据
- 选择索引 b,则需要在 b 索引上扫描 5w 条记录,然后同样回到主键索引上过滤掉不满足 a 条件的记录,因为索引有序,所以使用 b 索引不需要额外排序
-
解决方案
- 使用force index a让mysql直接选择a索引来处理此处查询
select * from test where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1; select * from test force index(a) where (a between 1000 and 2000) and (b between 50000 and 100000) order by b limit 1; -
其他场景:
- 数据表有频繁的删除或更新操作导致的数据空洞造成的
- 造成原因:分析器 explain 的结果预估的 rows 值跟实际情况差距比较大,分析器分析扫描行数用的是抽样调查
- 解决方案:统计信息不对,那就修正。analyze table test 命令,可以用来重新统计索引信息
第7 集 高级面试题之唯一索引与普通索引的区别
简介:唯一索引和普通索引的区别
-
关于唯一索引
- 定义:
UNIQUE索引可以强制执行值唯一的一列或多列。一个表可以有多个UNIQUE索引。 - 场景:联系人的电子邮件唯一、联系人的身份证唯一 123@qq.com 数据库层面的严格唯一
- 定义:
-
唯一索引与普通索引的性能区别
-
查询上的区别
- 对唯一索引,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止检索
- 对普通索引,查找到满足条件的第一个记录’ab‘后,需查找下个记录,直到碰到第一个不满足k=’ab‘条件的记录
- 结论:mysql采用page页(一页16K)为数据单位从磁盘load出数据,除非刚好值为’ab‘的记录在一页的最后一条数据,否则执行性能区别微乎其微
-
change buffer的定义
- 一种特殊的数据结构,该结构在 次要索引 中记录对 页 的更改
- 作用:提高更改索引操作性能,涉及更改缓冲区的一组功能统称为“更改缓冲区” ,由“插入缓冲区”,“删除缓冲区”和“清除缓冲区”组成
- 同步策略:当相关索引页被带入缓冲池而相关联的更改仍在更改缓冲区中时,该页的更改将使用更改缓冲区中的数据应用于缓冲池( 合并 )中。在系统大部分处于空闲状态或缓慢关机期间运行的“清除”操作会定期将新的索引页写入磁盘
-
修改上的区别
-
对于唯一索引,所有更新操作要先判断该操作是否违反唯一性约束,唯一索引不会用change buffer
-
若所修改的数据在内存中
- 找到索引对应该存储的位置,判断、到没有冲突,插入值,语句执行结束
- 找到索引对应该存储的位置,插入值,语句执行结束。
-
若所修改的数据不在内存中
- 需要将数据页读入内存,判断到没有冲突,插入值,语句执行结束
- 将更新记录在change buffer,语句执行结束
-
-
结论
- 唯一索引和普通索引在查询性能上没差别,主要考虑对更新性能影响
- 唯一索引可以从数据库上强制去重,但用不了change buffer的优化机制,从性能角度,推荐优先考虑非唯一索引
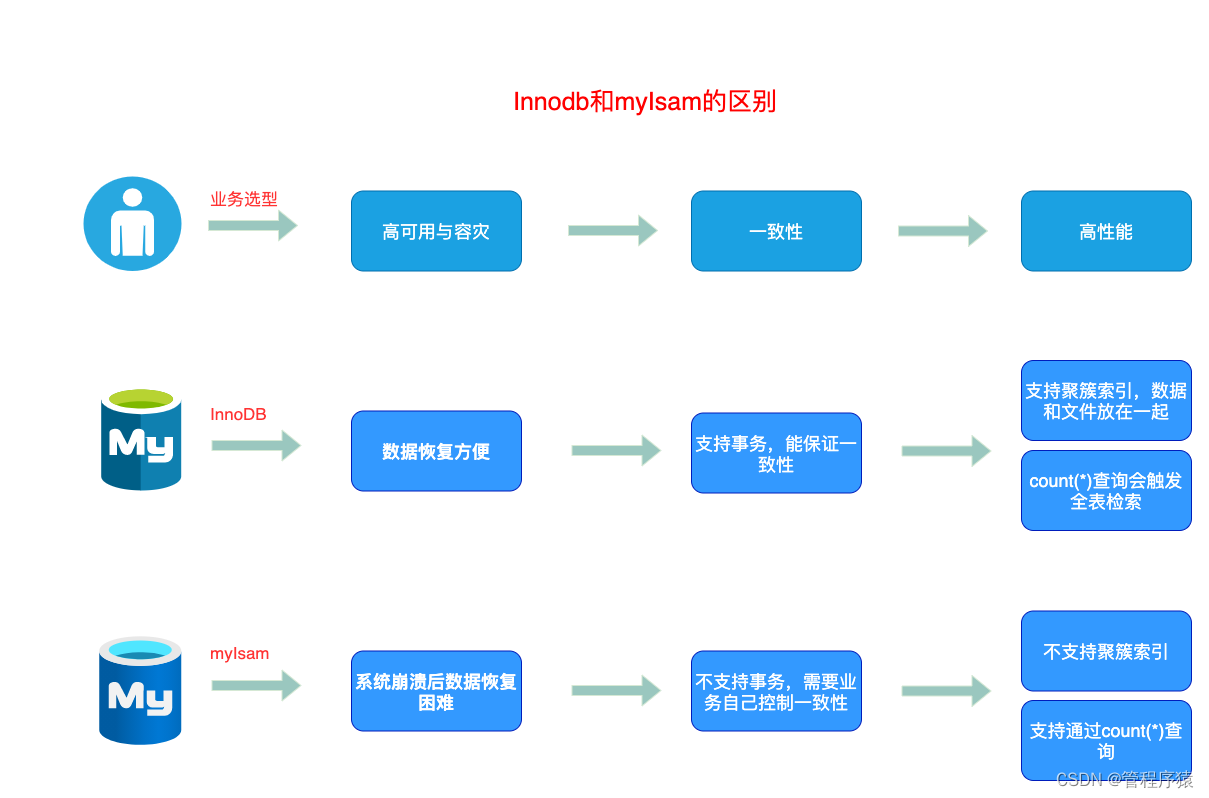
第8集 高级面试题之innodb和myIsam的区别在哪里?
简介:mysql数据库存储引擎之间的区别
-
InnoDB支持事务,MyISAM不支持
- innoDB将多条SQL语言放在begin和commit之间,组成一个事务,具备事务的ACID
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败
-
InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的
-
InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快
-
Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高
-
实际场景的选择
- 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB
- 系统奔溃后,MyISAM恢复起来更困难,能否接受;
- MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差
第六章 带你剖析Mysql事务
第1集 重温mysql事务特性
简介:mysql事务概念以及特性讲解
-
3个W原则:
- What:事务(Transaction)是并发控制的基本单位。所谓的事务,它是一个操作序列,这些操作要么都 执行,要么都不执行,它是一个不可分割的工作单位。
- Why :事务是数据库维护数据一致性的单位,在每个事务结束时,都能保持数据一致性,如积分总表和积分详情表要么一起更新、新增成功要么一起失败
- How :start transaction,step 1,step2,commit/rollback

-
事务的四大特性ACID
-
原子性(Atomicity):原子性指的是整个数据库的事务是一个不可分割的工作单位,每一个都应该是一个原子操作。
当我们执行一个事务的时候,如果一系列的操作中,有一个操作失败了,那么,需要将这一个事务中的所有操作恢复到执行事务之前的状态,这就是事务的原子性
-
一致性(Consistency):一致性是指事务将数据库从一种状态转变为下一种一致性的状态,也就是说在事务执行前后,这两种状态应该是一样的,也就是数据库的完整性约束不会被破坏,另外,需要注意的是一致性是不关注中间状态的
-
隔离性(Isolation):MySQL数据库中可以同时启动很多的事务,但是,事务和事务之间他们是相互分离的,也就是互不影响的,这就是事务的隔离性。
-
持久性(Durability):事务的持久性是指事务一旦提交,就是永久的了,就是发生问题,数据库也是可以恢复的。因此,持久性保证事务的高可靠性
-
-
mysql事务实战
第2集 Mysql事务隔离级别
简介:Mysql事务隔离级别分析
- read uncommitted(读取未提交数据):即便是事务没有commit,但是其他连接仍然能读到未提交的数据,这是所有隔离级别中最低的一种
- read committed(可以读取其他事务提交的数据):当前会话只能读取到其他事务提交的数据,未提交的数据读不到
- repeatable read(可重读)—MySQL默认的隔离级别:当前会话可以重复读,就是每次读取的结果集都相同,而不管其他事务有没有提交
- serializable(串行化):其他会话对该表的写操作将被挂起。可以看到,这是隔离级别中最严格的,但是这样做势必对性能造成影响
- 设置事务隔离级别代码
set session transaction isolation level serializable;
- 一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
1、为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
2、当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
set global transaction isolation level read uncommitted;
select @@tx_isolation;
start transaction
select * from xdclass_mysql.user where id =1;
commit;
第3集 Mysql脏读幻读不可重复读
简介:mysql脏读幻读不可重复读讲解
- 脏读:所谓脏读是指一个事务中访问到了另外一个事务未提交的数据

- 幻读:一个事务读取2次,得到的记录条数不一致

- 不可重复读:一个事务读取同一条记录2次,得到的结果不一致

- 解决方案:采用可重复读取(Repeatable Read),禁止不可重复读取和脏读取,但是有时可能出现幻读数据。这可以通过“共享读锁”和“排他写锁”实现。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
Select lock in share mode; select …for update.
第4集 Mysql数据执行过程剖析
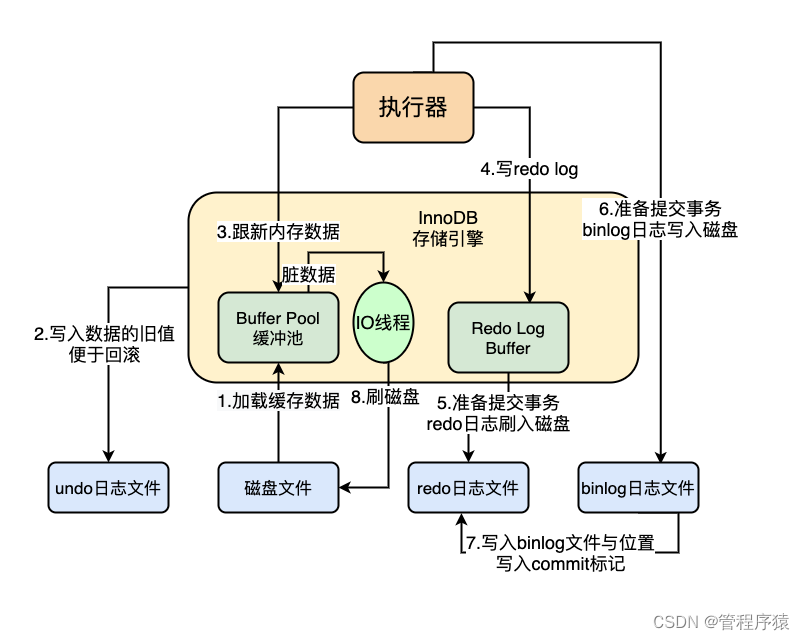
简介:mysql数据落盘步骤
-
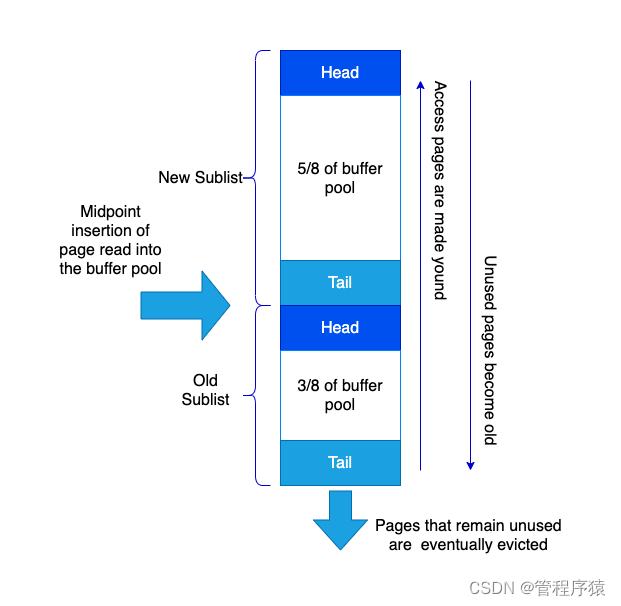
mysql从数据执行到落盘步骤分析 show variables like ‘innodb buffer pool’
-
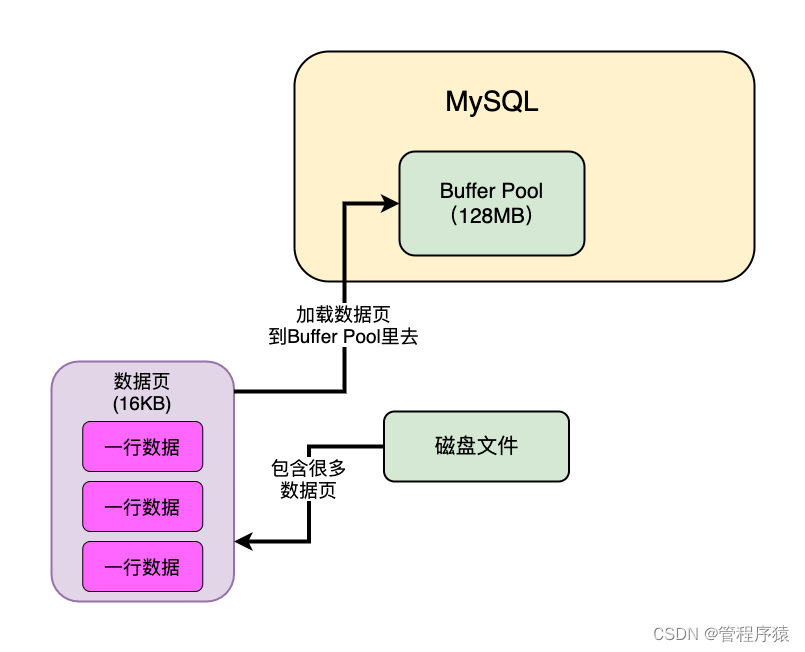
Buffer Pool是什么?
- Buffer Pool就是数据库的一个内存组件,缓存了磁盘上的真实数据,我们的系统对数据库执行的增删改操作,其实主要就是对这个内存数据结构中的缓存数据执行的
- 显示缓存区大小 show global variables like ‘innodb_buffer_pool_size’;
第5集 Mysql RedoLog与UndoLog日志
简介:Mysql 重要特性redo log和undo log日志讲解
-
InnoDB 使用undo、 redo log来保证事务原子性、一致性及持久性,同时采用预写日志方式将随机写入变成顺序追加写入,提升事务性能
-
undo log :
- 作用:记录事务变更前的状态。操作数据之前,先将数据备份到undo log,然后进行数据修改,如果出现错误或用户执行了rollback语句,则系统就可以利用undo log中的备份数据恢复到事务开始之前的状态。
- 内容:逻辑格式的日志,在执行undo的时候,仅仅是将数据从逻辑上恢复至事务之前的状态,而不是从物理页面上操作实现的
- 文件位置:位于数据库的data目录下的ibdata
-
redo log :
- 作用:记录事务变更后的状态。在事务提交前,只要将redo log持久化即可,数据在内存中变更。当系统崩溃时,虽然数据没有落盘,但是redo log已持久化,系统可以根据redo Log的内容,将所有数据恢复到最新的状态。
-
内容:物理格式的日志,记录的是物理数据页面的修改的信息,其redo log是顺序写入redo log file的物理文件中去的
- 文件位置:位于数据库的data目录下的ib_logfile1&ib_logfile2

- **checkpoint:**随着时间的积累,redo Log会变的很大很大。如果每次都从第一条记录开始恢复,恢复的过程就会很慢。为了减少恢复的时间,就引入了checkpoint机制。定期将databuffer的内容刷新到磁盘datafile内,然后清除checkpoint之前的redo log。
- 恢复:InnoDB通过加载最新快照,然后重做checkpoint之后所有事务(包括未提交和回滚了的),再通过undo log回滚那些未提交的事务,来完成数据恢复
第6集 Mysql事务MVCC结构
简介:Mysql MVCC讲解
-
InnoDB Multi-Versionning-InnoDB`是多版本存储引擎:它保留有关已更改行的旧版本的信息,以支持诸如并发和rollback的事务功能。此信息以称为rollback segment的数据结构存储在 table 空间中
-
实现原理:
InnoDB向存储在数据库中的每一行添加两个关键字段:DATA_TRX_ID和DATA_ROLL_PTR- 6字节的DATA_TRX_ID 标记了最新更新这条行记录的transaction id,每处理一个事务,其值自动+1
- DATA_ROLL_PTR则表示指向该行回滚段的指针,该行上所有旧的版本,在undo中都通过链表的形式组织,而该值,正式指向undo中该行的历史记录链表

-
MVCC的作用:
-
每行数据都存在一个版本,每次数据更新时都更新该版本
-
修改时Copy出当前版本随意修改,各个事务之间无干扰
-
把修改前的数据存放于undo log,通过回滚指针与主数据关联
-
修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
-
-
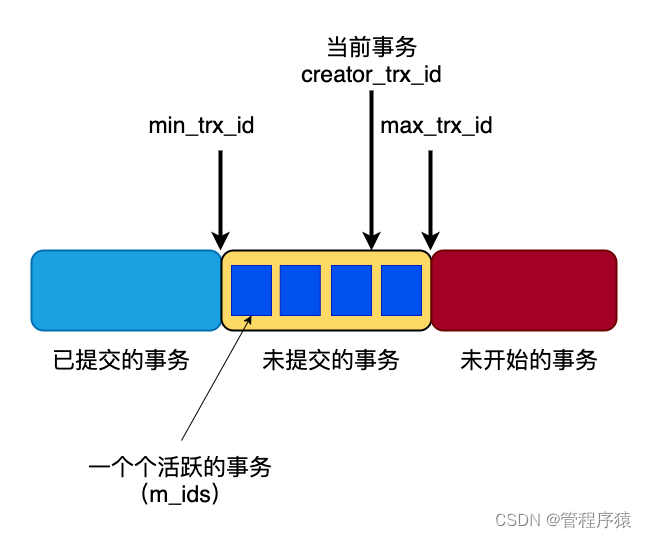
Read View: select * from user where name=‘daniel’;
-
定义:ReadView是一个数据结构,在SQL开始的时候被创建。这个数据结构中包含了3个主要的成员:ReadView{low_trx_id, up_trx_id, trx_ids},在并发情况下,一个事务在启动时,trx_sys链表中存在部分还未提交的事务,那么哪些改变对当前事务是可见的,哪些又是不可见的,这个需要通过ReadView来进行判定
-
low_trx_id表示该SQL启动时,当前事务链表中最大的事务id编号,也就是最近创建的除自身以外最大事务编号;
-
up_trx_id表示该SQL启动时,当前事务链表中最小的事务id编号,也就是当前系统中创建最早但还未提交的事务;
-
trx_ids表示所有事务链表中事务的id集合 s1: insert into user(1,“Daniel”) commit; s2: select * from user where id=1;
-
- ReadView读取区别:
- READ COMMITTED —— 每次读取数据前都生成一个ReadView
- REPEATABLE READ —— 在第一次读取数据时生成一个ReadView
第7集 InnoDB doublewrite缓冲区
简介:InndoBD doublewrite机制讲解
-
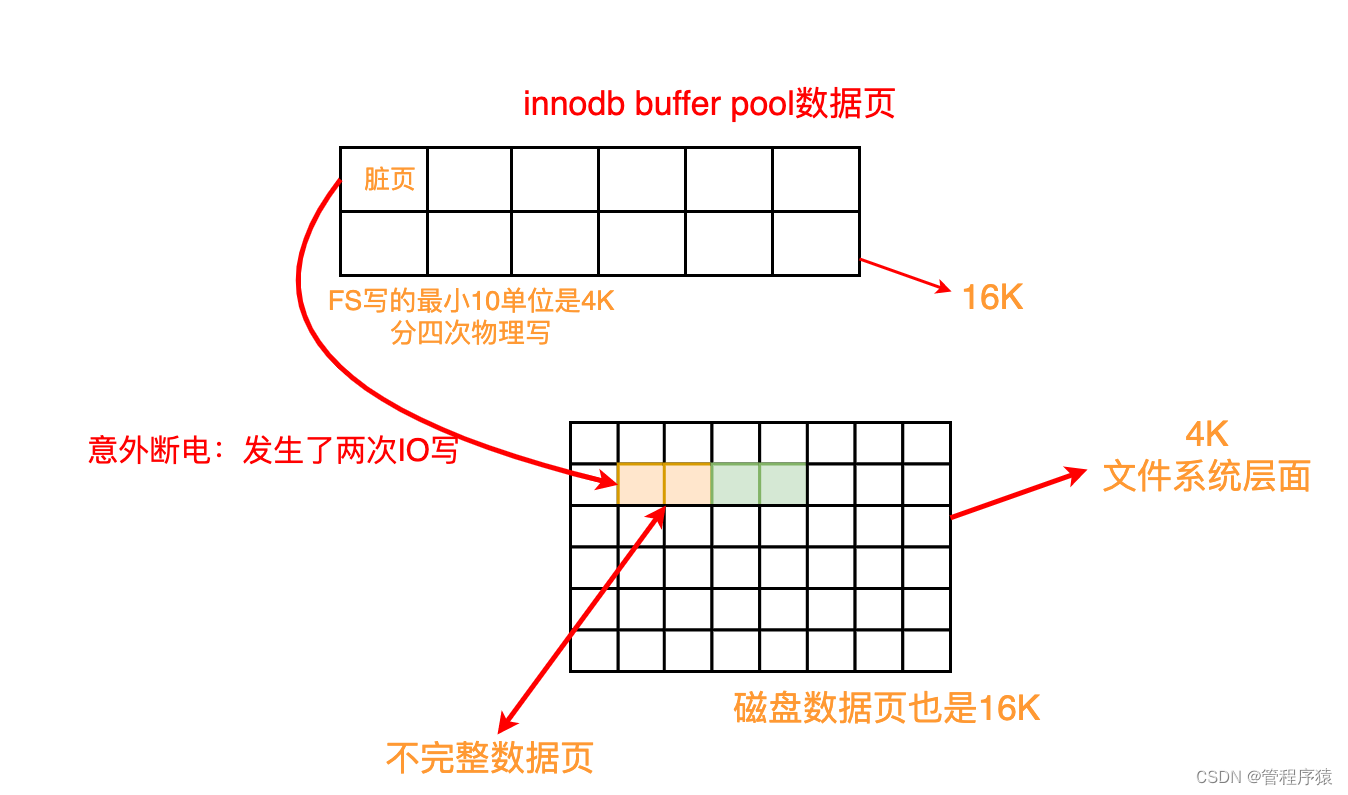
双重写入缓冲区,
InnoDB使用一种称为 doublewrite 的文件刷新技术。在将 页 写入 数据文件 之前,InnoDB首先将它们写入称为 doublewrite 缓冲区的存储区域 -
作用:提高innodb的可靠性,用来解决部分写失败(partial page write页断裂)。在页面写入过程中发生 os,存储子系统或mysqld进程崩溃,则
InnoDB随后可以在“崩溃恢复”期间从 doublewrite 缓冲区中找到该页面的良好副本。
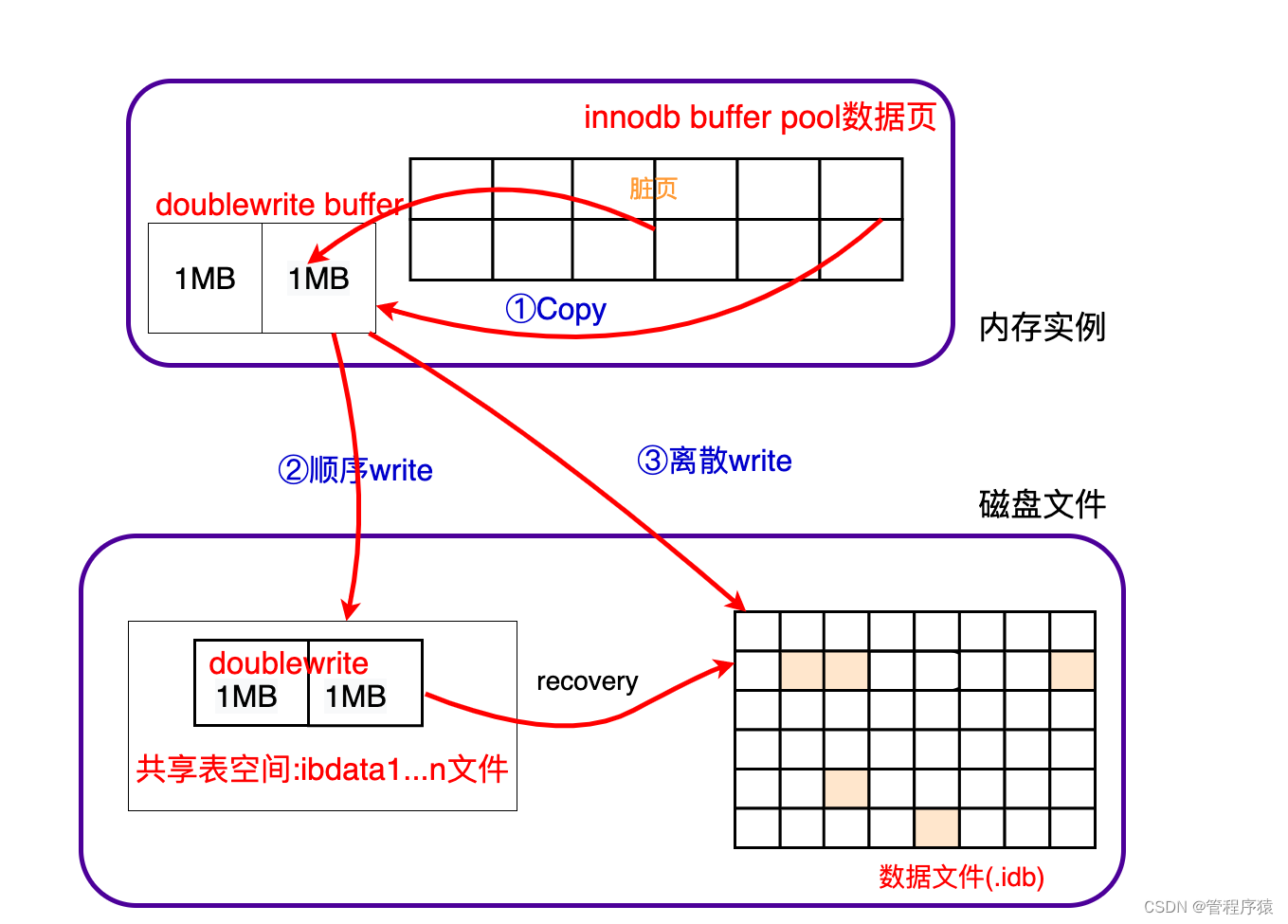
- doublewrite工作机制
-
带来的问题:
- double write是一个buffer, 但其实它是开在物理文件上的一个buffer, 其实也就是file, 所以它会导致系统有更多的fsync操作, 而硬盘的fsync性能是很慢的, 所以它会降低mysql的整体性能。
- doublewrite buffer写入磁盘共享表空间这个过程是连续存储,是顺序写,性能非常高,(约占写的%10),牺牲一点写性能来保证数据页的完整还是很有必要的。
-
配置doublewrite
show variables like '%double%';
第七章 进阶知识Mysql锁机制
第1集 初窥InnoDB锁分类
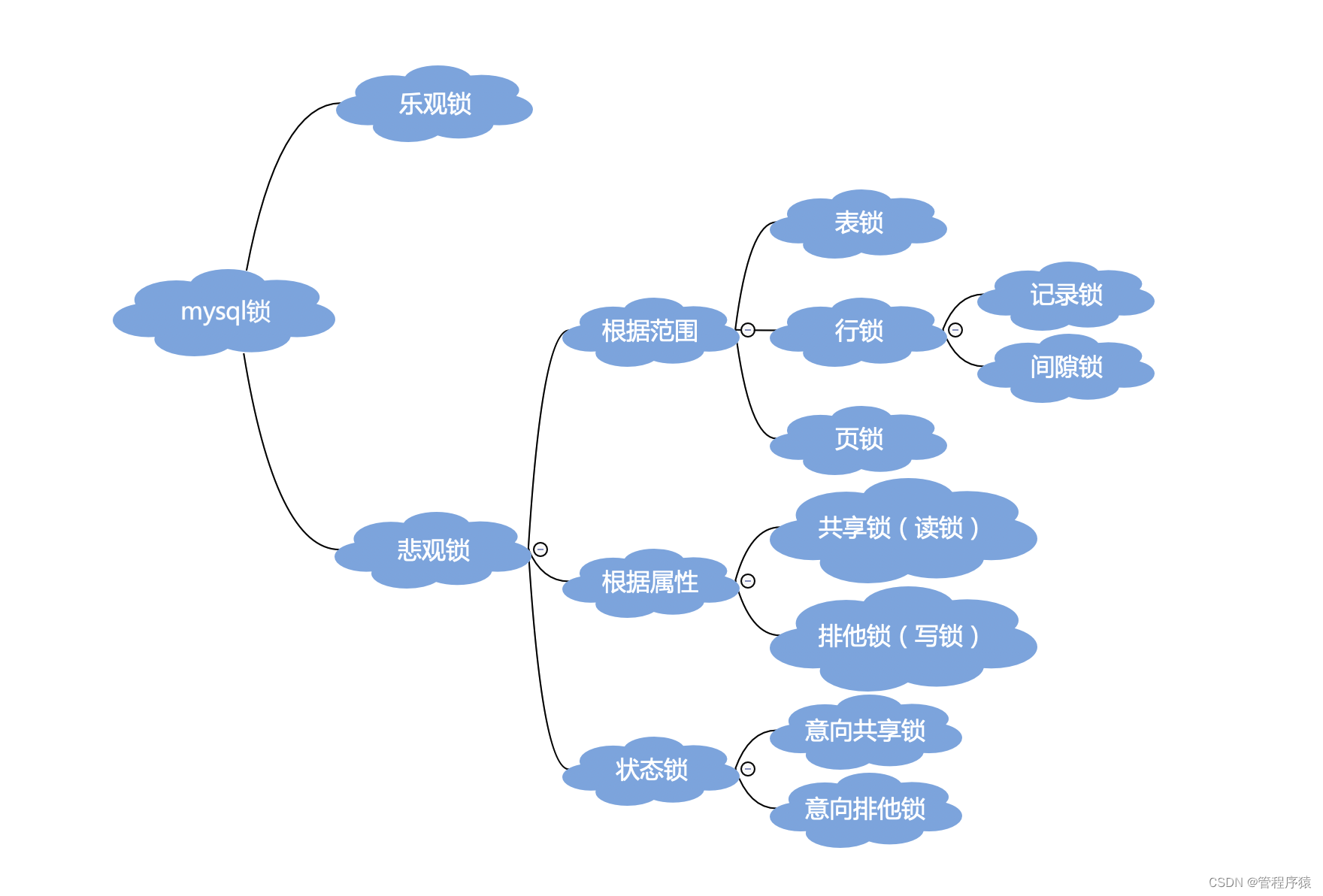
简介:Mysql锁是什么?锁有哪些类别?
-
锁定义
- 同一时间同一资源只能被一个线程访问 update test set a=a-1 where id=100 and a> 0;
- 在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
-
锁的分类
-
从对数据操作的类型分法(读或写)
- 读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
- 写锁(排它锁):当前写操作没有完成前,它会阻断其他写锁和读锁。
-
从对数据操作的粒度分法
- 表级锁:表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁
- 行级锁:行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁
- 页级锁:页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁,一次锁定相邻的一组记录
-
从并发角度的分发–实际上乐观锁和悲观锁只是一种思想
- 悲观锁:对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观) ,因此,在整个数据处理过程中,将数据处于锁定状态。
- 乐观锁:乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回错误信息再进行业务重试
-
其他锁:
- 间隙锁:在条件查询中,如:where id>100,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,间隙的目的是为了防止幻读
- 意向锁:意向锁分为 intention shared lock (IS) 和 intention exclusive lock (IX),意向锁的目的就是表明有事务正在或者将要锁住某个表中的行
The main purpose of intention locks is to show that someone is locking a row, or going to lock a row in the table.
-
第2集 行锁与表锁的比较
简介:行锁和表锁的区别,以及锁优化分析
-
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单。最常使用的MYISAM与INNODB都支持表级锁定。
- 特点:开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。
-
行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。
-
特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高
-
使用:InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁
-
-
行级锁改为表级锁的案例–不命中索引场景
update from test set a=100 where b='100'; -
实战查看行锁场景
第3集 附加技能之InnoDB死锁案例分析
简介:InnoDB死锁概念和死锁案例分析
-
定义:当两个或以上的事务相互持有和请求锁,并形成一个循环的依赖关系,就会产生死锁。多个事务同时锁定同一个资源时,也会产生死锁。在一个事务系统中,死锁是确切存在并且是不能完全避免的。
-
解决:InnoDB会自动检测事务死锁,立即回滚其中某个事务,并且返回一个错误。它根据某种机制来选择那个最简单(代价最小)的事务来进行回滚
-
死锁之select for update
-
产生场景:两个transaction都有两个select for update,transaction a先锁记录1,再锁记录2;而transaction b先锁记录2,再锁记录1
-
写锁:for update,读锁:for my share mode show engine innodb status
-
产生日志:
------------------------ LATEST DETECTED DEADLOCK ------------------------ 2020-10-18 17:21:00 0x700003222000 *** (1) TRANSACTION: TRANSACTION 3232878, ACTIVE 14 sec starting index read mysql tables in use 1, locked 1 LOCK WAIT 5 lock struct(s), heap size 1136, 4 row lock(s) MySQL thread id 26, OS thread handle 123145355436032, query id 1172 localhost 127.0.0.1 root Sending data select * from test where b=100 for update *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232878 lock_mode X waiting Record lock, heap no 101 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 80000064; asc d;; *** (2) TRANSACTION: TRANSACTION 3232879, ACTIVE 8 sec starting index read mysql tables in use 1, locked 1 6 lock struct(s), heap size 1136, 8 row lock(s) MySQL thread id 28, OS thread handle 123145354878976, query id 1173 localhost 127.0.0.1 root Sending data select * from test where b=200 for updated *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232879 lock_mode X Record lock, heap no 101 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 80000064; asc d;; Record lock, heap no 603 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 800186a5; asc ;; Record lock, heap no 605 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 800186a6; asc ;; *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232879 lock_mode X waiting Record lock, heap no 201 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 800000c8; asc ;; 1: len 4; hex 800000c8; asc ;; *** WE ROLL BACK TRANSACTION (1)
-
-
死锁之两个update
-
产生场景:两个transaction都有两个update,transaction a先更新记录1,再更新记录2;而transaction b先更新记录2,再更新记录1
-
产生日志:
LATEST DETECTED DEADLOCK ------------------------ 2020-10-18 17:30:02 0x700003222000 *** (1) TRANSACTION: TRANSACTION 3232880, ACTIVE 9 sec starting index read mysql tables in use 1, locked 1 LOCK WAIT 5 lock struct(s), heap size 1136, 4 row lock(s), undo log entries 1 MySQL thread id 26, OS thread handle 123145355436032, query id 1218 localhost 127.0.0.1 root updating update test set a =100 where b=100 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232880 lock_mode X waiting Record lock, heap no 101 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 80000064; asc d;; *** (2) TRANSACTION: TRANSACTION 3232881, ACTIVE 6 sec starting index read mysql tables in use 1, locked 1 6 lock struct(s), heap size 1136, 8 row lock(s), undo log entries 3 MySQL thread id 28, OS thread handle 123145354878976, query id 1219 localhost 127.0.0.1 root updating update test set a =100 where b=200 *** (2) HOLDS THE LOCK(S): RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232881 lock_mode X Record lock, heap no 101 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 80000064; asc d;; Record lock, heap no 603 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 800186a5; asc ;; Record lock, heap no 605 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 80000064; asc d;; 1: len 4; hex 800186a6; asc ;; *** (2) WAITING FOR THIS LOCK TO BE GRANTED: RECORD LOCKS space id 408 page no 11 n bits 1272 index b of table `xdclass_mysql`.`test` trx id 3232881 lock_mode X waiting Record lock, heap no 201 PHYSICAL RECORD: n_fields 2; compact format; info bits 0 0: len 4; hex 800000c8; asc ;; 1: len 4; hex 800000c8; asc ;; *** WE ROLL BACK TRANSACTION (1)
-
第4集 如何避免死锁
简介:程序开发过程中应该如何注意避免死锁
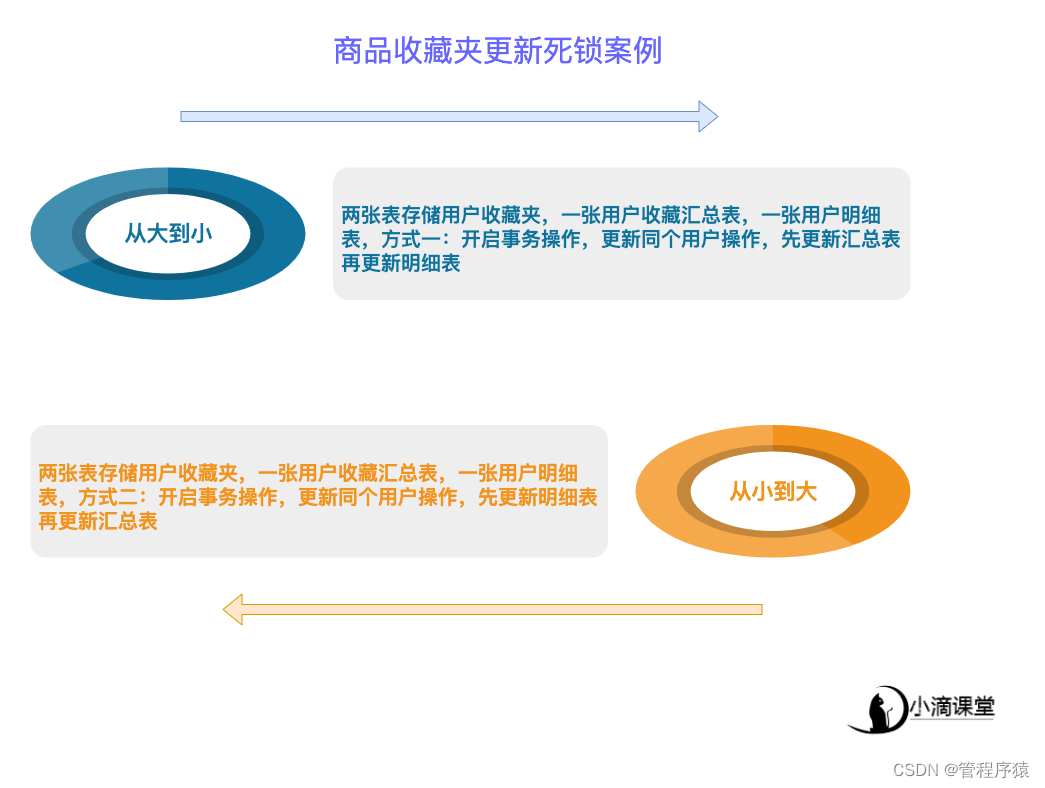
-
锁的本质是资源相互竞争,相互等待,往往是两个(或以上)的Session加锁的顺序不一致
-
如何有效避免:
-
在程序中,操作多张表时,尽量以相同的顺序来访问(避免形成等待环路)
-
批量操作单张表数据的时候,先对数据进行排序(避免形成等待环路) A线程 id:1 ,10 ,20按顺序加锁 B线程id:20,10,1
-
如果可以,大事务化成小事务,甚至不开启事务 select for update==>insert==>update = insert into update on duplicate key
-
尽量使用索引访问数据,避免没有 where 条件的操作,避免锁表 有走索引记录锁,没走索引表锁
-
使用等值查询而不是范围查询查询数据,命中记录,避免间隙锁对并发的影响 1,10,20 等值where id in (1,10,20) 范围查询 id>1 and id<20
-
避免在同一时间点运行多个对同一表进行读写的脚本,特别注意加锁且操作数据量比较大的语句;我们经常会有一些定时脚本,避免它们在同一时间点运行
-
第5集 大厂面试题之间隙锁
简介:说说你对Mysql间隙锁的了解
- 间隙锁的定义:间隙锁是一个在索引记录之间的间隙上的锁
- 间隙锁的作用:RR隔离级别保证对读取到的记录加锁 (记录锁),同时保证对读取的范围加锁,新的满足查询条件的记录不能够插入 (间隙锁),不存在幻读现象
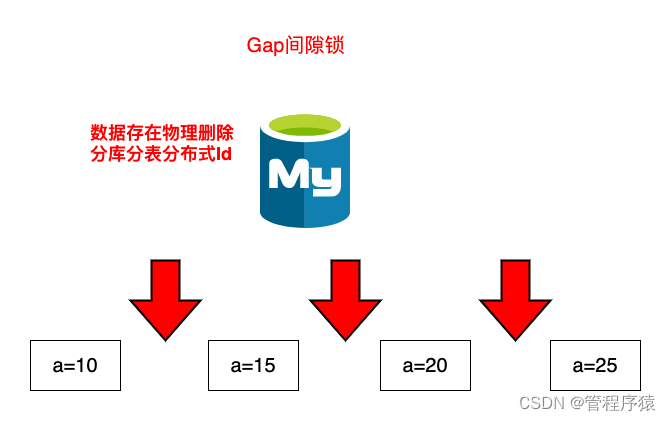
select id,a,b from test where a=10 for update; 1条满足的记录
update delete…
INSERT INTO test (id, a, b) VALUES (18, 10, 10);
select id,a,b from test where a=10; 2条满足的记录
-
验证间隙锁的方式,建表==》开启两个session==》第一个session进行锁操作==》另一个session插入数据
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `a` int(11) NOT NULL DEFAULT '0', `b` int(11) NOT NULL DEFAULT '0', PRIMARY KEY (`id`), KEY `a` (`a`) ) ENGINE=InnoDB AUTO_INCREMENT=100007 DEFAULT CHARSET=latin1; -
面试题回归:
- 说说什么是Mysql间隙锁
- 什么情况下会用到间隙锁
- 间隙锁可能带来什么问题?
- 造成死锁
- 加锁数据必须存在或者改用RC模式破坏间隙锁的使用
第6集 浅谈mysql大表性能问题
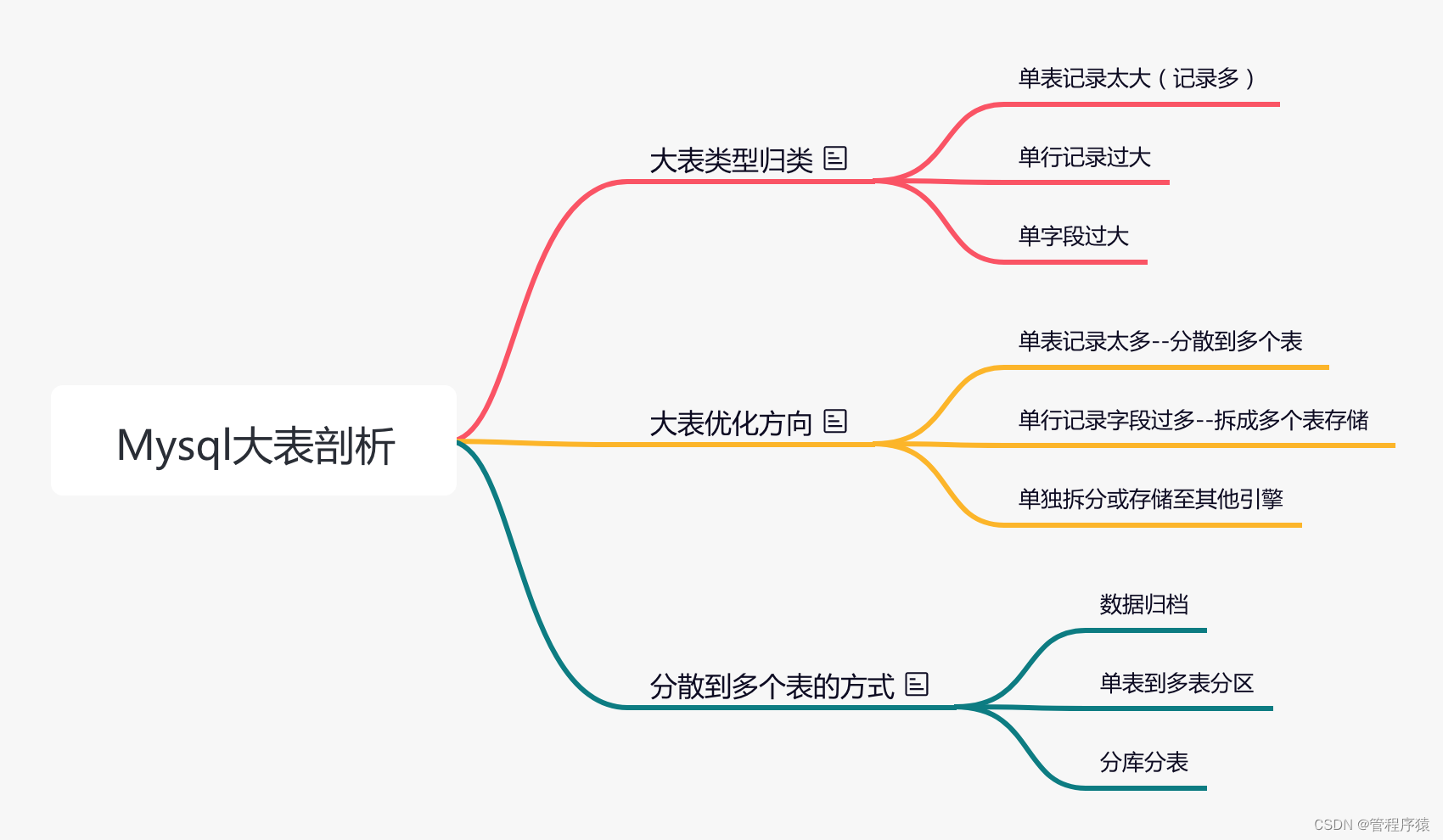
简介:谈谈mysql大表性能问题,性能优化方向
- 互联网的数据增长往往是指数型的,一个小型的项目往往考虑设计都很比较简单,当指数型流量来临时往往在数据库层面捉襟见肘,掌握大数据量下mysql的应对方案是每位高级工程师的必修课 2==》10 2^10=1024
- 对于大数据量的解决方案应该遵从场景优先,方案跟随场景变化和改动
第八章 Mysql数据复制同步
第1集 分析Mysql单点存在的问题
简介:剖析复制的意义,从常用复制模式讲解复制
-
小公司用单体服务,单体数据库,大公司考虑性能、考虑安全性、容灾性
-
Mysql复制拓扑结构使用场景: update、delete、insert select
-
横向扩展(Scale-Out):指在多个从库之间进行读负载均衡,以提高读性能。所有数据变更在主库上执行,把之前在主库上的读负载剥离出来,以承载更多的写请求,另外,如果读负载越来越大,可以通过扩展从库来提高读性能
-
数据安全性:形成多个备份库,减少在极端场景丢失造成损失,对于主库来说,从库有多个,所以如果在从库上执行备份,对只读应用的可用性影响就要小很多(从库的复制机制本身也支持断点续传)。也就是说,在执行备份操作时,选择使用从库而不使用主库是一个更好的替代方案,这样可以尽量减少对主库性能以及数据安全性的影响
-
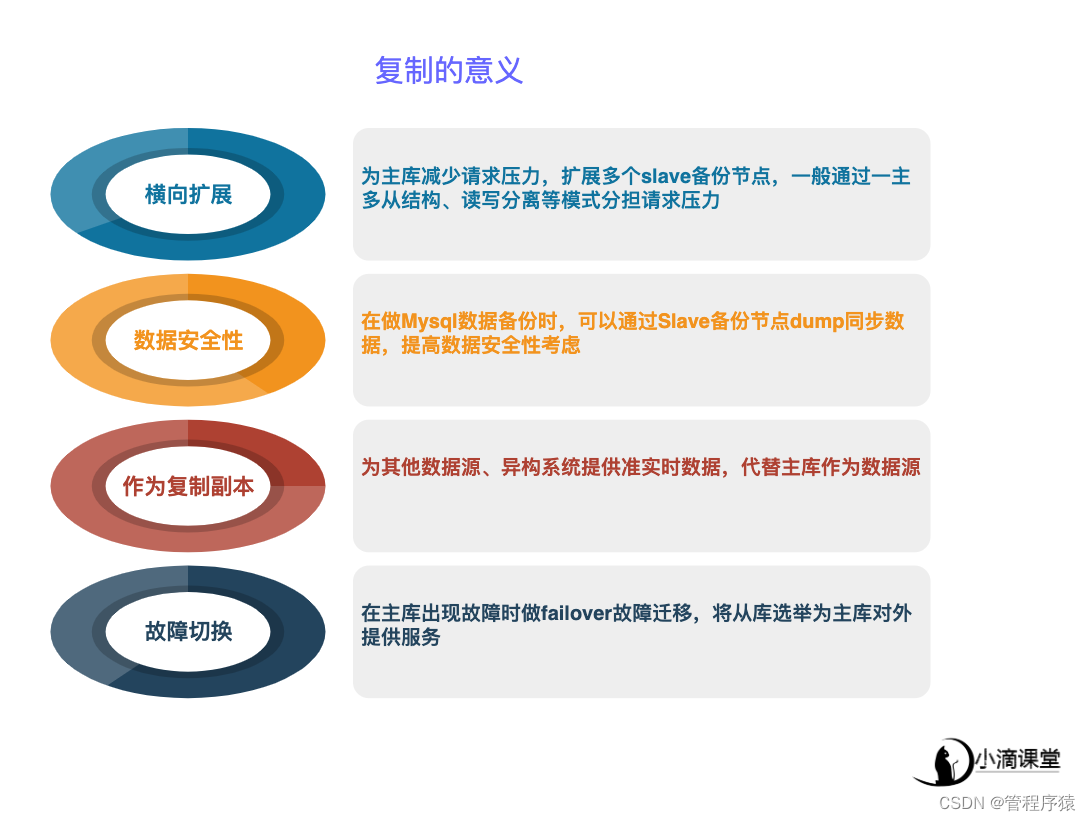
常用复制模式:一主多从、MHA+多节点集群 MHA Manage、MHA node
第2集 Mysql主从数据同步搭建
简介:mysql主从数据同步搭建
- 在内网内的两台机器装上Mysql
- 登录master账户,新创建一个账号,172.168.1.2代表slave内网地址
GRANT REPLICATION SLAVE ON *.* to 'root'@'172.168.1.2' identified by 'daniel';
//刷新系统权限表的配置
FLUSH PRIVILEGES;
-
接下来在找到mysql的配置文件/etc/my.cnf,增加以下配置
# 开启binlog log-bin=mysql-bin server-id=100 # 需要同步的数据库,如果不配置则同步全部数据库 binlog-do-db=xdclas_replication # binlog日志保留的天数,清除超过20天的日志 # 防止日志文件过大,导致磁盘空间不足 expire-logs-days=20
-
重启master节点
service mysql restart -
slave配置:在/etc/my.cnf配置文件,增加以下配置
server-id=101 -
进入到slave mysql后,再输入以下命令:
CHANGE MASTER TO MASTER_HOST='172.168.1.2',//主机IP MASTER_USER='root',//之前创建的用户账号 MASTER_PASSWORD='daniel',//之前创建的用户密码 MASTER_LOG_FILE='mysql-bin.000001',//master主机的binlog日志名称 MASTER_LOG_POS=100,//binlog日志偏移量 master_port=3306;//端口 -
启动slave服务
start slave;
show slave status;
- 连接master主机节点,往主机节点创建表检验、插入数据,检查slave节点是否有master插入的数据
第3集 Mysql主从同步原理讲解
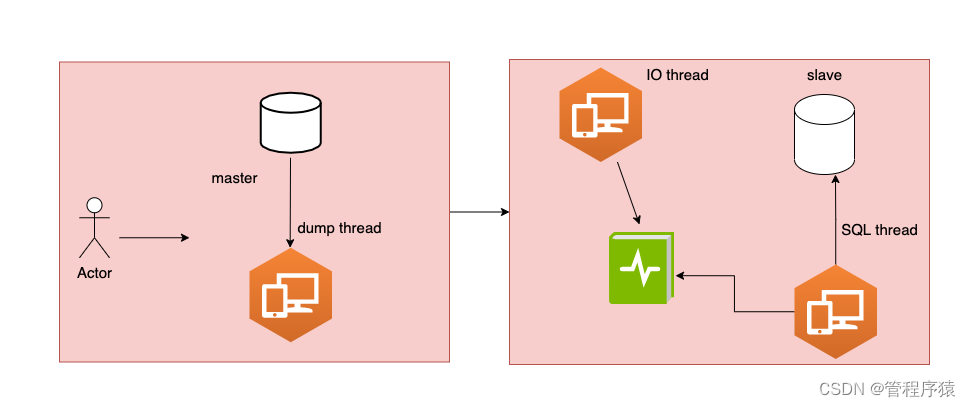
简介:mysql主从同步原理讲解
- Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件,这些记录叫做二进制日志事件(binary log events)
- Slave通过I/O线程读取Master中的binary log events并写入到它的中继日志(relay log)
- Slave重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放)
-
dump过程需要关注的信息:
- 是push还是pull方式:用户提交对数据的修改,然后Master(主库)把所有数据库变更写进Binary Log(二进制日志),主库通过Binlog Dump线程把二进制日志内容推送给Slave(从库),从库被动接收数据,不是主动去获取,除非是新建连接
- slave为甚么要用多个线程来处理数据同步,一个线程不可以吗?
- 实现获取时间和重放时间的解耦
- 每一对主从关系中,都有三个线程主库可以连接多个从库,而且会为每一个连接成功的从库创建一个Binlog Dump线程;从库也可以连接多个主库(多源复制),而且会为每一个连接成功的主库创建自己的I/O线程和SQL线程。从库使用两个线程分别将主库的二进制日志读取到本地,并应用这些日志以实现主从之间的数据同步。因此,即便SQL线程执行语句缓慢,也不会影响I/O线程读取日志的速度(正常情况下,I/O线程不会成为性能瓶颈,除非网络出现问题)。如果SQL线程已经应用完所有的中继日志,就表明I/O线程已经获取了主库中所有的二进制日志。
-
关于中继日志
- 从服务器 I/O 线程将主服务器的 Binlog 日志读取过来,解析到各类 Events 之后记录到从服务器本地文件,这个文件就被称为 relay log。然后 SQL 线程会读取 relay log 日志的内容并应用到从服务器,从而使从服务器和主服务器的数据保持一致。中继日志充当缓冲区,这样 master 就不必等待 slave 执行完成才发送下一个事件
第4集 常常说Binlog,你知道本质上是什么吗?
简介:Mysql实际上是在复制什么?复制的单位怎么定义
-
复制功能之所以能够正常工作,是因为写入二进制日志的事件是从主库获取,然后在从库上回放的。根据事件的类型,事件以不同的格式被记录在二进制日志中,一般有三种复制模式,基于row复制模式,基于statement的复制模式以及mixed复制模式
-
什么是基于row的复制模式
- 使用row格式的二进制日志时,主库会将产生的事件(一组事件)写入二进制日志,以事件来表示数据的变更。将这些表示数据变更的事件复制到从库,然后在从库中应用这些事件,把主库数据同步到从库,这称为基于row(行)的复制,简称为RBR
- 关键行为:将ROW变更转成Binlog二进制日志在从库重放
-
什么是基于statement的复制模式
-
使用statement格式的二进制日志时,主库会将SQL语句文本写入二进制日志。在主库上执行的SQL语句,然后将主库的SQL变更在从库重放,这称为基于statement(语句)的复制,简称为SBR
-
关键行为:SQL转成Binlog二进制日志在从库重放
-
-
什么是mixed复制模式
- 默认采用基于SQL的复制,一旦发现基于SQL的无法精确的复制时,就会采用基于行的复制
第5集 对于多种复制模式,他们有什么区别呢?
简介:深入分析复制模式的区别,分析Mysql开发者怎么改进,遵守什么门路?
-
基于row的优缺点在哪里?
- 优势:
- 可以正确复制所有数据的变更,这是最安全的复制格式
- 劣势:
- 生成更多的二进制日志数据,因为基于row的复制会将每行数据的变更都写入二进制日志。利用二进制日志进行备份和恢复的时间也会更长。此外,二进制日志的文件锁也会因为需要更长的时间来写入数据而被持有更久的时间,这可能会影响数据库的并发能
- 无法直接看到从库中执行的语句,但是可以使用mysqlbinlog工具
- 优势:
-
基于statement的优劣势在哪里?
- 优势:
- 写入日志文件的数据较少。当更新或删除操作涉及多行时,可以大大减少存储空间,在利用二进制日志备份与恢复数据时也可以快速完成。
- 日志文件中包含所有的数据变更的原始语句,可用于数据库审计。
- 劣势:
- 一些执行结果不确定的DML语句,不能使用基于statement的复制,否则可能会造成主从库的数据不一致
- DML语句中,使用不带ORDER BY的LIMIT子句时,由于在主从库之间执行的排序结果可能不同,所以执行结果是不确定的
- 使用statement格式的日志时,一些内置的函数无法正确复制,如下:
- LOAD_FILE()
- UUID()
- UUID_SHORT()
- USER()
- FOUND_ROWS()
- SYSDATE()(主库和从库都使用–sysdate-is-now选项启动时适用)
- GET_LOCK()
- IS_FREE_LOCK()
- IS_USED_LOCK()
- MASTER_POS_WAIT()
- RAND()
- RELEASE_LOCK()
- SLEEP()
- VERSION()
- 优势:
-
关于安全与不安全数据复制
- 什么情况下是不安全复制:“安全”是指是否可以使用基于statement的格式(这里指的是在二进制日志文件中实际记录的内容为statement格式,不是指设置系统变量binlog_format = statement)正确复制语句,如果能正确复制,则认为语句是安全的,否则就认为是不安全的
- Mysql对不安全执行的处理
- 使用mixed格式的日志时,被视为不安全的语句在记录到二进制日志时会自动转换为row格式,被视为安全的语句在记录到二进制日志时会使用statement格式
- 使用statement格式的日志时,对标记为不安全的语句会生成警告,甚至拒绝执行,被标记安全的语句则被正常记录
第6集 传统复制与基于GTID复制
简介:了解传统复制和基于GTID复制的区别,掌握GTID带来的便利
-
传统复制
- 复制拓扑的初始化配置和变更、复制的高可用切换等操作都需要找到正确的二进制日志文件和位置,否则就无法正确复制
- 每个从库都会记录当前对应主库的二进制日志文件位置、二进制日志文件名,以及在此文件中它已从主库读取和处理的位置(即SQL线程和I/O线程的位置)。每个从库独立地应用主库的二进制日志,相互之间不产生影响并各自记录自身应用到的位置,而且就算有从库与主库的连接发生断开或重连,也不会影响主库的操作
-
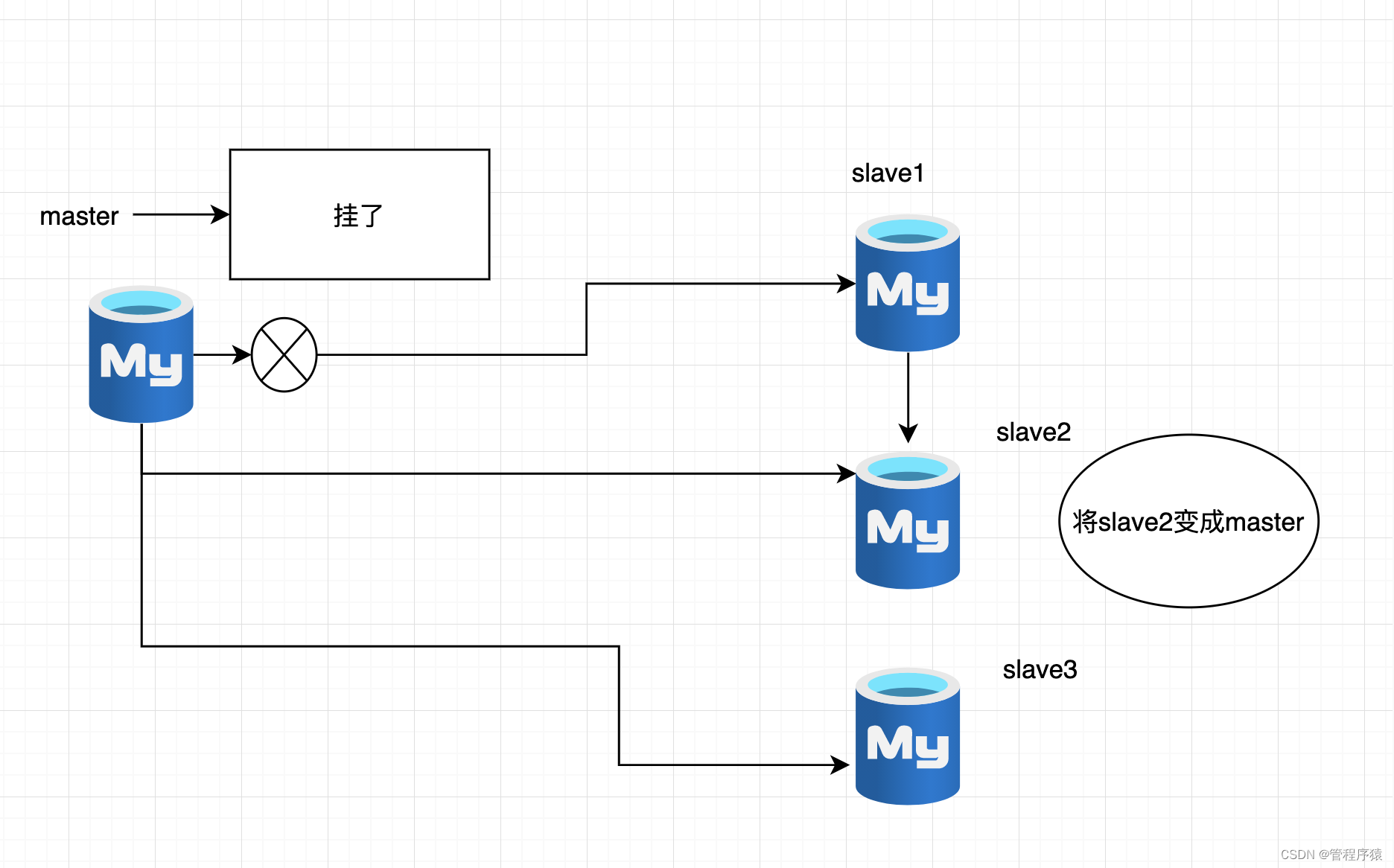
基于GTID的复制方式
- 定义:GTID(Global Transaction Identifier,全局事务标识符),即基于GTID实现的复制,指的是基于事务的复制
- 使用GTID复制在搭建新从库或者因故障转移到新主库时,会自动根据GTID来定位对应的二进制日志文件和位置,更准确地说,是自动寻找从库缺失的GTID SET对应的二进制日志记录,极大地降低了这些任务的复杂度
-
GTID SET信息在主库与从库中都会保存。这意味着可以通过GTID SET信息来追踪二进制日志的来源。此外,一旦在给定Server中提交过某个GTID的事务,则该Server将忽略后续提交的相同GTID的事务。因此,主库上提交的事务在从库上只能应用一次,之后碰到重复的GTID时会自动跳过整个事务,这有助于保证主从库数据一致
- 通过GTID可以区分事务的来源(通过GTID组成中的UUID可以区分事务是由哪个Server提交的
第7集 GTID的生命周期
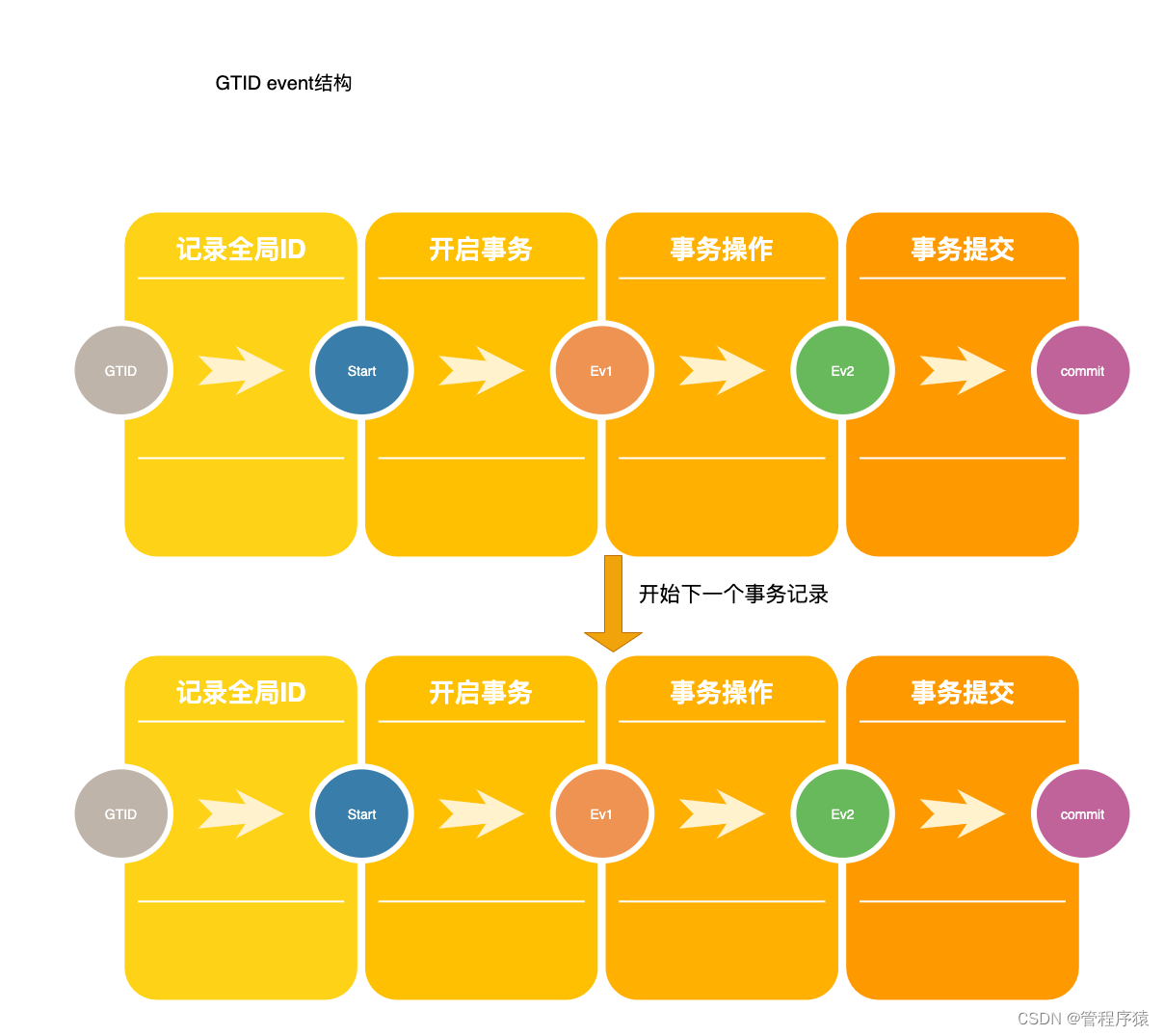
简介:GTID生成工作作用阶段以及GTID优缺点讲解
**
**
-
开启GTID复制模式,在my.cnf配置文件中添加 5.7+版本
gtid_mode=on (必选) enforce-gtid-consistency=1 (必选) log_bin=mysql-bin (可选) #高可用切换,最好开启该功能 log-slave-updates=1 (可选) #高可用切换,最好打开该功能 -
GTID作用方式
- 最开始的时候,MySQL只支持一种binlog dump方式,也就是指定binlog filename + position,向master发送COM_BINLOG_DUMP命令。在发送dump命令的时候,我们可以指定flag为BINLOG_DUMP_NON_BLOCK,这样master在没有可发送的binlog event之后,就会返回一个EOF package。不过通常对于slave来说,一直把连接挂着可能更好,这样能更及时收到新产生的binlog event
- 在MySQL 5.6之后,支持了另一种dump方式,也就是GTID dump,通过发送COM_BINLOG_DUMP_GTID命令实现,需要带上的是相应的GTID信息.
-
GTID工作原理
- master更新数据时,会在事务前产生GTID,一同记录到binlog日志中
- slave端的i/o 线程将变更的binlog,写入到本地的relay log中
- sql线程从relay log中获取GTID,然后对比slave端的binlog是否有记录 2 3 4 5
- 如果有记录,说明该GTID的事务已经执行,slave会忽略
- 如果没有记录,slave就会从relay log中执行该GTID的事务,并记录到binlog
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描
-
GTID优势
- 一个事务对应一个唯一ID,一个GTID在一个服务器上只会执行一次;
- GTID是用来代替传统复制的方法,GTID复制与普通复制模式的最大不同就是不需要指定二进制文件名和位置;
- 减少手工干预和降低服务故障时间,当主机挂了之后通过软件从众多的备机中提升一台备机为主机;
-
GTID的劣势
- 不支持非事务引擎;
- 不支持create table … select 语句复制(主库直接报错);(原理: 会生成两个sql, 一个是DDL创建表SQL, 一个是insert into 插入数据的 sql; 由于DDL会导致自动提交, 所以这个sql至少需要两个GTID, 但是GTID模式下, 只能给这个sql生成一个GTID)
- 不允许一个SQL同时更新一个事务引擎表和非事务引擎表
- 在一个复制组中,必须要求统一开启GTID或者是关闭GTID
第8集 Mysql异步复制与半同步复制
简介:梳理半复制与异步复制的区别,讲解半复制带来哪些改进
-
传统异步复制模式介绍
- 自动提交,主库发起事务提交,在execute(执行)阶段执行完对数据的修改操作,然后在binlog(二进制日志)阶段将修改数据所产生的二进制日志记录写入二进制日志文件中,在commit(提交)阶段完成存储引擎层的事务提交(事务的状态修改为“提交”)。与此同时,主库会通过Dump线程将二进制日志记录发送给两个从库,两个从库收到后会写入relay log(中继日志)文件中。之后,两个从库各自读取relay log文件中的内容进行apply(应用),即模拟事务在主库中的提交方式来回放relay log
-
由于主库执行提交与发送二进制日志是异步的,也就是说,从库是否成功接收二进制日志不影响主库中的事务执行提交,因此可能会出现“主库发生宕机,但主库中已提交事务的二进制日志并没有被任何从库成功接收”的情况,即发生了数据丢失
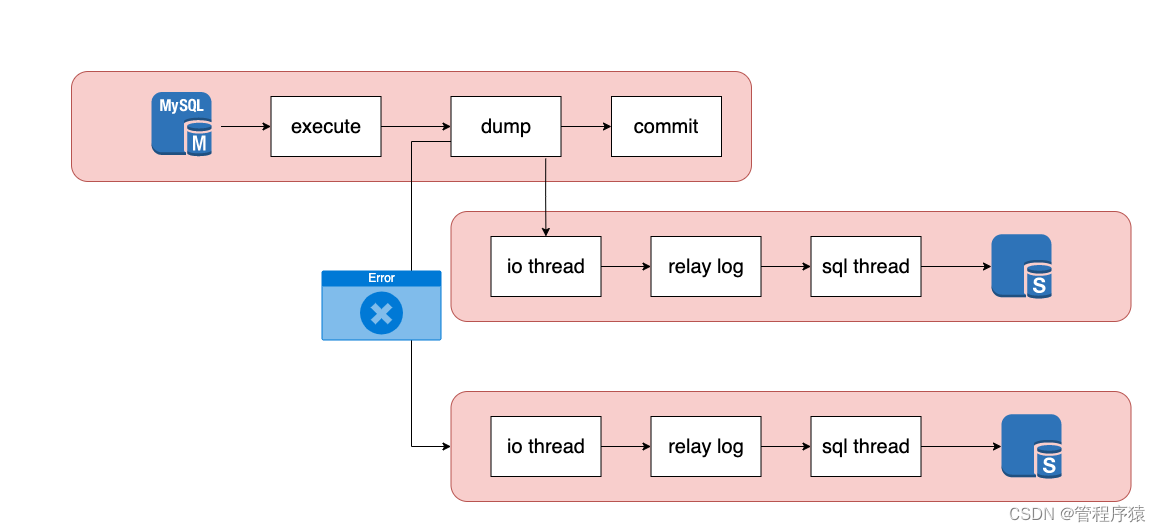
-
半同步复制模式介绍 5.7插件模式(微内核架构)
- 我们可以看到,在binlog阶段后commit阶段前,主库必须等待从库在relay log阶段之后回复的ACK消息。而从库给主库回复ACK消息之前,必须确保已经成功接收主库的二进制日志记录,并写入中继日志
- 当主库发生故障时,主库已提交的事务如果丢失,可以通过从库的中继日志恢复,避免在主库发生故障时已提交的数据丢失
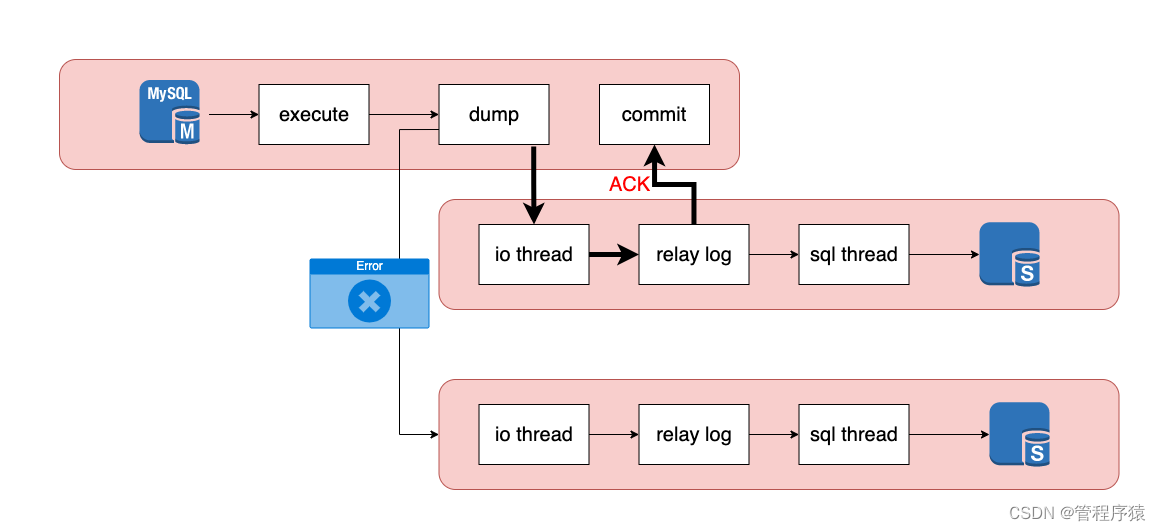
-
半复制的特点
- 如果主库在超时时间内没有收到任何从库的ACK消息,则主库将切换为异步复制,直到至少有一个从库恢复与主库的半同步复制连接,主库才重新切换为半同步复制
- 要正确使用半同步复制,需要主从库两端都启用半同步复制,如果在主库上禁用了半同步复制,或者在从库上禁用了半同步复制,则主库将使用异步复制中的方式传输二进制日志
第9集 Mysql多线程复制演进过程
简介:Mysql复制从单线程到多线程的演进过程
-
复制模式上的演进
- 单线程group_commit性能优化
- 5.6引入基于DATABASE的多线程复制模式
- 5.7引入基于LOGICAL_CLOCK的多线程复制(能支持到事务级别)
-
基于group_commit提交模式
- MySQL 5.6之前的版本,从库不支持多线程复制,但实际上在这之前的版本中,当不启用二进制日志时,InnoDB存储引擎本身是支持GroupCommit的(即支持一次提交多个事务),但当启用二进制日志之后,为了保证数据的一致性(也就是必须保证MySQL Server层和存储引擎层的提交顺序一致),启用了两阶段提交。而两阶段提交中的prepare阶段使用了prepare_commit_mutex互斥锁来强制事务串行提交,这也大大降低了数据库的写入效率
-
基于database的多线程复制模式
-
处理原则:多线程复制基于schema来实现,将多个数据库下的事务按照数据库拆分到多个线程上执行,保证数据库级别的事务一致性
-
在MYSQL中开启并行复制功能,SQL线程会变成coordinator线程,coordinator线程会对二进制日志的event进行判断
-
1、如果判断事件可以被并行执行,那么选择相应worker线程应用BINLOG事件
- 2、如果判断事件不可以被并行执行,如DDL操作或跨schema事务,则等待所有worker线程执行完成后,再执行该BINLOG事件
-
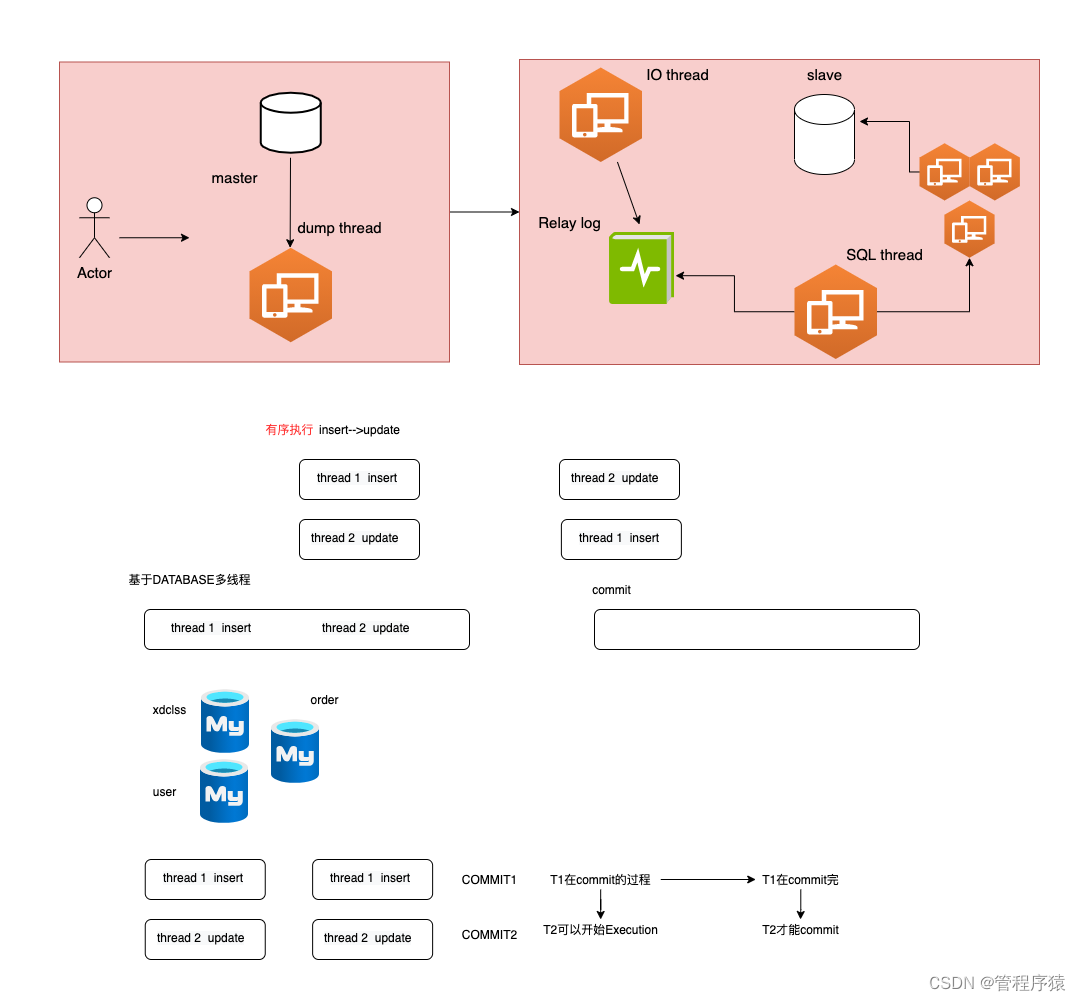
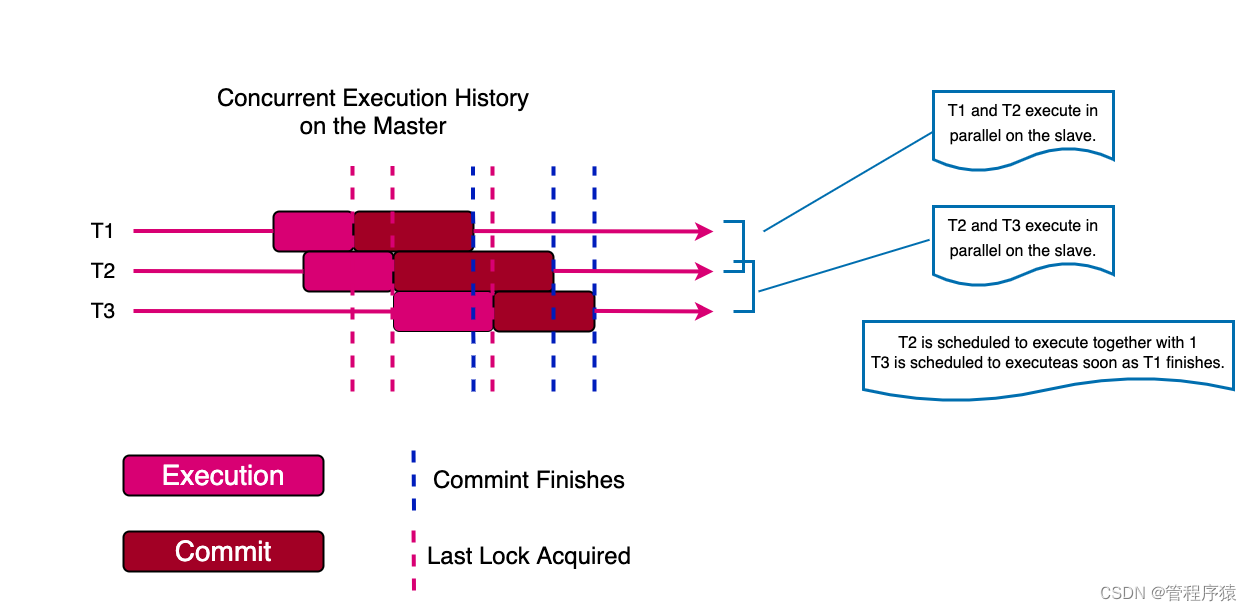
第10集 浅谈基于LOGICAL_CLOCK的多线程复制
简介:分析基于DataBase的问题以及基于LOGICAL_CLOCK模式的改进
-
基于database的复制优化可能存在的问题
- 允许并行回放的粒度为数据库级别,只有在同一时间修改数据且修改操作针对的是不同数据库,才允许并行
- MySQL使用Low-Water-Mark标记来最小已完成事件点,当发生宕机恢复时,根据Low-Water-Mark标记值来重放其后面的事件,而其中部分事件可能已被执行,重复执行可能会导致SQL线程异常或数据异常
-
基于logical_clock多线程复制
- 好处:允许并行回放的粒度为事务级别,即便在同一时间修改数据的操作针对的是同一个数据库,理论上只要事务之间不存在锁冲突,就允许并行
- 原理:在MySQL 5.7版本中引入,在主库上的某个时间点上,所有完成excution、处于prepare阶段的事务都处于一个"相同的数据库版本"上,这些事务之间不存在阻塞或者依赖,因此可以赋予一个相同的时间戳
- 拥有相同时间戳的事务可以在从库上并行执行并且不会导致相互等待。如果事务间存在依赖,那么被阻塞的事务肯定处于Execution状态而不会进入Prepare状态
第11集 mysql复制高级工程师面试题
简介:关于本章节常见高级工程师面试题
-
Mysql主从是如何复制的?怎么做到数据一致性?
-
Mysql复制模式有哪几种?他们分别有哪些区别
-
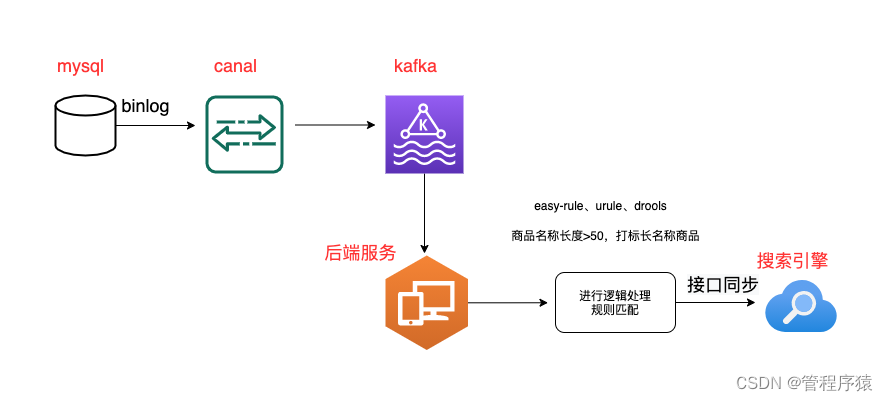
监听过binlog吗?怎么处理的?canal=>kafka,应用连接kafak
-
-
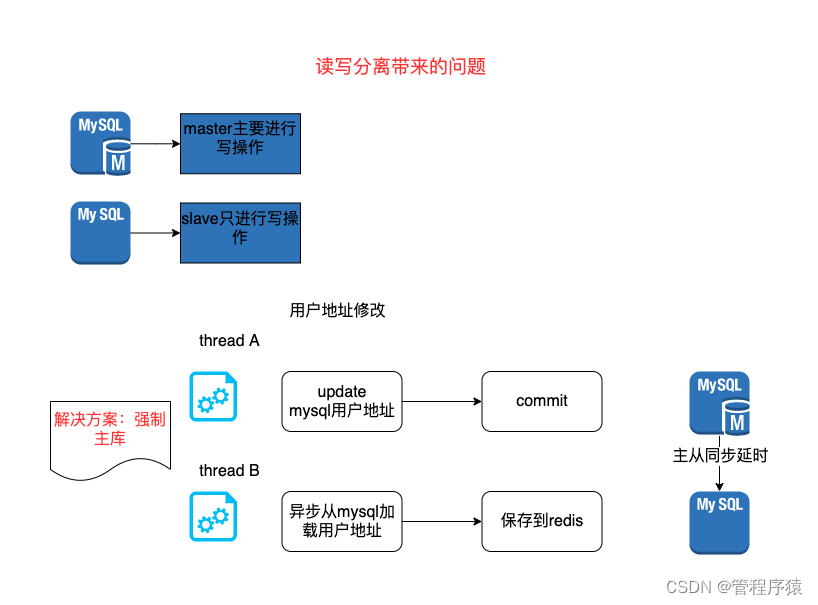
使用Mysql读写分离过程中遇到过什么问题, 你是怎么解决的?
第九章 高级篇之分库分表实战讲解
第1集 分库分表分区分别是什么?为什么这么做
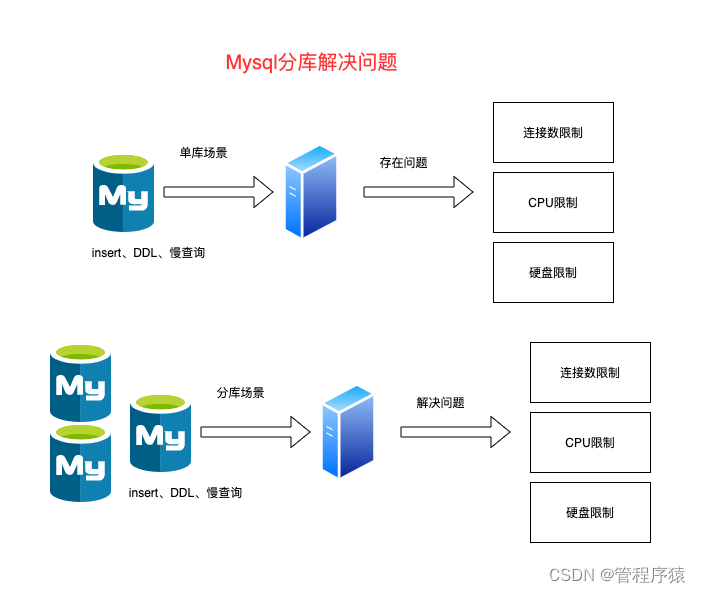
简介:了解分库分表的原因,如果不分表瓶颈会在哪里
- 分库分表的原因
- 数据库最容易产生性能瓶颈的服务组件。数据库连接数资源捉襟见肘和数据库因为表多、数据多造成的性能问题
- 单一服务中心的数据访问压力也必然会达到单机数据库的承载上限,所以在进行服务化改造的同一时间段内,需要对数据库能力做扩展的工作
- 单台数据库 这里以mysql为例,mysql数据库,当访问连接数过多时,就会出现‘too many connections’的错误,一般来说是访问量太大或者数据库设置的最大连接数太小的原因。Mysql默认的最大连接数为100.这个连接连接数可以修改,而mysql服务允许的最大连接数为16384
-
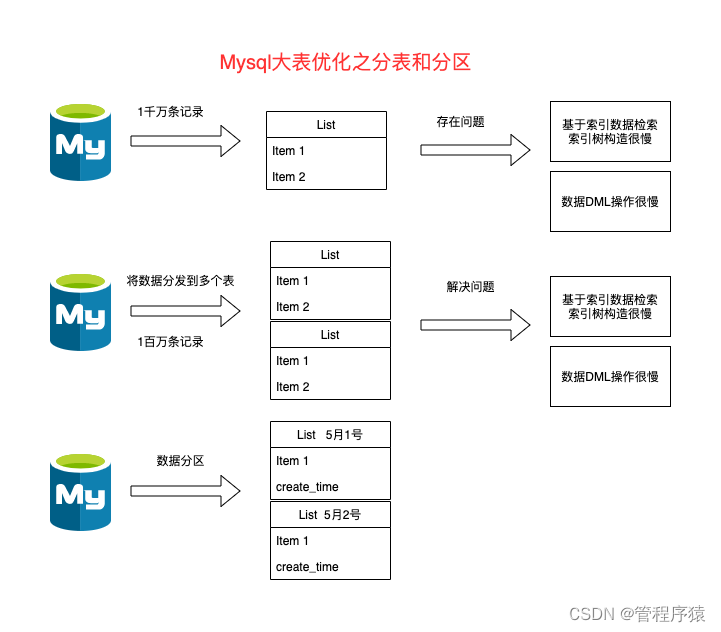
什么是分区?
- 分表是将一张表分成N多个小表,分区是把一张表的数据分成N多个区块,这些区块可以在同一个磁盘上,也可以在不同的磁盘上
- 物理上多表存储,但是逻辑上单表操作
第2集 分库分表常见手段分析
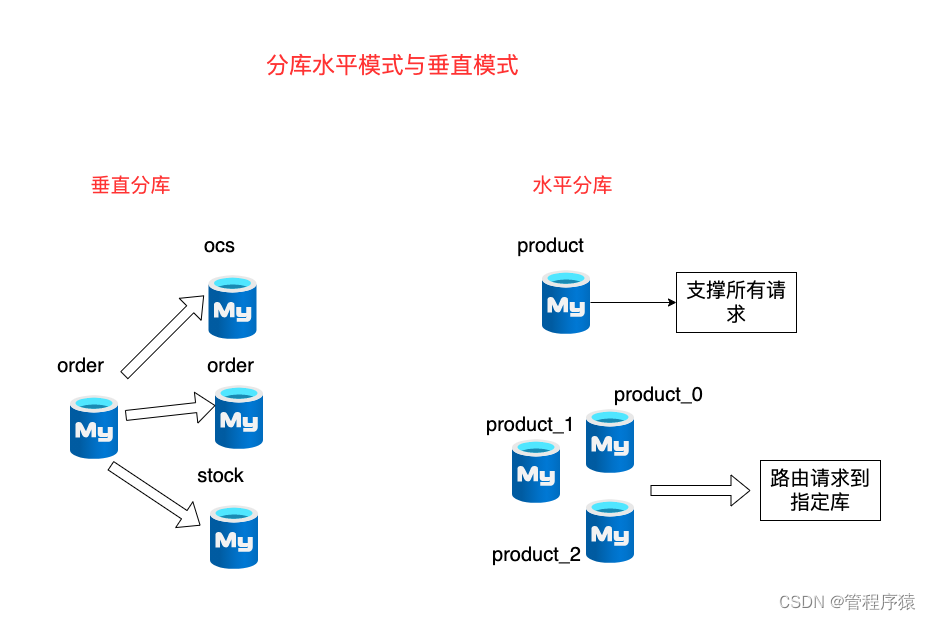
简介:了解分库分表常见手段以及选择考虑方向
- 一般会有两种分库分表方向,分别是垂直方向和水平方向,第一种方案是直接对现有的数据库进行垂直拆分,可以缓解目前写峰值QPS过大、DB主从延迟的问题。第二种方案是对现有数据库大表进行分库分表
-
根据不同规模对垂直方向和水平方向的选择
- 单个库太大,这时我们要看是因为表多而导致数据多,还是因为单张表里面的数据多。 如果是因为表多而数据多,使用垂直切分,根据业务切分成不同的库
- 单张表的数据量太大,这时要用水平切分,即把表的数据按某种规则切分成多张表,甚至多个库上的多张表。 分库分表的顺序应该是先垂直分,后水平分。 因为垂直分更简单,更符合我们处理现实世界问题的方式
-
垂直拆分
- 垂直分表:也就是“大表拆小表”,基于列字段进行的。一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“
- 垂直分库:垂直分库针对的是一个系统中的不同业务进行拆分, 数据库的连接资源比较宝贵且单机处理能力也有限,在高并发场景下,垂直分库一定程度上能够突破IO、连接数及单机硬件资源的瓶颈
-
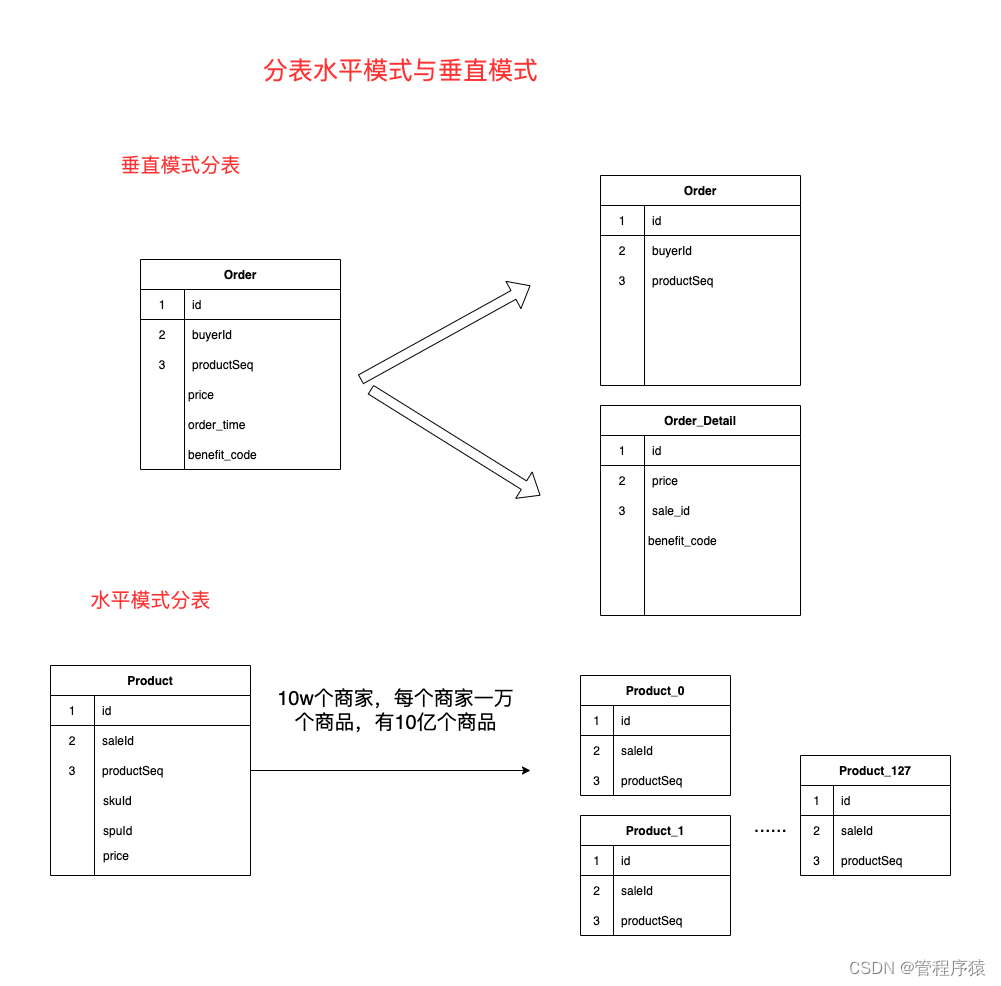
水平拆分
- 水平分表:针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈
- 水平分库:将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈
第3集 分库分表实战环境准备
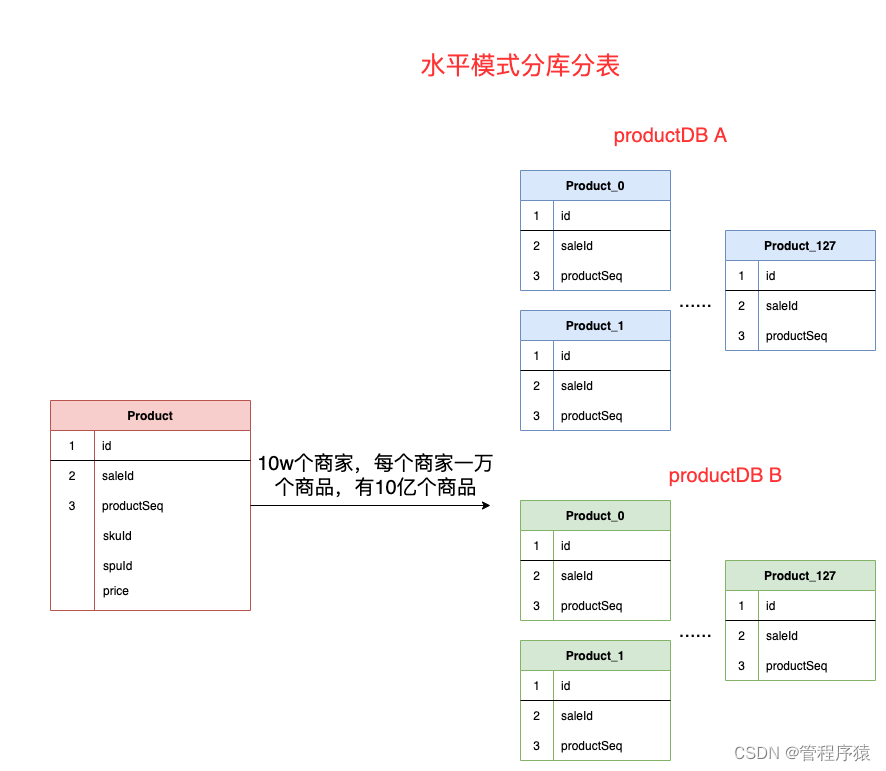
简介:分库分表环境准备
- 水平分库分表的模型设计
-
建表语句编写
CREATE TABLE if not exists product_0 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_1 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_2 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_3 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_4 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_5 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_6 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_7 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_8 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_9 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_10 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_11 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_12 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_13 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_14 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_15 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_16 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_17 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_18 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_19 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_20 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_21 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_22 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_23 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_24 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_25 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_26 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_27 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_28 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_29 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_30 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_31 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_32 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_33 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_34 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_35 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_36 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_37 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_38 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_39 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_40 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_41 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_42 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_43 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_44 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_45 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_46 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_47 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_48 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_49 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_50 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_51 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_52 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_53 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_54 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_55 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_56 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_57 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_58 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_59 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_60 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_61 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_62 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4; CREATE TABLE if not exists product_63 ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id',`sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` varchar(64) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
第4集 基于springboot实战分库分表搭建
简介:基于springboot+shardingJDBC分库分表实战
-
分库分表实战
- 引入pom依赖
- 配置yml或者properties文件
- 配置datasource config
- 配置分库分表策略
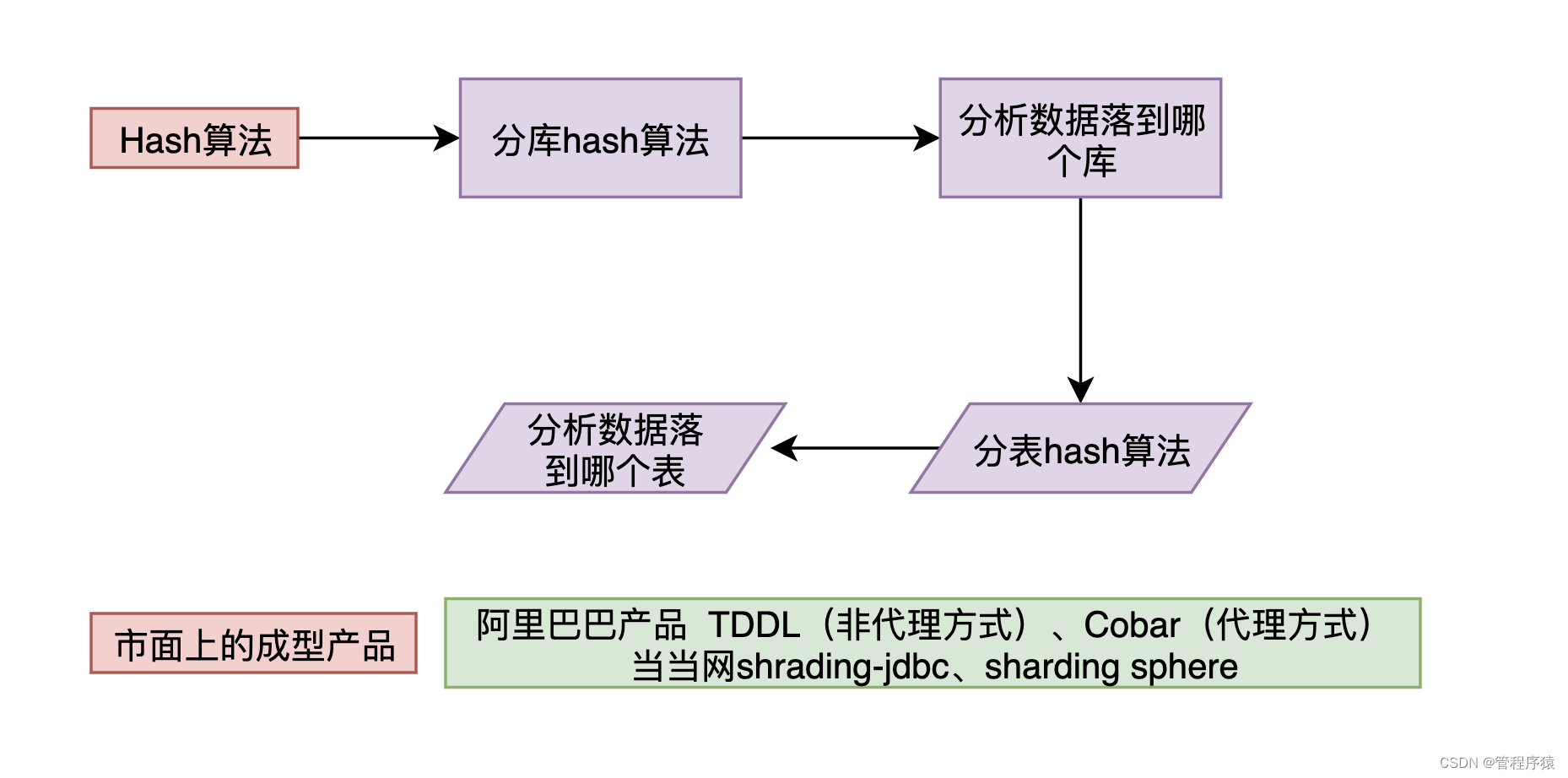
第5集 shardingJDBC实战使用
简介:shardingJDBC实战使用
- shardingJDBC hash函数映射
第6集 分布式场景怎么保证ID唯一性?
简介:讨论分布式场景ID怎么生成?
- 分布式场景ID生成分析
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要块,否则会成为业务瓶颈
- 高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性 99.9% 99.99%
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
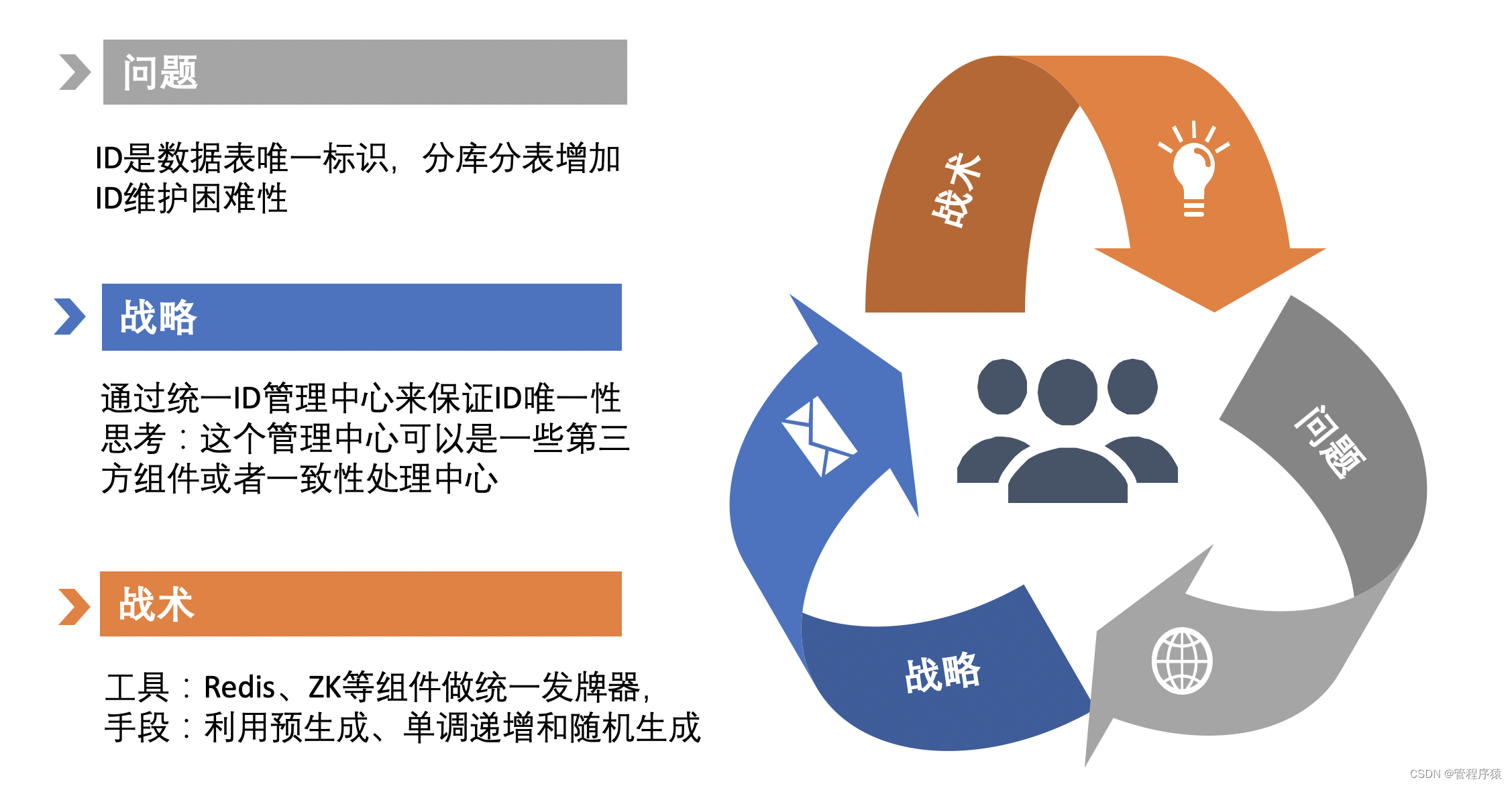
Zookeeper 一致性
第7集 分库分表ID唯一性实现手段
简介:讨论分布式场景ID怎么生成?
- 号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次自动生成一个号段,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存(分布式缓存)
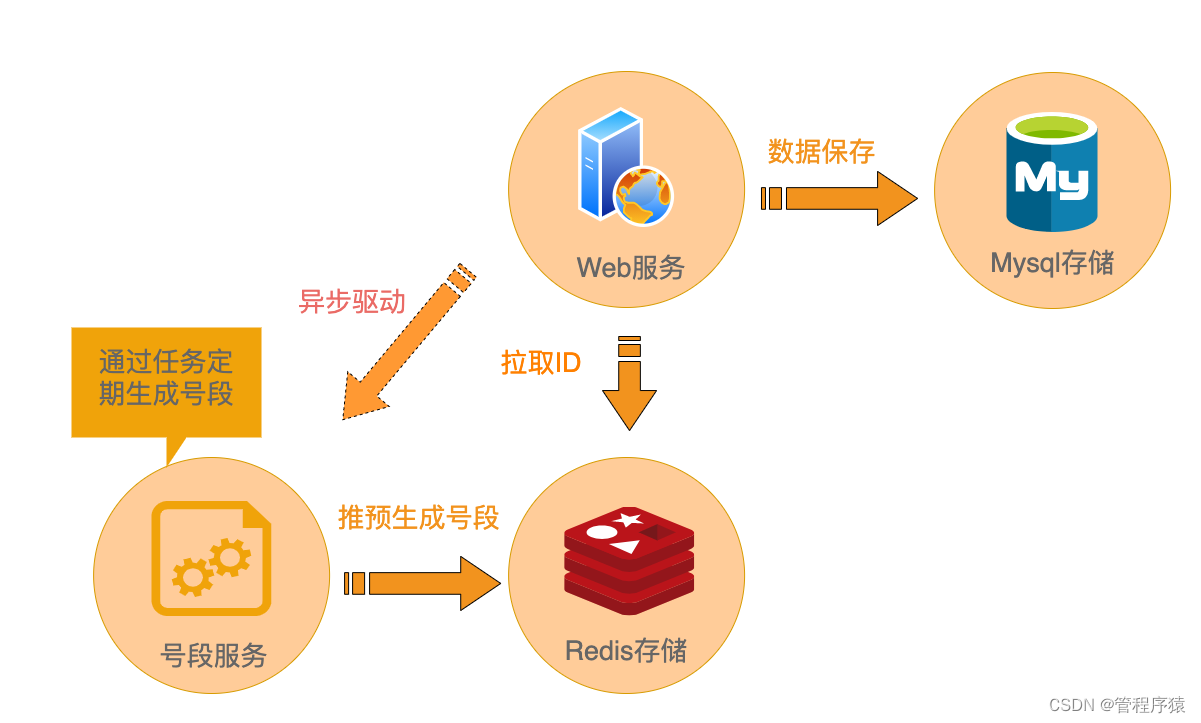
- 雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器 如:部署10台web服务,同一时间点,第一台机器生成uuid+00 第二台机器生成uuid+01 第三台机器生成uuid+02
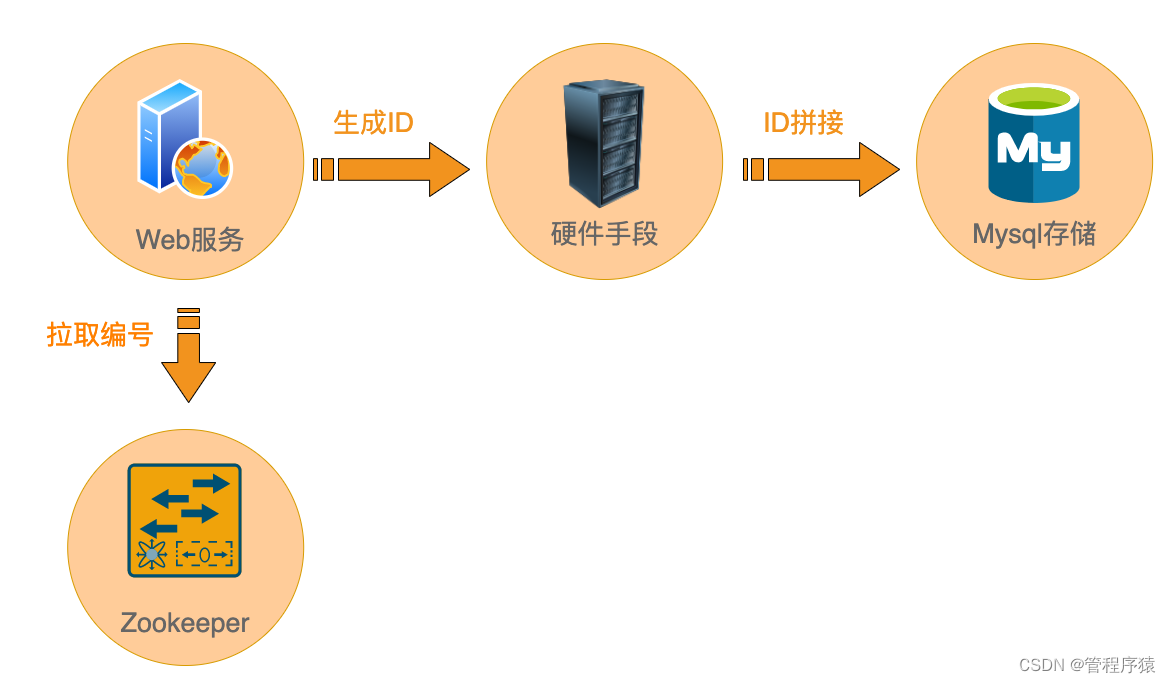
-
雪花算法生成原则和原理
- 使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0
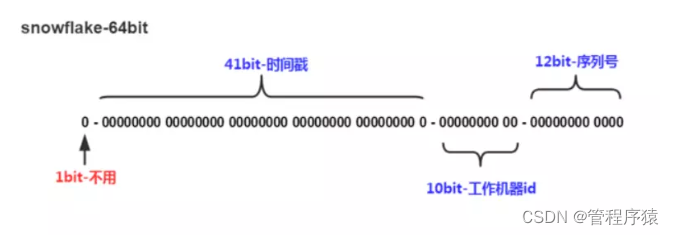
第8集 mysql分库分表非partition key检索
简介:解析分库分表遇到的问题,非partition key如何发起检索
-
分库分表是根据partition key做数据表下标定位,但在某些场景需要用到非partition key检索数据,就会遇到问题
- 无法直接找到具体连到哪个库和哪个表
-
对于单个非partition key查询一般可以根据业务场景需要解决方案
-
映射法检索,通过非partition key找到对应的partition key,再根据partition key做hash找到对应库表
- 优点:方案简单清晰
- 缺点:需要检索两次数据库,消耗IO较大
-
基因法检索,在存储非partition key时冗余一个字段用于预埋能找到对应的partition key,再根据partition key做hash找到对应库表
- 优点:建立冗余字段,只需要解析基因即可
- 缺点:需要设置基因解析逻辑
-
ES检索,根据非partition key作为条件建立起检索,后续查询直接走异构系统ES即可,性能和稳定性由ES保证
- 优点:性能高,能支撑高并发访问和多条件检索
- 缺点:开发成本增加,需要维护第三方组件
-
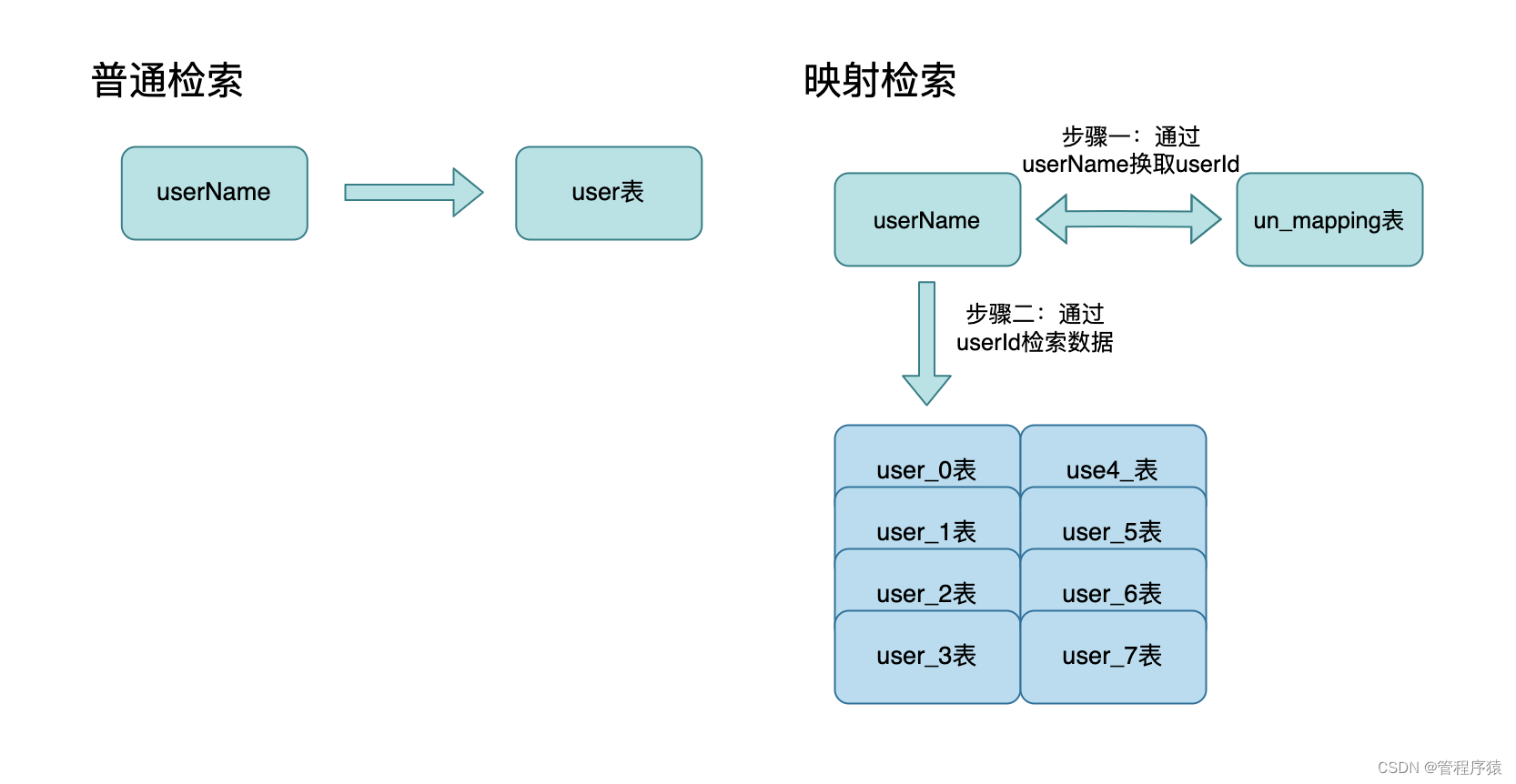
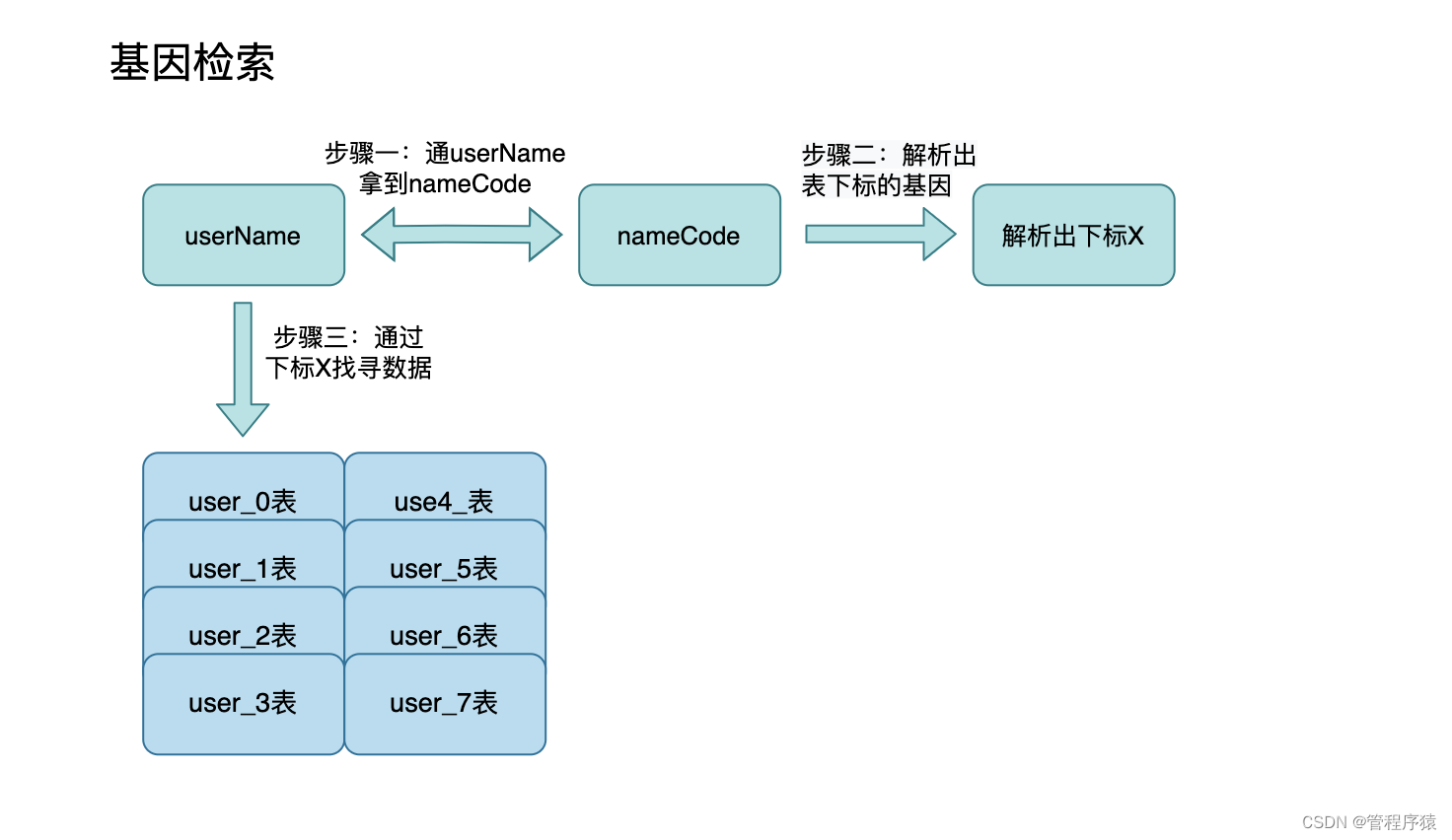
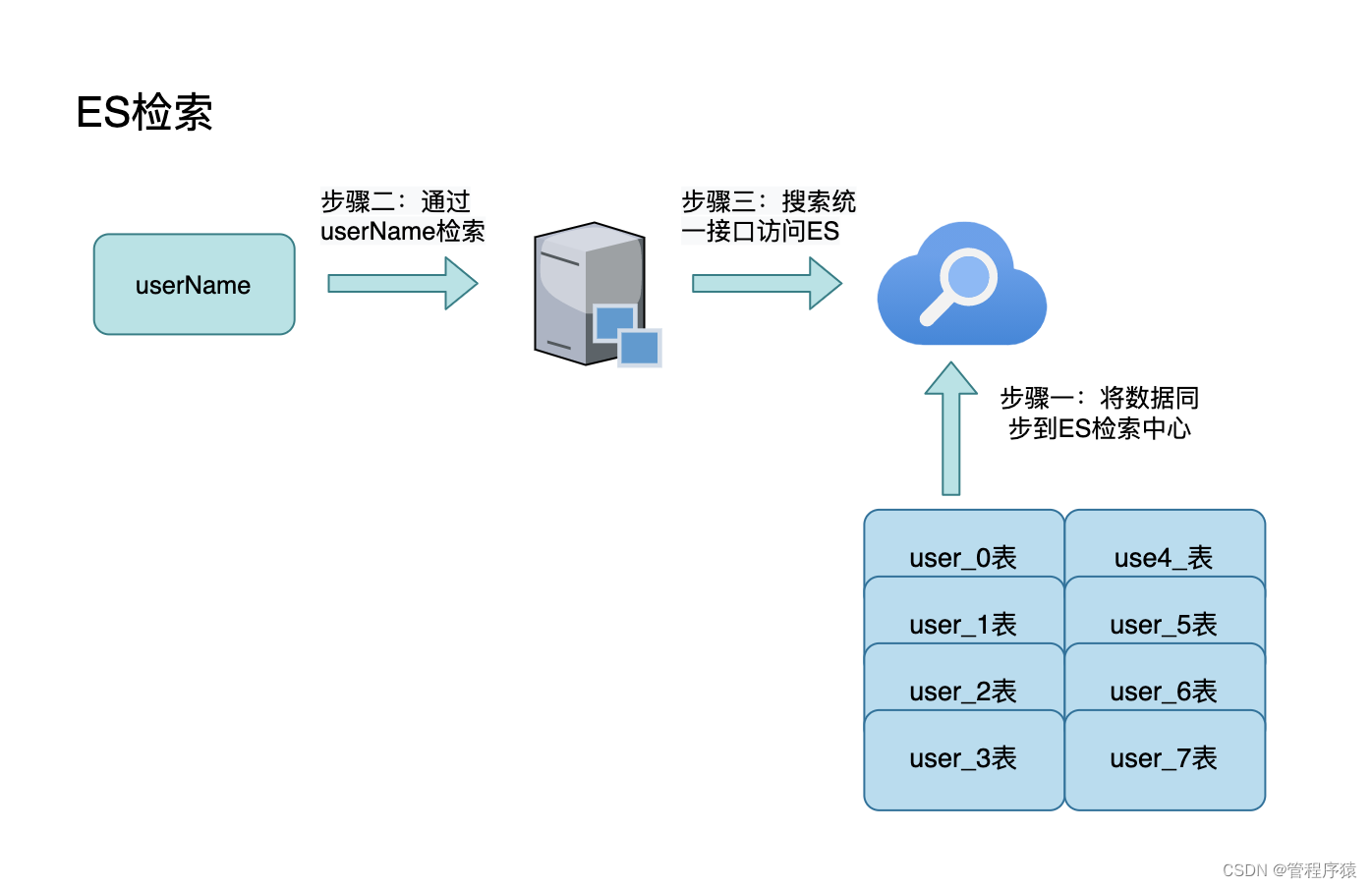
第9集 mysql分区是什么?
简介:mysql表分区概念讲解,分区有哪些优势
- 分区表的概念
- 分区和分表相似,都是按照规则分解表。不同在于分表将大表分解为若干个独立的实体表,而分区是将数据分段划分在多个位置存放,可以是同一块磁盘也可以在不同的机器
- 分区后,表面上还是一张表,但数据散列到多个位置了,app读写的时候操作的还是大表名字,db自动去组织分区的数据
- 分区表有哪些类型
- range分区类型:range 根据属于指定范围的列值将行分配到分区 (range就是区间,guave.range) a 判断==>[1,100]
- list分区类型: 根据与离散值集之一匹配的列将行分配到分区
- hash 分区类型:基于由用户定义的表达式返回的值而选择的分区,对要插入表中的行的列值进行操作
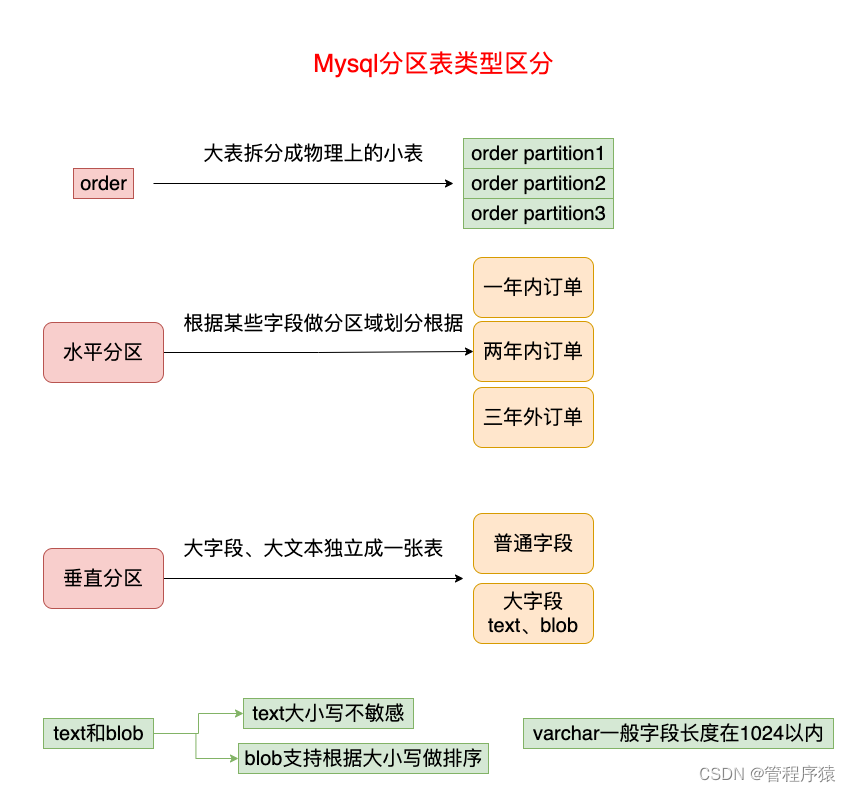
第10集 mysql分区原理和优劣势分析
简介:mysql表分区原理,分区有哪些优势
-
分区表实践
CREATE TABLE `product` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增id', `sale_id` varchar(64) NOT NULL DEFAULT '' COMMENT '卖家ID', `store_id` bigint(20) NOT NULL COMMENT '店铺ID', `product_seq` varchar(64) NOT NULL COMMENT '商品标识', `sku_id` varchar(64) NOT NULL COMMENT '商品skuID', `spu_id` varchar(64) NOT NULL COMMENT '商品spuID', `valid` tinyint(1) DEFAULT '1' COMMENT '是否有效,0无效,1有效', `create_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '创建时间', `update_time` datetime DEFAULT '2020-01-01 00:00:00' COMMENT '更新时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1001025 DEFAULT CHARSET=utf8mb4 partition by range columns(id,store_id) ( partition p01 values less than (10000), partition p02 values less than (20000), partition p03 values less than (100000000) ); -
分区表原理
- 存储角度分析:分区表是由多个相关的底层表实现,这些底层表也是由句柄对象表示,所以我们也可以直接访问各个分区,存储引擎管理分区的各个底层表和管理普通表一样
- 查询角度分析:分区表的索引只是在各个底层表上各自加上一个相同的索引,从存储引擎的角度来看,底层表和一个普通表没有任何不同,存储引擎也无须知道这是一个普通表还是一个分区表的一部分
-
分区表使用场景
- 表非常大以至于无法全部都放在内存中,或者只在表的最后部分有热点数据,其他都是历史数据
- 区表的数据更容易维护,如:想批量删除大量数据可以使用清除整个分区的方式
- 分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备
- 优化查询,在where字句中包含分区列时,可以只使用必要的分区来提高查询效率,同时在涉及sum()和count()这类聚合函数的查询时,可以在每个分区上面并行处理,最终做汇总 10个分区分别分别count()
-
分区表的劣势
- 5.1一个表最多只能有1024个分区(mysql5.6之后支持8192个分区)。
- 如果分区字段中有主键或者唯一索引列,那么所有主键列和唯一索引列都必须包含进来,如果表中有主键或唯一索引,那么分区键必须是主键或唯一索引
- 如果SQL不走分区键,很容易出现全表锁
- 分库分表,自己掌控业务场景与访问模式,可控;分区表,工程师写了一个SQL,自己无法确定MySQL是怎么玩的,不可控
- 在分区表实施关联查询,就是一个灾难
第十章 课程总结
第1集 MySQL高级篇课程总结
简介:mysql高级篇课程总结
- 课程内容回顾