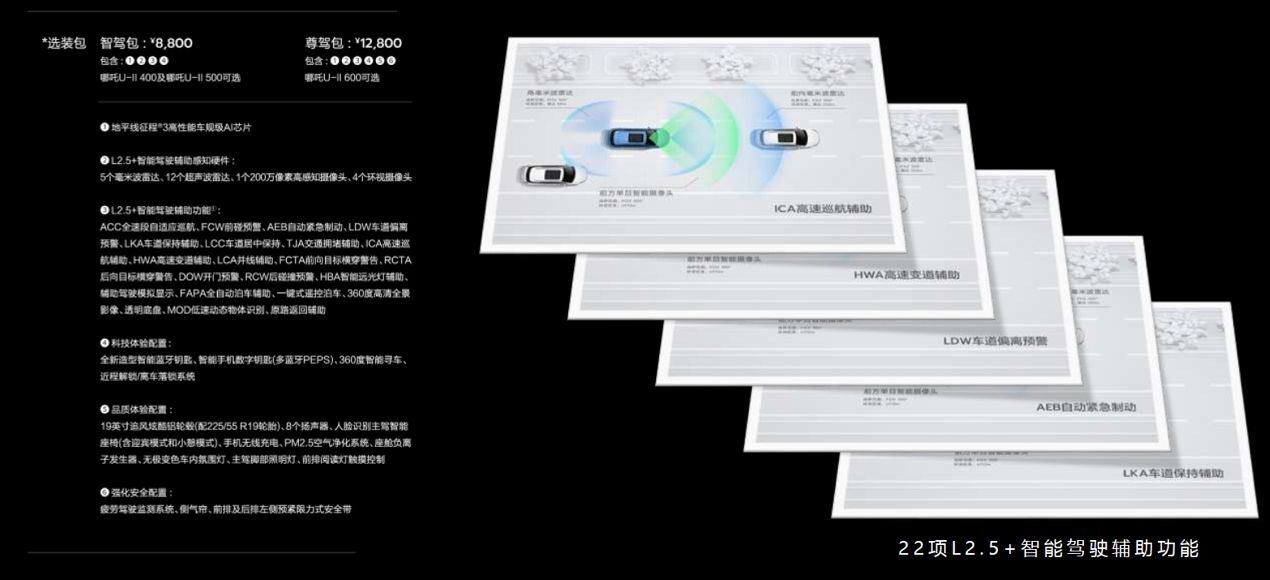
什么是原子操作
CUDA的原子操作可以理解为对一个Global memory或Shared memory中变 “读取-修改-写入” 这三个操作的一个最小单位的执行过程,在它执量进行行过程中,不允许其他并行线程对该变量进行读取和写入的操作。
基于这个机制,原子操作实现了对在多个线程间共享的变量的互斥保护,确保任何一次对变量的操作的结果的正确性。
如果没有原子操作,在一些情况下会有不确定性,例如Kernel程序最后面直接写 x = x * a。执行到这一步时, 有很多线程想读取 x 的值,同时也有很多线程想写入 x 的值,这就会产生不确定性的错误。
CUDA 原子操作常用函数
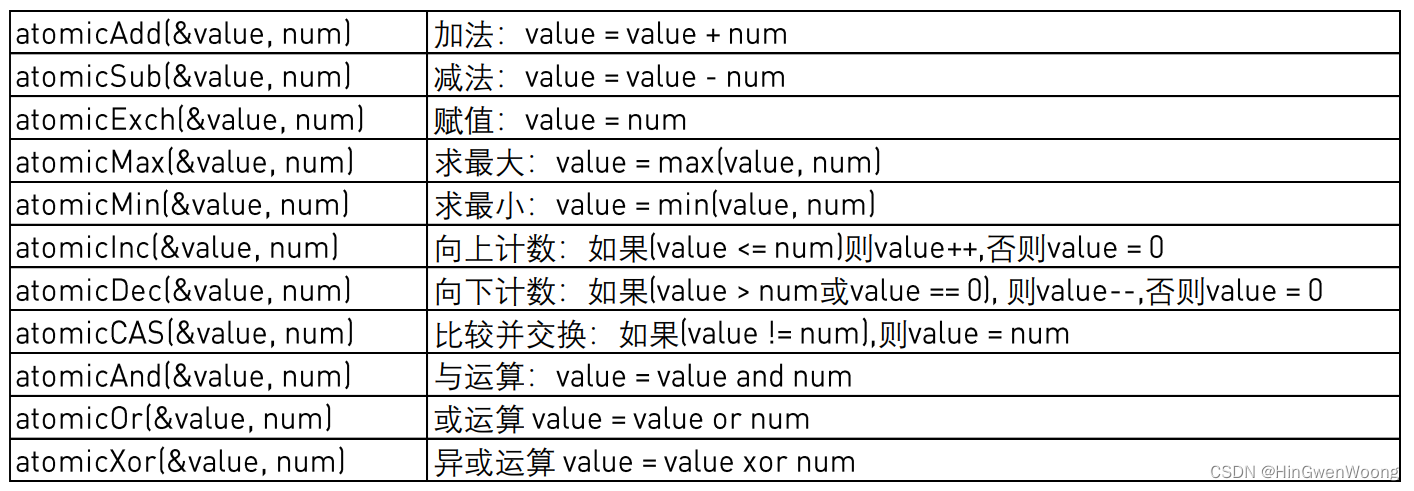
1. atomicAdd()
int atomicAdd(int* address, int val);
unsigned int atomicAdd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAdd(unsigned long long int* address,
unsigned long long int val);
float atomicAdd(float* address, float val);
double atomicAdd(double* address, double val);
__half2 atomicAdd(__half2 *address, __half2 val);
__half atomicAdd(__half *address, __half val);
__nv_bfloat162 atomicAdd(__nv_bfloat162 *address, __nv_bfloat162 val);
__nv_bfloat16 atomicAdd(__nv_bfloat16 *address, __nv_bfloat16 val);
读取位于全局或共享内存中地址 address 的 16 位、32 位或 64 位字 old,计算 (old + val),并将结果存储回同一地址的内存中。这三个操作在一个原子事务中执行。该函数返回old。
atomicAdd() 的 32 位浮点版本仅受计算能力 2.x 及更高版本的设备支持。
atomicAdd() 的 64 位浮点版本仅受计算能力 6.x 及更高版本的设备支持。
atomicAdd() 的 32 位 __half2 浮点版本仅受计算能力 6.x 及更高版本的设备支持。 __half2 或 __nv_bfloat162 加法操作的原子性分别保证两个 __half 或 __nv_bfloat16 元素中的每一个;不保证整个 __half2 或 __nv_bfloat162 作为单个 32 位访问是原子的。
atomicAdd() 的 16 位 __half 浮点版本仅受计算能力 7.x 及更高版本的设备支持。
atomicAdd() 的 16 位 __nv_bfloat16 浮点版本仅受计算能力 8.x 及更高版本的设备支持。
2. atomicSub()
int atomicSub(int* address, int val);
unsigned int atomicSub(unsigned int* address,
unsigned int val);
读取位于全局或共享内存中地址address的 32 位字 old,计算 (old - val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
3. atomicExch()
int atomicExch(int* address, int val);
unsigned int atomicExch(unsigned int* address,
unsigned int val);
unsigned long long int atomicExch(unsigned long long int* address,
unsigned long long int val);
float atomicExch(float* address, float val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old 并将 val 存储回同一地址的内存中。 这两个操作在一个原子事务中执行。 该函数返回old。
4. atomicMin()
int atomicMin(int* address, int val);
unsigned int atomicMin(unsigned int* address,
unsigned int val);
unsigned long long int atomicMin(unsigned long long int* address,
unsigned long long int val);
long long int atomicMin(long long int* address,
long long int val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最小值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMin() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
5. atomicMax()
int atomicMax(int* address, int val);
unsigned int atomicMax(unsigned int* address,
unsigned int val);
unsigned long long int atomicMax(unsigned long long int* address,
unsigned long long int val);
long long int atomicMax(long long int* address,
long long int val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 old 和 val 的最大值,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicMax() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
6. atomicInc()
unsigned int atomicInc(unsigned int* address,
unsigned int val);
读取位于全局或共享内存中地址address的 32 位字 old,计算 ((old >= val) ? 0 : (old+1)),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
7. atomicDec()
unsigned int atomicDec(unsigned int* address,
unsigned int val);
读取位于全局或共享内存中地址address的 32 位字 old,计算 (((old == 0) || (old > val)) ? val : (old-1) ),并将结果存储回同一个地址的内存。 这三个操作在一个原子事务中执行。 该函数返回old。
8. atomicCAS()
int atomicCAS(int* address, int compare, int val);
unsigned int atomicCAS(unsigned int* address,
unsigned int compare,
unsigned int val);
unsigned long long int atomicCAS(unsigned long long int* address,
unsigned long long int compare,
unsigned long long int val);
unsigned short int atomicCAS(unsigned short int *address,
unsigned short int compare,
unsigned short int val);
读取位于全局或共享内存中地址address的 16 位、32 位或 64 位字 old,计算 (old == compare ? val : old) ,并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old(Compare And Swap)。
Bitwise Functions
9. atomicAnd()
int atomicAnd(int* address, int val);
unsigned int atomicAnd(unsigned int* address,
unsigned int val);
unsigned long long int atomicAnd(unsigned long long int* address,
unsigned long long int val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old & val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicAnd() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
10. atomicOr()
int atomicOr(int* address, int val);
unsigned int atomicOr(unsigned int* address,
unsigned int val);
unsigned long long int atomicOr(unsigned long long int* address,
unsigned long long int val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old | val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicOr() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
11. atomicXor()
int atomicXor(int* address, int val);
unsigned int atomicXor(unsigned int* address,
unsigned int val);
unsigned long long int atomicXor(unsigned long long int* address,
unsigned long long int val);
读取位于全局或共享内存中地址address的 32 位或 64 位字 old,计算 (old ^ val),并将结果存储回同一地址的内存中。 这三个操作在一个原子事务中执行。 该函数返回old。
atomicXor() 的 64 位版本仅受计算能力 3.5 及更高版本的设备支持。
代码示例
下面是在线程中相加,需要使用原子操作的例子代码:
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp = 0;
for (int idx = threadIdx.x + blockDim.x * blockIdx.x;
idx < count;
idx += gridDim.x * blockDim.x
)
{
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp; //the per-thread partial sum is temp!
__syncthreads();
//**********shared memory summation stage***********
for (int length = BLOCK_SIZE / 2; length >= 1; length /= 2)
{
int double_kill = -1;
if (threadIdx.x < length)
{
double_kill = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x + length];
}
__syncthreads(); //why we need two __syncthreads() here, and,
if (threadIdx.x < length)
{
sum_per_block[threadIdx.x] = double_kill;
}
__syncthreads(); //....here ?
} //the per-block partial sum is sum_per_block[0]
if (blockDim.x * blockIdx.x < count) //in case that our users are naughty
{
//the final reduction performed by atomicAdd()
if (threadIdx.x == 0) atomicAdd(output, sum_per_block[0]);
}
}