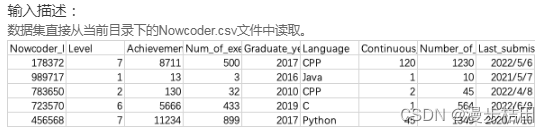
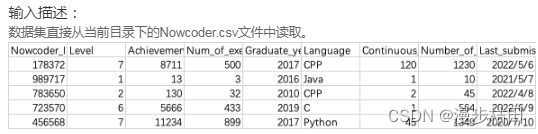
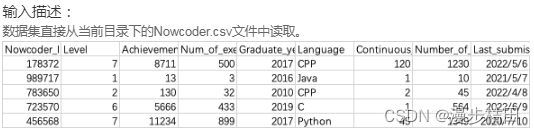
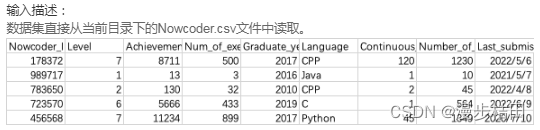
1.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
你想知道这个文件中记录了多少种常用语言,一并输出这些语言的名字。
import pandas as pd
Nowcoder=pd.read_csv('Nowcoder.csv',sep=',')
print(Nowcoder['Language'].nunique())
print(Nowcoder['Language'].unpque().tolist())2.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
对于牛客网的等级制度,你很感兴趣,你想知道大部分人都在什么等级,你能找到文件中等级的众数吗?
import pandas as pd
data = pd.read_csv("Nowcoder.csv")
num = data["Level"].mode()
print(pd.DataFrame(num, columns=["Level"]))3.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
现要分析牛客网用户的活跃情况,请依次输出用户成就值与最近连续签到天数的四分之一分位数以及刷题量与代码提交次数的四分之三分位数。

import pandas as pd
data = pd.read_csv("Nowcoder.csv")
print(data[["Achievement_value", "Continuous_check_in_days"]].quantile(q=0.25))
print(data[["Num_of_exercise", "Number_of_submissions"]].quantile(q=0.75))
4.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
牛客网有很多7级红名大佬,这是众所周知的,但是小白想知道这些大佬的成就值之间有没有什么不同,于是他想从这份文件中输出7级用户中最高成就值与最低成就值之差。

import pandas as pd
df = pd.read_csv("Nowcoder.csv")
level = df[df["Level"] == 7]["Achievement_value"]
a = level.max()
b = level.min()
print(int(a - b))5.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
假如牛牛正在统计用户的刷题情况,需要知道用户刷题量的方差以及提交代码次数的标准差,你能够帮助他吗?
import pandas as pd
df = pd.read_csv("Nowcoder.csv", sep=",")
a = df["Num_of_exercise"].var()
b = df["Number_of_submissions"].std()
print(round(a, 2), "\n", round(b, 2))6.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
牛客网有很多7级红名大佬这是众所周知的,小白希望知道这些大佬的成就值各自占据了所有人成就值总和的百分之多少,你能帮他吗?
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
nowcoder_sum = Nowcoder["Achievement_value"].sum()
print(Nowcoder[Nowcoder["Level"] == 7]["Achievement_value"] /nowcoder_sum)7.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
牛客网有那么多刷题的用户,有的人身经百战,刷题无数但是反复提交了多次错误的代码debug之后才能通过,牛牛想知道牛客网最高的正确率能有多少,为了公平起见,他决定只统计刷题数量大于10题的用户,请你帮帮他。

import pandas as pd
df = pd.read_csv("Nowcoder.csv")
coder = df[df["Num_of_exercise"] > 10][["Num_of_exercise", "Number_of_submissions"]]
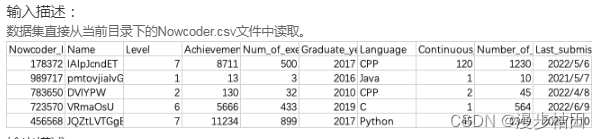
print((coder["Num_of_exercise"] / df["Number_of_submissions"]).max().round(3))8.现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
Nowcoder_ID:用户ID
Name:用户名
Level:等级
Achievement_value:成就值
Num_of_exercise:刷题量
Graduate_year:毕业年份
Language:常用语言
Continuous_check_in_days:最近连续签到天数
Number_of_submissions:提交代码次数
Last_submission_time:最后一次提交题目日期
运营小周同学想要统计这些用户的名字长度,你可以帮助她吗?
import pandas as pd
Nowcoder = pd.read_csv("Nowcoder.csv", sep=",")
print(Nowcoder["Name"].str.len())