目录
前言:
1、认识双向链表中的结点
2、认识并创建无头双向链表
3、实现双向链表当中的一些方法
3.1、遍历输出方法(display)
3.2、得到链表的长度(size)
3.3、查找关键字key是否包含在双链表中(contains)
3.4、头插法(addFirst)
【代码思路】
【代码实现】
3.5、尾插法 (addIndex)
【代码思路】
【代码实现】
3.6、任意位置插入 ,第一个数据结点为0号下标(addIndex)
【代码思路】
【代码示例】
3.7、 删除第一次出现关键字key的结点(remove)
【代码思路】
第一种情况,删除头节点。
【代码示例】
3.8、删除所有值为key的结点(removeAllKey)
【代码思路】
【代码示例】
3.9、清空双向链表(clear)
【代码思路】
【代码示例】
前言:
单向链表能够解决逻辑关系为"一对一"数据的存储问题,但是在解决某些特殊问题的时候,单链表并不是效率最有的存储结构。比如,需要找某个节点的前驱节点,使用单链表并不合适,单链表更适合"从前往后"找,而"从后往前"找并不是单链表的强项。这里就要使用双向链表来解决这类问题。
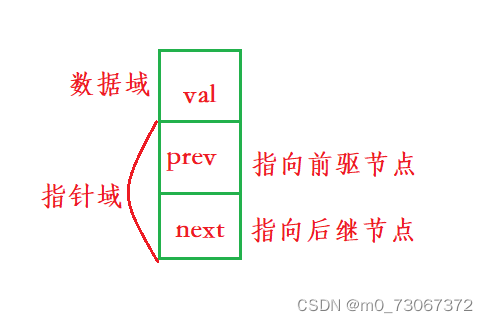
1、认识双向链表中的结点
双向链表中的结点有两个指针域和一个数据域,一个指针指向前驱结点,一个指向后继节点。(双向链表当中第一个结点的prev为null,最后一个结点的next为null)
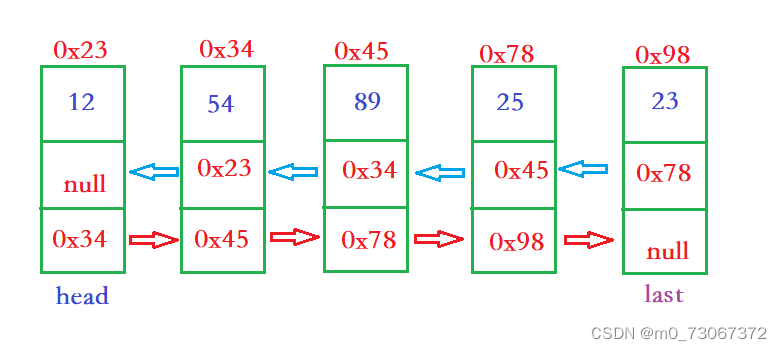
2、认识并创建无头双向链表
在Java当中,双链表相比于单链表增加了一个引用last,last永远指向双链表的最后一个结点。
创建链表类
public class MyLinkedList {
static class ListNode{//结点类
public int val;
public ListNode prev;//前驱
public ListNode next;//后继
public ListNode(int val){
this.val = val;
}
}
public ListNode head;
public ListNode last;//指向双向链表的结尾
}3、实现双向链表当中的一些方法
以下这些方法写在MyLinkdeList类当中
3.1、遍历输出方法(display)
public void display(){
ListNode cur = head;
while(cur != null){//说明cur还没有遍历完这个链表
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();//当整体输出完成之后换行,下一次打印的时候在下一行
}
3.2、得到链表的长度(size)
public int size(){
ListNode cur = head;
int len = 0;
while(cur != null){
len++;//因为cur是从head向后遍历,先通过len++将head计算在内
cur = cur.next;
}
return len;
}
3.3、查找关键字key是否包含在双链表中(contains)
public Boolean contains(int key){
ListNode cur = head;
while(cur != null){
if(cur.val == key){//如果cur在遍历的过程中找到了
return true;
}
cur = cur.next;//没有找到就向后走
}
return false;//遍历完还没找到返回false
}3.4、头插法(addFirst)
【代码思路】
头插法存在两种情况
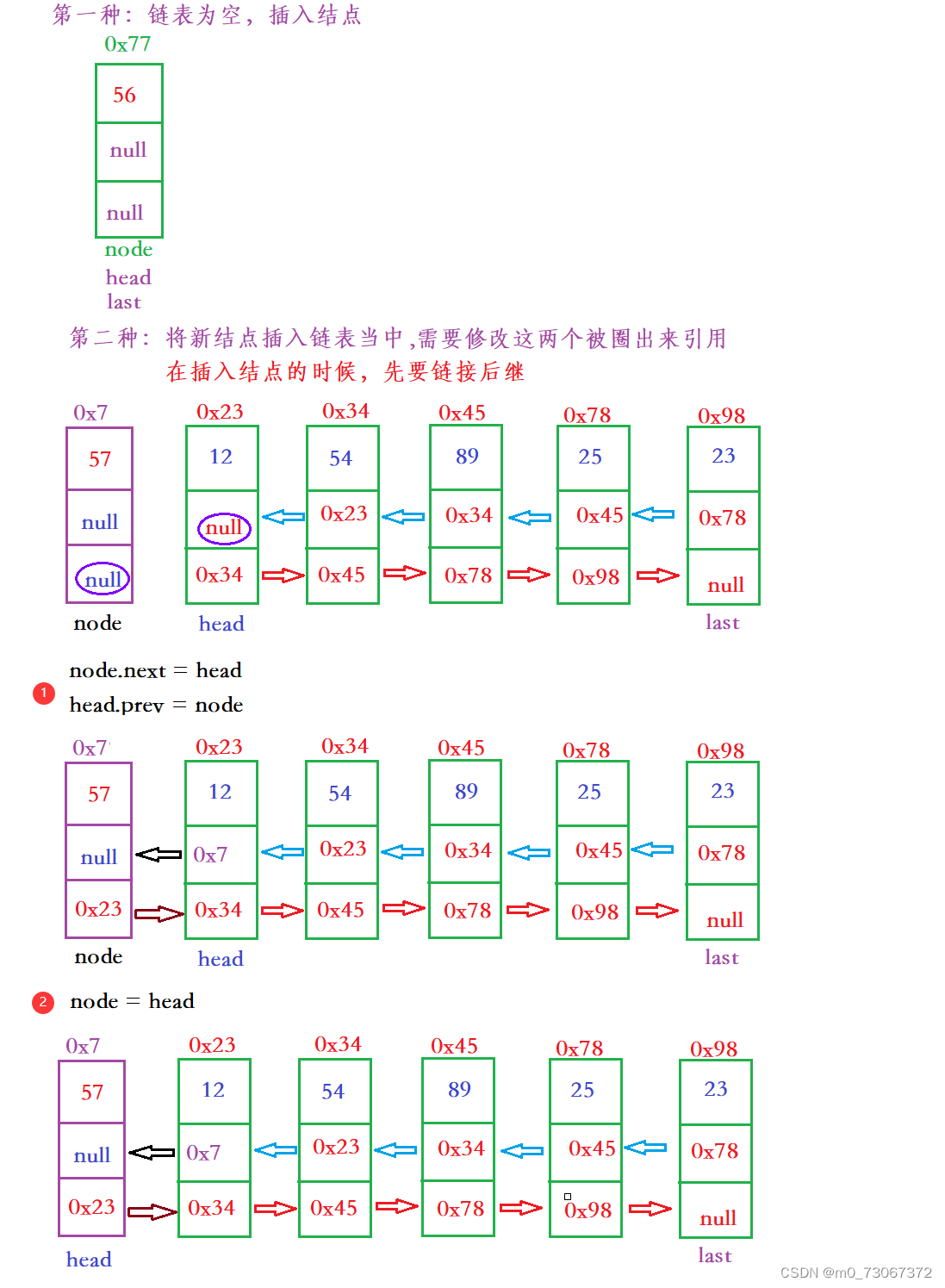
【代码实现】
public void addFirst(int data){
ListNode node = new ListNode(data);//创建一个新的结点
if(head == null){//如果链表为空,插入结点之后,头和尾都指向node
head = node;
last = node;
}else{//如果链表不为空。先连接后继,再链接前驱,最后将head前移
node.next = head;
head.prev = node;
head = node;
}
}3.5、尾插法 (addIndex)
【代码思路】
尾插法存在两种情况。
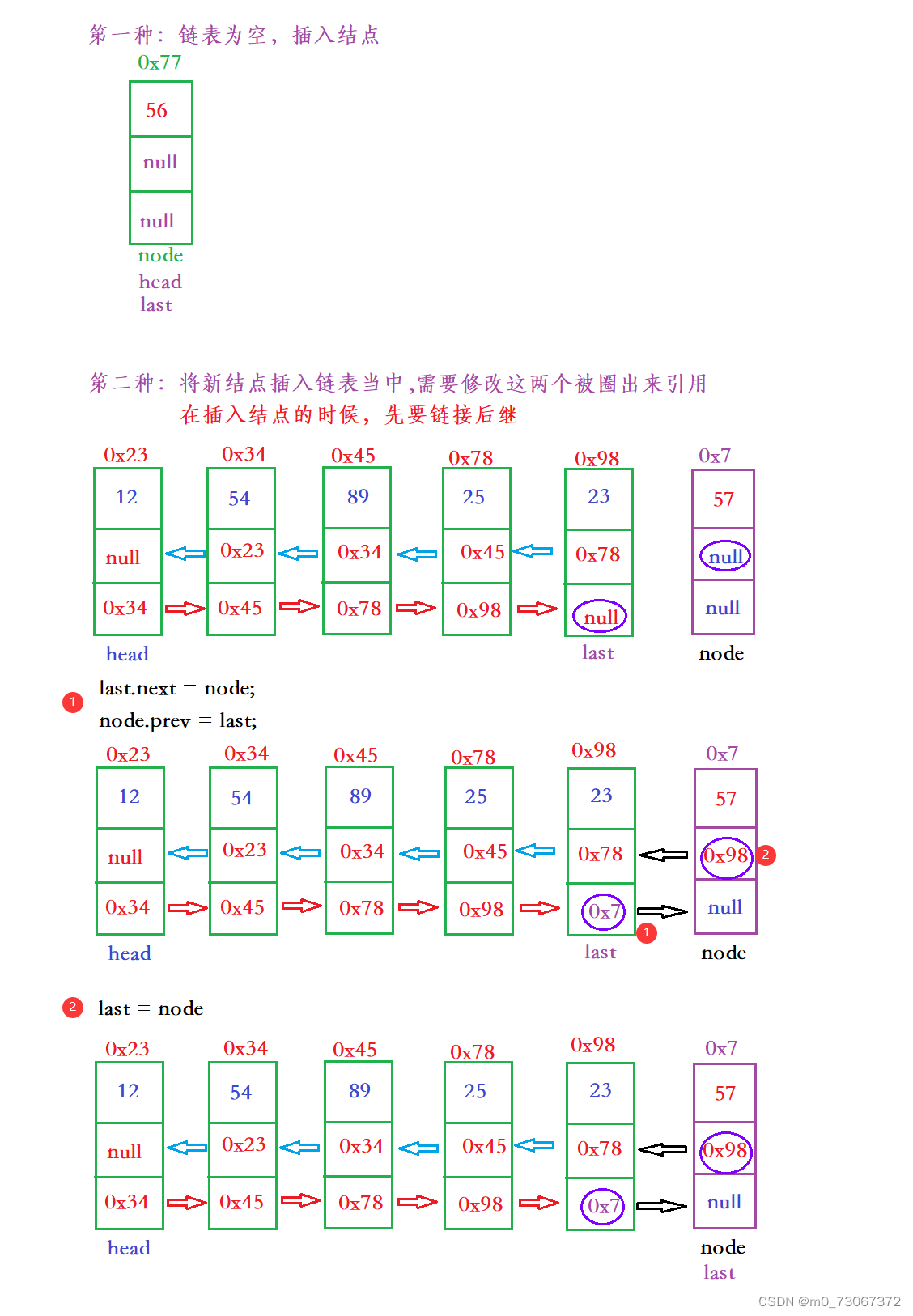
【代码实现】
public void addLast(int data){
ListNode node = new ListNode(data);
if(head == null){
head = node;
last = node;
}else{
last.next = node;
node.prev = last;
last = node;
}
}❗❗❗ 总结:
单链表的时间复杂度为O(N),而双链表的时间复杂度为O(1)。
3.6、任意位置插入 ,第一个数据结点为0号下标(addIndex)
【代码思路】

【代码示例】
public void addIndex(int index,int data){
if(index < 0 || index >size()){//检查位置的合法性
return;//这里可以抛异常,也可以直接return
}
if(index == 0){//在链表的开头插入结点
addFirst(data);
return;
}
if(index == size()){//再链表的结尾插入结点
addLast(data);
return;
}
ListNode node = new ListNode(data);//创建一个新的结点
ListNode cur = findIndex(index);//通过调用这个方法,找到要插入的位置
node.next = cur;
cur.prev.next = node;
node.prev = cur.prev;
cur.prev = node;
}
//通过这个方法来找要插入的位置
private ListNode findIndex(int index){
ListNode cur = head;
while(index != 0){//从头开始遍历链表。
cur = cur.next;
index--;
}
return cur;
}3.7、 删除第一次出现关键字key的结点(remove)
【代码思路】
第一种情况,删除头节点。
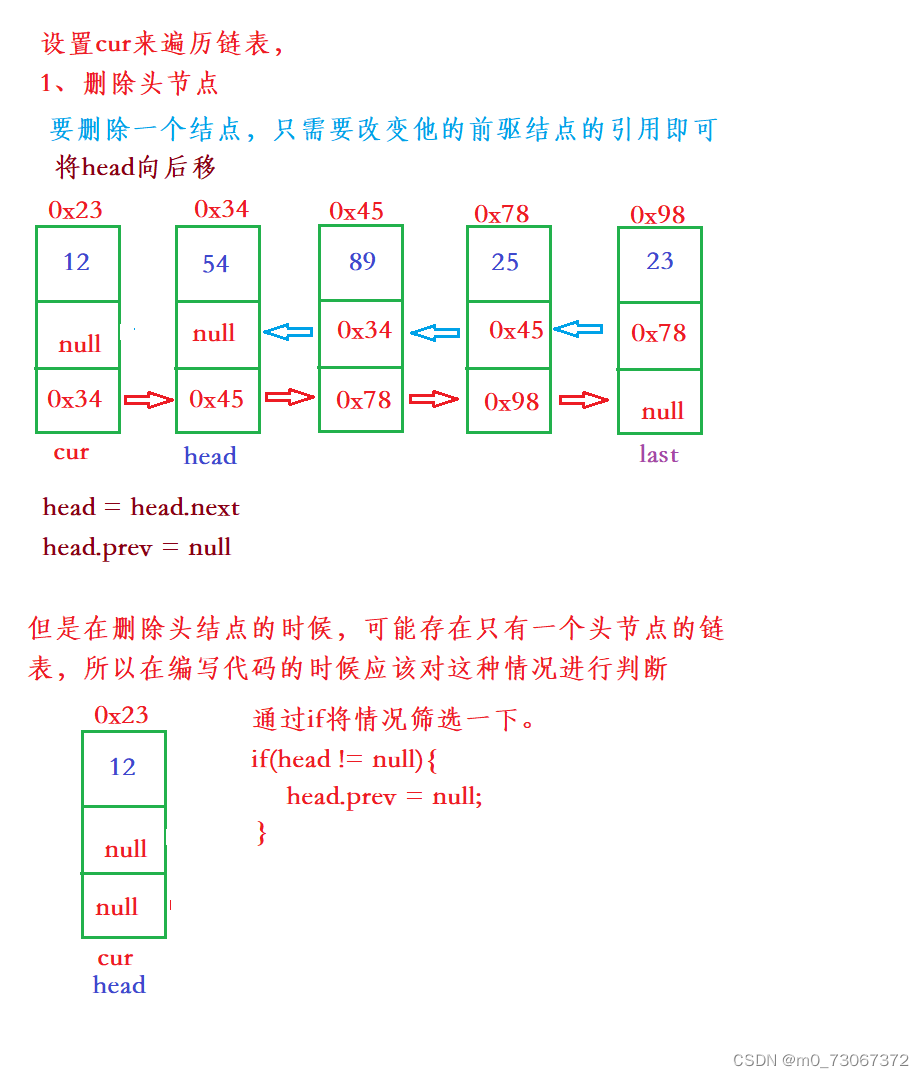
第二种和第三种情况,删除中间节点和结尾
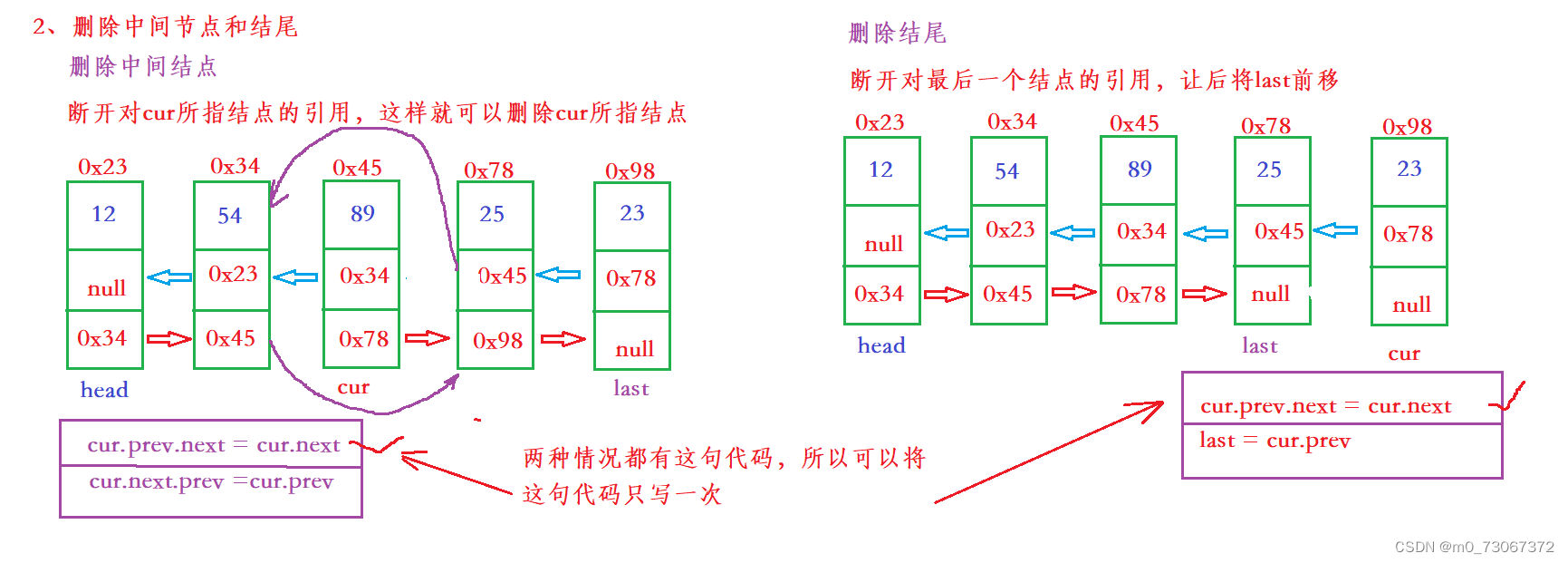
【代码示例】
public void remove(int key){
ListNode cur = head;
while(cur != null){
//开始删除了
if(cur.val == key){
//1、删除的是头节点
if(cur == head){
head = head.next;//head向后移
//处理链表只有一个结点的情况
if(head != null) {
head.prev = null;//将head的前驱置为空
}
}else{
//删除的是中间和结尾
cur.prev.next = cur.next;
//2、删除中间结点
if(cur.next != null){
cur.next.prev = cur.next;
//3、删除尾巴结点
}else{
last = cur.prev;
}
}
return;//这个return对应的是第2个if,找到一个与key值相等的结点,删除之后,就返回,只删一个与key值相等的结点
}
cur = cur.next;//对应最开始的if,若是要和删除的key不相同,继续向后走
}
}3.8、删除所有值为key的结点(removeAllKey)
【代码思路】
当写出删除一个值为key的结点的代码,那么删除所有值为key的结点的代码,就非常简单了,只需要将上述代码中的return去掉就可以了。让上述的代码从头跑到结尾就行,这样cur在遍历链表的时候,也只是遍历了一遍,就将所有与key值相等的结点就删除完了。他的时间复杂度为O(N).
【代码示例】
public void removeAllKey(int key){
ListNode cur = head;
while(cur != null){
//开始删除了
if(cur.val == key){
//1、删除的是头节点
if(cur == head){
head = head.next;//head向后移
//处理链表只有一个结点的情况
if(head != null) {
head.prev = null;//将head的前驱置为空
}
}else{
//删除的是中间和结尾
cur.prev.next = cur.next;
//2、删除中间结点
if(cur.next != null){
cur.next.prev = cur.next;
//3、删除尾巴结点
}else{
last = cur.prev;
}
}
}
cur = cur.next;
}
}3.9、清空双向链表(clear)
这里很多人会想到将head和last直接置为空,不让head引用和last引用,引用链表的节点即可,但是head所引用的结点的后继结点,还引用这个结点,last所引用的结点的前驱结点,还引用这个结点。所以这样的操作还是不能将链表清空,必须要将双向链表的所有结点的指针域清空。
【代码思路】
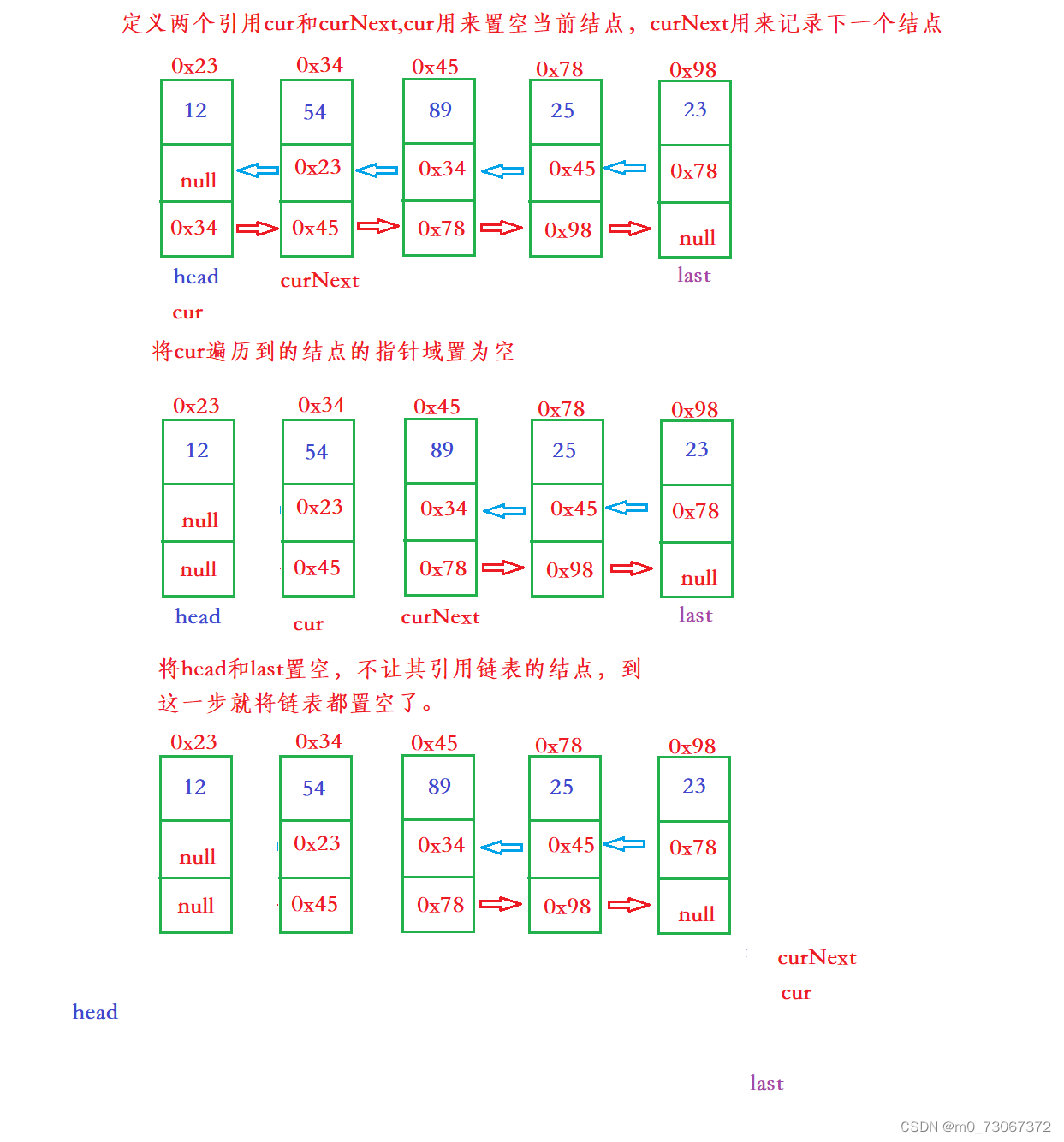
【代码示例】
public void clear(){
ListNode cur = head;
while(cur != null){//将每个结点的指针域都置为空,由于这里的数据域是基本数据类型,不用置空,但是当数据域当中为引用数据类型的时候,数据域还要置空
ListNode curNext = cur.next;
cur.prev = null;
cur.next = null;
cur = curNext;
}
head = null;//因为head和last作为引用,还在引用链表的第一个结点和最后一个结点。
last = null;
}