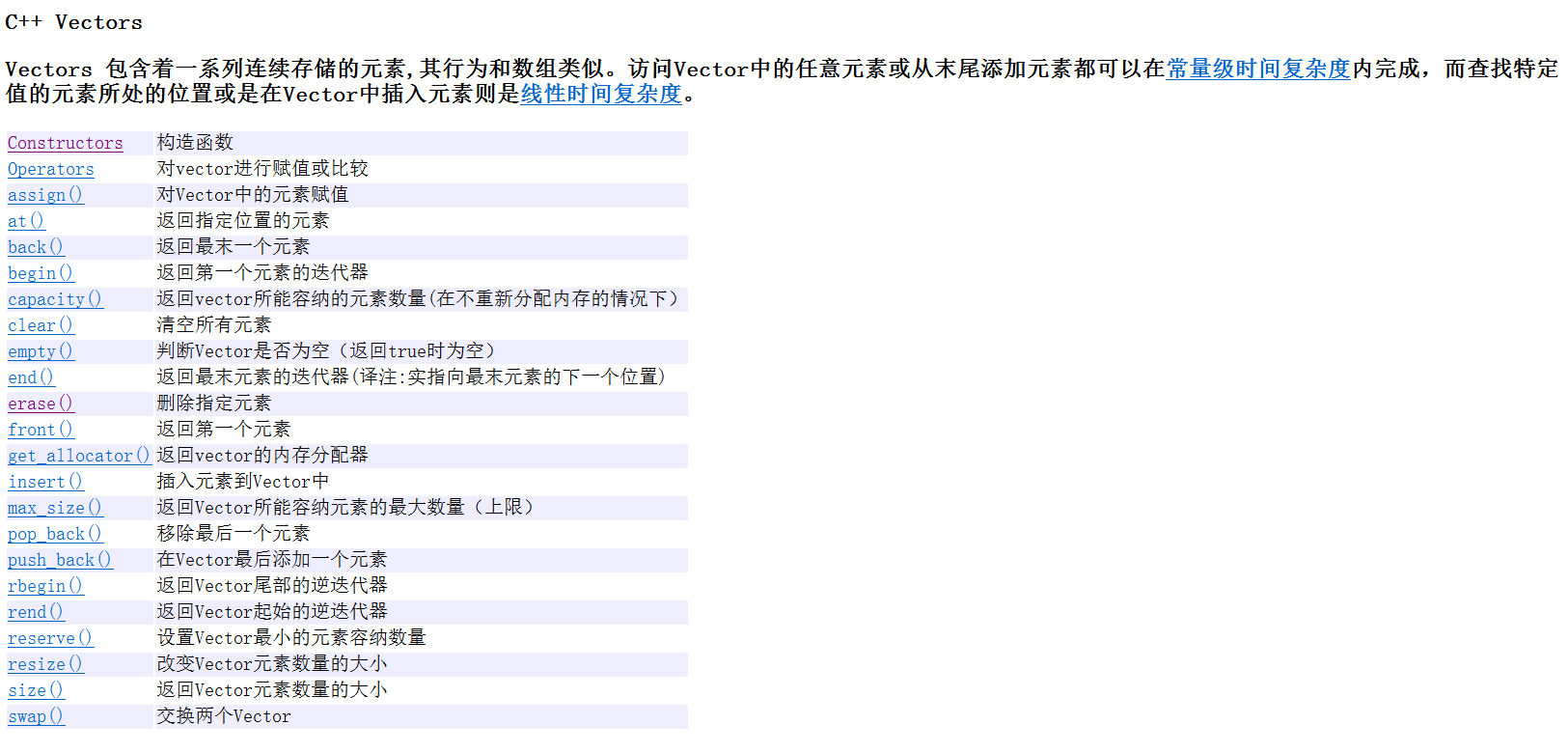
文章目录
- Constructors(构造函数)
- myvector()
- myvector(int n, const T& val = T())
- myvector(InputIterator first, InputIterator last)
- 拷贝构造
- 交换函数
- myvector< T >& operator=(myvector< T > v)
- 迭代器
- 扩容
- reserve
- resize
- 插入和删除
- push_back
- pop_back
- insert
- erase
- 全代码
- 总结
vector和我们学数据结构时候的顺序表差不多,不过STL库里面的vector给我们提供了很多的接口函数,十分方便。对于各接口的调用这里就不详细讲解了,用到的时候不熟悉可以去官网查一下。这篇文章主要讲讲 个人对vector模拟实现的方法
Constructors(构造函数)
vector是一个模板类,可以存储不同类型的数据。先来看看官方的几种构造法方法
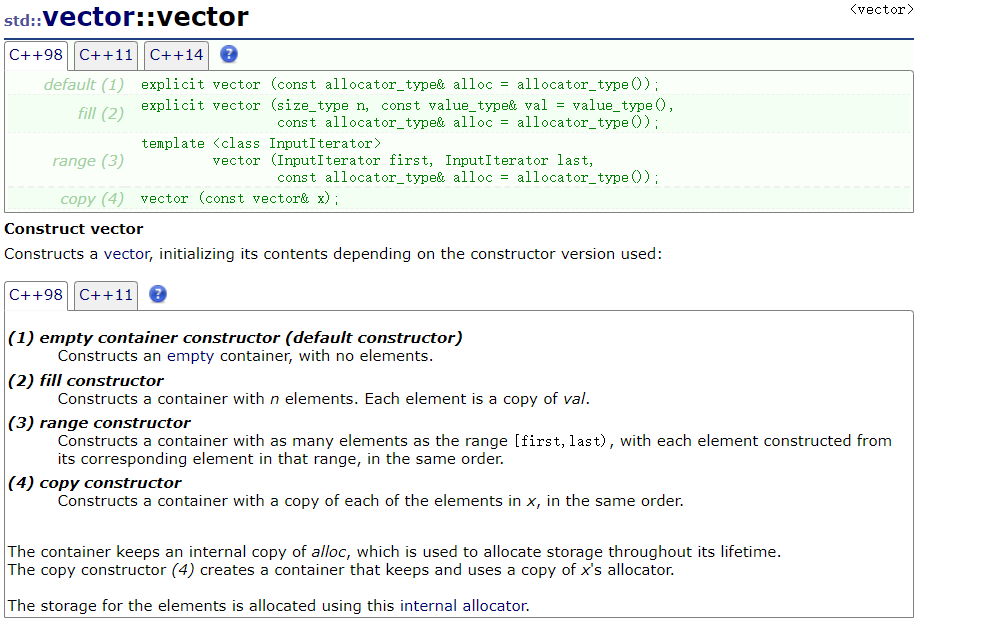
因为vector是一个模板类,所以在定义类时要用模板的格式。在vector中可以简单的定义三个类变量,全部用模板类型的指针类型
iterator _start;//首地址
iterator _finish;//最后一位有效数据的后一位地址
iterator _endofstorage;//容量的最后一位地址
template<class T>
class myvector {
public:
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start;//首地址
iterator _finish;//最后一位有效数据地址
iterator _endofstorage;//容量的最后一位地址
};
myvector()
定义好变量后,先实现一个无参的构造函数。因为变量都是指针类型,所以一开始我们可以将它们初始化为nullptr
myvector()
:_start(nullptr)
, _finish(nullptr)
,_endofstorage(nullptr)
{}
myvector(int n, const T& val = T())
再来实现一个跟库里面一样的,可以指定对象开辟的空间大小,并把指定值填入每一个空间中
myvector(int n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(n);
for (int i = 0; i < n; i++)
push_back(val);
}
push_back的实现下面再将。
注意:这个的缺省值不能用0或者" ",因为类型T没有确定,有可能会是我们自定义的类型,所以缺省值要使用T类型的默认初始值。参数中的n为什么不用size_t类型呢,下面会谈到
myvector(InputIterator first, InputIterator last)
接下来库里面的第三个构造函数,指定一段区间,并将这段区间的所有数值赋值到对象中。因为是一段区间,所以参数传的是指针,但是由于类型没有确定,所以要使用模板函数
template <class InputIterator>
myvector(InputIterator first, InputIterator last)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
while (first != last) {
push_back(*first);
first++;
}
}
为什么上面讲的第二个构造不使用size_t类型呢,就是因为第三个区间的构造传的参数是指针类型,如果第二个参数使用的是size_t类型,那么当我们构造传参时,编译器就不知道去匹配哪一个构造函数了。所以为了避免冲突,第二个构造我们使用int类型参数。
拷贝构造
接下来实现拷贝构造函数,因为有了上面的区间构造函数后,我们只需要创建一个临时的对象,然后和原对象交换一下后就可以了。需要注意的是,交换的时候要将地址交换才不会出现野指针的情况
myvector(const myvector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
myvector<int> tmp(v.begin(), v.end());
swap(tmp);
}
交换函数
交换地址就可以直接实现了
void swap(myvector<T>& v) {
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
myvector< T >& operator=(myvector< T > v)
按照我们的使用习惯,一般都会有对象给对象赋值,所以肯定少不了实现 =运算符重载了。因为形参的改变不会影响实参,所以我们只需要形参对象和原对象交换一下即可
myvector<T>& operator=(myvector<T> v) {
swap(v);
return *this;
}
迭代器
在模拟实现时只需要把迭代器看成是指针即可,所以迭代器的实现就非常的简单了。因为库里面也会有const类型的,所以我们也加上const类型的即可
iterator begin() {
return _start;
}
iterator end() {
return _finish;
}
const_iterator begin() const {
return _start;
}
const_iterator end() const {
return _finish;
}
既然vector的功能和顺序表差不多,那么肯定少不了随机读写的功能了,这就得重载[]运算符了
T& operator[](size_t pos) {
assert(pos < size());
//因为类变量的本质是数组,所以直接返回即可
return _start[pos];
}
扩容
reserve
和string一样,如果容量不足肯定是需要扩容的,但是这里和string不同的是,string我们可以直接使用 memcpy 将数据拷贝到新扩容的空间即可,但是memcpy只能浅拷贝数据。vector是可以嵌套vector类型的,也就相当于二维数组那样。如果单单浅拷贝的话,当我们将原有空间释放后,原地址的数据也都没有了,那这个时候新扩容的空间指向的就是一个野指针了。所以为了避免这种情况,我们只能稳稳地将每个数据复制到每一个对应的新地址
void reserve(size_t n) {
if (n > capacity()) {
T* tmp = new T[n];
//记录数据个数
size_t i = size();
if (_start) {
//浅拷贝
//memcpy(tmp, _start, sizeof(T) * i);
//深拷贝,将新的每一个对应的地址赋值
for (size_t k = 0; k < i; k++)
tmp[k] = _start[k];
delete[] _start;
}
//新的首地址
_start = tmp;
//新的finish就是新的首地址加上数据个数
_finish = _start + i;
//新的空间尾地址等于新的首地址加上空间容量
_endofstorage = _start + n;
}
}
resize
这里的resize和string的是一样的效果,可以参考一下上篇文章
void resize(size_t n, const T& x = T()) {
if (n > capacity())
reserve(n);
if (n > size())
while (_finish != _endofstorage) {
*_finish = x;
_finish++;
}
else
_finish = _start + n;
}
一样的缺省参数不可以直接使用0或" ",要用T类型的默认初值
插入和删除
push_back
void push_back(const T& x) {
if (_finish == _endofstorage) {
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
_finish++;
}
pop_back
void pop_back() {
assert(!empty());
--_finish;
}
insert
在指定位置插入一个指定数据,和string一样,不过这里有一个返回值,返回修改的那个位置。除此之外这里还需要注意一个非常重要的问题----迭代器失效
因为既然是插入就意味着可能会需要扩容,但是在C/C++中的扩容并不会保证是原地扩容还是异地扩容,所以总是会有异地扩容的情况,那这个时候传入的参数是一个指针,也就是说如果发生了异地扩容后,该指针就不再指向的是该 vector 对象里的空间了,那这个时候就失效了
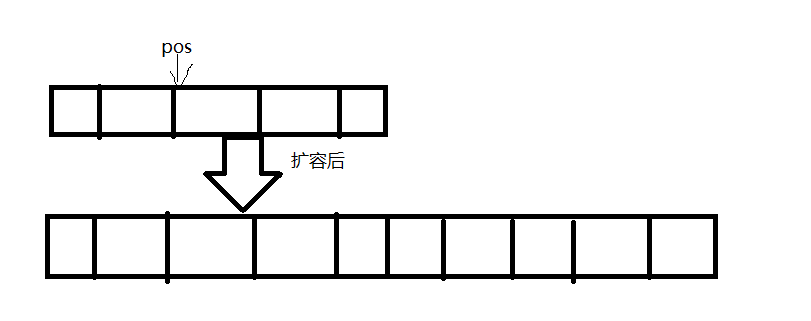
所以 如果想让pos指向扩容后的位置,那就需要一开始先记录pos和首地址之间的长度,扩容之后记录的长度加上首地址就是对应的pos应该指向的位置了
iterator insert(iterator pos, const T& x) {
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _endofstorage) {
//记录pos和首地址之间的长度
size_t len = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
//加回长度
pos = len + _start;
}
//挪动数据,留出pos插入数据
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
end--;
}
*pos = x;
_finish++;
return pos;
}
erase
删除指定位置的值,这个同样也会有一个返回值,返回原被删除位置的下一个位置。为什么这个也要有返回值呢,因为这个也会出现迭代器失效的情况,当删除完该位置的数据后,编译器会默认认为该迭代器就失效了,所以如果还需要使用就得更新一下,那就的返回一个迭代器接收之后再使用。
iterator erase(iterator pos) {
assert(pos >= _start);
assert(pos < _finish);
iterator begin = pos;
while (begin < _finish - 1) {
*begin = *(begin + 1);
begin++;
}
_finish--;
return pos;
}
全代码
#include<iostream>
#include<cassert>
using namespace std;
template<class T>
class myvector {
public:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin() {
return _start;
}
iterator end() {
return _finish;
}
const_iterator begin() const {
return _start;
}
const_iterator end() const {
return _finish;
}
T& operator[](size_t pos) {
assert(pos < size());
//因为类变量的本质是数组,所以直接返回即可
return _start[pos];
}
T& operator[](size_t pos) const {
assert(pos < size());
return _start[pos];
}
myvector()
:_start(nullptr)
, _finish(nullptr)
,_endofstorage(nullptr)
{}
myvector(int n, const T& val = T())
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(n);
for (int i = 0; i < n; i++)
push_back(val);
}
template <class InputIterator>
myvector(InputIterator first, InputIterator last)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
while (first != last) {
push_back(*first);
first++;
}
}
/*myvector(const myvector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(v.capacity());
for (const auto& e : v)
push_back(e);
}*/
myvector(const myvector<T>& v)
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
myvector<int> tmp(v.begin(), v.end());
swap(tmp);
}
myvector<T>& operator=(myvector<T> v) {
swap(v);
return *this;
}
void swap(myvector<T>& v) {
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
void reserve(size_t n) {
if (n > capacity()) {
T* tmp = new T[n];
//记录数据个数
size_t i = size();
if (_start) {
//浅拷贝
//memcpy(tmp, _start, sizeof(T) * i);
//深拷贝
for (size_t k = 0; k < i; k++)
tmp[k] = _start[k];
delete[] _start;
}
_start = tmp;
_finish = _start + i;
_endofstorage = _start + n;
}
}
void resize(size_t n, const T& x = T()) {
if (n > capacity())
reserve(n);
if (n > size())
while (_finish != _endofstorage) {
*_finish = x;
_finish++;
}
else
_finish = _start + n;
}
bool empty() const {
return _finish == _start;
}
size_t size() const {
return _finish - _start;
}
size_t capacity() const {
return _endofstorage - _start;
}
void push_back(const T& x) {
if (_finish == _endofstorage) {
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
}
*_finish = x;
_finish++;
}
void pop_back() {
assert(!empty());
--_finish;
}
iterator insert(iterator pos, const T& x) {
assert(pos >= _start);
assert(pos < _finish);
if (_finish == _endofstorage) {
//记录pos和首地址之间的长度
size_t len = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
//加回长度
pos = len + _start;
}
iterator end = _finish - 1;
while (end >= pos) {
*(end + 1) = *end;
end--;
}
*pos = x;
_finish++;
return pos;
}
iterator erase(iterator pos) {
assert(pos >= _start);
assert(pos < _finish);
iterator begin = pos;
while (begin < _finish - 1) {
*begin = *(begin + 1);
begin++;
}
_finish--;
return pos;
}
void clear() {
assert(!empty());
_finish = _start;
}
~myvector() {
delete[] _start;
_start = _finish = _endofstorage = nullptr;
}
private:
iterator _start;//首地址
iterator _finish;//最后一位有效数据地址
iterator _endofstorage;//容量的最后一位地址
};
总结
STL中的各容器都大同小异
需要掌握常见的接口的使用与作用
学完一种容器就可以去多做点题巩固一下
!!!!!



![[附源码]java毕业设计医院网上预约系统](https://img-blog.csdnimg.cn/4d32debe961d47929466abe08bceb862.png)