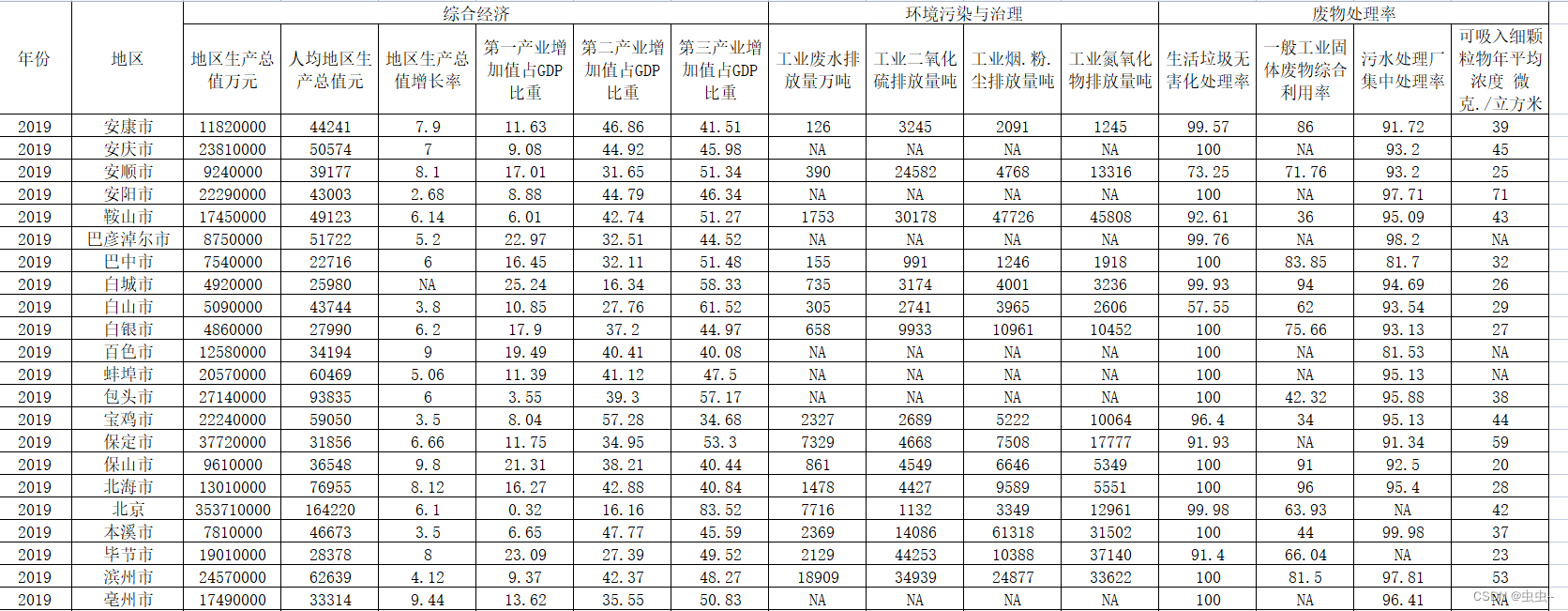
重分区函数
如何对RDD中分区数目进行调整(增加分区或减少分区),在RDD函数中主要有如下三个函数。
1)、增加分区函数
函数名称:repartition,此函数使用的谨慎,会产生Shuffle。

2)、减少分区函数
函数名称:coalesce,此函数不会产生Shuffle,当且仅当降低RDD分区数目。
比如RDD的分区数目为10个分区,此时调用rdd.coalesce(12),不会对RDD进行任何操作。

3)、调整分区函数
在PairRDDFunctions(此类专门针对RDD中数据类型为KeyValue对提供函数)工具类中
partitionBy函数:

范例演示代码,适当使用函数调整RDD分区数目:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD中分区函数,调整RDD分区数目,可以增加分区和减少分区
*/
object SparkPartitionTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 读取本地文件系统文本文件数据
val datasRDD: RDD[String] = sc.textFile("datas/wordcount/wordcount.data", minPartitions = 2)
// TODO: 增加RDD分区数
val etlRDD: RDD[String] = datasRDD.repartition(3)
println(s"EtlRDD 分区数目 = ${etlRDD.getNumPartitions}")
// 词频统计
val resultRDD: RDD[(String, Int)] = etlRDD
// 数据分析,考虑过滤脏数据
.filter(line => null != line && line.trim.length > 0)
// 分割单词,注意去除左右空格
.flatMap(line => line.trim.split("\\s+"))
// 转换为二元组,表示单词出现一次
.mapPartitions{iter =>
iter.map(word => (word, 1))
}
// 分组聚合,按照Key单词
.reduceByKey((tmp, item) => tmp + item)
// 输出结果RDD
resultRDD
// TODO: 对结果RDD降低分区数目
.coalesce(1)
.foreachPartition(iter => iter.foreach(println))
// 应用程序运行结束,关闭资源
sc.stop()
}
}
在实际开发中,什么时候适当调整RDD的分区数目呢?让程序性能更好好呢????
第一点:增加分区数目
- 当处理的数据很多的时候,可以考虑增加RDD的分区数目

第二点:减少分区数目
- 其一:当对RDD数据进行过滤操作(filter函数)后,考虑是否降低RDD分区数目

- 其二:当对结果RDD存储到外部系统

聚合函数
在数据分析领域中,对数据聚合操作是最为关键的,在Spark框架中各个模块使用时,主要就是其中聚合函数的使用。
集合中聚合函数
回顾列表List中reduce聚合函数核心概念:聚合的时候,往往需要聚合中间临时变量。查看列表List中聚合函数reduce和fold源码如下:

通过代码,看看列表List中聚合函数使用:

运行截图如下所示:

fold聚合函数,比reduce聚合函数,多提供一个可以初始化聚合中间临时变量的值参数:

聚合操作时,往往聚合过程中需要中间临时变量(到底时几个变量,具体业务而定),如下案例:

RDD 中聚合函数
在RDD中提供类似列表List中聚合函数reduce和fold,查看如下:

案例演示:求列表List中元素之和,RDD中分区数目为2,核心业务代码如下:

运行原理分析:

使用RDD中fold聚合函数:

查看RDD中高级聚合函数aggregate,函数声明如下:

业务需求:使用aggregate函数实现RDD中最大的两个数据,分析如下:

核心业务代码如下:

运行结果原理剖析示意图:

上述完整范例演示代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
/**
* RDD中聚合函数:reduce、aggregate函数
*/
object SparkAggTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 模拟数据,1 到 10 的列表,通过并行方式创建RDD
val datas = 1 to 10
val datasRDD: RDD[Int] = sc.parallelize(datas, numSlices = 2)
// 查看每个分区中的数据
datasRDD.foreachPartition{iter =>
println(s"p-${TaskContext.getPartitionId()}: ${iter.mkString(", ")}")
}
println("=========================================")
// 使用reduce函数聚合
val result: Int = datasRDD.reduce((tmp, item) => {
println(s"p-${TaskContext.getPartitionId()}: tmp = $tmp, item = $item")
tmp + item
})
println(result)
println("=========================================")
// 使用fold函数聚合
val result2: Int = datasRDD.fold(0)((tmp, item) => {
println(s"p-${TaskContext.getPartitionId()}: tmp = $tmp, item = $item")
tmp + item
})
println(result2)
println("=========================================")
// 使用aggregate函数获取最大的两个值
val top2: mutable.Seq[Int] = datasRDD.aggregate(new ListBuffer[Int]())(
// 分区内聚合函数,每个分区内数据如何聚合 seqOp: (U, T) => U,
(u, t) => {
println(s"p-${TaskContext.getPartitionId()}: u = $u, t = $t")
// 将元素加入到列表中
u += t //
// 降序排序
val top = u.sorted.takeRight(2)
// 返回
top
},
// 分区间聚合函数,每个分区聚合的结果如何聚合 combOp: (U, U) => U
(u1, u2) => {
println(s"p-${TaskContext.getPartitionId()}: u1 = $u1, u2 = $u2")
u1 ++= u2 // 将列表的数据合并,到u1中
//
u1.sorted.takeRight(2)
}
)
println(top2)
// 应用程序运行结束,关闭资源
sc.stop()
}
}
PairRDDFunctions 聚合函数
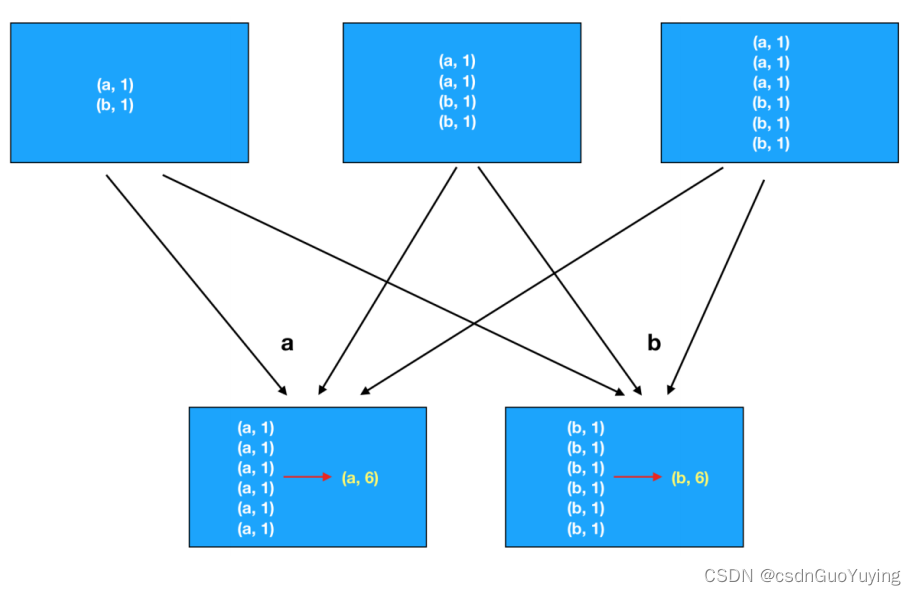
在Spark中有一个object对象PairRDDFunctions,主要针对RDD的数据类型是Key/Value对的数据提供函数,方便数据分析处理。比如使用过的函数:reduceByKey、groupByKey等。*ByKey函数:将相同Key的Value进行聚合操作的,省去先分组再聚合。
第一类:分组函数groupByKey

第二类:分组聚合函数reduceByKey和foldByKey

但是reduceByKey和foldByKey聚合以后的结果数据类型与RDD中Value的数据类型是一样的。
第三类:分组聚合函数aggregateByKey

在企业中如果对数据聚合使用,不能使用reduceByKey完成时,考虑使用aggregateByKey函数,基本上都能完成任意聚合功能。
演示范例代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* RDD中聚合函数,针对RDD中数据类型Key/Value对:
* groupByKey
* reduceByKey/foldByKey
* aggregateByKey
* combineByKey
*/
object SparkAggByKeyTest {
def main(args: Array[String]): Unit = {
// 创建应用程序入口SparkContext实例对象
val sc: SparkContext = {
// 1.a 创建SparkConf对象,设置应用的配置信息
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 1.b 传递SparkConf对象,构建Context实例
new SparkContext(sparkConf)
}
sc.setLogLevel("WARN")
// 1、并行化集合创建RDD数据集
val linesSeq: Seq[String] = Seq(
"hadoop scala hive spark scala sql sql", //
"hadoop scala spark hdfs hive spark", //
"spark hdfs spark hdfs scala hive spark" //
)
val inputRDD: RDD[String] = sc.parallelize(linesSeq, numSlices = 2)
// 2、分割单词,转换为二元组
val wordsRDD: RDD[(String, Int)] = inputRDD
.flatMap(line => line.split("\\s+"))
.map(word => word -> 1)
// TODO: 先使用groupByKey函数分组,再使用map函数聚合
val wordsGroupRDD: RDD[(String, Iterable[Int])] = wordsRDD.groupByKey()
val resultRDD: RDD[(String, Int)] = wordsGroupRDD.map{ case (word, values) =>
val count: Int = values.sum
word -> count
}
println(resultRDD.collectAsMap())
// TODO: 直接使用reduceByKey或foldByKey分组聚合
val resultRDD2: RDD[(String, Int)] = wordsRDD.reduceByKey((tmp, item) => tmp + item)
println(resultRDD2.collectAsMap())
val resultRDD3 = wordsRDD.foldByKey(0)((tmp, item) => tmp + item)
println(resultRDD3.collectAsMap())
// TODO: 使用aggregateByKey聚合
/*
def aggregateByKey[U: ClassTag]
(zeroValue: U) // 聚合中间临时变量初始值,类似fold函数zeroValue
(
seqOp: (U, V) => U, // 各个分区内数据聚合操作函数
combOp: (U, U) => U // 分区间聚合结果的聚合操作函数
): RDD[(K, U)]
*/
val resultRDD4 = wordsRDD.aggregateByKey(0)(
(tmp: Int, item: Int) => {
tmp + item
},
(tmp: Int, result: Int) => {
tmp + result
}
)
println(resultRDD4.collectAsMap())
// 应用程序运行结束,关闭资源
Thread.sleep(1000000)
sc.stop()
}
}
面试题
RDD中groupByKey和reduceByKey区别???
- reduceByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。

- groupByKey函数:在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的函数,将相同key的值聚合到一起,与reduceByKey的区别是只生成一个sequence。