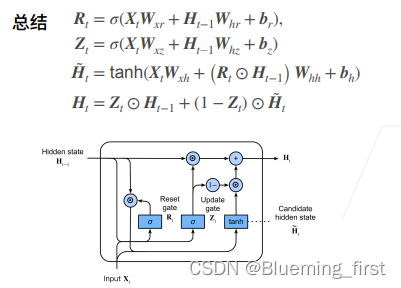
背景说明:
Mysql调优,是大家日常常见的调优工作。
所以,Mysql调优是一个非常、非常核心的面试知识点。
在40岁老架构师 尼恩的读者交流群(50+)中,其相关面试题是一个非常、非常高频的交流话题。
近段时间,有小伙伴面试滴滴,说遇到一个order by 调优的面试题:
order by 线上的查询速度太慢, 需要优化10倍以上, 说说你的思路?
社群中,还遇到过大概的变种:
形式1:order by 是怎么实现排序的?
形式2:order by 是怎么实现优化的?
形式3: 后面的变种,应该有很多变种…,会收入 《尼恩Java面试宝典》。
这里尼恩给大家order by 调优,做一下系统化、体系化的梳理,使得大家可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”。
也一并把这个 题目以及参考答案,收入咱们的《尼恩Java面试宝典》,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
回答这个order by的优化之前,首先要给面试官介绍一下order by的底层原理。
首先、什么是Order by 工作原理?
假设,有一个用户表为例,表结构如下:
create table `user` (
`id` int(11) not null auto_increment COMMENT 'id',
`city` varchar(16) not null COMMENT '城市',
`name` varchar(16) not null COMMENT '姓名',
`age` int(11) not null COMMENT '年龄',
`sex` int(1) default 1 COMMENT '性别',
primary key (`id`),
key `city` (`city`)
) engine = InnoDB comment '用户表';
表数据示例如下:

现在假定有个需求:查询前 5 个来自北京的用户姓名、年龄、城市,并且按照年龄升序排序。
那么相应的 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;
这条 SQL 语句逻辑简单清晰,要点有3个:
- city = ‘北京’ :有where 查询条件
- order by age :根据 age 排序,默认是asc
- limit 5 :取得 top5
那么 mysql 底层是如何执行的呢?
首先,给大家介绍一下宏观的思路。
Order by 执行的两步
总体来说,Order by 执行流程,分为两步,具体如下:

第1步:索引的查找
根据where 后面的字段,进行 二级索引的查找,找到后再回表 聚集索引,拿到需要的字段
第2步:原始数据的排序
原始数据的数据, 并不是按照 order by 有序的。
所以,需要按照 order by 字段,进行排序。
接下来,排序的地点在哪里呢?
- 优先选择内存。因为内存的性能高。
- 如果原始的数据实在规模太大,就借助磁盘进行排序。
用于排序的内存,称为 sort_buffer。其实 MySQL 会给每个线程分配一块内存用于排序的 sort_buffer。
了解了整个步骤后,开始来看看执行计划。
然后再看怎么优化。
Explain查看执行计划
我们先用Explain关键字查看一下执行计划。
那么相应的 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;

可以看到:
- key 字段表示使用到 city 索引,
- Extra 字段中的
Using index condition表示用到了索引条件, Using filesort表示用到了文件排序 。
用到文件排序,说明第一次查出来的 原始数据,在内存放不下, 需要借助 磁盘空间进行排序,
磁盘IO的性能比较低的,所以,需要进行调优。
再调优之前,首先图解一下order
图解一下Order by 执行的两步
第1步:索引的查找
根据where 后面的字段,进行 二级索引的查找,找到后再回表 聚集索引,拿到需要的字段
回顾 SQL 如下:
select name, age, city from user where city = '北京' order by age limit 5;
首先从 二级索引city 索引树 的查找 city = ‘北京’ 的索引叶子。
在 city 索引树中是非聚簇索引树,叶子节点存储的是主键 ID。city 索引树 如下:

聚簇索引树的叶子节点则存放的是每行数据,如下图:
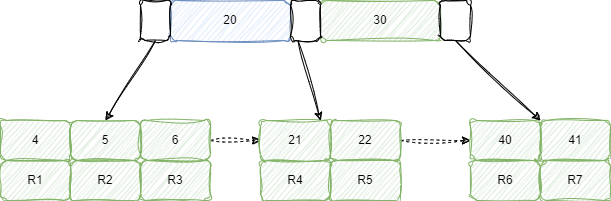
查询语句的执行流程就是先通过 city 索引树,找到对应的主键 ID,然后再搜索主键索引树,找到对应的行数据。
这些数据是原始数据,放在内存 sort_buffer 中。

第2步:原始数据的排序
原始数据的数据, 并不是按照 order by 有序的。 所以,需要按照 order by 字段,进行排序。
加上order by排序之后,整体的执行流程就是:

Order by 执行完整流程,如下:
- 当前线程首先初始化 sort_buffer 块,
- 然后从 city 索引树从查询一条满足
city='北京'的主键 ID, 比如图中的id=2, - 接着在聚簇索引树中查询
id=2的一行数据,将name、age、city三个字段的值,存到sort_buffer, - 继续重复前两个步骤,直到 city 索引树中找不到
city='北京'的主键 ID。 - 最后在sort_buffer中,将所有数据根据
age进行排序,取前 5 行返回给客户端。
全字段排序就是将查询所需的字段,如name、age、city三个字段数据全部存到 sort_buffer 中。
3个核心概念
接下来开始给面试官介绍如何调优。
不过不急,调优涉及到3个核心概念
- 全字段排序
- 外部排序
- rowid 排序
全字段排序
sort_buffer是 MySQL 为每个任务线程维护的一块内存区域,用于进行排序。
sort_buffer 的大小可以通过 sort_buffer_size 来设置。
那这种处理方式会存在一个问题, sort_buffer 是一块固定大小的内存,如果数据量太大,sort_buffer 放不下怎么办呢?
sort_buffer_size 是一个用于控制sort_buffer内存大小的参数。
外部排序
如果要排序的数据小于 sort_buffer_size,那在 sort_buffer 内存中就可以完成排序,如果要排序的数据大于 sort_buffer_size,则需要外部排序,借助磁盘文件来进行排序。
通过执行一下命令,可以查看 SQL 语句执行中是否采用了磁盘文件辅助排序。
set optimizer_trace = "enabled=on";
select name,age,city from user where city = '北京' order by age limit 5;
select * from information_schema.optimizer_trace;
可以从number_of_tmp_files中看出,是否使用了临时文件。
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`user`",
"field": "age"
}
],
"filesort_priority_queue_optimization": {
"limit": 5,
"rows_estimate": 992,
"row_size": 112,
"memory_available": 262144,
"chosen": true
},
"filesort_execution": [
],
"filesort_summary": {
"rows": 3,
"examined_rows": 28,
"number_of_tmp_files": 0,
"sort_buffer_size": 720,
"sort_mode": "<sort_key, additional_fields>"
}
}
]
}
}
number_of_tmp_files 表示使用来排序的磁盘临时文件数。如果 number_of_tmp_files>0,则表示使用了磁盘文件来进行排序。
使用了磁盘临时文件后,当 sort_buffer 内存不足时,先进行排序,将排序后的数据存放到一个小磁盘文件中,清空 sort_buffer。
然后继续存放数据到 sort_buffer,重复以上步骤。最后将多个磁盘小文件合并成一个有序的大文件。
Tips: 磁盘小文件合并排序,使用的是归并排序算法
这样依然会存在问题,数据存放到临时磁盘小文件,然后还需要归并排序为大文件,再读入到内存中,返回结果集,整体排序效率低下。
rowid 排序
要解决上述问题,可以将只需要用于排序的字段和主键 ID 放入 sort_buffer 中,也就是 rowid 排序,这样就可以在 sort_buffer 中完成排序。
max_length_for_sort_data 是一个用于表示 Mysql 用于排序行数据长度的一个参数,如果单行数据的长度超过了这个值,那么可能会导致采用临时文件排序,mysql 会换用 rowid 排序。
可以通过命令看下这个参数取值。
show variables like 'max_length_for_sort_data';

max_length_for_sort_data 默认值是 1024。本文中name,age,city 长度=64+4+64=132<1024, 所以走的是全字段排序。
我们执行以下命令,改下参数值,再重新执行 SQL。
set max_length_for_sort_data = 32;
select name,age,city from user where city = '北京' order by age limit 5;
使用 rowid 排序的后,执行示意图如下:

对比全字段排序,rowid 排序最后需要根据主键 ID 获取对应字段数据即多了回表查询。
当需要查询的数据在索引树中不存在的时候,需要再次到聚集索引中去获取,这个过程叫做回表
我们通过执行以下命令,可以看到是否使用了 rowid 排序的:
set optimizer_trace = "enabled=on";
select name,age,city from user where city = '北京' order by age limit 5;
select * from information_schema.optimizer_trace;
{
"join_execution": {
"select#": 1,
"steps": [
{
"filesort_information": [
{
"direction": "asc",
"table": "`user`",
"field": "age"
}
],
"filesort_priority_queue_optimization": {
"limit": 5,
"rows_estimate": 992,
"row_size": 8,
"memory_available": 262144,
"chosen": true
},
"filesort_execution": [],
"filesort_summary": {
"rows": 3,
"examined_rows": 28,
"number_of_tmp_files": 0,
"sort_buffer_size": 96,
"sort_mode": "<sort_key, rowid>"
}
}
]
}
}
sort_mode表示排序模式为 rowid 排序。
order by 的优化思路
重点来了
如何调优呢?两大措施:
-
联合索引优化
如果数据本身是有序的,那就不需要排序,而索引数据本身是有序的,所以,我们可以通过建立联合索引,跳过排序步骤。
-
参数优化
可以通过调整max_length_for_sort_data等参数优化排序算法;
联合索引
基于查询条件和排序条件,给表加个联合索引idx_city_age。然后再查看执行计划:
alter table user add index idx_city_age(city,age);
explain select name,age,city from user where city = '北京' order by age limit 5;

从执行计划Extra字段中可以发现没有再使用Using filesort排序,keys使用了idx_city_age索引。
idx_city_age联合索引示意图,如下:

整个 SQL 执行流程图如下所示:

任务线程从idx_city_age索引树中可以有序的获取满足条件的主键 ID, 然后根据主键 ID 查询对应字段数据,不需要在 sort_buffer 中排序了。
从示意图看来,还是有一次回表操作,那可以通过覆盖索引来解决,给city,name,age 组成一个联合索引,省去回表操作。
覆盖索引是 select 的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖。
参数优化
通过调整参数,也可以优化order by的执行。
- 调整 sort_buffer_size 参数的值。如果 sort_buffer 值太小而数据量大的话,MySQL 会采用磁盘临时文件辅助排序。MySQL 服务器配置高的情况下,可以将参数调大些。
- 调整 max_length_for_sort_data 的值,值太小的话 MySQL 会采用 rowid 排序,会多一次回表操作导致查询性能降低。同样可以适当调大些。
推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》## 推荐阅读:
《网易二面:CPU狂飙900%,该怎么处理?》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《场景题:假设10W人突访,你的系统如何做到不 雪崩?》
《2个大厂 100亿级 超大流量 红包 架构方案》
《Nginx面试题(史上最全 + 持续更新)》
《K8S面试题(史上最全 + 持续更新)》
《操作系统面试题(史上最全、持续更新)》
《Docker面试题(史上最全 + 持续更新)》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《Flux、Mono、Reactor 实战(史上最全)》
《sentinel (史上最全)》
《Nacos (史上最全)》
《TCP协议详解 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《nacos高可用(图解+秒懂+史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《单例模式(史上最全)》
《红黑树( 图解 + 秒懂 + 史上最全)》
《分布式事务 (秒懂)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《缓存之王:Caffeine 的使用(史上最全)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Docker原理(图解+秒懂+史上最全)》
《Redis分布式锁(图解 - 秒懂 - 史上最全)》
《Zookeeper 分布式锁 - 图解 - 秒懂》
《Zookeeper Curator 事件监听 - 10分钟看懂》
《Netty 粘包 拆包 | 史上最全解读》
《Netty 100万级高并发服务器配置》
《Springcloud 高并发 配置 (一文全懂)》

![[Android]网络框架之Retrofit(kotlin)](https://img-blog.csdnimg.cn/d854e138f623498d92d2c8410b8c21e9.png)





![13薪|运营策划[北京市 - 海淀区]-10k-15k](https://img-blog.csdnimg.cn/img_convert/c95fb7c6e276026b1effa861ca04622f.jpeg)