AWS Dynamodb简介
- Amazon DynamoDB 是一种完全托管式、无服务器的 NoSQL 键值数据库,旨在运行任何规模的高性能应用程序。
- DynamoDB能在任何规模下实现不到10毫秒级的一致响应,并且它的存储空间无限,可在任何规模提供可靠的性能。
- DynamoDB 提供内置安全性、连续备份、自动多区域复制、内存缓存和数据导出工具。
Redshift简介
- Amazon Redshift是一个快速、功能强大、完全托管的PB级别数据仓库服务。用户可以在刚开始使用几百GB的数据,然后在后期扩容到PB级别的数据容量。
- Redshift是一种联机分析处理OLAP(Online Analytics Processing)的类型,支持复杂的分析操作,侧重决策支持,并且能提供直观易懂的查询结果。
资源准备
VPC
- vpc
- cird block: 10.10.0.0/16
- internet gateway
- elastic ip address
- nat gateway:使用elastic ip address作为public ip
- public subnet
- 三个Availability Zone
- private subnet
- 三个Availability Zone
- public route table:public subnet关联的route table
- destination: 0.0.0.0/0 target: internet-gateway-id(允许与外界进行通信)
- destination:10.10.0.0/16 local(内部通信)
- private route table:private subnet关联的route table
- destination:10.10.0.0/16 local(内部通信)
- destination: 0.0.0.0/0 target: nat-gateway-id(允许内部访问外界)
- web server security group
- 允许任意ip对443端口进行访问
- 允许自己的ipdui22端口进行访问,以便ssh到服务器上向数据库插入数据
- glue redshift connection security group
- 只包含一条self-referencing rule ,允许同一个security group对所有tcp端口进行访
- 创建Glue connection时需要使用该security group:
- Reference: glue connection security group must have a self-referencing rule to allow to allow AWS Glue components to communicate. Specifically, add or confirm that there is a rule of Type All TCP, Protocol is TCP, Port Range includes all ports, and whose Source is the same security group name as the Group ID.
- private redshift security group
- 允许vpc内部(10.10.0.0/24)对5439端口进行访问
- 允许glue connection security group对5439端口进行访问
- public redshift security group
- 允许vpc内部(10.10.0.0/24)对5439端口进行访问
- 允许kenisis firehose所在region的public ip 对5439端口进行访问
-
13.58.135.96/27for US East (Ohio) -
52.70.63.192/27for US East (N. Virginia) -
13.57.135.192/27for US West (N. California) -
52.89.255.224/27for US West (Oregon) -
18.253.138.96/27for AWS GovCloud (US-East) -
52.61.204.160/27for AWS GovCloud (US-West) -
35.183.92.128/27for Canada (Central) -
18.162.221.32/27for Asia Pacific (Hong Kong) -
13.232.67.32/27for Asia Pacific (Mumbai) -
13.209.1.64/27for Asia Pacific (Seoul) -
13.228.64.192/27for Asia Pacific (Singapore) -
13.210.67.224/27for Asia Pacific (Sydney) -
13.113.196.224/27for Asia Pacific (Tokyo) -
52.81.151.32/27for China (Beijing) -
161.189.23.64/27for China (Ningxia) -
35.158.127.160/27for Europe (Frankfurt) -
52.19.239.192/27for Europe (Ireland) -
18.130.1.96/27for Europe (London) -
35.180.1.96/27for Europe (Paris) -
13.53.63.224/27for Europe (Stockholm) -
15.185.91.0/27for Middle East (Bahrain) -
18.228.1.128/27for South America (São Paulo) -
15.161.135.128/27for Europe (Milan) -
13.244.121.224/27for Africa (Cape Town) -
13.208.177.192/27for Asia Pacific (Osaka) -
108.136.221.64/27for Asia Pacific (Jakarta) -
3.28.159.32/27for Middle East (UAE) -
18.100.71.96/27for Europe (Spain) -
16.62.183.32/27for Europe (Zurich) -
18.60.192.128/27for Asia Pacific (Hyderabad)
-
VPC全部资源的serverless文件:
- custom:bucketNamePrefix 替换为自己的创建的bucket
-
service: dynamodb-to-redshift-vpc custom: bucketNamePrefix: "jessica" provider: name: aws region: ${opt:region, "ap-southeast-1"} stackName: ${self:service} deploymentBucket: name: com.${self:custom.bucketNamePrefix}.deploy-bucket serverSideEncryption: AES256 resources: Parameters: VpcName: Type: String Default: "test-vpc" Resources: VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: "10.10.0.0/16" EnableDnsSupport: true EnableDnsHostnames: true InstanceTenancy: default Tags: - Key: Name Value: !Sub "VPC_${VpcName}" # Internet Gateway InternetGateway: Type: "AWS::EC2::InternetGateway" Properties: Tags: - Key: Name Value: !Sub "VPC_${VpcName}_InternetGateway" VPCGatewayAttachment: Type: "AWS::EC2::VPCGatewayAttachment" Properties: VpcId: !Ref VPC InternetGatewayId: !Ref InternetGateway # web server security group WebServerSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Allow access from public VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: "0.0.0.0/0" Tags: - Key: Name Value: !Sub "VPC_${VpcName}_WebServerSecurityGroup" # public route table RouteTablePublic: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_RouteTablePublic" RouteTablePublicInternetRoute: Type: "AWS::EC2::Route" DependsOn: VPCGatewayAttachment Properties: RouteTableId: !Ref RouteTablePublic DestinationCidrBlock: "0.0.0.0/0" GatewayId: !Ref InternetGateway # public subnet SubnetAPublic: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [0, !GetAZs ""] CidrBlock: "10.10.0.0/24" MapPublicIpOnLaunch: true VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetAPublic" RouteTableAssociationAPublic: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetAPublic RouteTableId: !Ref RouteTablePublic SubnetBPublic: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [1, !GetAZs ""] CidrBlock: "10.10.32.0/24" MapPublicIpOnLaunch: true VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetBPublic" RouteTableAssociationBPublic: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetBPublic RouteTableId: !Ref RouteTablePublic SubnetCPublic: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [2, !GetAZs ""] CidrBlock: "10.10.64.0/24" MapPublicIpOnLaunch: true VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetCPublic" RouteTableAssociationCPublic: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetCPublic RouteTableId: !Ref RouteTablePublic # redshift security group PrivateRedshiftSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Allow access from inside vpc VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 5439 ToPort: 5439 CidrIp: 10.10.0.0/24 - IpProtocol: tcp FromPort: 5439 ToPort: 5439 SourceSecurityGroupId: !GetAtt GlueRedshiftConnectionSecurityGroup.GroupId Tags: - Key: Name Value: !Sub "VPC_${VpcName}_PrivateRedshiftSecurityGroup" # redshift security group PublicRedshiftSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Allow access from inside vpc and Kinesis Data Firehose CIDR block VpcId: !Ref VPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 5439 ToPort: 5439 CidrIp: 10.10.0.0/24 - IpProtocol: tcp FromPort: 5439 ToPort: 5439 CidrIp: 13.228.64.192/27 Tags: - Key: Name Value: !Sub "VPC_${VpcName}_PublicRedshiftSecurityGroup" GlueRedshiftConnectionSecurityGroup: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Allow self referring for all tcp ports VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_GlueRedshiftConnectionSecurityGroup" GlueRedshiftConnectionSecurityGroupSelfReferringInboundRule: Type: "AWS::EC2::SecurityGroupIngress" Properties: GroupId: !GetAtt GlueRedshiftConnectionSecurityGroup.GroupId IpProtocol: tcp FromPort: 0 ToPort: 65535 SourceSecurityGroupId: !GetAtt GlueRedshiftConnectionSecurityGroup.GroupId SourceSecurityGroupOwnerId: !Sub "${aws:accountId}" # nat gateway EIP: Type: "AWS::EC2::EIP" Properties: Domain: vpc NatGateway: Type: "AWS::EC2::NatGateway" Properties: AllocationId: !GetAtt "EIP.AllocationId" SubnetId: !Ref SubnetAPublic # private route table RouteTablePrivate: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_RouteTablePrivate" RouteTablePrivateRoute: Type: "AWS::EC2::Route" Properties: RouteTableId: !Ref RouteTablePrivate DestinationCidrBlock: "0.0.0.0/0" NatGatewayId: !Ref NatGateway # private subnet SubnetAPrivate: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [0, !GetAZs ""] CidrBlock: "10.10.16.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetAPrivate" RouteTableAssociationAPrivate: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetAPrivate RouteTableId: !Ref RouteTablePrivate SubnetBPrivate: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [1, !GetAZs ""] CidrBlock: "10.10.48.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetBPrivate" RouteTableAssociationBPrivate: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetBPrivate RouteTableId: !Ref RouteTablePrivate SubnetCPrivate: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Select [2, !GetAZs ""] CidrBlock: "10.10.80.0/24" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "VPC_${VpcName}_SubnetCPrivate" RouteTableAssociationCPrivate: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref SubnetCPrivate RouteTableId: !Ref RouteTablePrivate Outputs: VPC: Description: "VPC." Value: !Ref VPC Export: Name: !Sub "${self:provider.stackName}" SubnetsPublic: Description: "Subnets public." Value: !Join [ ",", [!Ref SubnetAPublic, !Ref SubnetBPublic, !Ref SubnetCPublic], ] Export: Name: !Sub "${self:provider.stackName}-PublicSubnets" SubnetsPrivate: Description: "Subnets private." Value: !Join [ ",", [!Ref SubnetAPrivate, !Ref SubnetBPrivate, !Ref SubnetCPrivate], ] Export: Name: !Sub "${self:provider.stackName}-PrivateSubnets" DefaultSecurityGroup: Description: "VPC Default Security Group" Value: !GetAtt VPC.DefaultSecurityGroup Export: Name: !Sub "${self:provider.stackName}-DefaultSecurityGroup" WebServerSecurityGroup: Description: "VPC Web Server Security Group" Value: !Ref WebServerSecurityGroup Export: Name: !Sub "${self:provider.stackName}-WebServerSecurityGroup" PrivateRedshiftSecurityGroup: Description: "The id of the RedshiftSecurityGroup" Value: !Ref PrivateRedshiftSecurityGroup Export: Name: !Sub "${self:provider.stackName}-PrivateRedshiftSecurityGroup" PublicRedshiftSecurityGroup: Description: "The id of the RedshiftSecurityGroup" Value: !Ref PublicRedshiftSecurityGroup Export: Name: !Sub "${self:provider.stackName}-PublicRedshiftSecurityGroup" GlueRedshiftConnectionSecurityGroup: Description: "The id of the self referring security group" Value: !Ref GlueRedshiftConnectionSecurityGroup Export: Name: !Sub "${self:provider.stackName}-GlueSelfRefringSecurityGroup"
Redshift Cluster
- Private Cluster subnet group
- 创建一个包含private subnet的private subnet group
- Private Cluster:用于测试glue job同步数据到redshift,PubliclyAccessible必须设为false,否则glue job无法连接
- ClusterSubnetGroupName
- 使用private subnet group
- VpcSecurityGroupIds
- 使用private redshift security group
- NodeType: dc2.large
- ClusterType: single-node
-
PubliclyAccessible: false
- ClusterSubnetGroupName
- Public Cluster subnet group
- 创建一个包含public subnet的public subnet group
- Public Cluster:用于测试glue job同步数据到redshift,PubliclyAccessible必须设为true,且security group允许kinesis firehose public ip对5439端口进行访问,否则firehose无法连接到redshift
- ClusterSubnetGroupName
- 使用public subnet group
- VpcSecurityGroupIds
- 使用public redshift security group
- NodeType: dc2.large
- ClusterType: single-node
- PubliclyAccessible: true
- ClusterSubnetGroupName
redshift全部资源的serverless文件:
- custom:bucketNamePrefix 替换为自己的创建的bucket
-
service: dynamodb-to-redshift-redshift custom: bucketNamePrefix: "jessica" provider: name: aws region: ${opt:region, "ap-southeast-1"} stackName: ${self:service} deploymentBucket: name: com.${self:custom.bucketNamePrefix}.deploy-bucket serverSideEncryption: AES256 resources: Parameters: ServiceName: Type: String Default: dynamodb-to-redshift Resources: PrivateClusterSubnetGroup: Type: "AWS::Redshift::ClusterSubnetGroup" Properties: Description: Private Cluster Subnet Group SubnetIds: Fn::Split: - "," - Fn::ImportValue: !Sub ${ServiceName}-vpc-PrivateSubnets Tags: - Key: Name Value: private-subnet PrivateCluster: Type: "AWS::Redshift::Cluster" Properties: ClusterIdentifier: test-data-sync-redshift ClusterSubnetGroupName: !Ref ClusterSubnetGroup VpcSecurityGroupIds: - Fn::ImportValue: !Sub ${ServiceName}-vpc-PrivateRedshiftSecurityGroup DBName: dev MasterUsername: admin MasterUserPassword: Redshift_admin_2022 NodeType: dc2.large ClusterType: single-node PubliclyAccessible: false PublicClusterSubnetGroup: Type: "AWS::Redshift::ClusterSubnetGroup" Properties: Description: Public Cluster Subnet Group SubnetIds: Fn::Split: - "," - Fn::ImportValue: !Sub ${ServiceName}-vpc-PublicSubnets Tags: - Key: Name Value: public-subnet PublicCluster: Type: "AWS::Redshift::Cluster" Properties: ClusterIdentifier: test-data-sync-redshift-public ClusterSubnetGroupName: !Ref PublicClusterSubnetGroup VpcSecurityGroupIds: - Fn::ImportValue: !Sub ${ServiceName}-vpc-PublicRedshiftSecurityGroup DBName: dev MasterUsername: admin MasterUserPassword: Redshift_admin_2022 NodeType: dc2.large ClusterType: single-node PubliclyAccessible: true Outputs: PrivateRedshiftEndpoint: Description: "Redshift endpoint" Value: !GetAtt Cluster.Endpoint.Address Export: Name: !Sub "${self:provider.stackName}-PrivateRedshiftEndpoint" PrivateRedshiftPort: Description: "Redshift port" Value: !GetAtt Cluster.Endpoint.Port Export: Name: !Sub "${self:provider.stackName}-PrivateRedshiftPort" PublicRedshiftEndpoint: Description: "Public Redshift endpoint" Value: !GetAtt PublicCluster.Endpoint.Address Export: Name: !Sub "${self:provider.stackName}-PublicRedshiftEndpoint" PublicRedshiftPort: Description: "Public Redshift port" Value: !GetAtt PublicCluster.Endpoint.Port Export: Name: !Sub "${self:provider.stackName}-PublicRedshiftPort"
使用AWS Glue ETL Job进行同步
适用场景
- 一次性整表同步
- 对于典型的时间序列数据(当前的数据写入和读取频率高,越老的数据读写频率越低),通常会采用为每个时间段(每天)创建一张表的方式来合理的分配WCU和RCU。
- 如果在当时时间段结束之后,需要对该时间段内的所有数据进行复杂的分析操作,则需要将dynamodb的整表同步到redshift
架构
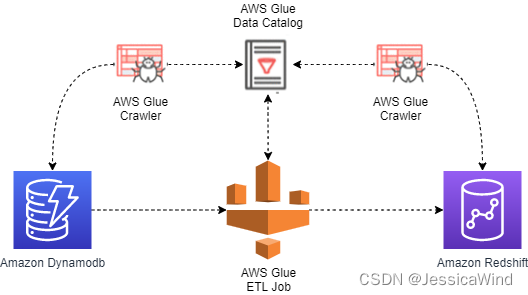
优点
- 使用AWS Glue Crawler可以自动管理源表和目标表的scheme,在Glue Job script中可以省去mapping的过程,Glue Job script代码易维护
资源部署
- Dynamodb table: 源数据表
- IAM role for glue crawler,crawler需要连接dynamodb和redshift的权限以读取表的scheme
- Dynamodb glue catalog database:用于存储crawler生成的dynamodb table scheme
- Redshift glue catalog database:用于存储crawler生成的redshift table scheme
- Dynamodb glue crawler:用于读取dynamodb表,生成对应的dynamodb table scheme
- Redshift glue crawler:用于读取redshift表,生成对应的redshift table scheme
- Glue connection:glue job连接redshift需要用到的connection
- IAM role for glue job:Glue job需要
- S3 bucket for glue job
- glue job
如何部署:
-
sls deploy -c glue-etl.yml #replace ${bucketNamePrefix} to your own glue bucket name crate in glue-etl.yml aws s3 cp dynamodb-to-redshift.py s3://com.${bucketNamePrefix}.glue-temp-bucket/script/
部署文件:glue-etl.yml
-
service: dynamodb-to-redshift-glue-etl custom: bucketNamePrefix: "jessica" provider: name: aws region: ${opt:region, "ap-southeast-1"} stackName: ${self:service} deploymentBucket: name: com.${self:custom.bucketNamePrefix}.deploy-bucket serverSideEncryption: AES256 resources: Parameters: DynamodbTableName: Type: String Default: "TestSyncToRedshift" ServiceName: Type: String Default: dynamodb-to-redshift GlueBucketName: Type: String Default: com.${self:custom.bucketNamePrefix}.glue-etl-temp-bucket Resources: TestTable: Type: AWS::DynamoDB::Table Properties: TableName: !Sub ${DynamodbTableName} BillingMode: PAY_PER_REQUEST AttributeDefinitions: - AttributeName: pk AttributeType: S - AttributeName: sk AttributeType: S KeySchema: - AttributeName: pk KeyType: HASH - AttributeName: sk KeyType: RANGE CrawlerRole: Type: AWS::IAM::Role Properties: RoleName: CrawlerRole AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "glue.amazonaws.com" Action: - "sts:AssumeRole" ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole - arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess - arn:aws:iam::aws:policy/AmazonRedshiftFullAccess - arn:aws:iam::aws:policy/AmazonS3FullAccess DynamodbDatabase: Type: AWS::Glue::Database Properties: CatalogId: !Ref AWS::AccountId DatabaseInput: Name: "dynamodb-database" DynamodbCrawler: Type: AWS::Glue::Crawler Properties: Name: "dynamodb-crawler" Configuration: Role: !GetAtt CrawlerRole.Arn DatabaseName: !Ref DynamodbDatabase Targets: DynamoDBTargets: - Path: !Sub ${DynamodbTableName} SchemaChangePolicy: UpdateBehavior: "UPDATE_IN_DATABASE" DeleteBehavior: "LOG" Schedule: ScheduleExpression: cron(0/10 * * * ? *) # run every 10 minutes GlueRedshiftConnection: Type: AWS::Glue::Connection Properties: CatalogId: !Sub "${aws:accountId}" ConnectionInput: Name: ${self:service}-redshift-connection ConnectionType: JDBC MatchCriteria: [] PhysicalConnectionRequirements: SecurityGroupIdList: - Fn::ImportValue: !Sub ${ServiceName}-vpc-GlueSelfRefringSecurityGroup SubnetId: Fn::Select: - 1 - Fn::Split: - "," - Fn::ImportValue: !Sub "${ServiceName}-vpc-PrivateSubnets" ConnectionProperties: JDBC_CONNECTION_URL: Fn::Join: - "" - - "jdbc:redshift://" - Fn::ImportValue: !Sub ${ServiceName}-redshift-PrivateRedshiftEndpoint - ":" - Fn::ImportValue: !Sub ${ServiceName}-redshift-PrivateRedshiftPort - "/dev" JDBC_ENFORCE_SSL: false USERNAME: admin PASSWORD: Redshift_admin_2022 RedshiftDatabase: Type: AWS::Glue::Database Properties: CatalogId: !Ref AWS::AccountId DatabaseInput: Name: "redshift-database" RedshiftCrawler: Type: AWS::Glue::Crawler Properties: Name: "redshift-crawler" Configuration: Role: !GetAtt CrawlerRole.Arn DatabaseName: !Ref RedshiftDatabase Targets: JdbcTargets: - ConnectionName: !Ref GlueRedshiftConnection Path: dev/public/test_sync_to_redshift SchemaChangePolicy: UpdateBehavior: "UPDATE_IN_DATABASE" DeleteBehavior: "LOG" RedshiftGlueJobRole: Type: AWS::IAM::Role Properties: RoleName: RedshiftGlueJobRole AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - glue.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSGlueServiceRole - arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess - arn:aws:iam::aws:policy/AmazonRedshiftFullAccess - arn:aws:iam::aws:policy/AmazonS3FullAccess - arn:aws:iam::aws:policy/CloudWatchLogsFullAccess GlueTempBucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub ${GlueBucketName} GlueJob: Type: AWS::Glue::Job Properties: Name: dynamodb-to-redshift-glue-etl-job Role: !GetAtt RedshiftGlueJobRole.Arn Command: Name: glueetl ScriptLocation: !Sub "s3://${GlueBucketName}/script/dynamodb-to-redshift.py" PythonVersion: 3 DefaultArguments: --TempDir: !Sub "s3://${GlueBucketName}/tmp/dynamodb-to-redshift/" WorkerType: G.1X NumberOfWorkers: 2 GlueVersion: "3.0" Connections: Connections: - !Ref GlueRedshiftConnection
glue job脚本:dynamodb-to-redshift.py
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
params = [
'JOB_NAME',
'TempDir',
]
args = getResolvedOptions(sys.argv, params)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
DynamoDBtable_node1 = glueContext.create_dynamic_frame.from_catalog(
database="dynamodb-database",
table_name="testsynctoredshift",
transformation_ctx="DynamoDBtable_node1",
)
RedshiftCluster_node2 = glueContext.write_dynamic_frame.from_catalog(
frame=DynamoDBtable_node1,
database="redshift-database",
table_name="dev_public_test_sync_to_redshift",
redshift_tmp_dir=args["TempDir"],
transformation_ctx="RedshiftCluster_node2",
)
job.commit()
测试
-
insert some data to dynamodb table with aws web console first, otherwise, the crawler can not detect the table scheme
2. run dynamodb-crawler, after run success, you can see the database and table in [glue console](https://ap-southeast-1.console.aws.amazon.com/glue/home?region=ap-southeast-1#catalog:tab=tables)
3. create redshift table with [Redshift query editor v2](https://ap-southeast-1.console.aws.amazon.com/sqlworkbench/home?region=ap-southeast-1#/client)
```
CREATE TABLE "public"."test_sync_to_redshift"(pk varchar(200) not null, sk varchar(200) NOT NULL, primary key(pk, sk));
```
4. run redshift-crawler, if encounter no valid connection error, please update password in the redshift-connection manually with aws console, don't know why the password is not correct when deploy with cloudformation. After run success, you can see the database and table in [glue console](https://ap-southeast-1.console.aws.amazon.com/glue/home?region=ap-southeast-1#catalog:tab=tables)
5. run glue etl job, after run success, you can check data in redshift table with [Redshift query editor v2](https://ap-southeast-1.console.aws.amazon.com/sqlworkbench/home?region=ap-southeast-1#/client).
This glue etl job will `insert all data in dynamodb table` to redshift table directly, as for redshift, [primary key, and foreign key constraints are informational only; they are not enforced by Amazon Redshift](https://docs.aws.amazon.com/redshift/latest/dg/t_Defining_constraints.html), so if you run the jon serval times, you will see duplicate data with some primary key in redshift table.
使用AWS Glue Streaming Job进行同步
适用场景
- 持续增量同步
- 表的操作支持插入,更新和删除
架构图
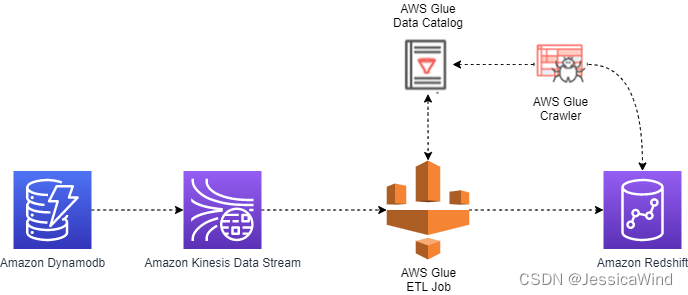
资源部署
- Dynamodb表
- VPC
- Redshift Cluster
- Glue Crawler
- GlueJob
优点
- 可以支持表的插入,更新和删除操作的同步
缺点
使用AWS kinesis Firehose进行同步
适用场景
- 持续增量同步
- 表的操作只支持插入,部分支持更新,不支持删除,比如记录传感器每秒收集的数据,记录网站用户的行为事件
- 由于kinesis firehose是通过Redshift COPY命令与redshift进行集成的,而redshift是不保证primary key的唯一性,对redshift来说,primary key只是提供信息,并没有保证primary key的唯一性,如果在COPY命令的源数据中包含多条primary key相同的数据(比如对一条数据进行多次修改),则会导致redshift表出现多条primary key相同的数据。
- 部分支持更新的意思就是如果多条primary key相同的数据对你的业务逻辑没有影响,那也可以使用AWS kinesis Firehose进行同步,如果多条primary key对业务逻辑有影响,那就不可以使用
- 由于kinesis firehose是通过Redshift COPY命令与redshift进行集成的,COPY命令是不支持删除的
架构图
资源部署
Reference
Setting up networking for development for AWS Glue - AWS Glue