安装部署
下载1:mycat2-install-template-1.21.zip
下载2:mycat2-1.21-release-jar-with-dependencies.jar
解压mycat2-install-template-1.21.zip
unzip mycat2-install-template-1.21.zip把mycat2-1.21-release-jar-with-dependencies.jar放在mycat/lib中
修改mycat/conf/datasources/prototypeDs.datasource.json配置文件
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"Q61@t6Udu8mW",
"type":"JDBC",
"url":"jdbc:mysql://192.168.202.150:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mysteel",
"weight":0
}进入到mycat/bin目录,执行以下命令对文件分配权限
chmod 777 ./*服务启动
./mycat start客户端进行连接

默认的端口是8066,可以在mycat/conf/server.json中修改
默认的用户名密码是root/123456,可以在mycat/conf/user/root.user.json中修改
此时整体架构图为:

配置逻辑库
mycat默认有个集群,在mycat/conf/clusters/prototype.cluster.json中配置
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"prototypeDs"
],
"maxCon":200,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"switchType":"SWITCH"
}默认有两个逻辑库:information_schema,mysql,在mycat/conf/schemas下面配置
当我们在mycat中操作information_schema,mysql逻辑库下面的表时候实际在操作原型库中表
现在让我们来配置新的业务逻辑库(逻辑库的名称要和原型库的名称一致)
在客户端执行:
/*+ mycat:createSchema{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"yc_nacos",
"shardingTables":{},
"targetName":"prototype"
} */;会在mycat/conf/schemas目录下自动创建yc_nacos.schema.json文件,并且自动把逻辑库中的逻辑表和原型库中的真实表进行映射

多数据源整合
创建mysql数据源:
/*+ mycat:createDataSource{
"dbType":"mysql",
"name":"yc-mysql",
"url":"jdbc:mysql://192.168.201.68:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"admin_user",
"password":"mOoBzUHGtqeX"
} */;配置逻辑库:
/*+ mycat:createSchema{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"oem_mysteel",
"shardingTables":{},
"targetName":"yc-mysql"
} */;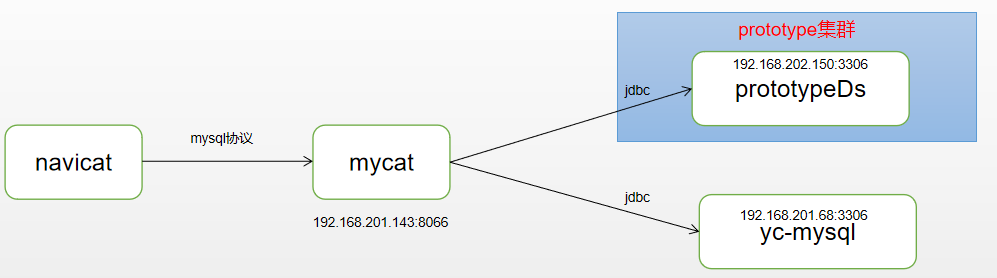

oem_mysteel逻辑库下面的mysteel_data_3逻辑表对应的数据源是:192.168.202.150:3306
yc_nacos逻辑库下面的users逻辑表对应的数据源是:192.168.201.68:3306
不同数据源下面的表可以通过mycat进行联合查询
读写分离
在两个数据源(192.168.202.150:3306,192.168.201.68:3306)分别创建master_slave数据库,及在数据库下创建travelrecord表
CREATE database master_slave;CREATE TABLE master_slave.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;创建集群:
/*! mycat:createCluster{"name":"prototype","masters":["prototypeDs"],"replicas":["yc-mysql"]} */;创建逻辑表关联集群
/*+ mycat:createSchema{
"customTables":{},
"globalTables":{},
"normalTables":{},
"schemaName":"master_slave",
"shardingTables":{},
"targetName":"prototype"
} */;查看集群状态:
/*+ mycat:showClusters{} */;
现在prototypeDs,yc-mysql两个数据源都可以读,我们改成只允许prototypeDs写,yc-mysql读,要修改两个地方
1、修改prototypeDs中的instanceType属性值为WRITE
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"prototypeDs",
"password":"Q61@t6Udu8mW",
"type":"JDBC",
"url":"jdbc:mysql://192.168.202.150:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mysteel",
"weight":0
}2、修改集群中BALANCE_ALL改成BALANCE_ALL_READ
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"prototypeDs"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"yc-mysql"
],
"switchType":"SWITCH"
}readBalanceType:查询负载均衡策略
BALANCE_ALL(默认值):获取集群中所有数据源
BALANCE_ALL_READ:获取集群中允许读的数据源
BALANCE_READ_WRITE:获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE:获取集群中允许写数据源,即主节点中选择
switchType
NOT_SWITCH:不进行主从切换
SWITCH:进行主从切换
配置重启之后:

当前主库prototypeDs中master_slave下面的travelrecord数据为:

当前从库yc-mysql中master_slave下面的travelrecord数据为:

现在在mycat客户端插入user_id为1000的数据:
insert into travelrecord(user_id)values ("1000");
此时主库prototypeDs中master_slave下面的travelrecord数据为:

此时从库yc-mysql中master_slave下面的travelrecord数据为:

现在在mycat客户端查询master_slave下面的travelrecord表数据为:

达到了在master_slave(prototypeDs)主库写,master_slave(yc-mysql)从库读的效果
配置prototypeDs,yc-mysql主从同步
可以查看https://yangcai.blog.csdn.net/article/details/122124151这个帖子
此时架构图为:

分库分表
创建数据源,因为我只准备了两个mysql库
/*+ mycat:createDataSource{
"dbType":"mysql",
"name":"m1",
"url":"jdbc:mysql://192.168.201.68:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"admin_user",
"password":"mOoBzUHGtqeX"
} */;/*+ mycat:createDataSource{
"dbType":"mysql",
"name":"m2",
"url":"jdbc:mysql://192.168.202.150:3306/mysql?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user":"mysteel",
"password":"Q61@t6Udu8mW"
} */;在mycat/conf/datasources下面会创建m1.datasource.json m2.datasource.json两个文件
创建两个集群:
/*! mycat:createCluster{"name":"c0","masters":["m1"],"replicas":[]} */;
/*! mycat:createCluster{"name":"c1","masters":["m2"],"replicas":[]} */;在mycat/conf/clusters下面会创建c0.cluster.json c1.cluster.json两个文件
注意:mycat分库分表默认选择的集群名称的规则是c${targetIndex},targetIndex是从0开始计算的
在mycat客户端创建分库分表逻辑库:
create database sub_base_table;在mycat/conf/schemas下面会创建sub_base_table.schema.json
在逻辑库下面创建分片表:
CREATE TABLE sub_base_table.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 dbpartition BY mod_hash ( user_id ) tbpartition BY mod_hash(id)tbpartitions 2 dbpartitions 2 ;在sub_base_table.schema.json中的内容为:
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"sub_base_table",
"shardingTables":{
"travelrecord":{
"createTableSQL":"CREATE TABLE sub_base_table.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(user_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 2",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/sub_base_table_${dbIndex}/travelrecord_${tableIndex}",
"tableNum":"2",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(user_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}此时m1,m2数据源就会创建分库分表,规则就是sub_base_table_${dbIndex}/travelrecord_${tableIndex},sub_base_table和targetIndex是从0开始计算的


此时架构图为:

全局表
如果项目中有一些数据类似字典常量等字段,这种数据一般数据量不会很大,而且改动也比较少,通常这种表可以不需要进行拆分,把它当做全局表进行处理,每个分片都创建一张相同的表,在所有的分片上都保存一份数据。在进行插入、更新、删除操作时,会将sql语句发送到所有分片上进行执行,在进行查询时,也会把sql发送到各个节点。这样避免了跨库JOIN操作,直接与本分片上的全局表进行聚合操作。
特性:
全局表的插入、更新、删除等操作会实时在所有节点上执行,保持各个分片的数据一致性;
全局表的查询操作,随机从一个节点上进行;
全局表可以跟任何一个表进行 JOIN 操作
在mycat客户端sub_base_table逻辑库执行:
CREATE TABLE sub_base_table.`user_config` (
`user_id` varchar(100) NOT NULL ,
`user_name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`user_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;此时sub_base_table.schema.json中的内容为:
{
"customTables":{},
"globalTables":{
"user_config":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE sub_base_table.`user_config` (\n\t`user_id` varchar(100) NOT NULL,\n\t`user_name` varchar(100) DEFAULT NULL,\n\tPRIMARY KEY (`user_id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{},
"schemaName":"sub_base_table",
"shardingTables":{
"travelrecord":{
"createTableSQL":"CREATE TABLE sub_base_table.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(user_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 2",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/sub_base_table_${dbIndex}/travelrecord_${tableIndex}",
"tableNum":"2",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(user_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}则在m1,m2中的sub_base_table物理库中都会创建user_config表


普通表
就是常规表
CREATE TABLE sub_base_table.`user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;此时sub_base_table.schema.json中的内容为:
{
"customTables":{},
"globalTables":{
"user_config":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE sub_base_table.`user_config` (\n\t`user_id` varchar(100) NOT NULL,\n\t`user_name` varchar(100) DEFAULT NULL,\n\tPRIMARY KEY (`user_id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{
"user":{
"createTableSQL":"CREATE TABLE sub_base_table.`user` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`name` varchar(100) DEFAULT NULL,\n\tPRIMARY KEY (`id`)\n) ENGINE = InnoDB CHARSET = utf8",
"locality":{
"schemaName":"sub_base_table",
"tableName":"user",
"targetName":"prototype"
}
}
},
"schemaName":"sub_base_table",
"shardingTables":{
"travelrecord":{
"createTableSQL":"CREATE TABLE sub_base_table.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(user_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 2",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/sub_base_table_${dbIndex}/travelrecord_${tableIndex}",
"tableNum":"2",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(user_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}其普通表默认指向的集群是prototype,在prototypeDs-sub_base_table中会创建user表

ER表
基于E-R关系进行分片,子表的记录与其关联的父表的记录保存在同一个分片上,这样关联查询就不需要跨库进行查询,要注意的是无需指定ER表,是自动识别的,两表的分片算法一致就可以了
如:travel是travelrecord的附属表
CREATE TABLE sub_base_table.`travel` (
`id` bigint NOT NULL AUTO_INCREMENT,
`u_id` varchar(100) DEFAULT NULL,
`travel` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = INNODB DEFAULT CHARSET = utf8 dbpartition BY mod_hash(u_id) tbpartition BY mod_hash(id) tbpartitions 2 dbpartitions 2 ;此时sub_base_table.schema.json中的内容为:
{
"customTables":{},
"globalTables":{
"user_config":{
"broadcast":[
{
"targetName":"c0"
},
{
"targetName":"c1"
}
],
"createTableSQL":"CREATE TABLE sub_base_table.`user_config` (\n\t`user_id` varchar(100) NOT NULL,\n\t`user_name` varchar(100) DEFAULT NULL,\n\tPRIMARY KEY (`user_id`)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8"
}
},
"normalProcedures":{},
"normalTables":{
"user":{
"createTableSQL":"CREATE TABLE sub_base_table.`user` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`name` varchar(100) DEFAULT NULL,\n\tPRIMARY KEY (`id`)\n) ENGINE = InnoDB CHARSET = utf8",
"locality":{
"schemaName":"sub_base_table",
"tableName":"user",
"targetName":"prototype"
}
}
},
"schemaName":"sub_base_table",
"shardingTables":{
"travelrecord":{
"createTableSQL":"CREATE TABLE sub_base_table.`travelrecord` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`user_id` varchar(100) DEFAULT NULL,\n\t`traveldate` date DEFAULT NULL,\n\t`fee` decimal(10, 0) DEFAULT NULL,\n\t`days` int DEFAULT NULL,\n\t`blob` longblob,\n\tPRIMARY KEY (`id`),\n\tKEY `id` (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(user_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 2",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/sub_base_table_${dbIndex}/travelrecord_${tableIndex}",
"tableNum":"2",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(user_id)"
},
"ranges":{}
},
"partition":{
},
"shardingIndexTables":{}
},
"travel":{
"createTableSQL":"CREATE TABLE sub_base_table.`travel` (\n\t`id` bigint NOT NULL AUTO_INCREMENT,\n\t`u_id` varchar(100) DEFAULT NULL,\n\t`travel` date DEFAULT NULL,\n\tPRIMARY KEY (`id`)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(u_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(id) TBPARTITIONS 2",
"function":{
"properties":{
"dbNum":"2",
"mappingFormat":"c${targetIndex}/sub_base_table_${dbIndex}/travel_${tableIndex}",
"tableNum":"2",
"tableMethod":"mod_hash(id)",
"storeNum":2,
"dbMethod":"mod_hash(u_id)"
}
},
"shardingIndexTables":{}
}
},
"views":{}
}

当执行以下sql的时候的就避免了跨库join,跨库join查询的性能非常慢
select * from sub_base_table.`travel` a INNER JOIN sub_base_table.`travelrecord` b on a.u_id = b.user_id 查看配置的表是否具有ER关系,使用
/*+ mycat:showErGroup{}*/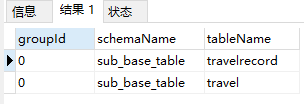
group_id表示相同的组,该组中的表具有相同的存储分布



![[Tomcat下载安装以及配置(详细教程)]](https://img-blog.csdnimg.cn/img_convert/3534669629da608f6e3bd3d57109474c.png)



![[python入门㊶] - python写入文件](https://img-blog.csdnimg.cn/a92c7028baf441df88b89d1542173c63.png)