目录
一、模型介绍
1. 集成学习
2. bagging
3. 随机森林算法
二、随机森林算法优缺点
三、代码实现
四、疑问
五、总结
本文使用mnist数据集,进行随机森林算法。
一、模型介绍
1. 集成学习
集成学习通过训练学习出多个估计器,当需要预测时通过结合器将多个估计器的结果整合起来当作最后的结果输出。
集成学习的优势是提升了单个估计器的通用性与鲁棒性,比单个估计器拥有更好的预测性能。集成学习的另一个特点是能方便的进行并行化操作。
2. bagging
Bagging 算法是一种集成学习算法,其全称为自助聚集算法(Bootstrap aggregating),顾名思义算法由 Bootstrap 与 Aggregating 两部分组成。
算法的具体步骤为:假设有一个大小为 N 的训练数据集,每次从该数据集中有放回的取选出大小为 M 的子数据集,一共选 K 次,根据这 K 个子数据集,训练学习出 K 个模型。当要预测的时候,使用这 K 个模型进行预测,再通过取平均值或者多数分类的方式,得到最后的预测结果。
3. 随机森林算法
将多个决策树结合在一起,每次数据集是随机有放回的选出,同时随机选出部分特征作为输入,所以该算法被称为随机森林算法。可以看到随机森林算法是以决策树为估计器的Bagging算法。
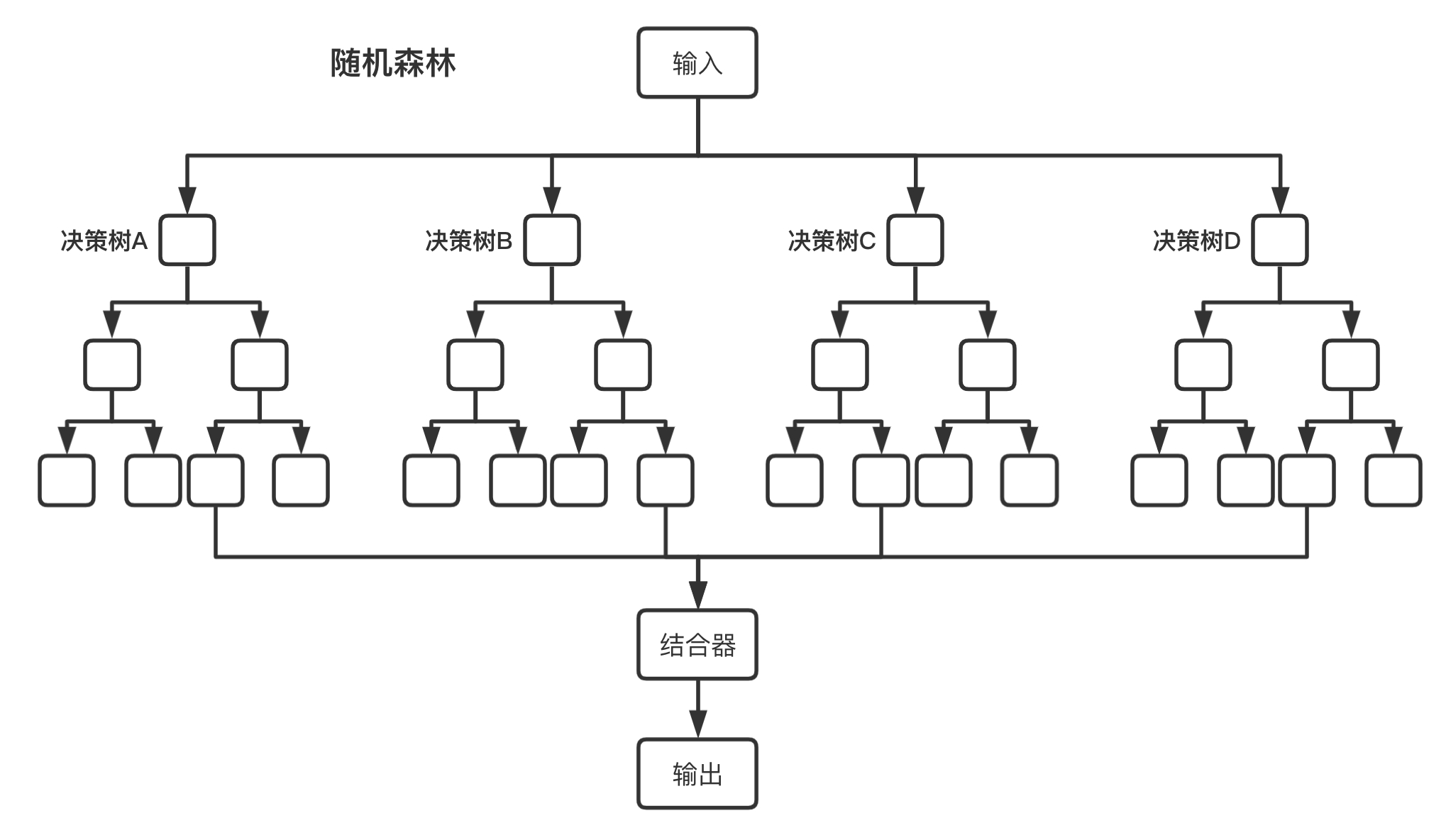
上图展示了随机森林算法的具体流程,其中结合器在分类问题中,选择多数分类结果作为最后的结果,在回归问题中,对多个回归结果取平均值作为最后的结果。
使用Bagging算法能降低过拟合的情况,从而带来了更好的性能。单个决策树对训练集的噪声非常敏感,但通过Bagging算法降低了训练出的多颗决策树之间关联性,有效缓解了上述问题。
二、随机森林算法优缺点
1. 对于很多种资料,可以产生高准确度的分类器
2. 可以处理大量的输入变量
3. 可以在决定类别时,评估变量的重要性
4. 在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计
5. 包含一个好方法可以估计丢失的资料,并且如果有很大一部分的资料丢失,仍可以维持准确度
6. 对于不平衡的分类资料集来说,可以平衡误差
7. 可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类,也可侦测偏离者和观看资料
8. 学习过程很快速
三、代码实现
代码:
from sklearn.ensemble import RandomForestClassifier # 随机森林分类器
from sklearn.datasets import load_digits # 数据集
from sklearn.model_selection import train_test_split # 数据分割模块
from sklearn.metrics import classification_report # 生产报告
from sklearn.metrics import confusion_matrix
# 1.加载数据
mnist = load_digits()
# 2.分割数据集
x_train, x_test, y_train, y_test, image_train, image_test = train_test_split(mnist.data, mnist.target, mnist.images,
test_size=0.25, random_state=33)
# 3.训练分类器
rfc = RandomForestClassifier(n_jobs=-1)
train_history = rfc.fit(x_train, y_train)
# 4.测试
pred = rfc.predict(x_test)
report = classification_report(y_test, pred)
confusion_mat = confusion_matrix(y_test, pred)
print(report)
print(confusion_mat)结果:
precision recall f1-score support
0 0.97 1.00 0.99 35
1 0.98 1.00 0.99 54
2 1.00 0.95 0.98 44
3 0.98 0.89 0.93 46
4 0.94 0.94 0.94 35
5 0.92 0.94 0.93 48
6 0.98 0.98 0.98 51
7 0.92 1.00 0.96 35
8 0.95 0.95 0.95 58
9 0.93 0.93 0.93 44
accuracy 0.96 450
macro avg 0.96 0.96 0.96 450
weighted avg 0.96 0.96 0.96 450
[[35 0 0 0 0 0 0 0 0 0]
[ 0 54 0 0 0 0 0 0 0 0]
[ 1 0 42 0 0 0 0 0 0 1]
[ 0 0 0 41 0 2 0 1 1 1]
[ 0 0 0 0 33 0 0 2 0 0]
[ 0 0 0 0 0 45 1 0 1 1]
[ 0 0 0 0 1 0 50 0 0 0]
[ 0 0 0 0 0 0 0 35 0 0]
[ 0 1 0 0 1 1 0 0 55 0]
[ 0 0 0 1 0 1 0 0 1 41]]四、疑问
以上代码是从书上学习的,但是有一些问题:
1. 为什么不划分验证集,结果如何以图片的形式可视化?
2. 为什么不进行数据的预处理,如下代码所示:
def get_mnist_data():
(x_train_original, y_train_original), (x_test_original, y_test_original) = mnist.load_data()
# 从训练集中分配验证集
x_val = x_train_original[50000:] #(10000,28,28)每一个图片
y_val = y_train_original[50000:] #10000,每个图片的标签
x_train = x_train_original[:50000]# (50000,28,28)
y_train = y_train_original[:50000]#50000
# 将图像转换为四维矩阵(nums,rows,cols,channels), 这里把数据从unint类型转化为float32类型, 提高训练精度。
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
#x_train.shape[0]表示x_train的行数。28是图片自身的大小。这里与原本的LeNet-5不同,原有的输入大小是32
x_val = x_val.reshape(x_val.shape[0], 28, 28, 1).astype('float32')
x_test = x_test_original.reshape(x_test_original.shape[0], 28, 28, 1).astype('float32')
# 原始图像的像素灰度值为0-255,为了提高模型的训练精度,通常将数值归一化映射到0-1。
x_train = x_train / 255
x_val = x_val / 255
x_test = x_test / 255
# 图像标签一共有10个类别即0-9,这里将其转化为独热编码(One-hot)向量
y_train = np_utils.to_categorical(y_train)#标签都变成为二维
y_val = np_utils.to_categorical(y_val)
y_test = np_utils.to_categorical(y_test_original)
return x_train, y_train, x_val, y_val, x_test, y_test不进行归一化,不转化为独热编码向量?
3. 所用划分测试集和训练集的代码:
x_train, x_test, y_train, y_test, image_train, image_test = train_test_split(mnist.data, mnist.target, mnist.images,
test_size=0.25, random_state=33)
经查询,只能划分测试集和训练集,那如果想要画验证集,怎么办呢?
4. 如何绘制loss曲线、accuracy曲线?按照tensprflow的结构,总是会报错,说不存在history
5. 损失函数如何定义呢?代码中似乎没有。
6. 不需要定义epochs等超参数吗?sklearn库的fit函数:
train_history = rfc.fit(x_train, y_train)不能添加上面所说的超参数
五、总结
总之,可能是我对sklearn库了解的不够,感觉和写cnn完全不是一个思路,还需要进一步的学习。如果该代码有进一步的后续改进,会在评论区发出。
![[附源码]SSM计算机毕业设计流浪动物救助网站JAVA](https://img-blog.csdnimg.cn/b3155fe830f2480a94d19c2a51814ef7.png)

![[附源码]SSM计算机毕业设计健身健康规划系统JAVA](https://img-blog.csdnimg.cn/82865be0f8e844b383308d3480682de5.png)