⭐️前言⭐️
本篇文章,博主分享的是在面试中JVM常考的考点,希望这篇文章能够对你有用。
🍉博客主页: 🍁【如风暖阳】🍁
🍉精品Java专栏【JavaSE】、【备战蓝桥】、【JavaEE初阶】、【MySQL】、【数据结构】
🍉欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁🍉本文由 【如风暖阳】 原创,首发于 CSDN🙉
🍉博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言
🍉博客中涉及源码及博主日常练习代码均已上传码云(gitee)、GitHub

📍内容导读📍
- 🍅1.JVM执行流程
- 🍅2.JVM内存区域划分
- 2.1 程序计数器
- 2.2 栈
- 2.3 堆
- 2.4 方法区
- 🍅3.JVM类加载机制
- 3.1 类加载过程
- 3.1.1 Loading
- 3.1.2 Linking
- 3.1.3 Initializing
- 3.2 典型面试题
- 3.2.1 代码块的执行先后
- 3.2.2 双亲委派模型
- 🍅4.JVM的垃圾回收(GC)
- 4.1 什么垃圾需要回收?
- 4.2 如何找垃圾(判定垃圾)?
- 4.2.1 基于引用计数
- 4.2.2 基于可达性分析
- 4.3 垃圾如何回收(释放内存)?
- 4.3.1 标记-清除算法
- 4.3.2 复制算法
- 4.3.3 标记-整理算法
- 4.3.4 分代回收算法
- 4.4 垃圾收集器
- 4.4.1 串行收集器
- 4.4.2 并行收集器
- 4.4.3 CMS收集器
- 4.4.4 G1收集器

🍅1.JVM执行流程
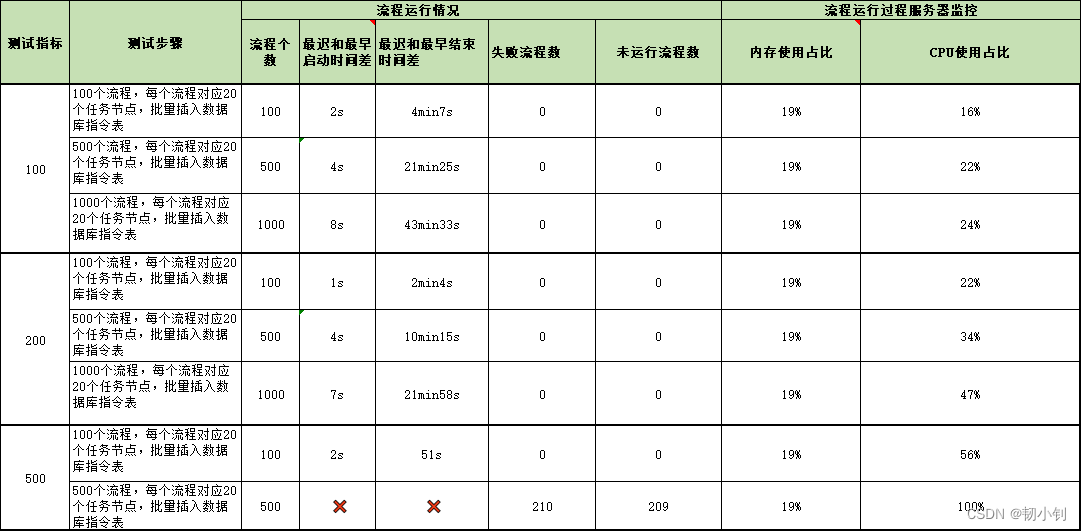
程序在执行之前先要把Java代码转换成字节码(class文件),JVM首先需要把字节码通过一定的方式如类加载器(ClassLoader),把文件加载到内存中的运行时数据区(Runtime Data Area),而字节码文件是JVM的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令再交给CPU去执行,而这个过程中需要调用其他语言的接口本地库接口(Native Interface),来实现整个程序的功能,这就是这4个主要组成部分的职责与功能。
🍅2.JVM内存区域划分
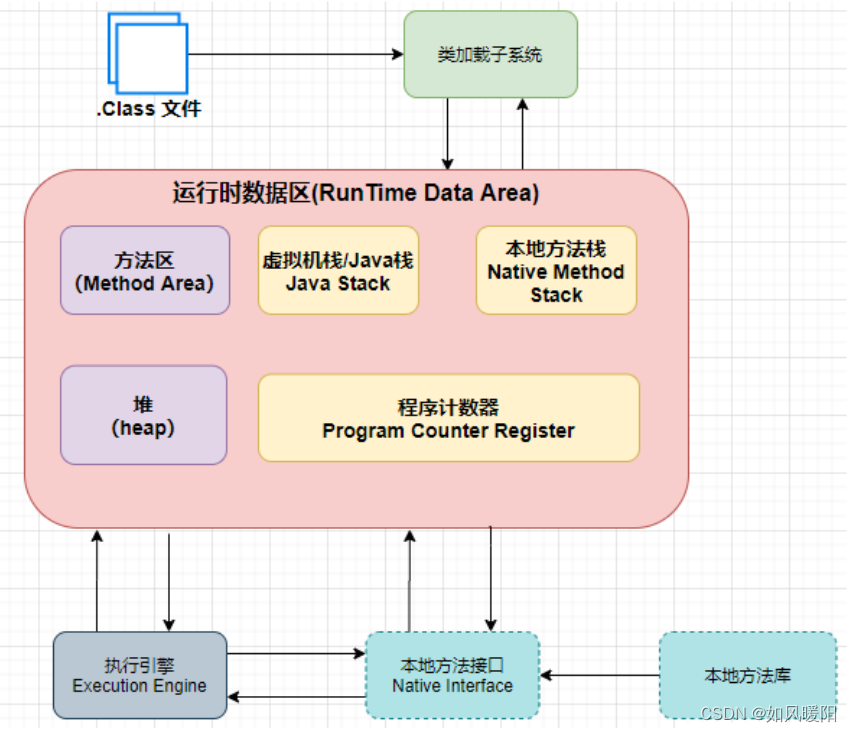
JVM的内存区域的划分就是指JVM的 运行时数据区(Runtime Data Area) 的划分,按照规范,其可以划分为以下几个区域:
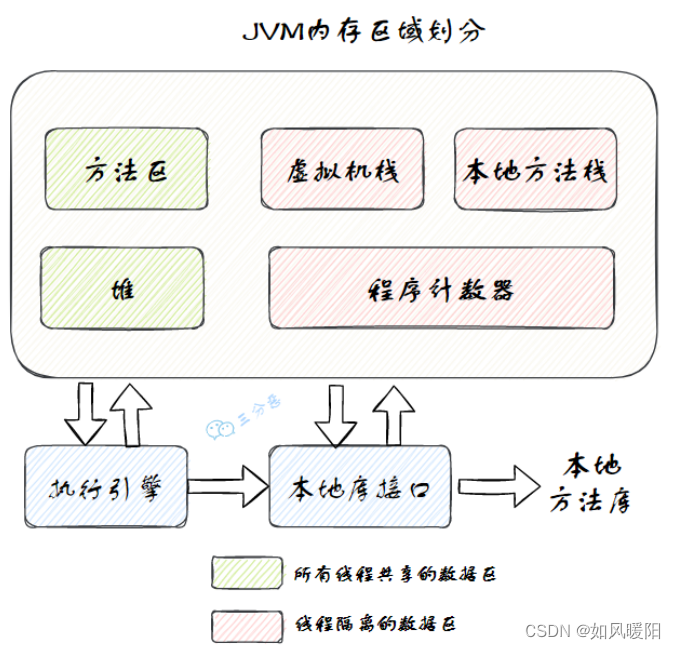
JVM内存分为线程私有区和线程共享区,其中方法区和堆是线程共享区,栈和程序计数器是线程隔离的私有数据区。
2.1 程序计数器
该区域是内存中最小的区域,保存了下一条要执行的指令(指令就是字节码)的地址在哪里。
程序要想运行,JVM就需要把字节码加载起来放到内存中,然后程序把一条一条的指令从内存中取出来,放到CPU上执行,由于CPU是并发式执行程序的,它同时为多个进程服务,线程则更多,所以每个线程都得记录自己的执行位置,即每个线程都有一个程序计数器。
2.2 栈
在该区域存储的有局部变量和方法调用信息
在方法调用的时候,每次调用一个新的方法,就都涉及到入栈操作,每次执行完了一个方法,就都涉及到出栈,每个线程都有这样一份栈。
2.3 堆
实例对象(new 出来的实例)在该区域存储
因为实例对象在堆区域存储,所以对象的成员变量也在该区域存储。
一个进程只有一份堆,多个线程共用一个堆
2.4 方法区
类对象存储在方法区中
程序的
.java文件转为.class字节码文件后,通过类加载器加载到内存中,就被JVM构造成了类对象,此处的类对象就在方法区中;
类对象描述了这个类的细节,类的名字、里面有哪些成员/方法,每个成员/方法叫啥名字是啥类型等类信息。
类对象中还有很重要的静态成员,也就是被static修饰的成员,其也是类属性;而普通的成员,叫做实例属性。
🍅3.JVM类加载机制
3.1 类加载过程
JVM的类加载,就是为了把.class文件加载到内存中,构建成类对象;具体加载过程见下图:
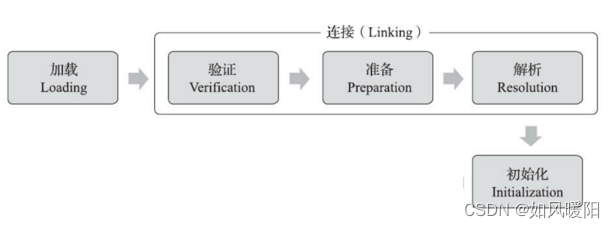
类加载包括三个步骤:Loading,Linking,Initializing
可参考官方文档:https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-5.html

3.1.1 Loading
先找到对应的.class文件,然后打开并读取.class文件,把读取并解析到的信息,初步的填写到生成的类对象中。
.class文件的格式如下图,JVM就按照这个格式来加载生成类对象
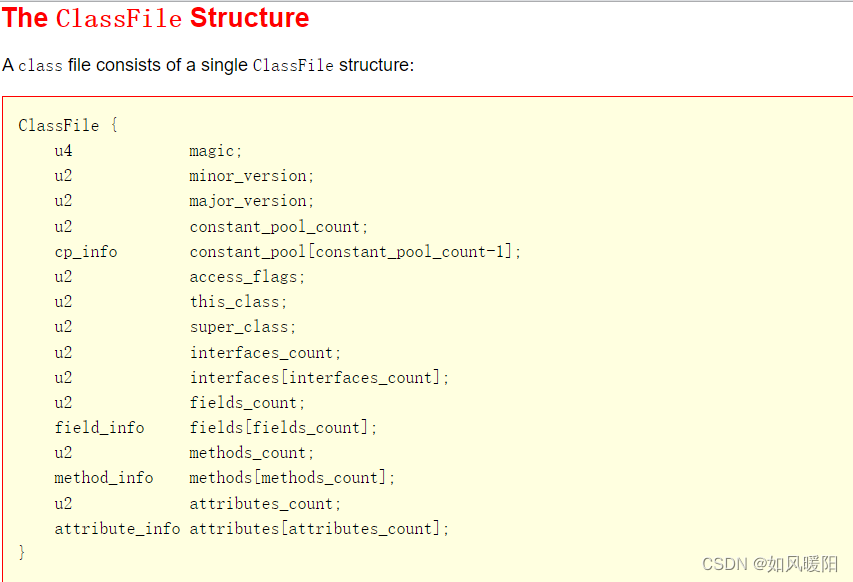
3.1.2 Linking
1)Verification
校验阶段
主要就是验证读到的内容是不是和规范中的规定格式完全匹配,如果发现这里读到的数据格式不符合规范,就会类加载失败,并且抛出异常。
2)Preparation
准备阶段
该阶段主要完成的工作是正式为类中定义的变量(即被staitic修饰的静态变量)分配内存,并设置类变量的初始值。
3)Resolution
解析阶段
该阶段主要完成的工作是Java虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
3.1.3 Initializing
真正地对类对象进行初始化,特别是静态成员,Java虚拟机真正开始执行类中编写的Java程序代码,将主导权移交给应用程序。
3.2 典型面试题
3.2.1 代码块的执行先后
执行以下代码块:
class A {
public A() {
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}
}
class B extends A {
public B() {
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}
}
public class Test {
public static void main(String[] args) {
new B();
System.out.println("----------");
new B();
}
}
//
A的静态代码块
B的静态代码块
A的构造代码块
A的构造方法
B的构造代码块
B的构造方法
----------
A的构造代码块
A的构造方法
B的构造代码块
B的构造方法
由以上代码的执行结果可得:
对象创建时代码的加载顺序为:静态代码–>非静态代码–>构造方法
若继承了父类,则加载顺序为:父类的静态代码块–>子类的静态代码块–>父类内部非静态代码–>父类的构造方法–>子类的非静态代码块–>子类的构造方法
静态代码块在类加载的时候只会执行一次,再实例化对象时并不会再次执行静态代码块。
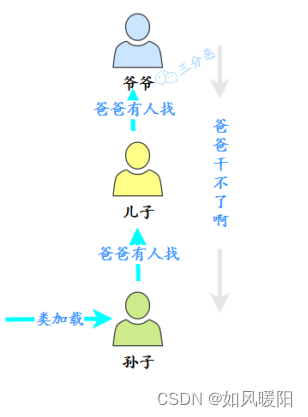
3.2.2 双亲委派模型
双亲委派模型,描述的是JVM中的类加载器,如何根据类的全限定名(java.lang.String)来找到.class文件的过程。
类加载器是专门负责进行类加载的对象,默认的类加载器主要有三个,每个类加载器负责一个片区:
1.启动类加载器 (Bootstrap Class Loader)
负责加载标准库中的类(String,ArrayList,Random,Scanner…)
2.扩展类加载器 (Extension Class Loader)
负责加载JDK中扩展的类(较少用到)
3.应用程序类加载器 (Application Class Loader)
负责加载当前项目目录中的类
程序猿还可以自定义类加载器,来加载其他目录中的类
例如Tomcat就自定义了类加载器,用来专门加载
webapps里面的.class
双亲委派模型就描述了上述类加载器如何通过配合,来找目录的过程:
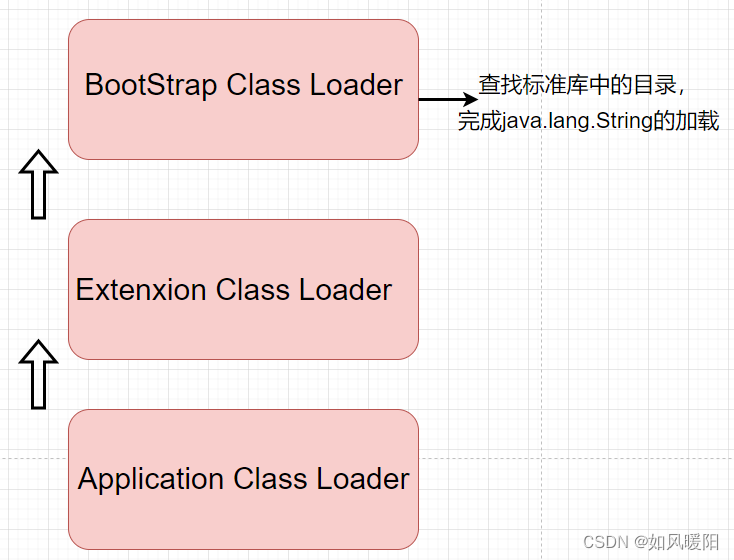
1)加载java.lang.String
a. 程序启动,先进入ApplicationClassLoader类加载器。
b. ApplicationClassLoader会检查其父加载器是否已经加载过了;如果没有就调用父 类加载器 ExtensionClassLoader
c. ExtensionClassLoader也会检查其父加载器是否加载过了;如果没有就调用父 类加载器 BootStrapClassLoader
d. BootStrapClassLoader也会检查其父加载器是否加载过了;但因为其没有父加载器,于是就扫描自己负责的目录
e. java.lang.String这个类在标准库中能找到,则直接由BootStrapClassLoader负责后续的加载过程
2)加载自己写的Test类
a. 程序启动,先进入ApplicationClassLoader类加载器。
b. ApplicationClassLoader会检查其父加载器是否已经加载过了;如果没有就调用父 类加载器 ExtensionClassLoader
c. ExtensionClassLoader也会检查其父加载器是否加载过了;如果没有就调用父 类加载器 BootStrapClassLoader
d. BootStrapClassLoader也会检查其父加载器是否加载过了;但因为其没有父加载器,于是就扫描自己负责的目录;没有扫描到,回到子加载器继续扫描
e. ExtensionClassLoader也扫描自己的目录,也没扫描到,回到子加载器继续扫描
f. ApplicationClassLoader也扫描自己负责的目录,能找到Test类,于是进行后续加载,查找目录环节结束
如果最终ApplicationClassLoader也找不到,就会抛出
ClassNotFoundException的异常
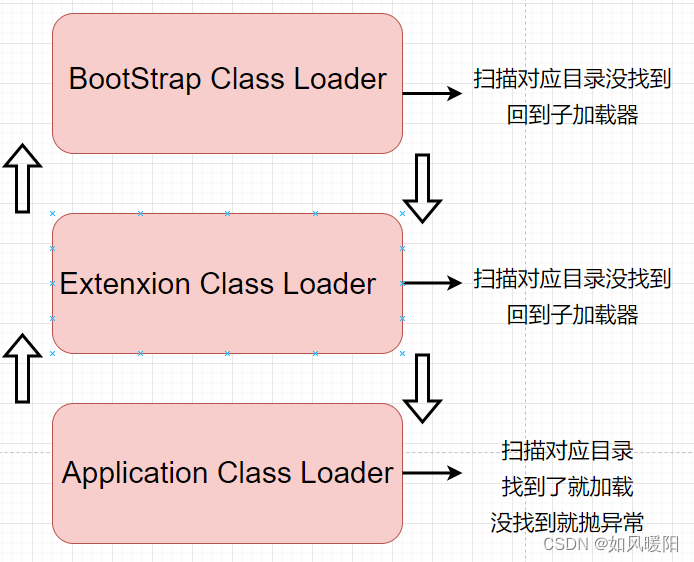
这样的查找规则就叫做双亲委派模型
🍅4.JVM的垃圾回收(GC)
在我们写代码的时候,经常会通过创建变量,new 对象或者加载类等方式来申请内存,但我们不能只申请内存而不释放。
申请内存的时机我们一般都是明确的(需要保存某些数据时,就需要申请内存),但是释放内存的时机,则不是那么清楚;
内存释放的早或者晚都会影响开发效率,所以我们需要让内存释放的时机恰到好处;
Java,Go,Python等较为主流的编程语言就采取了垃圾回收机制(GC),靠运行时环境额外多做一些工作,来完成释放内存的操作,让程序猿的工作量减少。
同样,垃圾回收机制也带来了一些劣势:
- 消耗额外的开销(消耗的资源更多了)
- 可能会影响程序的流畅运行(会引入STW问题)
STW<=>Stop The World 时间静止,就是卡了。
4.1 什么垃圾需要回收?
在JVM的内存中,划分有很多区域,我们在2中也有介绍,但是不是这些所有的区域都需要进行垃圾回收;
程序计数器占据固定大小的内存,不涉及释放,所以也就用不到GC;栈在函数执行完毕后,对应的栈帧就自动释放了,也不需要GC;堆是最需要GC的,因为代码中大量的内存都是在堆上;方法区中存储类对象,进行类卸载操作需要释放内存,但类卸载操作是一个非常低频的操作,所以也不需要过多考虑,只需考虑堆区域内存的垃圾回收即可。
在堆区域中,空间被分为三部分,一部分是正在使用的内存,一部分是不再使用,但尚未回收的内存,另一部分是未分配的内存;同时也有三类对象在这三部分区域中存在,一种是“积极派”,一种是“消极派”,还有另一种是“中间摇摆派”。

在上述的三个对象中,JVM只会回收“消极派”对象,GC回收是以对象为单位的,并不会出现半个对象的情况。
我们知道了什么垃圾需要回收,下边就需要我们来进行具体的垃圾回收操作,第一阶段需要我们找垃圾(判别垃圾),第二阶段就是释放垃圾,下边具体介绍:
4.2 如何找垃圾(判定垃圾)?
4.2.1 基于引用计数
该方案的具体操作是,针对每个对象,都会额外引入一小块内存,保存这个对象有多少个引用,当这个引用计数为0时,也就说明这个内存不再使用了,就释放了。
void func() {
Test t=new Test();
Test t2=t;//t和t2都是指向new对象的引用
}
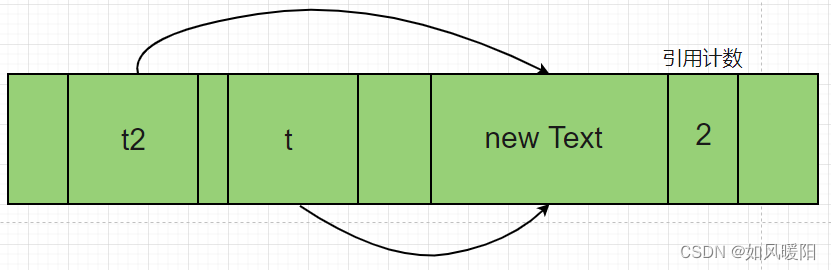
如上边的func()方法的调用过程中,创建了分配对象(分配了内存),在方法的执行过程中,引用计数是2,当方法执行结束后,由于t和t2都是局部变量,就跟随栈帧一起释放了,如此而来引用计数就变为了0,此时就认为这个对象是垃圾。
通过引用计数的方法来找垃圾,确实简单可靠高效,但也存在两个问题:
1.空间利用率较低
每个new的对象都需要额外开辟一块空间来存储计数器,如果对象本身就很小,而且还需要计数器,就会导致空间浪费很大。
2.会有循环引用的问题
通过以下代码来引入这个问题:
class Test {
Test t=null;
}
Test t1=new Test();
Test t2=new Test();
t1.t=t2;
t2.t=t1;
---------------------
t1=null;
t2=null;
//代码执行到这里就会出现循环引用的问题
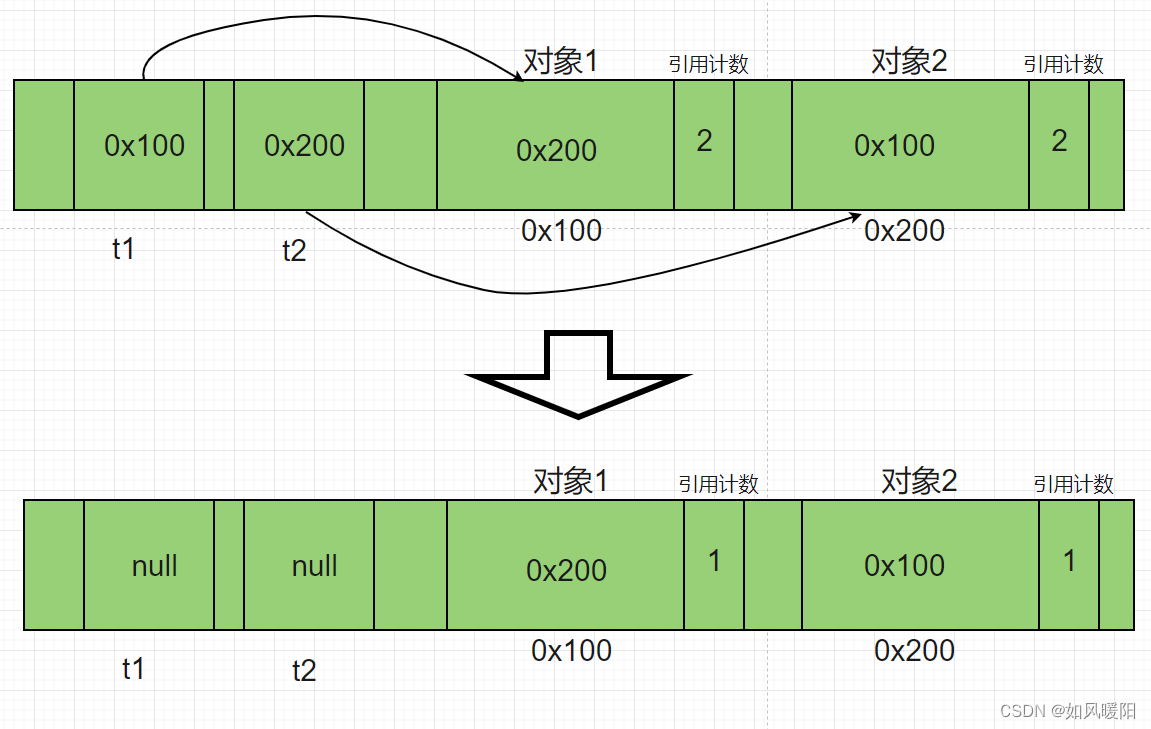
在代码执行完最后一行后,两个对象的引用计数不为0,但是引用在彼此身上,外界的代码无法访问到这两个对象,此时此刻,这两个对象既不能使用,也不能释放,就出现了“内存泄漏”的问题。
4.2.2 基于可达性分析
该方案是Java采取的方案。
可达性分析就是通过额外的线程,对整个内存空间的对象进行扫描,首先会找到一些起始位置GCRoots,从这些位置开始,以类似深度优先搜索的方式去遍历对象,它会对所有可以到达的对象进行标记,无法到达的对象自然也就没有标记,就被视为垃圾。
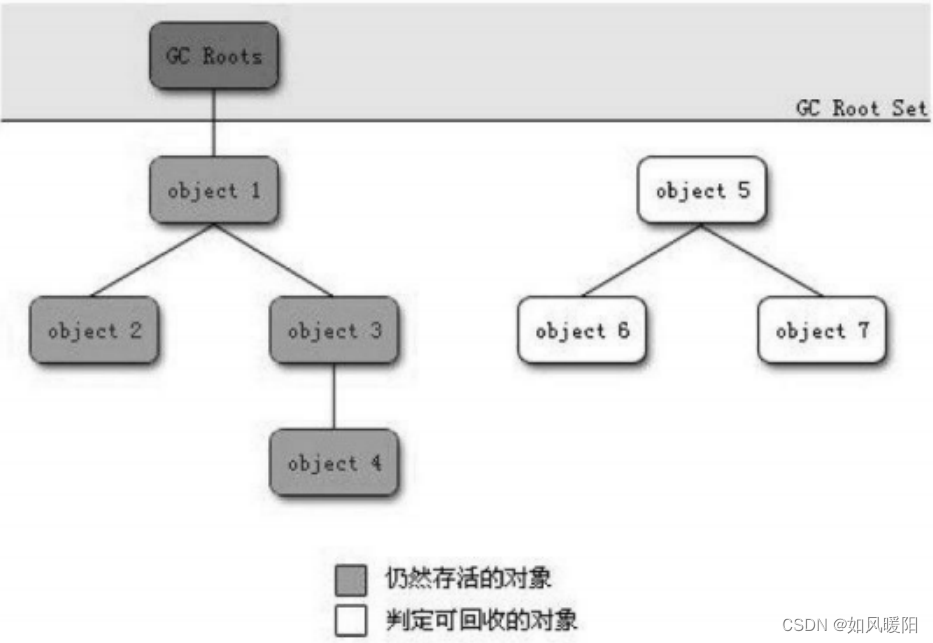
可以作为GCRoots的对象有以下几种:
- 栈上的局部变量
- 常量池中的引用指向的对象
- 方法区中的静态成员指向的对象
可达性分析的方法克服了引用计数中空间利用率低,循环引用两个缺点,但其也有自身的缺点:系统开销较大,遍历一次可能比较满。
结合以上两种方法,找垃圾的核心就是确定这个对象未来是否还会使用了,如果没有引用指向这个对象,这个对象就是垃圾,不再使用了。
4.3 垃圾如何回收(释放内存)?
垃圾回收算法共有以下四种:
4.3.1 标记-清除算法
标记就是可达性分析的过程,清除就是直接释放内存,如果直接释放内存,虽然内存是还给系统了,但是被释放的内存还是离散的(不连续)

在需要申请内存时,并不能提供连续的内存,这将非常影响程序的执行。
4.3.2 复制算法
为了解决内存碎片,引入了复制算法
复制算法就是把内存分为两部分,直接把不是垃圾的,拷贝到另一半,然后把原来的空间整体释放掉。

但该算法存在的问题有:
- 内存空间利用率低
- 如果要保留的对象多,要释放的对象少,此时复制开销就很大
4.3.3 标记-整理算法
该算法又针对复制算法做出了改进,该算法的实现类似于顺序表中删除中间元素的操作。
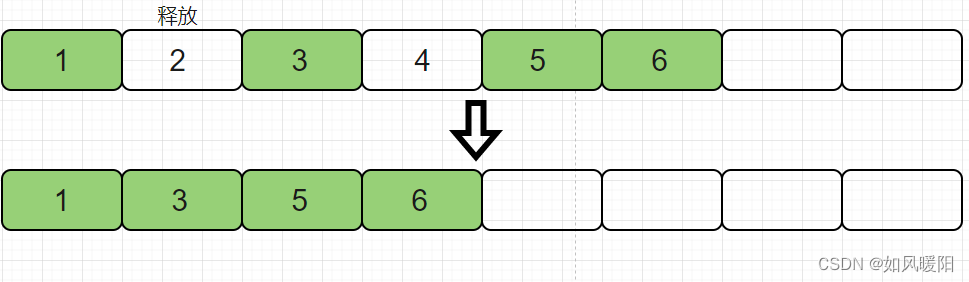
这个方法的空间利用率虽然提高了,但是仍然没有解决复制/搬运元素开销大的问题。
4.3.4 分代回收算法
上述的三种算法,虽然都能解决问题,但都有缺陷,在实际的JVM中的实现,会把多种方法结合起来使用,就形成了分代回收
针对对象进行分类(根据对象的“年龄”分类),一个对象经历过一轮GC扫描,就认为是“长了一岁”,针对不同年龄的对象,采取不同的方案,这就是分代回收。
在内存中划分出如下图的区域划分:

1.刚创建出来的对象,就放在伊甸区
2.如果伊甸区的对象熬过一轮GC扫描,就会被拷贝到幸存区(应用了复制算法)
3.在后续的几轮GC中,幸存区的对象就在两个幸存区之间来回拷贝(复制算法),每一轮拷贝都会淘汰掉一波幸存者
4.在持续若干轮之后,对象进入老年代,老年代中的对象都是比较老的,也就是继续存活的可能性是越大的,因此在老年代中的GC扫描频率大大低于新生代,所以在老年代中使用标记-清除或标记-整理的方式来进行回收。
4.4 垃圾收集器
在JVM里,上述垃圾回收算法具体实现的模块就是垃圾收集器,下边我们来了解一些常见的垃圾收集器。
4.4.1 串行收集器
串行收集就是指,在进行垃圾的扫描和释放的时候,业务线程要停止工作,这种方式扫描的慢,释放的也慢,会产生严重的STW(Stop The World,时间静止/卡顿)
基于这一方式的收集器有:
- Serial收集器(新生代收集器,串行GC)
- Serial Old收集器(老年代收集器,串行GC)
4.4.2 并行收集器
并行收集,就是通过引入多线程,来进行垃圾的扫描和释放任务,效率比串行更高
基于这一方式的收集器有:
- ParNew收集器(新生代收集器,并行GC)
- Parallel Scavenge收集器(新生代收集器,并行GC)
- Parallel Old收集器(老年代收集器,并行GC)
4.4.3 CMS收集器
该收集器设计的初衷就是尽可能的让STW时间短,其具体流程如下:
1)初始标记
速度很快,只会引起短暂的STW(这一步只是找到GCRoots)
2)并发标记
虽然速度慢,但是可以和业务线程并发执行,不会产生STW
3)重新标记
2)的业务代码可能会影响并发标记的结果,3)就是针对2)的结果进行微调,虽然会引起STW,但是很快。
4)回收内存
该操作也与业务线程并发
前三步就是可达性分析分开来完成了,最后一步就是通过标记-整理来处理老年代对象。
4.4.4 G1收集器
G1收集器是唯一一款全区域的垃圾回收器,该收集器把整个内存,分成了很多小的区域-Region,有的Region放新生代对象,有的放老年代对象,然后在扫描的时候,一次扫描若干个Region(不追求一轮GC就扫描完,分多次来扫描),这样对于业务代码的影响最小。
⭐️最后的话⭐️
总结不易,希望uu们不要吝啬你们的👍哟(^U^)ノ~YO!!如有问题,欢迎评论区批评指正😁