目录
DQL数据查询语言
简单查询语句
计算列
别名
distinct消除重复行
条件查询
条件运算符
null值判断
枚举查询
模糊查询
分支查询
函数
字符串函数
聚合函数
排序查询
分组查询Group by
分页查询Limit
表关联关系
一对一关联
一对多与多对一
多对多关联
外键约束
语法
级联
连接查询
内连接查询 inner join
笛卡尔积
内连接条件
左连接left join
子查询/嵌套查询
含义
单行单列
单列多行
多行多列
DQL数据查询语言
数据库的表:关系结构数据库是以表格(Table)进行数据存储,表格由“行”和“列”组成
使用查询语句获得的结果集是虚拟表,不会影响原数据库
简单查询语句
语法:select 列名1,列名2,... from 表名 [where 条件];
如果需要查询所有列可用 * 来代替字段名列表
select * from 表名;
SELECT p_id,p_name FROM person;
SELECT * FROM person;计算列
可以将数据表中查询的记录进行一定的运算之后显示出来
可使用:+,-,*,/,%
例如:计算出生年份,为今年减去年龄
SELECT p_name,2022-p_age FROM person;别名
如果在连接查询的多张表中存在相同名字的字段,我们可以使用 表名.字段名 来进行区 分,如果表名太长则不便于SQL语句的编写,我们可以使用数据表的别名
给列起别名,给表起别名
select 列名1,列名2 AS 别名,... from 表名 AS 别名
例:
SELECT p_name AS 名称 FROM person AS s;
给person起个别名s ,此表连接多张表时,使用 s.字段名 查询,就比person.字段名 查询易于书写实际书写中AS也可以省略不写
distinct消除重复行
在查询结果中消除重复行
语法:
select distinct 字段名1,字段名2....... from 表名;
例:
SELECT DISTINCT p_id,p_name FROM person;注意:distinct 语句中 select 显示的字段只能是 distinct 指定的字段,其他字段是不可能出现的
实际上是根据 "p_id+p_name" 来去重,distinct 同时作用在了 name 和 id 上。
distinct 会对结果集去重,对全部选择字段进行去重,并不能针对其中部分字段进行去重。
条件查询
条件运算符
1.可使用的条件关系运算符有
=,!=,>,<,>=,<=例:
SELECT * FROM person WHERE p_sex='女';
SELECT * FROM person WHERE p_age<100;还可以使用区间查询
between and 区间查询 between v1 and v2 [v1,v2]
结果是包含v1,v2的
例:
SELECT * FROM person WHERE p_age BETWEEN 9 AND 29 ;2.可使用的逻辑运算符
与:and
或:or
非:not
例:
SELECT * FROM person WHERE p_age>=9 AND p_age <=29;null值判断
is null 是空
is not null 不为空
语法:
select * from 表名where 字段名 is null;
select * from 表名where 字段名 is not null;
枚举查询
语法:字段名 in(字段值1,字段值2.....)
例如:
SELECT * FROM person WHERE p_age in(9,13,23);模糊查询
在where子句的条件中,我们可以使用like关键字来实现模糊查询
语法:
select * from 表名 where 列名 like 'reg';
reg为表达式,其中 % 表示任意多个字符 ,_ 表示任意单个字符
例如:
SELECT * FROM person WHERE p_name LIKE '%电%';
代表名称中含有 电 就会被查寻到
LIKE '%电' 电 结尾被查到
LIKE '电%' 电 开头被查到
LIKE '_电%' 第二个字为电被找到
LIKE '%电_' 倒数第二个字为电
以此类推 分支查询
语法:
select 字段1,字段2,.....
CASE
WHEN 条件1 THEN 结果1
WHEN 条件2 THEN 结果2
WHEN 条件3 THEN 结果3
ELSE 结果
END 可在end后给新列起个名
FROM 表名
注意:通过使用CASE END进行条件判断,每条数据对应生成一个值。
例:
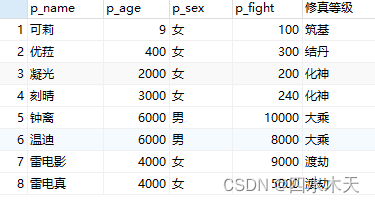
SELECT p_id,p_name,p_age,p_sex,p_fight,
CASE
WHEN p_age>=5000 THEN '大乘'
WHEN p_age>=4000 AND p_age<5000 THEN '渡劫'
WHEN p_age>=1000 AND p_age<4000 THEN '化神'
WHEN p_age>=500 AND p_age<1000 THEN '元婴'
WHEN p_age>=100 AND p_age<500 THEN '结丹'
ELSE'筑基'
END AS 修真等级
FROM person;
函数
1.时间函数
作用:当我们向日期类型的列添加数据时,可以通过字符串类型赋值(字符串格式必须为:yyyyMM-dd hh:mm:ss)
| 时间函数 | 描述 |
| SYSDATE()/now() | 当前系统时间(日、月、年、时、分、秒) |
| CURDATE() | 获取当前日期 |
| CURTIME() | 获取当前时间 |
| WEEK(DATE) | 获取指定日期为一年中的第几周 |
| YEAR(DATE) | 获取指定日期的年份 |
| HOUR(TIME) | 获取指定时间的小时值 |
| MINUTE(TIME) | 获取时间的分钟值 |
| DATEDIFF(DATE1,DATE2) | 获取DATE1 和 DATE2 之间相隔的天数 |
| ADDDATE(DATE,N) | 计算DATE 加上 N 天后的日期 |
SELECT NOW();
SELECT SYSDATE();
这两个可以直接打印出系统时间insert into
stus(stu_num,stu_name,stu_gender,stu_age,stu_tel,stu_qq,stu_enterence)
values('20200108','张小三','女',20,'13434343344','123111','2021-09-01
09:00:00');
使用字符串添加时间
insert into
stus(stu_num,stu_name,stu_gender,stu_age,stu_tel,stu_qq,stu_enterence)
values('20210109','张小四','女',20,'13434343355','1233333',now());
通过now()获取当前时间
insert into
stus(stu_num,stu_name,stu_gender,stu_age,stu_tel,stu_qq,stu_enterence)
values('20210110','李雷','男',16,'13434343366','123333344',sysdate());
通过sysdate()获取当前时间
字符串函数
对字符串进行处理
| 字符串函数 | 说明 |
| CONCAT(str1,str2,str....) | 将 多个字符串连接 |
| INSERT(str,pos,len,newStr) | 将str 中指定 pos 位置开始 len 长度的内容替换为 newStr |
| LOWER(str) | 将指定字符串转换为小写 |
| UPPER(str) | 将指定字符串转换为大写 |
| SUBSTRING(str,num,len) | 将str 字符串指定num位置开始截取 len 个内容 |
使用
# concat(colnum1,colunm2,...) 拼接多列
select concat(stu_name,'-',stu_gender) from stus;
# upper(column) 将字段的值转换成大写
select upper(stu_name) from stus;
select stu_name,substring(stu_tel,8,4) from stus;
# substring(column,start,len) 从指定列中截取部分显示 从select开始,截取len个,不包含start聚合函数
count:数量
select count(stu_num) from stus;
统计总数max:最大值
select max(stu_age) from stus;
获取最大年龄值min:最小值
sum:求和
select sum(stu_age) from stus;
统计此列总和avg:求平均数
select avg(stu_age) from stus;
统计年平均值排序查询
select * from 表名 where 条件 order by 列名 asc|desc;
order by 列名 表示将查询结果按照指定的列排序
asc 按照指定的列升序(默认)
desc 按照指定的列降序
例如:
select * from stus where stu_age>15 order by stu_gender desc;
年纪大于15的按 stu_gender 排序
单字段
select * from stus where stu_age>15 order by stu_gender asc,stu_age desc;
多字段排序 : 先满足第一个排序规则,当第一个排序的列的值相同时再按照第二个列的
规则排序
先按stu_gender升序,相同就按 stu_age 降序分组查询Group by
将表中记录按指定列进行分组
语法
select 分组字段/聚合函数
from 表名
[where 条件]
group by 分组列名 [having 条件]
[order by 排序字段]select 后通常显示分组字段和聚合函数(对分组后的数据进行统计、求和、平均值等)
语句执行顺序:
1,先根据where条件从数据库查询记录
2,group by对查询记录进行分组
3,执行having对分组后的数据进行筛选
4,排序
例:
SELECT p_sex,count(p_sex) FROM person GROUP BY p_sex;
对性别进行分组,并统计
SELECT p_sex,AVG(p_age ) FROM person GROUP BY p_sex;
用p_sex分组,求平均年龄SELECT p_age,COUNT(p_age) FROM person #查出来的是年龄,统计个数
WHERE p_sex='女' #只统计女的
GROUP BY p_age #用年龄分组
HAVING COUNT(p_age)>0#列出所有组
ORDER BY p_age;#升序排列分页查询Limit
把数据分页查询
select 查询的字段
from 表名
where 条件
limit param1,param2;
SELECT * FROM person LIMIT 1,4;
查询,从第一个数据开始,向下查询4个数据,不包含1表关联关系
关联关系:MySQL是一个关系型数据库,不仅可以存储数据,还可以维护数据与数据之间的关系 通过在数据表中添加字段建立外键约束。
数据之间的关系:
一对一关联
一对多关联
多对一关联
多对多关联
一对一关联
例如:
人 --- 身份证 一个人只有一个身份证、一个身份证只对应一个人
学生 --- 学籍 一个学生只有一个学籍、一个学籍也对应唯一的一个学生
方案1:主键关联,两张数据表中主键相同的数据为相互对应的数据
方案2:唯一外键,在任意一张表中添加一个字段添加外键约束与另一张表主键关联,并且将外键列添加唯一约束
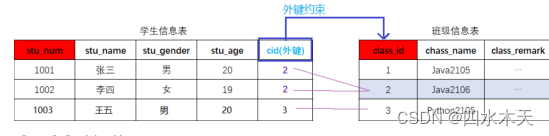
一对多与多对一
班级 --- 学生
图书 --- 分类
在多的一端添加外键 ,与一的一端主键进行关联
多对多关联
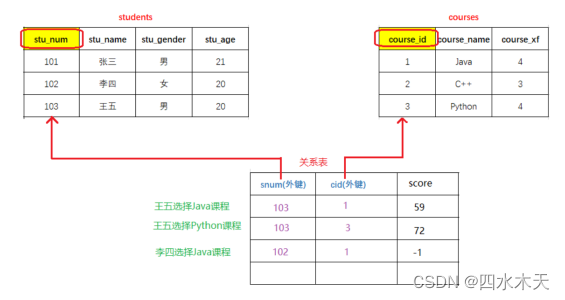
学生 --- 课程
订单 --- 商品
方案:需要额外创建一张关系表来维护多对多的关联,在关系表中定义两个外键,分别与两个数 据表的主键进行关联
外键约束
作用:将一个列添加外键约束与另一张表的主键进行关联后,这个外键约束的列添加的数据 必须要在关联的主键字段中存在,保证了数据的完整性。
具体的关联关系看上边。
例如: 一家公司有不同的部门,员工,
员工对部门为多对一
此时,可将员工表与部门表相关联
语法
方式1:创建表时就添加外键
#方式1:创建表时
create table 表名(
字段名1 数据类型 [约束],
字段名2 数据类型 [约束],
...
[constraint] [外键名称] #此处是给外键起个名字,一般用 FK_子列表名_主键、列表名
foreign key(外键列名)
references 主表(主表列表)
);
方式2:建表之后
alter table 表名 add [constraint] [外键名称] foreign key(外键列名)
references 主表(主表列表);
删除外键
alter table 表名 drop foreign key 外键名称;例:创建员工表,创建部门表
CREATE TABLE yg(
y_id INT PRIMARY KEY,
y_name varchar (5),
y_bm INT,
y_money INT
);
CREATE TABLE bm(
b_id INT PRIMARY KEY,
b_name VARCHAR(6)
);添加主键:
ALTER TABLE yg ADD CONSTRAINT FK_yg_bm 此处给外键起了个名
FOREIGN KEY(y_bm)#此处为添加外键的关键字 ,
REFERENCES bm(b_id); 此处为 主表以及相连的字段给bm添加数据
INSERT INTO bm(b_id,b_name)
VALUES(1,'美工'),
(2,'UI'),
(3,'前端'),
(4,'后端');给yg添加数据,
设置的外键y_bm值必须在关联的主表bm中的b_id值中存在
INSERT INTO yg(y_id,y_name,y_bm,y_money)
VALUES
(1,'火旺',2,1500),
(2,'李岁',3,20000),
(3,'季灾',2,9000),
(4,'易东',4,1000),
(5,'杨娜',4,100000),
(6,'高坚',4,1300),
(7,'白淼',3,1500),
(8,'小孩',2,1600);
如果不存在就会报错
级联
作用:主表改变某值,希望子表也跟着改变
例:上边的想修改部门的 b_id ,
UPDATE bm SET b_id=5 WHERE b_name = 'UI';修改不了的,外键报错

也删除不了,删除也会报错
这时就可以使用级联进行修改和删除
使用方法:
在添加外键时,设置级联删除(ON DELETE CASCADE)和级联修改(ON UPDATE CASCADE)以上边的为例,要先删除外键
ALTER TABLE yg DROP FOREIGN KEY FK_yg_bm;此时再重新添加,加上级联删除,级联修改
ALTER TABLE yg ADD CONSTRAINT FK_yg_bm FOREIGN KEY(y_bm)
REFERENCES bm(b_id) ON UPDATE CASCADE ON DELETE CASCADE;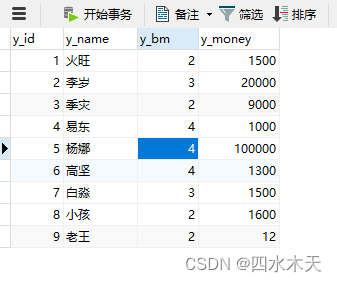
UPDATE bm SET b_id = 5 WHERE b_name = '后端';
把后端id改为 5 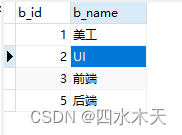
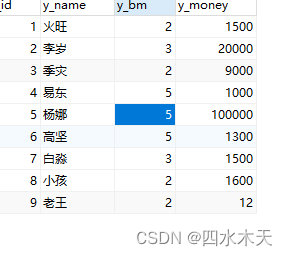
可以看到同步修改了
同样的如果删除 bm 数据,bm_id = 2的数据,则yg表中相应的y_bm值的员工也会被删除,相当于裁员了
连接查询
给上边表加一个没有加入部门的实习生
INSERT into yg(y_id,y_name,y_money)
VALUE(10,'实习生',200);此时表中有个人没有加入部门,有个部门没有人
内连接查询 inner join
作用:获取交集
语法:
select ... from 表1 inner join 表2 on 匹配条件 [where 筛选条件];
笛卡尔积
概念:将A中的数据全部关联一次B中的每个记录,所以其 积总数=A总数*B总数
如果直接执行
select ... from 表1 inner join 表2 则会直接产出笛卡尔积
例:
SELECT * FROM yg INNER JOIN bm;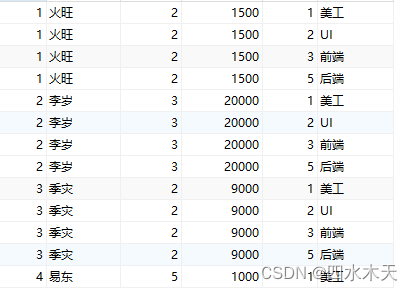
内连接条件
两张表时用inner join连接查询之后生产的笛卡尔积数据中很多数据都是无意义的,我们可以添加两张进行连接查询时的条件来消除无意义的数据(效率低)
使用 on 设置两张表连接查询的匹配条件,查询结果只获取两种表中匹配条件成立的数据, 任何一张表在另一种表如果没有找到对应匹配则不会出现在查询结果中
例:使用where 在笛卡尔积中寻找,所以效率低下
SELECT * FROM yg INNER JOIN bm WHERE yg.y_bm = bm.b_id;
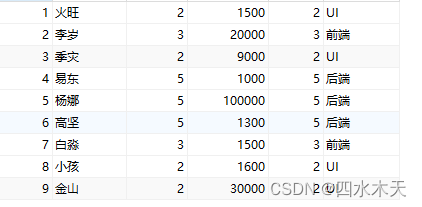
使用on先判断连接条件是否成立,如果成立两张表进行组合生成一条记录
之后也可以继续加 where 判断选择,但是上面那个where不能连用
SELECT * FROM yg INNER JOIN bm ON yg.y_bm = bm.b_id;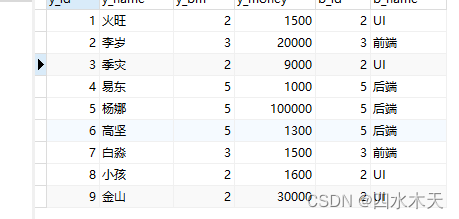
左连接left join
如上面的表没有显示实习生则需要左连接
需求:请查询出所有的员工信息,如果有对应的部门则显示,没有则不显示
语法:
select * from leftTabel LEFT JOIN rightTable ON 匹配条件 [where 条件];左连接:
SELECT * FROM yg LEFT JOIN bm ON yg.y_bm = bm.b_id;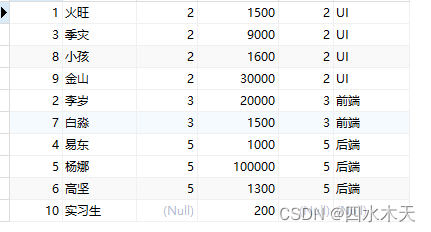
右连接right join
查询所有部门信息,看有没有人
SELECT * FROM yg RIGHT JOIN bm ON yg.y_bm = bm.b_id;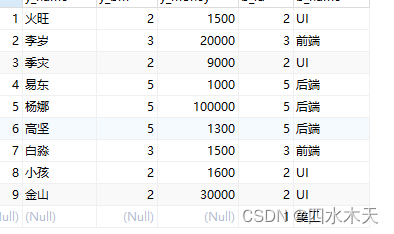
进一步,统计部门人数
SELECT b_name,COUNT(b_id) #需要的是部门名字,b_id为主键,所以统计它
FROM yg RIGHT JOIN bm ON yg.y_bm = bm.b_id#右连接
GROUP BY b_id;#分组
子查询/嵌套查询
含义
子查询 — 先进行一次查询,第一次查询的结果作为第二次查询的源/条件(第二次查询是基 于第一次的查询结果来进行的)
单行单列
子查询返回的是一个值,结果就是一个值,所以可以直接用关系运算符
例:查询前端部的人
select * FROM yg WHERE y_bm =
(SELECT b_id FROM bm WHERE b_name = '前端');
单列多行
如果子查询返回的结果是多个值(单列多行),条件使用IN / NOT IN
多行多列
把此表当作新表查询,放在from后面就行
![[CKA备考实验][ingress-nginx] 4.2 集群外访问POD](https://img-blog.csdnimg.cn/5053b8f7fd74464e8558d4efb2673f69.png)