学习大数据会使用到多台Linux服务器。
一、环境准备
1、VMware
基于VMware构建Linux虚拟机
- 是大数据从业者或者IT从业者的必备技能之一
- 也是成本低廉的方案
所以VMware虚拟机方案是必须要学习的。
(1)设置网关
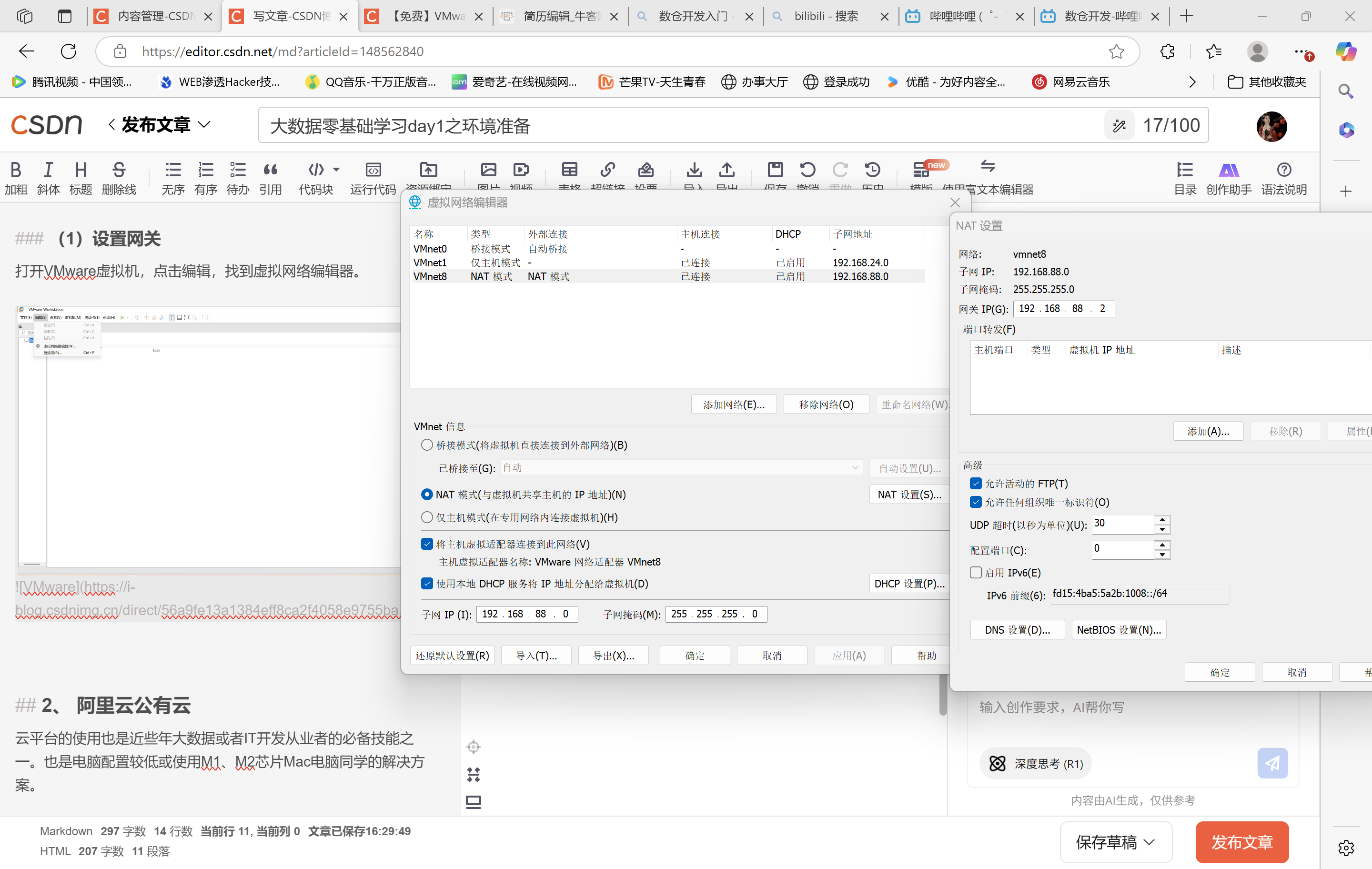
打开VMware虚拟机,点击编辑,找到虚拟网络编辑器。
点击VMware8,将VMware8的网卡的相应信息进行更改,
网段:192.168.88.0
网关:192.168.88.2
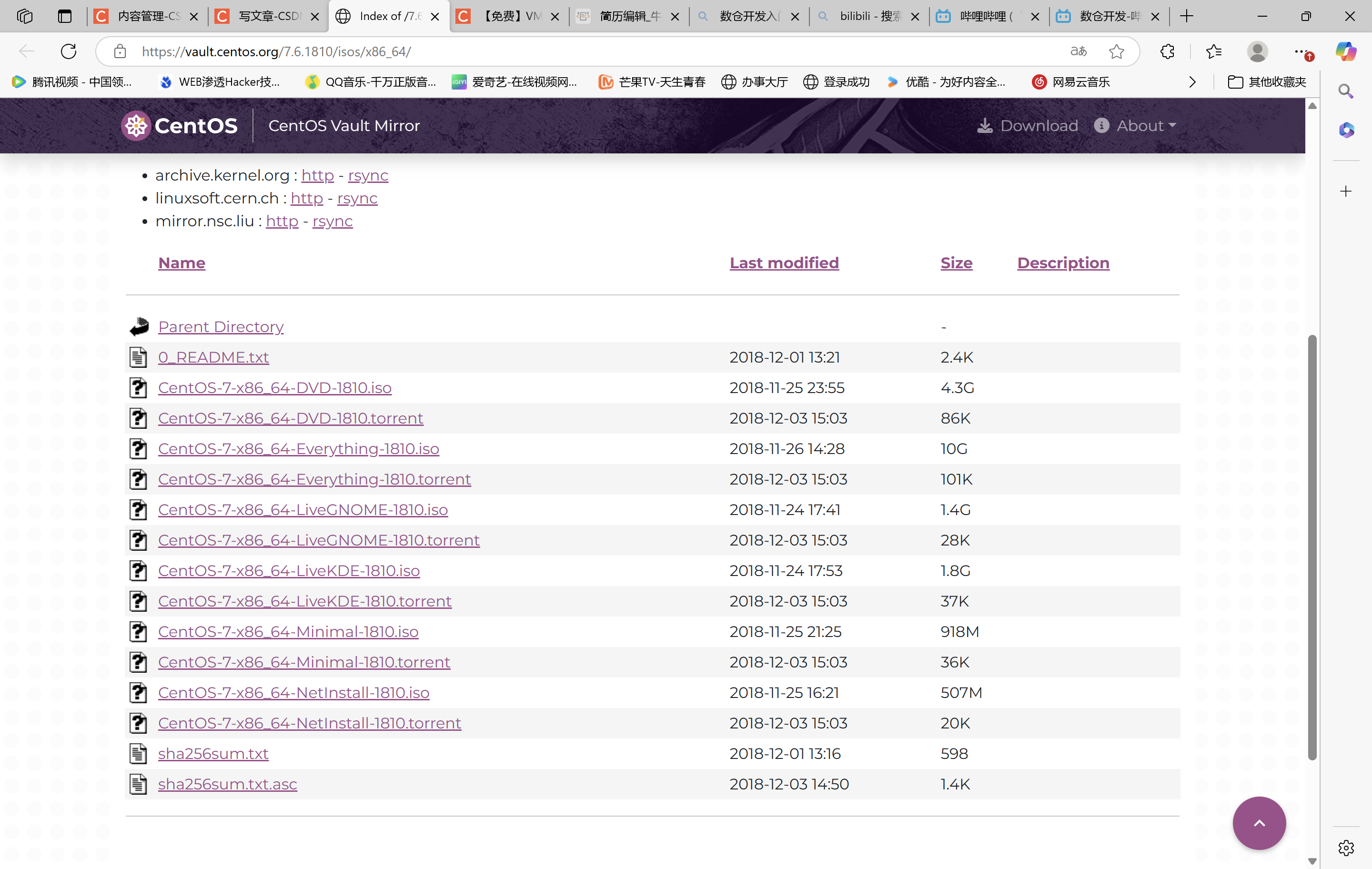
(2)下载镜像
我们需要下载对应的操作系统的安装文件,点击官网就可以直接点击自己电脑需要的版本进行下载了。
(3)安装镜像
打开虚拟机,点击创建新的虚拟机。
选择典型,继续下一步
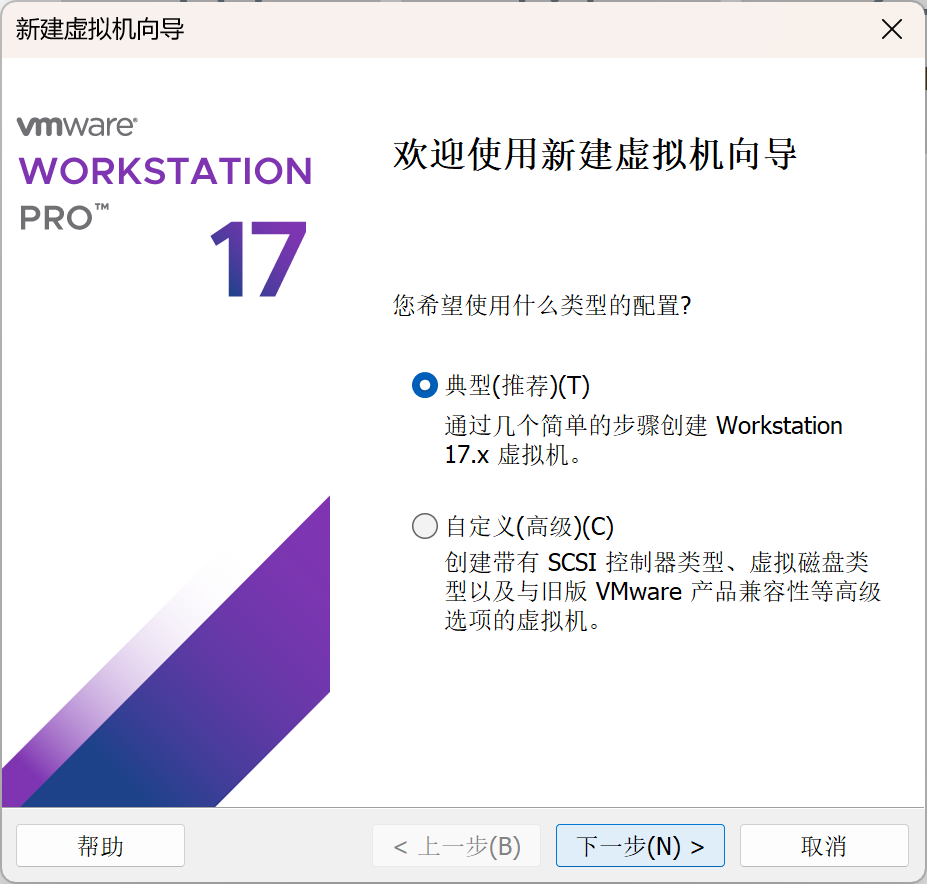
如下图所示,找到刚刚下载的镜像文件地址,点击下一步。
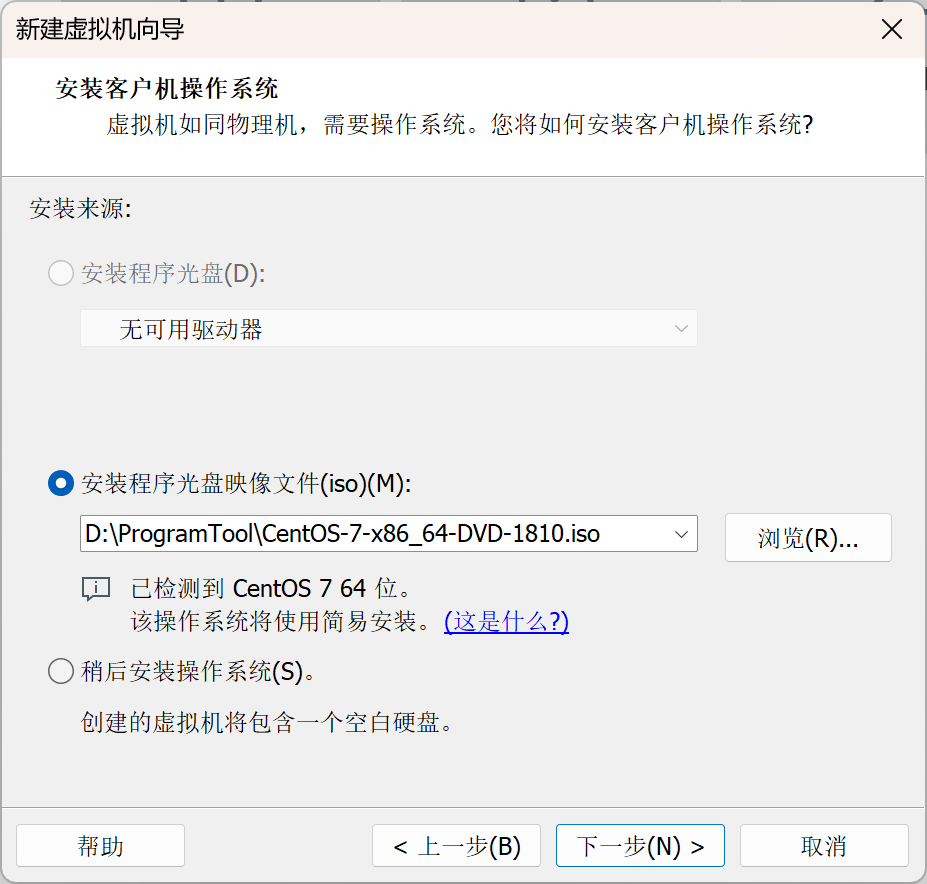
自定义账号和密码
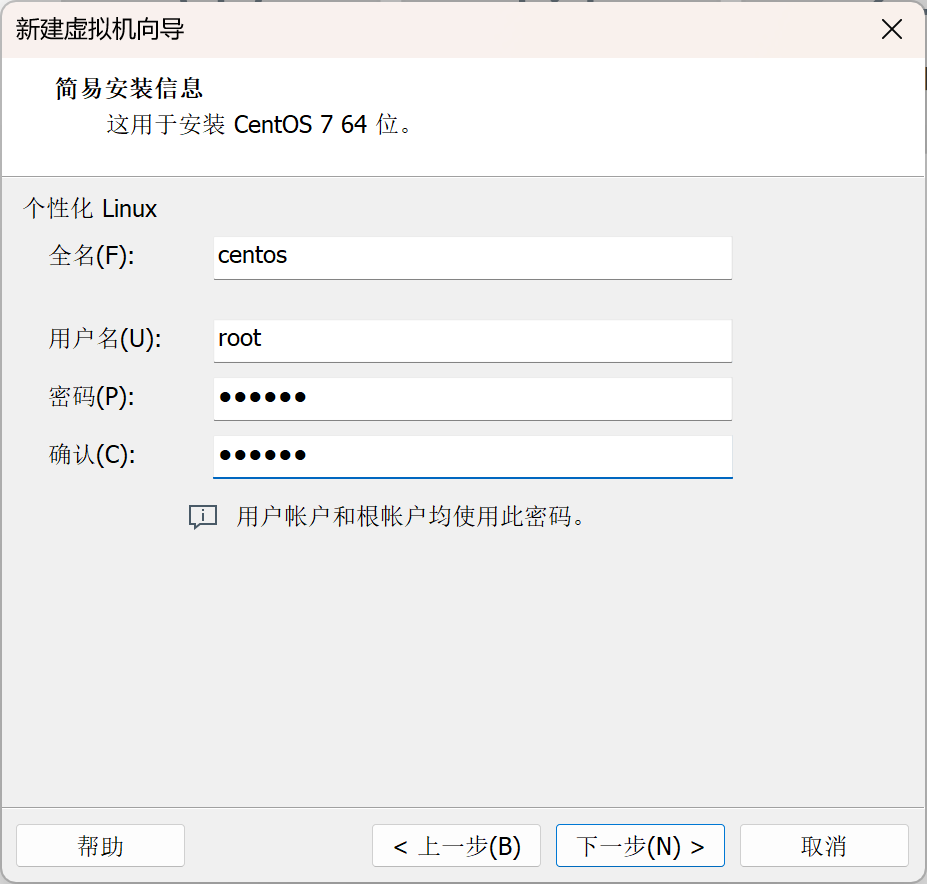
选择虚拟机存放的位置,自定义或者是系统默认都可以。
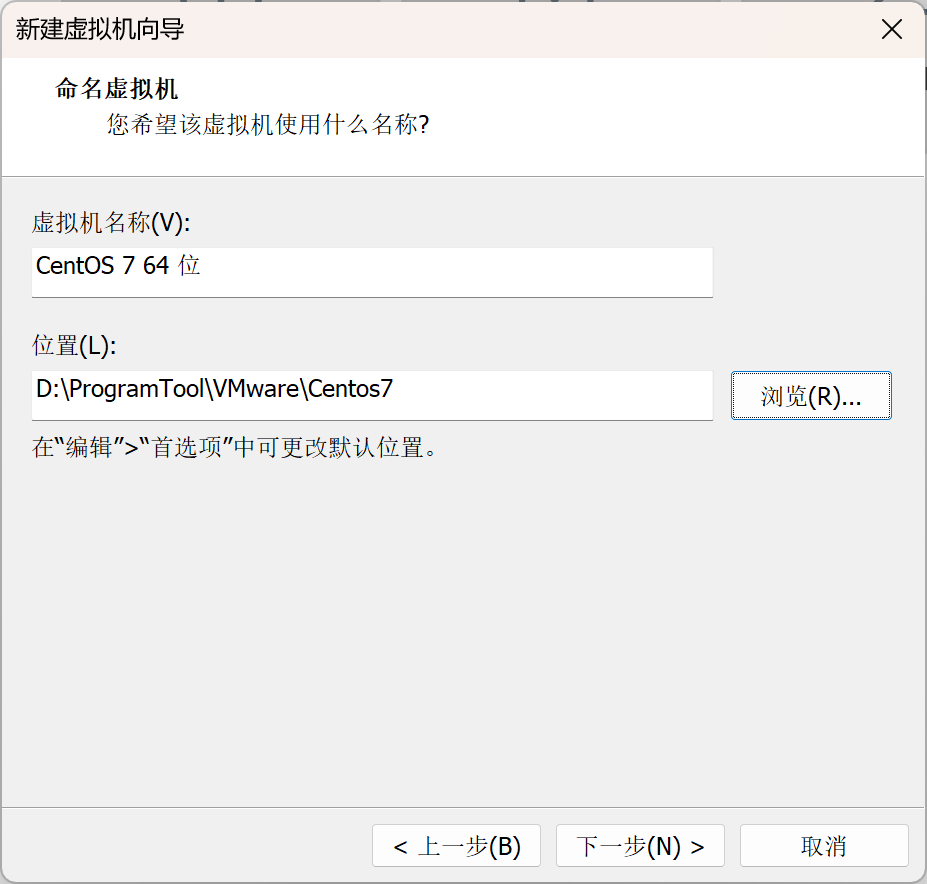
选择磁盘大小
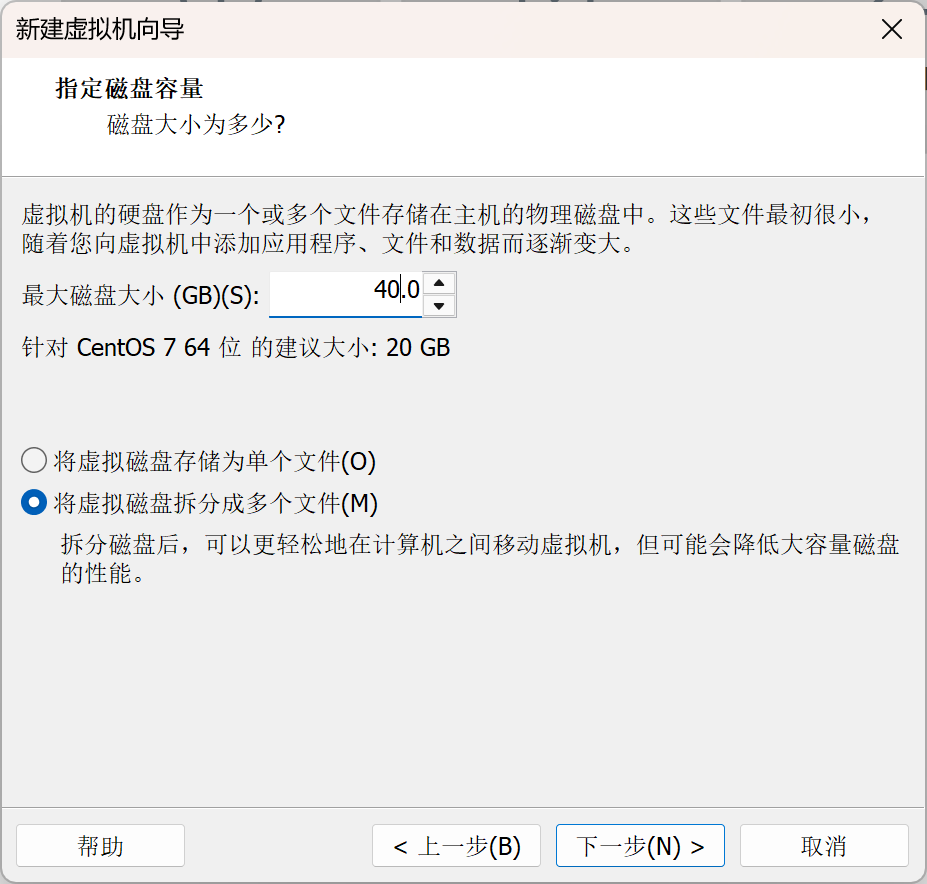
点击完成
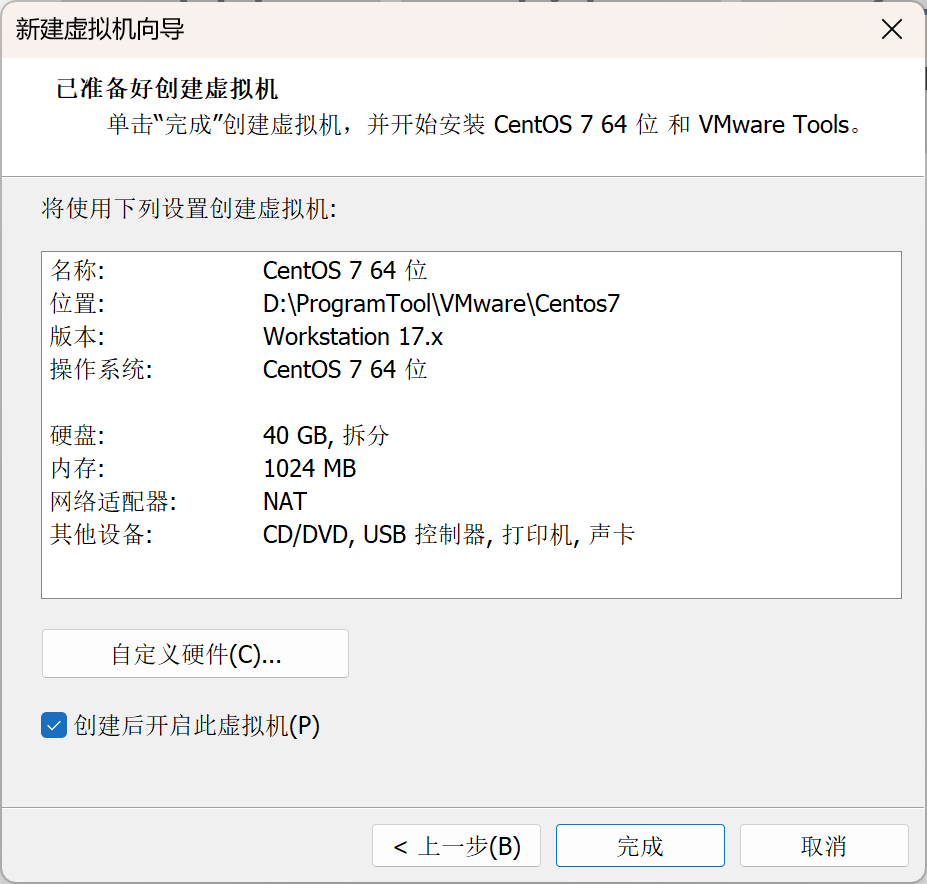
进入到虚拟机的安装中。
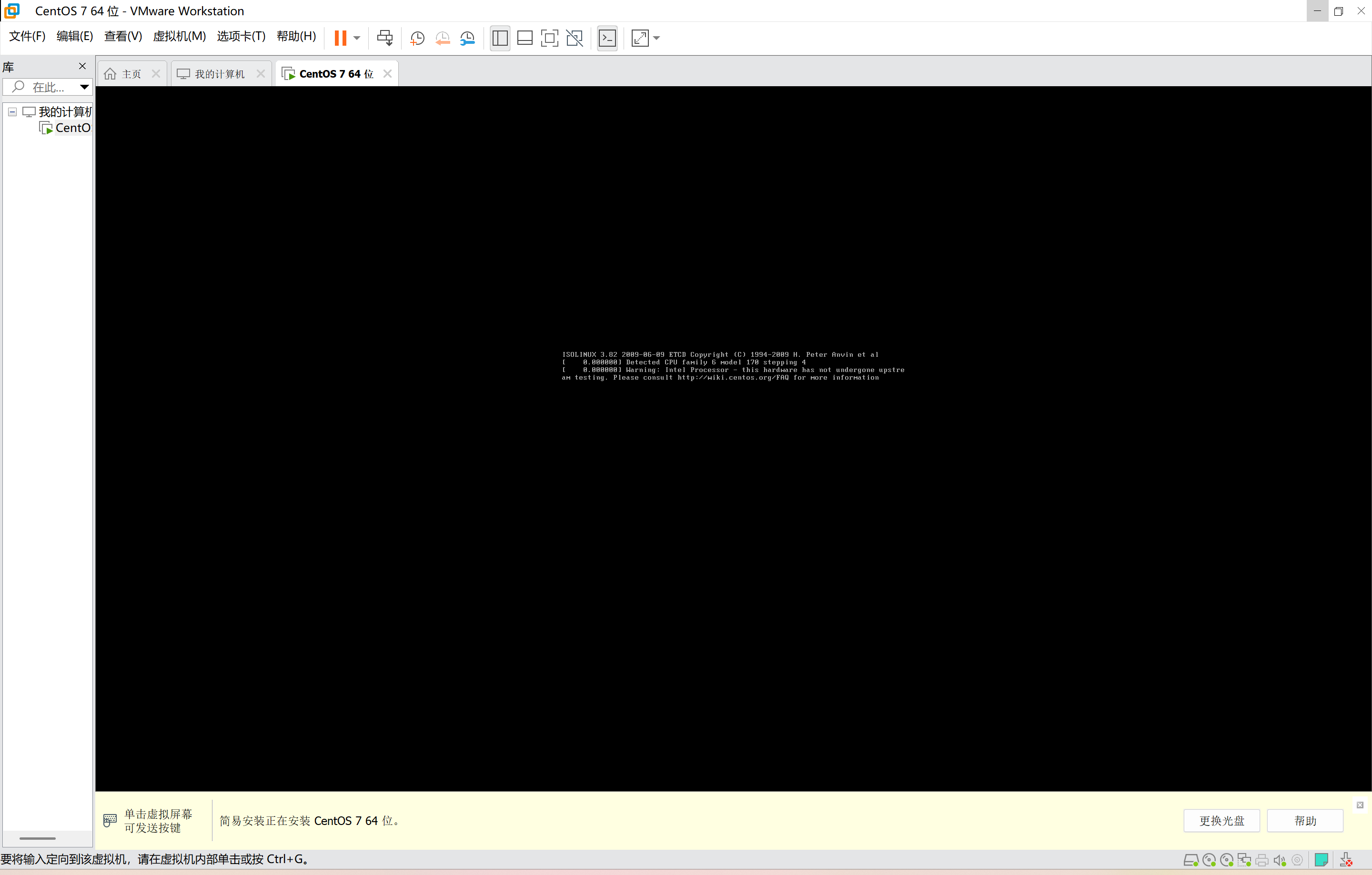
二、数据导论
1、数据是什么?
数据:一种可以被鉴定的对客观事件进行记录的符号。
简单来说就是:对人类的行为及产生的事件的一种记录。
2、数据的价值
数据的价值:数据的背后都会隐藏着巨大的价值,丰富的数据支撑可以让我们更好的了解,事和物在现实世界的运行规律。
大数据技术栈对超大规模的数据进行处理并挖掘出数据背后的价值的技术体系。
三、大数据的诞生
大数据的诞生和信息化以及互联网的发展是密切相关的。
早期的计算机(上世纪70年代之前)
大多数是互相独立的,各自处理各自的数据。
上世纪70年代后,逐步出现了基于TCP/IP协议的小规模的计算机互联互通。但大多数是军事、科研等用途。
上世纪90年代以后,全球互联的互联网出现。
个人、企业均可参与其中,真正逐步的实现了全球互联。
在2000年后,互联网上的商业行为剧增,现在知名的互联网公司(谷歌、AWS、腾讯、阿里等)也是在这个年代开始起步。在互联网参与者众多的前提下,商业公司、科研单位等,所能获得的数据量也是剧增。
剧增的数据量,和赢弱的单机性能,让许多的科技公司开始尝试以数量来解决问题。在这个过程中,分布式处理技术诞生了。
分布式处理技术——在数据量巨大的基础下,以服务器的数量来解决大规模数据处理问题。
大规模服务器集群下的大规模数据存储(存)
大规模服务器集群下的大规模数据计算(用)
大规模服务器集群下的大规模数据传输技术(传)
在2008年之前,这些在当时较为“高端”的分布式技术基本上还处于大企业内部专用且不够成熟。
在2008年,Apache Hadoop开源,广大企业拥有了成熟的、开源的、分布式数据处理解决方案。
基于这个前提逐步诞生了以分布式的形式(即多台服务器集群)完成海量数据处理的处理方式,并逐步发展成现代大数据体系。
Apache Hadoop是一款开源的分布式处理技术栈为业界提供了
- 基于Hadoop HDFS的:分布式数据存储技术
- 基于Hadoop MapReduce的:分布式数据计算技术
- 基于Hadoop YARN的:分布式资源调度技术
Apache Hadoop的出现具有非常重大的意义:
- 为业界提供了“第一款”企业级开源大数据分布式技术解决方案。
- 从Hadoop开始,大数据体系逐步建成,各类大数据技术不断出现。
四、大数据的概述
1、什么是大数据?
狭义的(技术思维的):大数据是一类技术栈,是一种用来处理海量数据的软件技术体系。
- 通过大数据的诞生,我们可以发现:大数据的出现,本质上是为了解决海量数据的处理难题。
- 大数据就是:使用分布式技术完成海量数据的处理,得到数据背后蕴含的价值。
广义的:大数据是数字化时代、信息化时代的基础(技术)支撑,以数据为生活赋能。
- 海量的数据:数字时代人人联网,日常活动产生数据记录是海量的,背后蕴含的价值也是巨大的。
- 基础设施:大数据在技术上,是数字化时代的基础设施。数字化时代的发展离不开大数据技术的支撑。
- 生活:警务、政务、电商。。。
2、大数据的特征
大数据有5个主要特征,称之为:5V特性
(1)Volume:体积(数据体量大)
- 采集数据量大
- 存储数据量大
- 计算数据量大
- TB、PB级别起步
(2)Varity:种类(来源多样化)
- 种类:结构化、半结构化、非结构化
- 来源:日志文本、图片、音频、视频
(3)Value:价值(低价值密度)
- 信息海量但是价值密度低
- 深度复杂的挖掘分析需要机器学习参与
(4)Velocity:速度(速度快)
- 数据增长速度快
- 获取数据速度快
- 数据处理速度快
(5)Veracity:质量(数据的质量)
- 数据的准确性
- 数据的可信赖度
3、大数据的核心工作
大数据的核心工作其实就是:从海量的高增长、多类别、低信息密度的数据中挖掘出高质量的结果。
- 数据存储:可以妥善存储海量待处理数据
- 数据计算:可以从海量数据中计算出背后的价值
- 数据传输:协助在各个环节中完成海量数据的传输
五、大数据软件生态
大数据软件生态:数据存储、数据计算、数据传输
1、数据存储
- Apache Hadoop - HDFS
Apache Hadoop框架内的组件HDFS是大数据体系中使用最为广泛的分布式存储技术。
- Apache HBase
Apache HBase 是大数据体系内使用非常广泛的NoSQL KV型数据库技术,HBase是基于HDFS之上构建的分布式系统。
- Apache KUDU
Apache KUDU 同样为大数据体系中使用较多的分布式存储引擎
- 云平台存储组件
除此以外,各大云平台厂商也有相应的大数据存储组件,如阿里云的OSS、UCloud的US3、AWS的S3、金山云的KS3等等。
2、数据计算
- Apache Hadoop -MapReduce
Apache Hadoop的MapReduce组件是最早一代的大数据分布式计算引擎对大数据的发展做出了卓越的贡献。
- Apache Hive
Apache Hive是一款以SQL为要开发语言的分布式计算框架。其底层使用了Hadoop的MapReduce技术
Apache Hive至今仍活跃在大数据一线,被许多公司使用。
- Apache Spark
Apache Spark是目前全球范围内最火热的分布式计算引擎。是大数据体系中的明星产品。
- Apache Flink
Apache Flink同样也是一款明星级的大数据分布式内存计算引擎。特别是在实时计算(流计算)领域,Flink占据了大多数的国内市场。
3、数据传输
- Apache Kafka
Apache Kafka是一款分布式的消息系统,可以完成海量规模的数据传输工作。Apache Kafka在大数据领域也是明星产品。
- Apache Pulsar
Apache Pulsar同样是一款分布式的消息系统,在大数据领域同样有非常多的使用者。
六、Hadoop的概述
1、什么是Hadoop?
Hadoop是Apache软件基金会下的顶级开源项目,用以提供:
- 分布式数据存储
- 分布式数据计算
- 分布式资源调度
为一体的整体解决方案。
Apache Hadoop是典型的分布式软件框架,可以部署在1台乃以成千上万台服务器节点上协调工作。
个人或企业可以借助Hadoop构建大规模服务器集群,完成海量数据的存储和计算。
2、Hadoop的功能
通常意义上,Hadoop是一个整体,其内部还会细分为三个功能组件:HDFS组件、MapReduce组件、YARN组件。



















