文章目录
- 🚀 消息队列系统设计与实践全解析
- 🔍 一、消息队列选型
- 1.1 业务场景匹配矩阵
- 1.2 吞吐量/延迟/可靠性权衡
- 💡 权衡决策框架
- 1.3 运维复杂度评估
- 🔧 运维成本降低策略
- 🏗️ 二、典型架构设计
- 2.1 分布式事务最终一致性
- 架构图解
- 实现要点
- 2.2 事件溯源模式
- 核心概念
- 实现示例
- 事件溯源的优势
- 2.3 CQRS架构实现
- 架构图解
- 实现示例
- CQRS的优势
- 🔧 三、监控与运维
- 3.1 核心监控指标
- 生产者指标
- Broker指标
- 消费者指标
- 监控实现示例
- 3.2 客户端配置优化
- Kafka生产者优化
- Kafka消费者优化
- 3.3 集群扩容方案
- 扩容前评估
- Kafka集群扩容步骤
- 无缝扩容最佳实践
- 🔮 未来趋势与总结
- 设计决策总结
🚀 消息队列系统设计与实践全解析
📢 编辑点评:消息队列已成为现代分布式系统的标配组件,但如何选型、设计架构和运维却是工程师们面临的三大挑战。本文将带你深入了解消息队列系统设计的核心要点,从选型决策到架构模式再到运维实践,全方位提升你的系统设计能力!
🔍 一、消息队列选型
在微服务架构大行其道的今天,消息队列的选择直接影响系统的可扩展性、可靠性和性能表现。如何在众多消息队列产品中选择最适合自己业务场景的方案?
1.1 业务场景匹配矩阵
不同的业务场景对消息队列有不同的需求,我们可以通过场景匹配矩阵来辅助决策:
| 业务场景 | 推荐消息队列 | 主要优势 | 典型应用 |
|---|---|---|---|
| 高吞吐量数据管道 | Kafka | 超高吞吐、持久化存储、数据流处理 | 日志收集、用户行为分析 |
| 复杂路由和工作流 | RabbitMQ | 灵活的交换机和路由机制、丰富的协议支持 | 订单处理流程、任务调度 |
| 简单解耦和削峰填谷 | Redis Streams | 轻量级、易部署、低延迟 | 应用解耦、请求缓冲 |
| 大规模云原生应用 | Pulsar | 多租户、存算分离、地理复制 | 跨区域消息同步、IoT数据处理 |
| 金融级可靠性要求 | RocketMQ | 事务消息、严格顺序、金融级可靠性 | 支付系统、交易平台 |
选型时,应该从业务场景出发,而不是盲目追求技术潮流。例如,对于电商订单系统,可能需要严格的消息顺序和事务支持,RocketMQ会是更好的选择;而对于日志收集分析系统,Kafka的高吞吐特性则更为重要。
1.2 吞吐量/延迟/可靠性权衡
消息队列的三大核心指标往往需要权衡取舍:
// 吞吐量优先配置示例 (Kafka Producer)
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 批量发送配置
props.put("batch.size", 16384);
props.put("linger.ms", 5);
// 压缩配置
props.put("compression.type", "snappy");
// 异步发送
props.put("acks", "1");
// 可靠性优先配置示例 (Kafka Producer)
Properties props = new Properties();
props.put("bootstrap.servers", "broker1:9092,broker2:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 可靠性配置
props.put("acks", "all");
props.put("retries", 3);
props.put("max.in.flight.requests.per.connection", 1);
// 幂等性配置
props.put("enable.idempotence", true);
💡 权衡决策框架
-
吞吐量优先场景:日志收集、监控数据、用户行为分析
- 选择:Kafka、Pulsar
- 配置重点:批量发送、压缩、异步确认
-
低延迟优先场景:实时推荐、即时通讯、实时监控告警
- 选择:Redis Streams、RabbitMQ
- 配置重点:小批量或无批处理、内存优先级
-
可靠性优先场景:支付交易、订单处理、金融记录
- 选择:RocketMQ、RabbitMQ (镜像队列)
- 配置重点:同步确认、事务消息、持久化存储
1.3 运维复杂度评估
选择消息队列时,不能只考虑功能和性能,还需要评估运维成本:
| 消息队列 | 部署复杂度 | 监控工具 | 运维挑战 | 社区活跃度 |
|---|---|---|---|---|
| Kafka | 中等 | Kafka Manager, Prometheus | 分区再平衡、磁盘管理 | 非常活跃 |
| RabbitMQ | 低 | 内置管理UI, Prometheus | 集群节点同步、内存压力 | 活跃 |
| RocketMQ | 中等 | 内置控制台, Prometheus | 主从同步、磁盘管理 | 较活跃 |
| Pulsar | 高 | Pulsar Manager, Prometheus | ZooKeeper依赖、BookKeeper管理 | 活跃增长中 |
| Redis Streams | 低 | Redis INFO, Prometheus | 内存管理、持久化策略 | 非常活跃 |
🔧 运维成本降低策略
- 容器化部署:使用Docker和Kubernetes简化部署和扩展
- 统一监控平台:集成Prometheus和Grafana实现统一监控
- 自动化运维:实现自动扩缩容、自动故障转移
- 云托管服务:考虑使用云厂商的托管消息服务
🏗️ 二、典型架构设计
消息队列不仅是一个中间件组件,更是构建复杂分布式系统的核心基础设施。以下是三种基于消息队列的典型架构模式。
2.1 分布式事务最终一致性
在分布式系统中,跨服务的事务一致性是一个经典难题。基于消息队列的最终一致性方案是一种实用的解决方案。
架构图解
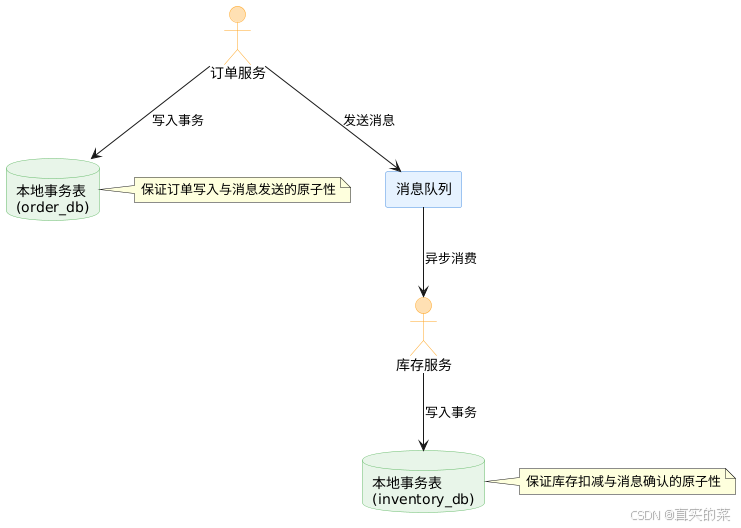
实现要点
-
本地消息表模式:
@Transactional public void createOrder(Order order) { // 1. 创建订单(本地事务) orderRepository.save(order); // 2. 写入本地消息表(同一事务) MessageRecord message = new MessageRecord(); message.setTopic("order-created"); message.setPayload(JSON.toJSONString(order)); message.setStatus(MessageStatus.PENDING); messageRepository.save(message); } -
消息投递服务:
@Scheduled(fixedDelay = 1000) public void deliverMessages() { List<MessageRecord> pendingMessages = messageRepository.findByStatus(MessageStatus.PENDING); for (MessageRecord message : pendingMessages) { try { // 发送消息到消息队列 kafkaTemplate.send(message.getTopic(), message.getPayload()); // 更新消息状态 message.setStatus(MessageStatus.DELIVERED); messageRepository.save(message); } catch (Exception e) { // 发送失败,记录重试次数 message.setRetryCount(message.getRetryCount() + 1); messageRepository.save(message); } } } -
消费者幂等处理:
@KafkaListener(topics = "order-created") public void handleOrderCreated(String payload) { Order order = JSON.parseObject(payload, Order.class); String messageId = order.getOrderId(); // 检查是否已处理过该消息(幂等性保证) if (processedMessageRepository.existsById(messageId)) { log.info("Message already processed: {}", messageId); return; } try { // 执行库存扣减逻辑 inventoryService.reduceInventory(order.getProductId(), order.getQuantity()); // 记录消息已处理 processedMessageRepository.save(new ProcessedMessage(messageId)); } catch (Exception e) { // 处理失败,记录异常,等待重试 log.error("Failed to process message: {}", messageId, e); throw e; // 重新抛出异常,触发消息重试 } }
2.2 事件溯源模式
事件溯源(Event Sourcing)是一种将系统状态变化记录为一系列事件的设计模式,特别适合与消息队列结合使用。
核心概念
- 事件(Event):系统中发生的所有状态变化
- 事件存储(Event Store):持久化存储所有事件的仓库
- 聚合(Aggregate):通过重放事件重建的业务实体
- 投影(Projection):基于事件流构建的读模型
实现示例
// 1. 事件定义
public interface DomainEvent {
String getAggregateId();
long getVersion();
LocalDateTime getTimestamp();
}
public class OrderCreatedEvent implements DomainEvent {
private String orderId;
private String customerId;
private List<OrderItem> items;
private long version;
private LocalDateTime timestamp;
// getters and setters
}
// 2. 事件存储
public interface EventStore {
void save(DomainEvent event);
List<DomainEvent> getEvents(String aggregateId);
}
// 3. 聚合根
public class Order {
private String orderId;
private String customerId;
private List<OrderItem> items;
private OrderStatus status;
private long version;
// 通过事件重建状态
public static Order recreateFrom(List<DomainEvent> events) {
Order order = new Order();
for (DomainEvent event : events) {
order.apply(event);
}
return order;
}
private void apply(DomainEvent event) {
if (event instanceof OrderCreatedEvent) {
applyOrderCreatedEvent((OrderCreatedEvent) event);
} else if (event instanceof OrderPaidEvent) {
applyOrderPaidEvent((OrderPaidEvent) event);
}
// 更新版本号
this.version = event.getVersion();
}
private void applyOrderCreatedEvent(OrderCreatedEvent event) {
this.orderId = event.getOrderId();
this.customerId = event.getCustomerId();
this.items = event.getItems();
this.status = OrderStatus.CREATED;
}
// 其他事件应用方法...
}
事件溯源的优势
- 完整的审计跟踪:系统的每一次状态变化都有记录
- 时间旅行能力:可以重建任意时间点的系统状态
- 事件驱动架构的自然契合:与消息队列完美结合
- 业务逻辑与存储解耦:降低系统复杂度
2.3 CQRS架构实现
CQRS(Command Query Responsibility Segregation,命令查询责任分离)是一种将系统的读操作和写操作分离的架构模式,特别适合与消息队列和事件溯源结合使用。
架构图解
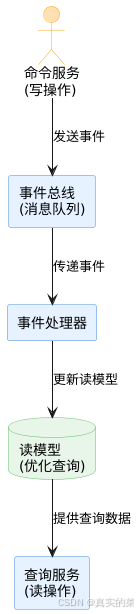
实现示例
// 1. 命令处理器(写模型)
@Service
public class OrderCommandService {
private final EventBus eventBus;
private final EventStore eventStore;
@Transactional
public void createOrder(CreateOrderCommand command) {
// 验证命令
validateCommand(command);
// 创建事件
OrderCreatedEvent event = new OrderCreatedEvent(
UUID.randomUUID().toString(),
command.getCustomerId(),
command.getItems(),
1L,
LocalDateTime.now()
);
// 保存事件
eventStore.save(event);
// 发布事件到消息队列
eventBus.publish("order-events", event);
}
}
// 2. 事件处理器(更新读模型)
@Service
public class OrderEventHandler {
private final OrderReadRepository readRepository;
@KafkaListener(topics = "order-events")
public void handleOrderEvent(String eventJson) {
DomainEvent event = deserializeEvent(eventJson);
if (event instanceof OrderCreatedEvent) {
updateReadModel((OrderCreatedEvent) event);
}
// 处理其他类型事件...
}
private void updateReadModel(OrderCreatedEvent event) {
OrderReadModel readModel = new OrderReadModel();
readModel.setOrderId(event.getAggregateId());
readModel.setCustomerId(event.getCustomerId());
readModel.setItems(event.getItems());
readModel.setStatus("CREATED");
readModel.setCreatedAt(event.getTimestamp());
readRepository.save(readModel);
}
}
// 3. 查询服务(读模型)
@Service
public class OrderQueryService {
private final OrderReadRepository readRepository;
public OrderReadModel getOrder(String orderId) {
return readRepository.findById(orderId)
.orElseThrow(() -> new OrderNotFoundException(orderId));
}
public List<OrderReadModel> getCustomerOrders(String customerId) {
return readRepository.findByCustomerId(customerId);
}
}
CQRS的优势
- 读写性能优化:可以针对读写场景分别优化
- 扩展性提升:读写服务可以独立扩展
- 模型复杂度降低:读写关注点分离
- 与事件溯源的自然结合:写操作产生事件,读模型消费事件
🔧 三、监控与运维
消息队列系统的稳定运行离不开完善的监控和运维体系。
3.1 核心监控指标
有效的监控是发现问题的第一道防线,以下是消息队列系统必须监控的核心指标:
生产者指标
- 生产速率:每秒发送消息数(msg/s)
- 平均消息大小:单条消息的平均字节数
- 发送延迟:从发送到确认的时间
- 错误率:发送失败的消息比例
Broker指标
- 积压量:未被消费的消息数量
- 磁盘使用率:存储空间占用情况
- 分区不平衡度:各分区负载差异
- GC暂停时间:垃圾回收对服务的影响
消费者指标
- 消费延迟:消费滞后时间
- 处理速率:每秒处理消息数
- 重平衡频率:消费者组重新分配的频率
- 处理错误率:消息处理失败比例
监控实现示例
// 使用Micrometer监控Kafka消费者延迟
@Configuration
public class KafkaMetricsConfig {
private final MeterRegistry meterRegistry;
@Scheduled(fixedRate = 30000) // 每30秒执行一次
public void reportConsumerLag() {
Map<TopicPartition, Long> currentOffsets = getCurrentOffsets();
Map<TopicPartition, Long> endOffsets = getEndOffsets();
for (Map.Entry<TopicPartition, Long> entry : currentOffsets.entrySet()) {
TopicPartition tp = entry.getKey();
Long currentOffset = entry.getValue();
Long endOffset = endOffsets.get(tp);
if (endOffset != null) {
long lag = endOffset - currentOffset;
// 记录延迟指标
meterRegistry.gauge(
"kafka.consumer.lag",
Tags.of(
"topic", tp.topic(),
"partition", String.valueOf(tp.partition()),
"consumer_group", consumerGroup
),
lag
);
}
}
}
}
3.2 客户端配置优化
消息队列的性能很大程度上取决于客户端的配置。以下是一些关键的优化参数:
Kafka生产者优化
// 高吞吐量生产者配置
Properties props = new Properties();
// 批处理优化
props.put("batch.size", 64 * 1024); // 64KB批次大小
props.put("linger.ms", 10); // 等待10ms收集更多消息
// 缓冲区优化
props.put("buffer.memory", 64 * 1024 * 1024); // 64MB缓冲区
// 压缩优化
props.put("compression.type", "lz4"); // 使用LZ4压缩
// 网络优化
props.put("max.in.flight.requests.per.connection", 5);
props.put("connections.max.idle.ms", 180000); // 3分钟
// 重试优化
props.put("retries", 3);
props.put("retry.backoff.ms", 100);
Kafka消费者优化
// 高吞吐量消费者配置
Properties props = new Properties();
// 批量拉取优化
props.put("max.poll.records", 500); // 每次拉取500条消息
props.put("fetch.min.bytes", 1024 * 1024); // 至少拉取1MB数据
props.put("fetch.max.wait.ms", 500); // 最多等待500ms
// 提交优化
props.put("enable.auto.commit", "false"); // 手动提交
props.put("auto.commit.interval.ms", 5000); // 自动提交间隔
// 会话优化
props.put("heartbeat.interval.ms", 3000); // 3秒心跳
props.put("session.timeout.ms", 30000); // 30秒会话超时
props.put("max.poll.interval.ms", 300000); // 5分钟处理超时
3.3 集群扩容方案
随着业务增长,消息队列集群的扩容是不可避免的。以下是一套完整的扩容方案:
扩容前评估
-
容量规划:
- 当前消息量:每秒消息数 × 平均消息大小
- 存储需求:日消息量 × 保留天数 × 副本数 × 1.5(冗余系数)
- 处理能力:单节点处理上限 × 节点数
-
性能瓶颈分析:
- CPU使用率:是否超过70%
- 磁盘I/O:是否接近饱和
- 网络带宽:是否接近上限
- JVM内存:GC频率是否正常
Kafka集群扩容步骤
# 1. 准备新节点
# 安装JDK和Kafka
scp kafka_2.13-3.3.1.tgz new-broker:/opt/
ssh new-broker "tar -xzf /opt/kafka_2.13-3.3.1.tgz -C /opt/"
# 2. 配置新节点
scp server.properties new-broker:/opt/kafka/config/
ssh new-broker "sed -i 's/broker.id=0/broker.id=3/g' /opt/kafka/config/server.properties"
# 3. 启动新节点
ssh new-broker "/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties"
# 4. 重新分配分区
cat > reassign.json << EOF
{
"version": 1,
"partitions": [
{"topic": "important-topic", "partition": 0, "replicas": [0,1,3]},
{"topic": "important-topic", "partition": 1, "replicas": [1,2,3]},
{"topic": "important-topic", "partition": 2, "replicas": [2,0,3]}
]
}
EOF
/opt/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server kafka:9092 \
--reassignment-json-file reassign.json --execute
# 5. 验证重分配状态
/opt/kafka/bin/kafka-reassign-partitions.sh --bootstrap-server kafka:9092 \
--reassignment-json-file reassign.json --verify
无缝扩容最佳实践
-
分批扩容:每次只增加少量节点,观察系统稳定性
-
错峰操作:选择业务低峰期进行扩容操作
-
自动化工具:使用Kafka Manager或Cruise Control自动平衡负载
-
监控加强:扩容期间加强监控频率,及时发现问题
-
回滚预案:制定详细的回滚方案,以应对扩容失败
-
容量预留:扩容后预留30%容量,应对突发流量
🔮 未来趋势与总结
消息队列技术正在快速发展,以下是值得关注的几个趋势:
- 云原生化:与Kubernetes深度集成,实现自动化运维
- 存算分离:计算节点和存储节点分离,实现独立扩展
- 多协议支持:单一消息系统支持多种协议(MQTT、AMQP、Kafka Protocol)
- 流批一体化:消息队列与流处理引擎的融合
- 全球化部署:跨区域、跨云的消息同步机制
设计决策总结
在消息队列系统设计中,需要平衡以下几个关键因素:
- 功能 vs. 性能:丰富的功能通常意味着更高的复杂度和更低的性能
- 一致性 vs. 可用性:强一致性会影响系统可用性和性能
- 复杂度 vs. 可维护性:过于复杂的架构会增加运维难度
- 成本 vs. 可靠性:更高的可靠性通常需要更多的资源投入
最佳的消息队列系统设计应该是业务需求、技术能力和资源约束的平衡点。
💻 关注我的更多技术内容
如果你喜欢这篇文章,别忘了点赞、收藏和分享!有任何问题,欢迎在评论区留言讨论!
本文首发于我的技术博客,转载请注明出处
![ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]](https://i-blog.csdnimg.cn/direct/e5a0413d5a534d7884b4716bb433432c.png#pic_center)