目录
分片
一、分片的本质与核心价值
二、分片实现方案对比
三、分片算法详解
1. 范围分片(顺序分片)
2. 哈希分片
3. 虚拟槽分片(Redis Cluster 方案)
四、Redis Cluster 分片实践要点
五、经典问题解析
Cluster模式配置
一、Cluster 核心配置参数
二、集群部署全流程
1. 节点初始化
2. 集群创建命令
3. 集群验证
三、关键运维操作
1. 节点扩容
2. 故障转移模拟
3. 集群修复
四、高级配置建议
五、常见问题解决
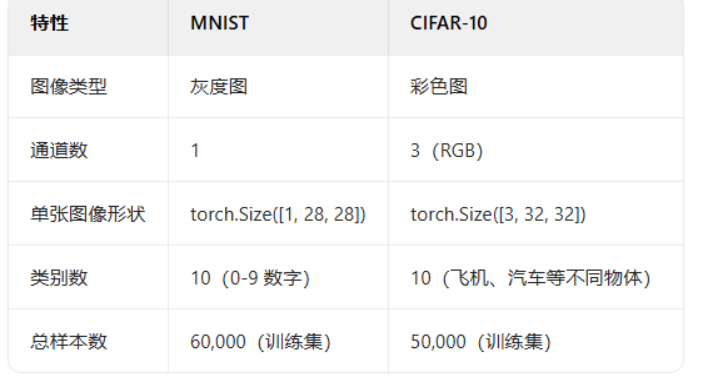
各模式优缺点
一、主从复制模式
二、哨兵模式(Sentinel)
三、Cluster模式(分布式集群)
四、对比表格
分片
一、分片的本质与核心价值
-
问题根源
单机 Redis 存在内存容量和吞吐量瓶颈,分片通过将数据分散到多个节点解决此问题。 -
核心价值
- 横向扩展:突破单机内存限制,支持 TB 级数据存储。
- 负载均衡:多节点并行处理请求,提升并发能力(如百万级 QPS)。
- 故障隔离:单节点故障仅影响其负责的数据分片。
- 资源优化:支持冷热数据分离存储(如 SSD/HDD 混合部署)。
二、分片实现方案对比
| 方案 | 工作原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 客户端分片 | 客户端计算键的哈希值,直接路由到目标节点(如取模或一致性哈希) | 无代理层,架构简单 | 节点变更需客户端调整,扩容复杂 | 小规模固定集群 |
| 代理分片 | 通过中间件(如 Twemproxy)接收请求,由代理计算分片并转发 | 客户端无感知,屏蔽分片细节 | 代理层可能成为性能瓶颈 | 需兼容旧客户端的场景 |
| 服务端分片(Redis Cluster) | 节点间通过 Gossip 协议同步槽位信息,客户端请求由服务端重定向(MOVED 指令) | 自动故障转移、支持动态扩缩容 | 不支持跨槽事务和多键操作 | 生产环境首选方案 |
三、分片算法详解
1. 范围分片(顺序分片)
- 原理:按数据范围划分(如 ID 1-10000 → 节点A,10001-20000 → 节点B)。
- 优点:支持高效范围查询(如
ZRANGE)和批量操作。 - 缺点:数据分布易倾斜,扩容时需迁移大量数据。
2. 哈希分片
- 哈希求余:
hash(key) % N确定节点,扩容时需迁移所有数据(N 变化导致重新映射)。 - 一致性哈希:
- 哈希环结构,节点增减仅影响相邻数据。
- 解决扩容痛点,但仍有数据倾斜风险。
3. 虚拟槽分片(Redis Cluster 方案)
- 核心机制:
- 预分配 16384 个哈希槽(slot),每个节点负责部分槽位。
- 槽位计算:
slot = CRC16(key) mod 16384。
- 动态扩缩容:
- 添加节点时,从现有节点迁移部分槽位到新节点。
- 删除节点时,将其槽位分配给其他节点。
- 优势:
- 数据分布均匀,避免热点问题。
- 槽位迁移原子操作,不影响集群可用性。
四、Redis Cluster 分片实践要点
-
集群要求
- 至少 3 个主节点(推荐 3 主 3 从)。
- 所有节点通过集群总线端口通信(Redis端口 + 10000)。
-
数据迁移命令
# 将槽位 1000 从节点 A 迁移到节点 B redis-cli --cluster reshard <节点A_IP>:<端口> --cluster-from <节点A_ID> --cluster-to <节点B_ID> --cluster-slots 1000 -
客户端交互
- 客户端连接任意节点,若请求的键不属于当前节点,返回
MOVED <slot> <目标节点IP>:<端口>重定向指令。 - 智能客户端(如 Lettuce)可缓存槽位映射表,减少重定向次数。
- 客户端连接任意节点,若请求的键不属于当前节点,返回
五、经典问题解析
-
为何使用 16384 槽?
- 集群心跳包携带全量槽分配信息,
16384(16KB)在带宽与数据粒度间取得平衡。 - 超过 16384 易导致网络拥堵。
- 集群心跳包携带全量槽分配信息,
-
分片下的限制
- 跨槽的多键操作(如
MSET、事务)需确保所有键在同一槽位,可通过 HashTag 强制绑定:MSET {user:1000}.name "Alice" {user:1000}.age 30 # 使用相同 HashTag
- 跨槽的多键操作(如
总结:Redis 分片是分布式系统的核心技术,虚拟槽方案(Redis Cluster)凭借自动分片、故障转移和动态扩缩容能力,成为生产环境首选。设计时需关注数据均衡性、扩容成本及跨分片操作限制
Cluster模式配置
一、Cluster 核心配置参数
-
基础配置(
redis.conf)cluster-enabled yes # 启用集群模式 cluster-config-file nodes-6379.conf # 节点自动生成的集群配置文件 cluster-node-timeout 15000 # 节点失联判定时间(毫秒) cluster-replica-validity-factor 10 # 从节点有效性因子(超时倍数) cluster-migration-barrier 1 # 主节点最少保留的从节点数cluster-node-timeout影响故障转移速度,建议生产环境设为 15-30 秒。cluster-migration-barrier防止主节点因从节点不足导致数据不可用。
-
网络与安全
bind 0.0.0.0 # 允许所有IP访问 protected-mode no # 关闭保护模式(需配合密码) requirepass yourpassword # 集群密码(所有节点需一致) masterauth yourpassword # 主从认证密码- 集群总线端口需开放(默认:Redis端口 + 10000)。
-
数据持久化
appendonly yes # 开启AOF持久化 appendfsync everysec # 折衷性能与数据安全
二、集群部署全流程
1. 节点初始化
# 启动6个节点(3主3从) redis-server /path/to/redis-7000.conf # 端口7000-7005 2. 集群创建命令
redis-cli --cluster create \
192.168.1.1:7000 192.168.1.1:7001 192.168.1.1:7002 \
192.168.1.1:7003 192.168.1.1:7004 192.168.1.1:7005 \
--cluster-replicas 1 \
--cluster-yes --cluster-replicas 1表示每个主节点配1个从节点。- 执行后自动分配16384个槽位(每个主节点约5461个槽)。
3. 集群验证
redis-cli -c -p 7000 cluster nodes # 查看节点角色及槽分布
redis-cli -p 7000 cluster info # 检查集群健康状态 三、关键运维操作
1. 节点扩容
# 添加新主节点
redis-cli --cluster add-node 192.168.1.2:7006 192.168.1.1:7000
# 迁移槽位(交互式)
redis-cli --cluster reshard 192.168.1.1:7000 - 扩容后需手动平衡槽位,避免热点问题58。
2. 故障转移模拟
# 手动触发主从切换(在从节点执行) redis-cli -p 7003 CLUSTER FAILOVER 3. 集群修复
# 修复孤儿槽(无主节点的槽) redis-cli --cluster fix 192.168.1.1:7000 四、高级配置建议
-
槽位分配优化
- 使用
CLUSTER SETSLOT手动调整槽位分布,避免数据倾斜。 - 监控槽位命中率:
redis-cli --cluster check 192.168.1.1:7000。
- 使用
-
客户端连接策略
- 智能客户端(如 Lettuce)应缓存槽位映射表,减少
MOVED重定向。 - 避免跨槽事务,优先使用 HashTag 绑定相关键:
{user1000}.profile。
- 智能客户端(如 Lettuce)应缓存槽位映射表,减少
-
监控指标
指标 监控命令 告警阈值 节点状态 CLUSTER NODES任何节点不可达 槽位覆盖率 CLUSTER INFO的cluster_slots_ok必须为 16384 内存使用率 INFO MEMORY>80% 触发告警
五、常见问题解决
-
节点无法加入集群
- 检查防火墙是否放行集群总线端口。
- 确认所有节点
requirepass和masterauth一致。
-
槽位迁移卡顿
- 增大
cluster-node-timeout减少网络抖动影响。 - 使用
--cluster-replace强制替换故障节点。
- 增大
-
数据不一致
- 从节点同步延迟可通过
INFO REPLICATION查看slave_repl_offset。
- 从节点同步延迟可通过
通过以上配置与运维策略,可构建高可用的 Redis Cluster 环境。实际部署时需结合监控工具(如 Prometheus)持续观察集群状态。
各模式优缺点
一、主从复制模式
优点
- 读写分离提升读性能,从节点分担主节点压力
- 配置简单,仅需在从节点设置
replicaof指令 - 数据冗余提高容灾能力
缺点
- 主节点单点故障需手动切换
- 写性能受限于主节点,无法横向扩展
- 全量同步时网络开销大
二、哨兵模式(Sentinel)
优点
- 自动监控与故障转移,解决主从模式手动切换问题
- 支持多哨兵部署,避免监控节点单点故障
- 客户端自动感知主节点变化
缺点
- 扩容仍需手动操作,无法自动分片
- 故障转移期间可能出现数据丢失
- 配置复杂度高于主从模式
三、Cluster模式(分布式集群)
优点
- 数据自动分片(16384槽),支持TB级数据存储
- 无中心架构,节点间通过Gossip协议通信
- 支持动态扩缩容与自动故障转移
缺点
- 不支持跨节点事务和多键操作(需HashTag绑定)
- 运维复杂度高,需管理槽位迁移与节点状态
- 客户端需支持集群协议(如MOVED重定向)
四、对比表格
| 模式 | 数据分片 | 自动故障转移 | 读写扩展性 | 适用场景 |
|---|---|---|---|---|
| 主从复制 | ❌ | ❌ | 读扩展 | 读多写少,容灾备份 |
| 哨兵模式 | ❌ | ✔️ | 读扩展 | 高可用但数据量中等 |
| Cluster模式 | ✔️ | ✔️ | 读写扩展 | 海量数据与高并发场景 |