一.项目创建
- 在想要将项目创键的目录下,输入cmd (进入命令提示符)
- 在cmd中输入:Django-admin startproject 项目名称 (创建项目)
- cd 项目名称 (进入项目)
- Django-admin startapp 程序名称 (创建程序)
- python manage.py runserver 8080 (运行程序)
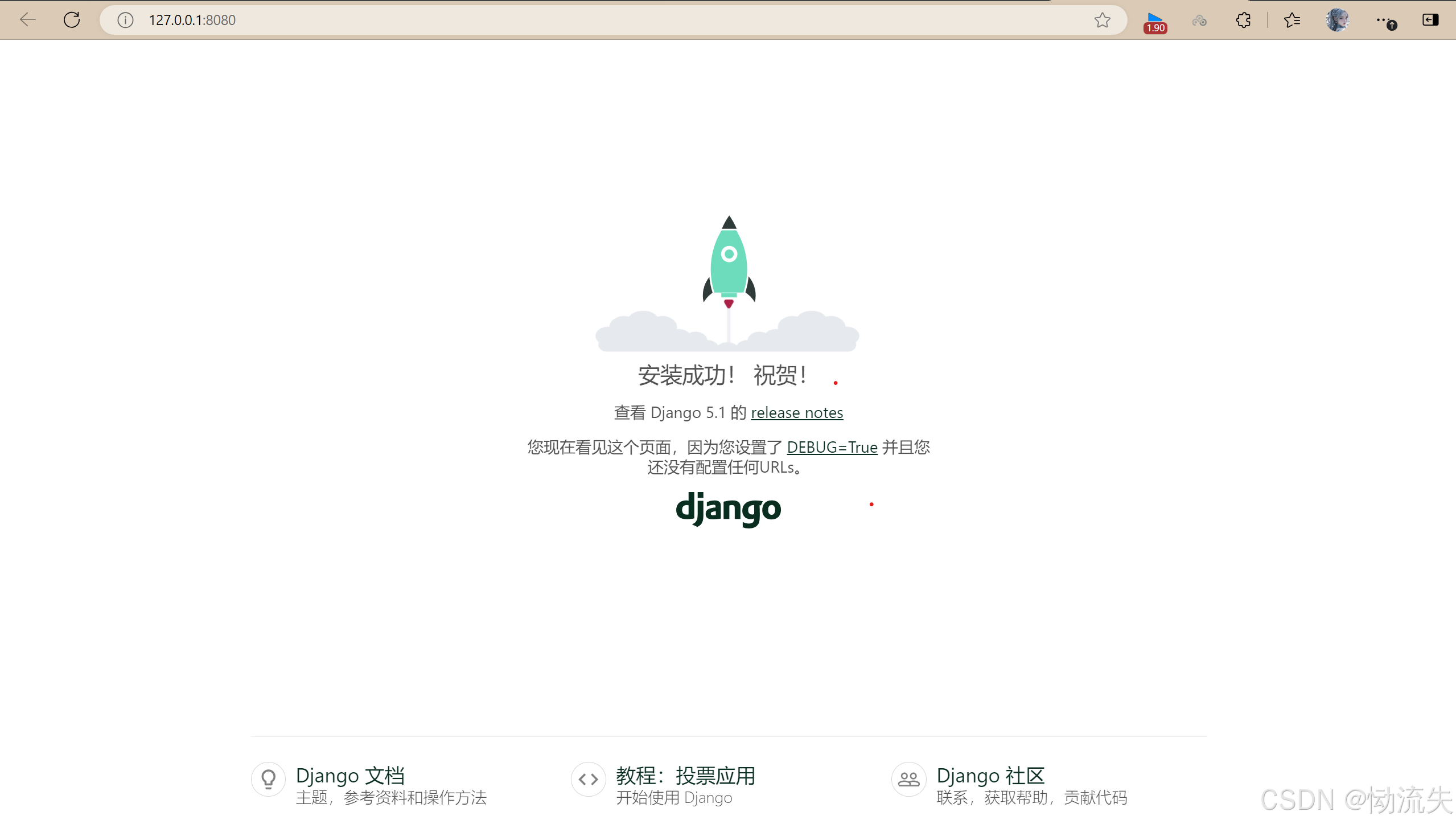
- 将弹出的网址复制到浏览器中http://127.0.0.1:8080/
当出现这个界面时说明运行成功了
二.设置settings
一.installed_apps
在INSTALLED_APPS中将我们创建的myday程序名称输入
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'myday'
]二.templates
在根目录下创建templates文件夹,并将TEMPLATES中的'DIRS'修改为如图所示
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR,'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
三.databases
在DATABASES中按如下格式输入,将数据库改为MYSQL数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '数据库名',
'USER': 'root',
'PASSWORD': 'MYSQL密码',
'HOST': '127.0.0.1',
'PORT': '3306',
}
}注意:因为在python3中mysql改名为pymysql所以需要在主目录下的_init_中输入
import pymysql
pymysql.install_as_MySQLdb()四.汉化
最后这样进行汉化处理
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/shanghai'三.模型类设置
1.字段类型
- AutoField:自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性
- BooleanField:布尔字段,值为True或False
- NullBooleanField:支持Null、True、False三种值
- CharField(max_length=字符长度):字符串,必选 参数max_length表示最大字符个数
- TextField:大文本字段,一般超过4000个字符时使用
- IntegerField:整数
- DecimalField(max_digits=None, decimal_places=None):十进制浮点数参数max_digits表示总位数,参数decimal_places表示小数位数
- FloatField:浮点数
- DateField[auto_now=False, auto_now_add=False]):日期 参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false,参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false,参数auto_now_add和auto_now是相互排斥的,组合将会发生错误
- TimeField:时间,参数同DateField
- DateTimeField:日期时间,参数同DateField
- FileField:上传文件字段
- ImageField:继承于FileField,对上传的内容进行校验,确保是有效的图片
关系型数据库的关系包括三种类型:
- ForeignKey:一对多,将字段定义在多的一端中
- ManyToManyField:多对多,将字段定义在两端中
- OneToOneField:一对一,将字段定义在任意一端中
2.定义模型-models
from django.db import models
# Create your models here.
class Tag(models.Model):
Tag_name = models.CharField(max_length=50, unique=True)
def __str__(self):
return self.Tag_name
class Meta:
verbose_name_plural = '标签名'
class Category(models.Model):
Category_name = models.CharField(max_length=50, unique=True)
def __str__(self):
return self.Category_name
class Meta:
verbose_name_plural = '分类名'
class Post(models.Model):
title = models.CharField("题目", max_length=50, unique=True)
content = models.TextField("内容")
author = models.CharField("作者", max_length=200, default="郭十一")
tag = models.ManyToManyField(Tag)
category = models.ForeignKey(Category, on_delete=models.CASCADE, null=True) # 这里的NULL表示,数据分类可以为空
def __str__(self):
return self.title
class Meta:
verbose_name_plural = "内容"Meta既对如下进行的修改显示

3.定义模型-admin
在注册这三个表时,admin会自行运行里面的方法,所以不用调用
from django.contrib import admin
from .models import Category, Post,Tag
#第二种注册表的方法:admin.site.register(Category)
@admin.register(Post)
class PostAdmin(admin.ModelAdmin):
#显示设置
list_display = ['title','content','author','display_tag','display_category'] #因为不能显示多对多,所以要美化
#区块设置
fieldsets =(
("标题/正文", {'fields': ['id','title', 'content'], 'classes': ['collapse']}),
("作者", {'fields': ['author'], 'classes': ['collapse']}),
("分类/标签", {'fields': ['tag','category'], 'classes': ['collapse']}),
)
#搜索功能
search_fields = ['title', 'content','author','category__Category_name','tag__Tag_name']
#过滤功能
list_filter = ['author','category','tag']
#分页功能
list_per_page = 3
def display_tag(self, obj):
return "/".join([tag.Tag_name for tag in obj.tag.all()])
display_tag.short_description = "标签"
def display_category(self, obj):
return obj.category.Category_name
display_category.short_description = "分类"
class PostInlines(admin.StackedInline): #StackedInline是上下布局,TabularInline左右布局
model = Post #关联的类
extra = 3 #空白3篇
@admin.register(Category) #第二类注册方式
class CategoryAdmin(admin.ModelAdmin):
list_display = ('display_category','id') #与PostAdmin相同,显示设置,需要自定义方法
def display_category(self, obj):
return obj.Category_name
display_category.short_description = "分类"
@admin.register(Tag)
class TagAdmin(admin.ModelAdmin):
list_display = ('display_tag','id') #与PostAdmin相同,显示设置,需要自定义方法
def display_tag(self, obj):
return obj.Tag_name
display_tag.short_description = "标签"使用display_tag方法自定义的列名,并使用list_display显示

4.模型类成员
- save():将模型对象保存到数据表中
- delete():将模型对象从数据表中删除
1.方法一:
在views中,编写视图函数进行数据的保存与删除
from django.shortcuts import render,HttpResponse
from .models import *
def save_tag(request,tag_name):
tag = Tag()
tag.Tag_name = tag_name
tag.save()
return HttpResponse(f"已成功添加{tag_name}")
def delete_tag(request,tag_name):
tag = Tag.objects.get(Tag_name=tag_name)
tag.delete()
return HttpResponse(f"已成功删除{tag_name}")
配置主路由
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path('',include('myday.urls')),
]
再使用正则配置子路由
from django.contrib import admin
from django.urls import path,include,re_path
from .views import *
urlpatterns = [
re_path(r"save_tag/(\w+)",save_tag),
re_path(r"delete_tag/(\w+)",delete_tag)
]2.方法二:
自定义管理器类主要用于两种情况 :
- 修改原始查询集,重写get_queryset()方法
- 向管理器类中添加额外的方法,如创建对象
在models中进行自定义管理器的编写
from django.db import models
# Create your models here.
class PostManage(models.Manager):
def get_queryset(self):
#return super(PostManage,self).get_queryset() #不变
return super(PostManage,self).get_queryset().filter(deleted=False) #只返回没有被逻辑删除的部分
def create(self,title,content,author,category):
p = self.model() # 创建模型类对象self.model可以获得模型类
p.title = title
p.content = content
p.author = author
p.category = category
p.delete = False
return p # 返回模型对象
class Post(models.Model):
#...其他代码
post_object = PostManage()
在视图中进行视图函数编写
def add_post(request):
title = 'python 高级快速入门4'
content = 'python 大法好'
author = Post.post_object.get(id=1).author # 作者
# category = Category() # 创建分类
# category.category_name = 'python高级'
# category.save()
#或使用:因为在这两个表中的object没有被覆盖
category, created = Category.objects.get_or_create(
Category_name='Python高级' # 尝试获取或创建
)
# 2. 同样的逻辑处理标签
tag, created = Tag.objects.get_or_create(
Tag_name='Python大法'
)
# tag = Tag() # 创建标签
# tag.tag_name = 'python大法'
# tag.save()
p = Post.post_object.create(title,content,author,category) #将带有数据的模型对象返回
p.save()
p.tag.add(tag) # 添加标签
return HttpResponse('添加成功')配置url
urlpatterns = [
path("add_post",add_post)
]5.查询集
1.返回列表的过滤器如下:
- all():返回所有数据
- filter():返回满足条件的数据
- exclude():返回满足条件之外的数据,相当于sql语句中where部分的not关键字
- order_by():排序,参数为字段名,-号表示降序
def show_post(request):
All = Post.post_object.all()
Filter = Post.post_object.filter(category__Category_name__contains='Python')
exclude = Post.post_object.exclude(category__Category_name__contains='Python')
order =Post.post_object.filter(category__Category_name__contains='Python').order_by('tag')
print("返回全部:",All)
print("返回分类包含Python的:",Filter)
print("返回分类不包含Python的:",exclude)
print("返回排序:",order)
return HttpResponse("返回成功")返回全部: <QuerySet [<Post: 1>, <Post: 2>, <Post: python 高级快速入门>, <Post: python 高级快速入门2>, <Post: python 高级快速入门3>, <Post: python 高级快速入门4>]>
返回分类包含Python的: <QuerySet [<Post: python 高级快速入门>, <Post: python 高级快速入门2>, <Post: python 高级快速入门3>, <Post: python 高级快速入门4>]>
返回分类不包含Python的: <QuerySet [<Post: 1>, <Post: 2>]>
返回排序: <QuerySet [<Post: python 高级快速入门>, <Post: python 高级快速入门2>, <Post: python 高级快速入门3>, <Post: python 高级快速入门4>]>2.返回单个值的过滤器如下:
- get():返回单个满足条件的对象 如果未找到会引发"模型类.DoesNotExist"异常 如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常
- count():返回当前查询的总条数
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False
category__Category_name__contains:两个下滑线的意思类似于category.Category_name.contains
Post.post_object.all().count()
3Post.post_object.all().exists() # 查询结果集有数据,exists返回True
True
Post.post_object.filter(id=1000).exists() # 数据中不存在id为1000的数据,查询结果集为空,返回False
False运算符如下:
exact:表示相等
contains:是否包含
startswith、endswith:以指定值开头或结尾
iexact,icontains,istartswith,iendswith功能同上面四个一样,前面加字母i表示不区分大小写。
isnull:是否为null
in:是否包含在范围内
gt:大于
gte:大于等于
lt:小于
lte:小于等于
exclude()方法:返回满足条件之外的数据,实现不等于效果
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算
F对象 专门取对象中某列值的操作,F() 返回的实例用作查询内部对模型字段的引用。这些引用可以用于查询的filter 中来比较相同模型实例上不同字段之间值的比较。
Q对象 逻辑运算
注意:在django中查询条件的运算符采用两个下划线连接。 比如:
Post.post_object.filter(id__exact=1) #查询条件:id等于1的数据
id大于1的数据:
Post.post_object.filter(id__gt=1)
翻译成sql语句为:
select * from Post where id>1;
演示:
- exact 等于 查询id等于1的数据
Post.post_object.filter(id__exact=1) #查询条件:id等于1的数据,注意是两个下划线
djago查询中条件查询默认使用exact运算符。 查询相等可简写:
Post.post_object.filter(id=1)
- contains:是否包含 查询标题(title字段) 中包含'django'的文章
>>> Post.post_object.filter(title__contains='django')
<QuerySet [<Post: e10分钟入门django>, <Post: django 快速开发>]>
- startswith、endswith:以指定值开头或结尾
查询标题中以python开头的文章
>>> Post.post_object.filter(title__startswith='python')
<QuerySet [<Post: python 高级快速入门>]>
查询标题中以django结尾的文章
>>> Post.post_object.filter(title__endswith='django')
<QuerySet [<Post: e10分钟入门django>]>
- isnull:是否为null 如果数据库中有字段值为null的不能直接使用 '字段=null' 的方式查询,需要使用isnull判断值是否为null
>>> Post.post_object.filter(title__isnull=False) #查询文章标题不为null的数据
<QuerySet [<Post: python 高级快速入门>, <Post: e10分钟入门django>, <Post: django 快速开发>]>
>>> Post.post_object.filter(title__isnull=True) <p>#查询文章标题为null的数据</p>
<QuerySet []>
- in:是否包含在范围内 查询id为2、3,4的文章,参数是一个列表,id在列表中,就是符合条件的。
>>> Post.post_object.filter(id__in=[2,3,4])
<QuerySet [<Post: e10分钟入门django>, <Post: django 快速开发>]>
- gt:大于 查询id大于3 的文章
>>> Post.post_object.filter(id__gt=3)
<QuerySet [<Post: python 高级快速入门>, <Post: django 快速开发>]>
- gte:大于等于 查询id大于等于3 的文章
>>> Post.post_object.filter(id__gte=3)
<QuerySet [<Post: python 高级快速入门>, <Post: e10分钟入门django>, <Post: django 快速开发>]>
- lt:小于 查询id小于4的文章
>>> Post.post_object.filter(id__lt=4)
<QuerySet [<Post: e10分钟入门django>]>
- lte:小于等于 查询id小于等于4的文章
>>> Post.post_object.filter(id__lte=4)
<QuerySet [<Post: e10分钟入门django>, <Post: django 快速开发>]>
- year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算 查询2018年写的文章:
>>> Post.post_object.filter(created_time__year=2018)
<QuerySet [<Post: python 高级快速入门>, <Post: e10分钟入门django>]>
查询2018年之前写的文章
>>> Post.post_object.filter(created_time__year__lt=2018)
<QuerySet [<Post: django 快速开发>]>
查询2018年1月1日之后的文章
>>> Post.post_object.filter(created_time__gte=date(2018,1,1))
F对象
如果查询条件为两个属性值比较那么需要用到F对象。使用F对象,被定义在django.db.models中所有要使用F对象要先导入
导入F对象。
from django.db.models import F
F() 返回的实例用作查询内部对模型字段的引用。这些引用可以用于查询的filter 中来比较相同模型实例上不同字段之间值的比较。
>>> Post.post_object.filter(created_time=F('modified_time'))
<QuerySet [<Post: python 高级快速入门>]>
Django 支持对F() 对象使用加法、减法、乘法、除法、取模以及幂计算等算术操作,两个操作数可以都是常数和其它F() 对象。
比如:查询阅读量大于两倍评论量的数据
Post.post_object.filter(read__gt=F('comment')*2)
Q对象:Q对象,被定义在django.db.models中所有要使用Q对象要先导入
from django.db.models import Q
两个条件逻辑与运算在多个条件用逗号分隔就是逻辑与:
>>> Post.post_object.filter(title='django 快速开发',id__gt=2)
<QuerySet [<Post: django 快速开发>]>
如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符 Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或 Q对象使用~操作符,表示逻辑非,not
例如:查询标题以django结尾或者python开头的文章。这种逻辑或的关系,直接查询是没办法查询的,需要使用Q对象结合 | 查询
>>> Post.post_object.filter(Q(title__startswith='python') | Q(title__endswith='django'))
<QuerySet [<Post: python 高级快速入门>, <Post: e10分钟入门django>]>
相当于mysql中的语句:
WHERE title LIKE 'python%' OR title LIKE '%django'
查询 id不等于3的文章:
>>> Post.post_object.filter(~Q(id=3))
<QuerySet [<Post: python 高级快速入门>, <Post: django 快速开发>]>
3、关联查询
Django中也能实现类似于mysql中的连接查询。
关联模型类名小写属性名运算符=值
例如:查询分类为'django'的文章
>>> Category.objects.filter(post__title='django 快速开发')
<QuerySet [<Category: django>]>
查询分类为django的所有文章
>>> Post.post_object.filter(category__category_name='django')
<QuerySet [<Post: e10分钟入门django>, <Post: django 快速开发>]>
4、反向查询
如果模型I有一个ForeignKey,那么该ForeignKey 所指的模型II实例可以通过一个管理器返回前面有ForeignKey的模型I的所有实例。这个管理器的名字为foo_set,其中foo是源模型的小写名称。
>>> cg = Category.objects.filter(category_name='django')[0]
>>> cg
<Category: django>
>>> cg.post_set.all()
<QuerySet [<Post: e10分钟入门django>, <Post: django 快速开发>]>
5、聚合函数
使用aggregate()过滤器调用聚合函数, 常用聚合函数:Avg,Count,Max,Min,Sum,被定义在django.db.models中 需要使用要先导入聚合函数
聚合函数返回结果是一个字典:
>>> from django.db.models import Max
>>> Post.post_object.aggregate(Max('id')) # 查询文章表中id的最大值
{'id__max': 7}
>>> from django.db.models import Min
>>> Post.post_object.aggregate(Min('id')) # 查询文章表中id的最小值
{'id__min': 3}
>>> from django.db.models import Avg
>>> Post.post_object.aggregate(Avg('id')) # 查询所有文章id的平均数
{'id__avg': 4.666666666666667}
>>> from django.db.models import Count
>>> Post.post_object.aggregate(Count('id')) #统计一共多少文章。
{'id__count': 3}
>>> from django.db.models import Sum
>>> Post.post_object.aggregate(Sum('id'))
{'id__sum': 14}



![2025年渗透测试面试题总结-腾讯[实习]安全研究员(题目+回答)](https://i-blog.csdnimg.cn/direct/2ea6508e11f348769528e86055da4fc5.png)