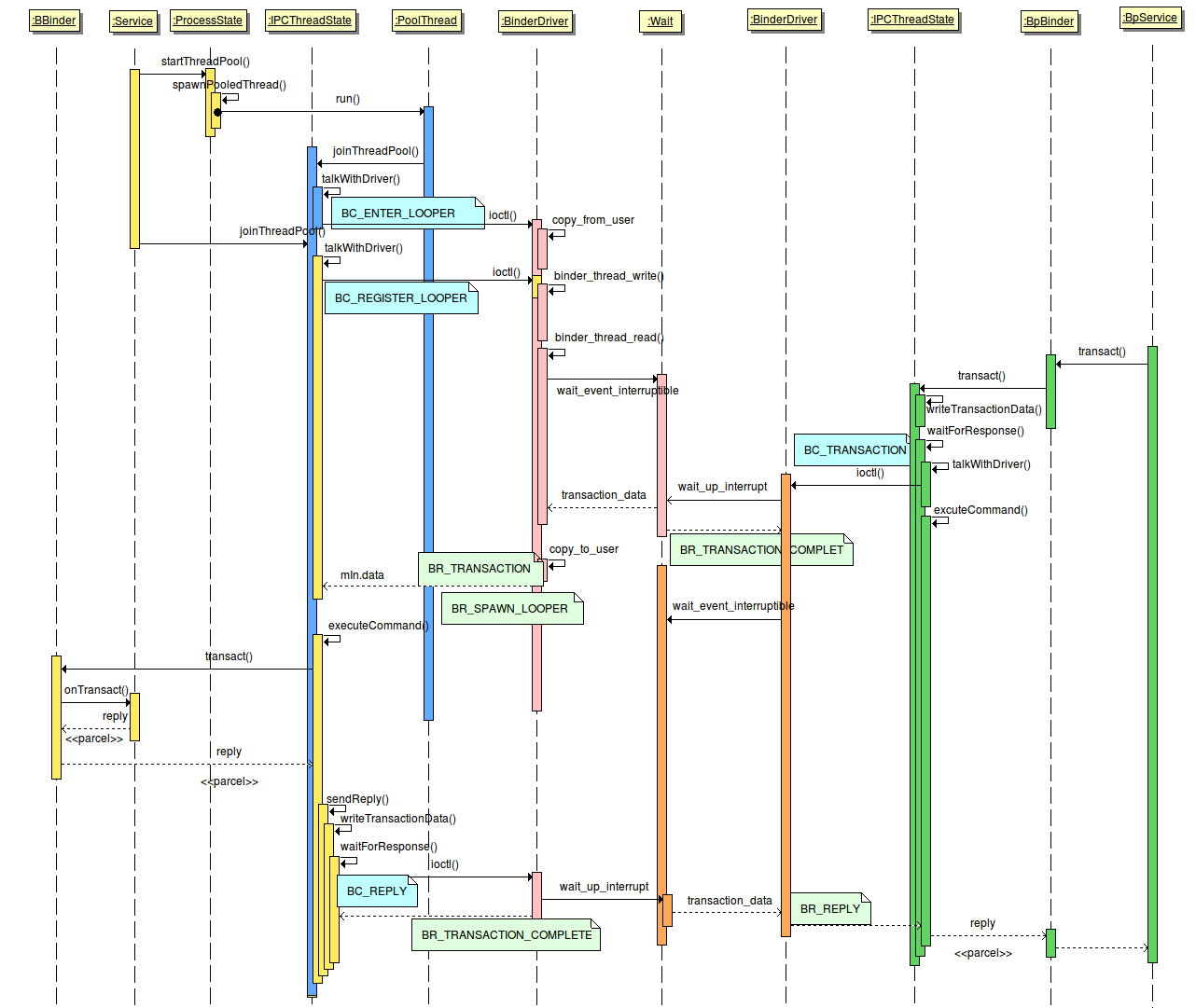
这是关于 C++ 游戏开发中内存接口与调试工具演进 的介绍,主要回顾了从早期到现在平台上的内存与调试策略变化:
游戏平台演进与内存接口编程风格
2000年 (PlayStation 2)
- 编程风格偏向嵌入式 C 风格。
- 系统资源有限(例如 32MB RAM),程序员需要手动管理内存、处理对齐、分段等细节。
- 调试手段非常基础,多用日志输出或硬编码方式定位错误。
2005年 (Xbox 360 / PS3)
- 引入 接口式编程(Interface Programming),代码结构更加模块化。
- 开始使用 EASTL(Electronic Arts Standard Template Library),适用于游戏开发的 STL 替代品,性能优化好,避免 heap allocation。
- 多核处理器开始普及,调试和内存问题更复杂。
现代平台 (PS4 / Xbox One)
- 系统采用 64 位地址空间,能管理更多内存。
- 内存分区、分配器(allocator)、cache line alignment 等成为设计重点。
- 多线程下对内存一致性和同步机制要求更高。
当前使用的调试工具(Our Current Tools)
- 主要关注点是:如何让所有调试系统协同工作。
- 内存追踪器(memory tracker)
- 自定义分配器(custom allocators)
- 崩溃堆栈追踪(stack trace)
- 热点分析器(hot path profiler)
- 内存泄漏检测器(leak detector)
- 工具之间共享信息,形成一个完整的调试生态系统。
这段介绍的重点在于: - 随着平台能力的提升,内存接口与调试工具也不断进化。
- 尤其在现代平台上,系统性调试框架是高性能游戏开发的核心之一。
理解了!
这段是关于 内存分配相关术语 的定义,用于构建游戏引擎中高效的内存管理系统。以下是对这些术语的解释和它们之间关系的总结:
核心术语解释
Allocator(分配器)
- 是一个 对象或接口,提供内存 分配(alloc) 和 释放(free) 的能力。
- 不同的 allocator 可以有不同的策略,比如:
- 线性分配器(Linear Allocator)
- 栈式分配器(Stack Allocator)
- 自由列表分配器(Free List Allocator)
- 分页分配器(Paged Allocator)
Arena(竞技场 / 内存池)
- 表示由某个 allocator 控制的一段或多段 地址范围(address ranges)。
- 一个 arena 实际上就是 一块内存的所有权,它知道哪些 allocator 可以访问它。
- 一个 arena 可以支持多个 allocator(用于不同用途),也可以是一个固定用途的池子。
相互引用关系
- 可以 从 Arena 找到它的 Allocator(它负责这块内存的分配与释放逻辑)。
- 也可以 从 Allocator 找到它的 Arena(它工作的那段实际物理/虚拟内存)。
Heap(堆)
- 近似表示为:
Heap ≈ Allocator + Arena - 即:一个堆既包含了分配策略(由 Allocator 提供),也包含了实际内存(由 Arena 管理)。
- 所以一个 Heap 是一个完整的内存分配单元,既有「如何分」又有「从哪分」。
总结
Allocator是「怎么分内存」的逻辑;Arena是「从哪分内存」的资源;Heap是这两者的组合体,能实际运行;- 它们之间相互关联,设计灵活,方便定制与调试。
这部分是关于2000年代初(例如 PlayStation 2 时代)游戏开发的内存使用和编程风格的简要概况。下面是逐点解释和背景补充:
2000 年代早期的 C 风格内存编程(以 PS2 为代表)
Year ~2000: PS2 有 32MB RAM
- 非常小的内存预算,开发者需要对内存使用极其小心。
- 大多数资源(纹理、模型、声音等)需要手动加载和卸载。
大多数使用的是 C++ 编译器
- 语言上是 C++,但风格上更接近 C:
- 没有使用高级特性如虚函数、多态、异常。
- 内存和对象生命周期都手动管理。
不使用 STL(Standard Template Library)
- 原因包括:
- STL 的实现不确定(不同编译器有差异)
- 运行时开销不可控
- 不透明的内存分配行为
- 所以:数据结构通常是手写的数组、链表、环形缓冲等。
没有虚拟内存
- 所有内存都是物理内存(固定的 32MB)。
- 内存访问越界会直接崩溃,没有“虚拟地址空间保护”。
几乎没有操作系统(OS)
- 没有 malloc/free、线程、文件系统等高级功能。
- 一切都是裸机式的:程序控制硬件,管理内存、I/O 全靠自己。
- 这使得编程非常接近嵌入式系统(如微控制器开发)。
开发风格特征总结
| 特征 | 意义 |
|---|---|
| 手动管理内存 | 所有分配、释放都要手动,小心碎片 |
| 自定义数据结构 | 替代 STL,自控内存和行为 |
| 无操作系统依赖 | 程序必须独立完成所有任务 |
| 高效与可预测性 | 所有设计追求低开销、可测性能 |
| 代码更像 C 而不是现代 C++ | 结构体 + 函数方式主导 |
你贴的这段代码和说明风格是典型的 2000 年代的 C/C++ 编程方式,强调性能优化,尤其是在对象内存管理方面。我们逐条解释:
总体风格说明:
“C style 2000s Interfaces for speed” 这种风格强调性能优先、手动管理内存、宏定义抽象、最小化虚函数等开销,适用于嵌入式开发、游戏引擎(如早期的 Unreal Engine、id Tech)等对性能极端敏感的领域。
#define NEW_DELETE_OPERATORS(debug_name) 是什么?
这是一个宏定义(macro),它为类统一地重载 new 和 delete 运算符。宏的作用是让你在每个类里轻松加上这些重载,而不用复制粘贴冗长的代码。
可能的宏定义如下(你贴的代码没给出具体内容,但这是惯用写法):
#define NEW_DELETE_OPERATORS(debug_name) \
void* operator new(size_t size) { \
return MyAllocator::Allocate(size, debug_name); \
} \
void operator delete(void* ptr) { \
MyAllocator::Deallocate(ptr); \
}
它的作用:
- 自定义内存分配器:比如固定大小的内存池(pool/slab allocator),用于更快地分配/回收对象。
- 调试信息:
debug_name用于记录是哪一类在调用内存分配,方便调试内存泄漏或碎片。 - 节省开销:避免
malloc/free或new/delete频繁调用造成的性能问题。
示例解析:
class CollisionChooser {
public:
NEW_DELETE_OPERATORS(CollisionChooser)
...
};
这一段代码意思是:
- 给
CollisionChooser类重载了new和delete。 - 内存的申请释放不走默认路径,而是走你自定义的
MyAllocator或其他机制。 CollisionChooser会作为一个“标签”传入,标记该对象是哪个类分配的。
这对程序员有什么意义?
优点:
- 性能更高,尤其在游戏、实时系统中。
- 内存调试更容易。
- 配合 slab/pool allocator 可以零碎化更少,缓存命中率更高。
缺点:
- 可读性差,调试复杂。
- 写法古老,现代 C++(C++11 以后)更推荐使用智能指针和
std::allocator,而非手动宏和内存管理。
总结:
你贴的内容描述的是早期 C++ 项目中通过宏定义和手动内存管理提升性能的做法。NEW_DELETE_OPERATORS(debug_name) 是一个宏,用来给类重载 new 和 delete 运算符,通常用于配合固定大小内存池以获得更快的内存分配和释放。
如果你想,我也可以帮你实现这个宏的完整写法,或者改写成现代 C++ 的等效写法(比如使用 allocator + std::make_unique)。要看你是想继续沿用旧风格还是现代化。
在调试构建中,通过自定义 operator new 实现对内存分配的追踪与验证,包括记录分配来源(debug_name)、使用 flags 控制分配策略,并通过内存块中的 footer 存储调试信息。
逐条拆解解释如下:
1. Global new 重载
void* operator new(size_t size, const char* debug_name, int flags = MB_LOW);
这是一种 全局重载的 operator new,增加了调试信息的参数:
debug_name: 一个字符串,用来标识这个内存块是由谁分配的。flags: 用于控制分配行为,比如是否来自低内存池 (MB_LOW) 或其他内存区。
这种设计可以帮助:- 追踪内存泄漏(知道谁分配了内存)。
- 校验非法释放、越界写(通过哨兵)。
- 分析内存分配来源(可以统计哪个系统最消耗内存)。
2. 内存布局结构(分配块带 Header / Footer)
你提到的:
Allocated Block Header footer
Allocated Block Header footer
Allocated Block Header footer
表示每个分配的内存块不是只包含用户数据,而是:
[Header][User Data][Footer]
Header: 一般存储 size、flags、校验信息、分配堆栈等。User Data: 真正给程序使用的部分。Footer: 存放debug_name,哨兵(sentinel)等。
这样设计可以实现:- 写入
Footer中的调试信息(如 “render::player”)。 - 设置哨兵值(如 0xDEADBEEF),检测写越界。
- 记录是谁在哪儿分配了这段内存。
3. debug_name 的使用:分类字符串标记来源
debug_name split into category::alloc
Examples:
"render::player"
"gameplay::physicsmesh"
这是一种 命名规范,用来把内存分配归类,便于调试分析:
render::player表示渲染子系统分配给玩家的对象。gameplay::physicsmesh表示游戏逻辑中的物理网格分配。
这样在工具中查看内存分布时,可以快速知道:- 哪个子系统分配了多少内存。
- 哪些分配对象最多、最大。
- 哪些系统可能有泄漏或碎片问题。
小结(中文)
你看到的这一风格,是 2000 年代在大型项目中常用的做法,尤其在游戏引擎、嵌入式系统、图形引擎中:
| 特征 | 说明 |
|---|---|
自定义 operator new | 增加调试信息参数 |
| 内存块加头尾部 | 记录元信息和检测内存破坏 |
debug_name 命名规范 | 类似命名空间,用于归类调试 |
flags 参数 | 控制使用哪种内存策略(如低地址池) |
如果你想深入理解或动手实现
我可以提供完整的示例代码,例如:
struct BlockHeader {
size_t size;
int flags;
// ...
};
struct BlockFooter {
const char* debug_name;
uint32_t sentinel;
};
void* operator new(size_t size, const char* debug_name, int flags = MB_LOW) {
size_t total = size + sizeof(BlockHeader) + sizeof(BlockFooter);
void* raw = malloc(total);
BlockHeader* header = (BlockHeader*)raw;
header->size = size;
header->flags = flags;
void* userPtr = (void*)(header + 1);
BlockFooter* footer = (BlockFooter*)((char*)userPtr + size);
footer->debug_name = debug_name;
footer->sentinel = 0xDEADBEEF;
return userPtr;
}
关于 内存分配策略(Allocation Technology) 的说明,重点是性能导向 + 手动内存管理,常见于游戏引擎、图形引擎、嵌入式系统等场景。
我来帮你分段解释和总结:
总体结构:一个主堆 + 特殊分配器
Almost all memory is in one heap
Well we did have a simple small block allocator
We had to work hard at defragmentation
含义:
- 主堆(General Heap):绝大多数内存通过一个统一的堆来分配。
- 小块分配器(Small Block Allocator):额外做了一个小块专用分配器,用于高频、短生命周期的小对象。
- 手动碎片整理(Defragmentation):因为分配和释放不规律,容易产生内存碎片(尤其在主机/嵌入式),需要程序员手动设计机制做 defrag。
图示说明解析:
Low Memory
├── Small Block Allocator
│ ├── Decompress
│ ├── Alloc
│ └── Mesh
│
└── Load compressed Texture 0
High Memory
└── General Allocator
└── Texture 0
意思是:
低地址空间(Low Memory):
- 用于一些 生命周期短/体积小的任务,例如:
Decompress: 解压缩缓冲区(临时内存)Alloc: 小对象分配(可能是游戏逻辑对象)Mesh: 小模型加载或中间数据结构
这些都可能使用 Small Block Allocator,优点:
- 分配快速、回收简单
- 减少碎片、对齐一致
- 有可能在任务完成后统一回收整个小块池
高地址空间(High Memory):
- 用于存储大对象、长生命周期资源,例如:
Texture 0: 贴图、大型资源缓冲区
- 使用的是通用内存分配器(General Allocator)
设计目的和优势:
| 技术 | 解释 | 优点 |
|---|---|---|
| 单一主堆 | 所有内存统一调度 | 简化结构 |
| 小块分配器 | 为频繁分配的小对象设计 | 快、低碎片 |
| 手动 Defrag | 需要程序员设计内存迁移和整理机制 | 保持长时间运行稳定性 |
| 地址分层 | 将低/高地址分区,绑定资源类型 | 有助于平台优化(如主机 GPU DMA) |
举例说明:
假设你在开发一款游戏:
- 游戏开始时加载纹理、网格等大资源,使用 General Allocator
- 游戏运行中,解压流式内容、创建粒子、生成 AI 临时路径点,使用 Small Block Allocator
- 游戏运行一小时后出现碎片,程序调用
DefragmentHeap()手动整理内存。
中文总结:
这段内容描述的是早期(2000年代)程序在内存分配方面的策略:
- 大部分内存集中在一个堆中管理(统一分配器)
- 对小对象使用一个简单快速的小块分配器
- 为了避免/修复内存碎片,需要程序员自己做 defrag
- 按照地址空间将“短期小内存”与“长期大资源”分开分配,以便优化
这种方式在当年追求极致性能和资源掌控时很常见,尤其是游戏主机、嵌入式设备等内存紧张场景中。
2005 年游戏开发内存管理技术变革 的总结,尤其是随着 Xbox 360 和 PS3 这代主机发布,对内存系统提出了新需求。我们逐条来解释这段话的含义和背后的技术背景。
背景:2004–2005 主机变革期
2004 - Xbox 360, PS3 (512MB RAM)
Virtual memory! - NO HDD , No GPU support, 32-bit
含义:
- Xbox 360 / PS3 的 RAM 是 512MB(当时很少),而游戏内容越来越复杂,必须精打细算。
- 支持虚拟内存,但由于:
- 没有硬盘(早期 Xbox 360 低配没有 HDD)
- 显卡不直接支持虚拟内存(不支持页表映射 GPU memory)
- 系统仍是 32-bit
所以不能靠操作系统自动管理内存,开发者必须手动优化内存布局和使用。
“All consoles have multiple CPUs” 是什么意义?
“不仅仅是 Sega Saturn 了 ”
- Sega Saturn 曾有 2 个 CPU,开发难度非常高。
- 到 Xbox 360 和 PS3,这种多核架构成为常态(例如 PS3 的 Cell 架构:1个 PPE + 7个 SPE)。
- 多核程序意味着:
- 你需要考虑多线程并发分配
- 需要线程安全的分配器(或线程局部分配器)
2005 年的主要内存系统变化
The main changes for 2005:
Support for multiple allocators
Better tracking and logging tools
Stomp allocator!!
Memory tracking with EASTL
1. Support for multiple allocators
- 项目开始支持多个不同用途的分配器:
- General allocator:大多数对象使用
- Frame allocator:每帧重置的临时内存
- Pool allocator:固定大小对象分配
- Small block allocator:频繁小对象分配
- 目的:减少碎片、提升分配速度、按功能隔离
2. Better tracking and logging tools
- 更强大的内存日志记录和可视化工具
- 支持:
- 记录每个分配点的
callstack - 显示
debug_name、分配时间、生命周期等 - 导出给分析工具(可能自己写的 GUI viewer)
- 记录每个分配点的
3. Stomp Allocator
- 一种用于调试的分配器,特点是:
- 每次分配返回一个特定位置的内存页
- 在内存块前后加上保护页(unmapped page)
- 用于检测:
- 越界写(写到已释放的内存或超出边界)
- 使用已释放指针(Use-after-free)
示意图:
[Guard Page][Allocated Block][Guard Page]
一旦代码非法访问了这些 guard page,系统就会立刻抛出崩溃,比传统调试手段更早发现问题。
4. Memory tracking with EASTL
- EASTL = Electronic Arts Standard Template Library
- 是 EA 出品的 STL 替代库,专为游戏开发优化:
- 可定制 allocator(每个容器都可以指定)
- 零 heap allocation(避免隐藏分配)
- 更好性能(少使用虚函数、无异常)
支持如下用法:
eastl::vector<MyType, MyCustomAllocator> myVector;
这样每个容器都可以明确指定 allocator,配合内存追踪使用,实现精准定位。
总结(中文)
2005 年游戏主机时代内存管理的主要变革如下:
| 项目 | 内容 | 目的 |
|---|---|---|
| 多分配器支持 | 各类内存按功能分离管理 | 减少碎片、提升性能 |
| 日志和追踪工具 | 更好调试和内存使用分析 | 查泄漏、优化分布 |
| Stomp Allocator | 分配器带保护页 | 抓内存越界/悬挂指针 |
| EASTL 跟踪支持 | 容器与 allocator 深度绑定 | 避免隐式 heap 分配 |
2005 年支持多分配器(multiple allocators)机制 的具体示例,说明了如何在一个资源受限、性能敏感的 C++ 项目中,通过显式分配器接口(ICoreAllocator*)实现对象的构造与析构,而不是使用普通的 new 和 delete。
下面来一步步详细解释:
示例代码分析:
SQLQuery* NewQuery(ICoreAllocator* a) {
return CORE_NEW(a, "sql", MEM_LOW) SQLQuery(a);
}
void DeleteQuery(ICoreAllocator* a, SQLQuery* sql) {
CORE_DELETE(a, sql);
}
背后关键点总结:
| 特性 | 含义 |
|---|---|
ICoreAllocator* a | 多态分配器接口,表示你可以传入不同的分配器(frame allocator, pool allocator, heap allocator 等) |
CORE_NEW(...) Type(args...) | 宏封装的 placement new,结合 allocator 分配内存 + 构造对象 |
CORE_DELETE(...) | 宏封装的:调用析构函数(~Type)+ allocator 回收内存 |
不使用 delete | 不走默认全局 operator delete,而是自定义内存系统负责销毁 |
为何要这么做?
传统写法:
SQLQuery* q = new SQLQuery(); // 调用全局 new
delete q; // 调用全局 delete
在高性能游戏/引擎中这么做有问题:
- 所有对象都走全局堆,容易碎片化
- 很难做内存追踪和调试
- 不容易切换分配策略
- 不适合嵌入式或没有操作系统的环境
新的写法带来优势:
支持 多分配器(polymorphic allocator)
- 你可以选择最合适的分配器,比如:
frame_allocator:一帧用完就丢pool_allocator:快速、适合大量同类对象debug_allocator:用于调试时追踪
可以更清晰地记录分配信息:
"sql" // 这个是 debug_name,可以在日志中记录
MEM_LOW // 分配 flags,告诉系统:低地址优先、小内存池
允许精确释放:
CORE_DELETE不只是释放指针,它会:- 显式调用
~SQLQuery()析构函数(非delete) - 调用
a->Free()来回收内存 - 避免标准库
delete的不确定行为
- 显式调用
CORE_NEW 和 CORE_DELETE 的等效实现:
假设定义如下宏:
#define CORE_NEW(alloc, name, flags) \
new ((alloc)->Alloc(sizeof(SQLQuery), name, flags))
#define CORE_DELETE(alloc, ptr) \
if (ptr) { (ptr)->~SQLQuery(); (alloc)->Free(ptr); }
这样就可以解释:
SQLQuery* q = CORE_NEW(a, "sql", MEM_LOW) SQLQuery(a);
等价于:
void* mem = a->Alloc(sizeof(SQLQuery), "sql", MEM_LOW);
SQLQuery* q = new (mem) SQLQuery(a); // placement new 构造对象
为什么特别强调 “Calls ~SQLQuery(), not delete!!”?
因为:
delete ptr;默认会:- 调用析构函数
- 然后调用
operator delete释放内存(通常是全局堆)
但在这个系统里:
- 内存不是从全局分配的,必须用对应的 allocator 回收
- 所以你不能用 delete,只能手动调用析构函数 + allocator->Free()
总结(中文):
你贴的代码体现了 2005 年游戏/引擎编程中,支持多种内存分配器(multiple allocators)的一种常见写法:
- 显式使用
ICoreAllocator*控制分配来源 - 使用
CORE_NEW/CORE_DELETE宏包装 placement new 和显式析构 - 避免使用标准的
new/delete - 可以根据功能/用途选择不同的 allocator,实现更高性能、更强控制、更好调试
需要我给你写一个完整的ICoreAllocator接口 + 一个实际 allocator 实现 + 宏用法的最小工作例子(可编译)吗?这可以让你真正“跑起来”看它如何工作。
2005 年游戏引擎内存系统如何组织 Heaps / Arenas(堆 / 区域) 的设计策略总结。这种设计旨在平衡性能、碎片控制、调试可追踪性,是当时大型项目(特别是主机游戏)中常见的高级内存组织方法。
下面我逐条解释你贴的内容。
核心目标:如何组织 Heaps / Arenas
“A mix of time and size gives good defragmentation properties.”
在 2005 年的游戏开发中,内存组织要面对的问题包括:
- 如何最小化碎片(fragmentation)
- 如何快速分配和释放
- 如何按功能模块分配内存以便调试/追踪(“谁用了多少内存”)
所以引入了多维度的 Heap / Arena 分类方式。
第一层分类:按模块组织(按用途拆堆)
Render Heap
Gameplay Heap
UI Heap
每个子系统(模块)有自己专属的 heap 和 SBA(Small Block Allocator):
| 模块 | 描述 |
|---|---|
| Render Heap | 用于渲染系统分配资源,比如纹理、渲染状态缓存等 |
| Gameplay Heap | 游戏逻辑使用,如实体、AI、碰撞体等 |
| UI Heap | 用户界面层的内存,如菜单、文本框、按钮对象等 |
| SBA | 每个模块都有自己的 small block allocator,优化小对象 |
| 这样做的好处: |
- 各系统互不干扰,减少内存争抢
- 调试时容易找到“是谁用了太多内存”
第二层分类:按大小划分池
Small / Medium / Large
这层是典型的 slab allocator / segregated size-class 策略:
| 大小 | 举例 |
|---|---|
| Small | 16B~128B(指针、字符串、组件对象) |
| Medium | 512B~2KB(纹理片段、小mesh、节点) |
| Large | >8KB(大纹理、全局缓存) |
| 好处: |
- 同类尺寸对象聚集,避免碎片
- 释放后容易复用(cache locality 好)
第三层分类:按生命周期组织 Arena
Static / Level / Global / SubLevel / Time
这是一种按“对象寿命周期”来分配堆的方法:
| 类别 | 生命周期 | 示例 |
|---|---|---|
| Static | 永久存在 | 全局配置、字体缓存 |
| Level | 一局游戏/关卡 | 角色数据、碰撞树 |
| SubLevel | 场景片段 | 动画段、子地图 |
| Time | 一帧/一小段时间 | 粒子、AI临时路径点 |
| 好处: |
- 在生命周期结束时可以整块回收整个 Arena(极高效率)
- 不需要一个个对象去 delete,零碎管理更少
第四层分类:按团队或模块分配
“Organizing by team fragments heaps but easy to set blame.”
可以根据开发团队或子系统将堆隔离,例如:
| 团队 | 对应堆 |
|---|---|
| 渲染组 | RenderHeap |
| 游戏逻辑组 | GameplayHeap |
| 网络组 | NetHeap |
| 好处: |
- “谁用的谁负责”,容易统计内存使用量
- 可以强制内存预算,防止某个组过量使用
缺点: - 有可能导致 heap 使用碎片化(因为各组实际用量不均)
总结(中文)
这段内容讲的是 如何多维度组织内存堆(Heap)/ 区域(Arena) 来满足游戏开发复杂场景中的性能、调试、碎片控制需求:
| 维度 | 分类方式 | 优点 |
|---|---|---|
| 按功能模块 | Render / Gameplay / UI Heap | 易于调试、分隔清晰 |
| 按分配大小 | Small / Medium / Large | 减少碎片、提升复用 |
| 按生命周期 | Static / Level / SubLevel / Time | 整块释放、低开销 |
| 按团队 | 各团队独立 Heap | 容易追责、监控预算 |
| 最终作者说: |
“我们团队会根据实际需要混合使用这些策略。”
这也是最理智的方式 —— 灵活地根据资源、内容、平台、目标设备调整内存组织方式。
2005 年游戏项目中“按团队组织内存(Heaps/Arenas)”和“按类别分类(Categories)”的对比。这是关于如何有效组织和追踪内存使用,以应对碎片问题和团队之间的协作责任问题。
背景问题:内存被多个团队/系统共享时,会发生什么?
Memory Corruption between teams sucks
Fragmentation between teams is hard.
Who to blame when you are out of memory?
现实中的挑战:
- 多个团队(如:渲染 Render,模拟 Simulation,UI)共享内存堆:
- 如果 A 团队的对象写越界,可能会破坏 B 团队的数据
- 很难定位谁造成了问题(“内存越界”)
- 内存碎片也是跨团队产生的:
- 某团队频繁 alloc/free 会导致其他团队无法分配大块连续内存
- 谁应该负责碎片问题?这不好判断
方案一:Team-Based Heaps / Arenas
Render Heap
Simulation Heap
UI Heap
每个团队独立分配自己一块内存区域(Arena),只有这个团队能在其中分配对象。
优点:
- 内存越界容易定位(“R 团队 Heap 崩了”)
- 易于统计团队的内存预算
- 不同团队互不干扰(安全性高)
缺点:
- 总内存利用率差(会造成“局部满了,整体还有空间”)
- 很容易造成碎片化,难以复用碎片
- 切堆逻辑复杂
方案二:Team-Based Categories(标签)
“Categories are a way to tag allocations so you can budget them together.”
这是更灵活的方法:
- 所有分配仍来自统一的 heap 或 allocator
- 但每一次分配都会打一个tag / category,如:
或CORE_NEW(a, "render::shadowmap", MEM_LOW) ShadowMap(a);Alloc(size, "gameplay::projectile", MEM_TEMP);
优点:
- 不分 heap,避免碎片划分问题
- 可以在工具中统计:某个 category 占了多少内存
- 容易动态调整预算
- 更适合分析、调试、报表
缺点:
- 需要更强的内存追踪系统(callstack、category 映射)
- 出错(如越界)时难以定位哪个团队的责任(你不能靠 arena 辨别)
实际做法:组合使用
很多项目团队在 2005 年(甚至今天)采用的做法是:
- 保留一些重要模块的 Arena(如:Render、Streaming)来隔离关键资源
- 同时所有分配加上 category 标签,用于统一统计/报表/监控
- 内存工具支持按 category 导出使用图表,如:
| Category | Current Usage | Peak | Count |
| ------------------- | ------------- | ---- | ----- |
|render::meshcache| 25 MB | 32MB | 210 |
|gameplay::npc| 12 MB | 18MB | 1,224 |
|ui::popupmenu| 2 MB | 2MB | 42 |
总结(中文)
| 方案 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| Team-Based Heaps | 每个团队/系统一个专属内存区域 | 隔离好,责任明确 | 容易碎片,不好复用 |
| Category-Based 分配 | 给每次分配打上 tag 分类 | 易追踪,灵活,统一调度 | 越界难追责,需要更强工具支持 |
| 作者最终推荐的是使用 category tagging 来进行统计和预算管理,同时保留部分 arena 来隔离关键高风险模块。 |
你贴的这页讲的是:2005 年游戏引擎中内存“追踪与日志系统”的改进方法,尤其是在 Debug 模式下,如何实现更强的内存追踪、调试和泄漏检测。
核心目的
在 Debug 模式下,更好地追踪每一次分配和释放,以便:
- 找内存泄漏
- 查越界
- 记录谁、在哪儿、分配了多少
- 输出日志用于分析
正常堆 vs 调试堆结构对比:
正常堆(Normal Heap)
- 分配出来的内存块结构简单:
[ Header ][ User Data ][ Footer Sentinel ] - 通常只在尾部放一个 sentinel(哨兵字节)防止越界写:
H - Header F - Footer(如 0xDEADBEEF) - 优点:高性能,占用少
- 缺点:调试信息不足
调试堆(Debug Heap)
- 在每次分配时,除了返回用户数据,还把所有 追踪信息记录到一个单独的表中
- 这个表可能是单独的 debug heap 或调试堆结构
| 地址(Address) | 大小(Size) | 分类(Category::AllocName) |
| ----------- | -------- | ----------------------- |
| 0x1000 | 128B |render::meshdata|
| 0x1100 | 64B |gameplay::enemy|
| … | … | … |
分配流程(带 Debug Heap)
- 调用
Alloc(size, "category::name") - 在普通堆中分配:
[Header][UserData][FooterSentinel] - 在 Debug Heap 中记录一条追踪记录:
logTable.Add({ ptr: 0x1000, size: 128, tag: "gameplay::npc" }); Free(ptr)时,自动在 Debug Heap 中移除对应记录
Logging / Tracing System
- 所有分配/释放记录可以实时写入内存日志缓冲区(或直接写入磁盘)
- 格式类似:
+ [ALLOC] 0x123456 Size: 128 Tag: gameplay::npc + [ALLOC] 0x1234F0 Size: 64 Tag: render::shadowmap - [FREE ] 0x123456 - 这样可以:
- 离线分析内存变化曲线
- 找出泄漏(存在未 free 条目)
- 对齐内存使用与场景(如进入城市场景后内存飙升)
为什么只在 Footer 存 Sentinel?
“Only sentinel stored in footer”
- Sentinel(哨兵)是一种轻量的越界写检测方法
- 常见写法:
*(end_of_alloc) = 0xDEADC0DE; - 每次
free时检查 sentinel 是否被改写 - 如果被改了,说明用户写越界了,爆红!
但这种方法不能告诉你是谁越界,只能告诉你 “这里坏了”。
所以才有 Debug Heap 来记录更详细的信息。
总结(中文)
| 特性 | 描述 | 目的 |
|---|---|---|
| Sentinel in Footer | 在每个块尾部加一个哨兵值 | 检测越界写入 |
| Debug Heap | 单独存储所有分配信息(地址、大小、tag) | 查内存泄漏、追踪来源 |
| Category Tag | render::player, gameplay::npc | 细粒度内存分类,易调试 |
| Memory Logging | 日志写入内存或磁盘 | 离线分析、自动化测试 |
| Live Allocation Tracking | 保持当前活跃内存状态 | 实时检测泄漏和峰值 |
| 如你有兴趣,我可以帮你写一个简单的 C++ 模拟实现,包括: |
- DebugHeap 类
- alloc/free 包装函数
- footer 检查
- category tag 日志记录
2005 年内存日志系统的时间轴分析能力(Memory Logging Over Time),也可以理解为早期游戏引擎中的**“内存快照 + 对比分析”工具**。这个功能对于调试内存泄漏、查看内存高峰、追踪异常增长等问题非常关键。
下面是详细解释:
时间轴日志系统(2005 Logging System)
你贴的关键词解释如下:
- Start of time / End of time
指的是两次内存快照的时间点,例如:- 游戏启动时
- 加载关卡前
- 进入战斗中
- 场景切换后
- Select Time
开发者可以从日志中选择任意时间点(或两个点)用于分析对比。
Snapshot(快照)
“whole snapshot of memory”
每个时间点系统会记录一份完整内存快照,包括:
- 当前所有的内存块
- 分配的地址、大小、category::allocname
- 分配堆(heap)
- 是否释放
示例条目:
| Addr | Size | Category | Heap |
| -------- | ---- | ------------------- | -------- |
| 0x123456 | 128B | gameplay::npc | GameHeap |
| 0x345678 | 64B | render::shadowcache | GfxHeap |
delta(内存变化对比)
“delta between 2 times”
当你选择两个时间点(如 A→B),系统会计算这段时间内:
| 项目 | 含义 |
|---|---|
| Alloc Count | 新增了多少次分配 |
| Alloc Size | 总共增加/减少了多少内存 |
| Category Changes | 哪些 category 增加最多 |
| Leaked Blocks | 哪些分配在 A 时有但 B 时还没释放 |
| 这就是所谓的 “内存差异分析” 或 delta report: | |
| Category | ΔCount |
| ----------------- | ------ |
render::mesh | +120 |
gameplay::enemy | +12 |
ui::tooltip | -8 |
主要用途
- 找内存泄漏:
- 看某些
alloc有没有“持续不释放” - 分析哪些 category 增长异常
- 看某些
- 理解场景变化带来的内存变化:
- 进入关卡 → 哪些系统增量最大?
- 某种粒子特效是否内存不回收?
- 优化内存预算:
- 看 category 的使用高峰
- 给团队分配预算参考
总结(中文)
| 概念 | 解释 |
|---|---|
| Memory Snapshot | 记录某一时刻完整的内存状态 |
| Time Selection | 选择任意两个时间点进行对比分析 |
| Delta Report | 比较两次快照的变化,包括分配次数和总大小 |
| Category Breakdown | 分析是哪些系统或类别的分配增长 |
| 日志输出 | 写入磁盘或调试工具,可用于可视化分析 |
| 这正是现代内存分析器(如 UE4 的 Memory Insights、Unity Profiler、RenderDoc)等工具的雏形。 |
2005 年内存调试工具中的 Arena(内存池)可视化视图 —— Arena Block View。这是用于查看内存分配情况的图形化界面,帮助开发者理解某个 Arena 中当前的内存布局和使用状态。
Arena Block View 是什么?
它是一个图形化调试工具,显示一个内存 Arena(或 Heap)里的每个内存块,包括:
- 哪些块被谁使用
- 哪些块空闲
- 块的大小和分布
- 当前选中块的详细信息
就像是给内存画了一张“地图”。
颜色含义(典型配色):
| 颜色 | 含义说明 |
|---|---|
| 🟩 绿色 Green | 系统(如 gameplay/render)正在使用的块 |
| 🟨 黄色 Yellow | 当前选中的块(用于查看详细信息) |
| 🟪 紫色 Purple | 演示系统用的内存块(如 UI、视频缓冲等) |
| ⬜ 灰色 Grey | 空闲的(free)内存块 |
功能示例
- 点击黄色块:查看这个块的详细信息,如:
Address: 0x12ACF000 Size: 256 bytes Tag: gameplay::npc Allocator: SmallBlockArena Age: 5.2 seconds - 颜色堆叠分布:帮助你理解碎片化程度和分布,比如:
- 一堆灰色碎块 → 空间被释放但无法整合成大块
- 很多小紫块 → UI 正在反复分配
- 展示 Arena 总大小 vs 已用大小,比如条形图:
[🟩🟩⬜⬜🟪🟨⬜⬜] (8KB blocks)
为什么重要?
- 找碎片化:可视化哪个 Arena 被割得像“披萨碎片”,不易重用
- 找泄漏:长期存在的绿色块可能是没释放的
- 优化资源布局:让内存分配更连续,利于缓存性能
- 团队内分析问题:看到哪个模块分配了多少块,便于追责或协作
总结(中文)
| 元素 | 含义 |
|---|---|
| Arena | 一块内存区域,通常按用途分,如 RenderArena、GameArena |
| Block | Arena 中的一个内存块,可能被使用或空闲 |
| 颜色标记 | 帮助快速区分谁用了哪些内存 |
| 可视化作用 | 显示内存使用布局,找碎片、查泄漏、优化性能 |
| 调试工具价值 | 是早期内存可视化调试器的重要组成部分 |
这页是在介绍2005 年游戏开发中用于内存错误检测的强力工具——“Stomp Allocator”。它是一个专门用于发现内存越界写(特别是写出边界)问题的调试分配器。
什么是 Stomp Allocator?
“Stomp Allocator” 是一种调试用内存分配器,它会在分配内存时故意制造条件,一旦代码写出边界就立刻崩溃(crash),以便在开发阶段快速发现内存越界 Bug。
结构解释(基于虚拟内存页)
每次分配都使用两页内存(例如 4KiB 一页):
[ Page 1 - Read/Write ] ← 用来存用户数据,前面一部分可用
[ Page 2 - ReadOnly / 未映射 ] ← 设置成不可写的保护页
比如:
|----------------| ← 4KiB RW 页
| [User Alloc] |
| 512B |
|----------------| ← 边界
| Guard Page | ← 4KiB 保护页(只读或根本没映射)
发生什么?
正常写入:
char* p = (char*)StompAlloc(512);
p[100] = 42; // OK
越界写:
p[1024] = 99; // 超过 512B,触发写到下一页
// 下一页是“只读”或“未映射”
// 程序立即崩溃,定位精确
为什么这么好用?
| 特点 | 说明 |
|---|---|
| 立即崩溃 | 一旦越界写,程序马上 crash,定位精确 |
| 替代 sentinel | 比“哨兵值”更主动更强力 |
| Debug 极有效 | 越界 Bug 很难发现,stomp 让它们“一击即中” |
| 利用虚拟内存保护机制 | 分配整页,操作系统级别防止非法访问 |
代价是什么?
| 问题 | 原因 |
|---|---|
| 非常浪费内存 | 每个小对象也要分配 4KiB(甚至 8KiB) |
| 性能开销高 | 页表、保护页修改开销大,不适合 release 模式 |
| 不能批量使用 | 不能用于大批量小对象的实际运行时分配,只能用于调试特定问题 |
衍生功能建议
“Use sentinel? Or Flip?”
- Use Sentinel:传统做法,用哨兵字节检查尾部是否被改写(低成本,但延迟发现错误)。
- Flip:
- 有时开发者会动态切换:
- 开启或关闭某些页的读写权限
- 或在 release 模式中不启用 stomp 分配器
- 或用双向 guard 页:
[ Guard ] [ Alloc ] [ Guard ]
- 有时开发者会动态切换:
总结(中文)
| 点 | 说明 |
|---|---|
| Stomp Allocator | 通过虚拟内存页保护实现越界写检测 |
| 原理 | 一页可写,一页只读/未映射 |
| 效果 | 越界写直接崩溃,方便定位 |
| 适用场景 | 调试阶段单元测试 / 找 Bug |
| 不适合 | 运行时、性能敏感场合 |
这页讲的是 2005 年游戏引擎中使用 引用计数指针(Ref Counted Pointers) 的挑战和建议,尤其是它在调试和生命周期管理中的复杂性。
核心概念
引用计数指针 (e.g. shared_ptr)
- 每次有新指针引用对象,计数 +1
- 每次引用销毁,计数 -1
- 当计数变为 0,自动释放内存
引用计数的问题(调试角度)
“Add a debug system for ref counts is hard”
1. 难以追踪引用链
- 谁增加了引用?
- 谁没有释放?
- 如果泄漏了,无法直接知道是哪个模块或函数负责。
举例图中描述的:
Sim → Player → ParticleSystem
Render → Player → Collision → Mesh
如果 Mesh 没释放,是因为哪个 Player 没释放?哪个系统保留了引用?很难定位。
2. 如果做全引用跟踪 → 就像垃圾回收器(GC)
“A tracking system would be like garbage collector…”
- 如果你想记录所有对象的引用关系,就得维护一整个图
- 就像 Java/C# 的垃圾收集器一样复杂
- C++ 引擎没这个成本或设计
3. 如果记录日志 → 会生成超大量数据
“A Logging system would generate even more data…”
- 每次引用增加/减少都记录日志
- 在大型游戏中,这会制造 海量 trace 数据
- 几乎不可用或难以查阅
解决方案建议(来自原文)
用 shared_ptr 是有用的
“shared_ptr are useful !!”
- 特别是用于多个子系统都可能引用一个资源(如 Mesh、Player、Collision)
☑ 但优先考虑以下替代方式:
| 替代方案 | 优点 |
|---|---|
unique_ptr | 生命周期简单、不会共享引用,适合局部逻辑 |
| ✴ 裸指针(bare ptr) | 更明确控制何时释放、更清晰所有权(适合短生命周期或静态对象) |
建议的设计哲学
| 情况 | 推荐做法 |
|---|---|
| 短生命周期,明确所有权 | unique_ptr |
| 无法明确所有权 / 多模块共享 | shared_ptr |
| 生命周期由全局控制 / 不拥有 | 裸指针 + 手动管理 |
总结(中文)
| 项目 | 说明 |
|---|---|
| 引用计数指针难调试 | 无法追踪谁加/减了引用,泄漏难找 |
| 引用跟踪像 GC | 会引入复杂的运行时开销 |
| 日志会爆炸 | 引用变动频繁,log 数据量大 |
| 建议 | shared_ptr 有用,但优先考虑 unique_ptr 或裸指针以简化生命周期 |
这页讲的是 2005 年游戏开发团队采用 EASTL(Electronic Arts Standard Template Library) 的原因,强调其相对于标准 C++ STL 在性能、内存管理、可读性、可控性方面的优势。
什么是 EASTL?
EASTL 是由 EA(Electronic Arts)为游戏开发专门设计的一套 C++ 模板库,目的是替代标准 STL,以满足游戏开发中对性能、内存控制、调试友好性的更高要求。
为什么不用标准 STL?
“STL allocators are painful to work with”
STL 的痛点(特别是 2005 年):
| 问题 | 原因 |
|---|---|
| 分配器接口复杂 | allocator 类型难用,修改 allocator 很痛苦 |
| 容器不可插入调试信息 | STL 没办法轻松标记 debug name 或分配来源 |
| 不支持 intrusive 容器 | 比如链表必须自己管理节点,STL 不允许这样 |
| 不可预测的分配行为 | 有些容器内部自己偷偷 new 内存,难以控制内存来源 |
| 没有 ring buffer 等 | 标准库功能不够多样,需手动实现一些常用结构 |
EASTL 的优势
| EASTL 特性 | 意义 |
|---|---|
| 自定义 allocator 系统 | 可以把 Arena、Heap、标签名都插进去 |
| 容器支持调试信息 | 可以传入 debug_name(比如 render::player) |
| 支持 intrusive 容器 | 低开销、高性能,适合内存池、链表管理等 |
| 支持 RingBuffer 等扩展容器 | 提供游戏常用的容器而不是通用场景 |
| 更好性能 | 没有多余的虚函数、异常支持,专为性能优化 |
| 更可控初始化行为 | 可以控制对象是否构造、何时分配内存 |
特别提到的问题
“Memory is allocated in empty versions of some STL objects”
这是对 标准 STL 的批评,例如:
std::string s;
在标准 STL 中,即使 string 是空的,也可能已经分配了 heap 内存!这会影响:
- 内存分析精度(你会看到未用数据也占了 heap)
- 堆碎片管理(很多小对象零散分配)
- 性能表现
EASTL 避免了这种行为,确保只有需要的时候才分配内存,有助于调试和追踪分配来源。
额外备注
“A 2010 version of EASTL is available now from webkit”
- 意思是后来 EASTL 开源了(可通过 WebKit 项目访问)
- 也就是你可以在 GitHub 上找到现代版本的 EASTL,用于非 EA 项目
总结(中文)
| 项目 | 说明 |
|---|---|
| EASTL 目的 | 替代 STL,提升性能、内存可控性 |
| 为什么不用 STL | 分配器不友好,调试难,不支持游戏常用容器 |
| EASTL 优势 | 支持自定义 allocator,支持 debug 标签,性能好 |
| 特别点 | 避免 STL 的“空对象分配内存”等问题 |
| 状态 | 2010 以后对外开源,有 GitHub 可用版本 |
EASTL 在性能优化场景下通常比标准 STL 稍快一些,但它不是在所有场景中都胜出,而是在多数重要场景中略有优势。
数据解读
你看到的是 EASTL 和 STL 在 188 个性能测试中的比较结果:
| 测试结果 | 含义 |
|---|---|
| EASTL 更快:71 次 | EASTL 速度达到或超过 STL 的 1.3 倍 |
| EASTL 更慢:10 次 | EASTL 的速度只有 STL 的 0.8 倍或更差 |
| 其他(107 次) | EASTL 和 STL 差别不大(中间地带) |
“Faster means 1.3x or better.”
“Slower means 0.8x as quick or slower.”
也就是说:
- 如果 EASTL 快,是显著快
- 如果它慢,那也是明显慢
- 但大部分测试差距不大
小结要点
| 内容 | 理解 |
|---|---|
| EASTL 在多数场景略快 | 在 71 次测试中 ≥1.3x,适合对性能敏感的系统 |
| 有些情况 EASTL 也可能慢 | 在 10 次中 ≤0.8x,表明某些 STL 优化场景可能更成熟 |
| 多数场景下两者性能差不多 | 在 100 多次测试中两者表现接近 |
| EASTL 更适合游戏/实时系统优化 | 它的设计初衷就是针对这类高性能需求 |
结论(中文)
EASTL 相对 STL:
- 通常略快,在性能关键场合(如游戏主循环、AI、渲染排序)更合适
- 更可控,更好地集成自定义分配器与调试信息
- 分析更方便,不会有 STL 那种“空对象也偷偷分配内存”的问题
但也不是银弹: - 并不是总快,特定 STL 用法在某些编译器上优化得更好
- 值得在关键路径使用,尤其是当你控制 allocator 和容器行为时
这页强调的是:在 Debug 模式下,EASTL 相比标准 STL 快得多,几乎在所有测试中都胜出。
数据说明(Debug 模式下的 188 个性能测试):
| 测试结果 | 数量 | 含义 |
|---|---|---|
| EASTL 更快 | 164 | EASTL 执行时间是 STL 的 1.3 倍更快或更好 |
| 表现差不多 | 19 | EASTL 和 STL 差异很小 |
| EASTL 更慢 | 2 | EASTL 明显慢(≤ 0.8x) |
为什么 Debug 模式下 STL 这么慢?
STL 在 Debug 模式下启用了大量“安全检查”,例如:
| STL Debug 模式特性 | 后果 |
|---|---|
| iterator 检查 | 每次迭代都要验证合法性 → 性能大幅下降 |
| bounds 检查 | 访问元素要做越界检测 |
| 拷贝构造/析构频繁调用 | 模拟真实运行 → 更慢 |
| 分配器使用不统一 | 可能频繁堆分配 |
EASTL 为什么快?
EASTL 设计就是为**性能敏感场景(特别是游戏引擎)**打造:
| EASTL 优化点 | 效果 |
|---|---|
| 没有 iterator 检查 | 提高迭代性能 |
| 无额外 Debug 辅助开销 | 不在 Debug 模式里做 STL 那些慢操作 |
| 支持自定义 allocator | 分配速度快,避免堆碎片 |
| 容器结构轻量 | 结构简单,拷贝/移动更快 |
总结(中文)
| 点 | 说明 |
|---|---|
| EASTL 在 Debug 模式中压倒性更快 | 在 164 / 188 次测试中胜出 |
| STL 在 Debug 模式有大量额外负担 | 使得测试极慢,不适合调试高性能系统 |
| EASTL 几乎没有 Debug 限制逻辑 | 使得 Debug 构建更接近 Release 行为 |
| EASTL 更适合游戏和嵌入式开发 | 因为 Debug 构建也要能流畅运行并测试帧率 |
小建议:
如果你在做游戏引擎、实时仿真系统或控制系统:
- 优先使用 EASTL 或自定义容器
- 即便是 Debug 构建也能跑得快 → 更易发现真实逻辑 bug
- 不用担心 STL 的 iterator 检查带来的性能陷阱
你这页内容分成了两个部分,下面分别解释:
第一部分:Open Sourcing EASTL
| 信息点 | 含义 |
|---|---|
| EA 准备开源 EASTL | Electronic Arts 决定让 EASTL 对外开源 |
| Roberto Parolin 接受 PR | EA 的工程师 Roberto Parolin 将负责维护并接受社区提交(pull request) |
| GitHub 地址 | 代码托管在 EA 的 GitHub: https://github.com/electronicarts |
| 技术细节稍后公布 | 细节将在 C++ 标准委员会的 SG14 小组中发布(SG14 是专注于“低延迟和嵌入式系统”的 C++ 小组) |
| 总结: EASTL 计划开源,将接受社区改进并持续维护,是游戏开发者和嵌入式系统开发者的重大利好。 |
第二部分:2005 EASTL 的内存跟踪问题
这部分说明 EASTL 在早期版本中(2005年)使用 allocator 跟踪内存分配比较麻烦。
问题:每次用 EASTL 容器都需要明确 allocator 类型
比如使用 eastl::vector<int> 时:
typedef eastl::vector<int, EASTLICoreAllocator> MyVec;
你要:
- 明确 allocator 的模板参数(不像 STL 容器那样可以默认)
- 必须手动传入 allocator 实例:
ICoreAllocator* alloc = GetGameplayAllocator();
MyVec vec(alloc);
为何这是个问题?
| 问题 | 原因 |
|---|---|
| 每个容器都要单独 typedef | 增加代码复杂度,无法复用模板通用代码 |
| 必须手动传 allocator | 增加出错可能(忘记传/传错) |
| 无法轻松做统一分配跟踪 | allocator 无法自动携带 debug name / category |
| 测试或日志系统难以集成 | 无法自动知道某个 vector 是属于哪个模块 |
后续改进方向(后来 EASTL 的做法)
现代 EASTL 引入了更自动化的 allocator 架构,例如:
EASTLAllocatorType allocator("render::player");
eastl::vector<int> v(allocator);
并且使用 默认全局 allocator + 分配器标签信息(debug name)能自动帮你追踪分配来源。
中文总结
| 内容 | 说明 |
|---|---|
| EASTL 将开源 | 托管在 EA GitHub 上,未来可参与开发 |
| 早期 EASTL allocator 使用繁琐 | 每个容器要指定 allocator 类型和构造时传入实例 |
| 原因 | 为了性能与分配器自定义,但导致调试与跟踪难度高 |
| 后续改进方向 | 更智能的 allocator 接口,支持 debug name 和自动分配器识别 |
这页讲的是 2005 年 EASTL 在内存跟踪时遇到的一个具体“使用难点”——默认参数设计导致强制使用自定义 allocator 很难做到。
内容拆解
1. EASTL 容器构造函数带有默认参数
以 unordered_map 为例:
unordered_map(
size_type n = 1000,
const hasher& hf = hasher(),
const key_equal& eql = key_equal(),
const allocator_type& alloc = allocator_type() // 默认 allocator 参数
);
- 构造函数参数有默认值,尤其是 allocator 也是默认构造的。
- 这样调用时,如果用户不显式传 allocator,就会用默认的 allocator_type(),这意味着不能强制用户传入定制的分配器。
2. 这导致的麻烦:
| 问题 | 说明 |
|---|---|
| 用户容易忽略传 allocator 参数 | 因为默认参数存在,用户可能不传,分配器就不是自定义的 |
| 内存跟踪失效 | 不能保证每个容器都用正确的、可跟踪的 allocator |
| 虽然能用,但很麻烦 | 需要额外调用接口,手动替换 allocator |
3. 解决方案(但不优雅)
EA::ICoreAllocator* alloc = GetRendAllocator();
vec.get_allocator().set_allocator(alloc);
- EASTL 容器默认构造时可能没有传 allocator。
- 这里是先默认构造,再用
get_allocator().set_allocator()手动设置 allocator。 - 虽然能工作,但非常不方便,使用流程冗长且容易出错。
总结
| 现象 | 说明 |
|---|---|
| EASTL 容器构造函数默认 allocator 参数 | 导致很难强制用户传自定义 allocator |
| 内存分配跟踪因此困难 | 容器可能用了默认 allocator,跟踪不准确 |
只能通过手动调用 set_allocator 解决 | 但使用体验差,容易漏掉或写错 |
2005 年为了方便内存跟踪,EA团队一开始对 EASTL 做了一些“临时”改动,但带来了新的问题:
主要内容解析:
1. “Hack” EASTL 让使用 allocator 更简单
vector v(eastl::allocator("AI::Piano::Input"));
- 直接在构造
vector时传入带有**字符串标识(debug 名称)**的 allocator。 - 这样方便在调试时直接知道这个容器属于哪个模块(比如 AI 模块的 Piano 输入部分)。
2. 但这样做的弊端:
| 问题 | 说明 |
|---|---|
| 不同团队代码难以共享 | 因为每个团队可能传入不同的 allocator 名称,导致容器和分配器强耦合 |
| 用字符串作为 allocator 标识不靠谱 | 运行时字符串查找、易出错,且难以统一管理和跟踪 |
| 这种 hack 只是临时方案 | 不利于长期维护和跨团队协作 |
总结:
| 结论 | 说明 |
|---|---|
| 直接通过带名字的 allocator 构造容器是简便但不健壮 | 增加团队间依赖和代码复杂度 |
| 更好的方案是用统一的 allocator 管理和共享机制 | 避免字符串管理带来的问题 |
这页讲的是 EASTL 在内存跟踪中遇到的类型擦除(type erasure)问题,尤其是不同 allocator 类型导致的容器赋值兼容性问题。
内容拆解
1. 代码示例说明问题
typedef vector<int, EASTLICoreAllocator> MyVec;
typedef vector<int> YourVec;
MyVec myVec;
YourVec yourVec;
myVec = yourVec; // 出错!
MyVec是带有自定义 allocator 的vector<int>。YourVec是默认 allocator 的vector<int>。- 两者类型不同,无法直接赋值。
2. 问题原因
| 原因 | 说明 |
|---|---|
| 模板类型不同导致不兼容 | vector<int, EASTLICoreAllocator> 和 vector<int> 被视为完全不同的类型 |
| C++ 没有内置“类型擦除”机制允许不同 allocator 的容器相互赋值 | 编译器报错:没有适合的赋值运算符或转换 |
| 这使得跨 allocator 的容器操作复杂 | 不能简单地把带有一个 allocator 的容器赋值给带有另一个 allocator 的容器 |
3. 类型擦除 (Type Erasure) 的含义
- 类型擦除是指隐藏模板参数(如 allocator)实现接口统一,使不同实现能互操作。
- EASTL 当时没有完善的类型擦除机制,导致不同 allocator 的容器无法相互赋值。
总结
| 现象 | 说明 |
|---|---|
| 不同 allocator 的容器类型不同 | 导致赋值操作编译失败 |
| 缺少类型擦除机制 | 不能轻松让容器间互换数据 |
| 这给内存跟踪和代码复用带来麻烦 | 需要开发者手动管理不同类型容器 |
这页讲的是 2005 年 EA 团队为了解决 EASTL 内存分配和跟踪问题,设计了一个叫 EASTLICA 的封装层,用来强制使用多态(polymorphic)allocator,从而简化和规范 allocator 的使用。
内容拆解
1. 问题背景
- EASTL 容器需要传 allocator,但用法复杂且容易出错。
- 希望强制所有容器都使用 同一个接口的多态 allocator(
ICoreAllocator*),方便管理和跟踪。
2. EASTLICA 的设计思路
- 使用模板继承封装 EASTL 容器,比如
String。 String继承自 EASTL 的base_string,并固定 allocator 类型为EASTLICoreAllocator。- 构造函数接收一个
ICoreAllocator*和一个字符串名字(用于调试/标记)。 - 在构造时,创建一个
EASTLICoreAllocator实例(传入名字和 allocator 指针)传给基类。
3. 代码示例
template <typename T>
class String : public base_string<T, EASTLICoreAllocator> {
public:
String(ICoreAllocator* alloc, const char* name = "Str")
: base_string<char, EASTLICoreAllocator>(
EASTLICoreAllocator(name, alloc))
{
// 其他初始化
}
};
- 这样用户用
EASTLICA::String就必须传入一个ICoreAllocator*。 - 例子:
ICoreAllocator* alloc = GetStringAllocator();
EASTLICA::String str(alloc);
4. 优势
| 优点 | 说明 |
|---|---|
| 统一 allocator 接口 | 所有 EASTLICA 容器都用 ICoreAllocator* 管理 |
| 强制分配器传递,避免默认 allocator | 减少忘传或误用问题 |
| 方便调试和内存跟踪 | 传入调试名字,能更精准地定位内存来源 |
| 团队共享代码更简洁 | 代码风格统一,便于维护 |
总结
- EASTLICA 是对 EASTL 的封装,提供了强制的多态 allocator 使用接口。
- 这种做法提升了 EASTL 容器内存管理的灵活性和可跟踪性。
- 解决了 2005 年 EASTL allocator 使用复杂和跟踪困难的问题。
这页讲的是 EA 用宏(macro)来简化和统一 EASTLICA 容器的定义,方便为不同子系统快速创建类似 STL 的容器类型。
具体内容解析
1. 宏定义作用
#define EASTLICA_VECTOR( EASTLICA_TYPE, GET_DEFAULT_ALLOC, ALLOC_NAME ) \
template<typename T> class EASTLICA_TYPE : public EASTLICA::Vector<T>
- 这个宏定义用来快速声明一个模板类
EASTLICA_TYPE,它继承自EASTLICA::Vector<T>。 - 其中
EASTLICA::Vector<T>是封装了多态 allocator 的 EASTL vector。 - 宏后面一般会配合具体子系统调用,用于生成对应的容器类型。
2. 宏使用示例
EASTLICA_STRING( CareerModeString,
CareerMode::GetStringDefaultAllocator(), "CareerStr");
- 这个示例展示了类似用法,为 CareerMode 子系统创建一个名为
CareerModeString的 EASTLICA string 类型。 - 宏会自动帮你把该类型绑定到对应的默认 allocator 和调试名
"CareerStr"。
3. 意图和优势
| 作用 | 优点 |
|---|---|
| 用宏快速生成类型定义 | 减少重复代码,写法统一 |
| 每个大系统用独立类型 | 清晰标识不同子系统的 allocator |
| 简化 allocator 绑定 | 容器和 allocator 一体化管理 |
总结
- EA 用宏封装 EASTLICA 容器定义,提升开发效率。
- 每个子系统可以快速创建自己专用的容器类型,方便管理内存分配。
- 这样既保证了灵活性,也便于调试和追踪。
这页讲的是 用 EASTLICA 宏封装后,解决了之前 EASTL 里因不同 allocator 导致的类型不兼容(type erasure)问题,同时也理顺了内存所有权管理。
具体内容解析
1. 解决类型擦除问题
CareerModeString str;
LocalizedString lstr = getStrId(42);
str = lstr; // 编译通过!
CareerModeString和LocalizedString都是用 相同的 allocator 类型(通过 EASTLICA 宏定义实现的)。- 因为统一了 allocator 类型,赋值操作不再报错,编译器认可二者兼容。
- 解决了之前直接用不同 allocator 类型导致的赋值失败问题。
2. 解决所有权问题
- CareerMode 字符串拥有自己的字符串内存(own strings),负责管理生命周期。
- Localization(本地化)字符串不拥有所有字符串,可能是共享或只引用,生命周期不同。
- EASTLICA 通过 allocator 管理让这两种不同的所有权场景都能正确处理。
3. Allocators 的拷贝
- 在某些情况下,allocator 会被拷贝(复制),但不是所有情况都拷贝。
- 这允许灵活管理内存归属和生命周期。
总结
| 解决的问题 | 说明 |
|---|---|
| 类型擦除(type erasure) | 统一 allocator 类型后,容器赋值兼容 |
| 所有权管理 | 支持不同子系统对字符串的拥有权差异 |
| 灵活的 allocator 复制 | 允许根据需求决定 allocator 是否拷贝 |
| 这就是 EASTLICA 通过封装 allocator 带来的最大改进:统一内存管理接口,提升代码复用和安全性,同时支持复杂的所有权模型。 |
现代(PS4、Xbox One 时代)的内存系统现状和主要特点,对比早期有了很大进步:
内容解析
1. 硬件环境
- 内存容量大幅提升:8GB 总内存,约5GB 留给游戏使用
- 64位虚拟地址空间:地址空间更大,支持更多内存和更灵活的管理
- 带硬盘(HDD):允许虚拟内存和数据交换,不再局限于纯内存空间
- GPU内存管理更灵活:
- GPU内存不需要线性映射
- GPU资源管理依然特殊,需要专门处理
2. 主要变化和趋势
| 重点方向 | 说明 |
|---|---|
| Debug Memory System | 增强的调试内存系统,方便找内存问题 |
| EASTL Memory Tracking | 使用 EASTL 的内存跟踪功能,精确统计和定位内存使用 |
| 新的调试工具 | 更新和增强的工具帮助调试性能和内存问题 |
总结
现代主机环境提供了更大、更复杂的内存系统,软件层面通过 先进的内存跟踪和调试机制 来充分利用硬件优势,减少内存错误和泄漏,提升开发效率和游戏质量。
这页讲的是 现代调试内存系统的演变和使用方法,特别是从过去依赖“分配调试名”向更结构化的“作用域(scopes)”管理转变。
具体内容解析
1. 调试名的变化
- 传统方式:给每次分配传递一个调试名字(alloc debug names),比如
operator new(size, "MyAlloc")。 - 现在趋势:这种方式慢慢被淘汰了,变得不够灵活和高效。
2. 新的调试接口
void* operator new(size_t size, EA::ICoreAllocator* alloc);
- 依然支持传 allocator 的分配接口,但调试信息更依赖“作用域”管理。
- Scopes(作用域)无处不在,比如资源名、资产名等。
3. Scope 的好处和用法
- 通过作用域追踪内存分配,自动绑定相关信息:
- 分配名称(Alloc Name)
- 分配器(Allocator)
- 分类(Category)
- 调用堆栈(Call stacks)
- 例子:
FB_MEMORYTRACKER_SCOPE(data->debugNames[i]);
FB_ALLOC_RES_SCOPE(data->debugNames[i]);
- 这些宏用来定义当前内存操作的上下文,方便追踪和调试。
4. 缺点
- 更多依赖 线程本地存储(Thread Local Storage, TLS),以便在不同线程间维护作用域信息,可能带来性能开销。
总结
| 变化点 | 说明 |
|---|---|
| 从单一调试名向作用域扩展 | 作用域能自动绑定更多上下文信息,调试更准确 |
| 保留老接口但逐步过渡 | 兼容性好,同时推动新模式发展 |
| 线程本地存储的广泛使用 | 方便多线程追踪,但需注意性能影响 |
这页讲的是 即使到了现在,大家依然用传统方式结合 EASTL 容器进行内存管理,但 EASTL 的内存跟踪依然存在问题。
内容拆解
1. 示例代码说明
class Team {
int teamid;
eastl::vector<player> players;
};
Team* home = new (allocator) Team;
- 用 EASTL 的
vector管理玩家列表。 - 通过自定义 allocator 分配
Team对象。 - 这是当前普遍的做法。
2. 但 EASTL 跟踪仍有问题
- EASTL 的内存分配和跟踪机制对复杂对象(尤其带自定义 allocator 的容器)支持仍不够理想。
- 可能导致:
- 内存泄漏难以定位
- 统计不精确
- 调试时不方便查看容器内存分配详情
总结
虽然大家依旧用 EASTL 容器结合自定义 allocator 进行内存管理,但 EASTL 本身的内存跟踪和调试功能还有不足,这是当下需要改进的地方。
这页讲的是 EASTL 容器默认用“父 arena”来跟踪和管理内存分配,方便内存分配结构化,具体是说:
具体内容解析
1. 结构示意
Team Home是一个整体分配(one allocation),里面有:int teamId;eastl::vector<player> players;
players这个 vector 本身也会分配内存(比如存放 Player 元素的数组)。
2. “Parent Arena” 概念
- vector 内部分配内存时,默认会用 父 arena(这里是
Gameplay Arena或Team Home的 arena)来做管理。 - 这样分配出来的内存形成树状结构,方便整体追踪。
3. Child Arena 灵活使用
- 虽然默认用父 arena,子对象也可以用不同的 arena。
- 例如,
players的内存分配不一定要用通用 allocator,可以用更专门的:Gameplay的小块分配器(Small Block Allocator)- 或其他适合的小型分配区域
4. 管理优势
- 通过这种 parent-child arena 机制:
- 内存分配关系清晰
- 更方便定位内存使用
- 支持不同对象灵活选择合适的分配器,提高效率
总结
| 关键点 | 说明 |
|---|---|
| 默认使用父 arena 分配 | 避免内存碎片,方便跟踪 |
| 子 arena 可以灵活切换 | 根据需求选择更合适的 allocator |
| 形成分配层次结构 | 方便内存调试和性能优化 |
这页讲了 EASTL 默认用父 arena 跟踪内存分配时遇到的一些问题和限制,以及应对策略。
内容拆解
1. 存在的问题
- CPU 开销:跟踪 arena 层级关系会消耗一定的 CPU 资源。
- 栈上对象:对于存在于栈上的对象,arena 跟踪机制不适用,因为它们不在堆上分配。
- 移动操作(move operators)问题:
- 例如,一个对象原本在
gameplay arena,后来被移动到rendering arena。 - 这种情况下,只有父对象的 arena 变了,内部子对象的 arena 可能没变,导致跟踪不一致。
- 例如,一个对象原本在
- “你创建你拥有”逻辑:
- 默认假设对象移动后依然“拥有”原来的内存,适用于80%的场景。
- 剩下的20%场景就会出问题。
2. 应对方案
- 对于复杂场景,建议使用 EASTLICA 模式:
- 特别适合“系统为其他系统工厂”的情况(Factory 模式)
- 能更灵活地管理不同 allocator 和 arena 间的关系,解决移动对象时的跟踪问题。
总结
| 问题点 | 说明 |
|---|---|
| 跟踪带来的 CPU 开销 | 需要权衡性能和调试需求 |
| 栈对象无法跟踪 | 只针对堆分配对象 |
| 移动操作 arena 跟踪困难 | 需要更复杂的策略避免跟踪失效 |
| 80% 规则 | 大部分场景下简单规则够用,但非全部 |
| 复杂场景用 EASTLICA | 解决特殊场景下的内存管理难题 |
这页讲的是 现代调试工具 DeltaViewer 的基本功能和工作流程,总结如下:
内容解析
1. 工具简介
- DeltaViewer 是一个用来展示和分析游戏运行期间内存数据的工具。
- 一次 session 指的是游戏的一次完整运行过程。
2. 数据流程
- 游戏在运行时,将内存数据(如分配、释放、堆使用情况等)发送到:
- 运行在 软件工程师(SE)或质量保证(QA)人员)电脑上的 HTTP 服务器。
- 服务器接收数据后,将其组织成结构化的 数据表。
3. 数据处理
- 这些表可以通过 表连接(join),生成更加丰富的 视图(views)。
- 视图帮助开发者更方便地理解内存使用情况,比如:
- 分配变化对比
- 内存泄漏分析
- 堆碎片化情况
总结
| 关键点 | 说明 |
|---|---|
| DeltaViewer 展示数据 | 通过界面查看内存分配和变化 |
| Session 是一次游戏运行 | 分析单次游戏运行的完整内存信息 |
| 数据传输到 HTTP 服务器 | 实时收集游戏内存数据 |
| 数据存储为表和视图 | 方便查询、组合和分析内存数据 |
这页介绍了 DeltaViewer 中几个常用的视图(Views)和它们的用途,具体如下:
内容解析
1. TTY events debugging (Trace Log)
- 用来调试文字终端事件,类似日志追踪(trace log)。
- 可以查看游戏运行时发生的各种事件和调试输出。
2. IO Load profiler (Turbo Tuner)
- 用于分析游戏的输入输出(IO)负载。
- 帮助找出磁盘读写、资源加载的瓶颈。
3. Frame rate and Job thread profiler (Performance Timer)
- 监控帧率和多线程作业执行时间。
- 帮助优化渲染性能和多线程效率。
4. Memory Investigator
- 专门审查内存泄漏和内存使用随时间的变化。
- 重点关注内存分配、释放,帮助定位泄漏点。
5. Memory Categorization
- 按类别对内存分配进行分组和统计。
- 方便分析不同功能模块的内存消耗。
总结
| 视图名称 | 功能描述 |
|---|---|
| TTY events debugging | 查看日志事件,调试程序运行流程 |
| IO Load profiler | 分析磁盘和资源加载的负载 |
| Frame rate & Job profiler | 监控性能和多线程执行效率 |
| Memory Investigator | 审查内存泄漏及变化 |
| Memory Categorization | 分类统计内存分配,便于资源管理 |
这几页详细介绍了 DeltaViewer 里“IO Load profiler(Turbo Tuner)”的功能和用法,以及它如何帮助理解游戏资源加载情况。总结如下:
1. TTY events debugging (Trace Log) 简介
- 层级显示事件日志(Level 1, Level 2),类似分级日志,方便跟踪不同重要性事件。
2. IO Load profiler (Turbo Tuner) 主要内容
资源分类
- Bundle:一组必须加载的文件,通常对应游戏中的“关卡”或子关卡。
- Chunks:游戏中的数据块,比如视频、音乐或开放世界游戏里的地形数据,是流式加载的单元。
时间线 (Timeline)
- 按时间顺序展示加载的 Bundle 和 Chunks。
- 方便看到什么时候加载了哪些资源。
事件关联
- 每个 printf(打印信息)在所选频道上产生一条事件线。
- 通过事件线,可以精确了解某个加载动作发生的时间点。
3. 实际问题分析举例
- 在“Loading Level 1”后进入“Playing Level 1”,但为什么还在加载“Level 2”的 Bundle?
- 通过查看加载时间线和事件,可以定位不合理的加载行为,进行优化。
4. 界面交互
- 鼠标悬停(Hover)在 Bundle 上可以显示其名称和详细信息,帮助快速识别资源。
总结
| 关键词 | 说明 |
|---|---|
| Bundle | 关卡或子关卡所需文件的集合 |
| Chunks | 按需流式加载的数据块(视频、音乐、地形等) |
| Timeline | 加载操作的时间轴视图 |
| 事件线 | 关联打印日志的加载事件,精准定位加载时机 |
| Hover | 悬停显示资源详细信息 |
这几页讲的是 Frame rate 和 Job 线程分析器(Performance Timer),以及结合加载分析的使用,具体如下:
1. Frame rate 和 Job thread profiler
- 每个矩形代表一帧(Frame):
- 矩形的高度表示该帧所用时间(单位:毫秒)。
- 蓝色矩形表示选中的帧,选中的帧信息会显示在视图顶部。
- “Expensive Frame”(耗时帧)表示运行时间较长的帧,可能是性能瓶颈。
- 显示帧的开始和结束时间。
- 可以查看 Job(工作任务) 及其内部调用的函数,帮助追踪性能热点。
2. 加载分析和帧率分析结合
- 这两个视图可以结合使用,原因是游戏加载不仅仅是磁盘性能问题,还涉及 CPU 和 GPU 的其他工作。
- 例如:
- 解压缩数据(Decompression)
- 给纹理打字(如贴字体)
- 重新压缩并上传纹理到显存(VRAM)
- 加载过程往往被 CPU 限制,不只是磁盘 I/O。
总结
| 内容点 | 说明 |
|---|---|
| 矩形代表帧 | 高度表示帧耗时(ms),蓝色是选中帧 |
| Expensive Frame | 性能瓶颈帧,耗时长的帧 |
| Job 和函数调用 | 分析多线程任务和具体函数性能 |
| 结合加载和帧率分析 | 加载过程涉及 CPU、解压、纹理处理等,不只是磁盘 I/O |
这页介绍了用 Memory Investigator 工具来检测和定位内存泄漏的流程和思路。总结如下:
1. 检测内存泄漏的基本思路
- 选取关键时间点:
- A:开始加载第1关
- B:第1关加载结束
- C:第2关加载结束
- 通过对比这几个时间点的内存分配情况,找出那些在 B 和 C 之间没有被释放的对象。
2. 操作步骤
- 捕获 A 到 B 之间的所有内存分配(allocs)。
- 到 C 时间点时,这些对象理应都已释放(free)。
- 如果某些对象仍然存在,即在 T1 分配但 T2 未释放,说明是 内存泄漏(LEAK)。
3. 工具界面
- 会列出所有检测到的泄漏对象,包括:
- 资产名称(Asset Name)
- 指针地址(Ptr)
- 大小(Size)
- 完整的调用堆栈(Call Stack)
- 唯一的堆栈ID(ID)
- 支持查看单个泄漏对象的详细调用堆栈,方便定位泄漏代码位置。
4. 额外说明
- 有时某些对象会“看起来像泄漏”,但随着游戏进程推进(多个关卡后)会自然释放,类似于“增长”的情况。
- 如果支持realloc(重新分配),可以减少这种假漏报。
总结
| 关键点 | 说明 |
|---|---|
| 时间点选取 | 选择关键加载开始和结束时间点对比内存分配情况 |
| 捕获分配 | 捕获加载期间的所有内存分配 |
| 比较释放 | 确认加载结束时是否有内存未释放 |
| 漏洞详情 | 资产名、地址、大小和调用堆栈 |
| 假漏报问题 | 部分对象增长后自然释放,需结合上下文判断 |
总结
Memory Categorization(内存分类)
- 通过 Turbo Tuner 等工具找出重要时间点,然后可以在不同时间点之间切换(scrub)查看内存变化。
- 大块内存分配(>= 2MB)占用绝大部分空间。
- 大量小块分配(<=512字节)数量多,但总体占用相对小。
- 渲染相关内存(procedural textures、缓冲区等)占用明显,但在整体大内存比例中不算大(例如示例中50MB)。
- 内容相关内存(模型、纹理、实体绑定等)占用大部分内存。
总结
DeltaViewer功能
- 支持多种视图:
- TTY事件时序(Trace Log)
- IO和加载时间分析
- Job和线程分析
- 内存变化追踪
EASTL和STL分配器问题
- 跟踪内存分配难度大。
- 建议使用“你造它,你就拥有它”的原则管理生命周期。
- 将分配器指针作为参数传递,方便追踪和管理。
- EASTLICA封装帮助统一分配器使用,解决类型擦除等问题。
游戏内存特点
- 大多数内存由大型分配占用(模型、纹理)。
- 同时存在大量小型分配。
- 小块分配器、池化分配器、slab分配器是优化好选择。
- Stomp Allocator非常有用,可以用内存映射快速定位写越界。