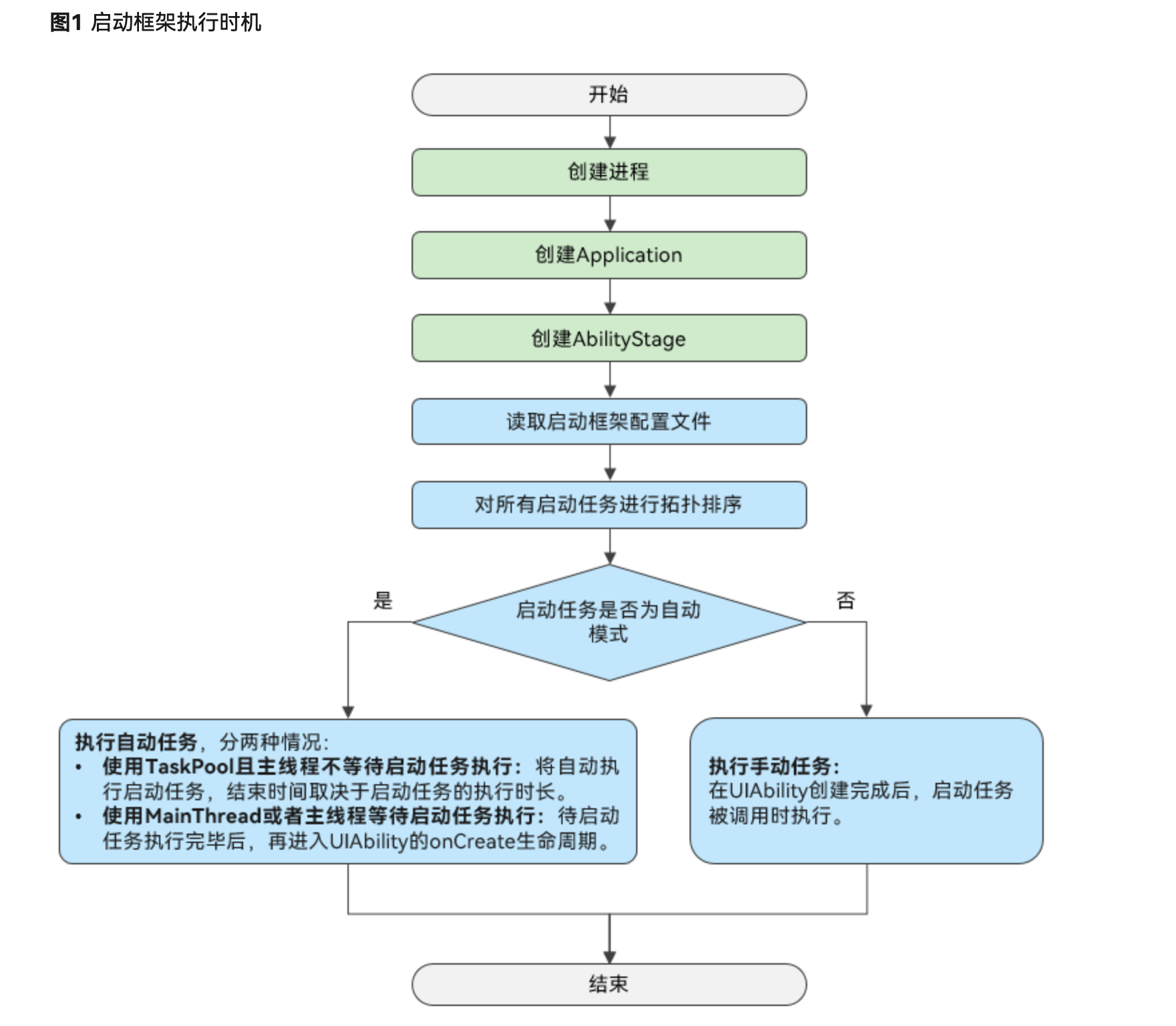
DQN算法
DQN算法使用的常见问题
Q1: 为什么用目标网络而非Q网络直接计算?
- 答案:避免“移动目标”问题(训练中Q网络频繁变化导致目标不稳定),提高收敛性。
Q2: 为什么用 max 而不是像SARSA那样采样动作?
- 答案:Q-learning是离线策略算法,直接选择最优动作的Q值(SARSA是在线策略,需采样实际动作)。
Q3: 如果动作空间连续怎么办?
- 答案:需改用DDPG等算法,通过Actor网络输出确定性动作。
DQN算法中的神经网络是如何代替Q值表的
NN代替Q值表的必要性
(1) 处理高维状态(如图像、语音)
- 传统 Q-learning 只能处理低维离散状态(如格子世界),但现实问题(如自动驾驶、游戏 AI)的状态可能是图像、雷达数据等高维输入。
- 神经网络(如 CNN)可以自动提取特征,例如:
- Atari 游戏(输入是像素)→ CNN 提取空间特征。
- 机器人控制(输入是传感器数据)→ MLP 或 LSTM 处理时序。
(2) 泛化能力(Generalization)
- Q-table 必须遍历所有 (s,a)(s,a) 才能学习,但神经网络可以通过相似状态 泛化:
- 例如:在迷宫游戏中,即使遇到新路径,神经网络也能基于相似状态预测 Q 值。
(3) 端到端学习(End-to-End Learning)
- 传统方法需要手工设计状态特征(如“距离目标多远”),但 DQN 可以直接从原始输入(如像素)学习策略,减少人工干预。
(4) 适用于连续动作空间
- Q-table 只能处理离散动作(如“左/右/跳”),但神经网络可以输出连续动作(如“方向盘转角 30°”)。
神经网络的优势
| 对比维度 | Q-table | DQN(神经网络) |
|---|---|---|
| 存储方式 | 离散表格存储 | 连续函数逼近 |
| 适用场景 | 低维离散状态 | 高维连续状态(图像、传感器数据) |
| 泛化能力 | 只能查表,无法泛化 | 相似状态自动泛化 |
| 训练方式 | 直接更新 Q 值 | 梯度下降优化 NN |
| 计算效率 | 状态多时存储爆炸 | 参数量固定,适合 GPU 加速 |
NN如何具体代替Q值表
之前我们学习的Q值表,其中s和a分别代表横纵坐标。值表示的是当前的Q值。但是当我们用DQN表示Q值表之后,输入的是各种状态
lr = 2e-3
num_episodes = 500
hidden_dim = 128
gamma = 0.98
epsilon = 0.01
target_update = 10
buffer_size = 10000
minimal_size = 500
batch_size = 64
device = torch.device("cuda") if torch.cuda.is_available() else torch.device(
"cpu")
env_name = 'CartPole-v0'
env = gym.make(env_name)
random.seed(0)
np.random.seed(0)
env.seed(0)
torch.manual_seed(0)
replay_buffer = ReplayBuffer(buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
agent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon,
target_update, device) # 构建智能体
return_list = []
for i in range(10):
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:
for i_episode in range(int(num_episodes / 10)):
episode_return = 0
state = env.reset()
done = False
while not done:
action = agent.take_action(state) # 先采取贪婪策略获得动作
next_state, reward, done, _ = env.step(action)
# 其中的env是gym环境,env.step()函数会获得环境给予的反馈
replay_buffer.add(state, action, reward, next_state, done)# 然后将函数给与的反馈加入到缓存中
state = next_state # 并且下一个状态也是.step()函数给出的,不断将新状态加入到缓存中,并将新状态赋值给当前的状态
episode_return += reward
# 当buffer数据的数量超过一定值后,才进行Q网络训练,这一点沿用的是n-step Sarsa算法中的滑动窗口策略
if replay_buffer.size() > minimal_size:
b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size) # 然后开始随机采样,注意在n-step Sarsa算法中采用的是用n步后的数据逐个更新当前数据。而在DQN算法中是随机采样,会在buffer中随机采取数据然后去更新agent。
transition_dict = {
'states': b_s,
'actions': b_a,
'next_states': b_ns,
'rewards': b_r,
'dones': b_d
}
agent.update(transition_dict) # 用随机采样的结果再次去更新agent
return_list.append(episode_return)
if (i_episode + 1) % 10 == 0:
pbar.set_postfix({
'episode':
'%d' % (num_episodes / 10 * i + i_episode + 1),
'return':
'%.3f' % np.mean(return_list[-10:])
})
pbar.update(1)
然后我们接着看DQN的类:
class DQN:
''' DQN算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma,
epsilon, target_update, device):
self.action_dim = action_dim
self.q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device) # Q网络
# 目标网络
self.target_q_net = Qnet(state_dim, hidden_dim,
self.action_dim).to(device)
# 使用Adam优化器
self.optimizer = torch.optim.Adam(self.q_net.parameters(),
lr=learning_rate)
self.gamma = gamma # 折扣因子
self.epsilon = epsilon # epsilon-贪婪策略
self.target_update = target_update # 目标网络更新频率
self.count = 0 # 计数器,记录更新次数
self.device = device
def take_action(self, state): # epsilon-贪婪策略采取动作
if np.random.random() < self.epsilon:
action = np.random.randint(self.action_dim)
# 这是一个随机整数生成函数,返回一个在 [0, self.action_dim) 区间内的随机整数。self.action_dim 是动作空间的维度,表示智能体可以选择的动作数量。这段代码的作用是从所有可能的动作中随机选择一个动作。
else:
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.q_net(state).argmax().item()
return action
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
q_values = self.q_net(states).gather(1, actions) # Q值
# 下个状态的最大Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones
) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
关于Gym的操作
env = gym.make(env_name)
这行代码的作用是创建一个制定环境的实例:
gym.make(env_name):gym是 OpenAI Gym 的库。make是一个函数,用于根据环境名称env_name创建一个环境实例。env_name是一个字符串,表示要加载的环境的名称。例如:"CartPole-v1":一个经典的平衡杆任务,目标是通过左右移动小车来保持竖直的杆不倒。"MountainCar-v0":一个山地车任务,目标是让小车爬到山顶。"LunarLander-v2":一个登月器任务,目标是安全着陆。
env:- 这是一个环境对象,包含了环境的所有状态和行为接口。通过这个对象,你可以与环境进行交互,例如重置环境、执行动作等。
state = env.reset()
这句代码的作用是将环境重置到初始状态:
env.reset():- 这是一个方法,用于将环境重置为初始状态。
- 它返回环境的初始状态(
state),这个状态是一个数组或数值,具体取决于环境的定义。 - 在强化学习中,每次训练或测试的开始都需要调用
reset()方法,以确保环境从一个一致的初始状态开始。
state:- 这是环境的初始状态,通常是一个数组或数值,表示环境的当前状态。
- 例如,在
CartPole-v1环境中,state可能是一个包含小车位置、小车速度、杆的角度和杆的角速度的数组。
next_state, reward, done, _ = env.step(action)
首先分析env.action(),这个是OpenAI Gym中的核心函数之一,用于在环境中执行一个动作,并且获取环境的反馈。这个函数是智能体和环境交互的主要方式,借着解释它的功能和返回值。
功能
env.step(action) 的作用是:
- 执行动作:根据智能体提供的动作
action,在环境中执行这个动作。 - 获取反馈:返回环境在执行动作后的状态变化、奖励值、任务是否结束的标志,以及一些额外信息。
参数
action:- 这是智能体选择的动作,通常是一个整数或数组,具体取决于环境的定义。
- 在离散动作空间的环境中(如
CartPole-v1),action是一个整数。 - 在连续动作空间的环境中(如
MountainCarContinuous-v0),action是一个数组。
返回值
env.step(action) 返回四个值:
next_state:- 执行动作后环境的下一个状态。
- 这是一个数组或数值,具体取决于环境的定义。
- 例如,在
CartPole-v1中,next_state是一个包含小车位置、小车速度、杆的角度和杆的角速度的数组。
reward:- 执行动作后获得的奖励值。
- 这是一个浮点数,表示智能体在当前步骤的性能。
- 例如,在
CartPole-v1中,每一步的奖励通常是1.0,直到任务结束。
done:- 一个布尔值,表示任务是否结束。
- 如果
done为True,表示任务已经完成(例如,小车到达目标位置、杆倒下等)。 - 如果
done为False,表示任务尚未结束,智能体可以继续执行动作。
info:- 一个字典,包含一些额外的信息。
- 这些信息通常用于调试或提供环境的额外细节。
- 例如,在某些环境中,
info可能包含违反规则的次数、任务完成的原因等。
import gym
# 创建环境
env = gym.make("CartPole-v1")
# 重置环境,获取初始状态
state = env.reset()
# 执行一个动作(例如,0 表示向左推,1 表示向右推)
action = 1
next_state, reward, done, _ = env.step(action)
print("初始状态:", state)
print("下一个状态:", next_state)
print("奖励:", reward)
print("任务是否结束:", done)
关于缓存池的操作(ReplayBuffer)
主要对应的是主函数中这一句代码 b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample(batch_size)
我们来讲讲replay_buffer,其产生源于 replay_buffer = ReplayBuffer(buffer_size)
所以最后还是要归结到ReplayBuffer类,也就涉及到DQN算法的创新点:缓存机制。
有点类似于n-step Sarsa 算法,但又不完全一样:
class ReplayBuffer:
''' 经验回放池 '''
def __init__(self, capacity):
# 一开始是设计了一个队列,这个很简单
self.buffer = collections.deque(maxlen=capacity) # 队列,先进先出
def add(self, state, action, reward, next_state, done): # 将数据加入buffer
# 此add操作就是队列操作,没什么可说的
self.buffer.append((state, action, reward, next_state, done))
# 关键在于采样函数,
def sample(self, batch_size): # 从buffer中采样数据,数量为batch_size
# random.sample()是从列表中随机选择不重复的元素,第一个参数的含义是从self.buffer中采样,并采样batch_size个元素,并且赋值给transitions
transitions = random.sample(self.buffer, batch_size)
# zip(*transitions)就是将transitions中的每个元祖解包
state, action, reward, next_state, done = zip(*transitions)
# 返回的是一个个元祖
return np.array(state), action, reward, np.array(next_state), done
def size(self): # 目前buffer中数据的数量
return len(self.buffer)
zip(*transitions)操作详解
我们首先假设transitions是:
[
(s1, a1, r1, s1_next, done1),
(s2, a2, r2, s2_next, done2),
...
]
之后我们用zip(*transitions)解包后,会得到:
(
(s1, s2, ...), # 所有的 state
(a1, a2, ...), # 所有的 action
(r1, r2, ...), # 所有的 reward
(s1_next, s2_next, ...), # 所有的 next_state
(done1, done2, ...), # 所有的 done
)
也就是把transitions的每一部分都给拆分开,然后赋给不同的变量,形成元祖,作为函数返回值
智能体的更新(详解update())
采样之后,将其包装成transition_dict,之后我们分析agent.update(transition_dict)
def update(self, transition_dict):
# 将传入的字典的参数都给转化成张量
states = torch.tensor(transition_dict['states'],
dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions']).view(-1, 1).to(
self.device)
rewards = torch.tensor(transition_dict['rewards'],
dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'],
dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'],
dtype=torch.float).view(-1, 1).to(self.device)
# 这里的q_net是一开始初始化的神经网络
# self.q_net()会直接返回forward()函数的返回值,由于继承了nn.Model(),因此forward()函数是自动执行的
# q_values = self.q_net(states) 的返回值是 forward 函数的输出,而 forward 函数的自动执行是由PyTorch框架的设计决定的。
q_values = self.q_net(states).gather(1, actions) # Q值
#下个状态的最大Q值
max_next_q_values = self.target_q_net(next_states).max(1)[0].view(
-1, 1)
q_targets = rewards + self.gamma * max_next_q_values * (1 - dones
) # TD误差目标
dqn_loss = torch.mean(F.mse_loss(q_values, q_targets)) # 均方误差损失函数
self.optimizer.zero_grad() # PyTorch中默认梯度会累积,这里需要显式将梯度置为0
dqn_loss.backward() # 反向传播更新参数
self.optimizer.step()
if self.count % self.target_update == 0:
self.target_q_net.load_state_dict(
self.q_net.state_dict()) # 更新目标网络
self.count += 1
self.q_net(states).gather(1, actions)操作
首先我们知道,网络中除了init函数,forward函数本身就是有返回值的,并且forward操作是自动执行的,因此直接可以用变量去接
终点在于后续的.gather()操作
如何理解神经网络的传参操作?我们单看网络结构的定义,forward()函数就只有一个形参位置
class Qnet(torch.nn.Module):
''' 只有一层隐藏层的Q网络 '''
def __init__(self, state_dim, hidden_dim, action_dim):
super(Qnet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x)) # 隐藏层使用ReLU激活函数
return self.fc2(x)
所以返回的是"self.fc2(states)",也就是说返回参数的维度和传入的参数没关系。和输出层的维度和输出层前一层的维度相关:例如输出层的维度是64,输出层前一层的维度是32,那么输出的维度就是(32,64)
self.q_net(states)
- 功能:
输入状态states(通常是一个批量的状态,形状为[batch_size, state_dim]),通过 Q 网络 (q_net) 计算每个状态下所有可能动作的 Q 值。 - 输出:
一个形状为[batch_size, num_actions]的张量,表示每个状态下所有动作的 Q 值。
示例(假设batch_size=3,num_actions=4):
q_values = self.q_net(states) # 输出示例:
tensor([[0.1, 0.4, -0.2, 0.5], # 状态1的4个动作的Q值
[0.3, 0.6, 0.0, 0.8], # 状态2的Q值
[-0.1, 0.2, 0.7, 0.3]]) # 状态3的Q值
并且我们要注意:输入self.q_net(state)得到的是整体的输出表,我们根据传入的字典更新的内容必须是跟动作相关的,因此我们得到整体的输出表是无用的,故需要一个筛选的操作,也就是gather(1, actions)完成的内容:
actions 的含义与形状
actions:实际执行的动作索引(整数),形状为 [batch_size, 1]。
示例:
actions = tensor([[1], # 状态1执行动作1
[2]]) # 状态2执行动作2
那gather()函数和action参数组合,其实就是筛选出action表示的Q值
.gather(1, actions) 的作用
- 功能:沿维度
1(动作维度)从q_values中按actions的索引提取对应的Q值。 - 输出形状:
[batch_size, 1],即每个状态下实际执行动作的Q值。
接上例:
selected_q = q_values.gather(1, actions) # 输出:
tensor([[0.4], # 状态1的动作1的Q值
[0.0]]) # 状态2的动作2的Q值
为什么需要这个操作?
(1) 计算TD误差(关键用途)
在更新Q值时,需要计算实际执行动作的预测Q值与目标Q值的差异(TD误差):
# 预测Q值(实际执行动作的Q值)
predicted_q = q_values.gather(1, actions) # 形状: [batch_size, 1]
# 目标Q值(如Q-learning的最大Q值)
target_q = rewards + gamma * next_q_values.max(1)[0] # 形状: [batch_size]
# 计算损失(MSE)
loss = (predicted_q - target_q).pow(2).mean()
(2) 避免冗余计算
- 如果直接使用
q_values(所有动作的Q值),会引入无关动作的噪声,而gather精确提取相关值。
类比协助理解
想象你在玩一个游戏:
q_values:游戏界面显示每个按钮(动作)的预期得分(Q值)。actions:你实际按下的按钮编号。gather:从界面显示的得分中,只记录你按下按钮对应的分数,用于计算你的表现。
self.target_q_net(next_states).max(1)[0].view(-1, 1)
我们分步骤解释,其实也是为了获取最大Q值的操作:
self.target_q_net(next_states)
还是输入状态,我们会得到一个Q值表。
.max(1)[0]
沿维度1(动作维度)取最大值,返回两个值:分别是最大值和最大索引,之后通过[0]取出的是最大值部分,形状是[batch_size]。
.view(-1, 1)
将结果从 [batch_size] 调整为 [batch_size, 1],以便后续与奖励等张量运算。
self.optimizer.step()
作用:执行优化器的一步更新操作,用于根据当前的梯度信息更新模型的参数。
详细步骤:
-
计算梯度:
- 在执行
self.optimizer.step()之前,通常会先计算模型的损失函数,并通过反向传播(loss.backward())计算梯度。 - 梯度会被存储在模型参数的
.grad属性中。
- 在执行
-
更新参数:
-
调用
self.optimizer.step()时,优化器会根据当前的梯度信息和优化算法的规则来更新模型的参数。 -
例如,对于 SGD 优化器,更新规则通常是:
θnew=θold−η⋅∇L
其中,θ 是模型参数,η 是学习率,∇L 是损失函数的梯度。
-
-
清空梯度:
- 在更新参数后,通常需要清空梯度,以便下一次迭代可以重新计算梯度。
- 这可以通过调用
self.optimizer.zero_grad()来完成。
神经网络复习
假设我们有500条数据,20个特征,标签为3分类,第一层有13个神经元,第二层有8个神经元,第三层是输出层;其中第一层的激活函数是relu,第二层的激活函数是sigmoid。那么我们该如何设计数据和网络架构呢?
首先第一点,数据和特征的关系:
数据是行(一行行数据),特征是列。
import torch
import torch.nn as nn
from torch.nn import functional as F
from torch import optim # 梯度下降优化算法库
torch.manual_seed(420)
X = torch.rand((500,20),dtype=torch.float32) # 设计输入数据,500行是500个输入数据,20列表示有20个特征
y = torch.randint(low=0,high=3,size=(500,1),dtype=torch.float32)
# 随后我们定义网络架构
# torch.nn中有nn.Module和nn.functional
# 前者中是一些网络层和结构,后者是需要调用的各种函数,那么实际上我们可以从nn.Module中继承神经网络架构
class Model(nn.Module):
# 实例化的时候,init函数会被瞬间调用,至于forward函数,是在实例化之后被调用的
def __init__(self,in_features = 10,out_features = 2):
# 为了帮助我们继承更多父类的细节,我们需要super()
# 注意这里继承的是Model的父类,虽然参数中填写的是Model。那实际上查找或者说继承的是nn.Module
# 第二个参数表示的是希望通过继承的类替换什么内容,这里是self。那替换的是什么内容呢?是.后面的内容,就是替换的init函数,也就是将nn.Module中的init()函数复制过来作为我Model初始化的第一行
# 如果没有super(),那么子类将不会有父类中init函数的方法和属性
super(Model,self).__init__()
# 随后开始实例化内容的编写,在init函数中,我们一般要实例化的是层的内容
self.linear1 = nn.Linear(in_features,13,bias=True) #输入层不用
self.linear2 = nn.Linear(13,8,bias=True)
self.output = nn.Linear(8,out_features,bias=True)
# 最后的输出结构,就是样本数量*输出层神经元个数
def forward(self,x):
z1 = self.linear1(x)
sigma1 = torch.relu(z1)
z2 = self.linear2(sigma1)
sigma2 = torch.sigmoid(z2)
z3 = self.output(sigma2)
#sigma3 = F.softmax(z3,dim=1)
return z3
# 定义了网络架构,之后仅需要定义损失函数并且将预测值输入进去,即可进行反向传播
criterion = nn.CrossEntropyLoss()
# 前向传播得到预测值
zhat = net.forward(X)
# 得到损失
loss = criterion(zhat,y.reshape(500).long())
# 反向传播,反向传播后其实也没有更新权重
loss.backward()
# 但是为了让梯度下降的更合理,也为了不陷入局部最优,所以我们需要一些技巧进行梯度下降,比方说动量法
# 首先需要定义优化算法
opt = optim.SGD(net.parameters()
, lr=lr #学习率
, momentum = gamma #动量参数
)
# 接下来开始进行一轮完整的梯度下降:
zhat = net.forward(X)
loss = criterion(zhat,y.reshape(500).long()) #损失函数值
loss.backward() #反向传播
opt.step() #更新权重w,从这一瞬间开始,坐标点就发生了变化,所有的梯度必须重新计算
opt.zero_grad() #清除原来储存好的,基于上一个坐标点计算的梯度,为下一次计算梯度腾出空间
# 实际上也不只经过一轮训练,我们可能要经过好几轮的训练,所以需要迭代,迭代需要batch_size与epoches
# 首先是小批量训练,batch_size。然后是epoch,表示迭代次数
# 如果要进行小批量梯度下降,那么就需要对数据进行采样、分割等操作。
# 合并张量和标签,我们就要使用TensorDataset,也就是将维度一致的tensor进行打包。
# 打包成一个对象之后,就需要使用划分小批量的功能DataLoader
# DataLoader可以接受任意形式的数组、张量作为输入,并将其一次性转换为神经网络可以接受的tensor
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
import numpy as np
torch.manual_seed(420)
X = torch.rand((50000,20),dtype=torch.float32) * 100 #要进行迭代了,增加样本数量
y = torch.randint(low=0,high=3,size=(50000,1),dtype=torch.float32)
epochs = 4
bs = 4000
data = TensorDataset(X,y) # 先合并并打包
batchdata = DataLoader(data, batch_size=bs, shuffle = True) # 然后将其转化成神经网络能接受的tensor
# 接着我们看看一般的训练函数是如何定义的
def fit(net,batchdata,lr=0.01,epochs=5,gamma=0):
criterion = nn.NLLLoss() #定义损失函数
opt = optim.SGD(net.parameters(), lr=lr,momentum=gamma) #定义优化算法
correct = 0
samples = 0
for epoch in range(epochs):
for batch_idx, (x,y) in enumerate(batchdata):
y = y.view(x.shape[0])
sigma = net.forward(x) # 我们一般将前向传播->计算损失->反向传播->更新梯度->梯度清零的操作放到循环或者放到训练函数中去做
loss = criterion(sigma,y)
loss.backward()
opt.step()
opt.zero_grad()
#求解准确率
yhat = torch.max(sigma,1)[1]
correct += torch.sum(yhat == y)
samples += x.shape[0]
if (batch_idx+1) % 125 == 0 or batch_idx == len(batchdata)-1:
print('Epoch{}:[{}/{}({:.0f}%)]\tLoss:{:.6f}\t Accuracy:
{:.3f}'.format(
epoch+1
,samples
,len(batchdata.dataset)*epochs
,100*samples/(len(batchdata.dataset)*epochs)
,loss.data.item()
,float(correct*100)/samples))
获取输入空间和输出空间的维度
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
state_dim:状态的特征维度,决定神经网络输入大小。action_dim:可选动作的数量,决定神经网络输出大小。- 关键作用:为构建DQN网络提供参数,确保智能体与环境的交互维度匹配。
实例:
import torch.nn as nn
class QNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super().__init__()
self.fc1 = nn.Linear(state_dim, 64) # 输入层维度=state_dim
self.fc2 = nn.Linear(64, action_dim) # 输出层维度=action_dim
# 初始化网络
q_net = QNetwork(state_dim, action_dim)