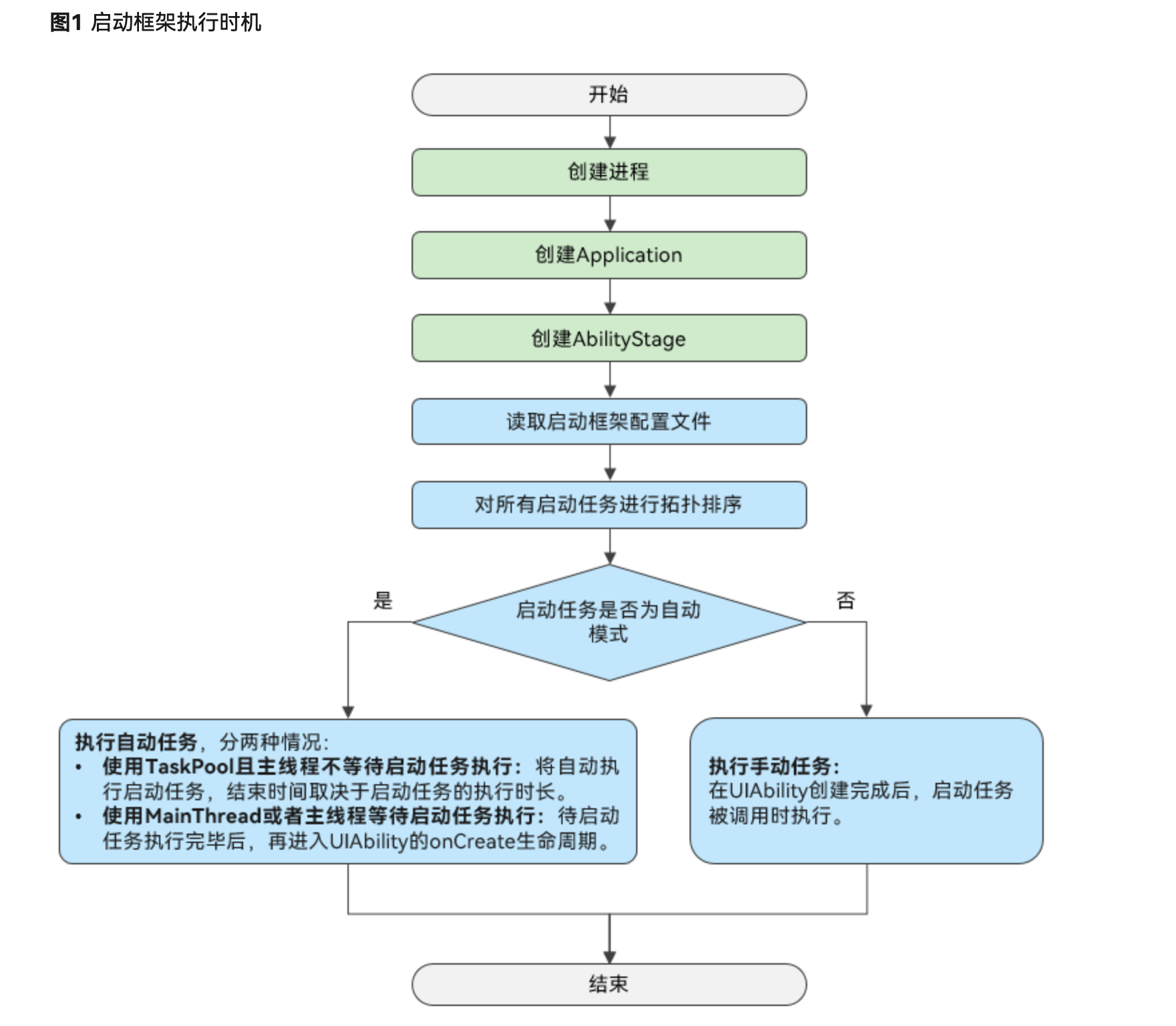
- 论文地址: The Change You Want To Detect: Semantic Change Detection In Earth Observation With Hybrid Data Generation
Abstract
摘要内容介绍
📌 问题背景
“Bi-temporal change detection at scale based on Very High Resolution (VHR) images is crucial for Earth monitoring.”
- 双时相变化检测是指:通过对比两个时间点拍摄的卫星或航拍图像,识别地表发生了哪些变化。
- 使用非常高分辨率(VHR)图像进行大规模变化检测对于地球监测(如城市规划、灾害响应、环境监测等)非常重要。
❗️当前研究存在的问题
“This remains poorly addressed so far: methods either require large volumes of annotated data (semantic case), or are limited to restricted datasets (binary set-ups).”
- 当前的方法存在两大问题:
- 语义级变化检测需要大量人工标注的数据,成本很高;
- 二分类变化检测虽然简单,但只能判断“有没有变化”,不能说明“变的是什么”,且只适用于小规模或受限的数据集。
“Most approaches do not exhibit the versatility required for temporal and spatial adaptation: simplicity in architecture design and pretraining on realistic and comprehensive datasets.”
- 现有方法缺乏灵活性,无法很好地适应不同的时间和空间场景;
- 模型设计不够简洁,而且训练所用的数据集往往不够真实或全面。
🔍解决方案:合成数据
“Synthetic datasets are the key solution but still fail to handle complex and diverse scenes.”
- 合成数据集被认为是解决上述问题的关键(因为可以自动生成大量带标签的数据);
- 但目前的合成数据在模拟复杂多样的真实场景方面仍表现不佳。
✅本文贡献:HySCDG 和 FSC-180k 数据集
“In this paper, we present HySCDG a generative pipeline for creating a large hybrid semantic change detection dataset that contains both real VHR images and inpainted ones…”
- 作者提出了一个名为 HySCDG 的生成式数据处理流程,用于创建一个混合型语义变化检测数据集;
- 这个数据集包含:
- 真实的VHR图像
- 经过图像修复(inpainting)处理的图像
- 两个时间点的地物覆盖类型图(land cover maps)
- 变化图(change map)
“Being semantically and spatially guided, HySCDG generates realistic images, leading to a comprehensive and hybrid transfer-proof dataset FSC-180k.”
- HySCDG 是根据语义和空间信息引导生成图像,因此图像更接近真实世界;
- 最终生成了一个高质量、多样化的数据集,命名为 FSC-180k,具有良好的迁移能力(transfer-proof),即可以在不同任务中通用。
🧪实验验证
“We evaluate FSC-180k on five change detection cases (binary and semantic), from zero-shot to mixed and sequential training, and also under low data regime training.”
- 作者在五种变化检测任务上对 FSC-180k 进行了评估:
- 包括二分类和语义级变化检测
- 包括从零样本学习(zero-shot) 到 混合训练、序列训练
- 也包括低数据量训练(low data regime)
“Experiments demonstrate that pretraining on our hybrid dataset leads to a significant performance boost, outperforming SyntheWorld, a fully synthetic dataset, in every configuration.”
- 实验结果表明:使用 FSC-180k 预训练模型能显著提升性能;
- 在所有实验配置中,FSC-180k 均优于完全合成的数据集 SyntheWorld。
🧠 总结一句话:
这篇论文提出了一种结合真实与生成图像的新颖数据集构建方法 HySCDG,并生成了一个大规模、高质量、适用于多种变化检测任务的混合数据集 FSC-180k,实验证明其性能优于现有合成数据集。
名词解释
VHR:非常高分辨率图像
语义级检测:要明确描述发生了怎么样的变化
二分类检测:只需要判断出有变化
Introduction部分
📘 引言部分主要内容总结
1. ✅ 变化检测(Change Detection, CD)的重要性
“Efficient methods for change detection (CD) are crucial for monitoring territories and the various phenomena and activities that impact them.”
- 变化检测是遥感领域的一个核心任务,用于监测地表的变化,比如城市扩张、自然灾害、气候变化、农业活动等。
- 随着人类活动加剧和气候变化的影响增大,对变化检测的要求也越来越高:
- 更高的空间分辨率(Very High Resolution, VHR)
- 更强的语义识别能力(Semantic Change Detection, SCD)
2. 🔍 当前挑战:数据标注成本高
“Creating a large-scale dataset for bi-temporal remote sensing change detection poses significant challenges and costs…”
- 构建大规模双时相变化检测数据集非常困难且昂贵,尤其对于VHR图像(地面采样距离 < 1米)来说更是如此。
- 原因包括:
- 收集、预处理和标注图像需要大量专业人力;
- 特别是在多类别标注(即语义变化检测)的情况下,工作量巨大;
- 目前缺乏一个全面、多样、高质量的大规模训练数据集(见图1)。
3. 🔄 合成数据的潜力与局限性
“As an alternative, synthetic data generation is a promising direction…”
- 合成数据生成技术被视为解决数据不足问题的一种有前途的方法。
- 目前主要有两种方法:
- 全合成数据集(Fully Synthetic Datasets):
- 使用计算机图形引擎渲染出两个时间点的虚拟场景;
- 虽然灵活,但真实感不足,难以迁移到真实世界。
- 混合方法(Hybrid Solutions):
- 在真实图像上进行对象级别的修改(如添加/删除物体、图像修复inpainting);
- 这种方法在生成效率和真实感之间取得了较好的平衡。
- 全合成数据集(Fully Synthetic Datasets):
“However, none of these solutions meet the requirements for scalable SCD with VHR imagery…”
- 然而,现有方法存在以下问题:
- 多数只针对单一任务或特定区域;
- 缺乏多样性;
- 没有保证双时相图像之间的语义一致性;
- 因此,在真实数据上的迁移效果不佳。
4. 💡 本文提出的解决方案:HySCDG 和 FSC-180k 数据集
“To address this challenge, we introduce a generative pipeline built upon Stable Diffusion and ControlNet…”
- 为了解决上述问题,作者提出了一个新的生成式管道 HySCDG,基于:
- Stable Diffusion(强大的扩散模型)
- ControlNet(控制图像生成过程)
- 利用现有的VHR土地覆盖语义数据集 FLAIR 和实例掩码(instance masks),生成一个包含以下内容的大型混合语义双时相变化检测数据集:
📦 数据集内容:
- 真实和修复后的VHR图像
- 两个时间点的土地覆盖语义地图(land cover maps)
- 变化图(change map)
(参考图1,说明该数据集支持多种变化检测任务的迁移学习)
5. 🧪 实验验证:广泛的任务适应性
“We evaluate the transferability of our synthetic dataset on five datasets for both binary and semantic change detection cases…”
-
作者在五个不同的变化检测数据集上进行了评估,涵盖:
- 二分类变化检测
- 语义级变化检测
- 零样本学习(zero-shot)
- 序列训练(sequential training)
- 混合训练(mixed training)
- 低数据量训练(low-data regime)
-
实验结果表明:使用该合成数据集进行预训练,能够显著提升模型性能,并优于完全合成的数据集(如SyntheWorld)。
6. 🧩 主要贡献总结
作者明确列出了本研究的三大主要贡献:
✅ 贡献一:HySCDG 生成管道
- 提出了一种基于Stable Diffusion和ControlNet的新生成流程;
- 可以根据任意土地覆盖数据集生成具有语义一致性的双时相图像;
- 支持对单个对象进行可调节的、语义引导的图像修复(inpainting);
- 生成的图像保留了原始数据集的风格和特征。
✅ 贡献二:FSC-180k 数据集
- 发布了一个名为 FSC-180k 的新数据集;
- 基于 FLAIR 数据集构建;
- 包含约 30 万个对象的实例掩码;
- 是目前最大规模、最全面的混合型语义变化检测预训练数据集。
✅ 贡献三:多任务迁移学习评估
- 对提出的合成数据集进行了系统性的迁移学习评估;
- 覆盖了多种实际应用场景;
- 证明其在不同任务和训练策略下的通用性和有效性。
Relate Work
这篇论文的 Related Work(相关工作) 部分主要从三个方向回顾了变化检测领域的研究进展:
📚 一、深度学习时代的变化检测(Detecting changes in the deep learning era)
✅ 主要内容:
- 研究的是双时相土地覆盖变化检测,目标是识别两个时间点之间地表发生的变化,并给出每个时间段的土地覆盖类别。
- 这是一个历史悠久的任务,近年来随着深度学习的发展取得了显著进步,尤其是使用 CNN 和 Transformer 架构的模型。
- 大多数方法采用**孪生网络结构(Siamese architecture)来处理双时相图像。
🔍 存在的问题:
- 数据集规模小、地理范围有限;
- 图像几何或标注质量低;
- 多数集中在二分类变化检测任务,特别是建筑物或灾害类别的变化;
- 缺乏高质量、多样化的大规模语义级变化标签数据。
🔄 解决方案:
- 使用**迁移学习(transfer learning)缓解数据不足问题;
- 在大规模非遥感数据上预训练模型,再迁移到变化检测任务中。
🎨 二、遥感图像的合成与修复(Synthesizing and inpainting remote sensing images)
✅ 相关技术:
- 合成遥感图像可用于云去除、图像修复、训练监督模型等;
- 已有方法包括:基于补丁的方法、自编码器、GAN、像素对齐生成等;
- 扩散模型(Diffusion Models, DM) 提高了图像生成质量;
- 但大多数方法仅用于中分辨率RGB图像,忽略了多光谱和VHR特性。
🎯 关键发现:
- 通过控制模块(如边缘图、语义图、元数据)实现语义引导的图像生成;
- 本文提出使用 Stable Diffusion + ControlNet 实现语义控制的 VHR 图像修复;
- 从而利用现有图像生成大规模、多样化的混合语义变化检测数据集。
🧬 三、合成变化数据集的生成(Generating synthetic change datasets)
✅ 两种主流方法:
1. 全合成数据集(Fully Synthetic Datasets)
- 使用3D渲染引擎生成虚拟场景;
- 可控性强(实例位置、光照、类别等);
- 例如:SyntheWorld [53] 使用 GPT-4 提示的扩散模型生成多样化数据。
2. 混合方法(Hybrid Approaches)
- 在真实图像上插入“假变化”;
- 方法包括:随机裁剪、对象复制粘贴、GAN/DM 图像修复;
- 使用风格迁移增强多样性;
- 例如:Changen2 [69] 利用语义图控制扩散模型生成双时相图像。
🆕 本文贡献对比:
- HySCDG 也是基于语义图控制的扩散模型;
- 但相比 Changen2 更加通用,可以适配不同分辨率、尺寸和变化特性的数据集;
- 生成的数据集 FSC-180k 是目前最大规模、最多类别(16类)、最高分辨率(GSD=0.2m)的混合语义变化检测数据集。
📊 表格 1:合成变化数据集比较
| Dataset | OA (开放获取) | 像素数(百万) | 分辨率(m) | 类别数 | 来源 | 地理区域 | 类型 |
|---|---|---|---|---|---|---|---|
| SynCW [27] | ❌ | 37 | 0.6 | 1 | X | 局部 | 合成 |
| SMARS [17] | ✔️ | 110 | 0.3–0.5 | 2 | X | 局部 | 合成 |
| IAug [5] | ❌ | 1,167 | 0.075–0.5 | 1 | LEVIR-CD/WHU-CD | 局部 | 混合 |
| Ce-100K [54] | ❌ | 6,553 | 0.25–0.5 | 8 | OEM | 全球 | 合成 |
| Changen2 [69] | ❌ | 7,077 | 0.25–0.5 | 8 | OEM | 全球 | 混合 |
| Changen [71] | ❌ | 11,796 | 0.8 | 1 | xView2 | 局部 | 混合 |
| SyntheWorld [53] | ✔️ | 18,350 | 0.3–1 | 1 | X | 全球 | 合成 |
| FSC-180k (Ours) | ✔️ | 80,740 | 0.2 | 16 | FLAIR | 国家级 | 混合 |
✅ FSC-180k 是当前最大的混合语义变化检测数据集,具有更高的分辨率、更多类别和更大的像素总量。
🔄 四、从合成/混合数据集进行迁移学习(Transfer learning from synthetic/hybrid datasets)
✅ 迁移学习策略:
- 顺序学习(Sequential learning):先在合成数据上预训练,再在真实数据上微调;
- 混合训练(Mixed training):将真实和合成样本混合训练;
- 低数据量训练(Low data regime):在极小的真实数据集上微调;
- 零样本学习(Zero-shot):不使用真实数据直接测试。
📌 本文评估:
- 在上述四种迁移设置下全面评估 FSC-180k 的有效性;
- 证明其在多种任务和训练策略下的泛化能力。
Hybrid generation of semantic changes
文章最主要的构建部分包括:
- 针对缺乏可用于训练双时相语义变化检测模型的大规模数据集 ,作者提出了HySCDG(Hybrid Semantic Change Detection Generation) ,这是一种新的数据生成方法;
- 利用HySCDG,生成了数据集FSC-180k,并使用这个数据集进行了多组迁移学习的测试;
最主要的两个基础思想:
- 通过调整和微调一个 Stable Diffusion 模型 ,可以实现对VHR 图像的高效图像修复(inpainting) ,并具备语义控制能力 和地理对象选择能力 。
- 可以在输入图像所对应的 土地覆盖图(land cover map) 中,随机选择一些地物对象(instances) ,并通过修改它们的类别标签来模拟出足够多样的变化场景。
Adaptation of Stable Diffusion for Inpainting.
为什么要微调?
原始的 Stable Diffusion 主要用于生成艺术风格或自然场景图像,但在遥感图像中存在以下问题:
- 遥感图像的视角与地面摄影不同(高空俯视、多光谱)
- 地物结构复杂、纹理丰富、无明显主体
- 图像分辨率高(VHR),细节要求高
因此,为了使 Stable Diffusion 能够更好地处理遥感图像的修复任务,作者对其进行了系统性地微调。
整个微调流程分为三个主要阶段:
| 步骤 | 内容 |
|---|---|
| ✅ 第一步 | 微调 Variational Autoencoder (VAE),使其能高效编码遥感图像到扩散模型的潜在空间 |
| ✅ 第二步 | 微调 Diffusion U-Net,适配新的 VAE,并训练其进行 VHR 图像修复 |
| ✅ 第三步 | 添加并训练 ControlNet,利用土地覆盖地图进行语义引导 |
🧱 三、详细步骤解析
1️⃣ 微调 Variational Autoencoder (VAE)
📌 目标:
- 提高对 多波段 VHR 遥感图像(5波段:RGB + 红外 + 高程) 的压缩与重建能力;
- 减少模糊、过饱和等失真现象。
🔧 改进方法:
- 在原始 VAE 的损失函数中引入了多种新损失项:
- L2 Loss:减少高频误差,避免图像模糊;
- Focal Loss [31]:增强对罕见地物类别的关注;
- Color Loss(在 5×5 patch 上计算 L2):防止颜色过度饱和,提升地物色彩真实性;
- 使用 FLAIR 数据集中的 VHR 图像进行训练。
⏱️ 训练资源:
- 使用 A100 GPU,耗时 160 小时
2️⃣ 微调 Diffusion U-Net
📌 目标:
- 使 U-Net 适应新的 VAE 编码器;
- 学会根据提示(prompt)和掩码(mask)完成高质量的 VHR 图像修复。
🛠️ 方法:
- 基于
stable-diffusion-2-inpainting模型继续微调; - 在 10%~20% 的样本中也保留“纯文本生成”的任务,以保持模型原有的文本理解能力;
- 使用 FLAIR 数据集进行训练。
⏱️ 训练资源:
- 使用 A100 GPU,训练 30,000 步
- Batch size = 32
- 总耗时约 300 小时
3️⃣ 添加 ControlNet 进行语义控制
📌 目标:
- 引入外部语义信息(如土地覆盖图、OpenStreetMap)来控制图像修复的内容和位置;
- 实现对特定地理对象(如建筑、道路)的修改。
🛠️ 方法:
- 使用 FLAIR 数据集提供的语义地图;
- 结合 OpenStreetMap 和地理坐标信息生成提示词;
- ControlNet 接收这些信息作为额外输入,指导扩散模型生成符合语义逻辑的修复区域。
📝 四、Prompt Engineering(提示工程)
为了更有效地控制图像生成,作者设计了一种结构化的 prompt 格式,结合了以下三种信息:
| 类型 | 内容示例 |
|---|---|
| 空间信息 | 地名、城市、区域(如 Savigny-en-Revermont, Bourgogne-Franche-Comté) |
| 时间信息 | 时间段、季节(如 “morning”, “summer”) |
| 语义信息 | 当前修复区域的主要类别(如 “grass and agricultural vegetation”) |
📌 示例完整 prompt:
"Grass and agricultural vegetation next to a highway, locality of Savigny-en-Revermont, Bourgogne-Franche-Comté, in the morning, during Summer."
夏季早晨,勃艮第-弗朗什-孔泰Savigny-en-Revermont地区高速公路旁的草地和农业植被
Conditional change inpainting with ControlNet
使用 ControlNet 模块,结合语义分割图(土地覆盖图)和文本提示,控制扩散模型在指定区域内生成特定类别的图像内容。
🔍 技术要点:
- ControlNet 是一种插件式模块,可以附加在预训练的扩散模型上;
- 它允许在图像生成过程中引入额外的语义信息(如边缘图、语义地图等);
- 在本工作中,ControlNet 被用来接收 语义地图(land cover map) 和 文本 prompt,从而精确控制图像修复的内容;
- 不仅支持图像修复任务,也保留了原始 SD 的文本到图像生成能力。
Select, Mask, Change, Inpaint : the HySCDG pipeline
“Select and Inpaint”机制
Inspired by [46], the core of our method lies in our “Select and Inpaint” mechanism.
✅ 核心思想:
- 受文献 [46] 启发,作者提出了一种基于图像修复的双时相语义变化模拟方法;
- 基本流程为:选择对象 → 创建掩码 → 修改类别 → 使用 SD+ControlNet 进行图像修复;
- 最终生成一对图像
(
I
1
,
I
2
)
(I_1, I_2)
(I1,I2),及其对应的语义地图
(
M
1
,
M
2
)
(M_1, M_2)
(M1,M2) 和变化图
C
C
C。
以下是对整个 HySCDG 流程的逐步说明:
1️⃣ 输入
- 一张 VHR 图像 I 1 I_1 I1;
- 对应的语义分割图 M 1 M_1 M1;
- 实例集合 O i {O_i} Oi(即图像中所有可识别的地物对象,如建筑、道路等)。
2️⃣ 步骤详解
(1)随机选择 Nchange 个实例进行修改
- 从所有实例中随机选取一部分用于模拟地表变化;
- 模拟的是真实世界中可能发生的土地覆盖变化(如草地变建筑)。
(2)创建 inpainting mask(修复区域)
- 每个选中的实例都会被赋予一个“修复掩码”,包括:
- 原始占地范围(footprint)
- 周围的缓冲区(spatial buffer),以提升边界自然度
(3)获取 T1 类别(原类别)
- 在该实例的原始语义图中,找到最常见的类别 c1;
- 提取该类别的凸包区域作为变化区域(change mask)
(4)随机选择新类别 c2(目标类别)
- 从所有类别中随机选择一个新的类别,替换原来的类别;
- 选择方式考虑了全局类别频率与局部区域频率的比例,以保证多样性;
- 例如:如果某个区域原本主要是草地(grass),那么更可能变成道路(road)、建筑(building)等常见类别。
(5)添加 Nnochange 个“未变化区域”
- 在图像中再随机选取一些区域进行图像修复;
- 但不改变它们的语义标签;
- 目的是防止模型学习修复痕迹(inpainting signature),而忽略真实的变化模式。
(6)使用 SD+CN 进行图像修复
- 将带掩码的图像和新的语义图输入到微调后的 Stable Diffusion + ControlNet 模型中;
- 输出新的图像 I 2 I_2 I2 和语义图 M 2 M_2 M2。
(7)生成样本对
- 得到双时相图像对 ( I 1 , I 2 ) (I_1, I_2) (I1,I2)
- 语义图对 ( M 1 , M 2 ) (M_1, M_2) (M1,M2)
- 变化图 C = M 2 − M 1 C = M2 - M1 C=M2−M1(表示哪些地方发生了什么类别的变化)
🔧关键技术细节
1️⃣ 缓冲区(Buffer Zone)
- 在每个要修改的实例周围增加一个缓冲区;
- 目的是让扩散模型在生成新纹理时有更多自由空间;
- 同时缓解语义图与实际图像之间的空间误差问题。
2️⃣ 减少修复特征影响(Inpainting Signature Mitigation)
- 在未变化区域也做图像修复,但不更改语义标签;
- 防止模型过度依赖修复过程的“人工痕迹”,从而忽略真实变化信息。
3️⃣ 平滑掩码(Continuous Mask)
- 使用连续掩码代替二值掩码;
- 改善修复区域与原图之间的融合效果,使过渡更加自然。
📦 实例提取来源:FLAIR 数据集
✅ FLAIR 数据集简介:
- 来自法国国家地理研究所(IGN);
- 包含超过 800 km² 的遥感图像;
- 提供 16 种土地覆盖类别的语义分割图;
- 公开可用,且包含大量实例信息;
- 无需全景分割(panoptic segmentation),只需足够多的实例即可保证多样性。
📌 提取成果:
- 总共提取了约 300,000 个实例掩码
📊 FSC-180k 数据集结构
✅ 基本信息:
| 属性 | 内容 |
|---|---|
| 名称 | FSC-180k(FLAIR Synthetic Change) |
| 来源 | FLAIR 数据集 |
| 图像数量 | 180,000 张 |
| 分辨率 | 512×512 像素 |
| 波段数 | 5(RGB + 红外 + 高程) |
| 地面分辨率 | 0.2 米/像素 |
| 语义类别数 | 16 类 |
| 总像素数 | 约 800 亿像素 |
📈 扩展性:
- 可通过将同一张真实图像生成的不同版本组合成多个图像对;
- 这样可使图像对数量翻倍。
📈 与其他合成数据集对比(Table 1)
| 数据集 | 像素数(百万) | GSD(m) | 类别数 | 开放获取 | 类型 |
|---|---|---|---|---|---|
| SyntheWorld [53] | 18,350 | 0.3–1 | 1 | ✔️ | 合成 |
| Changen2 [69] | 7,077 | 0.25–0.5 | 8 | ❌ | 混合 |
| FSC-180k(本文) | 80,740 | 0.2 | 16 | ✔️ | 混合 |
✅ 优势总结:
- 是目前最大规模的合成变化检测数据集;
- 支持最多语义类别(16类);
- 最高空间分辨率(0.2m);
- 更接近现实场景下的变化比例(约5%);
- 支持多种类型的变化(不只是建筑物);
📊 FSC-180k 质量评估
1️⃣ 语义一致性验证:
- 使用 UNet 模型对生成图像进行语义分割;
- 与原始语义图比较,错误率低于 20%;
- 表明语义一致性较好。
2️⃣ 图像真实性评估:
- 使用标准图像生成评价指标:
- Inception Score (IS):6.2(越高越好,接近真实图像)
- FID Score:0.43(越低越好,表示生成图像与真实图像非常接近)
HySCDG 利用 Stable Diffusion 和 ControlNet,在 FLAIR 语义数据集基础上,通过“选+修”机制自动生成具有语义一致性和视觉逼真性的双时相遥感图像对,构建出目前最大规模、最多类别、最高分辨率的混合语义变化检测数据集 FSC-180k,并经过系统评估验证了其高质量和实用性。