一、引言
(一) AI Agent 技术发展背景 🚀
AI Agent 的演进是一场从“遵循指令”到“自主决策”的深刻变革。早期,以规则引擎为核心的系统(如关键词匹配的客服机器人)只能在预设的流程上运行。然而,大语言模型的崛起为 Agent 注入了“灵魂”,使其具备了前所未有的自主规划与执行能力。像 AutoGPT 和 BabyAGI 这样的项目,已经能根据用户设定的宏大目标,自主地分解任务、调用工具、并完成一系列复杂操作,这标志着认知型 Agent 时代的到来。
在现代 Agent 设计中,任务型 Agent 和 认知型 Agent 的界限愈发清晰。前者专注于高效执行封闭领域的具体流程(如处理退款申请),而后者则致力于解决开放域的复杂问题(如“分析市场趋势并撰写报告”)。架构设计是决定 Agent 智能上限的关键。ReAct 和 Self-Ask 正是当前 LLM-based Agent 架构中,分别代表“行动派”和“思考派”的两种主流范式。
(二) ReAct 与 Self-Ask 模式的技术定位
ReAct (Reasoning and Acting) 和 Self-Ask 都是驱动 LLM 进行复杂决策的核心架构,但它们的实现路径截然不同。
- ReAct:以任务执行为中心。它将 LLM 封装在一个“思考 → 行动 → 观察 → 思考…”的循环中。LLM 不直接回答最终问题,而是生成一个“想法”(Thought)和一个需要执行的“动作”(Action),通过与外部工具(如搜索引擎、API)交互来获取信息,然后根据“观察”(Observation)到的结果进行下一步推理。这种模式侧重于实时交互和动态适应。
- Self-Ask:以问题分解为核心。它通过递归地向自己提问来将一个复杂问题拆解成一系列更简单的子问题。每个子问题都通过外部工具(主要是搜索引擎)来回答,然后将这些中间答案逐步聚合,最终形成对原始问题的完整解答。这种模式侧重于深度推理和知识溯源。
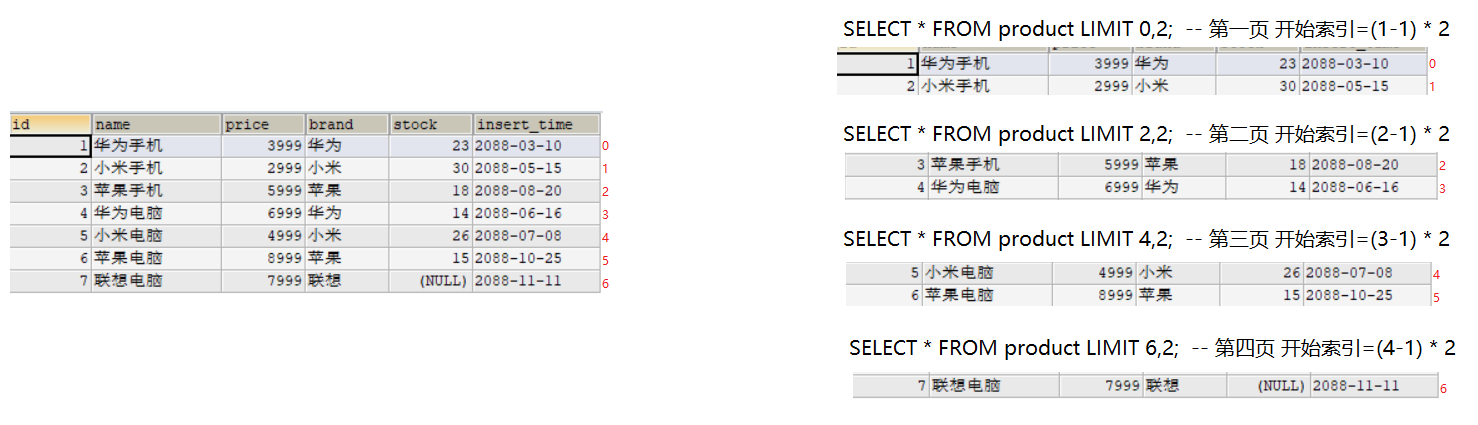
| 特性 | ReAct | Self-Ask |
|---|---|---|
| 核心逻辑 | 推理-动作循环 | 递归问题分解 |
| 适用场景 | 需要与环境/工具持续交互的流程化任务 (如智能客服、个人助理) | 需要深度知识推理和证据链的复杂问答 (如研究分析、报告生成) |
| 交互模式 | 多轮、动态 | 通常为单轮、离线分析 |
| 产出特点 | 过程透明,展示行动轨迹 | 逻辑清晰,展示推理链条 |
二、ReAct 模式技术解析 ⚙️
(一) 核心技术原理
ReAct 的精髓在于将推理和行动解耦并显式化。它强迫 LLM 不仅要思考“做什么”,还要思考“为什么这么做”,并将此过程以文本形式表达出来。这极大地增强了 Agent 的可控性和可解释性。
其核心循环可以用下图表示:
这个循环的背后是精巧的提示词工程。模型被引导生成特定格式的文本,通常包含:
- Thought: 模型的内心独白,用于分析当前情况、制定下一步计划。
- Action: 决定调用的具体工具及输入参数。
- Observation: 执行 Action 后从外部环境(工具)返回的结果。
- Final Answer: 当模型认为已经收集到足够信息时,给出的最终答案。
(二) 架构组成要素
一个完备的 ReAct Agent 系统通常包含以下几个模块:
- LLM 核心 (LLM Core):负责根据上下文和历史记录生成
Thought和Action。 - 工具集 (Tool Suite):一组可供 Agent 调用的函数或 API,如搜索引擎、计算器、数据库查询接口等。
- 提示模板 (Prompt Template):定义了 Agent 思考和行动的框架,是引导 LLM 按 ReAct 范式工作的关键。
- 解析器 (Output Parser):负责解析 LLM 的输出,从中提取出
Action和Action Input,以便分发给相应的工具。 - 执行器 (Executor):协调整个 ReAct 循环,接收用户输入,调用 LLM,解析输出,执行工具,并将结果反馈给 LLM,直到任务完成。
(三) 工程实践与代码案例
原有的 LangChain 示例非常经典,但为了更深入地理解其工作原理,我们来构建一个不依赖高级抽象、能清晰展示每一步循环的 Python 案例。
场景:一个简单的研究助手,需要回答“LangChain 的作者是谁?他现在的公司是什么?” 这个问题需要两次搜索。
import os
import re
from openai import OpenAI
# 假设已配置 OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
client = OpenAI()
# --- 1. 定义工具 ---
# 这是一个模拟的搜索工具
def search_tool(query: str) -> str:
"""一个模拟的搜索引擎"""
print(f" [Tool] 正在搜索: {query}")
# 针对本案例的模拟数据库
mock_db = {
"who is the author of LangChain": "The main author of LangChain is Harrison Chase.",
"Harrison Chase's current company": "Harrison Chase founded a company called LangChain AI.",
}
return mock_db.get(query, "No information found.")
tools = {
"search": search_tool
}
# --- 2. 定义 ReAct 提示模板 ---
react_prompt_template = """
Answer the following questions as best you can. You have access to the following tools:
search: A search engine. Use this to find information about people, events, or concepts.
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [search]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {question}
Thought:
"""
# --- 3. 构建 ReAct 执行循环 ---
def run_react_agent(question: str):
prompt = react_prompt_template.format(question=question)
max_turns = 5
for i in range(max_turns):
print(f"--- Turn {i+1} ---")
# 调用 LLM
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
stop=["Observation:"] # 让模型在生成 Action 后停止
)
generated_text = response.choices[0].message.content
print(f"[LLM Output]\n{generated_text}")
prompt += generated_text
# 解析 Action
action_match = re.search(r"Action: (.*)\nAction Input: (.*)", generated_text)
if action_match:
action = action_match.group(1).strip()
action_input = action_match.group(2).strip()
# 执行工具
if action in tools:
tool_output = tools[action](action_input)
observation = f"Observation: {tool_output}\n"
print(f"[Observation]\n{observation}")
prompt += observation
else:
prompt += "Observation: Invalid tool name.\n"
else:
# 如果没有 Action,说明可能已经得出最终答案
final_answer_match = re.search(r"Final Answer: (.*)", generated_text, re.DOTALL)
if final_answer_match:
final_answer = final_answer_match.group(1).strip()
print(f"\n✅ Final Answer Found: {final_answer}")
return final_answer
else:
# 无法解析,可能是逻辑卡住了
print("\n❌ Agent stopped: Cannot parse action or find final answer.")
return None
print("\n❌ Agent stopped: Reached max turns.")
return None
# --- 4. 执行任务 ---
question = "Who is the author of LangChain and what is his current company?"
run_react_agent(question)
代码运行输出:
--- Turn 1 ---
[LLM Output]
I need to find out who the author of LangChain is first.
Action: search
Action Input: who is the author of LangChain
[Tool] 正在搜索: who is the author of LangChain
[Observation]
Observation: The main author of LangChain is Harrison Chase.
--- Turn 2 ---
[LLM Output]
Thought: Now that I know the author is Harrison Chase, I need to find his current company.
Action: search
Action Input: Harrison Chase's current company
[Tool] 正在搜索: Harrison Chase's current company
[Observation]
Observation: Harrison Chase founded a company called LangChain AI.
--- Turn 3 ---
[LLM Output]
Thought: I have found the author of LangChain and his current company. I can now provide the final answer.
Final Answer: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
✅ Final Answer Found: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
三、Self-Ask 模式技术解析 🧠
(一) 核心技术原理
Self-Ask 的核心思想是化繁为简。它模拟了人类解决复杂问题时的思维过程:先将大问题分解为一系列可以被直接回答的小问题,然后逐个击破。
其工作流程可以描绘成一个依赖图:
与 ReAct 不同,Self-Ask 的提示中通常包含 Are follow up questions needed here: 这样的关键词,引导模型判断当前信息是否足以回答,如果不足,则生成一个 Follow up: 问题,并通过 Intermediate answer: 记录中间结果。
(二) 架构组成要素
一个标准的 Self-Ask Agent 架构包括:
- **分解器 **:通常是 LLM,负责接收原始问题和历史对话,生成下一个需要被回答的子问题。
- **搜索引擎 **:这是 Self-Ask 的关键外部工具,用于回答分解器生成的具体子问题。
- **合成器 **:也是 LLM,负责整合所有子问题的答案,形成一个连贯、全面的最终答案。在实践中,分解器和合成器可以是同一个 LLM。
(三) 工程实践与代码案例
场景:回答与 ReAct 案例中相同的问题:“LangChain 的作者是谁?他现在的公司是什么?”
import os
from openai import OpenAI
# 假设已配置 OpenAI API Key
client = OpenAI()
# --- 1. 定义工具 (与 ReAct 案例相同) ---
def search_tool(query: str) -> str:
"""一个模拟的搜索引擎"""
print(f" [Tool] 正在搜索: {query}")
mock_db = {
"who is the author of LangChain": "Harrison Chase is the main author of LangChain.",
"Harrison Chase's current company": "Harrison Chase is the founder of LangChain AI.",
}
return mock_db.get(query, "No information found.")
# --- 2. 定义 Self-Ask 提示模板 ---
self_ask_prompt_template = """
Question: Who is the author of LangChain and what is his current company?
Are follow up questions needed here: Yes.
Follow up: Who is the author of LangChain?
Intermediate answer: Harrison Chase is the main author of LangChain.
Are follow up questions needed here: Yes.
Follow up: What is Harrison Chase's current company?
Intermediate answer: Harrison Chase is the founder of LangChain AI.
Are follow up questions needed here: No.
So the final answer is: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
Question: {question}
"""
# --- 3. 构建 Self-Ask 执行类 ---
class SelfAskAgent:
def __init__(self, llm_client, search_tool):
self.client = llm_client
self.search_tool = search_tool
def run(self, question: str, max_iters=5):
prompt = self_ask_prompt_template.format(question=question)
for i in range(max_iters):
print(f"--- Iteration {i+1} ---")
prompt += "\nAre follow up questions needed here:"
# 调用 LLM 判断是否需要子问题或生成最终答案
response = self.client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
stop=["\n"] # 在换行符处停止
)
choice = response.choices[0].message.content.strip()
prompt += choice
print(f"[LLM Decision]: {choice}")
if "Yes" in choice:
# 生成并执行子问题
prompt += "\nFollow up:"
resp_follow_up = self.client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
stop=["\n"]
).choices[0].message.content.strip()
prompt += resp_follow_up
sub_question = resp_follow_up
print(f"[Sub-question]: {sub_question}")
# 执行搜索
answer = self.search_tool(sub_question)
prompt += f"\n {answer}"
print(f"[Intermediate Answer]: {answer}")
elif "No" in choice:
# 生成最终答案
prompt += "\nSo the final answer is:"
resp_final = self.client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
temperature=0,
).choices[0].message.content.strip()
print(f"\n✅ Final Answer: {resp_final}")
return resp_final
else:
print("\n❌ Agent stopped: Unexpected decision.")
return None
print("\n❌ Agent stopped: Reached max iterations.")
return None
# --- 4. 执行任务 ---
agent = SelfAskAgent(client, search_tool)
agent.run("Who is the author of LangChain and what is his current company?")
代码运行输出:
--- Iteration 1 ---
[LLM Decision]: Yes.
[Sub-question]: Who is the author of LangChain?
[Tool] 正在搜索: Who is the author of LangChain?
[Intermediate Answer]: Harrison Chase is the main author of LangChain.
--- Iteration 2 ---
[LLM Decision]: Yes.
[Sub-question]: What is Harrison Chase's current company?
[Tool] 正在搜索: What is Harrison Chase's current company?
[Intermediate Answer]: Harrison Chase is the founder of LangChain AI.
--- Iteration 3 ---
[LLM Decision]: No.
✅ Final Answer: The author of LangChain is Harrison Chase, and his current company is LangChain AI.
四、核心技术对比与选型指南
| 对比维度 | ReAct | Self-Ask |
|---|---|---|
| 决策逻辑 | 任务导向:基于环境反馈进行状态转移,遵循决策过程 。决策粒度为细粒度动作。 | 问题导向:基于问题依赖图进行推理,状态转移由子问题驱动。决策粒度为粗粒度问题分解。 |
| 任务处理能力 | 流程化任务王者。非常适合需要与多个不同工具(API、数据库)交互的场景,如智能客服、自动化运维、个人助理。 | 知识推理专家。在处理需要深度、广度信息检索和整合的开放域问题上表现出色,如学术研究、市场分析。 |
| 上下文管理 | 依赖对话历史和中间Thought来维持上下文,对长序列处理能力要求高。 | 通过Intermediate answer显式记录知识,上下文压力相对较小,但依赖于清晰的问题分解。 |
| 错误处理 | Observation中返回的错误信息可以被Thought捕获,进行重试或改变策略。对工具的健壮性要求高。 | 如果一个子问题无法回答或回答错误,可能会影响整个推理链。可以通过设计更好的回溯机制来弥补。 |
| 性能与成本 | 时间复杂度约为 O ( n ⋅ m ) O(n \cdot m) O(n⋅m),其中 n n n 是交互轮次, m m m 是每次 LLM 推理和工具调用的平均耗时。API 调用频繁。 | 时间复杂度约为 O ( k d ) O(k^d) O(kd),其中 k k k 是每个问题分解出的子问题数, d d d 是推理深度。LLM 调用次数可能较多。 |
| 可解释性 | 行动轨迹透明。用户可以看到 Agent 的每一步思考和尝试,即使失败了也能理解原因。 | 推理链条清晰。用户可以看到原始问题是如何一步步被拆解和回答的,答案的来源有据可查。 |
如何选择:一个实用的决策框架 🤔
在实际项目中,该如何选择?可以从以下四个角度考虑:
-
任务的本质是什么?
- 是“做事”还是“回答”? 如果任务是执行一个多步骤流程(预订机票、管理日历),选择 ReAct。如果任务是回答一个复杂的、需要查证和综合信息的问题,选择 Self-Ask。
-
交互性要求有多高?
- 需要实时反馈吗? 如果 Agent 需要与用户或动态环境进行多轮对话和交互,ReAct 的循环机制更具优势。如果是一次性提交问题,等待最终分析报告,Self-Ask 更合适。
-
工具的多样性如何?
- 需要调用多种工具吗? ReAct 的
Action设计天然支持调用各种不同的工具(计算器、代码解释器、搜索引擎等)。Self-Ask 则强依赖于一个核心工具——搜索引擎。
- 需要调用多种工具吗? ReAct 的
-
对过程还是结果更看重?
- 需要追溯答案来源吗? 如果最终答案的可靠性和证据链至关重要,Self-Ask 提供的
Intermediate answer提供了极佳的可追溯性。如果更关心任务是否被成功执行,ReAct 的行动日志则更为直观。
- 需要追溯答案来源吗? 如果最终答案的可靠性和证据链至关重要,Self-Ask 提供的
混合模式:未来的方向
ReAct 和 Self-Ask 并非完全互斥。先进的 Agent 架构已经开始融合两者的优点。例如,一个 ReAct Agent 在其 Thought 阶段,可能会发现需要回答一个复杂的子问题,此时它可以“启动”一个临时的 Self-Ask 流程来解决这个子问题,然后将结果作为 Observation 返回到 ReAct 的主循环中。这种分层、混合的架构将是未来 AI Agent 实现更高级智能的关键。