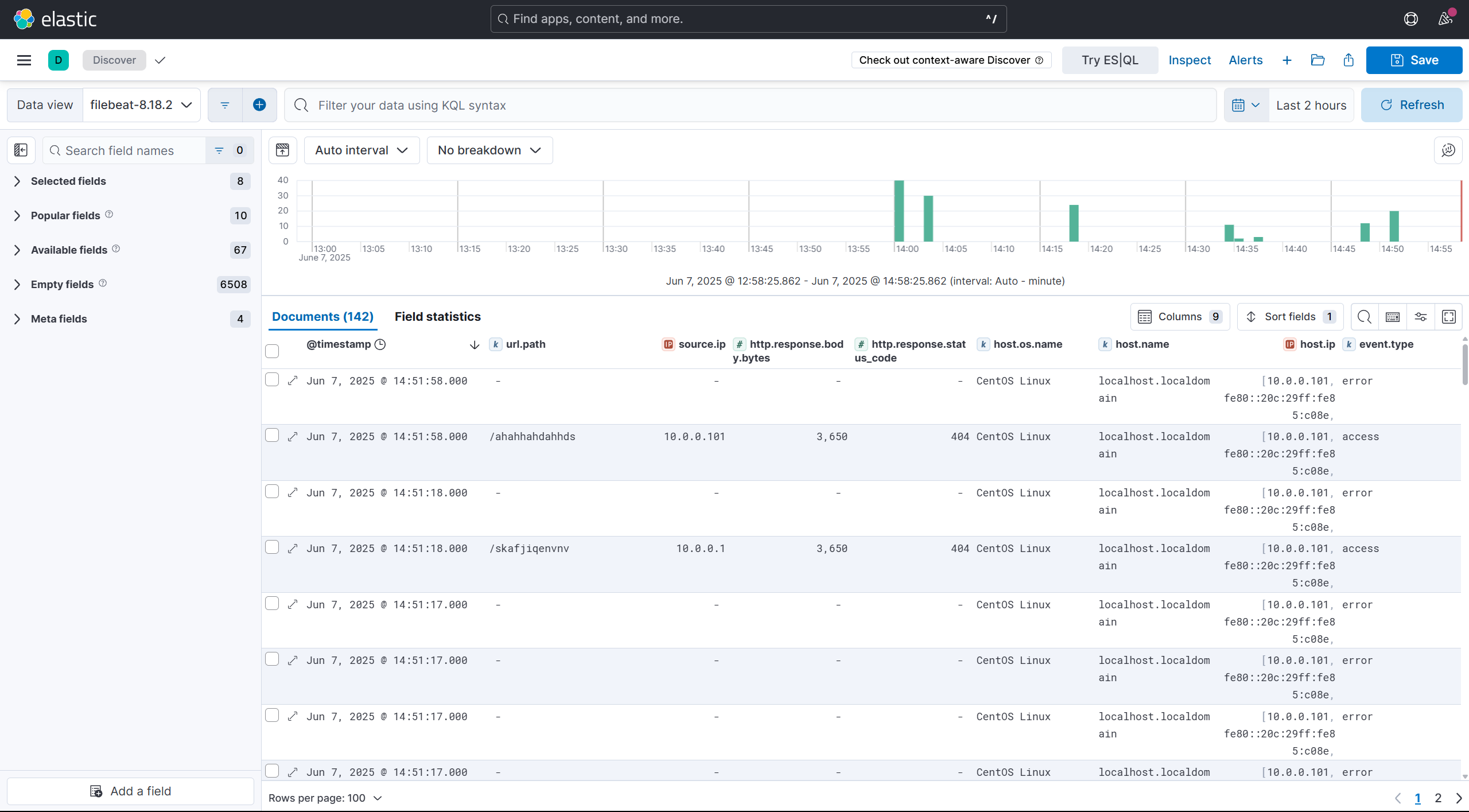
效果图
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from lxml import etree
def get_taobao_auction_data():
# 配置Chrome选项
chrome_options = Options()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--window-size=1920,1080')
# 设置Chrome浏览器路径
chrome_options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
# 设置User-Agent
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
try:
print("正在初始化Chrome驱动...")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
print("Chrome驱动初始化成功")
# 设置页面加载超时时间
driver.set_page_load_timeout(30)
# 访问目标网页
url = "https://zc-paimai.taobao.com/wow/pm/default/pc/zichansearch?fcatV4Ids=[%22206067201%22]&corp_type=[%226%22]&structFieldMap={%22corp_type%22:[%226%22]}&page=1"
driver.get(url)
# 等待页面加载
print("等待页面加载...")
time.sleep(10)
# 执行JavaScript滚动页面
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# 获取页面内容
page_source = driver.page_source
# 保存原始响应到文件
with open('taobao_auction.html', 'w', encoding='utf-8') as f:
f.write(page_source)
print("页面内容已保存到 taobao_auction.html")
# 使用lxml解析HTML
html = etree.HTML(page_source)
# 解析拍卖项目 - 更新XPath以匹配实际结构
items = html.xpath('//div[contains(@style, "border: 1px solid rgb(230, 230, 230)")]')
if items:
print(f"\n找到 {len(items)} 个拍卖项目")
for item in items:
try:
# 提取详情链接
detail_url = item.xpath('.//a/@href')
detail_url = "https:" + detail_url[0] if detail_url else "无链接"
# 提取图片URL
img_url = item.xpath('.//img[contains(@style, "object-fit: cover")]/@src')
img_url = "https:" + img_url[0] if img_url else "无图片"
# 提取标题
title = item.xpath('.//span[contains(@class, "text") and contains(@style, "font-size: 16px")]/@title')
title = title[0].strip() if title else "无标题"
# 提取当前价格
current_price = item.xpath('.//div[contains(text(), "当前价")]/following-sibling::div//span[contains(@style, "font-size: 24px")]/text()')
current_price = current_price[0].strip() if current_price else "无价格"
# 提取评估价
eval_price = item.xpath('.//div[contains(text(), "评估价")]/following-sibling::span[2]/text()')
eval_price = eval_price[0].strip() if eval_price else "无评估价"
# 提取拍卖状态
status = item.xpath('.//div[contains(@style, "background: rgb(235, 0, 69)")]/text()')
status = status[0].strip() if status else "无状态"
# 提取围观次数
views = item.xpath('.//span[contains(text(), "次围观")]/preceding-sibling::span/text()')
views = views[0].strip() if views else "0"
# 提取报名人数
signups = item.xpath('.//span[contains(text(), "人报名")]/preceding-sibling::span/text()')
signups = signups[0].strip() if signups else "0"
print("\n拍卖项目信息:")
print(f"标题: {title}")
print(f"当前价: {current_price}")
print(f"评估价: {eval_price}")
print(f"状态: {status}")
print(f"围观次数: {views}")
print(f"报名人数: {signups}")
print(f"图片URL: {img_url}")
print(f"详情链接: {detail_url}")
print("-" * 50)
except Exception as e:
print(f"解析项目时出错: {e}")
continue
else:
print("未找到拍卖项目,请检查页面结构")
print("请查看保存的HTML文件以分析页面结构")
except Exception as e:
print(f"发生错误: {e}")
finally:
# 关闭浏览器
try:
driver.quit()
except:
pass
if __name__ == "__main__":
get_taobao_auction_data()获取登录cookie
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from lxml import etree
import re
def get_auction_detail():
# 1. 采集页面并保存html(如已有可跳过)
chrome_options = Options()
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_argument('--window-size=1920,1080')
chrome_options.binary_location = r"C:\Program Files\Google\Chrome\Application\chrome.exe"
chrome_options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
try:
print("正在初始化Chrome驱动...")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
print("Chrome驱动初始化成功")
driver.set_page_load_timeout(30)
print("访问淘宝首页...")
driver.get("https://www.taobao.com")
time.sleep(3)
print("请在浏览器中手动登录淘宝...")
input("登录完成后请按回车键继续...")
cookies = driver.get_cookies()
print("已获取登录Cookie")
url = "https://sf-item.taobao.com/sf_item/903309584546.htm"
print(f"正在访问拍卖详情页: {url}")
driver.get(url)
print("等待页面加载...")
time.sleep(10)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
page_source = driver.page_source
with open('auction_detail.html', 'w', encoding='utf-8') as f:
f.write(page_source)
print("页面内容已保存到 auction_detail.html")
except Exception as e:
print(f"采集页面时发生错误: {e}")
finally:
try:
driver.quit()
except:
pass
# 2. 解析本地auction_detail.html,提取全部关键信息
print("\n正在解析 auction_detail.html ...")
with open('auction_detail.html', 'r', encoding='utf-8') as f:
html = etree.HTML(f.read())
def get_first(xpath_expr):
res = html.xpath(xpath_expr)
return res[0].strip() if res else ''
# 标题
title = get_first('//title/text()')
# 当前价
current_price = get_first('//span[contains(@class,"pm-current-price")]/em/text()')
if not current_price:
current_price = get_first('//span[contains(@class,"J_Price")]/em/text()')
# 变卖价、保证金、加价幅度、评估价、变卖周期、延时周期、竞价规则(表格)
def get_table_value(key):
td = html.xpath(f'//table//span[contains(text(),"{key}")]/../../following-sibling::td[1]//span[contains(@class,"family-tahoma")]/text()')
if not td:
# 兼容" : "后直接文本
td = html.xpath(f'//table//span[contains(text(),"{key}")]/../following-sibling::div//span[contains(@class,"family-tahoma")]/text()')
if not td:
# 兼容" : "后直接文本(无span)
td = html.xpath(f'//table//span[contains(text(),"{key}")]/../../following-sibling::td[1]//text()')
return td[0].strip() if td else ''
sell_price = get_table_value('变卖价')
deposit = get_table_value('保证金')
increase = get_table_value('加价幅度')
eval_price = get_table_value('评估价')
sell_period = get_table_value('变卖周期')
delay_period = get_table_value('延时周期')
rule = ''
rule_td = html.xpath('//table//span[contains(text(),"竞价规则")]/../../following-sibling::td[1]//span/text()')
if rule_td:
rule = rule_td[0].strip()
else:
# 兼容" : "后直接文本
rule = get_first('//table//span[contains(text(),"竞价规则")]/../following-sibling::div//span/text()')
# 主办法院
court = get_first('//div[@class="unit-org-content"]/p/text()')
# 拍卖公司及联系人
company = get_first('//em[contains(@class,"contact-unit-person")]/text()')
# 联系方式(手机号)
phone = get_first('//span[@class="c-title" and contains(text(),"手机")]/following-sibling::span[@class="c-text"]/text()')
# 公告链接
notice_link = html.xpath('//a[contains(@class,"view-ano")]/@href')
notice_link = notice_link[0] if notice_link else ''
if notice_link and not notice_link.startswith('http'):
notice_link = 'https:' + notice_link
print("\n拍卖详情信息:")
print(f"标题: {title}")
print(f"当前价: {current_price}")
print(f"变卖价: {sell_price}")
print(f"保证金: {deposit}")
print(f"加价幅度: {increase}")
print(f"评估价: {eval_price}")
print(f"变卖周期: {sell_period}")
print(f"延时周期: {delay_period}")
print(f"竞价规则: {rule}")
print(f"主办法院: {court}")
print(f"拍卖公司及联系人: {company}")
print(f"联系方式: {phone}")
print(f"公告链接: {notice_link}")
print("-" * 50)
if __name__ == "__main__":
get_auction_detail() 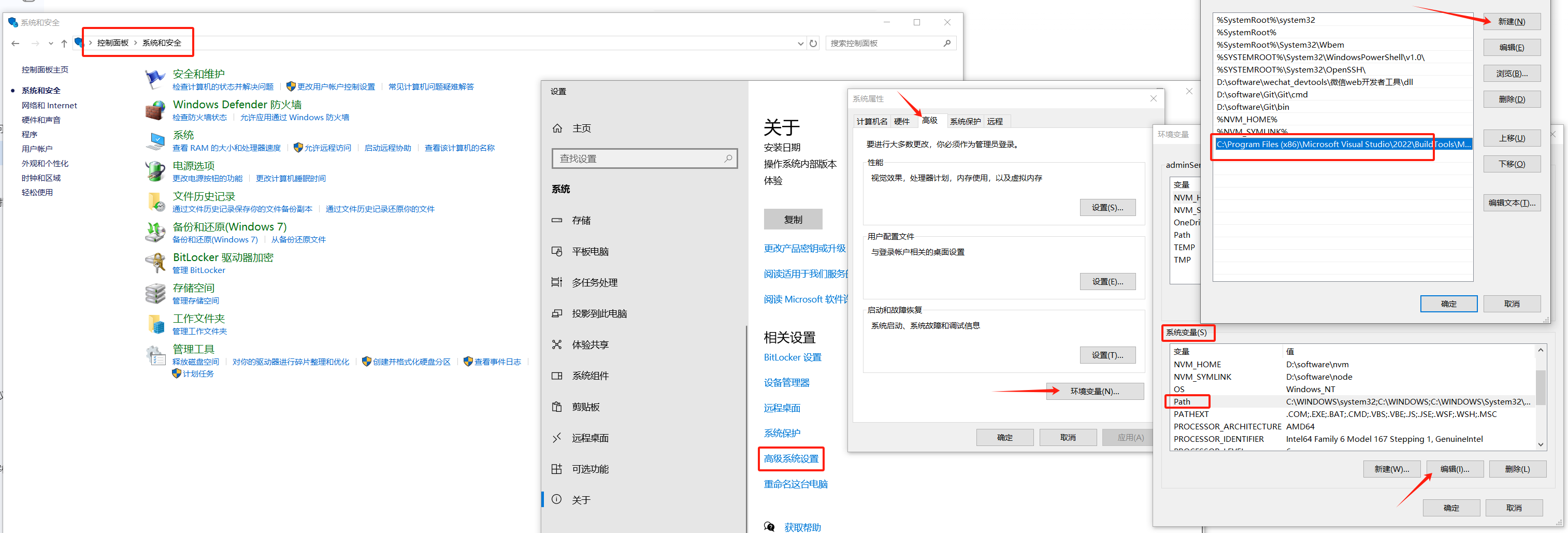
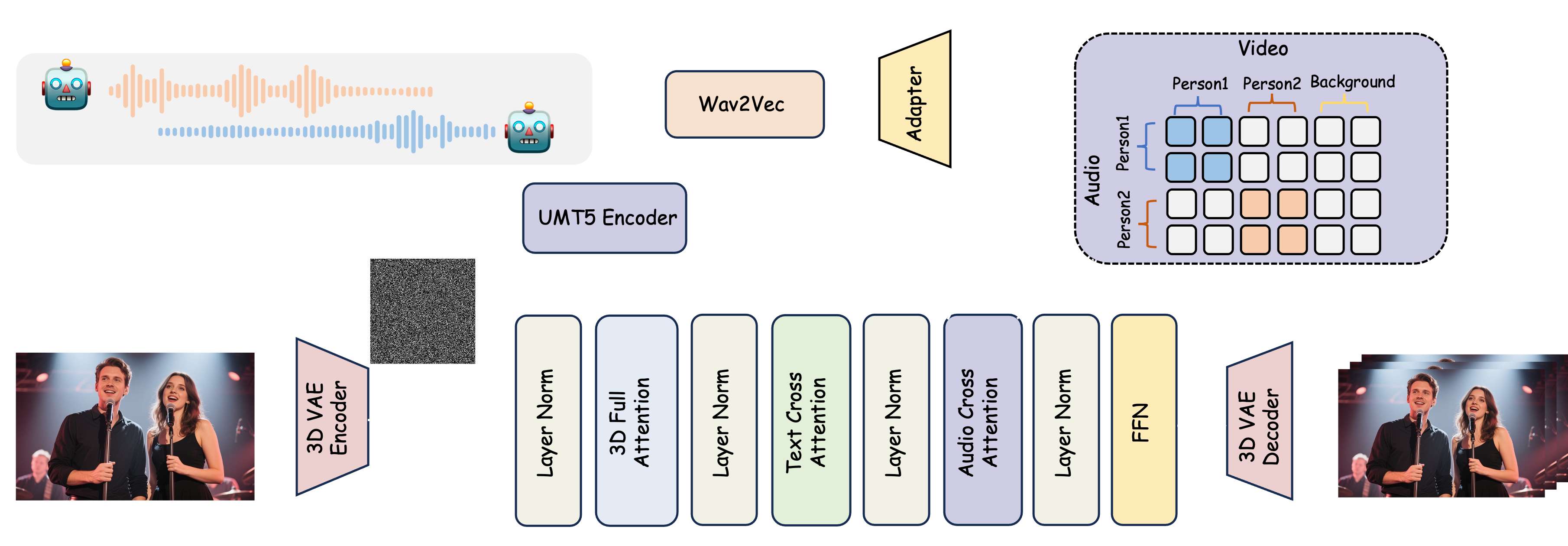










![[文献阅读] Emo-VITS - An Emotion Speech Synthesis Method Based on VITS](https://i-blog.csdnimg.cn/direct/4aadf56dd16246a79bbdbaf70ed36238.png)