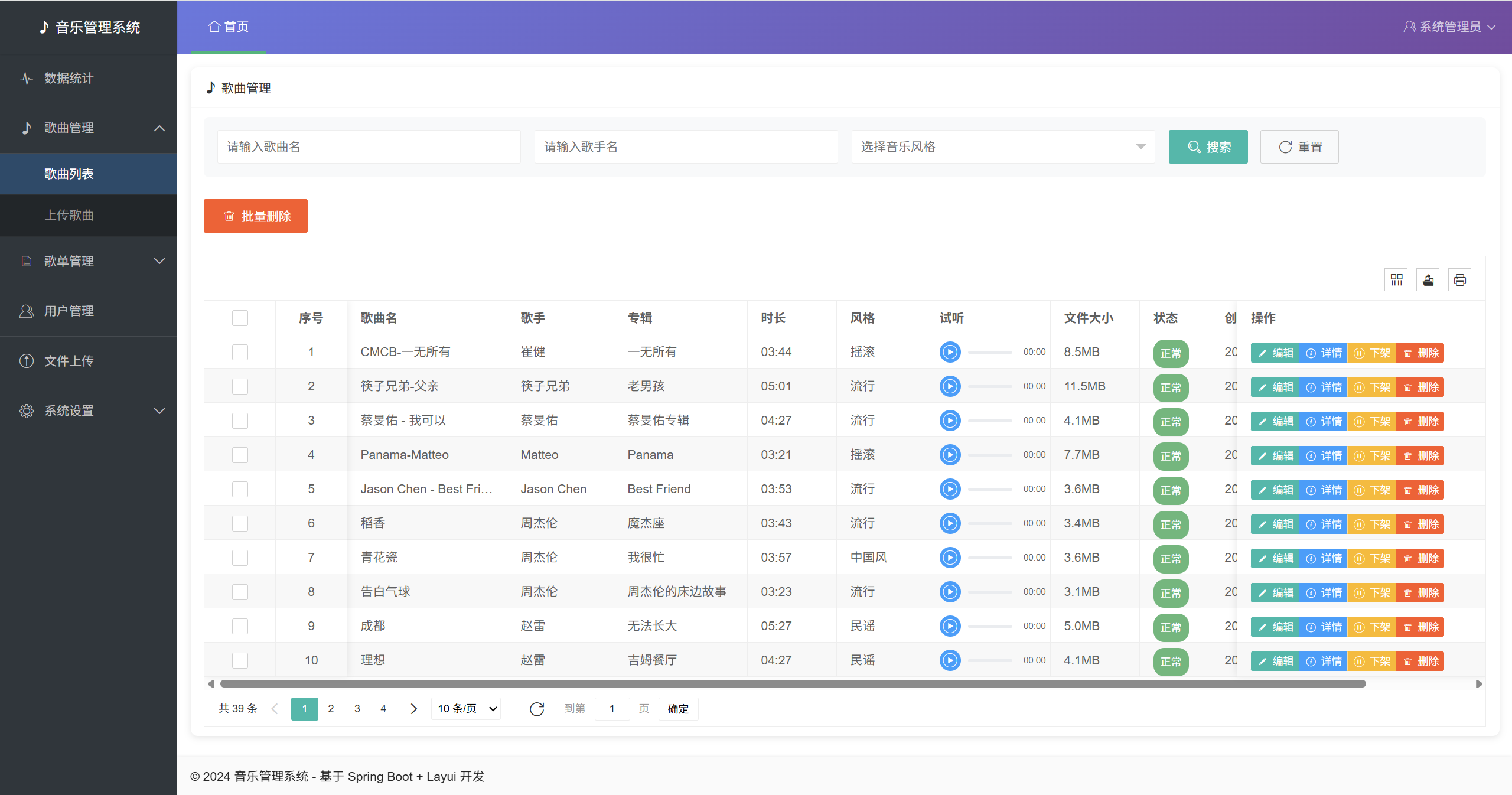
一、解决机制
1. 什么是循环依赖
循环依赖是指两个或多个Bean之间相互依赖对方,形成一个闭环的依赖关系。最常见的情况是当Bean A依赖Bean B,而Bean B又依赖Bean A时,就形成了循环依赖。在Spring容器初始化过程中,如果不加以特殊处理,这种循环依赖会导致Bean的创建过程陷入死循环,最终导致应用启动失败。
例如以下代码展示了一个典型的循环依赖场景:
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}
2. Spring三级缓存机制概述
Spring框架通过巧妙的"三级缓存"机制解决了循环依赖问题。这三级缓存在Spring源码中是通过三个Map集合实现的:
// 一级缓存:存放完全初始化好的Bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:存放原始的Bean对象(尚未填充属性),用于解决循环依赖
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存:存放Bean工厂对象,用于解决循环依赖
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
这三级缓存的作用分别是:
-
一级缓存(singletonObjects):用于存储完全初始化好的Bean,即已经完成实例化、属性填充和初始化的Bean,可以直接被其他对象使用。
-
二级缓存(earlySingletonObjects):用于存储早期曝光的Bean对象,这些Bean已经完成实例化但还未完成属性填充和初始化。当出现循环依赖时,其他Bean可以引用这个未完全初始化的Bean。
-
三级缓存(singletonFactories):用于存储Bean的工厂对象,主要用于处理需要AOP代理的Bean的循环依赖问题。它存储的是一个Lambda表达式,这个表达式会返回Bean的早期引用,并在需要时将其放入二级缓存。
3. 三级缓存的查找顺序
当Spring需要获取一个单例Bean时,会按照以下顺序查找:
- 首先从一级缓存(singletonObjects)中查找,如果找到直接返回
- 如果一级缓存没有,再从二级缓存(earlySingletonObjects)中查找
- 如果二级缓存也没有,则从三级缓存(singletonFactories)中查找对应的工厂,如果找到则通过工厂获取对象,并将其放入二级缓存,同时从三级缓存中移除
这种层级查找的机制确保了在循环依赖的情况下,Bean能够被正确地创建和注入。
4. Spring解决循环依赖的详细流程
以A、B两个类相互依赖为例,Spring解决循环依赖的流程如下:
-
创建Bean A:
- Spring首先创建Bean A的实例(仅完成实例化,未进行属性填充)
- 将A的创建工厂放入三级缓存singletonFactories中
- 开始给A填充属性,发现依赖了B
-
创建Bean B:
- Spring开始创建B(因为A依赖B)
- 实例化B,并将B的创建工厂放入三级缓存
- 开始给B填充属性,发现依赖了A
-
处理循环依赖:
- 此时需要注入A,但A正在创建中
- Spring尝试从一级缓存查找A,未找到
- 继续从二级缓存查找A,未找到
- 最后从三级缓存中找到A的工厂对象
- 通过工厂获取A的早期引用(可能是原始对象,也可能是代理对象)
- 将A的早期引用放入二级缓存,并从三级缓存中移除A的工厂
- 将A的早期引用注入到B中
-
完成Bean创建:
- B完成属性填充和初始化,放入一级缓存
- 返回到A的属性填充流程,将B注入到A中
- A完成属性填充和初始化,放入一级缓存
通过这个流程,Spring成功解决了循环依赖问题,关键在于提前暴露了Bean的早期引用。
5. 为什么需要三级缓存
很多人会疑惑,为什么需要三级缓存?二级缓存不能解决循环依赖问题吗?
实际上,在不考虑AOP的情况下,二级缓存确实可以解决循环依赖问题。但Spring设计三级缓存的主要目的是为了处理AOP代理的情况。
在Spring中,AOP代理是在Bean生命周期的最后阶段(初始化后)创建的。但如果出现循环依赖,就需要提前创建代理对象。三级缓存中的工厂对象可以在需要时(即真正出现循环依赖时)才创建代理对象,而不是对所有Bean都提前创建代理。
这种设计有以下优势:
- 延迟代理对象的创建:只有在真正需要时才创建代理对象,避免了不必要的性能开销
- 保持Bean生命周期的一致性:尽可能地保持Bean的标准生命周期流程
- 灵活处理各种代理场景:适应不同的AOP实现和代理方式
6. 三级缓存的局限性
虽然三级缓存机制能够解决大多数循环依赖问题,但它仍有一些局限性:
-
不能解决构造器注入的循环依赖:因为构造器注入发生在实例化阶段,此时Bean还未被放入三级缓存,所以无法解决
-
不能解决prototype作用域的循环依赖:三级缓存机制只对单例Bean有效,对于prototype作用域的Bean,Spring不会缓存其实例,因此无法解决其循环依赖
-
不能解决多例Bean之间的循环依赖:原因同上,Spring不会缓存非单例Bean
7. 源码分析
Spring解决循环依赖的核心源码主要在DefaultSingletonBeanRegistry类中,关键方法包括:
getSingleton(String beanName):按照一级、二级、三级缓存的顺序查找BeanaddSingletonFactory(String beanName, ObjectFactory<?> singletonFactory):将Bean的工厂对象放入三级缓存doGetBean(String name, Class<T> requiredType, Object[] args, boolean typeCheckOnly):获取Bean的主要逻辑
在AbstractAutowireCapableBeanFactory的doCreateBean方法中,会在Bean实例化后立即将其工厂对象放入三级缓存,为解决循环依赖做准备。
8. 总结
Spring通过三级缓存机制巧妙地解决了循环依赖问题,其核心思想是将Bean的实例化和初始化分离,提前暴露实例化但未完全初始化的对象。三级缓存的设计不仅解决了基本的循环依赖问题,还优雅地处理了AOP代理场景下的循环依赖。
这种机制体现了Spring框架设计的精妙之处,通过缓存分层和提前暴露对象的方式,在不影响Bean正常生命周期的前提下解决了看似棘手的循环依赖问题。
二、实际示例与解析
为了更直观地理解Spring如何通过三级缓存解决循环依赖问题,我们来看一个具体的示例,并详细分析整个过程。
1. 示例代码
首先,我们创建两个相互依赖的Service类:
@Service
public class UserService {
@Autowired
private OrderService orderService;
public void findUserOrders(Long userId) {
System.out.println("查询用户订单");
orderService.getOrdersByUserId(userId);
}
}
@Service
public class OrderService {
@Autowired
private UserService userService;
public List<Order> getOrdersByUserId(Long userId) {
System.out.println("获取用户订单");
return new ArrayList<>();
}
public void notifyUser(Long orderId) {
System.out.println("通知用户订单状态");
userService.findUserOrders(1L); // 调用UserService的方法
}
}
在这个示例中,UserService依赖OrderService,而OrderService又依赖UserService,形成了典型的循环依赖。
2. 详细解析Spring处理流程
让我们详细分析Spring如何处理这个循环依赖:
2.1 创建UserService
当Spring容器启动时,会按照Bean定义顺序开始创建Bean。假设先创建UserService:
1. 实例化UserService对象(仅调用构造函数,此时内部属性尚未赋值)
2. 将UserService实例的创建工厂添加到三级缓存(singletonFactories)中
singletonFactories.put("userService", () -> getEarlyBeanReference(beanName, mbd, userService实例))
3. 开始填充UserService的属性,发现需要注入OrderService
2.2 创建OrderService
由于UserService依赖OrderService,Spring开始创建OrderService:
1. 实例化OrderService对象(仅调用构造函数)
2. 将OrderService实例的创建工厂添加到三级缓存中
singletonFactories.put("orderService", () -> getEarlyBeanReference(beanName, mbd, orderService实例))
3. 开始填充OrderService的属性,发现需要注入UserService
2.3 处理循环依赖
此时出现了关键的循环依赖处理步骤:
1. OrderService需要注入UserService,但UserService正在创建中
2. Spring尝试从一级缓存(singletonObjects)查找UserService,未找到
3. 继续从二级缓存(earlySingletonObjects)查找UserService,未找到
4. 最后从三级缓存(singletonFactories)中找到UserService的工厂对象
5. 调用工厂对象的getObject()方法获取UserService的早期引用
- 如果UserService需要被代理(如有@Transactional注解),此时会创建代理对象
- 如果不需要代理,则返回原始对象
6. 将获取到的UserService早期引用放入二级缓存,同时从三级缓存中移除
earlySingletonObjects.put("userService", userService早期引用)
singletonFactories.remove("userService")
7. 将UserService的早期引用注入到OrderService中
2.4 完成Bean创建
接下来完成两个Bean的创建过程:
1. OrderService完成属性填充(已注入UserService的早期引用)
2. OrderService完成初始化(调用各种初始化方法)
3. 如果OrderService需要被代理,创建代理对象(AOP)
4. 将完全初始化好的OrderService放入一级缓存
singletonObjects.put("orderService", 完全初始化的orderService)
5. 返回到UserService的属性填充流程,将完全初始化好的OrderService注入到UserService中
6. UserService完成初始化
7. 如果UserService需要被代理且之前没有提前创建代理,创建代理对象
8. 将完全初始化好的UserService放入一级缓存
singletonObjects.put("userService", 完全初始化的userService)
3. 关键源码执行分析
让我们看一下在这个过程中涉及的关键源码执行流程:
3.1 从getSingleton方法开始
当Spring尝试获取一个Bean时,首先会调用getSingleton方法:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 首先从一级缓存查找
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存没有,且该Bean正在创建中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 从二级缓存查找
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存也没有,且允许早期引用
if (singletonObject == null && allowEarlyReference) {
// 从三级缓存获取工厂
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 通过工厂获取早期引用
singletonObject = singletonFactory.getObject();
// 放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存移除
this.singletonFactories.remove(beanName);
}
}
}
return singletonObject;
}
3.2 添加Bean到三级缓存
在Bean实例化后,Spring会将其添加到三级缓存中:
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
// 如果一级缓存中不存在
if (!this.singletonObjects.containsKey(beanName)) {
// 添加到三级缓存
this.singletonFactories.put(beanName, singletonFactory);
// 确保二级缓存中不存在
this.earlySingletonObjects.remove(beanName);
// 记录注册的单例
this.registeredSingletons.add(beanName);
}
}
}
3.3 创建早期引用
当需要处理循环依赖时,Spring会通过getEarlyBeanReference方法获取早期引用:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp =
(SmartInstantiationAwareBeanPostProcessor) bp;
// 这里可能创建代理对象
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
4. AOP场景下的循环依赖
特别值得注意的是,当涉及到AOP代理时,循环依赖的处理会更加复杂。例如,如果我们的示例中添加了事务注解:
@Service
@Transactional
public class UserService {
// ...
}
@Service
@Transactional
public class OrderService {
// ...
}
在这种情况下:
- 当从三级缓存获取UserService的早期引用时,会通过
AbstractAutoProxyCreator.getEarlyBeanReference方法创建代理对象 - 这个代理对象会被放入二级缓存,并最终注入到OrderService中
- 这就确保了OrderService依赖的是UserService的代理对象,而不是原始对象
这也解释了为什么需要三级缓存而不是二级缓存:三级缓存中存储的工厂可以在需要时(出现循环依赖时)才创建代理对象,而不是对所有Bean都提前创建代理。
5. 总结
通过这个实际示例,我们可以清晰地看到Spring如何通过三级缓存机制解决循环依赖问题:
- 实例化Bean后立即将其工厂对象放入三级缓存
- 当出现循环依赖时,通过三级缓存获取早期引用(可能是代理对象)
- 将早期引用放入二级缓存,并从三级缓存中移除
- 使用早期引用完成依赖注入
- 最终将完全初始化的Bean放入一级缓存
这种机制既解决了循环依赖问题,又保持了Spring Bean生命周期的完整性,同时还能灵活处理AOP代理场景,体现了Spring框架设计的精妙之处。