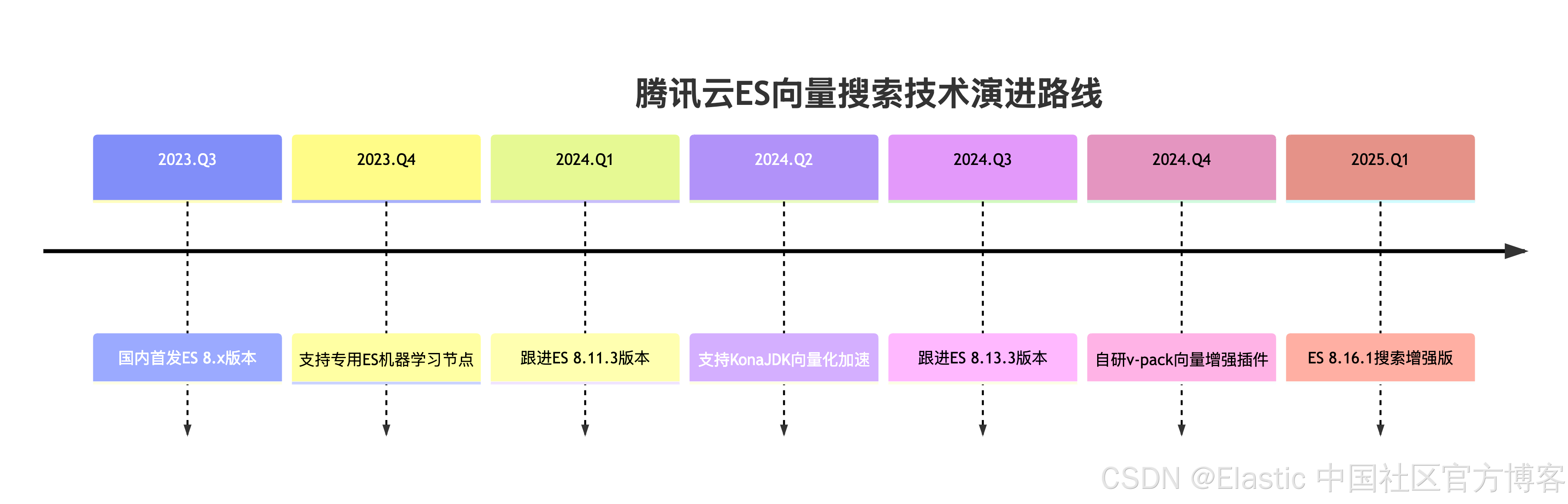
序
我最早用Python做大数据项目时,接触最早的就是Pandas了。觉得对于IT技术人员而言,它是可以属于多场景的存在,因为它的本身就是数据驱动的技术生态中,对于软件工程师而言,它是快速构建数据处理管道的基石;对数据分析师来说,它是洞察商业规律的显微镜;而对目前开始深度学习、机器学习从业者,它则是特征工程的精密车床。

在我的眼里,它的特点还是非常的明显:
- 效率与灵活性: Python 列表循环在面对 10 万行数据时会陷入 "龟速" 困境,而 Pandas 通过向量化操作将数据处理速度提升 10-100 倍,同时保持动态类型系统的灵活性。某电商平台数据工程师实测显示,使用 Pandas 进行用户行为数据清洗的效率,比纯 Python 实现提升 47 倍。
- 学术原型与工业落地的桥梁: 用过R 语言都知道,它在统计分析上表现优异,但难以集成到生产系统。Pandas 既保留了 R 式数据框的易用性,又能无缝对接 Flask、Django 等 Web 框架。我们之前做过风控系统,使用 Pandas 构建的用户画像系统,部署成本明显比 R 方案要低很多。
- 单节点处理与分布式扩展的平滑过渡:当数据量从 GB 级跃升至 TB 级时,Pandas 通过 Dask 生态实现计算资源的线性扩展。
所以Pandas 在 "数据处理工具" 类别中连续 6 年保持使用率第一,超过 Excel、SQL 等传统工具。很多python的实操,都是用Pandas去处理Excel。对于技术人员而言,掌握 Pandas 已不仅是技能加分项,而是进入数据科学领域的必备通行证。
好了,今天我们就从这一专题入手,共同的探讨学习一下。首先还是了解一下背景,它是如何出现的。
一、诞生背景与发展
2008 年,当 Wes McKinney 在 AQR Capital Management 从事量化金融研究时,Python 生态系统正面临一个关键痛点:尽管 NumPy 提供了高效的数组计算能力,但缺乏针对表格型数据的结构化处理工具。当时金融领域普遍使用 Excel 和 MATLAB 处理交易数据,而 R 语言虽具备统计分析优势,却在工程化部署中存在短板。这种 "数据分析工具链断裂" 的现实需求,催生了 Pandas(Python Data Analysis Library)的雏形。
1、关键历史节点解析
开源社区(2010-2012):2010 年 Pandas 正式开源,其核心数据结构仅包含 Series 和基本的 DataFrame 功能;2011 年加入 NumFOCUS 基金会,标志着从个人项目向社区驱动项目的转型,同年 0.8.0 版本引入 groupby 机制;2012 年 0.10.0 版本实现 DataFrame 列类型混合存储,奠定结构化数据处理基础
生态整合期(2013-2016):2014 年与 Scikit-learn 达成数据格式兼容协议,推动机器学习工作流标准化;2015 年 0.18.0 版本引入 Timedelta 类型,完善时间序列处理能力;2016 年 1.0.0 候选版发布,首次实现对 Python 3.5 + 的全面支持
性能提升期间(2017 至今):2018 年推出向量化字符串操作引擎,处理速度提升 10 倍以上;2020 年引入 BlockManager 内存管理架构,大幅优化大数据场景下的内存利用率;2022 年发布的 2.0 版本重构了 C 扩展层,新增 DataFrame._melt 等底层操作接口
2、技术特点
1、灵活性与效率的平衡:通过 NumPy 数组存储与 Python 接口分离的设计,既保持动态类型灵活性,又通过 C 扩展实现性能优化
2、学术研究与工业落地的衔接:从早期服务量化金融,到如今支撑 Netflix 推荐系统等大规模工业场景
3、单节点处理与分布式扩展的兼容:通过 Dask 等生态工具,实现从单机分析到集群计算的平滑过渡
二、核心数据结构
我个人认为,Pandas 构建在两个核心数据结构之上,它们就像是数据世界的基础积木,通过不同的组合方式构建出各种复杂的数据处理场景。
1、Series:一维数据的智能容器
Series 可以看作是一个带标签的一维数组,它就像超市里的一列商品,每个商品都有一个唯一的标签(索引)。与普通数组不同的是,Series 的索引可以是任意类型,不仅仅是整数。这种灵活性使得 Series 在处理非连续索引数据时表现出色,比如时间序列数据。
在底层实现上,Series 基于 NumPy 的 ndarray 构建,但增加了索引机制。索引本质上是一个 Pandas 的 Index 对象,它可以是哈希表结构(用于整数或对象索引)或排序数组(用于范围索引)。这种设计使得 Series 能够高效地进行数据对齐操作,这是 Pandas 的核心特性之一。
2、DataFrame:二维数据的表格
DataFrame 是 Pandas 的明星数据结构,它就像是一个电子表格,但功能更加强大。可以将其视为由多个 Series 组成的字典,每个 Series 代表一列数据。这种设计使得 DataFrame 在处理结构化数据时具有天然的优势,比如 CSV 文件、数据库表等。
DataFrame 的底层实现更加巧妙,它实际上是由多个 NumPy 数组组成的,每个数组对应一列数据。这种设计使得 DataFrame 在保持灵活性的同时,能够利用 NumPy 的向量化操作提高计算效率。列索引和行索引的设计使得数据的访问和操作变得非常便捷,就像在表格中查找数据一样简单。
三、Pandas 的实现原理
1、向量化操作:告别循环的计算革命
在传统的 Python 编程中,循环是处理数据的常用方式,但在面对大规模数据时,循环的效率往往令人头疼。Pandas 的向量化操作彻底改变了这一局面,它就像是一位高效的指挥官,能够同时指挥所有数据元素执行操作。
向量化操作的底层实现依赖于 NumPy 的 ndarray 和 C 语言扩展。当我们在 Pandas 中执行诸如 df ['column'] * 2 这样的操作时,实际上是在调用底层的 C 函数,这些函数经过高度优化,能够利用 CPU 的并行计算能力。这种方式比 Python 的循环快几个数量级,尤其是在处理大规模数据时,优势更加明显。
2、数据对齐:智能的数据匹配机制
数据对齐是 Pandas 的一大特色,它就像是一个智能的拼图大师,能够自动将不同来源的数据按照索引进行匹配。当我们对两个 DataFrame 进行合并或计算时,Pandas 会自动根据索引对齐数据,即使索引的顺序不同也没有关系。
这种数据对齐机制的实现基于哈希表和排序算法。在进行合并操作时,Pandas 会先对索引进行排序或哈希处理,然后找到匹配的元素。这种设计使得数据处理变得更加便捷,无需手动处理索引匹配问题,大大提高了数据处理的效率和准确性。
3、缺失值处理:数据清洗能力强
在实际的数据处理中,缺失值是一个常见的问题,就像白纸上的污点,需要我们进行处理。Pandas 提供了一套完整的缺失值处理机制,包括缺失值的检测、填充和删除等操作。
在底层,Pandas 使用 NaN(Not a Number)来表示缺失值,这是一个特殊的浮点数值。对于不同类型的数据,Pandas 采用不同的存储方式,比如对于整数类型,会使用一个额外的布尔数组来标记缺失值。这种设计使得缺失值处理既高效又灵活,能够满足各种数据处理场景的需求。
4、内存管理:大数据处理的关键保障
在处理大规模数据时,内存管理是一个关键问题。Pandas 提供了多种内存优化技术,就像是一位精打细算的管家,合理分配和使用内存资源。其中,分块处理是一种常用的技术,它将大数据分成多个小块,每次只处理一块数据,这样可以大大减少内存的占用。另外,Pandas 还提供了数据类型优化功能,比如将整数列转换为更小的数据类型(如 int8),从而节省内存空间。对于稀疏数据,Pandas 还提供了专门的 SparseDataFrame 结构,进一步提高内存使用效率。
下面说说,应用场景的应用。
四、Pandas 的应用场景
1、数据分析场景
在数据分析领域,无论是读取 CSV、Excel 等常见数据格式,还是进行数据的基本统计分析,Pandas 都能轻松应对。用Pandas操作EXCEL表做数据处理,真是so easy!使用 Pandas 读取调研数据,然后进行数据清洗、分组统计和可视化等操作。通过 Pandas 的 groupby 功能,我们可以轻松计算你对不同分组的需求轻松解决提供数据支持的场景。
2、数据清洗与预处理场景
在机器学习领域,数据清洗和预处理是一个必不可少的环节,就像是建造高楼大厦前的地基准备工作。Pandas 提供了丰富的数据清洗工具,能够帮助我们处理缺失值、异常值、数据标准化等问题。如:使用 Pandas 的 fillna 方法,我们可以方便地填充缺失值;使用 drop_duplicates 方法可以去除重复数据;使用 scikit-learn 与 Pandas 的集成,我们可以轻松进行数据标准化和特征工程。
3、金融数据分析场景
在金融领域,Pandas 更像是是量化分析师的必备工具。它就像是一个精准的金融计算器,能够处理各种复杂的金融数据和计算。无论是股票价格分析、投资组合优化还是风险评估,Pandas 都能发挥重要作用。例如:在股票分析场景,可以使用 Pandas 读取股票历史交易数据,计算各种技术指标(如移动平均线、相对强弱指数等),进行趋势分析和预测。通过 Pandas 的时间序列功能,我们可以轻松处理日内高频交易数据,进行套利策略的回测和优化。
4\业务报表与数据可视化
在企业日常运营中,业务报表和数据可视化是数据沟通的重要方式。Pandas 与 Matplotlib、Seaborn 等可视化库的完美集成,使得数据可视化变得非常简单,就像是一位出色的设计师,将枯燥的数据转化为直观的图表。
五、Pandas 的生态系统
我们知道Pandas 并不是一个孤立的工具,它与众多其他库和工具形成了一个强大的生态系统,就像是一个庞大的数据处理家族,各个成员之间相互协作,共同完成复杂的数据处理任务。
1、与 NumPy 的深度集成
NumPy 是 Pandas 的基础,Pandas 的核心数据结构底层都依赖于 NumPy 的 ndarray。这种深度集成使得 Pandas 能够充分利用 NumPy 的强大计算能力,同时又提供了更高级的数据结构和功能。下次我可能会NumPy再做一下深度的剖析。
2、与机器学习库的无缝对接
Pandas 与 scikit-learn、TensorFlow 等机器学习库有着良好的兼容性。我们可以直接将 Pandas 的 DataFrame 作为输入传递给机器学习模型,无需进行复杂的数据格式转换。这种无缝对接大大简化了机器学习工作流程,提高了开发效率。
3、大数据处理的扩展工具
对于大规模数据处理,Pandas 提供了 Dask 等扩展工具。Dask 可以将 Pandas 的操作并行化,处理超出内存容量的数据,就像是给 Pandas 插上了一双翅膀,使其能够在大数据的天空中自由翱翔。
4、数据库交互的便捷接口
Pandas 提供了便捷的数据库交互接口,我们可以使用 pandas.read_sql 函数直接从数据库中读取数据,也可以使用 to_sql 函数将处理后的数据写入数据库。这种功能使得 Pandas 在数据 ETL(提取、转换、加载)过程中发挥重要作用。
六、Pandas 的性能优化
1、向量化操作的充分利用
如前所述,向量化操作是 Pandas 性能的关键。在编写代码时,我们应该尽量避免使用 Python 循环,而是使用 Pandas 的内置函数和向量化操作。例如,使用 df.apply 而不是 for 循环,使用 df.query 而不是复杂的条件判断。
2、数据类型的合理选择
合理选择数据类型可以大大提高内存使用效率和计算速度。在处理整数数据时,尽量使用较小的数据类型(如 int8、int16);在处理浮点数数据时,考虑使用 float16 或 float32。Pandas 提供了 astype 方法和 to_numeric 函数,方便我们进行数据类型转换。
3、内存映射文件的使用
对于超大文件,使用内存映射文件(mmap)可以在不将整个文件加载到内存的情况下进行操作。Pandas 的 read_csv 函数提供了 memory_map 参数,启用后可以大大减少内存占用,提高处理效率。
4、并行计算的引入
虽然 Pandas 本身不是一个并行计算框架,但我们可以利用 Dask 等工具将 Pandas 操作并行化。Dask 提供了与 Pandas 兼容的 API,使得我们可以轻松地将单线程的 Pandas 代码转换为并行执行,大大提高处理大规模数据的效率。
最后小结
我是从数据分析统计的项目接触到Pandas的,我想对于数据处理的角色,Pandas 是入门的最佳选择之一,它能够让复杂的数据处理变得简单直观;而对于专业的数据分析领域来说,Pandas也 是不可或缺的工具,它能够帮助我们高效地处理数据,专注于数据分析和建模。
它的强大之处不仅在于其强大的功能和高效的性能,更在于其简洁易用的接口和强大的生态系统。随着数据科学的不断发展,Pandas 也在不断进化,新的功能和优化持续推出。无论您是刚刚踏入数据科学领域的新手,还是经验丰富的专业人士,掌握 Pandas 都将为您的数据分析之旅增添强大的动力。我的能力有限只能讲到这些地方,如果您对此文有兴趣,欢迎指点让我们一起探索 Pandas 的更多可能性,释放数据的全部价值!