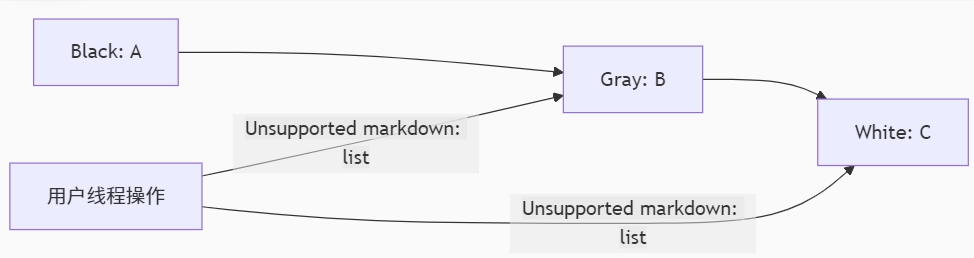
之前做过一个项目,他要求是只爬取新产生的或者已经更新的页面,避免重复爬取未变化的页面,从而节省资源和时间。这里我需要设计一个增量式网络爬虫的通用模板。可以继承该类并重写部分方法以实现特定的解析和数据处理逻辑。这样可以更好的节约时间。

以下就是我熬几个通宵写的一个Python实现的增量式网络爬虫通用模板,使用SQLite数据库存储爬取状态,实现URL去重、增量更新和断点续爬功能。
import sqlite3
import hashlib
import time
import requests
from urllib.parse import urlparse, urljoin
from bs4 import BeautifulSoup
import re
import os
import logging
from queue import Queue
from threading import Thread, Lock
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("incremental_crawler.log"),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
class IncrementalCrawler:
def __init__(self, db_path='crawler.db', max_threads=5, max_depth=3,
politeness_delay=1.0, user_agent=None):
"""
增量式网络爬虫初始化
参数:
db_path: 数据库文件路径
max_threads: 最大线程数
max_depth: 最大爬取深度
politeness_delay: 请求延迟时间(秒)
user_agent: 自定义User-Agent
"""
self.db_path = db_path
self.max_threads = max_threads
self.max_depth = max_depth
self.politeness_delay = politeness_delay
self.user_agent = user_agent or "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
# 初始化数据库
self._init_database()
# 线程安全锁
self.lock = Lock()
# 请求会话
self.session = requests.Session()
self.session.headers.update({"User-Agent": self.user_agent})
# 爬取队列
self.queue = Queue()
# 统计信息
self.stats = {
'total_crawled': 0,
'total_links_found': 0,
'start_time': time.time(),
'last_crawl_time': 0
}
def _init_database(self):
"""初始化数据库结构"""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# 创建URL表
cursor.execute('''
CREATE TABLE IF NOT EXISTS urls (
id INTEGER PRIMARY KEY,
url TEXT UNIQUE NOT NULL,
depth INTEGER DEFAULT 0,
status TEXT DEFAULT 'pending',
content_hash TEXT,
last_crawled REAL,
created_at REAL DEFAULT (datetime('now'))
)
''')
# 创建域延迟表
cursor.execute('''
CREATE TABLE IF NOT EXISTS domain_delays (
domain TEXT PRIMARY KEY,
last_request REAL DEFAULT 0
)
''')
conn.commit()
def add_seed_urls(self, urls, depth=0):
"""添加种子URL到队列和数据库"""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
for url in urls:
# 规范化URL
normalized_url = self._normalize_url(url)
if not normalized_url:
continue
# 检查URL是否已存在
cursor.execute("SELECT 1 FROM urls WHERE url = ?", (normalized_url,))
if cursor.fetchone():
continue
# 插入新URL
try:
cursor.execute(
"INSERT INTO urls (url, depth, status) VALUES (?, ?, ?)",
(normalized_url, depth, 'pending')
)
self.queue.put((normalized_url, depth))
logger.info(f"Added seed URL: {normalized_url} at depth {depth}")
except sqlite3.IntegrityError:
pass # URL已存在
conn.commit()
def _normalize_url(self, url):
"""规范化URL"""
parsed = urlparse(url)
if not parsed.scheme:
return None
# 移除URL中的片段标识符
return parsed.scheme + "://" + parsed.netloc + parsed.path
def _get_domain(self, url):
"""从URL中提取域名"""
return urlparse(url).netloc
def _should_crawl(self, url, depth):
"""决定是否应该爬取该URL"""
# 检查深度限制
if depth > self.max_depth:
return False
# 检查URL是否已爬取
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"SELECT content_hash, last_crawled FROM urls WHERE url = ?",
(url,)
)
row = cursor.fetchone()
if not row:
return True # 新URL,需要爬取
content_hash, last_crawled = row
# 如果从未成功爬取过,则重试
if last_crawled is None:
return True
# 如果上次爬取时间超过24小时,则重新爬取
if time.time() - last_crawled > 24 * 3600:
return True
return False
def _respect_politeness(self, domain):
"""遵守爬取礼貌规则,避免对同一域名请求过快"""
with self.lock:
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"SELECT last_request FROM domain_delays WHERE domain = ?",
(domain,)
)
row = cursor.fetchone()
last_request = 0
if row:
last_request = row[0]
# 计算需要等待的时间
elapsed = time.time() - last_request
if elapsed < self.politeness_delay:
wait_time = self.politeness_delay - elapsed
logger.debug(f"Respecting politeness for {domain}, waiting {wait_time:.2f}s")
time.sleep(wait_time)
# 更新最后请求时间
cursor.execute(
"INSERT OR REPLACE INTO domain_delays (domain, last_request) VALUES (?, ?)",
(domain, time.time())
)
conn.commit()
def _fetch_url(self, url):
"""获取URL内容"""
try:
response = self.session.get(url, timeout=10)
response.raise_for_status() # 检查HTTP错误
return response.content, response.status_code
except requests.RequestException as e:
logger.error(f"Error fetching {url}: {str(e)}")
return None, None
def _extract_links(self, content, base_url):
"""从HTML内容中提取链接"""
soup = BeautifulSoup(content, 'html.parser')
links = set()
# 提取所有<a>标签的href
for a_tag in soup.find_all('a', href=True):
href = a_tag['href'].strip()
if not href or href.startswith('javascript:'):
continue
# 解析相对URL
absolute_url = urljoin(base_url, href)
normalized_url = self._normalize_url(absolute_url)
if normalized_url:
links.add(normalized_url)
return list(links)
def _calculate_hash(self, content):
"""计算内容哈希值"""
return hashlib.sha256(content).hexdigest()
def _process_page(self, url, depth, content, status_code):
"""处理页面内容"""
# 计算内容哈希
content_hash = self._calculate_hash(content)
# 检查内容是否已存在
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"SELECT id FROM urls WHERE content_hash = ?",
(content_hash,)
)
existing_id = cursor.fetchone()
if existing_id:
logger.info(f"Content already exists for {url}, skipping processing")
else:
# 处理内容 - 用户可重写此部分
self.process_content(url, content)
# 更新数据库
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"""UPDATE urls
SET status = ?, content_hash = ?, last_crawled = ?
WHERE url = ?""",
('completed', content_hash, time.time(), url)
)
conn.commit()
# 提取链接
links = self._extract_links(content, url)
new_depth = depth + 1
new_urls = []
# 添加新链接到数据库和队列
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
for link in links:
# 检查是否应该爬取
if not self._should_crawl(link, new_depth):
continue
# 插入新URL或更新现有URL
try:
cursor.execute(
"""INSERT INTO urls (url, depth, status)
VALUES (?, ?, ?)
ON CONFLICT(url) DO UPDATE SET depth = ?, status = ?""",
(link, new_depth, 'pending', new_depth, 'pending')
)
new_urls.append(link)
except sqlite3.Error as e:
logger.error(f"Error adding URL {link}: {str(e)}")
conn.commit()
# 添加新URL到队列
for link in new_urls:
self.queue.put((link, new_depth))
# 更新统计
with self.lock:
self.stats['total_crawled'] += 1
self.stats['total_links_found'] += len(links)
self.stats['last_crawl_time'] = time.time()
logger.info(f"Crawled: {url} | Depth: {depth} | Links found: {len(links)} | New URLs: {len(new_urls)}")
def process_content(self, url, content):
"""
处理页面内容的方法 - 用户应重写此方法以实现具体业务逻辑
参数:
url: 当前页面的URL
content: 页面内容(字节)
"""
# 示例: 保存HTML文件
domain = self._get_domain(url)
path = urlparse(url).path
filename = re.sub(r'[^\w\-_\.]', '_', path) or "index.html"
# 创建域目录
os.makedirs(f"crawled_pages/{domain}", exist_ok=True)
# 保存文件
with open(f"crawled_pages/{domain}/{filename}", "wb") as f:
f.write(content)
logger.debug(f"Saved content for {url}")
def _worker(self):
"""爬虫工作线程"""
while True:
url, depth = self.queue.get()
# 检查是否应该爬取
if not self._should_crawl(url, depth):
self.queue.task_done()
continue
domain = self._get_domain(url)
self._respect_politeness(domain)
# 获取URL内容
content, status_code = self._fetch_url(url)
# 处理响应
if content:
self._process_page(url, depth, content, status_code)
else:
# 标记为失败
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"UPDATE urls SET status = ? WHERE url = ?",
('failed', url)
)
conn.commit()
logger.warning(f"Failed to crawl {url}")
self.queue.task_done()
def start_crawling(self, resume=False):
"""
启动爬虫
参数:
resume: 是否从上次中断处继续
"""
logger.info("Starting incremental crawler")
if resume:
# 恢复未完成的URL
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
cursor.execute(
"SELECT url, depth FROM urls WHERE status IN ('pending', 'failed')"
)
pending_urls = cursor.fetchall()
for url, depth in pending_urls:
self.queue.put((url, depth))
logger.info(f"Resuming pending URL: {url} at depth {depth}")
# 启动工作线程
for i in range(self.max_threads):
t = Thread(target=self._worker, daemon=True)
t.start()
# 等待队列完成
self.queue.join()
# 计算总时间
total_time = time.time() - self.stats['start_time']
logger.info(f"Crawling completed! Total URLs crawled: {self.stats['total_crawled']}")
logger.info(f"Total links found: {self.stats['total_links_found']}")
logger.info(f"Total time: {total_time:.2f} seconds")
def print_stats(self):
"""打印爬虫统计信息"""
with sqlite3.connect(self.db_path) as conn:
cursor = conn.cursor()
# 获取URL统计
cursor.execute("SELECT status, COUNT(*) FROM urls GROUP BY status")
status_counts = cursor.fetchall()
# 获取最常爬取的域名
cursor.execute('''
SELECT domain, COUNT(*) as count
FROM (
SELECT
CASE
WHEN INSTR(url, '://') > 0
THEN SUBSTR(url, INSTR(url, '://') + 3, INSTR(SUBSTR(url, INSTR(url, '://') + 3), '/') - 1)
END as domain
FROM urls
)
WHERE domain IS NOT NULL
GROUP BY domain
ORDER BY count DESC
LIMIT 5
''')
top_domains = cursor.fetchall()
print("\n===== Crawler Statistics =====")
print(f"Total URLs crawled: {self.stats['total_crawled']}")
print(f"Total links found: {self.stats['total_links_found']}")
print("\nURL Status Summary:")
for status, count in status_counts:
print(f" {status}: {count}")
print("\nTop Domains:")
for domain, count in top_domains:
print(f" {domain}: {count} URLs")
if self.stats['last_crawl_time'] > 0:
last_crawl = time.strftime(
"%Y-%m-%d %H:%M:%S",
time.localtime(self.stats['last_crawl_time'])
)
print(f"\nLast crawl time: {last_crawl}")
# 使用示例
if __name__ == "__main__":
# 创建爬虫实例
crawler = IncrementalCrawler(
max_threads=3,
max_depth=2,
politeness_delay=2.0
)
# 添加种子URL
seed_urls = [
"https://example.com",
"https://www.wikipedia.org",
"https://github.com"
]
crawler.add_seed_urls(seed_urls)
# 启动爬虫 (resume=True 可以从上次中断处继续)
try:
crawler.start_crawling(resume=False)
except KeyboardInterrupt:
logger.info("Crawler interrupted by user")
# 打印统计信息
crawler.print_stats()
增量式爬虫核心功能
-
URL去重与状态管理:
- 使用SQLite数据库存储所有URL及其状态
- 基于URL和内容哈希进行去重
- 记录最后爬取时间,避免重复爬取
-
增量更新机制:
- 仅爬取新URL或24小时内未更新的URL
- 内容哈希比对,避免处理相同内容
-
礼貌爬取策略:
- 域名级别的请求延迟控制
- 可配置的延迟时间
- 避免对同一域名请求过快
-
断点续爬功能:
- 记录爬取状态到数据库
- 支持从"pending"或"failed"状态恢复爬取
-
多线程支持:
- 可配置的线程数量
- 线程安全的数据访问
使用说明
-
初始化爬虫:
crawler = IncrementalCrawler( db_path='crawler.db', # 数据库路径 max_threads=5, # 最大线程数 max_depth=3, # 最大爬取深度 politeness_delay=1.0, # 请求延迟(秒) user_agent="Custom Agent" # 自定义User-Agent ) -
添加种子URL:
crawler.add_seed_urls([ "https://example.com", "https://www.example.org" ]) -
自定义内容处理:
class MyCrawler(IncrementalCrawler): def process_content(self, url, content): # 实现自定义处理逻辑 # 例如:解析内容、存储数据等 pass -
启动爬虫:
# 首次爬取 crawler.start_crawling(resume=False) # 断点续爬 crawler.start_crawling(resume=True) -
查看统计信息:
crawler.print_stats()
数据库结构
urls 表
| 字段 | 类型 | 描述 |
|---|---|---|
| id | INTEGER | 主键ID |
| url | TEXT | URL地址(唯一) |
| depth | INTEGER | 爬取深度 |
| status | TEXT | 状态(pending/completed/failed) |
| content_hash | TEXT | 内容哈希值 |
| last_crawled | REAL | 最后爬取时间 |
| created_at | REAL | 创建时间 |
domain_delays 表
| 字段 | 类型 | 描述 |
|---|---|---|
| domain | TEXT | 域名(主键) |
| last_request | REAL | 最后请求时间 |
注意事项
- 遵守网站的robots.txt规则
- 根据目标网站调整爬取延迟(politeness_delay)
- 重写process_content方法实现具体业务逻辑
- 避免爬取敏感或受版权保护的内容
- 定期备份数据库文件
这个模版就是以前我做过的一个项目,主要提供了增量式爬虫的核心功能,具体情况可以根据需求进行扩展和优化。不管是小型爬虫还是大型增量爬虫都可以完美胜任,如果有问题可以留言讨论。