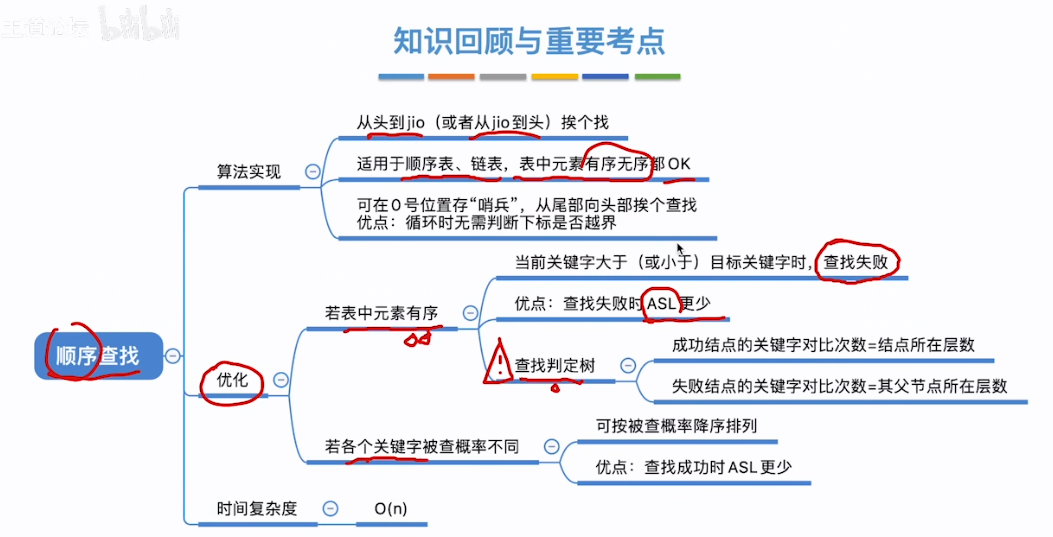
Qwen2.5-VL - 模型结构
flyfish
| 配置项 (Configuration) | Qwen2.5-VL-3B | Qwen2.5-VL-7B | Qwen2.5-VL-72B |
|---|---|---|---|
| 视觉Transformer (ViT) | |||
| 隐藏层大小 (Hidden Size) | 1280 | 1280 | 1280 |
| 层数 (# Layers) | 32 | 32 | 32 |
| 头数 (# Num Heads) | 16 | 16 | 16 |
| 中间层大小 (Intermediate Size) | 3456 | 3456 | 3456 |
| patch尺寸 (Patch Size) | 14 | 14 | 14 |
| 窗口尺寸 (Window Size) | 112 | 112 | 112 |
| 全注意力块索引 (Full Attention Block Indexes) | {7, 15, 23, 31} | {7, 15, 23, 31} | {7, 15, 23, 31} |
| 视觉-语言融合器 (Vision-Language Merger) | |||
| 输入通道 (In Channel) | 1280 | 1280 | 1280 |
| 输出通道 (Out Channel) | 2048 | 3584 | 8192 |
| 大语言模型 (LLM) | |||
| 隐藏层大小 (Hidden Size) | 2048 | 3584 | 8192 |
| 层数 (# Layers) | 36 | 28 | 80 |
| KV头数 (# KV Heads) | 2 | 4 | 8 |
| 头大小 (Head Size) | 128 | 128 | 128 |
| 中间层大小 (Intermediate Size) | 4864 | 18944 | 29568 |
| 嵌入绑定 (Embedding Tying) | ✔️ | ✖️ | ✖️ |
| 词汇表大小 (Vocabulary Size) | 151646 | 151646 | 151646 |
| 训练 token 数 (# Trained Tokens) | 4.1T | 4.1T | 4.1T |
以Qwen2.5-VL-3B 为例
Qwen2.5 VL 主要由三部分组成:
视觉处理模块(visual):处理图像输入,提取视觉特征
语言模型模块(model):处理文本输入,生成语言表示
输出层(lm_head):将融合后的特征映射到词表空间
简化
-
视觉路径:
图像 → patch_embed(Conv3d)→ 旋转位置编码 → 32个视觉块(注意力+MLP)→ merger(特征融合)→ 2048维视觉表示 -
语言路径:
文本token → embed_tokens(词嵌入)→ 36个解码器层(自注意力+MLP)→ norm归一化 → 2048维语言表示 -
融合与输出:
视觉表示 + 语言表示(在merger中融合)→ 语言解码器处理融合特征 → lm_head(线性层)→ 词表空间预测(151936维)
Qwen2.5 VL各模块前向传播流程
视觉处理路径
图像输入 (3通道)
↓
patch_embed (视觉分块嵌入)
↳ Conv3d(3, 1280, kernel=(2,14,14), stride=(2,14,14))
↓
rotary_pos_emb (旋转位置编码)
↓
blocks (32个视觉Transformer块)
↳ 块0-31: Qwen2_5_VLVisionBlock
↳ norm1: Qwen2RMSNorm(eps=1e-06)
↳ attn: Qwen2_5_VLVisionFlashAttention2
↳ qkv: Linear(1280→3840)
↳ FlashAttention2计算
↳ proj: Linear(1280→1280)
↳ norm2: Qwen2RMSNorm(eps=1e-06)
↳ mlp: Qwen2_5_VLMLP
↳ gate_proj: Linear(1280→3420)
↳ up_proj: Linear(1280→3420)
↳ act_fn: SiLU()
↳ down_proj: Linear(3420→1280)
↓
merger (视觉-语言特征融合)
↳ ln_q: Qwen2RMSNorm(eps=1e-06)
↳ mlp: Sequential
↳ Linear(5120→5120)
↳ GELU()
↳ Linear(5120→2048)
↓
视觉特征输出: 2048维向量
语言处理路径
文本token输入 (ID序列)
↓
embed_tokens: Embedding(151936, 2048)
↓
layers (36个解码器层)
↳ 层0-35: Qwen2_5_VLDecoderLayer
↳ input_layernorm: Qwen2RMSNorm(eps=1e-06)
↳ self_attn: Qwen2_5_VLFlashAttention2
↳ q_proj: Linear(2048→2048)
↳ k_proj: Linear(2048→256)
↳ v_proj: Linear(2048→256)
↳ rotary_emb: 旋转位置编码
↳ FlashAttention2计算 (带因果掩码)
↳ o_proj: Linear(2048→2048)
↳ post_attention_layernorm: Qwen2RMSNorm(eps=1e-06)
↳ mlp: Qwen2MLP
↳ gate_proj: Linear(2048→11008)
↳ up_proj: Linear(2048→11008)
↳ act_fn: SiLU()
↳ down_proj: Linear(11008→2048)
↓
norm: Qwen2RMSNorm(eps=1e-06)
↓
语言特征输出: 2048维向量
多模态融合与输出
视觉特征 (2048维) + 语言特征 (2048维)
↓ 在merger模块中融合 (见视觉路径末尾)
↓
融合特征输入语言解码器
↓
lm_head: Linear(2048→151936)
↓
输出: 词表空间预测 (用于文本生成或分类)
一、视觉特征提取路径
-
图像分块与嵌入:
输入3通道图像(如H×W×3),通过patch_embed模块的3D卷积(Conv3d)进行分块处理。卷积核大小为(2,14,14),步长(2,14,14),将图像在时间维度(假设为2帧)和空间维度(14×14)划分为补丁,同时将通道数从3映射至1280维,生成初始视觉补丁特征。 -
位置编码注入:
通过rotary_pos_emb模块为视觉补丁添加旋转位置编码,赋予特征空间位置信息,提升模型对图像结构的感知能力。 -
多层视觉Transformer处理:
特征依次通过32个Qwen2_5_VLVisionBlock。每个块内:- 先经
norm1(RMSNorm)归一化; - 通过
attn模块的qkv线性层(1280→3840)生成Query、Key、Value,执行FlashAttention2计算补丁间的关联,再经proj线性层(1280→1280)还原维度; - 再经
norm2归一化后,进入mlp模块:通过gate_proj和up_proj将特征扩展至3420维,经SiLU激活后由down_proj映射回1280维,增强特征表达能力。
- 先经
-
跨模态特征融合:
视觉处理的最终特征(1280维)进入merger模块:- 先通过
ln_q(RMSNorm)归一化语言路径的输入特征; - 经三层MLP(5120→5120→2048,GELU激活)将视觉特征与语言特征拼接后映射至2048维,实现视觉特征向语言空间的对齐。
- 先通过
二、语言特征处理路径
-
文本嵌入表示:
输入文本token ID序列,通过embed_tokens(词嵌入层)映射为2048维的词向量,作为语言模型的初始特征。 -
多层解码器处理:
特征依次通过36个Qwen2_5_VLDecoderLayer。每个层内:- 先经
input_layernorm(RMSNorm)归一化; - 通过
self_attn模块的q_proj(2048→2048)、k_proj(2048→256)、v_proj(2048→256)生成Query、Key、Value,结合rotary_emb位置编码执行带因果掩码的FlashAttention2(确保解码时只能关注前文),再经o_proj(2048→2048)还原维度; - 经
post_attention_layernorm归一化后,进入mlp模块:通过gate_proj和up_proj扩展至11008维,经SiLU激活后由down_proj映射回2048维,捕捉文本语义依赖。
- 先经
-
最终归一化:
所有解码器层输出经norm(RMSNorm)归一化,生成2048维的语言特征表示。
三、多模态融合与输出
-
特征融合:
视觉路径输出的2048维特征与语言路径的2048维特征在merger模块中融合,形成包含视觉-语言信息的联合表示。 -
生成预测:
融合后的特征输入语言解码器进行跨模态推理,最终通过lm_head线性层(2048→151936)映射至词表空间,输出文本生成的概率分布,用于回答问题、图像描述等任务。
Qwen2_5_VLForConditionalGeneration(
(visual): Qwen2_5_VisionTransformerPretrainedModel(
(patch_embed): Qwen2_5_VisionPatchEmbed(
(proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False)
)
(rotary_pos_emb): Qwen2_5_VisionRotaryEmbedding()
(blocks): ModuleList(
(0-31): 32 x Qwen2_5_VLVisionBlock(
(norm1): Qwen2RMSNorm((0,), eps=1e-06)
(norm2): Qwen2RMSNorm((0,), eps=1e-06)
(attn): Qwen2_5_VLVisionFlashAttention2(
(qkv): Linear(in_features=1280, out_features=3840, bias=True)
(proj): Linear(in_features=1280, out_features=1280, bias=True)
)
(mlp): Qwen2_5_VLMLP(
(gate_proj): Linear(in_features=1280, out_features=3420, bias=True)
(up_proj): Linear(in_features=1280, out_features=3420, bias=True)
(down_proj): Linear(in_features=3420, out_features=1280, bias=True)
(act_fn): SiLU()
)
)
)
(merger): Qwen2_5_VLPatchMerger(
(ln_q): Qwen2RMSNorm((0,), eps=1e-06)
(mlp): Sequential(
(0): Linear(in_features=5120, out_features=5120, bias=True)
(1): GELU(approximate='none')
(2): Linear(in_features=5120, out_features=2048, bias=True)
)
)
)
(model): Qwen2_5_VLModel(
(embed_tokens): Embedding(151936, 2048)
(layers): ModuleList(
(0-35): 36 x Qwen2_5_VLDecoderLayer(
(self_attn): Qwen2_5_VLFlashAttention2(
(q_proj): Linear(in_features=2048, out_features=2048, bias=True)
(k_proj): Linear(in_features=2048, out_features=256, bias=True)
(v_proj): Linear(in_features=2048, out_features=256, bias=True)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): Qwen2_5_VLRotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=2048, out_features=11008, bias=False)
(up_proj): Linear(in_features=2048, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((0,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((0,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((0,), eps=1e-06)
(rotary_emb): Qwen2_5_VLRotaryEmbedding()
)
(lm_head): Linear(in_features=2048, out_features=151936, bias=False)
)