1、列表
1.1 概念
格式: 名称 = [ “元素1”,“元素2”,…]
#定义一个列表
computer = ["主机","键盘","显示器","鼠标"]
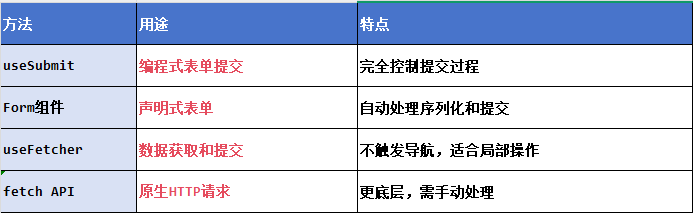
| 类型 | 方法 | 用途 |
|---|---|---|
| 查 | index(“元素”) | 查看元素索引位置 |
| count(“元素”) | 统计元素出现的次数 | |
| reverse() | 倒序排序元素 | |
| sort | 进行排序 | |
| 增 | append(“元素”) | 追加一个元素 |
| insert(index,“元素”) | 在指定索引位置插入一个元素 | |
| 改 | computer[index] = “元素” | 修改指定索引的值 |
| 删除 | remove(“元素”) | 删除指定的元素 |
| pop(index=-1) | 通过索引删除元素并返回索引 |
1.2 习题
1.2.1 定义一个列表并打印出列表里的元素
#1、创建一个列表,命名为names,往里面添加陈贤贤、大财神、飞鱼、WuYing、阿阳和Black元素
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
print(names)
1.2.2 引用列表的长度拼接字符串
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
print('我建立的学习群有',len(names),'个学生在微信群里面') #6的前后有空格
print('我建立的学习群有'+str(len(names))+'个学生在微信群里面') #6的前后没有空格
1.2.3 引用列表里面的变量拼接字符串
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
print("我们班的班花叫:",names[2])
print("我们班的班花叫:"+ str(names[2]))
注意:拼接字符串引用列表里面的元素时,默认元素前时有空格的,如果不需要空格使用+str转换,此时就不需要使用逗号隔开
1.2.3 往列表中添加两个元素
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
names.insert(2,["老男孩,老女孩"])
print(names)
1.2.4改变列表中的某一个元素名称
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
names[names.index("WuYing")] = "吴莹"
print(names)
#方法二:
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
names[3] = "吴莹"
print(names)
1.2.5返回列表中元素的位置(索引值)
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
print(names.index("飞鱼"))
1.2.6 合并列表(使用extend)
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
numbers = [1,2,3,4,5,6,2,5,4]
names.extend(numbers)
print(names)
1.2.7 取出列表中指定的元素
1、取出names列表中索引4-7的元素
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
numbers = [1,2,3,4,5,6,2,5,4]
names.extend(numbers)
print(names[4:8]) #包含第七个元素
2、取出names列表中索引2-10的元素,步长为2
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
numbers = [1,2,3,4,5,6,2,5,4]
names.extend(numbers)
print(names[2:11:2])
1.2.8 打印特定索引值和元素
1、循环names列表,打印每个元素的索引值和元素。
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
for i in names:
print(names.index(i),i)
2、enumerate()枚举
names = ["陈贤贤","大财神","飞鱼","WuYing","阿阳","Black"]
for index,i in enumerate(names):
print(index,i)
3、names列表里有3个2,请返回第二个2的索引值,不要人肉,要动态找
names = ["陈贤贤", "大财神", "飞鱼", "WuYing", "阿阳", "Black", 1, 2, 3, 4, 2, 5, 6, 2]
print(names.index(2, names.index(2)+1))
1.2.9 商品列表
products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
print("------ 商品列表 ------ ")
for index,i in enumerate(products):
print("%s %s %s" % (index, i[0],i[1]))

1.2.10 根据products列表写一个循环,不断询问用户想买什么,用户选择一个商品编号,就把对应的商品添加到购物车里,最终用户输入q退出时,打印购买的商品列表
products = [["iphone", 6888], ["MacPro", 14800], ["小米6", 2499], ["Coffee", 31], ["Book", 60], ["Nike", 699]]
shop_car = [] #用户购物车
shop_cost = 0 #用户花费金额
exit_log = False #标志位
while not exit_log:
print("------ 商品列表 ------")
for index,i in enumerate(products):
print("%s %s %s" %(index,i[0],i[1]))
use_choice = input("\n输入你想购买的产品序列号(按q退出):")
if use_choice.isdigit(): #判断用户输入的是否是数字
use_choice = int(use_choice)
if use_choice >=0 and use_choice < len(products):
shop_car.append(products[use_choice]) #加入购物车
shop_cost += products[use_choice][1] #计算费用
print("\n %s 已经加入你的购物车\n"%products[use_choice])
else:
print("抱歉,此商品不存在\n")
elif use_choice == "q":
# 用户选择退出
if len(shop_car) > 0:
# 判断用户是否购买了商品
print("\n------ 你的购物车 ------")
for index, i in enumerate(shop_car):
# index和i为临时变量,与前一个for循环里index和i作用的列表不同,故可重用
print("%s %s" % (i[0], i[1]))
print("\n你此次购物的花费合计是:%s元\n" % shop_cost)
exit_log = True # 退出购物
else:
exit_log = True # 未购买商品,不打印购物车商品,直接退出
else:
# 输入不合法
exit_log = True
1.2.11 删除列表元素
names = ["陈贤贤", "大财神", "飞鱼", "WuYing", "阿阳", "Black"]
names.remove('飞鱼')
print(names)
2、元组
2.1 概念
元组:与列表相似,也是一个序列数据结构。主要区别在于元组中的元素不能修改
格式:名称 = (“a”,“b”,“c”,…)
#定义一个元组
computer = ("主机","显示器","鼠标","键盘")
print(computer)
2.2 综合案例
students = (
("alice",85),
("bob",99),
("david",78)
)
#1. 访问元组中的数据
print("学生名单以及成绩如下:")
for student_sheet in students:
name,sore = student_sheet
print(f"{name}的成绩是{sore}")
# 2. 计算总成绩和平均成绩
total_sore = 0 #初始化总成绩
for student_sheet in students:
total_sore += int(student_sheet[1])
average_sore = int(total_sore / len(students))
print("班级总成绩:"+ str(total_sore))
print("班级平均成绩:",average_sore)
#创建新的元组,代表新的学生
new_student = ("Frank", 90)
students = students + (new_student,)
print(students)
注意:元组里面元素的内容是不可逆的,无法修改的
3、集合
3.1概念
集合是一个无序、不重复的元素序列,主要用于元素去重和关系测试
关系测试支持:
- 联合
- 交集
- 差集
- 对称差集
格式: 名称 = {“a”,“b”,…}或者 名称 = set([“a”,“b”,“…”])
#定义一个集合
computer = ["主机","显示器","鼠标","键盘","显示器","鼠标"]
com = set(computer)
print(com)
3.2案例
# 创建一个字典来管理学生选课信息
students_courses = {
"alice": {"math", "english", "science"},
"bob": {"math", "history"},
"charlie": {"science", "art"},
"david": {"math", "science", "art"},
}
# 函数:添加课程
def add_course(student, course):
if student in students_courses:
students_courses[student].add(course)
print(f"{student} 已添加课程: {course}")
else:
print(f"学生 {student} 不存在。")
# 函数:删除课程
def remove_course(student, course):
if student in students_courses:
if course in students_courses[student]:
students_courses[student].remove(course)
print(f"{student} 已删除课程: {course}")
else:
print(f"{student} 没有选修课程: {course}")
else:
print(f"学生 {student} 不存在。")
# 函数:查看某位学生已选课程
def view_courses(student):
if student in students_courses:
print(f"{student} 已选课程: {students_courses[student]}")
else:
print(f"学生 {student} 不存在。")
# 函数:计算选修同一课程的学生
def students_in_course(course):
enrolled_students = {student for student, courses in students_courses.items() if course in courses}
return enrolled_students
# 函数:计算选修所有课程的学生
def all_students_in_courses():
all_courses = set()
for courses in students_courses.values():
all_courses.update(courses)
return all_courses
# 测试添加课程
add_course("alice", "art")
add_course("bob", "science")
# 测试删除课程
remove_course("charlie", "art")
remove_course("david", "math")
# 查看学生已选课程
view_courses("alice")
view_courses("bob")
# 计算选修同一课程的学生
course_to_check = "math"
enrolled_students = students_in_course(course_to_check)
print(f"选修 {course_to_check} 的学生有: {enrolled_students}")
# 计算所有选修的课程
all_courses = all_students_in_courses()
print(f"所有选修的课程有: {all_courses}")
4、字典
4.1概念
字典:是一个具有映射关系的键值对的数据结构。用于存储有一定关系的元素
格式: d = {‘key1’:value1,“key2”:value2,…}
注意:字典通过key来访问value,因此字典中的key不允许重复
#定义字典
computer = {"主机":5000,"鼠标":1000}
| 类型 | 方法 | 用途 |
|---|---|---|
| computer[“key”] | 获取字典key的值 | |
| 查 | computer.get(“key”,None) | 获取字典keyd的值,如果不存在返回None |
| keys() | 获取所有键 | |
| values() | 获取所有键的值 | |
| items() | 获取所有键值 | |
| 增 | computer[“key”] = value | 添加键值,如果键存在则覆盖 |
| update(“key”) | 添加新字典 | |
| setdefault(“key”,default=None) | 如果键不存在,添加键并将值设置默认值,如果键存在返回值 | |
| 删 | pop(“key”) | 删除指定键 |
| computer.popitem() | 删除最后一对键值并返回 |
4.2 综合案例
# 创建一个学生成绩字典
students_scores = {
"alice": {"math": 85, "english": 78, "science": 92},
"bob": {"math": 90, "english": 88, "science": 95},
"charlie": {"math": 70, "english": 80, "science": 85}
}
# 函数:添加新学生的成绩
def add_student(name, scores):
if name in students_scores:
print(f"学生 {name} 已存在,更新其成绩。")
students_scores[name] = scores
# 函数:更新学生的某一科目成绩
def update_score(name, subject, score):
if name in students_scores and subject in students_scores[name]:
students_scores[name][subject] = score
print(f"{name} 的 {subject} 成绩已更新为 {score}。")
else:
print(f"学生 {name} 或科目 {subject} 不存在。")
# 函数:删除学生
def delete_student(name):
if name in students_scores:
del students_scores[name]
print(f"学生 {name} 已被删除。")
else:
print(f"学生 {name} 不存在。")
# 函数:打印所有学生及其成绩
def print_all_scores():
for student, scores in students_scores.items():
print(f"{student} 的成绩:")
for subject, score in scores.items():
print(f" {subject}: {score}")
print()
# 函数:计算某一学生的平均成绩
def calculate_average(name):
if name in students_scores:
scores = students_scores[name].values()
average = sum(scores) / len(scores)
print(f"{name} 的平均成绩是:{average:.2f}")
else:
print(f"学生 {name} 不存在。")
# 添加新学生
add_student("david", {"math": 88, "english": 76, "science": 90})
# 更新成绩
update_score("alice", "math", 90)
# 删除学生
delete_student("charlie")
# 打印所有学生成绩
print_all_scores()
# 计算某一学生的平均成绩
calculate_average("bob")
calculate_average("david")

![[蓝桥杯]耐摔指数](https://i-blog.csdnimg.cn/direct/f60af2b1ddd74bf7b0a91fbd05379bfe.png)