前言
最近赶上AI的热潮,很多业务都在接入AI大模型相关的接口去方便的实现一些功能,后端需要做的是接入AI模型接口,并整合成流式输出到前端,下面有一些经验和踩过的坑。
集成
Spring WebFlux是全新的Reactive Web技术栈,基于反应式编程,很适合处理我们需求的流式数据。
依赖
只需要下面这一个依赖即可,但是需要助力springboot父版本,不同的版本在相关的API实现上面有些许的差别。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
代码
这边我在controller写了一个测试代码,意思是每秒产生一段json数据,一共10次,需要注意,响应头一定要设置text/event-stream 这个值,标志着是流式输出
@GetMapping(path = "/test/chat", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> chatTest() {
//chat交互测试
return Flux.interval(Duration.ofSeconds(1)).take(10).map(sequence -> "{" + " \"data\": \"33\"," + " \"count\": \"" + sequence + "\"" + "}");
}
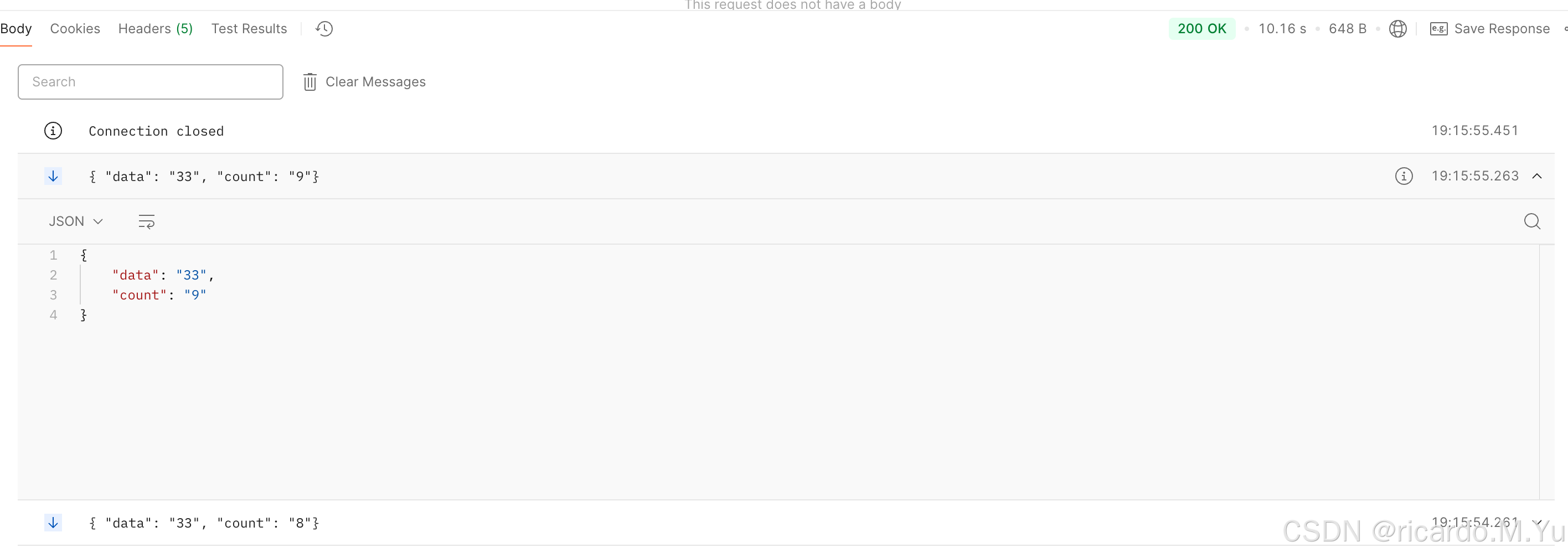
postman 调用接口测试下,正常返回数据了
后端集成AI大模型
在实际业务中,基本上都是后端来调用 deepseek,再返回给前端,下面大概是集成
public Flux<ServerSentEvent<ObjectNode>> chat() {
WebClient webClient = WebClient.create();
String url = "大模型url链接";
return webClient.post()
.uri(url)
.header("Accept", "text/event-stream")
.body(BodyInserters.fromObject(reqNode)) // 注意高版本的API 可以直接用 bodyValue()
.retrieve()
.bodyToFlux(new ParameterizedTypeReference<ServerSentEvent<ObjectNode>>() {
}).log()
.onBackpressureBuffer()
.doOnError(throwable -> {
//错误处理
log.error("chat request error -> {}", throwable.getMessage());
throw new RuntimeException("request error -> " +throwable.getMessage());
}).doOnNext(v -> {
//每次输出流处理
log.info("received chat message: {}", v);
}).doOnComplete(() -> {
//流输出完成处理
});
一些错误解决
reactor.core.Exceptions$OverflowException: Could not emit buffer due to lack of requests
报错是由于发布者(Publisher)尝试以比订阅者(Subscriber)请求速率更快的速度推送数据时。这种情况违反了 Reactive Streams 的背压(Backpressure)机制,导致异常抛出。导致流异常终止。
在上面请求时加上了 .onBackpressureBuffer() 用缓冲机制解决