大语言模型预备数学知识
复习一下在大语言模型中用到的矩阵和向量的运算,及概率统计和神经网络中常用概念。
矩阵的运算
矩阵

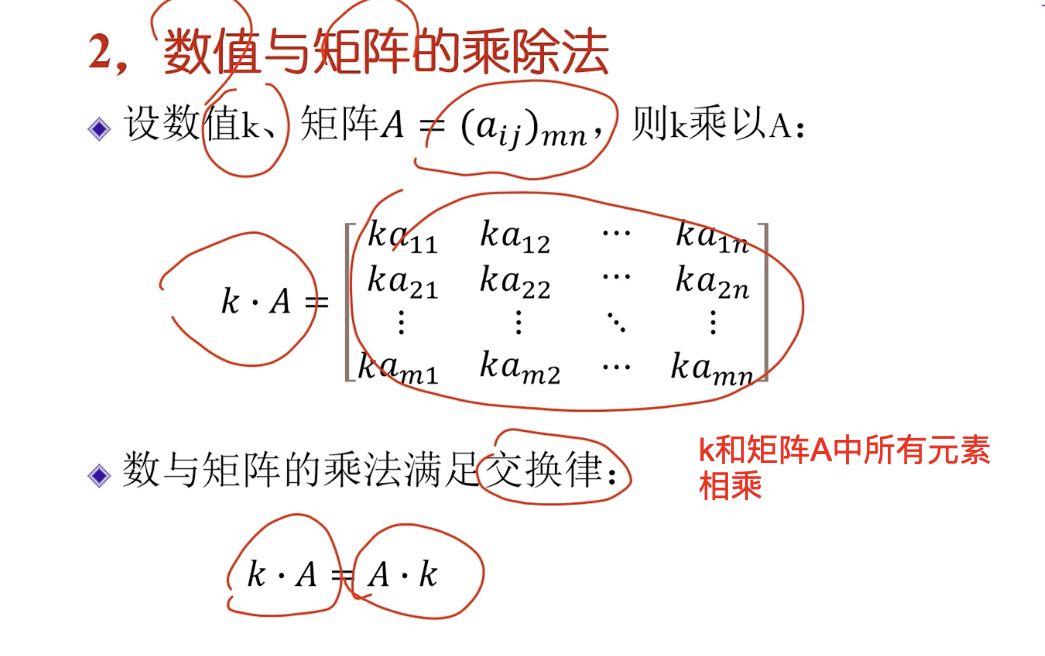
矩阵加减法
条件:行数列数相同的矩阵才能做矩阵加减法
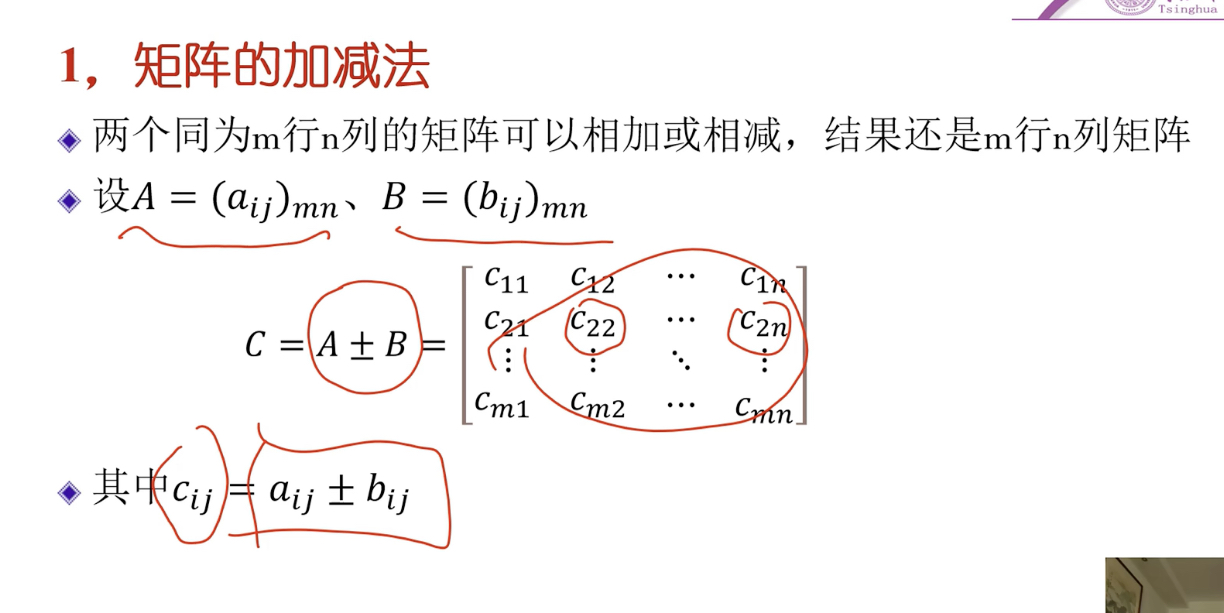
数值与矩阵的乘除法

矩阵乘法
条件:矩阵A的列数 = 矩阵B的行数时, A才能乘B
因为矩阵乘法是前一个矩阵各行中各个元素乘后一个矩阵各列中对于元素,所以要求矩阵A的列数 = 矩阵B的行数。

矩阵乘法性质

矩阵的转置
转置:矩阵所有的行按顺序变成列

转置的性质

向量的运算
向量
本博客后续,默认用行向量来表示默认向量

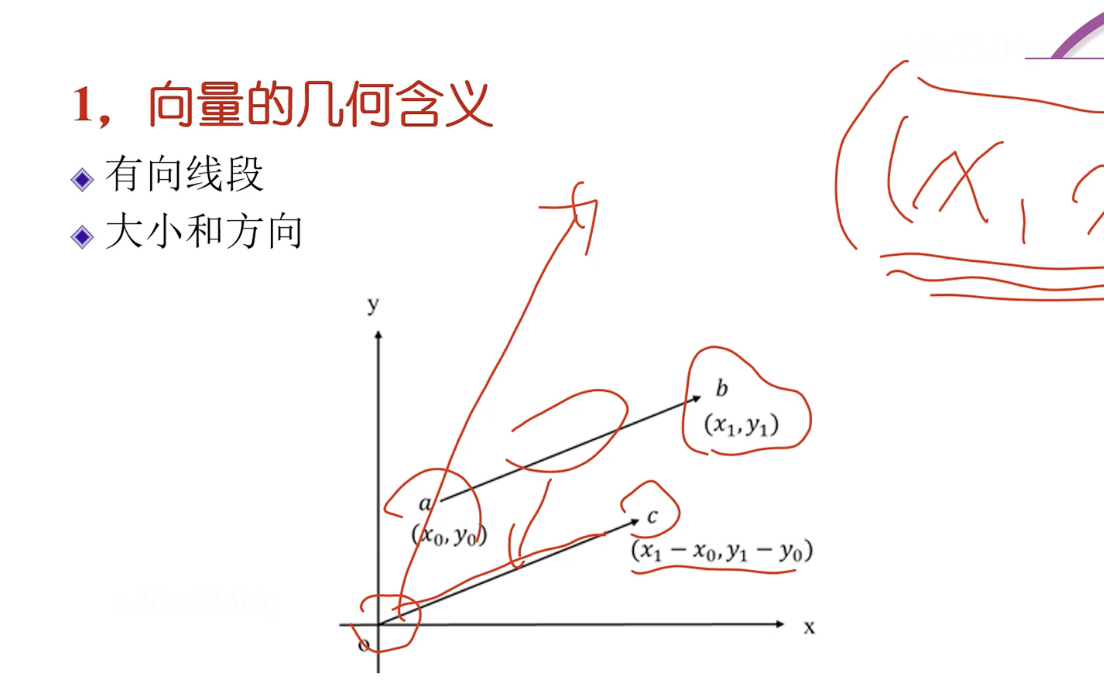
向量的几何意义
起点在坐标原点,终点在坐标数值的向量
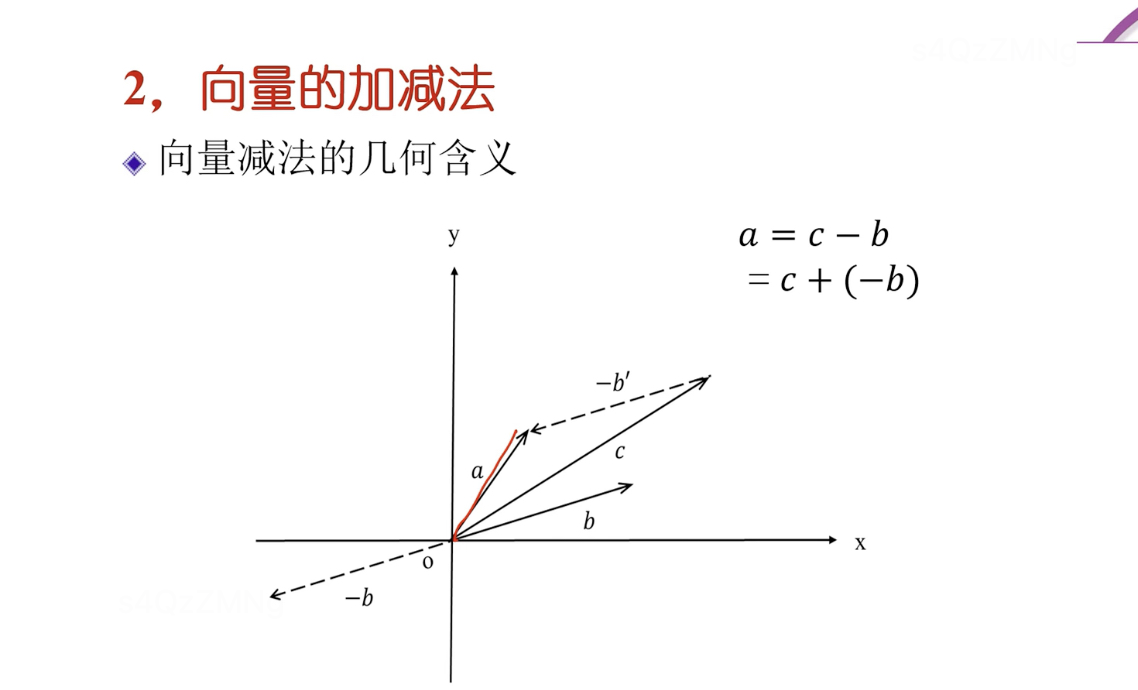
向量的加减法
条件:向量a,b的元素的个数相同

向量加法,以零点为起点,以b’终点为终点的向量(b’的起点为a的终点)。减法就相当于 加 负向量
数值与向量的乘除法
a向量乘2,表示对a向量伸长了两倍。

向量的乘法
向量乘法是向量的点积运算,又称内积
点积:行向量乘列向量,结果为标量

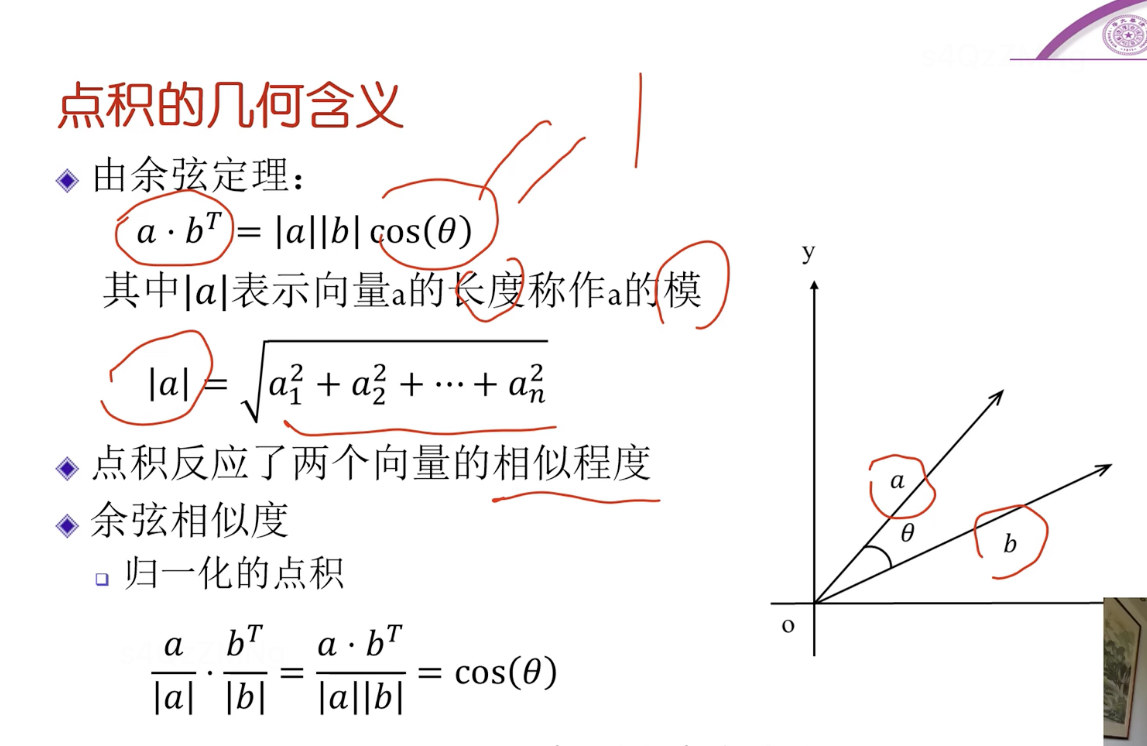
点积点几何含义(常用)
反映了两个向量相似程度,当两个向量方向一致时,夹角为0,cos夹角 = 1,两向量长度不变则此时两向量的点积最大,表示两向量此时最相似。
但点积的大小也跟向量a,b的长度有关,所以可以进行归一化,即分别对每个向量除各自的长度(模),称为余弦相似度。(归一化了,就跟具体的向量长度没关系了,其值完全反映两个向量的相似性)
矩阵和向量的乘法
向量(指行向量)右乘矩阵(矩阵在右边),条件:矩阵行数与向量元素个数相等。相乘结果为一个行向量,其元素个数为矩阵的列数。

向量(指列向量)左乘矩阵(矩阵在左边),条件:矩阵列数与向量元素个数相等。相乘结果为一个列向量,其元素个数为矩阵的行数。

矩阵和向量的乘法的几何意义
向量右乘矩阵的几何意义
- 相似性角度

- 空间变换角度,表示对向量的旋转操作
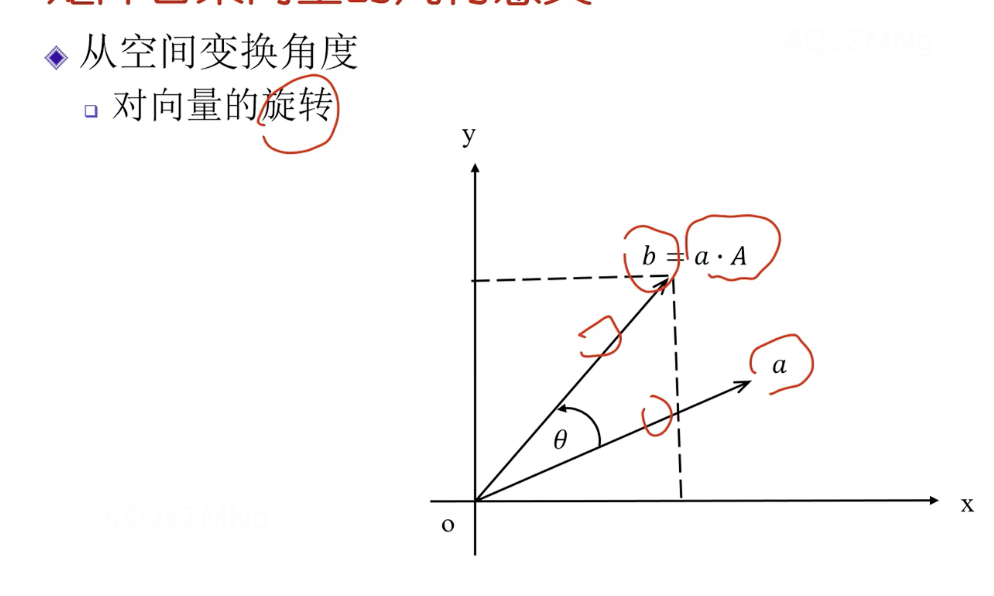
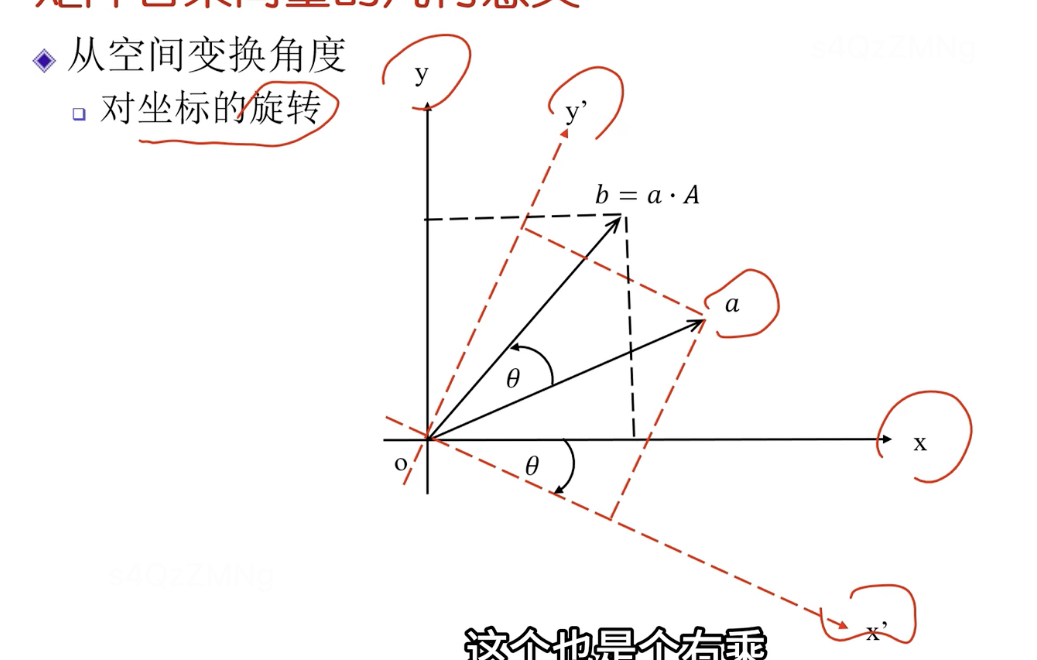
a在新坐标系中的坐标
概率
数学期望与方差

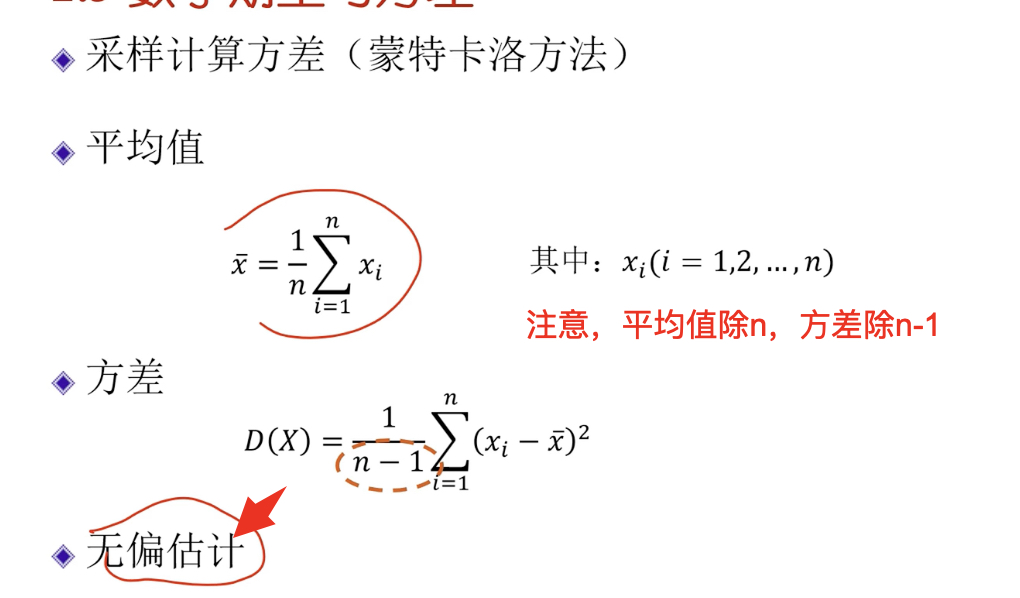
数学期望:离散型随机变量每个可能的取值,与该取值对应的概率相乘,统一相加的结果,反映取值的平均值


蒙特卡洛方法(通过采样的方法)
即计算数学期望值的时候,通过采样计算平均值的方式去近似(蒙特卡洛方法)。
为什么?因为我们不知道每种概率是多少,就通过采样的办法去近似,当采样数量足够多时,采样平均值就可被认为数学期望。


数学期望的性质


最后一条性质指,随机变量x,任何可能都>=0,则数学期望>=0
方差


计算方差的过程
如何理解评价值除n,方差除n-1。因为前面求平均值时除n,知道了n个数中n-1个就可以把第n个算出来,它们之间有一定相关性。除n-1得到的才是无偏估计。
举例

方差的性质

马尔可夫过程
马尔可夫过程是一个随机过程,且未来的发展只与当前状态有关,而跟之前的状态无关。一般来说都是一种近似的结果,通过近似来简化计算。
一般的随机过程
X(t)的取值称为随机过程在时间t的状态

马尔可夫过程

神经网络与深度学习
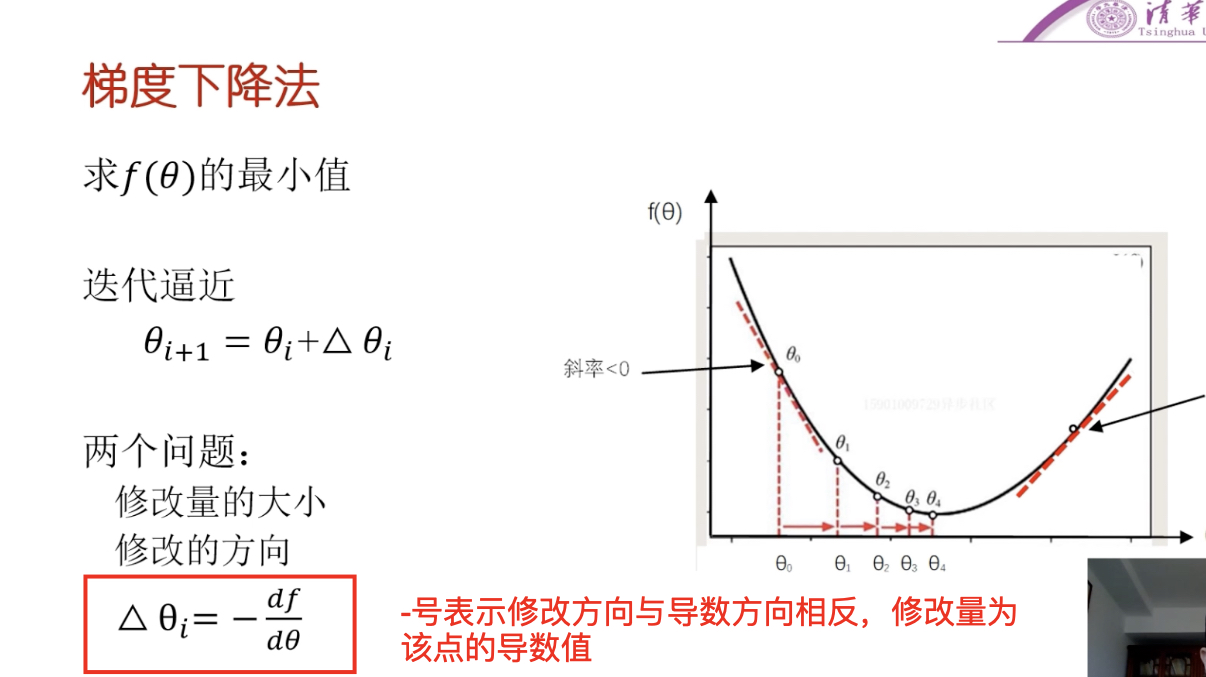
梯度下降
方向:如果斜率(导数)>0,则x减;如果斜率(导数)<0,则x加(即修改的方向跟导数的方向相反)
大小:离最低点(最优值)远时,比较陡(导数绝对值越大越陡)—导数绝对值越大,修改量越大。
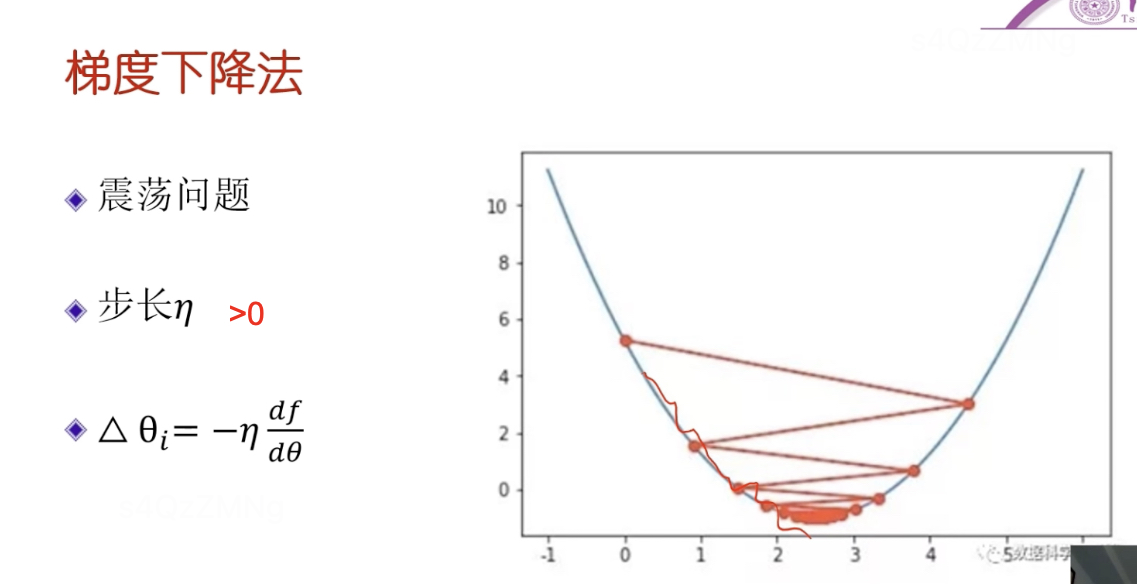
震荡问题,因为导数趋于∞时,会导致震荡, 引入一个大于0的常量步长,防止震荡很大,使其一步步过来。
在神经网络中因为参数量很大所以用偏导数

导数反映某一处切线斜率,梯度表示在曲线中的某个切平面的斜率。梯度下降核心思想:沿着梯度的反方向,看那个地方下降最快,沿最陡峭地方往下走,一点点找到最优值。
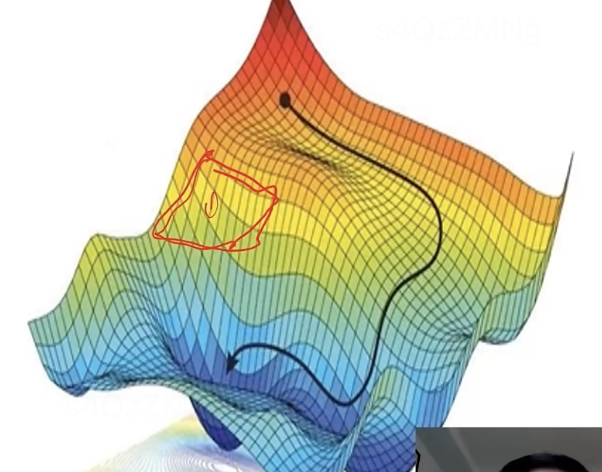
常见梯度下降算法

欢迎各位读者点赞评论收藏,本人后续也会对这块基础数学知识进行进一步更新