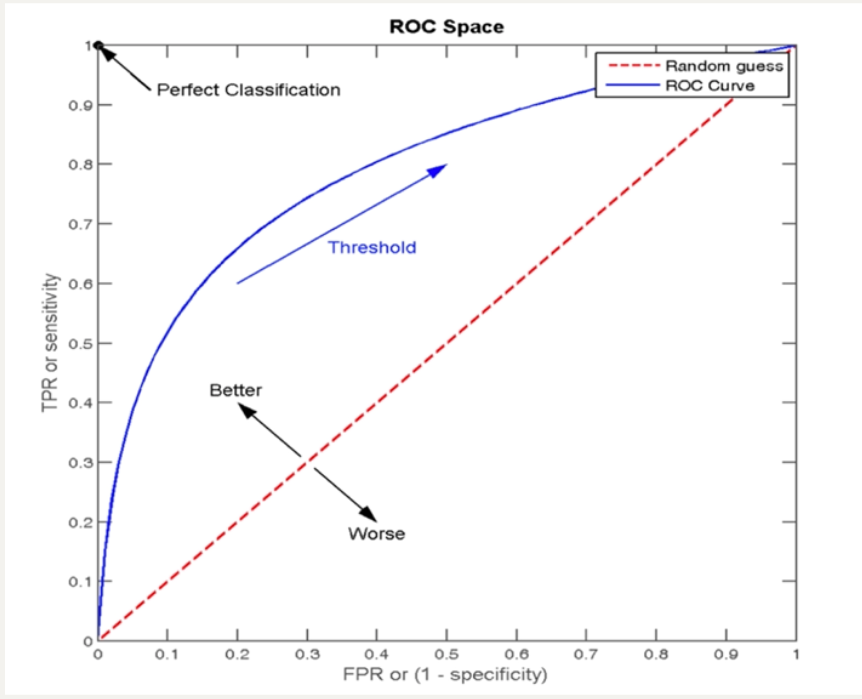
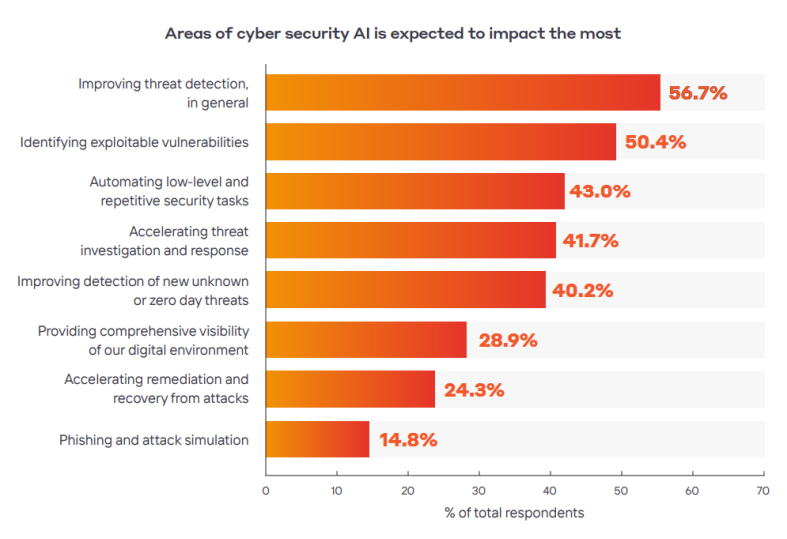
我们都知道Scrapy是一个用于爬取网站数据、提取结构化数据的Python框架。在Scrapy中,Spiders是用户自定义的类,用于定义如何爬取某个(或某些)网站,包括如何执行爬取(即跟踪链接)以及如何从页面中提取结构化数据(即爬取项)。至于如何定义Spiders爬虫逻辑和规则可以看看我下面总结的经验。

Scrapy 是一个强大的 Python 爬虫框架,其核心组件 Spiders 用于定义爬取逻辑和数据提取规则。下面是一个详细的结构解析和示例:
一、Scrapy Spider 核心组件
- 类定义:继承
scrapy.Spider或其子类 - 必要属性:
name:爬虫唯一标识符start_urls:初始爬取 URL 列表
- 核心方法:
parse(self, response):默认回调函数,处理响应并提取数据
- 可选扩展:
- 自定义设置(
custom_settings) - 链接跟踪规则(
CrawlSpider)
- 自定义设置(
二、基础 Spider 示例
import scrapy
class BookSpider(scrapy.Spider):
name = "book_spider"
start_urls = ["http://books.toscrape.com/"]
def parse(self, response):
# 提取书籍列表页数据
for book in response.css("article.product_pod"):
yield {
"title": book.css("h3 a::attr(title)").get(),
"price": book.css("p.price_color::text").get(),
"rating": book.css("p.star-rating::attr(class)").get().split()[-1]
}
# 跟踪下一页
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)
三、进阶 CrawlSpider 示例(自动链接跟踪)
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class AdvancedSpider(CrawlSpider):
name = "crawl_spider"
allowed_domains = ["example.com"]
start_urls = ["http://www.example.com/catalog"]
# 定义链接提取规则
rules = (
# 匹配商品详情页(回调函数处理)
Rule(LinkExtractor(restrict_css=".product-item"), callback="parse_item"),
# 匹配分页链接(无回调默认跟随)
Rule(LinkExtractor(restrict_css=".pagination"))
)
def parse_item(self, response):
yield {
"product_name": response.css("h1::text").get(),
"sku": response.xpath("//div[@class='sku']/text()").get(),
"description": response.css(".product-description ::text").getall()
}
四、关键功能解析
| 组件 | 作用 |
|---|---|
response.css() | 用 CSS 选择器提取数据(推荐 ::text/::attr(xxx)) |
response.xpath() | XPath 选择器,处理复杂结构 |
response.follow() | 自动处理相对 URL 的请求生成 |
LinkExtractor | 自动发现并跟踪链接,支持正则/CSS/XPath 过滤 |
custom_settings | 覆盖全局配置(如:DOWNLOAD_DELAY, USER_AGENT) |
五、最佳实践
-
数据管道:
- 在
pipelines.py中定义数据清洗/存储逻辑 - 在
settings.py启用管道:ITEM_PIPELINES
- 在
-
中间件:
-
下载中间件处理请求头/代理/IP轮换
-
示例代理中间件:
class ProxyMiddleware: def process_request(self, request, spider): request.meta["proxy"] = "http://proxy_ip:port"
-
-
防反爬策略:
- 随机 User-Agent:
scrapy-fake-useragent库 - 自动限速:
AUTOTHROTTLE_ENABLED = True
- 随机 User-Agent:
六、运行与调试
-
启动爬虫:
scrapy crawl book_spider -o books.json -
Shell 调试:
scrapy shell "http://books.toscrape.com" >>> response.css('h1::text').get()
七、常见问题解决
- 403 禁止访问:添加合法
USER_AGENT - 数据缺失:检查目标页面动态加载(需启用
scrapy-splash或selenium中间件) - 重复 URL:启用去重中间件
DUPEFILTER_CLASS
如果掌握上面这些核心模式后,大体上就可以灵活应对各类网站爬取需求。但是也要建议多结合Scrapy 官方文档多多学习。