提示:线程相关面试题,持续更新中
文章目录
- 一、Java线程池
- 1、Java线程池有哪些核心参数,分别有什么的作用?
- 2、线程池有哪些拒绝策略?
- 3、说一说线程池的执行流程?
- 4、线程池核心线程数怎么设置呢?
- 4、Java线程池中submit()和execute()方法有什么区别?
- 二、ThreadLocal
- 1、请介绍一下ThreadLocal底层是怎么实现的?
- 2、ThreadLocal为什么会内存泄漏?
- 三、Thread
- 1、请说说sleep()和wait()有什么区别?
- 2、多个线程如何保证按顺序执行?
一、Java线程池
1、Java线程池有哪些核心参数,分别有什么的作用?
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
8,
16,
60,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(1024),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy()
);
构造方法最多的是7个参数:
(1)int corePoolSize : 线程池中的核心线程数量
allowCoreThreadTimeOut:允许核心线程超时销毁,默认false(不销毁);
boolean prestartCoreThread(),初始化一个核心线程;
int prestartAllCoreThreads(),初始化所有核心线程;
(2)int maximumPoolSize : 线程池中允许的最大线程数
当核心线程全部繁忙且任务队列存满之后,线程池会临时追加线程,直到总线程数达到maximumPoolSize这个上限;
(3)long keepAliveTime :线程空闲超时时间
如果一个非核心线程处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁;
(4)TimeUnit unit :keepAliveTime的时间单位
(天、小时、分、秒......);
(5)BlockingQueue<Runnable> workQueue :任务队列
当核心线程全部繁忙时,任务存放到该任务队列中,等待被核心线程来执行;
(6)ThreadFactory threadFactory :线程工厂
用于创建线程,一般采用默认的线程工厂即可,也可以自定义实现;
Executors.defaultThreadFactory():推荐使用,
Executors.privilegedThreadFactory():已过时,不推荐使用,
(7)RejectedExecutionHandler handler :拒绝策略(饱和策略)
当任务太多来不及处理时,如何“拒绝”任务?
“拒绝”触发条件:
1、核心线程corePoolSize正在执行任务;
2、线程池的任务队列workQueue已满;
3、线程池中的线程数达到maximumPoolSize时;
就需要“拒绝”掉新提交过来的任务;
2、线程池有哪些拒绝策略?
JDK提供了4种内置的拒绝策略:AbortPolicy、CallerRunsPolicy、DiscardOldestPolicy和DiscardPolicy;
1、AbortPolicy(默认):丢弃任务并抛出RejectedExecutionException异常,这是默认的拒绝策略;
2、DiscardPolicy:直接丢弃任务,不抛出异常,没有任何提示;
3、DiscardOldestPolicy:丢弃任务队列中靠最前的任务,当前提交的任务不会丢弃;
4、CallerRunsPolicy: 交由任务的调用线程(提交任务的线程)来执行当前任务;
除了上面的四种拒绝策略,还可以通过实现RejectedExecutionHandler接口,实现自定义的拒绝策略;
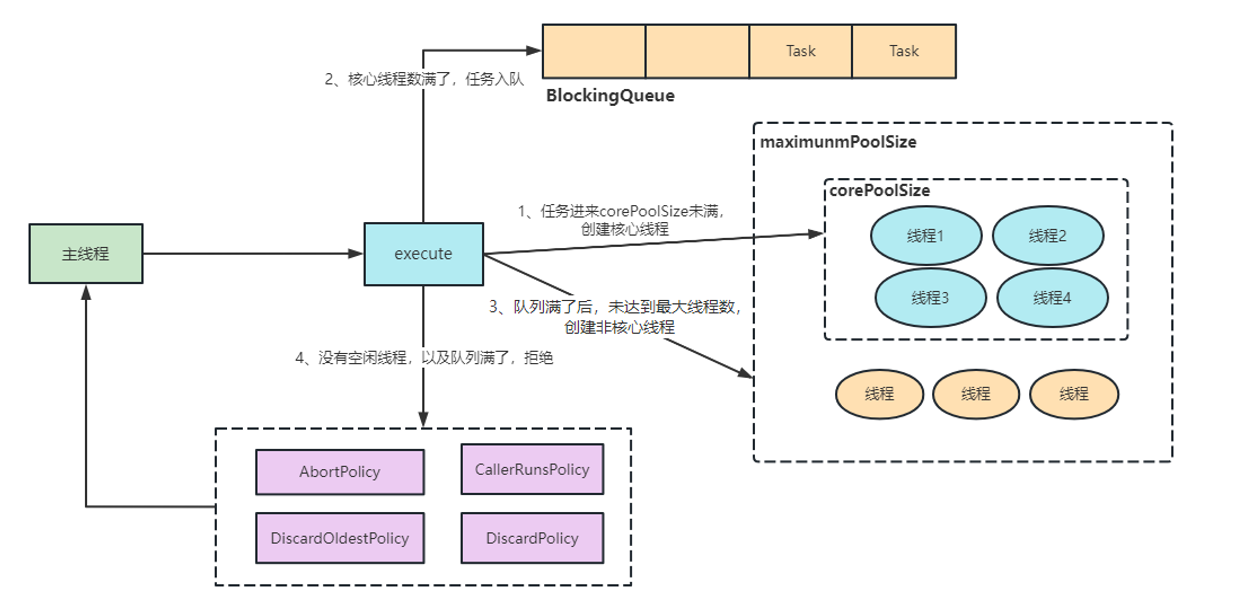
3、说一说线程池的执行流程?
当提交一个新任务到线程池时,具体的执行流程如下:
1. 当我们提交任务,线程池会根据corePoolSize大小创建线程来执行任务;
2. 当任务的数量超过corePoolSize数量,后续的任务将会进入阻塞队列阻塞排队;
3. 当阻塞队列也满了之后,那么将会继续创建(maximumPoolSize-corePoolSize)个数量的线程来执行任务,
如果任务处理完成,maximumPoolSize-corePoolSize个额外创建的线程等待 keepAliveTime之后被自动销毁;
4. 如果达到maximumPoolSize,阻塞队列还是满的状态,那么将根据不同的拒绝策略进行拒绝处理;
4、线程池核心线程数怎么设置呢?
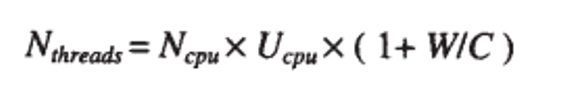
Ncpu = cpu的核心数 ,Ucpu = cpu的使用率(在0~1之间)
W = 线程等待时间,C = 线程计算时间
举例:
8 * 100% * (1+60/40) = 20
8 * 100% * (1+80/20) = 40
----------------------------------------------------------------------------------------------------------------------------
任务分为CPU密集型和IO密集型
CPU密集型
线程数 = CPU核心数 + 1;
这种任务主要是消耗CPU资源, 比如像加解密、压缩、计算等一系列需要大量耗费 CPU 资源的任务;
+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。
一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间;
IO密集型
线程数 = CPU核心数 * 2;
这种任务会有大部分时间在进行IO操作,比如像MySQL数据库、文件读写、网络通信等任务,这类任务不会特别消耗CPU资源,
但是IO操作比较耗时,会占用比较多时间;
线程在处理IO的时间段内不会占用CPU,这时就可以将CPU交出给其它线程使用,因此在IO密集型任务的应用中,可以多配置一些线程;
----------------------------------------------------------------------------------------------------------------------------
基本原则:
1、线程执行时间越多,就需要越少的线程;
2、线程等待时间越多,就需要越多的线程;
以上理论参考依据,实际项目中建议在本地或者测试环境进行压测多次调整线程池大小,找到相对理想的值大小;
4、Java线程池中submit()和execute()方法有什么区别?
1、 两个方法都可以向线程池提交任务;
2、 execute只能提交Runnable,无返回值;
3、 submit既可以提交Runnable,返回值为null,也可以提交Callable,返回值Future;
4、 execute()方法定义在Executor接口中;
5、 submit()方法定义在ExecutorService接口中;
6、 execute执行任务时遇到异常会直接抛出;
7、 submit执行任务时遇到异常不会直接抛出,只有在调用Future的get()方法获取返回值时,才会抛出异常;
-----------------------------------------------------------------------------------------------------------------------
Runnable和Callable都是用于定义线程执行任务的接口
特性 Runnable Callable
返回值 无(void) 有(泛型V)
异常处理 不能抛出受检异常 可以抛出受检异常
方法签名 void run() V call() throws Exception
使用场景 简单任务,无需结果 复杂任务,需要结果或异常处理
线程池集成 execute(Runnable) submit(Callable) + Future
功能扩展性 基础 支持任务取消、超时、结果获取
选择建议
使用Runnable:当任务简单、无需返回值且不涉及受检异常时。
使用Callable:当任务需要返回值、可能抛出异常或需要高级控制(如超时、取消)时。
二、ThreadLocal
1、请介绍一下ThreadLocal底层是怎么实现的?
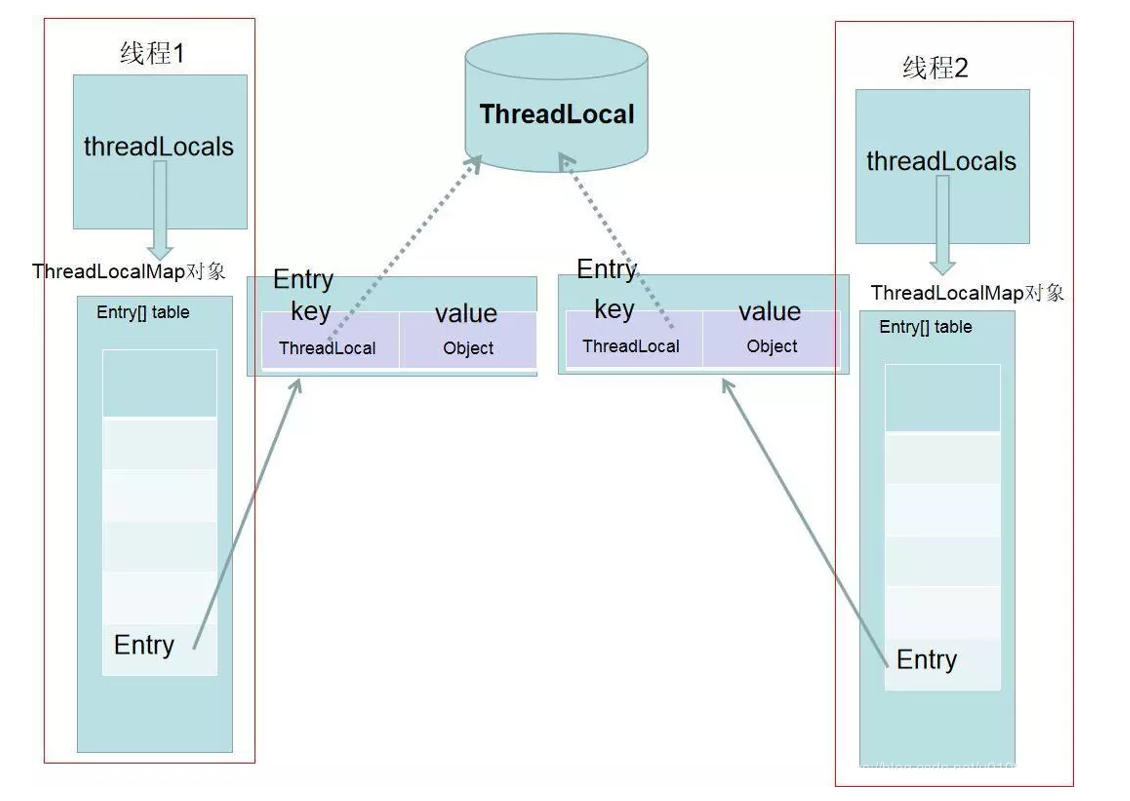
定义:
ThreadLocal 是 Java 中用于实现线程隔离存储的核心工具类,它为每个线程提供独立的变量副本,确保线程间数据互不干扰。
-------------------------------------------------------------------------------------------------------------------------
ThreadLocal是一个类似于HashMap的数据结构;
ThreadLocal的实现原理就是通过set把value set到线程的threadlocals属性中,threadlocals是一个Map,
其中的key是ThreadLocal的this引用,value是我们所set的值;
-------------------------------------------------------------------------------------------------------------------------
解释:
1、线程运行时,会生成ThreadLocalMap类型的名称为threadLocals的成员变量
2、ThreadLocalMap底层是Entry 数组
键值对存储:Entry[] 数组存储键值对,键为 ThreadLocal 对象,值为线程本地变量。
弱引用键:Entry 的键是弱引用(WeakReference<ThreadLocal<?>>),避免 ThreadLocal 实例无法被 GC 回收。
但值仍为强引用,需手动清理。
2、ThreadLocal为什么会内存泄漏?
一、内存泄漏的核心原因
1、弱引用键(Weak Key)的特性:
ThreadLocalMap 的 Entry 键是弱引用类型,指向 ThreadLocal 对象。
弱引用的特点:当 ThreadLocal 实例没有其他强引用时,GC 会回收它,但 Entry 的值(Value)仍被强引用持有。
2、值对象的强引用(Strong Value):
Entry 的值是强引用,指向用户存储的对象。
问题:即使 ThreadLocal 实例被 GC 回收,Entry 的值仍可能被线程长期持有(如线程池中的线程),导致值对象无法被释放。
二、内存泄漏的典型场景
1、线程长期存活:
线程池场景:线程被复用(如 ExecutorService),且未调用 ThreadLocal.remove()。
后果:Entry 的值对象一直被线程持有,无法被 GC 回收。
2、未调用 remove() 方法:
代码疏忽:在使用完 ThreadLocal 后,未显式调用 remove() 清理值。
后果:即使 ThreadLocal 实例被回收,值对象仍可能残留在 ThreadLocalMap 中。
三、内存泄漏的后果
1、内存占用增长:值对象无法被释放,导致堆内存占用持续增加。
2、OOM 风险:在极端情况下,可能引发 OutOfMemoryError(OOM)。
四、解决方案与最佳实践
1、显式调用 remove():
必须执行:在使用完 ThreadLocal 后,务必调用 remove() 清理值。
示例:
try {
threadLocal.set(value);
// ... 业务逻辑 ...
} finally {
threadLocal.remove(); // 确保清理
}
2、避免静态 ThreadLocal 变量:
风险:静态变量生命周期长,可能导致 ThreadLocalMap 长期存活。
替代方案:使用局部变量或依赖注入框架管理。
3、线程池场景的特殊处理:
自定义线程池:在任务执行前后清理 ThreadLocal。
使用 ThreadLocal 清理工具:如阿里开源的 TransmittableThreadLocal,支持线程池传递和清理。
4、依赖 GC 的局限性:
不要依赖 GC:虽然 ThreadLocalMap 在 set/get 操作时会扫描并清理部分过期 Entry(expungeStaleEntry),
但这种清理是启发式的,无法保证完全释放。
五、底层机制补充
1、ThreadLocalMap 的清理逻辑:
探测式清理:在 set/get 操作时,扫描 Entry 数组,发现键为 null 的 Entry,清除值并释放键。
启发式清理:以对数复杂度清理部分过期数据,平衡性能与内存。
2、为什么值不使用弱引用?
设计权衡:若值也使用弱引用,可能导致用户无意识丢失数据。
替代方案:通过 remove() 显式管理值的生命周期。
三、Thread
1、请说说sleep()和wait()有什么区别?
1. 所属类与方法签名
sleep():
属于Thread类。
方法签名:public static void sleep(long millis) throws InterruptedException。
是一个静态方法,作用于当前线程。
wait():
属于Object类。
方法签名:public final void wait() throws InterruptedException(还有其他重载方法,如wait(long timeout))。
是一个实例方法,必须通过对象调用。
2. 核心作用
sleep():
让当前线程暂停执行一段时间(以毫秒为单位)。
不释放锁:线程在睡眠期间仍持有对象锁或监视器锁。
用途:模拟延时、暂停线程执行(如轮询间隔、超时控制)。
wait():
让当前线程等待,释放对象锁,直到其他线程调用notify()或notifyAll()。
释放锁:线程在等待期间不再持有对象锁。
用途:多线程间协调,等待某个条件满足(如生产者-消费者模型)。
3. 线程状态变化
sleep():
线程进入TIMED_WAITING状态。
时间到后自动恢复执行。
wait():
线程进入WAITING(无超时)或TIMED_WAITING(有超时)状态。
必须由其他线程调用notify()/notifyAll()(或超时)才能恢复。
4. 锁的行为
sleep():
不释放锁:即使线程睡眠,其他线程仍无法获取该线程持有的锁。
wait():
释放锁:线程释放对象锁,允许其他线程竞争锁并执行同步代码块。
5. 唤醒机制
sleep():
自动唤醒:睡眠时间到后,线程自动恢复执行。
wait():
被动唤醒:必须由其他线程调用notify()(唤醒单个等待线程)或notifyAll()(唤醒所有等待线程)。
6. 使用场景
sleep():
简单延时(如定时任务、超时重试)。
示例:
try {
Thread.sleep(1000); // 睡眠1秒
} catch (InterruptedException e) {
e.printStackTrace();
}
wait():
多线程协作(如生产者-消费者模型)。
示例:
synchronized (lock) {
while (!condition) {
lock.wait(); // 等待条件满足
}
// 执行操作
}
| 特性 | sleep() | wait() |
|---|---|---|
| 所属类 | Thread | Object |
| 释放锁 | 否 | 是 |
| 唤醒方式 | 自动(时间到) | 被动(notify()/notifyAll()) |
| 线程状态 | TIMED_WAITING | WAITING/TIMED_WAITING |
| 典型用途 | 简单延时 | 多线程协作 |
| 是否静态方法 | 是 | 否(需通过对象调用) |
2、多个线程如何保证按顺序执行?
比如任务B,它需要等待任务A执行之后才能执行,任务C需要等待任务B执行之后才能执行;
解决方法:
1、通过join()方法使当前线程“阻塞”,等待指定线程执行完毕后继续执行;
2、通过创建单一化线程池newSingleThreadExecutor()实现;
3、通过倒数计时器CountDownLatch实现;
4、使用Object的wait/notify方法实现;
5、使用线程的Condition(条件变量)方法实现;
6、使用线程的CyclicBarrier(回环栅栏)方法实现;
7、使用线程的Semaphore(信号量)方法实现;
(1) 通过join()方法使当前线程“阻塞”,等待指定线程执行完毕后继续执行:
方法1:
public static void main(String[] args) throws Exception {
// t1线程
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t1");
// t2线程
Thread t2 = new Thread(() -> {
try {
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t2");
// t3线程
Thread t3 = new Thread(() -> {
try {
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t3");
t1.start();
t2.start();
t3.start();
}
---------------------------------------------------------------------------------------------------------------------------
方法2:
public static void main(String[] args) throws Exception {
// t1线程
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t1");
// t2线程
Thread t2 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t2");
// t3线程
Thread t3 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t3");
t1.start();
t1.join();
t2.start();
t2.join();
t3.start();
}
(2) 通过创建单一化线程池newSingleThreadExecutor()实现:
public class Test {
//自己手动创建单一化线程池(推荐使用)
private static final ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,
1,
0L,
TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy());
//创建单一化线程池(不建议使用Executors)
private static ExecutorService executorService = Executors.newSingleThreadExecutor();
public static void main(String[] args) throws Exception {
// t1线程
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " t1执行");
}, "t1");
// t2线程
Thread t2 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " t2执行");
}, "t2");
// t3线程
Thread t3 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " t3执行");
}, "t3");
threadPoolExecutor.execute(t1);
threadPoolExecutor.execute(t2);
threadPoolExecutor.execute(t3);
threadPoolExecutor.shutdown();
}
}
(3) 通过倒数计时器CountDownLatch实现:
public class Test {
/** 用于判断t1线程是否执行,倒计时设置为1,执行后减1 */
private static final CountDownLatch countDownLatch1 = new CountDownLatch(1);
/** 用于判断t2线程是否执行,倒计时设置为1,执行后减1 */
private static final CountDownLatch countDownLatch2 = new CountDownLatch(1);
public static void main(String[] args) throws Exception {
// t1线程
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName() + " 执行");
countDownLatch1.countDown(); // -1
}, "t1");
// t2线程
Thread t2 = new Thread(() -> {
try {
countDownLatch1.await(); //只有当 countDownLatch1 的计数器归零后,才会继续执行后续代码
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 执行");
countDownLatch2.countDown();
}, "t2");
// t3线程
Thread t3 = new Thread(() -> {
try {
countDownLatch2.await(); //只有当 countDownLatch2 的计数器归零后,才会继续执行后续代码
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " 执行");
}, "t3");
t1.start();
t2.start();
t3.start();
}
}







![NSSCTF [LitCTF 2025]test_your_nc](https://i-blog.csdnimg.cn/img_convert/b75c5494a84d2a4b9600afc6270dcf70.png)