原文链接:SpringAI(GA):RAG下的ETL源码解读
教程说明
说明:本教程将采用2025年5月20日正式的GA版,给出如下内容
- 核心功能模块的快速上手教程
- 核心功能模块的源码级解读
- Spring ai alibaba增强的快速上手教程 + 源码级解读
版本:JDK21 + SpringBoot3.4.5 + SpringAI 1.0.0 + SpringAI Alibaba 1.0.0.2
将陆续完成如下章节教程。本章是第六章(Rag增强问答质量)下的ETL-pipeline源码解读
代码开源如下:https://github.com/GTyingzi/spring-ai-tutorial

微信推文往届解读可参考:
第一章内容
SpringAI(GA)的chat:快速上手+自动注入源码解读
SpringAI(GA):ChatClient调用链路解读
第二章内容
SpringAI的Advisor:快速上手+源码解读
SpringAI(GA):Sqlite、Mysql、Redis消息存储快速上手
第三章内容
SpringAI(GA):Tool工具整合—快速上手
第五章内容
SpringAI(GA):内存、Redis、ES的向量数据库存储—快速上手
SpringAI(GA):向量数据库理论源码解读+Redis、Es接入源码
第六章内容
SpringAI(GA):RAG快速上手+模块化解读
SpringAI(GA):RAG下的ETL快速上手
获取更好的观赏体验,可付费获取飞书云文档Spring AI最新教程权限,目前49.9,随着内容不断完善,会逐步涨价。
注:M6版快速上手教程+源码解读飞书云文档已免费提供
ETL Pipeline 源码解析
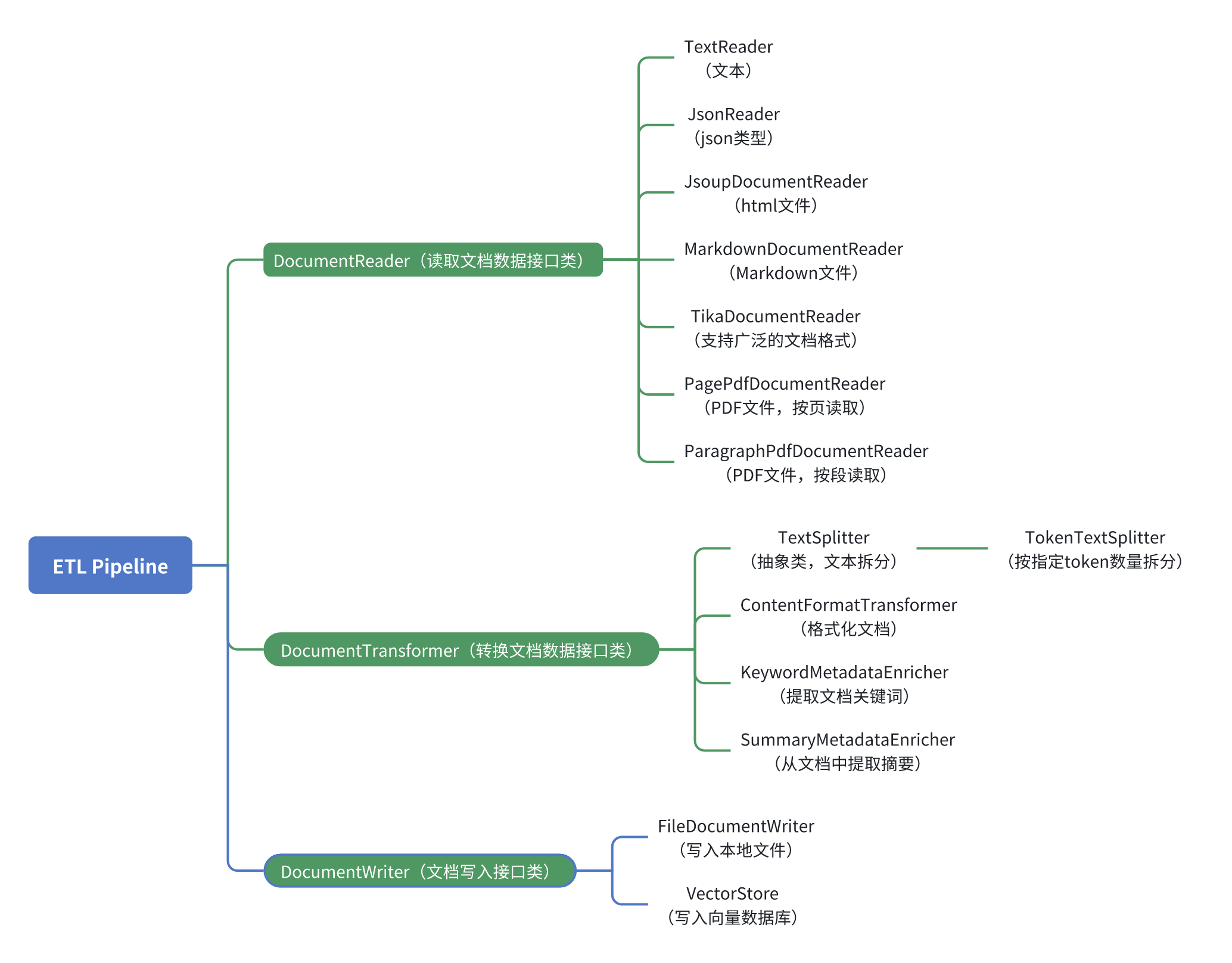
DocumentReader(读取文档数据接口类)
package org.springframework.ai.document;
import java.util.List;
import java.util.function.Supplier;
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return (List)this.get();
}
}
TextReader
用于从资源中读取文本内容并将其转换为 Document 对象
Resource resource:读取的资源Map<String, Object> customMetadata:存储与 Document 对象相关的元数据Charset charset:指定读取文本时使用的字符集,默认为 UTF8
方法说明
| 方法名称 | 描述 |
| TextReader | 通过资源URL、资源对象构造读取器 |
| setCharset | 设置读取文本时的字符集,默认为UTF8 |
| getCharset | 获取当前使用的字符集 |
| getCustomMetadata | 获取自定义元数据 |
| get | 读取文本,返回Document列表 |
| getResourceIdentifier | 获取资源的唯一标识(如文件名、URI、URL或描述信息) |
package org.springframework.ai.reader;
import java.io.IOException;
import java.net.URI;
import java.net.URL;
import java.nio.charset.Charset;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.util.StreamUtils;
public class TextReader implements DocumentReader {
public static final String CHARSETMETADATA = "charset";
public static final String SOURCEMETADATA = "source";
private final Resource resource;
private final Map<String, Object> customMetadata;
private Charset charset;
public TextReader(String resourceUrl) {
this((new DefaultResourceLoader()).getResource(resourceUrl));
}
public TextReader(Resource resource) {
this.customMetadata = new HashMap();
this.charset = StandardCharsets.UTF8;
Objects.requireNonNull(resource, "The Spring Resource must not be null");
this.resource = resource;
}
public Charset getCharset() {
return this.charset;
}
public void setCharset(Charset charset) {
Objects.requireNonNull(charset, "The charset must not be null");
this.charset = charset;
}
public Map<String, Object> getCustomMetadata() {
return this.customMetadata;
}
public List<Document> get() {
try {
String document = StreamUtils.copyToString(this.resource.getInputStream(), this.charset);
this.customMetadata.put("charset", this.charset.name());
this.customMetadata.put("source", this.resource.getFilename());
this.customMetadata.put("source", this.getResourceIdentifier(this.resource));
return List.of(new Document(document, this.customMetadata));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
protected String getResourceIdentifier(Resource resource) {
String filename = resource.getFilename();
if (filename != null && !filename.isEmpty()) {
return filename;
} else {
try {
URI uri = resource.getURI();
if (uri != null) {
return uri.toString();
}
} catch (IOException var5) {
}
try {
URL url = resource.getURL();
if (url != null) {
return url.toString();
}
} catch (IOException var4) {
}
return resource.getDescription();
}
}
}
JsonReader
用于从 JSON 资源中读取数据并将其转换为 Document 对象
Resource resource:表示要读取的 JSON 资源JsonMetadataGenerator jsonMetadataGenerator:用于生成与 JSON 数据相关的元数据ObjectMapper objectMapper:用于解析 JSON 数据List<String> jsonKeysToUse:用于从 JSON 中提取哪些字段作为文档内容,若未指定则使用整个 JSON 对象
方法说明
| 方法名称 | 描述 |
| JsonReader | 通过资源对象、提取的字段名构造读取器 |
| get | 读取json文件,返回Document列表 |
package org.springframework.ai.reader;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
import java.util.Collections;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import java.util.stream.Stream;
import java.util.stream.StreamSupport;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.core.io.Resource;
public class JsonReader implements DocumentReader {
private final Resource resource;
private final JsonMetadataGenerator jsonMetadataGenerator;
private final ObjectMapper objectMapper;
private final List<String> jsonKeysToUse;
public JsonReader(Resource resource) {
this(resource);
}
public JsonReader(Resource resource, String... jsonKeysToUse) {
this(resource, new EmptyJsonMetadataGenerator(), jsonKeysToUse);
}
public JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String... jsonKeysToUse) {
this.objectMapper = new ObjectMapper();
Objects.requireNonNull(jsonKeysToUse, "keys must not be null");
Objects.requireNonNull(jsonMetadataGenerator, "jsonMetadataGenerator must not be null");
Objects.requireNonNull(resource, "The Spring Resource must not be null");
this.resource = resource;
this.jsonMetadataGenerator = jsonMetadataGenerator;
this.jsonKeysToUse = List.of(jsonKeysToUse);
}
public List<Document> get() {
try {
JsonNode rootNode = this.objectMapper.readTree(this.resource.getInputStream());
return rootNode.isArray() ? StreamSupport.stream(rootNode.spliterator(), true).map((jsonNode) -> this.parseJsonNode(jsonNode, this.objectMapper)).toList() : Collections.singletonList(this.parseJsonNode(rootNode, this.objectMapper));
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private Document parseJsonNode(JsonNode jsonNode, ObjectMapper objectMapper) {
Map<String, Object> item = (Map)objectMapper.convertValue(jsonNode, new TypeReference<Map<String, Object>>() {
});
StringBuilder sb = new StringBuilder();
Stream var10000 = this.jsonKeysToUse.stream();
Objects.requireNonNull(item);
var10000.filter(item::containsKey).forEach((key) -> sb.append(key).append(": ").append(item.get(key)).append(System.lineSeparator()));
Map<String, Object> metadata = this.jsonMetadataGenerator.generate(item);
String content = sb.isEmpty() ? item.toString() : sb.toString();
return new Document(content, metadata);
}
protected List<Document> get(JsonNode rootNode) {
return rootNode.isArray() ? StreamSupport.stream(rootNode.spliterator(), true).map((jsonNode) -> this.parseJsonNode(jsonNode, this.objectMapper)).toList() : Collections.singletonList(this.parseJsonNode(rootNode, this.objectMapper));
}
public List<Document> get(String pointer) {
try {
JsonNode rootNode = this.objectMapper.readTree(this.resource.getInputStream());
JsonNode targetNode = rootNode.at(pointer);
if (targetNode.isMissingNode()) {
throw new IllegalArgumentException("Invalid JSON Pointer: " + pointer);
} else {
return this.get(targetNode);
}
} catch (IOException e) {
throw new RuntimeException("Error reading JSON resource", e);
}
}
}
JsoupDocumentReader
用于从 HTML 文档中提取文本内容,并将其转换为 Document 对象
各字段含义:
Resource htmlResource:要读取的 HTML 资源JsoupDocumentReaderConfig config:配置 HTML 文档读取行为,包括字符集、选择器、是否提取所有元素,是否按元素分组等
方法说明
| 方法名称 | 描述 |
| JsoupDocumentReader | 通过资源URL、资源对象、解析HTML配置等构造读取器 |
| get | 读取html文件,返回Document列表 |
package org.springframework.ai.reader.jsoup;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.jsoup.config.JsoupDocumentReaderConfig;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
public class JsoupDocumentReader implements DocumentReader {
private final Resource htmlResource;
private final JsoupDocumentReaderConfig config;
public JsoupDocumentReader(String htmlResource) {
this((new DefaultResourceLoader()).getResource(htmlResource));
}
public JsoupDocumentReader(Resource htmlResource) {
this(htmlResource, JsoupDocumentReaderConfig.defaultConfig());
}
public JsoupDocumentReader(String htmlResource, JsoupDocumentReaderConfig config) {
this((new DefaultResourceLoader()).getResource(htmlResource), config);
}
public JsoupDocumentReader(Resource htmlResource, JsoupDocumentReaderConfig config) {
this.htmlResource = htmlResource;
this.config = config;
}
public List<Document> get() {
try (InputStream inputStream = this.htmlResource.getInputStream()) {
org.jsoup.nodes.Document doc = Jsoup.parse(inputStream, this.config.charset, "");
List<Document> documents = new ArrayList();
if (this.config.allElements) {
String allText = doc.body().text();
Document document = new Document(allText);
this.addMetadata(doc, document);
documents.add(document);
} else if (this.config.groupByElement) {
for(Element element : doc.select(this.config.selector)) {
String elementText = element.text();
Document document = new Document(elementText);
this.addMetadata(doc, document);
documents.add(document);
}
} else {
Elements elements = doc.select(this.config.selector);
String text = (String)elements.stream().map(Element::text).collect(Collectors.joining(this.config.separator));
Document document = new Document(text);
this.addMetadata(doc, document);
documents.add(document);
}
return documents;
} catch (IOException e) {
throw new RuntimeException("Failed to read HTML resource: " + String.valueOf(this.htmlResource), e);
}
}
private void addMetadata(org.jsoup.nodes.Document jsoupDoc, Document springDoc) {
Map<String, Object> metadata = new HashMap();
metadata.put("title", jsoupDoc.title());
for(String metaTag : this.config.metadataTags) {
String value = jsoupDoc.select("meta[name=" + metaTag + "]").attr("content");
if (!value.isEmpty()) {
metadata.put(metaTag, value);
}
}
if (this.config.includeLinkUrls) {
Elements links = jsoupDoc.select("a[href]");
List<String> linkUrls = links.stream().map((link) -> link.attr("abs:href")).toList();
metadata.put("linkUrls", linkUrls);
}
metadata.putAll(this.config.additionalMetadata);
springDoc.getMetadata().putAll(metadata);
}
}
JsoupDocumentReaderConfig
配置 JsoupDocumentReader 行为的工具类
String charset:读取 HTML 文档时使用的字符编码,默认值为 “UTF-8”String selector:用于提取 HTML 元素的 CSS 选择器,默认值为 “body”String separator:在提取多个元素的文本内容时使用的分隔符,默认值为 “\n”boolean allElements:是否提取 HTML 文档中所有元素的文本内容,并生成一个 Document 对象,默认值为 falseboolean groupByElement:是否按元素分组提取文本内容,并为每个元素生成一个 Document 对象,默认值为 falseboolean includeLinkUrls:是否将 HTML 文档中的链接 URL 包含在元数据中,默认值为 falseList<String> metadataTags:指定从 HTML 文档的 标签中提取哪些元数据,默认包含 “description” 和 “keywords”Map<String, Object> additionalMetadata:用于添加额外的元数据到生成的 Document 对象中
package org.springframework.ai.reader.jsoup.config;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.util.Assert;
public final class JsoupDocumentReaderConfig {
public final String charset;
public final String selector;
public final String separator;
public final boolean allElements;
public final boolean groupByElement;
public final boolean includeLinkUrls;
public final List<String> metadataTags;
public final Map<String, Object> additionalMetadata;
private JsoupDocumentReaderConfig(Builder builder) {
this.charset = builder.charset;
this.selector = builder.selector;
this.separator = builder.separator;
this.allElements = builder.allElements;
this.includeLinkUrls = builder.includeLinkUrls;
this.metadataTags = builder.metadataTags;
this.groupByElement = builder.groupByElement;
this.additionalMetadata = builder.additionalMetadata;
}
public static Builder builder() {
return new Builder();
}
public static JsoupDocumentReaderConfig defaultConfig() {
return builder().build();
}
public static final class Builder {
private String charset = "UTF-8";
private String selector = "body";
private String separator = "\n";
private boolean allElements = false;
private boolean includeLinkUrls = false;
private List<String> metadataTags = new ArrayList(List.of("description", "keywords"));
private boolean groupByElement = false;
private Map<String, Object> additionalMetadata = new HashMap();
private Builder() {
}
public Builder charset(String charset) {
this.charset = charset;
return this;
}
public Builder selector(String selector) {
this.selector = selector;
return this;
}
public Builder separator(String separator) {
this.separator = separator;
return this;
}
public Builder allElements(boolean allElements) {
this.allElements = allElements;
return this;
}
public Builder groupByElement(boolean groupByElement) {
this.groupByElement = groupByElement;
return this;
}
public Builder includeLinkUrls(boolean includeLinkUrls) {
this.includeLinkUrls = includeLinkUrls;
return this;
}
public Builder metadataTag(String metadataTag) {
this.metadataTags.add(metadataTag);
return this;
}
public Builder metadataTags(List<String> metadataTags) {
this.metadataTags = new ArrayList(metadataTags);
return this;
}
public Builder additionalMetadata(String key, Object value) {
Assert.notNull(key, "key must not be null");
Assert.notNull(value, "value must not be null");
this.additionalMetadata.put(key, value);
return this;
}
public Builder additionalMetadata(Map<String, Object> additionalMetadata) {
Assert.notNull(additionalMetadata, "additionalMetadata must not be null");
this.additionalMetadata = additionalMetadata;
return this;
}
public JsoupDocumentReaderConfig build() {
return new JsoupDocumentReaderConfig(this);
}
}
}
MarkdownDocumentReader
用于从 Markdown 文件中读取内容并将其转换为 Document 对象。基于 CommonMark 库解析 Markdown 文档,支持将标题、段落、代码块等内容分组为 Document 对象,并生成相关元数据
Resource markdownResource:要读取的 Markdown 资源MarkdownDocumentReaderConfig config:配置 Markdown 文档读取行为,包括是否将水平分割线视为文档分隔符、是否包含代码块、是否包含引用块等Parser parser:解析 Markdown 文档的 CommonMark 解析器,用于将 Markdown 文本解析为节点树
DocumentVisitor 作为内部静态类,继承自 CommonMark 的 AbstractVisitor,用于遍历和解析 Markdown 的语法树节点,将其内容按配置分组、提取为结构化的 Document 对象
- 历 Markdown 解析后的节点树,根据配置(如是否按水平线分组、是否包含代码块/引用等)将内容分组
- 识别标题、段落、代码块、引用等不同类型节点,提取文本和元数据,构建 Document
- 支持为不同类型内容(如标题、代码块、引用)添加分类、标题、语言等元数据,便于后续 AI 处理。
| 方法名称 | 描述 |
| MarkdownDocumentReader | 通过资源URL、资源对象、解析markdown配置等构造读取器 |
| get | 读取markdown文件,返回Document列表 |
package org.springframework.ai.reader.markdown;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.Objects;
import org.commonmark.node.AbstractVisitor;
import org.commonmark.node.BlockQuote;
import org.commonmark.node.Code;
import org.commonmark.node.FencedCodeBlock;
import org.commonmark.node.HardLineBreak;
import org.commonmark.node.Heading;
import org.commonmark.node.ListItem;
import org.commonmark.node.Node;
import org.commonmark.node.SoftLineBreak;
import org.commonmark.node.Text;
import org.commonmark.node.ThematicBreak;
import org.commonmark.parser.Parser;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
public class MarkdownDocumentReader implements DocumentReader {
private final Resource markdownResource;
private final MarkdownDocumentReaderConfig config;
private final Parser parser;
public MarkdownDocumentReader(String markdownResource) {
this((new DefaultResourceLoader()).getResource(markdownResource), MarkdownDocumentReaderConfig.defaultConfig());
}
public MarkdownDocumentReader(String markdownResource, MarkdownDocumentReaderConfig config) {
this((new DefaultResourceLoader()).getResource(markdownResource), config);
}
public MarkdownDocumentReader(Resource markdownResource, MarkdownDocumentReaderConfig config) {
this.markdownResource = markdownResource;
this.config = config;
this.parser = Parser.builder().build();
}
public List<Document> get() {
try (InputStream input = this.markdownResource.getInputStream()) {
Node node = this.parser.parseReader(new InputStreamReader(input));
DocumentVisitor documentVisitor = new DocumentVisitor(this.config);
node.accept(documentVisitor);
return documentVisitor.getDocuments();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
static class DocumentVisitor extends AbstractVisitor {
private final List<Document> documents = new ArrayList();
private final List<String> currentParagraphs = new ArrayList();
private final MarkdownDocumentReaderConfig config;
private Document.Builder currentDocumentBuilder;
DocumentVisitor(MarkdownDocumentReaderConfig config) {
this.config = config;
}
public void visit(org.commonmark.node.Document document) {
this.currentDocumentBuilder = Document.builder();
super.visit(document);
}
public void visit(Heading heading) {
this.buildAndFlush();
super.visit(heading);
}
public void visit(ThematicBreak thematicBreak) {
if (this.config.horizontalRuleCreateDocument) {
this.buildAndFlush();
}
super.visit(thematicBreak);
}
public void visit(SoftLineBreak softLineBreak) {
this.translateLineBreakToSpace();
super.visit(softLineBreak);
}
public void visit(HardLineBreak hardLineBreak) {
this.translateLineBreakToSpace();
super.visit(hardLineBreak);
}
public void visit(ListItem listItem) {
this.translateLineBreakToSpace();
super.visit(listItem);
}
public void visit(BlockQuote blockQuote) {
if (!this.config.includeBlockquote) {
this.buildAndFlush();
}
this.translateLineBreakToSpace();
this.currentDocumentBuilder.metadata("category", "blockquote");
super.visit(blockQuote);
}
public void visit(Code code) {
this.currentParagraphs.add(code.getLiteral());
this.currentDocumentBuilder.metadata("category", "codeinline");
super.visit(code);
}
public void visit(FencedCodeBlock fencedCodeBlock) {
if (!this.config.includeCodeBlock) {
this.buildAndFlush();
}
this.translateLineBreakToSpace();
this.currentParagraphs.add(fencedCodeBlock.getLiteral());
this.currentDocumentBuilder.metadata("category", "codeblock");
this.currentDocumentBuilder.metadata("lang", fencedCodeBlock.getInfo());
this.buildAndFlush();
super.visit(fencedCodeBlock);
}
public void visit(Text text) {
Node var3 = text.getParent();
if (var3 instanceof Heading heading) {
this.currentDocumentBuilder.metadata("category", "header%d".formatted(heading.getLevel())).metadata("title", text.getLiteral());
} else {
this.currentParagraphs.add(text.getLiteral());
}
super.visit(text);
}
public List<Document> getDocuments() {
this.buildAndFlush();
return this.documents;
}
private void buildAndFlush() {
if (!this.currentParagraphs.isEmpty()) {
String content = String.join("", this.currentParagraphs);
Document.Builder builder = this.currentDocumentBuilder.text(content);
Map var10000 = this.config.additionalMetadata;
Objects.requireNonNull(builder);
var10000.forEach(builder::metadata);
Document document = builder.build();
this.documents.add(document);
this.currentParagraphs.clear();
}
this.currentDocumentBuilder = Document.builder();
}
private void translateLineBreakToSpace() {
if (!this.currentParagraphs.isEmpty()) {
this.currentParagraphs.add(" ");
}
}
}
}
MarkdownDocumentReaderConfig
配置 MarkdownDocumentReader 的行为
boolean horizontalRuleCreateDocument:是否将水平分割线分隔的文本创建为新的 Documentboolean includeCodeBlock:是否将代码块包含在段落文档中,还是单独创建新文档boolean includeBlockquote:是否将引用块包含在段落文档中,还是单独创建新文档Map<String, Object> additionalMetadata:添加额外元数据
package org.springframework.ai.reader.markdown.config;
import java.util.HashMap;
import java.util.Map;
import org.springframework.util.Assert;
public class MarkdownDocumentReaderConfig {
public final boolean horizontalRuleCreateDocument;
public final boolean includeCodeBlock;
public final boolean includeBlockquote;
public final Map<String, Object> additionalMetadata;
public MarkdownDocumentReaderConfig(Builder builder) {
this.horizontalRuleCreateDocument = builder.horizontalRuleCreateDocument;
this.includeCodeBlock = builder.includeCodeBlock;
this.includeBlockquote = builder.includeBlockquote;
this.additionalMetadata = builder.additionalMetadata;
}
public static MarkdownDocumentReaderConfig defaultConfig() {
return builder().build();
}
public static Builder builder() {
return new Builder();
}
public static final class Builder {
private boolean horizontalRuleCreateDocument = false;
private boolean includeCodeBlock = false;
private boolean includeBlockquote = false;
private Map<String, Object> additionalMetadata = new HashMap();
private Builder() {
}
public Builder withHorizontalRuleCreateDocument(boolean horizontalRuleCreateDocument) {
this.horizontalRuleCreateDocument = horizontalRuleCreateDocument;
return this;
}
public Builder withIncludeCodeBlock(boolean includeCodeBlock) {
this.includeCodeBlock = includeCodeBlock;
return this;
}
public Builder withIncludeBlockquote(boolean includeBlockquote) {
this.includeBlockquote = includeBlockquote;
return this;
}
public Builder withAdditionalMetadata(String key, Object value) {
Assert.notNull(key, "key must not be null");
Assert.notNull(value, "value must not be null");
this.additionalMetadata.put(key, value);
return this;
}
public Builder withAdditionalMetadata(Map<String, Object> additionalMetadata) {
Assert.notNull(additionalMetadata, "additionalMetadata must not be null");
this.additionalMetadata = additionalMetadata;
return this;
}
public MarkdownDocumentReaderConfig build() {
return new MarkdownDocumentReaderConfig(this);
}
}
}
PagePdfDocumentReader
用于将 PDF 文件按页分组解析为多个 Document,每个 Document 可包含一页或多页内容,支持自定义分组和页面裁剪
PDDocument document:要读取的 PDF 文档对象- String resourceFileName:存储 PDF 文件的名字
PdfDocumentReaderConfig config:配置 PDF 文档读取行为,包括每份文档包含的页数、页边距
| 方法名称 | 描述 |
| PagePdfDocumentReader | 通过资源URL、资源对象、解析PDF配置等构造读取器 |
| get | 读取PDF,返回Document列表 |
| toDocument | 将指定页内容和元数据封装为 Document |
package org.springframework.ai.reader.pdf;
import java.awt.Rectangle;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.pdfbox.io.RandomAccessReadBuffer;
import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.reader.pdf.layout.PDFLayoutTextStripperByArea;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
public class PagePdfDocumentReader implements DocumentReader {
public static final String METADATASTARTPAGENUMBER = "pagenumber";
public static final String METADATAENDPAGENUMBER = "endpagenumber";
public static final String METADATAFILENAME = "filename";
private static final String PDFPAGEREGION = "pdfPageRegion";
protected final PDDocument document;
private final Logger logger;
protected String resourceFileName;
private PdfDocumentReaderConfig config;
public PagePdfDocumentReader(String resourceUrl) {
this((new DefaultResourceLoader()).getResource(resourceUrl));
}
public PagePdfDocumentReader(Resource pdfResource) {
this(pdfResource, PdfDocumentReaderConfig.defaultConfig());
}
public PagePdfDocumentReader(String resourceUrl, PdfDocumentReaderConfig config) {
this((new DefaultResourceLoader()).getResource(resourceUrl), config);
}
public PagePdfDocumentReader(Resource pdfResource, PdfDocumentReaderConfig config) {
this.logger = LoggerFactory.getLogger(this.getClass());
try {
PDFParser pdfParser = new PDFParser(new RandomAccessReadBuffer(pdfResource.getInputStream()));
this.document = pdfParser.parse();
this.resourceFileName = pdfResource.getFilename();
this.config = config;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public List<Document> get() {
List<Document> readDocuments = new ArrayList();
try {
PDFLayoutTextStripperByArea pdfTextStripper = new PDFLayoutTextStripperByArea();
int pageNumber = 0;
int pagesPerDocument = 0;
int startPageNumber = pageNumber;
List<String> pageTextGroupList = new ArrayList();
int totalPages = this.document.getDocumentCatalog().getPages().getCount();
int logFrequency = totalPages > 10 ? totalPages / 10 : 1;
int counter = 0;
PDPage lastPage = (PDPage)this.document.getDocumentCatalog().getPages().iterator().next();
for(PDPage page : this.document.getDocumentCatalog().getPages()) {
lastPage = page;
if (counter % logFrequency == 0 && counter / logFrequency < 10) {
this.logger.info("Processing PDF page: {}", counter + 1);
}
++counter;
++pagesPerDocument;
if (this.config.pagesPerDocument != 0 && pagesPerDocument >= this.config.pagesPerDocument) {
pagesPerDocument = 0;
String aggregatedPageTextGroup = (String)pageTextGroupList.stream().collect(Collectors.joining());
if (StringUtils.hasText(aggregatedPageTextGroup)) {
readDocuments.add(this.toDocument(page, aggregatedPageTextGroup, startPageNumber, pageNumber));
}
pageTextGroupList.clear();
startPageNumber = pageNumber + 1;
}
int x0 = (int)page.getMediaBox().getLowerLeftX();
int xW = (int)page.getMediaBox().getWidth();
int y0 = (int)page.getMediaBox().getLowerLeftY() + this.config.pageTopMargin;
int yW = (int)page.getMediaBox().getHeight() - (this.config.pageTopMargin + this.config.pageBottomMargin);
pdfTextStripper.addRegion("pdfPageRegion", new Rectangle(x0, y0, xW, yW));
pdfTextStripper.extractRegions(page);
String pageText = pdfTextStripper.getTextForRegion("pdfPageRegion");
if (StringUtils.hasText(pageText)) {
pageText = this.config.pageExtractedTextFormatter.format(pageText, pageNumber);
pageTextGroupList.add(pageText);
}
++pageNumber;
pdfTextStripper.removeRegion("pdfPageRegion");
}
if (!CollectionUtils.isEmpty(pageTextGroupList)) {
readDocuments.add(this.toDocument(lastPage, (String)pageTextGroupList.stream().collect(Collectors.joining()), startPageNumber, pageNumber));
}
this.logger.info("Processing {} pages", totalPages);
return readDocuments;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
protected Document toDocument(PDPage page, String docText, int startPageNumber, int endPageNumber) {
Document doc = new Document(docText);
doc.getMetadata().put("pagenumber", startPageNumber);
if (startPageNumber != endPageNumber) {
doc.getMetadata().put("endpagenumber", endPageNumber);
}
doc.getMetadata().put("filename", this.resourceFileName);
return doc;
}
}
PdfDocumentReaderConfig
PDF 文档读取器的配置类,用于控制 PDF 解析和分组行为
int ALLPAGES:常量,值为 0,表示将所有页合并为一个 Documentboolean reversedParagraphPosition:是否反转每页内段落顺序,默认为 falseint pagesPerDocument:每个 Document 包含的页数,0 表示所有页合并,默认 1int pageTopMargin:每页顶部裁剪的像素数,默认 0int pageBottomMargin:每页底部裁剪的像素数,默认 0int pageExtractedTextFormatter:提取文本后的格式化器,可自定义每页文本的处理方式
package org.springframework.ai.reader.pdf.config;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.util.Assert;
public final class PdfDocumentReaderConfig {
public static final int ALLPAGES = 0;
public final boolean reversedParagraphPosition;
public final int pagesPerDocument;
public final int pageTopMargin;
public final int pageBottomMargin;
public final ExtractedTextFormatter pageExtractedTextFormatter;
private PdfDocumentReaderConfig(Builder builder) {
this.pagesPerDocument = builder.pagesPerDocument;
this.pageBottomMargin = builder.pageBottomMargin;
this.pageTopMargin = builder.pageTopMargin;
this.pageExtractedTextFormatter = builder.pageExtractedTextFormatter;
this.reversedParagraphPosition = builder.reversedParagraphPosition;
}
public static Builder builder() {
return new Builder();
}
public static PdfDocumentReaderConfig defaultConfig() {
return builder().build();
}
public static final class Builder {
private int pagesPerDocument = 1;
private int pageTopMargin = 0;
private int pageBottomMargin = 0;
private ExtractedTextFormatter pageExtractedTextFormatter = ExtractedTextFormatter.defaults();
private boolean reversedParagraphPosition = false;
private Builder() {
}
public Builder withPageExtractedTextFormatter(ExtractedTextFormatter pageExtractedTextFormatter) {
Assert.notNull(pageExtractedTextFormatter, "PageExtractedTextFormatter must not be null.");
this.pageExtractedTextFormatter = pageExtractedTextFormatter;
return this;
}
public Builder withPagesPerDocument(int pagesPerDocument) {
Assert.isTrue(pagesPerDocument >= 0, "Page count must be a positive value.");
this.pagesPerDocument = pagesPerDocument;
return this;
}
public Builder withPageTopMargin(int topMargin) {
Assert.isTrue(topMargin >= 0, "Page margins must be a positive value.");
this.pageTopMargin = topMargin;
return this;
}
public Builder withPageBottomMargin(int bottomMargin) {
Assert.isTrue(bottomMargin >= 0, "Page margins must be a positive value.");
this.pageBottomMargin = bottomMargin;
return this;
}
public Builder withReversedParagraphPosition(boolean reversedParagraphPosition) {
this.reversedParagraphPosition = reversedParagraphPosition;
return this;
}
public PdfDocumentReaderConfig build() {
return new PdfDocumentReaderConfig(this);
}
}
}
ParagraphPdfDocumentReader
用于将 PDF 文件按段落(基于目录/结构信息)解析为多个 Document,每个 Document 通常对应一个段落
PDDocument document:要读取的 PDF 文档对象String resourceFileName:存储 PDF 文件的名字PdfDocumentReaderConfig config:配置 PDF 文档读取行为,包括每份文档包含的页数、页边距ParagraphManager paragraphTextExtractor:负责解析 PDF 并提取段落信息
| 方法名称 | 描述 |
| ParagraphPdfDocumentReader | 通过资源URL、资源对象、解析PDF配置等构造读取器 |
| get | 读取带目录的PDF,返回Document列表 |
| toDocument | 将指定段落内容和元数据封装为 Document |
| addMetadata | 为 Document 添加元数据 |
| getTextBetweenParagraphs | 提取两个段落之间的文本内容 |
package org.springframework.ai.reader.pdf;
import java.awt.Rectangle;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.pdfbox.io.RandomAccessReadBuffer;
import org.apache.pdfbox.pdfparser.PDFParser;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.pdf.config.ParagraphManager;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.reader.pdf.layout.PDFLayoutTextStripperByArea;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
public class ParagraphPdfDocumentReader implements DocumentReader {
private static final String METADATASTARTPAGE = "pagenumber";
private static final String METADATAENDPAGE = "endpagenumber";
private static final String METADATATITLE = "title";
private static final String METADATALEVEL = "level";
private static final String METADATAFILENAME = "filename";
protected final PDDocument document;
private final Logger logger;
private final ParagraphManager paragraphTextExtractor;
protected String resourceFileName;
private PdfDocumentReaderConfig config;
public ParagraphPdfDocumentReader(String resourceUrl) {
this((new DefaultResourceLoader()).getResource(resourceUrl));
}
public ParagraphPdfDocumentReader(Resource pdfResource) {
this(pdfResource, PdfDocumentReaderConfig.defaultConfig());
}
public ParagraphPdfDocumentReader(String resourceUrl, PdfDocumentReaderConfig config) {
this((new DefaultResourceLoader()).getResource(resourceUrl), config);
}
public ParagraphPdfDocumentReader(Resource pdfResource, PdfDocumentReaderConfig config) {
this.logger = LoggerFactory.getLogger(this.getClass());
try {
PDFParser pdfParser = new PDFParser(new RandomAccessReadBuffer(pdfResource.getInputStream()));
this.document = pdfParser.parse();
this.config = config;
this.paragraphTextExtractor = new ParagraphManager(this.document);
this.resourceFileName = pdfResource.getFilename();
} catch (IllegalArgumentException iae) {
throw iae;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public List<Document> get() {
List<ParagraphManager.Paragraph> paragraphs = this.paragraphTextExtractor.flatten();
List<Document> documents = new ArrayList(paragraphs.size());
if (!CollectionUtils.isEmpty(paragraphs)) {
this.logger.info("Start processing paragraphs from PDF");
Iterator<ParagraphManager.Paragraph> itr = paragraphs.iterator();
ParagraphManager.Paragraph current = (ParagraphManager.Paragraph)itr.next();
ParagraphManager.Paragraph next;
if (!itr.hasNext()) {
documents.add(this.toDocument(current, current));
} else {
for(; itr.hasNext(); current = next) {
next = (ParagraphManager.Paragraph)itr.next();
Document document = this.toDocument(current, next);
if (document != null && StringUtils.hasText(document.getText())) {
documents.add(this.toDocument(current, next));
}
}
}
}
this.logger.info("End processing paragraphs from PDF");
return documents;
}
protected Document toDocument(ParagraphManager.Paragraph from, ParagraphManager.Paragraph to) {
String docText = this.getTextBetweenParagraphs(from, to);
if (!StringUtils.hasText(docText)) {
return null;
} else {
Document document = new Document(docText);
this.addMetadata(from, to, document);
return document;
}
}
protected void addMetadata(ParagraphManager.Paragraph from, ParagraphManager.Paragraph to, Document document) {
document.getMetadata().put("title", from.title());
document.getMetadata().put("pagenumber", from.startPageNumber());
document.getMetadata().put("endpagenumber", to.startPageNumber());
document.getMetadata().put("level", from.level());
document.getMetadata().put("filename", this.resourceFileName);
}
public String getTextBetweenParagraphs(ParagraphManager.Paragraph fromParagraph, ParagraphManager.Paragraph toParagraph) {
int startPage = fromParagraph.startPageNumber() - 1;
int endPage = toParagraph.startPageNumber() - 1;
try {
StringBuilder sb = new StringBuilder();
PDFLayoutTextStripperByArea pdfTextStripper = new PDFLayoutTextStripperByArea();
pdfTextStripper.setSortByPosition(true);
for(int pageNumber = startPage; pageNumber <= endPage; ++pageNumber) {
PDPage page = this.document.getPage(pageNumber);
int fromPosition = fromParagraph.position();
int toPosition = toParagraph.position();
if (this.config.reversedParagraphPosition) {
fromPosition = (int)(page.getMediaBox().getHeight() - (float)fromPosition);
toPosition = (int)(page.getMediaBox().getHeight() - (float)toPosition);
}
int x0 = (int)page.getMediaBox().getLowerLeftX();
int xW = (int)page.getMediaBox().getWidth();
int y0 = (int)page.getMediaBox().getLowerLeftY();
int yW = (int)page.getMediaBox().getHeight();
if (pageNumber == startPage) {
y0 = fromPosition;
yW = (int)page.getMediaBox().getHeight() - fromPosition;
}
if (pageNumber == endPage) {
yW = toPosition - y0;
}
if (y0 + yW == (int)page.getMediaBox().getHeight()) {
yW -= this.config.pageBottomMargin;
}
if (y0 == 0) {
y0 += this.config.pageTopMargin;
yW -= this.config.pageTopMargin;
}
pdfTextStripper.addRegion("pdfPageRegion", new Rectangle(x0, y0, xW, yW));
pdfTextStripper.extractRegions(page);
String text = pdfTextStripper.getTextForRegion("pdfPageRegion");
if (StringUtils.hasText(text)) {
sb.append(text);
}
pdfTextStripper.removeRegion("pdfPageRegion");
}
String text = sb.toString();
if (StringUtils.hasText(text)) {
text = this.config.pageExtractedTextFormatter.format(text, startPage);
}
return text;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
ParagraphManager
类用于管理 PDF 文档的段落结构,主要通过解析 PDF 目录(TOC/书签)生成段落树,并可将其扁平化为段落列表,便于后续内容提取和分组
Paragraph rootParagraph:段落树的根节点,类型为 Paragraph,包含所有段落的层级结构PDDocument document:PDFBox 的 PDDocument,表示当前处理的 PDF 文档
| 方法名称 | 描述 |
| ParagraphManager | 传入 PDF 文档,自动解析目录生成段落树 |
| flatten | 将段落树扁平化为 Paragraph 列表,便于顺序遍历 |
| getParagraphsByLevel | 按指定层级获取段落列表,可选是否包含跨层级段落 |
| Paragraph | 静态内部类,表示段落的元数据(标题、层级、起止页码、位置、子段落等) |
| generateParagraphs | ParagraphManager 的核心递归方法,用于遍历 PDF 目录(TOC/书签)的树结构,将每个目录项(PDOutlineItem)转换为 Paragraph,并构建出完整的段落树(章节层级结构) |
package org.springframework.ai.reader.pdf.config;
import java.io.IOException;
import java.io.PrintStream;
import java.util.ArrayList;
import java.util.List;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.PDPageTree;
import org.apache.pdfbox.pdmodel.interactive.documentnavigation.destination.PDPageXYZDestination;
import org.apache.pdfbox.pdmodel.interactive.documentnavigation.outline.PDOutlineItem;
import org.apache.pdfbox.pdmodel.interactive.documentnavigation.outline.PDOutlineNode;
import org.springframework.util.Assert;
import org.springframework.util.CollectionUtils;
public class ParagraphManager {
private final Paragraph rootParagraph;
private final PDDocument document;
public ParagraphManager(PDDocument document) {
Assert.notNull(document, "PDDocument must not be null");
Assert.notNull(document.getDocumentCatalog().getDocumentOutline(), "Document outline (e.g. TOC) is null. Make sure the PDF document has a table of contents (TOC). If not, consider the PagePdfDocumentReader or the TikaDocumentReader instead.");
try {
this.document = document;
this.rootParagraph = this.generateParagraphs(new Paragraph((Paragraph)null, "root", -1, 1, this.document.getNumberOfPages(), 0), this.document.getDocumentCatalog().getDocumentOutline(), 0);
this.printParagraph(this.rootParagraph, System.out);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public List<Paragraph> flatten() {
List<Paragraph> paragraphs = new ArrayList();
for(Paragraph child : this.rootParagraph.children()) {
this.flatten(child, paragraphs);
}
return paragraphs;
}
private void flatten(Paragraph current, List<Paragraph> paragraphs) {
paragraphs.add(current);
for(Paragraph child : current.children()) {
this.flatten(child, paragraphs);
}
}
private void printParagraph(Paragraph paragraph, PrintStream printStream) {
printStream.println(paragraph);
for(Paragraph childParagraph : paragraph.children()) {
this.printParagraph(childParagraph, printStream);
}
}
protected Paragraph generateParagraphs(Paragraph parentParagraph, PDOutlineNode bookmark, Integer level) throws IOException {
for(PDOutlineItem current = bookmark.getFirstChild(); current != null; current = current.getNextSibling()) {
int pageNumber = this.getPageNumber(current);
int nextSiblingNumber = this.getPageNumber(current.getNextSibling());
if (nextSiblingNumber < 0) {
nextSiblingNumber = this.getPageNumber(current.getLastChild());
}
int paragraphPosition = current.getDestination() instanceof PDPageXYZDestination ? ((PDPageXYZDestination)current.getDestination()).getTop() : 0;
Paragraph currentParagraph = new Paragraph(parentParagraph, current.getTitle(), level, pageNumber, nextSiblingNumber, paragraphPosition);
parentParagraph.children().add(currentParagraph);
this.generateParagraphs(currentParagraph, current, level + 1);
}
return parentParagraph;
}
private int getPageNumber(PDOutlineItem current) throws IOException {
if (current == null) {
return -1;
} else {
PDPage currentPage = current.findDestinationPage(this.document);
PDPageTree pages = this.document.getDocumentCatalog().getPages();
for(int i = 0; i < pages.getCount(); ++i) {
PDPage page = pages.get(i);
if (page.equals(currentPage)) {
return i + 1;
}
}
return -1;
}
}
public List<Paragraph> getParagraphsByLevel(Paragraph paragraph, int level, boolean interLevelText) {
List<Paragraph> resultList = new ArrayList();
if (paragraph.level() < level) {
if (!CollectionUtils.isEmpty(paragraph.children())) {
if (interLevelText) {
Paragraph interLevelParagraph = new Paragraph(paragraph.parent(), paragraph.title(), paragraph.level(), paragraph.startPageNumber(), ((Paragraph)paragraph.children().get(0)).startPageNumber(), paragraph.position());
resultList.add(interLevelParagraph);
}
for(Paragraph child : paragraph.children()) {
resultList.addAll(this.getParagraphsByLevel(child, level, interLevelText));
}
}
} else if (paragraph.level() == level) {
resultList.add(paragraph);
}
return resultList;
}
public static record Paragraph(Paragraph parent, String title, int level, int startPageNumber, int endPageNumber, int position, List<Paragraph> children) {
public Paragraph(Paragraph parent, String title, int level, int startPageNumber, int endPageNumber, int position) {
this(parent, title, level, startPageNumber, endPageNumber, position, new ArrayList());
}
public String toString() {
String indent = this.level < 0 ? "" : (new String(new char[this.level * 2])).replace('\u0000', ' ');
return indent + " " + this.level + ") " + this.title + " [" + this.startPageNumber + "," + this.endPageNumber + "], children = " + this.children.size() + ", pos = " + this.position;
}
}
}
TikaDocumentReader
用于从多种文档格式(如 PDF、DOC/DOCX、PPT/PPTX、HTML 等)中提取文本,并将其封装为 Document 对象,基于 Apache Tika 库实现,支持广泛的文档格式。
AutoDetectParser parser:自动检索文档类型并文本的解析器ContentHandler handler:管理内容提取的处理器Metadata metadata:读取文档相关的元数据ParseContext context:解析过程信息的上下文Resource resource:指向文档的资源对象ExtractedTextFormatter textFormatter:格式化提取的文本
| 方法名称 | 描述 |
| TikaDocumentReader | 通过资源URL、资源对象、文本格式化器等构造读取器 |
| get | 从多种文档格式读取,返回Document列表 |
package org.springframework.ai.reader.tika;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import java.util.Objects;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.sax.BodyContentHandler;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.core.io.Resource;
import org.springframework.util.StringUtils;
import org.xml.sax.ContentHandler;
public class TikaDocumentReader implements DocumentReader {
public static final String METADATASOURCE = "source";
private final AutoDetectParser parser;
private final ContentHandler handler;
private final Metadata metadata;
private final ParseContext context;
private final Resource resource;
private final ExtractedTextFormatter textFormatter;
public TikaDocumentReader(String resourceUrl) {
this(resourceUrl, ExtractedTextFormatter.defaults());
}
public TikaDocumentReader(String resourceUrl, ExtractedTextFormatter textFormatter) {
this((new DefaultResourceLoader()).getResource(resourceUrl), textFormatter);
}
public TikaDocumentReader(Resource resource) {
this(resource, ExtractedTextFormatter.defaults());
}
public TikaDocumentReader(Resource resource, ExtractedTextFormatter textFormatter) {
this(resource, new BodyContentHandler(-1), textFormatter);
}
public TikaDocumentReader(Resource resource, ContentHandler contentHandler, ExtractedTextFormatter textFormatter) {
this.parser = new AutoDetectParser();
this.handler = contentHandler;
this.metadata = new Metadata();
this.context = new ParseContext();
this.resource = resource;
this.textFormatter = textFormatter;
}
public List<Document> get() {
try (InputStream stream = this.resource.getInputStream()) {
this.parser.parse(stream, this.handler, this.metadata, this.context);
return List.of(this.toDocument(this.handler.toString()));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private Document toDocument(String docText) {
docText = (String)Objects.requireNonNullElse(docText, "");
docText = this.textFormatter.format(docText);
Document doc = new Document(docText);
doc.getMetadata().put("source", this.resourceName());
return doc;
}
private String resourceName() {
try {
String resourceName = this.resource.getFilename();
if (!StringUtils.hasText(resourceName)) {
resourceName = this.resource.getURI().toString();
}
return resourceName;
} catch (IOException e) {
return String.format("Invalid source URI: %s", e.getMessage());
}
}
}
DocumentTransformer(转换文档数据接口类)
package org.springframework.ai.document;
import java.util.List;
import java.util.function.Function;
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return (List)this.apply(transform);
}
}
TextSplitter
主要用于将长文本型 Document 拆分为多个较小的文本块(chunk),它为具体的文本分割策略(如按长度、按句子、按段落等)提供了通用框架
boolean copyContentFormatter:表示是否将文档内容格式化后,拆分复制到子文档中
| 方法名称 | 描述 |
| apply | 对输入文档列表进行拆分,返回拆分后的文档列表 |
| split | 拆分文档,返回拆分后的文档列表 |
| setCopyContentFormatter | 控制是否继承内容格式化器 |
| isCopyContentFormatter | 获取 copyContentFormatter 当前值 |
package org.springframework.ai.transformer.splitter;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.ContentFormatter;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
public abstract class TextSplitter implements DocumentTransformer {
private static final Logger logger = LoggerFactory.getLogger(TextSplitter.class);
private boolean copyContentFormatter = true;
public List<Document> apply(List<Document> documents) {
return this.doSplitDocuments(documents);
}
public List<Document> split(List<Document> documents) {
return this.apply(documents);
}
public List<Document> split(Document document) {
return this.apply(List.of(document));
}
public boolean isCopyContentFormatter() {
return this.copyContentFormatter;
}
public void setCopyContentFormatter(boolean copyContentFormatter) {
this.copyContentFormatter = copyContentFormatter;
}
private List<Document> doSplitDocuments(List<Document> documents) {
List<String> texts = new ArrayList();
List<Map<String, Object>> metadataList = new ArrayList();
List<ContentFormatter> formatters = new ArrayList();
for(Document doc : documents) {
texts.add(doc.getText());
metadataList.add(doc.getMetadata());
formatters.add(doc.getContentFormatter());
}
return this.createDocuments(texts, formatters, metadataList);
}
private List<Document> createDocuments(List<String> texts, List<ContentFormatter> formatters, List<Map<String, Object>> metadataList) {
List<Document> documents = new ArrayList();
for(int i = 0; i < texts.size(); ++i) {
String text = (String)texts.get(i);
Map<String, Object> metadata = (Map)metadataList.get(i);
List<String> chunks = this.splitText(text);
if (chunks.size() > 1) {
logger.info("Splitting up document into " + chunks.size() + " chunks.");
}
for(String chunk : chunks) {
Map<String, Object> metadataCopy = (Map)metadata.entrySet().stream().filter((e) -> e.getKey() != null && e.getValue() != null).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
Document newDoc = new Document(chunk, metadataCopy);
if (this.copyContentFormatter) {
newDoc.setContentFormatter((ContentFormatter)formatters.get(i));
}
documents.add(newDoc);
}
}
return documents;
}
protected abstract List<String> splitText(String text);
}
TokenTextSplitter
用于将文本按 token 拆分为指定大小块,基于 jtokit 库实现,适用于需要按 token 粒度处理文本的场景,如 LLM 的输入处理。
int chunkSize:每个文本块的目标 token 数量,默认为 800int minChunkSizeChars:每个文本块的最小字符数,默认为 350int minChunkLengthToEmbed:丢弃小于此长度的文本块,默认为 5int maxNumChunks:文本中生成的最大块数,默认为 10000boolean keepSeparator:是否保留分隔符(如换号符),默认EncodingRegistry registry:用于获取编码的注册表Encoding encoding:用于编码和解码的 token 的编码器
| 方法名称 | 描述 |
| splitText | 实现自 TextSplitter,将文本按 token 分块,返回分块后的字符串列表 |
| doSplit | 核心分块逻辑,按 token 长度切分文本 |
package org.springframework.ai.transformer.splitter;
import com.knuddels.jtokkit.Encodings;
import com.knuddels.jtokkit.api.Encoding;
import com.knuddels.jtokkit.api.EncodingRegistry;
import com.knuddels.jtokkit.api.EncodingType;
import com.knuddels.jtokkit.api.IntArrayList;
import java.util.ArrayList;
import java.util.List;
import java.util.Objects;
import org.springframework.util.Assert;
public class TokenTextSplitter extends TextSplitter {
private static final int DEFAULTCHUNKSIZE = 800;
private static final int MINCHUNKSIZECHARS = 350;
private static final int MINCHUNKLENGTHTOEMBED = 5;
private static final int MAXNUMCHUNKS = 10000;
private static final boolean KEEPSEPARATOR = true;
private final EncodingRegistry registry;
private final Encoding encoding;
private final int chunkSize;
private final int minChunkSizeChars;
private final int minChunkLengthToEmbed;
private final int maxNumChunks;
private final boolean keepSeparator;
public TokenTextSplitter() {
this(800, 350, 5, 10000, true);
}
public TokenTextSplitter(boolean keepSeparator) {
this(800, 350, 5, 10000, keepSeparator);
}
public TokenTextSplitter(int chunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator) {
this.registry = Encodings.newLazyEncodingRegistry();
this.encoding = this.registry.getEncoding(EncodingType.CL100KBASE);
this.chunkSize = chunkSize;
this.minChunkSizeChars = minChunkSizeChars;
this.minChunkLengthToEmbed = minChunkLengthToEmbed;
this.maxNumChunks = maxNumChunks;
this.keepSeparator = keepSeparator;
}
public static Builder builder() {
return new Builder();
}
protected List<String> splitText(String text) {
return this.doSplit(text, this.chunkSize);
}
protected List<String> doSplit(String text, int chunkSize) {
if (text != null && !text.trim().isEmpty()) {
List<Integer> tokens = this.getEncodedTokens(text);
List<String> chunks = new ArrayList();
int numchunks = 0;
while(!tokens.isEmpty() && numchunks < this.maxNumChunks) {
List<Integer> chunk = tokens.subList(0, Math.min(chunkSize, tokens.size()));
String chunkText = this.decodeTokens(chunk);
if (chunkText.trim().isEmpty()) {
tokens = tokens.subList(chunk.size(), tokens.size());
} else {
int lastPunctuation = Math.max(chunkText.lastIndexOf(46), Math.max(chunkText.lastIndexOf(63), Math.max(chunkText.lastIndexOf(33), chunkText.lastIndexOf(10))));
if (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) {
chunkText = chunkText.substring(0, lastPunctuation + 1);
}
String chunkTextToAppend = this.keepSeparator ? chunkText.trim() : chunkText.replace(System.lineSeparator(), " ").trim();
if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) {
chunks.add(chunkTextToAppend);
}
tokens = tokens.subList(this.getEncodedTokens(chunkText).size(), tokens.size());
++numchunks;
}
}
if (!tokens.isEmpty()) {
String remainingtext = this.decodeTokens(tokens).replace(System.lineSeparator(), " ").trim();
if (remainingtext.length() > this.minChunkLengthToEmbed) {
chunks.add(remainingtext);
}
}
return chunks;
} else {
return new ArrayList();
}
}
private List<Integer> getEncodedTokens(String text) {
Assert.notNull(text, "Text must not be null");
return this.encoding.encode(text).boxed();
}
private String decodeTokens(List<Integer> tokens) {
Assert.notNull(tokens, "Tokens must not be null");
IntArrayList tokensIntArray = new IntArrayList(tokens.size());
Objects.requireNonNull(tokensIntArray);
tokens.forEach(tokensIntArray::add);
return this.encoding.decode(tokensIntArray);
}
public static final class Builder {
private int chunkSize = 800;
private int minChunkSizeChars = 350;
private int minChunkLengthToEmbed = 5;
private int maxNumChunks = 10000;
private boolean keepSeparator = true;
private Builder() {
}
public Builder withChunkSize(int chunkSize) {
this.chunkSize = chunkSize;
return this;
}
public Builder withMinChunkSizeChars(int minChunkSizeChars) {
this.minChunkSizeChars = minChunkSizeChars;
return this;
}
public Builder withMinChunkLengthToEmbed(int minChunkLengthToEmbed) {
this.minChunkLengthToEmbed = minChunkLengthToEmbed;
return this;
}
public Builder withMaxNumChunks(int maxNumChunks) {
this.maxNumChunks = maxNumChunks;
return this;
}
public Builder withKeepSeparator(boolean keepSeparator) {
this.keepSeparator = keepSeparator;
return this;
}
public TokenTextSplitter build() {
return new TokenTextSplitter(this.chunkSize, this.minChunkSizeChars, this.minChunkLengthToEmbed, this.maxNumChunks, this.keepSeparator);
}
}
}
ContentFormatTransformer
对 Document 列表中的每个文档应用内容格式化器,以格式化文档
boolean disableTemplateRewrite:表示是否禁用内容格式化器的模版重写功能ContentFormatter contentFormatter:用于格式化文档内容的实例
package org.springframework.ai.transformer;
import java.util.ArrayList;
import java.util.List;
import org.springframework.ai.document.ContentFormatter;
import org.springframework.ai.document.DefaultContentFormatter;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
public class ContentFormatTransformer implements DocumentTransformer {
private final boolean disableTemplateRewrite;
private final ContentFormatter contentFormatter;
public ContentFormatTransformer(ContentFormatter contentFormatter) {
this(contentFormatter, false);
}
public ContentFormatTransformer(ContentFormatter contentFormatter, boolean disableTemplateRewrite) {
this.contentFormatter = contentFormatter;
this.disableTemplateRewrite = disableTemplateRewrite;
}
public List<Document> apply(List<Document> documents) {
if (this.contentFormatter != null) {
documents.forEach(this::processDocument);
}
return documents;
}
private void processDocument(Document document) {
ContentFormatter var4 = document.getContentFormatter();
if (var4 instanceof DefaultContentFormatter docFormatter) {
var4 = this.contentFormatter;
if (var4 instanceof DefaultContentFormatter toUpdateFormatter) {
this.updateFormatter(document, docFormatter, toUpdateFormatter);
return;
}
}
this.overrideFormatter(document);
}
private void updateFormatter(Document document, DefaultContentFormatter docFormatter, DefaultContentFormatter toUpdateFormatter) {
List<String> updatedEmbedExcludeKeys = new ArrayList(docFormatter.getExcludedEmbedMetadataKeys());
updatedEmbedExcludeKeys.addAll(toUpdateFormatter.getExcludedEmbedMetadataKeys());
List<String> updatedInterfaceExcludeKeys = new ArrayList(docFormatter.getExcludedInferenceMetadataKeys());
updatedInterfaceExcludeKeys.addAll(toUpdateFormatter.getExcludedInferenceMetadataKeys());
DefaultContentFormatter.Builder builder = DefaultContentFormatter.builder().withExcludedEmbedMetadataKeys(updatedEmbedExcludeKeys).withExcludedInferenceMetadataKeys(updatedInterfaceExcludeKeys).withMetadataTemplate(docFormatter.getMetadataTemplate()).withMetadataSeparator(docFormatter.getMetadataSeparator());
if (!this.disableTemplateRewrite) {
builder.withTextTemplate(docFormatter.getTextTemplate());
}
document.setContentFormatter(builder.build());
}
private void overrideFormatter(Document document) {
document.setContentFormatter(this.contentFormatter);
}
}
ContentFormatte(格式化接口类)
public interface ContentFormatter {
String format(Document document, MetadataMode mode);
}
DefaultContentFormatter
用于格式化 Document 对象的内容和元数据,通过模版和配置来控制文档显示方式
String metadataTemplate:元数据格式化模版,包含{key}和{value}占位符String metadataSeparator:元数据字段之间的分隔符String textTemplate:文档文本格式化模板,包含{content}和{metadatastring}占位符List<String> excludedInferenceMetadataKeys:在推理模式下排除的元数据键列表List<String> excludedEmbedMetadataKeys:在嵌入模式下排除的元数据键列表
package org.springframework.ai.document;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.stream.Collectors;
import org.springframework.util.Assert;
public final class DefaultContentFormatter implements ContentFormatter {
private static final String TEMPLATECONTENTPLACEHOLDER = "{content}";
private static final String TEMPLATEMETADATASTRINGPLACEHOLDER = "{metadatastring}";
private static final String TEMPLATEVALUEPLACEHOLDER = "{value}";
private static final String TEMPLATEKEYPLACEHOLDER = "{key}";
private static final String DEFAULTMETADATATEMPLATE = String.format("%s: %s", "{key}", "{value}");
private static final String DEFAULTMETADATASEPARATOR = System.lineSeparator();
private static final String DEFAULTTEXTTEMPLATE = String.format("%s\n\n%s", "{metadatastring}", "{content}");
private final String metadataTemplate;
private final String metadataSeparator;
private final String textTemplate;
private final List<String> excludedInferenceMetadataKeys;
private final List<String> excludedEmbedMetadataKeys;
private DefaultContentFormatter(Builder builder) {
this.metadataTemplate = builder.metadataTemplate;
this.metadataSeparator = builder.metadataSeparator;
this.textTemplate = builder.textTemplate;
this.excludedInferenceMetadataKeys = builder.excludedInferenceMetadataKeys;
this.excludedEmbedMetadataKeys = builder.excludedEmbedMetadataKeys;
}
public static Builder builder() {
return new Builder();
}
public static DefaultContentFormatter defaultConfig() {
return builder().build();
}
public String format(Document document, MetadataMode metadataMode) {
Map<String, Object> metadata = this.metadataFilter(document.getMetadata(), metadataMode);
String metadataText = (String)metadata.entrySet().stream().map((metadataEntry) -> this.metadataTemplate.replace("{key}", (CharSequence)metadataEntry.getKey()).replace("{value}", metadataEntry.getValue().toString())).collect(Collectors.joining(this.metadataSeparator));
return this.textTemplate.replace("{metadatastring}", metadataText).replace("{content}", document.getText());
}
protected Map<String, Object> metadataFilter(Map<String, Object> metadata, MetadataMode metadataMode) {
if (metadataMode == MetadataMode.ALL) {
return new HashMap(metadata);
} else if (metadataMode == MetadataMode.NONE) {
return new HashMap(Collections.emptyMap());
} else {
Set<String> usableMetadataKeys = new HashSet(metadata.keySet());
if (metadataMode == MetadataMode.INFERENCE) {
usableMetadataKeys.removeAll(this.excludedInferenceMetadataKeys);
} else if (metadataMode == MetadataMode.EMBED) {
usableMetadataKeys.removeAll(this.excludedEmbedMetadataKeys);
}
return new HashMap((Map)metadata.entrySet().stream().filter((e) -> usableMetadataKeys.contains(e.getKey())).collect(Collectors.toMap((e) -> (String)e.getKey(), (e) -> e.getValue())));
}
}
public String getMetadataTemplate() {
return this.metadataTemplate;
}
public String getMetadataSeparator() {
return this.metadataSeparator;
}
public String getTextTemplate() {
return this.textTemplate;
}
public List<String> getExcludedInferenceMetadataKeys() {
return Collections.unmodifiableList(this.excludedInferenceMetadataKeys);
}
public List<String> getExcludedEmbedMetadataKeys() {
return Collections.unmodifiableList(this.excludedEmbedMetadataKeys);
}
public static final class Builder {
private String metadataTemplate;
private String metadataSeparator;
private String textTemplate;
private List<String> excludedInferenceMetadataKeys;
private List<String> excludedEmbedMetadataKeys;
private Builder() {
this.metadataTemplate = DefaultContentFormatter.DEFAULTMETADATATEMPLATE;
this.metadataSeparator = DefaultContentFormatter.DEFAULTMETADATASEPARATOR;
this.textTemplate = DefaultContentFormatter.DEFAULTTEXTTEMPLATE;
this.excludedInferenceMetadataKeys = new ArrayList();
this.excludedEmbedMetadataKeys = new ArrayList();
}
public Builder from(DefaultContentFormatter fromFormatter) {
this.withExcludedEmbedMetadataKeys(fromFormatter.getExcludedEmbedMetadataKeys()).withExcludedInferenceMetadataKeys(fromFormatter.getExcludedInferenceMetadataKeys()).withMetadataSeparator(fromFormatter.getMetadataSeparator()).withMetadataTemplate(fromFormatter.getMetadataTemplate()).withTextTemplate(fromFormatter.getTextTemplate());
return this;
}
public Builder withMetadataTemplate(String metadataTemplate) {
Assert.hasText(metadataTemplate, "Metadata Template must not be empty");
this.metadataTemplate = metadataTemplate;
return this;
}
public Builder withMetadataSeparator(String metadataSeparator) {
Assert.notNull(metadataSeparator, "Metadata separator must not be empty");
this.metadataSeparator = metadataSeparator;
return this;
}
public Builder withTextTemplate(String textTemplate) {
Assert.hasText(textTemplate, "Document's text template must not be empty");
this.textTemplate = textTemplate;
return this;
}
public Builder withExcludedInferenceMetadataKeys(List<String> excludedInferenceMetadataKeys) {
Assert.notNull(excludedInferenceMetadataKeys, "Excluded inference metadata keys must not be null");
this.excludedInferenceMetadataKeys = excludedInferenceMetadataKeys;
return this;
}
public Builder withExcludedInferenceMetadataKeys(String... keys) {
Assert.notNull(keys, "Excluded inference metadata keys must not be null");
this.excludedInferenceMetadataKeys.addAll(Arrays.asList(keys));
return this;
}
public Builder withExcludedEmbedMetadataKeys(List<String> excludedEmbedMetadataKeys) {
Assert.notNull(excludedEmbedMetadataKeys, "Excluded Embed metadata keys must not be null");
this.excludedEmbedMetadataKeys = excludedEmbedMetadataKeys;
return this;
}
public Builder withExcludedEmbedMetadataKeys(String... keys) {
Assert.notNull(keys, "Excluded Embed metadata keys must not be null");
this.excludedEmbedMetadataKeys.addAll(Arrays.asList(keys));
return this;
}
public DefaultContentFormatter build() {
return new DefaultContentFormatter(this);
}
}
}
KeywordMetadataEnricher
从文档中提取关键词,并将其作为元数据添加到文档中。通过调用 ChatModel 生成关键词,并将关键词存储在文档的元数据中
ChatModel chatModel:与 LLM 交互,生成关键词int keywordCount:要提取的关键词数量
package org.springframework.ai.model.transformer;
import java.util.List;
import java.util.Map;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
import org.springframework.util.Assert;
public class KeywordMetadataEnricher implements DocumentTransformer {
public static final String CONTEXTSTRPLACEHOLDER = "contextstr";
public static final String KEYWORDSTEMPLATE = "{contextstr}. Give %s unique keywords for this\ndocument. Format as comma separated. Keywords:";
private static final String EXCERPTKEYWORDSMETADATAKEY = "excerptkeywords";
private final ChatModel chatModel;
private final int keywordCount;
public KeywordMetadataEnricher(ChatModel chatModel, int keywordCount) {
Assert.notNull(chatModel, "ChatModel must not be null");
Assert.isTrue(keywordCount >= 1, "Document count must be >= 1");
this.chatModel = chatModel;
this.keywordCount = keywordCount;
}
public List<Document> apply(List<Document> documents) {
for(Document document : documents) {
PromptTemplate template = new PromptTemplate(String.format("{contextstr}. Give %s unique keywords for this\ndocument. Format as comma separated. Keywords:", this.keywordCount));
Prompt prompt = template.create(Map.of("contextstr", document.getText()));
String keywords = this.chatModel.call(prompt).getResult().getOutput().getText();
document.getMetadata().putAll(Map.of("excerptkeywords", keywords));
}
return documents;
}
}
SummaryMetadataEnricher
用于从文档中提取摘要,并将其作为元数据添加到文档中。支持提取当前文档、前一个文档和下一个文档的摘要,并将这些摘要存储在文档的元数据中
-
ChatModel chatModel:与 LLM 交互,生成摘要 -
List<SummaryType> summaryTypes:要提取的摘要类型列表(当前、前一个、后一个) -
MetadataMode metadataMode:元数据模式,用于控制文档内容的格式化方式- ALL:格式化内容时包含所有元数据(如作者、页码、标题等),适合需要上下文丰富信息的场景
- EMBED:仅包含用于向量嵌入相关的元数据。通常用于向量数据库检索,保证只输出对嵌入有用的元数据,减少无关信息干扰
- INFERENCE:仅包含推理相关的元数据。适合推理、问答等场景,输出对模型推理有帮助的元数据,过滤掉无关内容
- NONE:只输出纯文本内容,不包含任何元数据,适合只关心正文的场景
-
String summaryTemplate:用于生成摘要的模版
package org.springframework.ai.model.transformer;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentTransformer;
import org.springframework.ai.document.MetadataMode;
import org.springframework.util.Assert;
import org.springframework.util.CollectionUtils;
public class SummaryMetadataEnricher implements DocumentTransformer {
public static final String DEFAULTSUMMARYEXTRACTTEMPLATE = "Here is the content of the section:\n{contextstr}\n\nSummarize the key topics and entities of the section.\n\nSummary:";
private static final String SECTIONSUMMARYMETADATAKEY = "sectionsummary";
private static final String NEXTSECTIONSUMMARYMETADATAKEY = "nextsectionsummary";
private static final String PREVSECTIONSUMMARYMETADATAKEY = "prevsectionsummary";
private static final String CONTEXTSTRPLACEHOLDER = "contextstr";
private final ChatModel chatModel;
private final List<SummaryType> summaryTypes;
private final MetadataMode metadataMode;
private final String summaryTemplate;
public SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes) {
this(chatModel, summaryTypes, "Here is the content of the section:\n{contextstr}\n\nSummarize the key topics and entities of the section.\n\nSummary:", MetadataMode.ALL);
}
public SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode) {
Assert.notNull(chatModel, "ChatModel must not be null");
Assert.hasText(summaryTemplate, "Summary template must not be empty");
this.chatModel = chatModel;
this.summaryTypes = CollectionUtils.isEmpty(summaryTypes) ? List.of(SummaryMetadataEnricher.SummaryType.CURRENT) : summaryTypes;
this.metadataMode = metadataMode;
this.summaryTemplate = summaryTemplate;
}
public List<Document> apply(List<Document> documents) {
List<String> documentSummaries = new ArrayList();
for(Document document : documents) {
String documentContext = document.getFormattedContent(this.metadataMode);
Prompt prompt = (new PromptTemplate(this.summaryTemplate)).create(Map.of("contextstr", documentContext));
documentSummaries.add(this.chatModel.call(prompt).getResult().getOutput().getText());
}
for(int i = 0; i < documentSummaries.size(); ++i) {
Map<String, Object> summaryMetadata = this.getSummaryMetadata(i, documentSummaries);
((Document)documents.get(i)).getMetadata().putAll(summaryMetadata);
}
return documents;
}
private Map<String, Object> getSummaryMetadata(int i, List<String> documentSummaries) {
Map<String, Object> summaryMetadata = new HashMap();
if (i > 0 && this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.PREVIOUS)) {
summaryMetadata.put("prevsectionsummary", documentSummaries.get(i - 1));
}
if (i < documentSummaries.size() - 1 && this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.NEXT)) {
summaryMetadata.put("nextsectionsummary", documentSummaries.get(i + 1));
}
if (this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.CURRENT)) {
summaryMetadata.put("sectionsummary", documentSummaries.get(i));
}
return summaryMetadata;
}
public static enum SummaryType {
PREVIOUS,
CURRENT,
NEXT;
}
}
DocumentWriter(文档写入接口类)
package org.springframework.ai.document;
import java.util.List;
import java.util.function.Consumer;
public interface DocumentWriter extends Consumer<List<Document>> {
default void write(List<Document> documents) {
this.accept(documents);
}
}
FileDocumentWriter
将一组 Document 文档对象的内容写入到指定文件,支持追加写入、文档分隔标记、元数据格式化等功能
String fileName:写入文件的名称boolean withDocumentMarkers:表示是否在文件中包含文档标记(如文档索引、页码)MetadataMode metadataMode:元数据模式,控制文档内容的格式化方式boolean append:是否将内容追加到文件末尾,而不是覆盖
| 方法名称 | 描述 |
| FileDocumentWriter | 通过文件名、分隔标记、元数据、追加等构造写入器 |
| accept | 将文档内容写入文件,支持分隔标记和元数据格式化 |
package org.springframework.ai.writer;
import java.io.FileWriter;
import java.util.List;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentWriter;
import org.springframework.ai.document.MetadataMode;
import org.springframework.util.Assert;
public class FileDocumentWriter implements DocumentWriter {
public static final String METADATASTARTPAGENUMBER = "pagenumber";
public static final String METADATAENDPAGENUMBER = "endpagenumber";
private final String fileName;
private final boolean withDocumentMarkers;
private final MetadataMode metadataMode;
private final boolean append;
public FileDocumentWriter(String fileName) {
this(fileName, false, MetadataMode.NONE, false);
}
public FileDocumentWriter(String fileName, boolean withDocumentMarkers) {
this(fileName, withDocumentMarkers, MetadataMode.NONE, false);
}
public FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append) {
Assert.hasText(fileName, "File name must have a text.");
Assert.notNull(metadataMode, "MetadataMode must not be null.");
this.fileName = fileName;
this.withDocumentMarkers = withDocumentMarkers;
this.metadataMode = metadataMode;
this.append = append;
}
public void accept(List<Document> docs) {
try {
try (FileWriter writer = new FileWriter(this.fileName, this.append)) {
int index = 0;
for(Document doc : docs) {
if (this.withDocumentMarkers) {
writer.write(String.format("%n### Doc: %s, pages:[%s,%s]\n", index, doc.getMetadata().get("pagenumber"), doc.getMetadata().get("endpagenumber")));
}
writer.write(doc.getFormattedContent(this.metadataMode));
++index;
}
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
VectorStore
VectorStore 继承了 DocumentWriter 接口,详情可见 《Vector Databases》