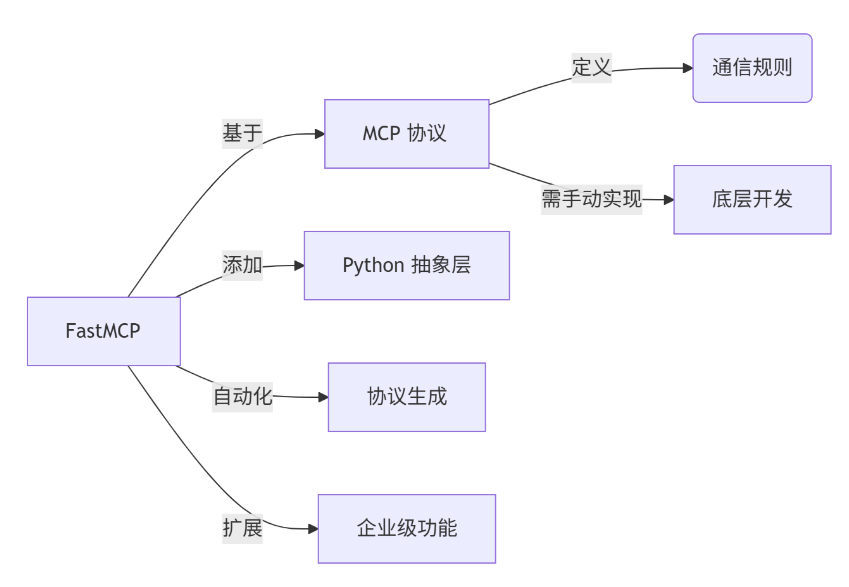
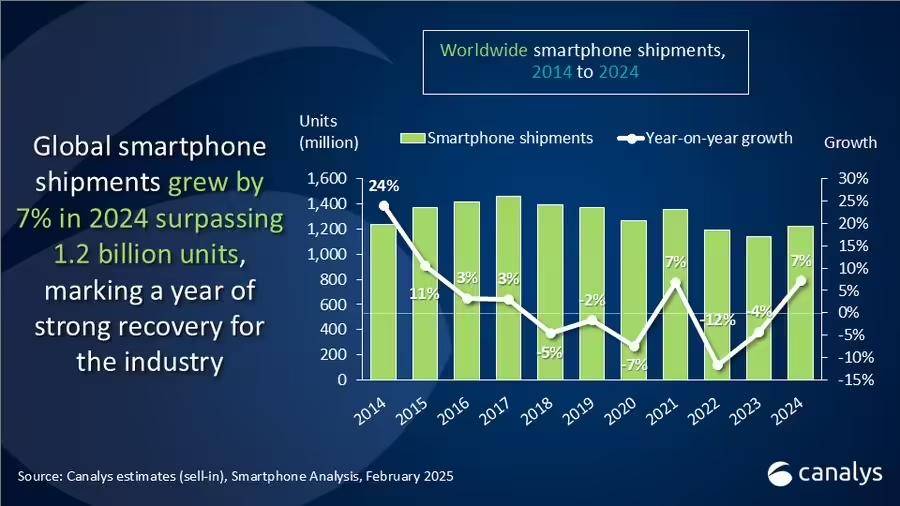
cacti导出的1分钟监控数据csv文件读取并按5分钟求平均值,然后计算95计费值,假设31天的月份
import pandas as pd
import openpyxl
from openpyxl.styles import Font
from openpyxl.utils.dataframe import dataframe_to_rows
import os
import chardet
import numpy as np
# 文件路径
file_path = r'E:\data\feishu\BGP-CT-SN-同道新龙-9K-IN-AG.csv'
output_dir = r'E:\data\feishu'
output_file = os.path.join(output_dir, "处理结果.xlsx")
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
print(f"开始处理文件: {file_path}")
# 第一步:检测文件编码
def detect_encoding(file_path):
print("检测文件编码...")
with open(file_path, 'rb') as f:
rawdata = f.read(10000)
result = chardet.detect(rawdata)
encoding = result['encoding']
confidence = result['confidence']
print(f"检测到编码: {encoding} (置信度: {confidence:.2%})")
return encoding
# 第二步:读取文件并正确分割列
try:
# 检测文件编码
file_encoding = detect_encoding(file_path)
# 如果置信度低,尝试常见中文编码
if file_encoding is None or file_encoding.lower() == 'ascii':
print("编码检测置信度低,尝试常见中文编码")
for encoding in ['gb18030', 'gbk', 'big5', 'utf-8']:
try:
# 读取前5行检查实际分隔符
with open(file_path, 'r', encoding=encoding) as f:
sample_lines = [f.readline().strip() for _ in range(5)]
# 分析最可能的分隔符
possible_seps = [',', '\t', ';', '|']
sep_counts = {sep: line.count(sep) for sep in possible_seps for line in sample_lines}
most_common_sep = max(sep_counts, key=sep_counts.get)
print(f"检测到最可能的分隔符: '{most_common_sep}'")
# 使用检测到的分隔符读取文件
df = pd.read_csv(file_path, sep=most_common_sep, encoding=encoding, header=None)
print(f"成功使用 {encoding} 编码和分隔符 '{most_common_sep}' 读取文件")
# 手动设置列名(根据列数)
if df.shape[1] == 3:
df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']
print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")
else:
raise Exception(f"列数异常: {df.shape[1]}列,应为3列")
break
except Exception as e:
print(f"尝试 {encoding} 编码失败: {e}")
continue
else:
raise Exception("无法使用常见中文编码读取文件")
else:
# 读取前5行检查实际分隔符
with open(file_path, 'r', encoding=file_encoding) as f:
sample_lines = [f.readline().strip() for _ in range(5)]
# 分析最可能的分隔符
possible_seps = [',', '\t', ';', '|']
sep_counts = {sep: line.count(sep) for sep in possible_seps for line in sample_lines}
most_common_sep = max(sep_counts, key=sep_counts.get)
print(f"检测到最可能的分隔符: '{most_common_sep}'")
# 使用检测到的分隔符读取文件
df = pd.read_csv(file_path, sep=most_common_sep, encoding=file_encoding, header=None)
print(f"使用检测到的编码 {file_encoding} 和分隔符 '{most_common_sep}' 成功读取文件")
# 手动设置列名(根据列数)
if df.shape[1] == 3:
df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']
print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")
else:
raise Exception(f"列数异常: {df.shape[1]}列,应为3列")
except Exception as e:
print(f"文件读取失败: {e}")
print("尝试使用错误恢复模式读取...")
try:
# 尝试使用错误恢复模式
df = pd.read_csv(file_path, sep=None, engine='python', encoding='gb18030',
on_bad_lines='skip', header=None)
print("使用错误恢复模式成功读取文件(可能丢失部分数据)")
# 手动设置列名(根据列数)
if df.shape[1] == 3:
df.columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']
print("手动设置列名为: Date, Total IN-MAX, Total OUT-MAX")
else:
raise Exception(f"列数异常: {df.shape[1]}列,应为3列")
except:
raise Exception("无法读取文件,请手动检查文件格式和编码")
print(f"成功读取数据,行数: {len(df)}")
print("df.columns:", df.columns)
# 检查必要列是否存在
required_columns = ['Date', 'Total IN-MAX', 'Total OUT-MAX']
print("检查必要列...")
for col in df.columns:
print(f'列名: {col} (类型: {type(col)})')
if not all(col in df.columns for col in required_columns):
missing = [col for col in required_columns if col not in df.columns]
raise Exception(f"文件缺少必要列: {missing}")
else:
print("所有必要列都存在")
# 转换数值列为浮点数
print("转换数值列为浮点数...")
for col in ['Total IN-MAX', 'Total OUT-MAX']:
# 先尝试直接转换
df[col] = pd.to_numeric(df[col], errors='coerce')
# 检查转换失败的行
failed_conversions = df[col].isna().sum()
if failed_conversions > 0:
print(f"警告: {col} 列有 {failed_conversions} 个值无法直接转换")
# 尝试更复杂的转换(处理科学计数法)
def try_convert(val):
try:
return float(val)
except:
# 尝试处理可能连接在一起的多个数值
if isinstance(val, str) and 'e+' in val:
parts = []
current = ""
for char in val:
if char in '0123456789.e+-':
current += char
elif current:
try:
parts.append(float(current))
current = ""
except:
current = ""
if current:
try:
parts.append(float(current))
except:
pass
if parts:
return np.mean(parts)
return np.nan
# 应用复杂转换
df[col] = df[col].apply(try_convert)
# 再次检查失败转换
still_failed = df[col].isna().sum()
if still_failed > 0:
print(f"仍有 {still_failed} 个值无法转换,将被设为NaN")
# 重命名列以便后续处理
df = df.rename(columns={
'Date': '日期',
'Total IN-MAX': 'Total_in',
'Total OUT-MAX': 'Total_out'
})
# 转换日期列
print("处理日期列...")
try:
# 尝试多种日期格式
df['日期'] = pd.to_datetime(df['日期'], format='%Y/%m/%d %H:%M', errors='coerce')
if df['日期'].isna().any():
print("尝试替代日期格式...")
df['日期'] = pd.to_datetime(df['日期'], format='%Y-%m-%d %H:%M:%S', errors='coerce')
# 检查是否有无效日期
invalid_dates = df['日期'].isna().sum()
if invalid_dates > 0:
print(f"警告: 发现 {invalid_dates} 个无效日期")
# 删除无效日期的行
df = df.dropna(subset=['日期'])
print(f"删除无效日期行后剩余: {len(df)} 行")
except Exception as e:
print(f"日期转换错误: {e}")
raise
# 设置日期为索引并排序
df.set_index('日期', inplace=True)
df.sort_index(inplace=True) # 确保时间顺序正确
print(f"处理后数据点数: {len(df)}")
# 每5分钟重采样求平均值 - 使用新的频率表示法
print("进行5分钟重采样...")
resampled = df.resample('5min').mean()
resampled.columns = ['Total_in_avg', 'Total_out_avg']
# 计算每个5分钟区间的最大值
resampled['max_value'] = resampled[['Total_in_avg', 'Total_out_avg']].max(axis=1)
# 对所有5分钟区间的最大值进行降序排序
sorted_max = resampled['max_value'].sort_values(ascending=False).reset_index()
sorted_max.columns = ['时间区间', '降序最大值']
# 创建Excel工作簿
print("创建Excel工作簿...")
wb = openpyxl.Workbook()
# 工作表1: 原始数据
ws1 = wb.active
ws1.title = "原始数据"
for r in dataframe_to_rows(df.reset_index(), index=False, header=True):
ws1.append(r)
# 工作表2: 5分钟平均值和最大值
ws2 = wb.create_sheet("5分钟平均值")
# 准备数据
avg_data = resampled.reset_index()
avg_data.columns = ['时间区间', 'Total_in_avg', 'Total_out_avg', 'max_value']
for r in dataframe_to_rows(avg_data, index=False, header=True):
ws2.append(r)
# 工作表3: 降序最大值序列
ws3 = wb.create_sheet("降序最大值")
for r in dataframe_to_rows(sorted_max, index=False, header=True):
ws3.append(r)
# 标记第447个值为红色(如果存在)
if len(sorted_max) >= 447:
# 第447行(表头占第1行,数据从第2行开始)
target_row = 447 + 1
ws3.cell(row=target_row, column=2).font = Font(color="FF0000", bold=True)
# 添加注释说明
ws3.cell(row=1, column=3, value="说明")
ws3.cell(row=2, column=3, value=f"第447个最大值已用红色标记 (值={sorted_max.iloc[446]['降序最大值']:.2e})")
ws3.cell(row=target_row, column=3, value="← 第447个最大值")
print(f"已标记第447个值: {sorted_max.iloc[446]['降序最大值']:.2e}")
else:
print(f"警告: 数据不足447个点 (只有{len(sorted_max)}个点)")
# 自动调整列宽
print("调整列宽...")
for sheet in wb.sheetnames:
ws = wb[sheet]
for col_idx, column in enumerate(ws.columns, 1):
max_length = 0
for cell in column:
try:
value = str(cell.value) if cell.value is not None else ""
if len(value) > max_length:
max_length = len(value)
except:
pass
adjusted_width = min(max_length + 2, 50) # 限制最大宽度为50
ws.column_dimensions[openpyxl.utils.get_column_letter(col_idx)].width = adjusted_width
# 保存Excel文件
print(f"保存Excel文件到: {output_file}")
wb.save(output_file)
print("处理完成!")
print("\n=== 处理结果统计 ===")
print(f"原始数据点数: {len(df)}")
print(f"5分钟区间数: {len(resampled)}")
print(f"最大值序列长度: {len(sorted_max)}")
if len(sorted_max) >= 447:
print(f"第447个最大值: {sorted_max.iloc[446]['降序最大值']:.2e}")