每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

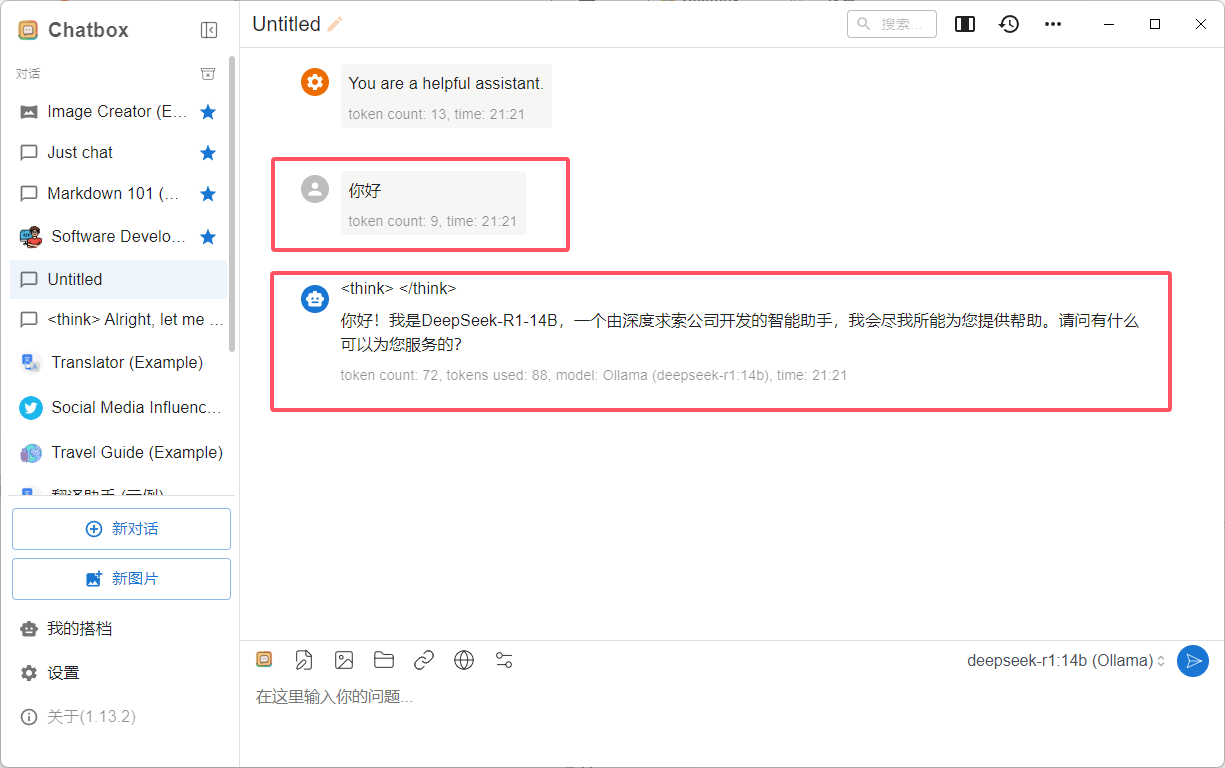
在一场技术实验中,我们在 Google Colab 上利用开源工具,演示了如何在不重新训练模型的前提下,为大型语言模型(LLM)添加“记忆”功能。通过集成 FAISS 向量检索、LangChain 工作流和 Sentence Transformers 嵌入模型,该系统实现了动态知识注入、模拟遗忘、处理记忆冲突以及时间偏好排序等行为。
🎯 实验目标
- 注入模型从未学过的事实(如:“狗狗 YoYo 喜欢胡萝卜”)
- 模拟“遗忘”机制
- 处理前后矛盾的信息(如:“YoYo 现在讨厌胡萝卜”)
- 实现“时间偏好”逻辑(更倾向于检索最近的信息)
🛠️ 技术配置:LangChain + FAISS + Sentence Transformers
系统构建过程如下:
pythonCopyEditfrom langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
import faiss
import numpy as np
import time
# 加载嵌入模型
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
print("Embedding model loaded.")
# 创建 FAISS 索引
sample_embedding = embedding_model.embed_query("test")
dimension = np.array(sample_embedding).shape[0]
index = faiss.IndexFlatL2(dimension)
print("FAISS index initialized.")
# 初始化 FAISS 向量存储
faiss_store = FAISS(embedding_model.embed_query, index, {}, {})
print("FAISS vector store initialized.")
🧠 添加记忆与查询记忆的函数
pythonCopyEdit# 添加记忆函数
def add_memory(text, reason):
metadata = {'reason': reason, 'timestamp': time.time()}
doc = Document(page_content=text, metadata=metadata)
faiss_store.add_documents([doc])
print(f"Added to memory: {text}")
# 查询记忆函数
def retrieve_memory(query):
retrieved_docs = faiss_store.similarity_search(query, k=1)
if retrieved_docs:
print(f"Retrieved: {retrieved_docs[0].page_content}")
else:
print("No relevant information found.")
🧪 实验部分:知识注入、遗忘、矛盾更新、时间偏好
1️⃣ 注入新知识
pythonCopyEditadd_memory("My dog's name is YoYo and he loves carrots.", "initial fact")
retrieve_memory("What does my dog love?")
输出结果:
vbnetCopyEditAdded to memory: My dog's name is YoYo and he loves carrots.
Retrieved: My dog's name is YoYo and he loves carrots.
📌 分析:系统成功存储并检索新事实,表明具备动态注入知识的能力。
2️⃣ 模拟遗忘机制
pythonCopyEdit# 清空 FAISS 索引
faiss_store.index.reset()
print("Memory cleared.")
# 尝试再次检索
retrieve_memory("What does my dog love?")
输出结果:
pgsqlCopyEditMemory cleared.
No relevant information found.
📌 分析:通过清空向量索引,系统“遗忘”了原先的信息。
3️⃣ 处理前后矛盾的记忆更新
pythonCopyEditadd_memory("My dog's name is YoYo and he hates carrots.", "contradictory update")
retrieve_memory("What does my dog love?")
输出结果:
vbnetCopyEditAdded to memory: My dog's name is YoYo and he hates carrots.
Retrieved: My dog's name is YoYo and he hates carrots.
📌 分析:系统将新信息覆盖旧记忆,默认以“最近添加”为准,成功处理冲突。
4️⃣ 实现时间偏好(Recency Bias)
pythonCopyEditadd_memory("My dog's name is YoYo and he is indifferent to carrots.", "updated preference")
retrieve_memory("What does my dog feel about carrots?")
输出结果:
vbnetCopyEditAdded to memory: My dog's name is YoYo and he is indifferent to carrots.
Retrieved: My dog's name is YoYo and he is indifferent to carrots.
📌 分析:最新信息被成功检索,说明系统能根据时间排序优先返回更新内容。
📦 完整代码参考(含时间偏好查询与记忆清空)
pythonCopyEditimport time
from uuid import uuid4
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_core.documents import Document
import faiss
import numpy as np
# 加载嵌入模型
embedding_model = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2")
print("Loading embedding model...")
# 初始化 FAISS 索引
dimension = np.array(embedding_model.embed_query("test")).shape[0]
index = faiss.IndexFlatL2(dimension)
# 初始化文档存储
docstore = InMemoryDocstore()
# 初始化索引到文档 ID 映射
index_to_docstore_id = {}
# 创建 FAISS 向量存储
print("Initializing FAISS vector store...")
faiss_index = FAISS(
embedding_function=embedding_model,
index=index,
docstore=docstore,
index_to_docstore_id=index_to_docstore_id
)
# 添加事实到记忆
def add_fact(fact_text, reason):
print(f"\n Adding to memory: {fact_text}")
metadata = {'reason': reason, 'timestamp': time.time()}
doc = Document(page_content=fact_text, metadata=metadata)
faiss_index.add_documents([doc])
print(f"Fact added with metadata: {metadata}")
# 查询记忆
def query_memory(query_text):
print(f"\n Querying memory for: '{query_text}'")
results = faiss_index.similarity_search(query_text, k=1)
if results:
top_result = results[0].page_content
print(f" Retrieved: {top_result}")
return top_result
else:
print("No relevant information found.")
return None
# 清除所有记忆
def clear_memory():
print("\n Clearing memory...")
faiss_index.index.reset()
faiss_index.docstore = InMemoryDocstore()
faiss_index.index_to_docstore_id = {}
print("Memory cleared.")
# 基于时间排序的查询
def query_with_recency(query_text):
print(f"\n Querying with recency for: '{query_text}'")
results = faiss_index.similarity_search(query_text, k=5)
if not results:
print("No relevant information found.")
return None
results.sort(key=lambda x: x.metadata.get('timestamp', 0), reverse=True)
top_result = results[0].page_content
print(f"Retrieved (most recent): {top_result}")
return top_result
# 实验流程
add_fact("My dog's name is YoYo and he loves carrots.", reason="initial fact")
query_memory("What does my dog love?")
clear_memory()
query_memory("What does my dog love?")
add_fact("My dog's name is YoYo and he hates carrots.", reason="contradictory update")
query_memory("What does my dog love?")
add_fact("My dog's name is YoYo and he is indifferent to carrots.", reason="updated preference")
query_with_recency("What does my dog feel about carrots?")
📍 总结与未来展望
此次实验验证了在推理阶段通过外部记忆系统增强LLM能力的可行性,主要涵盖以下几点:
- ✅ 可即时注入新知识
- ✅ 能模拟“遗忘”行为
- ✅ 可处理信息矛盾
- ✅ 支持按时间优先级检索
🔭 后续优化建议
- 智能遗忘机制:引入时间衰减、容量限制或信息价值打分;
- 多版本记忆管理:保留多个版本并支持冲突检测;
- 混合排序策略:结合语义相似度与时间因素进行记忆排序;
- 扩展性提升:支持 Pinecone、Weaviate 等分布式向量存储;
- 与 LLM 提示融合:将检索出的记忆动态嵌入模型提示上下文;
- 构建结构化记忆体系:例如情节性、语义性与工作记忆等模块化架构。
本实验为理解和构建具“记忆力”的语言模型系统提供了重要起点。随着架构与逻辑不断优化,有望迈出通用型 AI 记忆系统的第一步。

![[总结]前端性能指标分析、性能监控与分析、Lighthouse性能评分分析](https://i-blog.csdnimg.cn/direct/fd33901551484f66b843dea8946638ca.png)