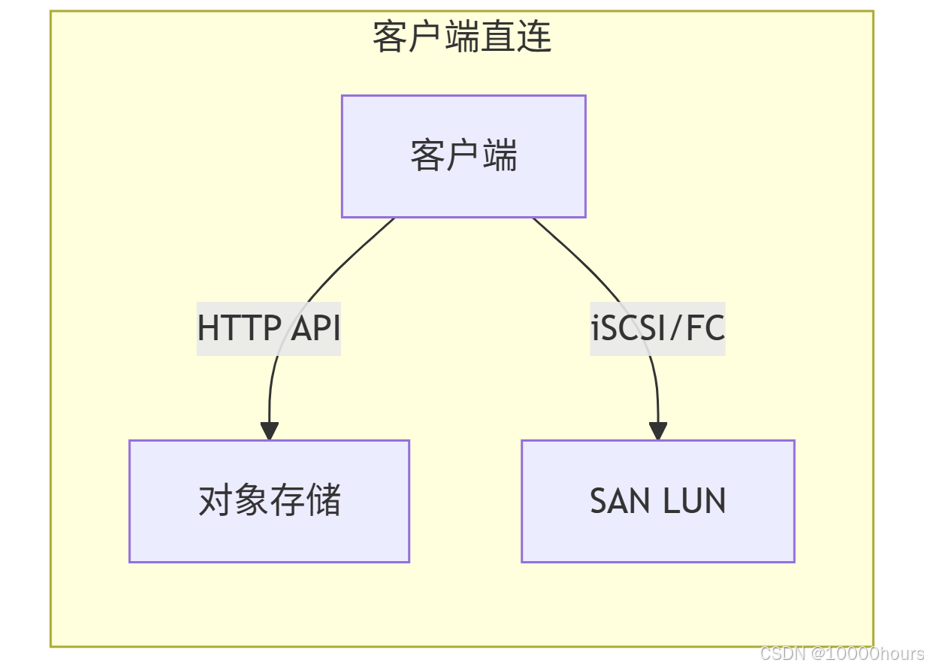
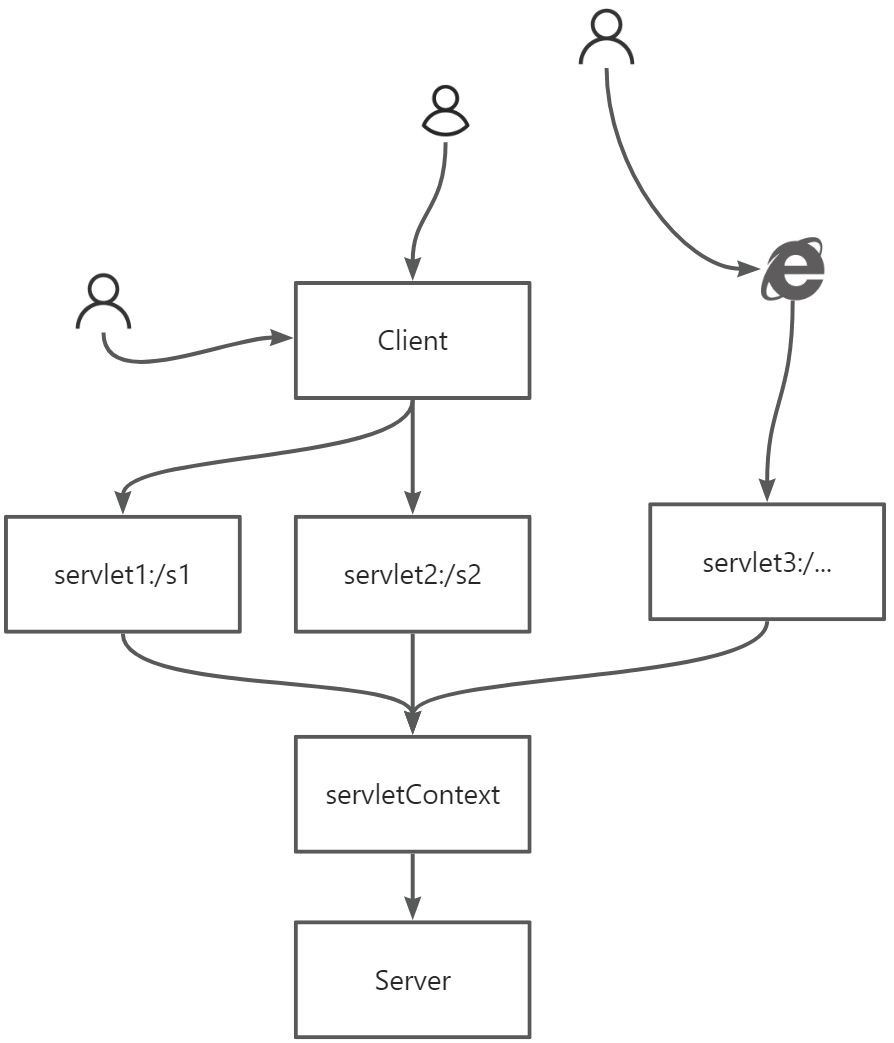
此项目可以理解为MySQL数据迁移,由Flink Stream监听MySQL的Binlog日志写入Kafka,在Kafka消费端将消息写入Doris或其他外部对象存储。
涉及的环境与版本
| 组件 | 版本 |
|---|---|
| flink | 1.20.1 |
| flink-cdc | 3.4.0 |
| kafka | 2.13-4.0.0 |
| Dragonwell | 17 |
引入相关依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>etl</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.20.1</flink.version>
<flink-cdc.version>3.4.0</flink-cdc.version>
<kafka-clients.version>3.3.1</kafka-clients.version>
<fastjson.version>1.2.83</fastjson.version>
<aliyun-sdk-oss.version>3.18.2</aliyun-sdk-oss.version>
<lombok.version>1.18.30</lombok.version>
<hadoop.version>3.3.6</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>${flink-cdc.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka-clients.version}</version>
</dependency>
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>${aliyun-sdk-oss.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.12.3</version>
</dependency>
</dependencies>
</project>
主程序入口,flinck cdc监听mysql binlog
package org.example;
import com.google.common.collect.ImmutableMap;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.cdc.connectors.mysql.source.MySqlSource;
import org.apache.flink.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.time.Duration;
public class ConditionalEventSync {
public static void main(String[] args) throws Exception {
// 配置源mysql连接信息
MySqlSource<String> source =
MySqlSource.<String>builder().hostname("xxx").port(3306)
.databaseList("xx").tableList("xx").username("xx")
.password("xx").deserializer(new JsonDebeziumDeserializationSchema())
// 优化项
.splitSize(50) // 表快照分片数(默认30)
.fetchSize(1024) // 每次fetch行数(默认1024)
.connectTimeout(Duration.ofSeconds(30))
.connectionPoolSize(5) // 连接池大小(默认3)
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(3000);
env.fromSource(source, WatermarkStrategy.noWatermarks(), "MySQL Source").flatMap(new EventFilterFunction())
// 将监听到的数据写入kafka
.addSink(new KafkaSink("event_tracking"));
env.setParallelism(4);
env.enableCheckpointing(10000);
// 避免因大数据量写入状态后端(如 RocksDB)导致 Checkpoint 超时
env.getCheckpointConfig().setCheckpointTimeout(60000);
// todo 大表快照可能导致频繁 Full GC,启动参数增大堆内存
env.execute("Conditional Event Tracking Sync");
}
public static class EventFilterFunction implements FlatMapFunction<String, String> {
@Override
public void flatMap(String json, Collector<String> out) {
// JSONObject event = JSONObject.parseObject(json);
// // 条件1:只同步特定类型
// if (event.getIntValue("type") == 2) return;
// // 条件2:过滤测试IP段
// if (event.getString("ip").startsWith("192.168.")) return;
out.collect(json);
}
}
}
将监听到的binlog日志写入kafka
kafka需要先创建对应的topic,UI客户端可以使用https://github.com/obsidiandynamics/kafdrop
package org.example;
import java.util.Properties;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaSink implements SinkFunction<String> {
private transient KafkaProducer<String, String> producer;
private final String topic;
public KafkaSink(String topic) {
this.topic = topic;
}
@Override
public void invoke(String value, Context context) {
if (producer == null) {
producer = createKafkaProducer();
}
System.out.println("【KafkaSink】Sending event to Kafka.topic: "+topic+",body:" + value);
producer.send(new ProducerRecord<>(topic, value));
}
private KafkaProducer<String, String> createKafkaProducer() {
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1:9092"); // Kafka broker 地址
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer<>(props);
}
public void close() throws Exception {
if (producer != null) {
producer.close();
}
}
}
监听到的binlog数据如下,根据op字段判断监听到的数据变更是新增、更新还是删除,消费端需要区分做对应的处理。
{
"before": null,
"after": {
"id": 3,
"type": 1,
"tag": "pay_enter",
"user_id": 23,
"ip": null,
"client": null,
"create_time": 1744045915000
},
"source": {
"version": "1.9.8.Final",
"connector": "mysql",
"name": "mysql_binlog_source",
"ts_ms": 0,
"snapshot": "false",
"db": "linda_source",
"sequence": null,
"table": "event_tracking",
"server_id": 0,
"gtid": null,
"file": "",
"pos": 0,
"row": 0,
"thread": null,
"query": null
},
"op": "r",
"ts_ms": 1745309434361,
"transaction": null
}
kafka消费端可以单独起个项目部署在其他服务器
package org.example;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.time.Duration;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
import java.util.Base64;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.http.HttpHeaders;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.parquet.column.ParquetProperties;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.LogicalTypeAnnotation;
import org.apache.parquet.schema.MessageType;
import org.apache.parquet.schema.PrimitiveType;
import org.apache.parquet.schema.Types;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.google.common.collect.Lists;
public class KafkaConsumer {
public static void main(String[] args) {
// ===================kafka消费==================
Properties props = new Properties();
props.put("bootstrap.servers", "127.0.0.1:9092"); // Kafka broker 地址
props.put("group.id", "test-group"); // 消费者组 ID
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
org.apache.kafka.clients.consumer.KafkaConsumer<String, String> consumer =
new org.apache.kafka.clients.consumer.KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("tool_event_tracking")); // 订阅 topic
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf(
"【KafkaConsumer】Received message: topic = %s, partition = %d, offset = %d, key = %s, value = %s%n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
handleMqEvent(record.value());
}
}
} finally {
consumer.close();
}
}
public static void handleMqEvent(String event) {
System.out.println("handleMqEvent接收内容:" + event);
JSONObject value = JSONObject.parseObject(event);
String op = value.getString("op");// u:更新,r:新增,d:删除
JSONObject before = value.getJSONObject("before");
JSONObject after = value.getJSONObject("after");
String userId = null;
String path = null;
switch (op) {
case "c":
// 新增
saveToDoris(Lists.newArrayList(after.toJavaObject(EventTrackingEntity.class)));
break;
case "d":
userId = before.getString("user_id");
// 删除
// todo
break;
case "u":
userId = after.getString("user_id");
// 更新
// todo
break;
}
}
public static String saveToDoris(List<EventTrackingEntity> dataList) {
String jdbcUrl = "jdbc:mysql://172.20.89.65:9030/devops";
String username = "root";
String password = "";
String insertSQL =
"INSERT INTO event_tracking (id, type, tag, user_id, ip, client, create_time) VALUES (?, ?, ?, ?, ?, ?, ?)";
try (Connection conn = DriverManager.getConnection(jdbcUrl, username, password);
PreparedStatement ps = conn.prepareStatement(insertSQL)) {
// 设置自动提交为 false,提高性能
conn.setAutoCommit(false);
for (EventTrackingEntity item : dataList) {
ps.setLong(1, item.getId() != null ? item.getId() : 0);
ps.setInt(2, item.getType() != null ? item.getType() : 0);
ps.setString(3, item.getTag());
ps.setLong(4, item.getUserId() != null ? item.getUserId() : 0);
ps.setString(5, item.getIp());
ps.setString(6, item.getClient());
ps.setLong(7, item.getCreateTime().toEpochSecond(ZoneOffset.UTC));
ps.addBatch();
}
int[] result = ps.executeBatch();
conn.commit();
System.out.println("批量插入完成,影响记录数:" + result.length);
return "Success";
} catch (SQLException e) {
throw new RuntimeException("JDBC 写入 Doris 出错", e);
}
}
}