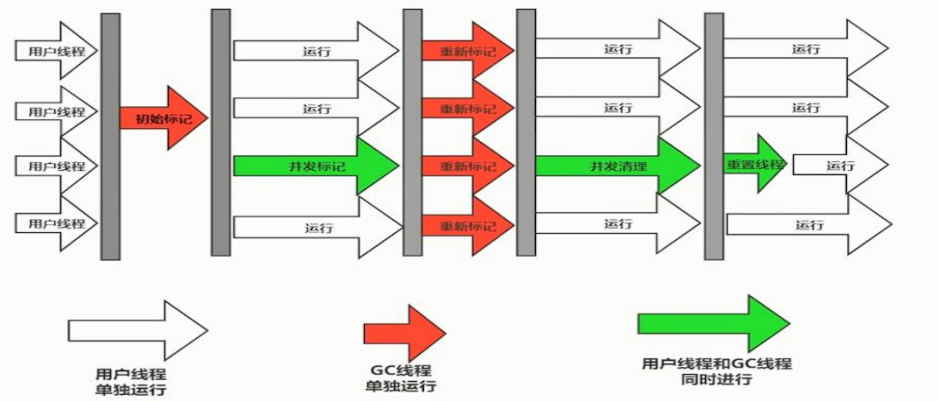
一、基本思想
(分支限界, 分枝限界, 分支界限 文献不同说法但都是一样的)
分支限界法类似于回溯法,也是一种在问题的解空间树上搜索问题解的算法。
但一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出解空间树中满足约束条件的所有解(或一个解),而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
分支限界法与回溯法对解空间的搜索方式不同:
- 回溯法按深度优先策略搜索解空间;
- 分支限界法以广度优先或以最小耗费优先的方式搜索解空间。
分支限界法的搜索策略是广度优先或以最小耗费优先的方式搜索:
- 在扩展结点处,先生成其所有的儿子结点(分支),然后再从当前的活结点表中选择下一个扩展结点。
- 为了有效地选择下一个扩展结点,加速搜索的进程,在每一个活结点处,计算一个函数值(限界),并根据函数值,从当前活结点表中选择一个最有利的结点作为扩展结点,使搜索朝着解空间上有最优解的分支推进,以便尽快地找出一个最优解。
搜索解空间时,分支限界法与回溯法的主要区别在于它们对当前扩展结点所采用的扩展方式不同。在分支限界法中,每一个活结点只有一次机会成为扩展结点。活结点一旦成为扩展结点,就一次性产生其所有儿子结点。在这些儿子结点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子结点被加入活结点表中。
分支限界法与回溯法的主要区别
| 方法 | 解空间搜索方式 | 存储结点的数据结构 | 结点存储特性 | 常用应用 |
|---|---|---|---|---|
| 回溯法 | 深度优先 | 栈 | 活结点的所有可行子结点被遍历后才从栈中出栈 | 找出满足条件的所有解 |
| 分支限界法 | 广度优先 | 队列,优先 队列 | 每个结点只有一次 成为活结点的机会 | 找出满足条件一个解或 者特定意义的最优解 |
二、分支限界法的设计思想
- 设计合适的限界函数
- 组织活结点表
- 确定最优解的解向量
2.1 设计合适的限界函数
在搜索解空间树时,每个活结点可能有很多孩子结点,其中有些孩子结点搜索下去是不可能产生问题解或最优解的。
可以设计好的限界函数在扩展时删除这些不必要的孩子结点,从而提高搜索效率
假设活结点si有4个孩子结点,而满足限界函数的孩子结点只有2个,可以删除这2个不满足限界函数的孩子结点,使得从si出发的搜索效率提高一倍。
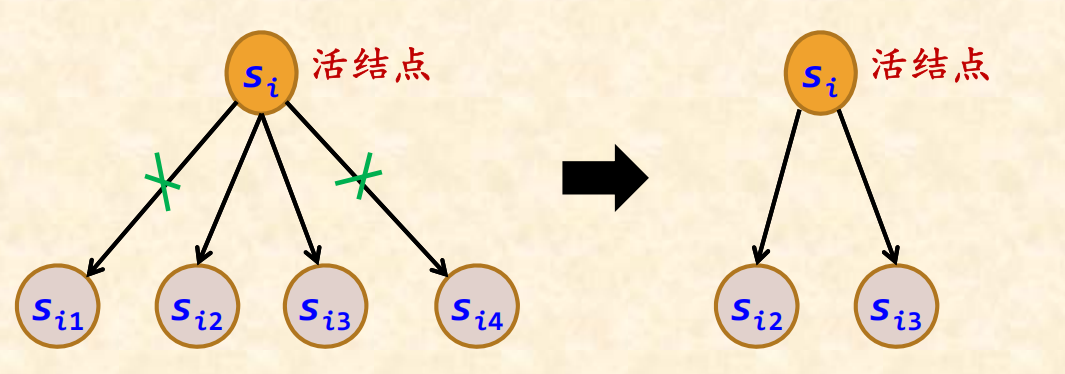
目标函数是求最大值:则设计上界限界函数ub(根结点的ub值通常大于或等于最优解的ub值),若si是sj的双亲结点,应满足ub(si)≥ub(sj),当找到一个可行解ub(sk)后,将所有小于ub(sk)的结点剪枝。
目标函数是求最小值:则设计下界限界函数lb(根结点的lb值一定要小于或等于最优解的lb值),若si是sj的双亲结点,应满足lb(si)≤lb(sj),当找到一个可行解lb(sk)后,将所有大于lb(sk)的结点剪枝。
2.2 组织活结点表
根据选择下一个扩展结点的方式来组织活结点表,不同的活结点表对应不同的分支搜索方式。
队列式分支限界法
队列式分支限界法
优先队列式分支限界法
2.2.1 队列式分支限界法
队列式分支限界法将活结点表组织成一个队列,并按照队列先进先出(FIFO)原则选取下一个结点为扩展结点。步骤如下:
- 将根结点加入活结点队列。
- 从活结点队中取出队头结点,作为当前扩展结点。
- 对当前扩展结点,先从左到右地产生它的所有孩子结点,用约束条件检查,把所有满足约束条件的孩子结点加入活结点队列。
- 重复步骤②和③,直到找到一个解或活结点队列为空为止。
2.2.2 优先队列式分支限界法
优先队列式分支限界法的主要特点是将活结点表组组成一个优先队列,并选取优先级最高的活结点成为当前扩展结点。步骤如下:
- 计算起始结点(根结点)的优先级并加入优先队列(与特定问题相关的信息的函数值决定优先级)。
- 从优先队列中取出优先级最高的结点作为当前扩展结点,使搜索朝着解空间树上可能有最优解的分支推进,以便尽快地找出一个最优解。
- 对当前扩展结点,先从左到右地产生它的所有孩子结点,然后用约束条件检查,对所有满足约束条件的孩子结点计算优先级并加入优先队列。
- 重复步骤②和③,直到找到一个解或优先队列为空为止。
2.2.3 堆、最大堆、最小堆
堆的定义如下:
(1)堆是一棵完全二叉树;
(2)堆中某个节点的值总是不大于或不小于其孩子节点的值;
(3)堆中每个节点的子树都是堆。
当父节点的键值总是大于或等于任何一个子节点的键值时为最大堆。
当父节点的键值总是小于或等于任何一个子节点的键值时为最小堆。
(下图为最大堆)
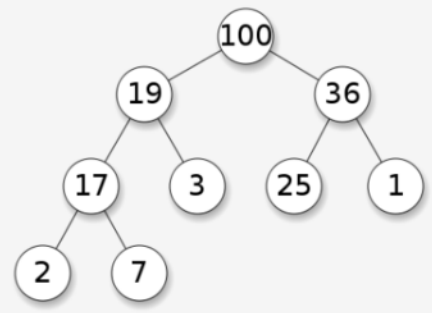
(下图为最小堆)
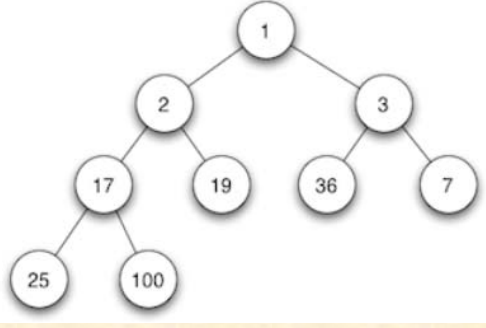
在算法实现时通常用最大堆来实现最大优先队列;用最小堆来实现最小优先队列。
2.3 确定最优解的解向量
分支限界法在搜索解空间树时,结点的处理是跳跃式的,回溯也不是单纯地沿着双亲结点一层一层地向上回溯,因此当搜索到某个叶子结点且该结点对应一个可行解时,如何得到对应的解向量呢?
- 对每个扩展结点保存从根结点到该结点的路径。
每个结点带有一个可能的解向量。这种做法比较浪费空间,但实现起来简单。 - 在搜索过程中构建搜索经过的树结构。
每个结点带有一个双亲结点指针,当找到最优解时,通过双亲指针找到对应的最优解向量。这种做法需保存搜索经过的树结构,每个结点增加一个指向双亲结点的指针。
三、案例
3.1 装载问题
**【问题描述】**有一批总重为W的共n个集装箱要装上2艘载重量分别为c1和c2的轮船,其中集装箱i的重量为wi,且 W ≤c1+c2。
要求确定是否有一个合理的装载方案可将这些集装箱装上这2艘轮船。如果
有,找出一种装载方案。
其实质是要求将第一艘轮船尽可能装满(最优装载)。即选取全体集装箱的一个子集,使该子集中集装箱重量之和最接近。
采用队列式分支限界法求解
首先检测当前扩展结点的左儿子结点是否为可行结点。如果是则将其加入到活结点队列中。然后将其右儿子结点加入到活结点队列中(右儿子结点一定是可行结点)。2个儿子结点都产生后,当前扩展结点被舍弃。
节点的左子树表示将此集装箱装上船,
右子树表示不将此集装箱装上船。
当队列元素的值为-1时,表示队列已到达解空间树同一层结点的尾部。
当取出的元素是-1时,要判断当前队列是否为空。如果队列非空,则将尾部标记-1加入活结点队列,算法开始处理下一层的活结点。
while (true)
{
if (ew + w[i] <= c) enQueue(ew + w[i], i); // 检查左儿子结点(x[i]=1)
enQueue(ew, i); //右儿子结点总是可行的(x[i]=0)
ew = ((Integer) queue.remove()).intValue(); // 取下一扩展结点
if (ew == -1) // 同层结点尾部标识(是否队尾呢?)
{
if (queue.isEmpty()) return bestw;
queue.put(new Integer(-1)); // 同层结点尾部标识
ew = ((Integer) queue.remove()).intValue(); // 取下一扩展结点
i++; // 进入下一层
}
}
采用队列式分支限界法求解 算法改进
设bestw是当前最优解;ew是当前扩展结点所相应的重量;r是剩余集装箱的重量。则当ew+r≤ bestw时,可将其右子树剪去。
为了确保右子树成功剪枝,应该在算法每一次进入左子树的时候更新bestw的值。
// 检查左儿子结点
int wt = ew + w[i];
if (wt <= c)
{ // 可行结点
if (wt > bestw) bestw = wt; // 提前更新bestw
// 加入活结点队列
if (i < n)
queue.put(new Integer(wt));
}
// 检查右儿子结点
if (ew + r > bestw && i < n) // 右儿子剪枝
// 可能含最优解
queue.put(new Integer(ew));
ew=((Integer)queue.remove())
.intValue();
// 取下一扩展结点
构造最优解
为了在算法结束后能方便地构造出与最优值相应的最优解,算法必须存储相应子集树中从活结点到根结点的路径。为此目的,可在每个结点处设置指向其父结点的指针,并设置左、右儿子标志。
private static class QNode
{ QNode parent; // 父结点
boolean leftChild; // 左儿子标识
int weight; // 结点所相应的载重量
找到最优值后,可以根据parent回溯到根节点,找到最优解。
// 构造当前最优解
for (int j = n; j > 0; j--)
{ bestx[j] = (e.leftChild) ? 1 : 0;
e = e.parent;
}
采用优先队列式分支限界法求解
求解装载问题的优先队列式分支限界法用最大优先队列存储活结点表。
用最大堆表示活结点优先队列。
活结点x在优先队列中的优先级定义为从根结点到结点x的路径所相应的载重量再加上剩余集装箱的重量之和。
- 优先队列中优先级最大的活结点成为下一个扩展结点
- 以结点x为根的子树中所有结点相应的路径的载重量不超过它的优先级
- 子集树中叶结点所相应的载重量与其优先级相同
在优先队列式分支限界法中,一旦有一个叶结点成为当前扩展结点,则可以断言该叶结点所相应的解即为最优解。此时可终止算法。
四、总结
(1) 适于求解组合搜索问题及优化问题
(2) 解的表示:解向量,求解是不断扩充解向量的过程
(3) 分支策略:广度优先
(4) 限界函数(约束条件、优化问题的代价函数)
(5) 扩展结点处理方式
队列式
优先队列式