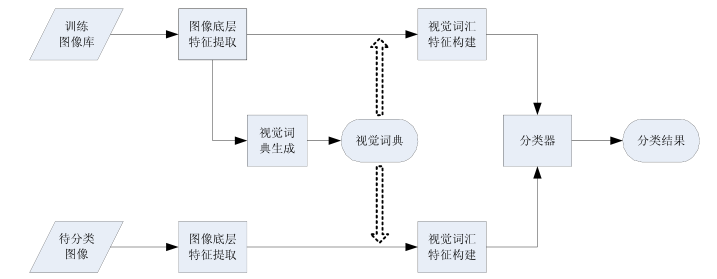
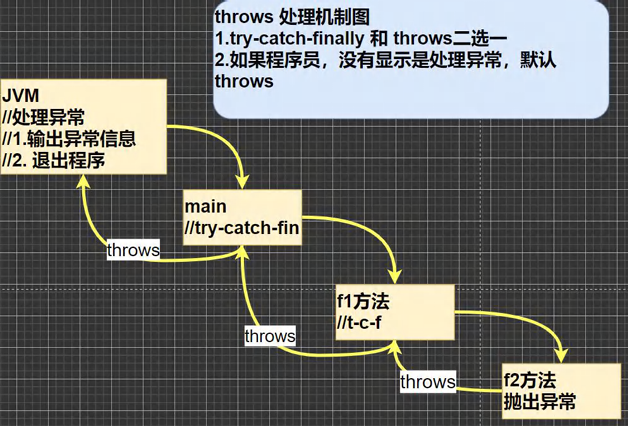
张量是PyTorch中的核心数据抽象。这个交互式笔记本提供了一个深入的介绍torch. Tensor 类.,
首先,让我们导入PyTorch模块。我们还将添加Python的数学模块来简化一些示例。
import torch
import math
创建张量
创建张量最简单的方法是调用torch.empty():
x = torch.empty(3, 4)
print(type(x))
print(x)
输出为:
<class 'torch.Tensor'>
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
让我们总结一下刚才的内容:
-
我们使用火炬模块附带的众多工厂方法之一创建了一个张量。
-
张量本身是二维的,有3行4列。
-
返回的对象类型是torch。Tensor,它是torch.FloatTensor的别名;默认情况下,PyTorch张量使用32位浮点数填充。(下面是关于数据类型的更多信息。)
-
在打印张量时,您可能会看到一些看起来随机的值。torch.empty()调用为张量分配内存,但没有用任何值初始化它-因此您看到的是分配时内存中的内容。
关于张量及其维数和术语的简要说明:
-
你有时会看到一个一维张量叫做矢量。
-
同样地,二维张量通常被称为矩阵。
-
任何二维以上的东西通常都叫做张量。
通常情况下,您需要用某个值初始化张量。常见的情况是全零、全一或随机值,torch模块为所有这些提供了工厂方法:
zeros = torch.zeros(2, 3)
print(zeros)
ones = torch.ones(2, 3)
print(ones)
torch.manual_seed(1729)
random = torch.rand(2, 3)
print(random)
输出为:
tensor([[0., 0., 0.],
[0., 0., 0.]])
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[0.3126, 0.3791, 0.3087],
[0.0736, 0.4216, 0.0691]])
工厂方法所做的都是你所期望的——我们有一个全是0的张量,另一个全是1的张量,还有一个是0到1之间的随机值。
随机张量和播种
说到随机张量,你注意到它之前对torch.manual_seed()的调用了吗?用随机值初始化张量(比如模型的学习权值)是很常见的,但有时——尤其是在研究环境中——你需要对结果的可重复性有一定的保证。手动设置随机数生成器的种子是这样做的。让我们仔细看看:
torch.manual_seed(1729)
random1 = torch.rand(2, 3)
print(random1)
random2 = torch.rand(2, 3)
print(random2)
torch.manual_seed(1729)
random3 = torch.rand(2, 3)
print(random3)
random4 = torch.rand(2, 3)
print(random4)
输出为:
tensor([[0.3126, 0.3791, 0.3087],
[0.0736, 0.4216, 0.0691]])
tensor([[0.2332, 0.4047, 0.2162],
[0.9927, 0.4128, 0.5938]])
tensor([[0.3126, 0.3791, 0.3087],
[0.0736, 0.4216, 0.0691]])
tensor([[0.2332, 0.4047, 0.2162],
[0.9927, 0.4128, 0.5938]])
您应该在上面看到的是random1和random3携带相同的值,random2和random4也是如此。手动设置RNG的种子会重置它,所以在大多数情况下,基于随机数的相同计算应该会提供相同的结果。
有关更多信息,请参阅PyTorch关于再现性的文档。
张量的形状
通常,当你在两个或更多张量上执行操作时,它们需要具有相同的形状——也就是说,在每个维度上具有相同数量的维数和相同数量的单元。为此,我们使用了torch.*_like()方法:
x = torch.empty(2, 2, 3)
print(x.shape)
print(x)
empty_like_x = torch.empty_like(x)
print(empty_like_x.shape)
print(empty_like_x)
zeros_like_x = torch.zeros_like(x)
print(zeros_like_x.shape)
print(zeros_like_x)
ones_like_x = torch.ones_like(x)
print(ones_like_x.shape)
print(ones_like_x)
rand_like_x = torch.rand_like(x)
print(rand_like_x.shape)
print(rand_like_x)
输出为:
torch.Size([2, 2, 3])
tensor([[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]])
torch.Size([2, 2, 3])
tensor([[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]])
torch.Size([2, 2, 3])
tensor([[[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.]]])
torch.Size([2, 2, 3])
tensor([[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]])
torch.Size([2, 2, 3])
tensor([[[0.6128, 0.1519, 0.0453],
[0.5035, 0.9978, 0.3884]],
[[0.6929, 0.1703, 0.1384],
[0.4759, 0.7481, 0.0361]]])
上面代码单元中的第一个新内容是在张量上使用.shape属性。这个属性包含了张量每个维度的范围列表——在我们的例子中,x是一个形状为2 x 2 x 3的三维张量。
下面,我们调用。empty_like()、。zeros_like()、。ones_like()和。rand_like()方法。使用.shape属性,我们可以验证这些方法中的每一个都返回具有相同维度和范围的张量。
最后一种创建张量的方法是直接从PyTorch集合中指定它的数据:
some_constants = torch.tensor([[3.1415926, 2.71828], [1.61803, 0.0072897]])
print(some_constants)
some_integers = torch.tensor((2, 3, 5, 7, 11, 13, 17, 19))
print(some_integers)
more_integers = torch.tensor(((2, 4, 6), [3, 6, 9]))
print(more_integers)
输出为:
tensor([[3.1416, 2.7183],
[1.6180, 0.0073]])
tensor([ 2, 3, 5, 7, 11, 13, 17, 19])
tensor([[2, 4, 6],
[3, 6, 9]])
如果你已经在Python元组或列表中拥有数据,使用torch.tensor()是创建张量最直接的方法。如上所示,嵌套集合将产生一个多维张量。
张量数据类型
设置张量的数据类型有两种方法:
a = torch.ones((2, 3), dtype=torch.int16)
print(a)
b = torch.rand((2, 3), dtype=torch