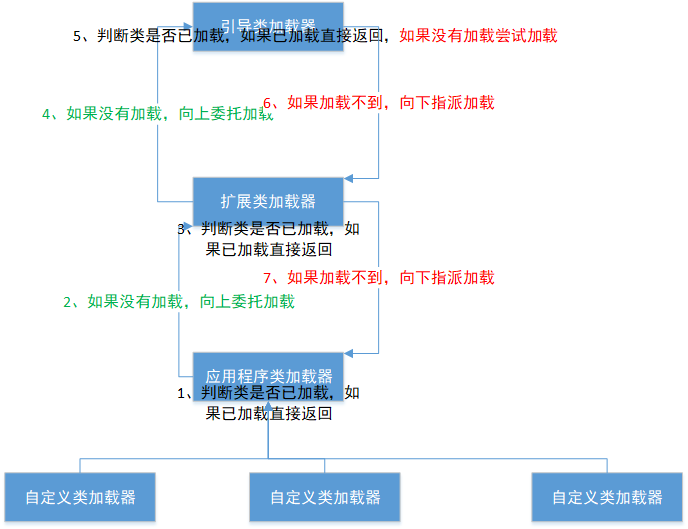
文章目录
- 前言
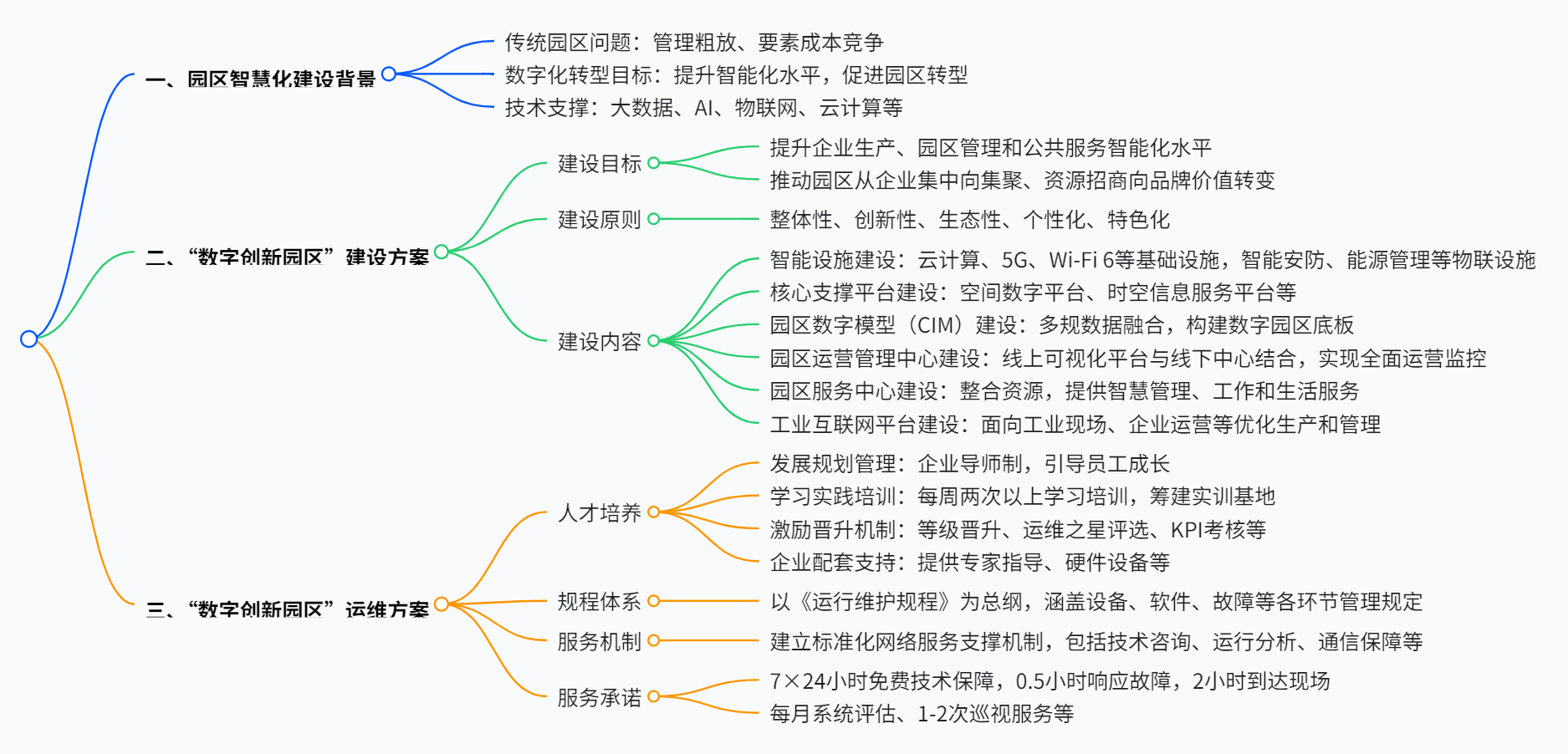
- 一、KV-cache
- 1、为什么使用KV-cache
- 2、KV-cache的运作原理
- 二、Decoder-only VS Encoder-Decoder
- 1、Decoder-only
- 2、Encoder-Decoder
- 三、Causal LM VS PrefixLM
- 总结
前言
decoder-only模型是目前大模型的主流架构,由于OpenAI勇于挖坑踩坑,大家跟随它的脚步使其目前主流大模型均为decoder-only架构。但目前也没有明确实验表明decoder-only模型一定要优于encoder-decoder架构或其它架构。本文主要decoder-only涉及到一些技术点。
一、KV-cache
其实我觉得decoder-only目前一个很大的优势就是其已经逐渐成熟的部署生态,其中的重点之一KV-cache。
KV-Cache 指在 Transformer 解码器中缓存住过去生成 token 的 Key(K)和值(Value,V),以避免每次都重复计算前面 token 的 attention。
1、为什么使用KV-cache
在 decoder-only 架构中,当生成第 t 个 token 时,需要用 1~t-1 的 token 计算 attention。
如果不缓存,就要重复计算每个前面位置的 K/V (我们知道Q, K, V均经过各自的线性层获得,如果每次都计算将导致巨大的计算量)。
而有了 KV-Cache:
每一步只计算当前 query 的 attention,然后从缓存中提取之前的 K/V。
时间复杂度从 O(T²) ➜ 降为 O(T)(每步 O(1))。
Query_t --> Attention(Q_t, K_1~t-1, V_1~t-1)
↑
来自缓存的 K/V
2、KV-cache的运作原理
基本代码如下:
outputs = model(input_ids, use_cache=True)
past_key_values = outputs.past_key_values # 缓存的Key 和 Value
next_outputs = model(next_input_ids, past_key_values=past_key_values)
具体一点,假设prompt为 'The cat is' ,
第一次输入:"The cat is" → 模型生成 sleeping(next token id 是 sleeping 对应的 token)
第二次输入:next_input_ids = [sleeping_token_id],配合上一次的 past_key_values
第三次输入:模型又生成了 on,然后 next_input_ids = [on_token_id]
以此类推...
基于此,简单的伪代码如下:
input_ids = tokenizer("The cat is", return_tensors="pt").input_ids
outputs = model(input_ids, use_cache=True)
past_key_values = outputs.past_key_values
generated_ids = input_ids
for _ in range(max_gen_len):
next_token_id = outputs.logits[:, -1, :].argmax(dim=-1)
generated_ids = torch.cat([generated_ids, next_token_id.unsqueeze(-1)], dim=-1)
outputs = model(input_ids=next_token_id.unsqueeze(0), past_key_values=outputs.past_key_values)
这里再提一点:因为Q要和之前所有的K和V计算attention,
attn_scores = Q_t × [K_1, ..., K_{t-1}]ᵀ # shape: [1, t-1]
attn_weights = softmax(attn_scores)
output_t = attn_weights × [V_1, ..., V_{t-1}] # shape: [1, d_model]
output_t = α₁ · V₁ + α₂ · V₂ + ... + α_{t-1} · V_{t-1}
二、Decoder-only VS Encoder-Decoder
首先要了解的一点,这两种架构都是针对语言端来说的,对于多模态是一定会有编码器来编码视觉等信息的。
基本架构如下:
┌────────────┐
Input Text → │ Encoder │ ─┐
└────────────┘ │
▼
┌────────────┐
Target Tokens → │ Decoder │ → Output tokens
└────────────┘
首先最明显的结构上的差异,多了个encoder。
此外Decoder-only是只有单向注意力(causal attention),天然具备隐式的位置编码能力,即使没有外部的位置编码,也能表达出 token 顺序。
Encoder-Decoder中是存在交叉注意力的,可以完整看到encoder的输出,比较适合并行处理
1、Decoder-only
适合任务:语言建模、对话、长文生成、代码补全等
[Prompt + Target] → 单个 Decoder → 逐 token 输出
注意力结构:
每个 token 只能看到自己左边的内容(自回归)
优点:
结构简单,统一处理输入输出
非常适合 autoregressive 生成(逐字输出)
2、Encoder-Decoder
适合翻译任务
Input: I love you
↓
Encoder: 编码为隐藏状态
↓
Decoder: 预测输出:我 爱 你
个人觉得其实encoder-decoder的训练会比decoder-only更容易下,因为多了一个encoder的语义理解过程。不过也许正因decoder-only的训练困难,才能使其能力上限更高。
三、Causal LM VS PrefixLM
前面已经提到了Decoder-only主要使用 Causal LM(从左至右,单向推理),其实还有一种训练范式为Prefix LM (Causal LM 和 Prefix LM在推理时是保持一致的,但是在训练时候的策略不同)
PrefixLM 做的 attention 限制是:
对于 prompt 的 token(你是谁?):
它们可以看到彼此(全注意力);
对于 target 的 token(皮卡丘):
它们只能看到 prompt + 自己左边的 token(自回归 attention);
不能 peek 后面的词。
可以看成是:“编码器-解码器合体”的一种 attention 掩码策略
Attention Mask格式如下:
Causal LM(如 GPT)
Token sequence: [ A B C D E ]
Mask matrix:
A → A
B → A B
C → A B C
D → A B C D
E → A B C D E
Prefix LM
Prefix = [A B]
Target = [C D E]
Token sequence: [ A B | C D E ]
Mask matrix:
A → A B ✅ full attention for prefix
B → A B
C → A B C ✅ target attends to prefix + left
D → A B C D
E → A B C D E
可以看到PrefixLM
显式建模「任务输入 + 输出」的结构;
在训练时就区分 prompt 和 response;
比纯 Causal LM 更有效地学习「用 prompt 解任务」的能力。
总结
其实我觉得encoder-decoder, prefix这些方法仍然有很大的探索空间,只不过对于大模型来说这些实验的成本是巨大且不可控的,decoder-only的生态逐渐成熟,这些方法的探索也就逐渐变少了,不过依然未来可期