详细分析一下 Qwen-0.5B (5亿参数) 这个模型在不同训练阶段的显存需求以及它的用途。(根据网页反馈:1、0.5b做蒸馏,特定领域轻松超越sft的7b;2、大部分实时要求高的业务需要用小模型初筛降量,比如意图识别;3、取倒数第一层的hidden vector拿来做text embedding,相当于是一个可以接受prompt的bert,再对比学习调一下就是embedding模型;4、给无显卡的人调参数做实验;5、边缘计算、端侧应用;6、rag差不多够用;)
一、训练阶段显存需求估算 (估算值,受多种因素影响)
显存需求是一个动态值,受到以下关键因素显著影响:
- 训练方式: 全参数微调 vs. 参数高效微调 (PEFT, 如 LoRA, Prefix-Tuning)。
- 优化器: AdamW 比 SGD 占用更多显存(需要存储动量和方差)。
- 精度: FP32 (单精度) vs. FP16/BF16 (半精度) vs. FP8 (8位精度,较少支持)。半精度训练是当前主流,能显著节省显存和加速训练,以下估算主要基于 BF16/FP16。
- Batch Size: 批次大小直接影响激活值和梯度的显存占用。
- 序列长度: 输入文本的最大长度,直接影响激活值显存。
- 梯度累积: 是否使用梯度累积来模拟更大的 Batch Size。
- 激活检查点: 是否开启梯度检查点技术(用计算时间换显存)。
- 并行策略: 是否使用数据并行、模型并行、流水线并行、Zero Redundancy Optimizer (ZeRO) 等技术。
- 其他开销: 框架开销、通信开销(在多卡训练时)、数据加载等。
核心估算逻辑:
- 模型参数: 5亿参数,在 BF16/FP16 下,每个参数占 2 字节。模型参数本身占用约
0.5B * 2 bytes = 1 GB。 - 优化器状态 (AdamW): 对于每个参数,AdamW 需要存储其 FP32 格式的参数副本、动量、方差。通常每个参数需要
4 bytes (FP32 param) + 4 bytes (momentum) + 4 bytes (variance) = 12 bytes。在 BF16/FP16 训练下,模型参数是半精度的,但优化器状态通常是 FP32 的。优化器状态占用约0.5B * 12 bytes = 6 GB。 - 梯度: 在 BF16/FP16 下,每个参数的梯度占 2 字节。梯度占用约
0.5B * 2 bytes = 1 GB。 - 激活值: 这是最难精确估算的部分,它高度依赖于 Batch Size、序列长度、模型结构(层数、隐藏层大小)、是否使用激活检查点。对于 0.5B 模型,在合理配置下,激活值占用通常在模型参数大小的数倍到十倍左右(尤其在序列较长、Batch Size 较大时)。
以下是不同训练阶段的大致显存需求范围 (单卡,BF16/FP16):
-
Pretraining (预训练):
- 需求最高。 需要处理海量原始数据,通常使用大 Batch Size 和长序列。
- 需要存储完整的模型参数、优化器状态、梯度、大量激活值。
- 估算范围: 15 GB - 40+ GB
- 典型场景: 需要至少一张 24GB 显存的卡 (如 NVIDIA RTX 3090/4090, Tesla A10) 才能进行小规模预训练(Batch Size 较小,序列长度适中,可能开启激活检查点)。进行有意义的预训练通常需要 多张 A100 (40/80GB) 或 H100 卡,利用数据并行或 ZeRO 等技术。
-
Supervised Fine-Tuning (SFT,监督微调):
- 需求中等。 数据量通常远小于预训练,任务更聚焦,可以使用较小的 Batch Size 和序列长度。强烈推荐使用 PEFT (如 LoRA)!
- 全参数微调: 显存占用结构与预训练类似,但激活值压力通常小一些(因为 Batch Size 和序列长度可能更小)。估算范围: 10 GB - 30+ GB。一张 24GB 卡 (如 3090/4090) 在精心配置(小 Batch Size, 激活检查点)下通常可以进行。
- PEFT 微调 (强烈推荐): 只微调少量额外参数(如 LoRA 的秩矩阵),冻结原始模型的大部分参数。优化器状态和梯度只存在于这些少量参数上,显存需求大幅降低。
- 估算范围: 2 GB - 8 GB (取决于基础模型加载方式、LoRA 配置、Batch Size)。
- 典型场景: 可以在 消费级显卡 (如 RTX 3060 12GB, RTX 4060 16GB) 甚至更低显存的卡上轻松进行。
-
RLHF / DPO Training (人类反馈强化学习 / 直接偏好优化):
- 需求高 (尤其 RLHF) / 中等偏高 (DPO)。 需要同时处理多个模型。
- RLHF (传统 PPO):
- 需要同时加载和运行:
- Policy Model (策略模型): 正在训练的模型 (SFT 后的模型)。
- Reference Model (参考模型): 通常是 SFT 后的模型(冻结)。
- Reward Model (奖励模型): 另一个训练好的模型(冻结)。
- PPO 过程本身还需要存储经验回放缓存、优势函数估计等额外信息。
- 估算范围 (Policy + Ref + RM): 2.5 - 3 倍于单个 SFT 模型全参微调的显存。对于 0.5B 模型,通常在 30 GB - 80+ GB 范围。通常需要多张高显存卡 (如 A100/H100) 和复杂的并行策略 (ZeRO Stage 3, 模型并行)。
- 需要同时加载和运行:
- DPO:
- 需要同时加载:
- Policy Model (策略模型): 正在训练的模型。
- Reference Model (参考模型): 冻结的 SFT 模型。
- 优化过程相对 PPO 更简单直接,不需要奖励模型和复杂的 PPO 更新步骤。
- 估算范围 (Policy + Ref): 约 2 倍于单个 SFT 模型全参微调的显存。对于 0.5B 模型,通常在 20 GB - 60+ GB 范围。比 RLHF (PPO) 显存需求低,但对单卡压力仍然很大。使用 PEFT (如 LoRA) 进行 DPO 可以显著降低显存需求,可能降到 5 GB - 15 GB 左右,使得在 单张 24GB 卡 上运行成为可能(仍需仔细配置)。
- 需要同时加载:
总结显存需求表 (单卡 BF16/FP16, 粗略估算):
| 训练阶段 | 主要特点 | 显存需求范围 (GB) | 典型可行硬件 (单卡) | 关键节省技术 |
|---|---|---|---|---|
| Pretraining | 海量数据,大Batch,长序列 | 15 - 40+ | A100/H100 (多卡常见) | 激活检查点, ZeRO, 低精度 |
| SFT (全参) | 任务数据,中等配置 | 10 - 30+ | RTX 3090/4090 (24GB) | 激活检查点, 小Batch |
| SFT (PEFT) | 仅微调少量参数 | 2 - 8 | RTX 3060 (12GB) / 4060 (16GB) 或更高 | LoRA 等 PEFT 方法 |
| RLHF (PPO) | Policy + Ref + RM + PPO 机制 | 30 - 80+ | 多张 A100/H100 + ZeRO Stage 3 / 模型并行 | 极其依赖并行和优化 |
| DPO (全参) | Policy + Ref | 20 - 60+ | 高显存单卡或多卡 (A100/H100) | 激活检查点 |
| DPO (PEFT) | Policy (LoRA) + Ref | 5 - 15 | RTX 3090/4090 (24GB) | LoRA + 激活检查点 |
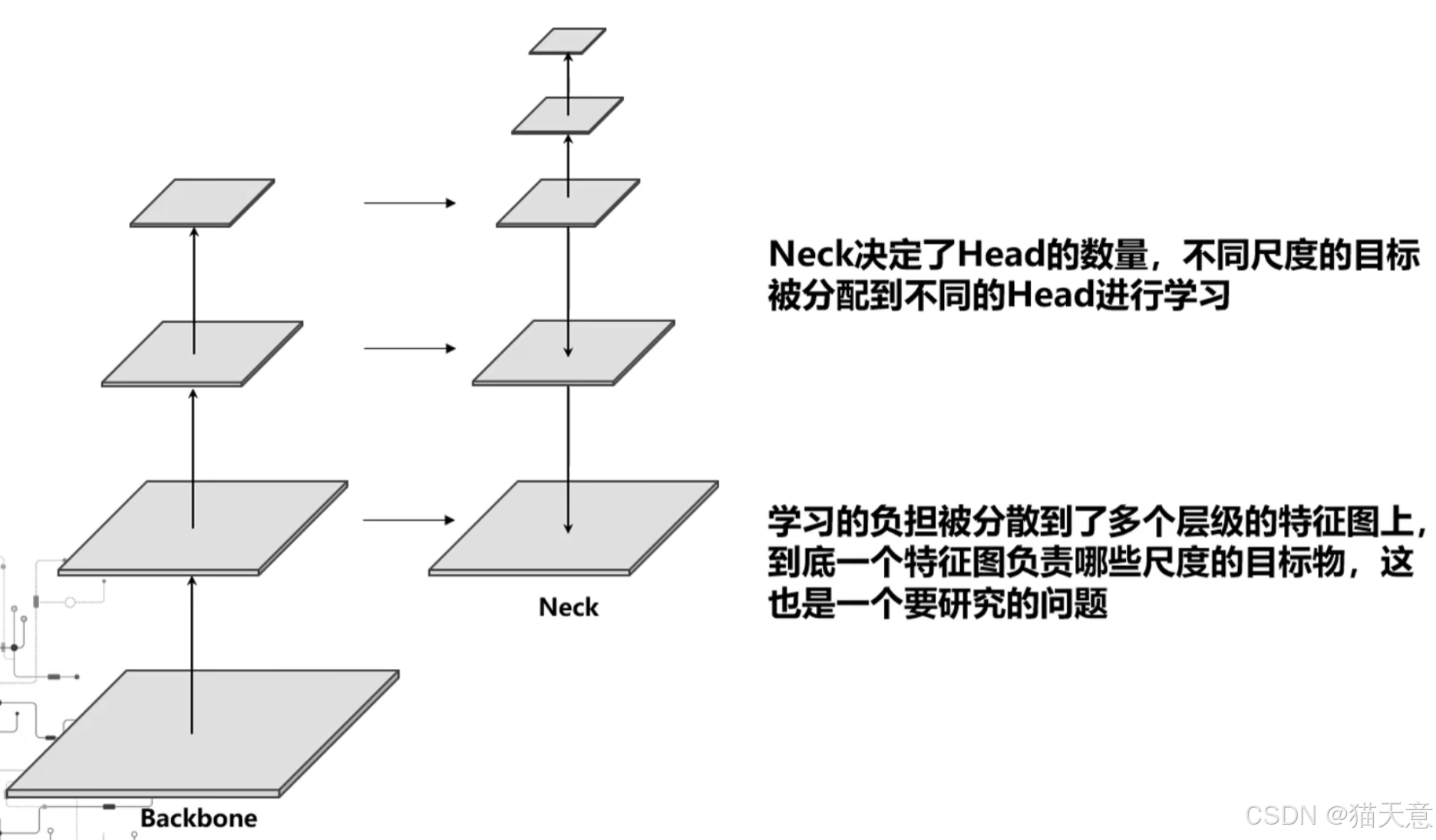
二、Qwen-0.5B (5亿参数) 模型的用途
虽然 5亿参数在当今大模型(百亿、千亿级)面前显得很小,但 Qwen-0.5B 这样的模型在特定场景下依然非常有价值:
-
边缘计算与端侧部署:
- 核心优势: 模型体积小(通常几百MB),计算量和内存占用低。
- 应用场景: 可以在手机、平板、嵌入式设备、物联网设备上本地运行,实现离线智能功能,保护用户隐私,降低延迟。
- 具体任务: 设备本地的简单对话助手、文本摘要、关键词提取、基础问答、情感分析、翻译(短语或句子级别)、写作辅助(短文本生成、润色)。
-
对延迟敏感的应用:
- 核心优势: 推理速度快,响应时间短。
- 应用场景: 实时交互系统(如聊天机器人需要快速回复)、高频API服务(处理大量并发请求时,小模型成本更低、速度更快)、游戏NPC对话。
-
轻量级任务自动化:
- 应用场景: 自动生成简单的报告模板、邮件草稿、社交媒体帖子;进行基础的文本分类(如垃圾邮件过滤、主题分类);信息抽取(如从固定格式文本中提取关键字段)。
-
教育、研究与原型开发:
- 学习工具: 学生和研究人员可以更轻松地在个人电脑上理解和实验大语言模型的基本原理、训练/微调流程、评估方法,学习成本低。
- 快速原型验证: 在产品开发早期,可以用小模型快速搭建功能原型,验证想法和用户交互流程,然后再考虑是否需要更大模型提升效果。
- 算法研究平台: 研究新的训练方法(如更高效的 RLHF/DPO)、模型压缩技术、PEFT 方法等,在小模型上迭代速度更快,成本更低。
-
成本敏感型业务:
- 核心优势: 训练和推理的硬件成本、云服务费用、电力消耗都远低于大模型。
- 应用场景: 初创公司、预算有限的项目、需要大规模部署的简单智能功能(如客服系统中的关键词触发回复、工单自动分类)。
-
特定领域垂直应用的基石:
- 虽然通用能力不如大模型,但在某个狭窄、定义清晰的任务领域(例如:根据特定模板生成产品描述、分析特定类型的客服日志情绪、回答某个知识库内的常见问题),经过高质量的领域数据微调后,Qwen-0.5B 可以表现得非常高效和实用。
总结
- 显存: Qwen-0.5B 的预训练 (Pretrain) 需要高显存卡或多卡并行(15-40+ GB)。SFT 微调在消费级显卡上可行(全参10-30+ GB,PEFT 2-8 GB)。RLHF (PPO) 训练显存需求极高(30-80+ GB),通常需要专业级多卡集群。DPO 训练需求低于 PPO(全参20-60+ GB,PEFT 5-15 GB),在高端消费卡上使用 PEFT 是可能的。PEFT (尤其是 LoRA) 是大幅降低 SFT 和 DPO 显存需求的关键。
- 用途: Qwen-0.5B 的核心价值在于其小巧、快速、低成本。它非常适合端侧/边缘部署、实时应用、轻量级任务自动化、教育研究、快速原型开发、成本敏感型业务以及在特定垂直领域经过精调后提供高效的解决方案。它是轻量化和实用性的代表,虽然能力上无法与数百亿参数的大模型匹敌,但在其适用场景下性价比极高。
选择是否使用 Qwen-0.5B,取决于你的具体应用场景对模型能力、响应速度、部署成本、隐私要求和硬件限制的权衡。



![[网页五子棋][对战模块]处理连接成功,通知玩家就绪,逻辑问题(线程安全,先手判定错误)](https://i-blog.csdnimg.cn/img_convert/4cf9d079297ca2b379f55884862c1074.png)