学习的博客(在此致谢):
初识CV - Transformer模型详解(图解最完整版)
1 整体结构
![![[Pasted image 20250528161501.png]]](https://i-blog.csdnimg.cn/direct/50c9dd7eae65401aa0440fadf9fd975d.png)
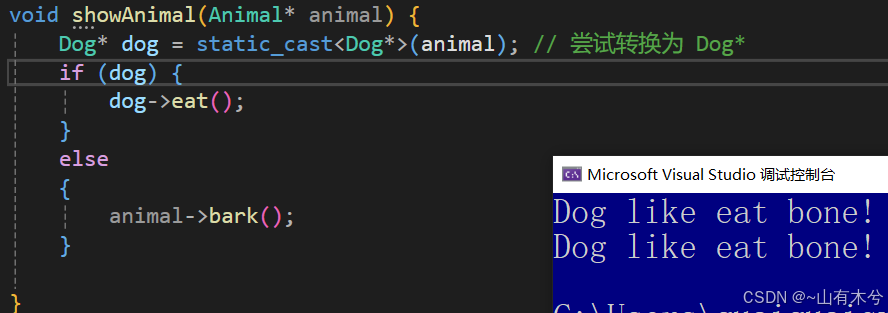
Transformer由Encoder和Decoder组成,分别包含6个block。
Transformer的工作流程大体如下:
- 获取每个单词的embedding vector X X X, X X X由词嵌入(word embedding)和位置编码(Positional Encoding)得到。
- 将得到的单词 X X X传入Encoder中,经过6个Encoder block后可以得到句子所有单词的编码信息矩阵 C C C。单词向量矩阵可以用 X n × d X_{n\times d} Xn×d表示,其中 n n n为单词数, d d d为向量维度(论文中为512)。每个Encoder block输出的矩阵维度与输入完全一致。
- 将 C C C传递到Decoder中,Decoder会根据翻译过的单词 1 , ⋯ , i 1,\cdots,i 1,⋯,i翻译单词 i + 1 i+1 i+1。翻译 i + 1 i+1 i+1时需要用mask盖住 i + 2 , ⋯ , n i+2,\cdots,n i+2,⋯,n。
2 Transformer的输入
X X X由词嵌入(word embedding)和位置编码(Positional Encoding)得到。
2.1 词嵌入
输入的是一句话,比如:“我 爱 自然语言处理”,每个词会被映射成一个向量,叫词嵌入(word embedding)。
“我” → [0.2, 0.5, ..., -0.1] (一个 d_model 维的向量)
“爱” → [...]
“自然语言处理” → [...]
2.2 位置编码
Transformer除了词嵌入,还需要位置编码(Positional Encoding, PE) 来表示单词在句子中出现的位置。由于Transformer不采用RNN结构,而是使用全局信息,不能利用单词的顺序信息,而这部分信息对于NLP来说非常重要。 所以Transformer中使用位置编码来保存单词在序列中的相对/绝对位置。
Transformer中计算PE的公式如下:
PE
(
pos
,
2
i
)
=
sin
(
pos
/
10000
2
i
/
d
)
\text{PE}_{(\text{pos},2i)}=\sin(\text{pos}/10000^{2i/d})
PE(pos,2i)=sin(pos/100002i/d)
PE
(
pos
,
2
i
+
1
)
=
cos
(
pos
/
10000
2
i
/
d
)
\text{PE}_{(\text{pos},2i+1)}=\cos(\text{pos}/10000^{2i/d})
PE(pos,2i+1)=cos(pos/100002i/d)
其中,
pos
\text{pos}
pos表示单词在句子中的位置,
d
d
d表示PE的维度(与词嵌入的维度相同)。
对于每个位置
pos
\text{pos}
pos,我们计算
d
d
d维向量(其中一半维度是
sin
\sin
sin,另一半是
cos
\cos
cos)。所以每个位置的PE也是长度为
d
d
d的向量。
2.3 Transformer的输入
有了词嵌入
input_embedding
\text{input\_embedding}
input_embedding和位置编码
positional_encoding
\text{positional\_encoding}
positional_encoding(即
PE
\text{PE}
PE),我们有
X
=
input_embedding
+
positional_encoding
X=\text{input\_embedding}+\text{positional\_encoding}
X=input_embedding+positional_encoding
为什么是相加而不是连接(concat)?
- 加法不增加维度,后面的模型结构无需改动。
- PE被视为微调词语的表示,可以看作是在词向量的基础上“注入一点位置感知”。比如“I saw a cat.” 中的 “cat” 在句首或句尾含义不同,但你不需要让两个“cat”产生完全不同的表示,只需加一点“位置信息”做微调。
- Attention中的缩放点积更适合加法式表示。
- 原论文实验验证:加法的效果已经很好,因此选择加法方案。
3 Self-Attention 自注意力机制
![![[Pasted image 20250528164507.png]]](https://i-blog.csdnimg.cn/direct/7340de41e9634b95a7613f727b98a0ea.png)
上图为论文中Transformer的内部结构图,左侧为Encoder block,右侧为Decoder block。红色圈中的部分为Multi-Head Attention,由多个Self-Attention组成。
还可以发现,Encoder block包含一个Multi-Head Attention,而Decoder block包含两个,其中一个用到了mask。
还可以发现,Multi-Head Attention上方还包括一个Add & Norm层,Add表示残差链接(Redidual Connection),用于防止网络退化;Norm表示Layer Normalization,用于对每一层的激活值进行归一化。
3.1 Self-Attention结构
![![[Pasted image 20250528172649.png]]](https://i-blog.csdnimg.cn/direct/822a09f8d04e4152a22a8e27c6ae8894.png)
上图为Self-Attention结构,计算时需要用到矩阵Q(Query, 查询), K(Key, 键值), V(Value, 值)。Self-Attention接收的是输入(第2章中的矩阵
X
X
X) 或者上一个Encoder block的输出。
而Q,K,V正是通过Self-Attention的输入进行线性变换得到的。
3.2 Q, K, V
已知
X
∈
R
n
×
d
X\in\mathbb{R}^{n\times d}
X∈Rn×d。定义三个参数矩阵:
W
Q
∈
R
d
×
d
Q
W_Q\in\mathbb{R}^{d\times d_Q}
WQ∈Rd×dQ,
W
K
∈
R
d
×
d
K
W_K\in\mathbb{R}^{d\times d_K}
WK∈Rd×dK,
W
V
∈
R
d
×
d
V
W_V\in\mathbb{R}^{d\times d_V}
WV∈Rd×dV。对于每个输入
X
X
X:
Q
=
X
W
Q
,
K
=
X
W
K
,
V
=
X
W
V
Q=XW_Q,\ K=XW_K,\ V=XW_V
Q=XWQ, K=XWK, V=XWV
得到的矩阵:
Q
∈
R
n
×
d
Q
Q\in\mathbb{R}^{n\times d_Q}
Q∈Rn×dQ,
K
∈
R
n
×
d
K
K\in\mathbb{R}^{n\times d_K}
K∈Rn×dK,
V
∈
R
n
×
d
V
V\in\mathbb{R}^{n\times d_V}
V∈Rn×dV。通常,
d
Q
,
d
K
,
d
V
d_Q,d_K,d_V
dQ,dK,dV是相同的。
在注意力机制中,每个词会
- 用 Q Q Q询问别的词的 K K K,来判断该关注谁;
- 用 V V V提供实际信息,如果我关注你,要拿到你的什么内容。
注意力公式如下:
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
⊤
d
K
)
V
\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^\top}{\sqrt{d_K}})V
Attention(Q,K,V)=softmax(dKQK⊤)V
最后输出的矩阵
Z
∈
R
n
×
d
V
Z\in\mathbb{R}^{n\times d_V}
Z∈Rn×dV。
3.3 Multi-head Attention
![![[Pasted image 20250528223553.png]]](https://i-blog.csdnimg.cn/direct/2c95bf1882374bfe99639e212e1c21be.png)
假设
X
X
X经过QKV计算后得到
Z
Z
Z。上图可以看出Multi-head Attention包含多个Self-Attention层。首先将输入
X
X
X分别传递到
h
h
h个不同的Self-Attention中,计算得到
h
h
h个输出矩阵
Z
=
[
Z
1
,
⋯
,
Z
h
]
Z=[Z_1,\cdots,Z_h]
Z=[Z1,⋯,Zh]。Multi-head Attention将其连接(concat)起来,得到
Z
′
∈
R
n
×
(
h
⋅
d
K
)
Z'\in\mathbb{R}^{n\times (h\cdot d_K)}
Z′∈Rn×(h⋅dK)。
最后再经过一层
R
(
h
⋅
d
K
)
×
d
\mathbb{R}^{(h\cdot d_K)\times d}
R(h⋅dK)×d的线性层,得到最终的输出
Z
∈
R
n
×
d
Z\in\mathbb{R}^{n\times d}
Z∈Rn×d,和输入
X
X
X的维度相同。
4 Encoder
![![[Pasted image 20250528235507.png]]](https://i-blog.csdnimg.cn/direct/786d27930c384c619e37d8880f4f387b.png)
上图红色部分是Transformer的Encoder block结构,可以看到是由Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm组成的。刚刚已经了解了Multi-Head Attention的计算过程,现在了解一下Add & Norm和Feed Forward部分。
4.1 Add & Norm
Add & Norm层由Add和Norm两部分组成,其计算公式如下:
LayerNorm
(
X
+
MultiHeadAttention
(
X
)
)
\text{LayerNorm}(X+\text{MultiHeadAttention}(X))
LayerNorm(X+MultiHeadAttention(X))
LayerNorm
(
X
+
FeedForward
(
X
)
)
\text{LayerNorm}(X+\text{FeedForward}(X))
LayerNorm(X+FeedForward(X))
其中
X
X
X表示Multi-Head Attention或者Feed Forward的输入,MultiHeadAttention(X)和 FeedForward(X) 表示输出(输出与输入X维度是一样的,所以可以相加)。
Add指X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:
![![[Pasted image 20250529000354.png]]](https://i-blog.csdnimg.cn/direct/951d53ad1fae41babe0a87dfa0949600.png)
Norm指Layer Normalization,通常用于RNN结构,Layer Normalization会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
4.2 Feed Forward
Feed Forward层比较简单,是一个两层的全连接层,第一层的激活函数为Relu,第二层不使用激活函数:
max
(
0
,
X
W
1
+
b
1
)
W
2
+
b
2
\max(0,XW_1+b_1)W_2+b_2
max(0,XW1+b1)W2+b2
X是输入,Feed Forward最终得到的输出矩阵的维度与X一致。
最后, X X X经过一连串Encoder得到编码信息矩阵 C C C。
5 Decoder
![![[Pasted image 20250529000555.png]]](https://i-blog.csdnimg.cn/direct/0ac232064b294936a479202dccabd758.png)
上图红色部分为Transformer的Decoder block结构,与Encoder block相似,但是存在一些区别:
- 包含两个Multi-Head Attention层。
- 第一个Multi-Head Attention层采用了Masked操作。
- 第二个Multi-Head Attention层的K, V矩阵使用Encoder的编码信息矩阵 C C C进行计算,而Q使用上一个Decoder block的输出计算。
- 最后有一个Softmax层计算下一个翻译单词的概率。
5.1 Masked Multi-Head Attention (1st)
Decoder block 的第一个Multi-Head Attention采用了Masked操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第i+1个单词。通过Masked操作可以防止第i个单词知道i+1个单词之后的信息。
下面的描述中使用了类似Teacher Forcing的概念。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入"Begin"预测出第一个单词为 “I”,然后根据输入"Begin I"预测下一个单词 “have”。

**第一步:**是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 “(begin) I have a cat” (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
![![[Pasted image 20250529001717.png]]](https://i-blog.csdnimg.cn/direct/1fc5ac88c0ee437189d54038b0bf9241.png)
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵
X
X
X计算得到
Q
,
K
,
V
Q,K,V
Q,K,V矩阵。然后计算
Q
Q
Q和
K
⊤
K^\top
K⊤的乘积
Q
K
⊤
QK^\top
QK⊤。
![![[Pasted image 20250529001815.png]]](https://i-blog.csdnimg.cn/direct/f192d77984174a948becc917b97a84c1.png)
第三步:在得到
Q
K
⊤
QK^\top
QK⊤之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
![![[Pasted image 20250529001838.png]]](https://i-blog.csdnimg.cn/direct/0166bec6bbdb4f9eaf510e78e4e48e61.png)
得到Mask Q K ⊤ QK^\top QK⊤之后在Mask Q K ⊤ QK^\top QK⊤上进行Softmax,每一行的和都是1,但是单词0在单词1,2,3,4上的attention score都为0。
第四步:使用Mask
Q
K
⊤
QK^\top
QK⊤与矩阵
V
V
V相乘得到
Z
Z
Z,则单词1的输出向量
Z
1
Z_1
Z1是只包含单词1的信息的。
![![[Pasted image 20250529002009.png]]](https://i-blog.csdnimg.cn/direct/6b3a7ab8caf74a65919ce3e8d88786ec.png)
第五步:通过上述步骤就可以得到一个Masked Self-Attention的输出矩阵 Z i Z_i Zi,然后和Encoder类似,通过Multi-Head Attention拼接多个输出 Z i Z_i Zi,然后计算得到第一个Multi-Head Attention的输出 Z Z Z, Z Z Z与输入 X X X的维度相同。
5.2 Multi-Head Attention (2nd)
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个Decoder block的输出计算的,而是使用Encoder 的编码信息矩阵C计算的。
根据Encoder的输出 C C C计算得到 K , V K, V K,V,根据上一个Decoder block的输出 Z Z Z计算 Q Q Q (如果是第一个Decoder block则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在Decoder的时候,每一位单词都可以利用到Encoder所有单词的信息 (这些信息无需Mask)。
5.3 Softmax预测输出单词
Decoder block 最后的部分是利用 Softmax 预测下一个单词,在之前的网络层我们可以得到一个最终的输出
Z
Z
Z,因为 Mask 的存在,使得单词0的输出
Z
0
Z_0
Z0 只包含单词0的信息,如下:
![![[Pasted image 20250529002358.png]]](https://i-blog.csdnimg.cn/direct/1313bea3e12b4c62987ab8e741e28ba2.png)
Softmax 根据输出矩阵的每一行预测下一个单词:
![![[Pasted image 20250529002410.png]]](https://i-blog.csdnimg.cn/direct/caa812e43532443ea8c03a53a29aa373.png)
这就是Decoder block的定义,与Encoder一样,Decoder是由多个Decoder block组合而成。