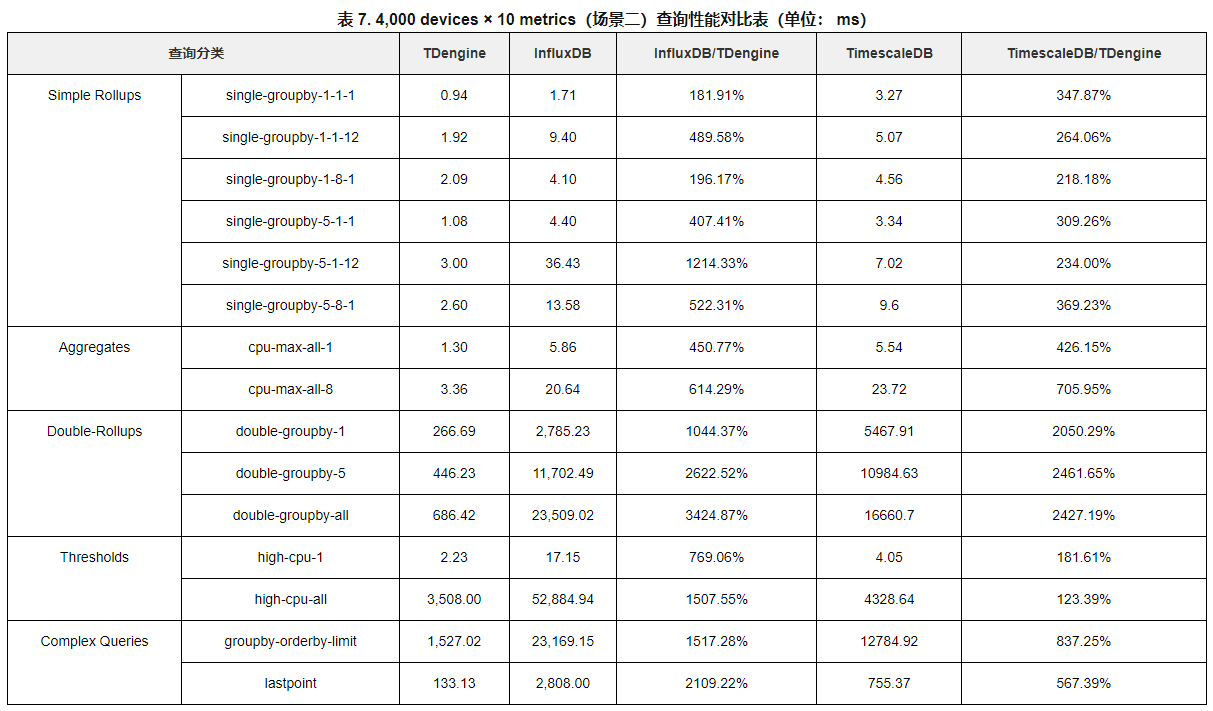
目录
- 1 基础概念与原理
- 1.1 Cloudera Manager的主要作用是什么?
- 1.2 与Ambari有何区别?
- 1.3 Cloudera Manager 的核心功能和架构是什么?
- 1.4 解释一下 Cloudera Manager 中的服务模型和角色?
- 1.5 Cloudera Manager 是如何实现对 CDH 集群的集中管理的?
- 2 集群运维场景
- 2.1 如何通过 CM 实现集群的滚动升级?
- 2.2 CM 如何监控 HDFS 的健康状态?若发现块丢失如何修复?
- 2.3 CM 如何在集群中添加新节点?(这个偏实践,较容易,概括一下,一看就行)
- 3 故障排查与调优
- 3.1 故障排查方面
- (1) 如何监控集群的健康状况并处理常见的节点故障?
- (2)假设集群中某个服务出现了故障,如何通过 Cloudera Manager 快速定位和解决问题?
- (3)假设集群中出现了数据不一致的情况,如何进行排查和修复?
- (4)若 Cloudera Manager 服务无法启动,该如何解决?
- (5)处理 HDFS 数据丢失问题时的解决思路
- (6)其他问题
- 3.2 CM 如何备份和恢复集群?
- (1)备份集群
- (2)恢复集群
- 3.3 性能优化方面
- (1)如何优化 Cloudera 管理的 Hadoop 集群的性能?
- (2)举例说明如何通过 CM 的监控数据来发现性能瓶颈,并进行优化调整?
- (3)查询性能优化方面,对于 Cloudera 的 SQL 引擎如 Impala 或 Hive,有哪些经验和技巧?
1 基础概念与原理
1.1 Cloudera Manager的主要作用是什么?
CM 是 Hadoop 生态的集中管理工具,提供集群部署、监控、配置和运维功能。
1.2 与Ambari有何区别?
- 开源性与社区驱动
- Ambari 开源,允许用户自由修改和二次开发。
- CM 免费版 功能受限,企业版需付费且闭源。
- Ambari 依赖社区力量维护和更新,兼容 Hadoop生态的最新组件(如Spark、Kylin等)。
- CM 则主要由Cloudera公司主导,定制化开发可能导致与社区版本脱节。
- 灵活性与二次开发能力
- Ambari 支持自定义服务集成,支持用户通过编写脚本和配置文件,集成第三方服务(如Elasticsearch、Redis、TensorFlow等),可管理非Hadoop生态的服务。
- CM仅支持预定义的CDH组件,扩展性较弱。
- Ambari允许界面与功能定制,用户可创建自定义视图、修改前端页面(如汉化、样式调整),并开发新的RESTful API接口。
- CM的界面和功能固化,不支持二次开发。
- 版本控制与滚动升级
- Ambari支持配置文件的版本历史记录和回滚功能,便于追踪变更。CM免费版缺乏此功能。
- Ambari支持在不中断服务的情况下滚动升级Hadoop组件(需HDFS HA支持),而CM不支持滚动升级,需停机操作。
- 权限管理与组件集成
- Ambari 权限控制简化,默认集成Apache Ranger进行权限管理,配置相对简单。
- CM使用Sentry,权限体系更复杂,适合企业级安全需求但学习成本较高。
- Ambari 组件兼容性更强,支持更广泛的组件(如ES、Kylin、Presto),适合需要多样化技术栈的场景。
- CM的集成组件较少,主要集中在CDH生态。
- 轻量化与快速部署
- Ambari的服务器端内存占用与CM相近(约2G),但整体部署流程更简单,适合中小型集群快速搭建。
- Ambari使用RPM包,与 Linux 系统兼容性好;CM 采用Parcel 包,部署流程较复杂。
- 总结:
- CM 更注重企业级稳定性(如高级安全、混合云支持)、商业化支持与深度监控,适合对运维自动化、安全合规要求高的大型企业。
- Ambari 更强调开源灵活性、社区协作、服务扩展性,适合需要自定义开发、频繁集成新技术或预算有限的企业。
若追求稳定性和“开箱即用”,CM更合适。若需深度定制和开放性,Ambari是优选。
1.3 Cloudera Manager 的核心功能和架构是什么?
- 核心功能
- 集群部署与配置管理:简化 CDH 集群的安装配置,自动完成节点配置、服务部署等任务,集中管理集群配置,统一更新配置参数。
- 服务管理:提供对 CDH 中各类服务(如 HDFS、MapReduce、HBase、Hive 等)的启动、停止、重启、状态监控等管理功能,方便查看、操作服务。
- 主机管理:对集群中的主机进行添加、删除、监控等操作,实时掌握资源使用情况,如 CPU、内存、磁盘空间等,便于及时调整主机配置,进行故障排除。
- 监控与警告:实时监测集群和各服务的运行状态,收集关键指标数据,如服务性能指标、资源使用情况等。可设置警告规则,当指标超出阈值或出现异常时及时发出警告通知。
- 用户与权限管理:支持基于角色的访问控制,可为不同用户分配不同的权限,确保集群的安全性,同时方便对用户权限进行统一管理和审计。
- 备份与恢复:提供集群的备份和恢复功能,可定期备份集群的配置和数据,以便在系统故障或数据丢失时快速恢复集群,减少停机时间。
- 架构
- 管理服务器(Cloudera Manager Server):是核心组件,与 CDH 集群交互,管理各服务和主机。存储集群的配置信息、服务状态等数据,通过与代理服务器通信来控制和监控集群中的节点。
- 代理服务器(Cloudera Manager Agent):安装在集群的每个节点上,作为管理服务器与节点间的桥梁。负责执行管理服务器下达的命令,如启动或停止服务、收集节点信息等,并将节点的状态和数据反馈给管理服务器。
- 数据库(Database):存储元数据,包括集群配置、服务状态、监控数据等。可用内置数据库或外部数据库,如 PostgreSQL、MySQL 等。
- Web 界面(Web UI):管理员可以通过 Web UI 查看集群状态、配置服务、执行操作等。
- API :CM提供的一套 REST API,可用编程方式与 CM 交互,实现自动化管理和集成。
1.4 解释一下 Cloudera Manager 中的服务模型和角色?
服务模型:CM 将 CDH 中的各个组件抽象为服务,如 HDFS 服务、YARN 服务、HBase 服务等。每个服务都有其特定的功能和配置参数,通过管理这些服务,可管理整个 CDH 集群。
角色:指服务在集群中所扮演的具体职责。不同的服务有不同的角色,如:
主角色(Master Roles) :通常是服务的主要节点,负责协调和管理整个服务的运行,如 HDFS 的 NameNode、YARN 的 ResourceManager 等。
工作角色(Worker Roles) :在集群工作节点上运行的角色,负责执行具体的数据处理和存储任务,如 HDFS 的 DataNode、YARN 的 NodeManager 等。
客户端角色(Client Roles) :允许用户或其他服务与 CDH 服务进行交互的组件,如 HDFS 客户端、Hive 客户端等。
1.5 Cloudera Manager 是如何实现对 CDH 集群的集中管理的?
统一的管理界面 :通过 Web UI 或 API 提供了一个集中式的管理平台,管理员可在一个界面上查看、管理整个 CDH 集群的所有服务、主机和配置,无需分别登录到各节点。
自动化部署与配置 :借助自动化脚本和工具,能快速在集群中部署 CDH 服务,根据预定义的模板和策略配置,确保集群的一致性和稳定性。
集中监控与告警 :实时收集、分析集群中各节点和服务的运行数据,一旦发现问题或异常,能及时发出通知,使管理员能迅速响应并采取措施。
权限控制与安全管理 :基于角色的访问控制机制,可对不同用户、用户组设不同权限,限制对集群资源的访问和操作,保障集群安全性。
服务协调与管理 :统一的协调、管理 CDH 中的各个服务,包括服务的启动、停止、重启、故障转移等操作,确保服务的正常运行和高可用性。
2 集群运维场景
2.1 如何通过 CM 实现集群的滚动升级?
CM 界面选择“升级”选项,按服务依赖顺序逐个节点重启,确保服务高可用,并监控升级日志。
2.2 CM 如何监控 HDFS 的健康状态?若发现块丢失如何修复?
通过 CM 的 HDFS 服务仪表盘查看块报告,使用 hdfs fsck 命令定位丢失块,并通过 Balancer 重新均衡数据。
2.3 CM 如何在集群中添加新节点?(这个偏实践,较容易,概括一下,一看就行)
准备工作:
- 确保新节点的硬件和网络配置符合集群的要求,如足够的 CPU、内存、磁盘空间,以及与集群中其他节点的网络连通性。
- 在新节点上安装与集群中其他节点相同版本的 CDH 软件和 Cloudera Manager Agent。
- 配置新节点的主机名和 IP 地址,并确保其能正确解析。
- 安装并配置 JDK,设置 JAVA_HOME 环境变量。
- 配置无密码 SSH 访问,以便 Cloudera Manager 能够远程管理新节点。
准备工作做好后,在 CM 的 Web 界面,选 “主机” ,点击 “添加主机” 按钮。在弹出的对话框中,输入新节点的主机名或 IP 地址,安装包的路径(可以是本地路径或远程仓库地址)。点击 “下一步”,等一会就好了,安装完成后,检查新节点的状态,确保其显示为 “已连接” 并且健康状况良好。
将新节点分配给服务:
- 根据集群的需要,将新节点分配给相应的服务。例如,如果新节点将用于存储数据,可以将其分配给 HDFS 的 DataNode 角色;如果将用于运行计算任务,可以将其分配给 YARN 的 NodeManager 角色等。
- 选择要分配服务的角色,点击 “添加角色实例” 按钮,并选择新添加的节点作为目标主机。
- 配置角色的参数,如 DataNode 的存储目录、NodeManager 的内存和 CPU 配置等。
- 完成配置后,启动新添加的角色实例。
3 故障排查与调优
3.1 故障排查方面
(1) 如何监控集群的健康状况并处理常见的节点故障?
如何监控集群:(偏实践,很容易,知道一下就行)
进到 CM Web 界面,里面的 “ 主机 ” 页面可查看所有节点的健康状况、资源使用情况(如 CPU、内存、磁盘 I/O 等)、运行的服务、角色状态;
“ 服务 ” 页面可查看各服务的健康状况、性能指标、警告信息等。Cloudera Manager 会根据预定义的阈值和规则,对服务的关键指标进行监控,出现问题时会发出警告通知;
还可通过自定义监控仪表板,集中展示 " 重点关注指标 " 和 图表,方便快速了解集群的整体运行状态。
处理常见的节点故障:
-
磁盘空间不足:节点磁盘空间不足,会导致数据写入失败或服务运行异常。
解决方法: 清理磁盘空间 增加磁盘容量(如添加新硬盘、扩展存储卷等) 重新分配数据存储目录到其他有足够空间的磁盘上 -
内存使用过高:可能会导致服务响应缓慢或出现内存溢出错误。
解决方法: 尝试优化服务的内存配置参数(如调整 JVM 堆大小、YARN 容器内存限制等) 关闭不必要的后台进程 增加节点的物理内存 -
CPU 使用率过高:可能会影响服务的性能。
解决方法: 分析系统进程和线程,找出占用 CPU 资源较多的进程,优化其代码或配置 调整服务的调度策略(如 YARN 的资源分配和调度算法)来平衡 CPU 负载 -
网络问题:可能导致节点之间的通信延迟增加或中断,影响数据传输和分布式计算任务的执行。
解决方法: 检查网络设备(如交换机、路由器等)的配置和状态,修复网络连接问题 优化网络拓扑结构以提高网络性能
(2)假设集群中某个服务出现了故障,如何通过 Cloudera Manager 快速定位和解决问题?
- 查看服务状态和警告信息:登上 CM 的 Web 界面,进入 “服务” 页面,找到出现故障的服务,查看其状态和警告信息。
Cloudera Manager 会显示服务的健康状况、导致问题的可能原因、相关日志信息。
- 分析服务日志:根据警告信息,定位到相关的服务日志文件。通过分析日志中的错误信息和堆栈跟踪,可以了解服务故障的具体原因。
Cloudera Manager 提供了日志查看功能,可以方便地查看服务的日志内容,包括错误日志、警告日志和调试信息等。
- 检查服务配置:检查服务的配置参数是否正确。可通过对比服务的默认配置和当前配置,找出问题并修正。
可能存在的配置问题包括:参数设置不合理(如内存分配不足、端口冲突等)、配置文件语法错误、配置更新未生效等。
- 重启服务或角色实例:若服务故障是由 临时的系统问题 或 进程异常 导致的,可以尝试重启服务或相关的角色实例。
在 Cloudera Manager 中,选择出现故障的服务,点击 “重启” 按钮,或者选择具体的角色实例进行重启操作。
- 进一步排查:若还是无法解决,则进一步深入排查。根据排查结果,采取相应的解决措施,如修复数据、优化资源分配、升级服务版本等。
检查服务所依赖的其他服务是否正常运行(如数据库服务、ZooKeeper 服务等)
检查数据的一致性和完整性
分析系统的资源使用情况(如内存、CPU、磁盘 I/O 等)是否存在瓶颈
(3)假设集群中出现了数据不一致的情况,如何进行排查和修复?
第一步:排查问题,例如网络问题、磁盘故障、节点故障、服务异常等。
- 确认问题范围
① 确定具体表现。是某些文件丢失、数据损坏,还是不同节点间的数据版本不一致。
② 确定受影响的数据范围,是单个文件、某个表,还是整个集群。 - 检查 HDFS 数据完整性
用 fsck 命令检查文件系统的健康状况。hdfs fsck / -files -blocks -locations。该命令会列出文件系统中的问题,如丢失的块、损坏的文件等。 - 检查 HDFS 副本一致性
确保 HDFS 中的文件副本数量和位置符合预期。如,检查是否有副本丢失或副本所在的节点不可用。 - 检查相关服务日志
看一下 HDFS、NameNode、DataNode 等服务的日志文件,查找可能导致数据不一致的错误信息。日志文件通常位于 /var/log/hadoop-hdfs/ 目录下。 - 检查节点状态
① 通过 CM 的 Web 界面,检查所有节点的健康状态,确认是否有节点离线或出现故障。
② 检查节点的磁盘空间是否不足,或者磁盘是否出现故障。
第二步:修复问题
- 修复 HDFS 数据问题
若发现有丢失的块,可从其他副本中恢复数据。如:hdfs dfsadmin -recoverLease <file_path>; 若某个 DataNode 节点出现故障,可尝试重启该节点的服务,或将其从集群中移除并重新添加。 - 重新平衡 HDFS 副本
若副本数量不足或分布不均匀,可以运行 HDFS 的 balancer 工具来重新平衡数据,如:hdfs balancer - 修复元数据问题
若 NameNode 的元数据出现损坏,可尝试从备份中恢复元数据;或使用 hdfs namenode -format 命令重新格式化 NameNode。
注意:这样会删掉所有数据。 - 验证修复结果
① 修复完后,再次运行 hdfs fsck 命令,确认数据已恢复一致。
② 检查相关服务的日志,确认没有新的错误信息。
(4)若 Cloudera Manager 服务无法启动,该如何解决?
第一步:排查问题
可能由多种原因引起的,如配置错误、数据库问题、网络故障等。
- 检查日志文件
① 看 Cloudera Manager Server 的日志文件,通常位于 /var/log/cloudera-scm-server/ 目录下。文件中可能会包含导致服务无法启动的错误信息。
② 看 Cloudera Manager Agent 的日志文件,通常位于 /var/log/cloudera-scm-agent/ 目录下。 - 检查数据库连接
① 确保 Cloudera Manager Server 能成功连接到数据库(如 PostgreSQL 或 MySQL)。检查数据库服务是否正常运行,网络连接是否正常。
② 检查数据库的配置文件(如 cloudera-scm-server.properties),确认数据库连接参数是否正确。 - 检查网络连接
① 确保 Cloudera Manager Server 和 Agent 之间的网络连接正常。
② 检查防火墙规则,确保相关端口(如 7180、7182 等)没有被阻止。 - 检查系统资源
确保服务器的 CPU、内存和磁盘空间充足。如果资源不足,可能会导致服务无法启动。 - 恢复备份
若问题无法解决,可尝试从备份中恢复 Cloudera Manager 的配置和数据。
(5)处理 HDFS 数据丢失问题时的解决思路
首先,通知团队成员,启动应急响应流程,暂停所有可能影响 HDFS 数据的操作,避免问题进一步恶化。
- 快速定位问题
① hdfs fsck 命令检查文件系统的健康状况,确认丢失的文件和块。
② 查看 HDFS NameNode 和 DataNode 的日志文件,查找可能导致数据丢失的错误信息。 - 分析原因,例如:发现其中一个 DataNode 节点的磁盘出现故障,导致部分数据块丢失。则需确认 HDFS 的副本策略是否正确,以及是否有足够的副本用于恢复数据。
- 修复数据
① 从其他副本中恢复丢失的数据块。使用 HDFS 的 dfsadmin 命令重新分配数据块:hdfs dfsadmin -recoverLease <file_path>
② 若某些文件的副本数量不足,则手动添加副本:hdfs dfs -setrep -w 3 <file_path> - 重新平衡数据
用 HDFS 的 balancer 工具重新平衡数据,确保数据均匀分布在所有 DataNode 上:hdfs balancer - 预防措施
① 定期监控磁盘健康状况,及时更换故障磁盘。
② 定期运行 hdfs fsck 命令,检查文件系统的完整性。
③ 确保 HDFS 的副本策略符合业务需求,避免因副本数量不足导致数据丢失。
(6)其他问题
- YARN任务频繁失败,如何通过CM定位问题?
检查 ResourceManager 日志、任务 Attempt 日志,分析资源申请是否超限(如内存不足),调整 YARN 的 yarn.scheduler.maximum-allocation-mb 等参数。
- CM中如何配置Hive的元存储高可用?
将Hive Metastore与MySQL或PostgreSQL集成,并在CM中配置多实例和负载均衡。
3.2 CM 如何备份和恢复集群?
(1)备份集群
- 数据备份
HDFS 中的数据,可通过 HDFS 备份工具(如 distcp 命令)将数据复制到其他 HDFS 集群或备份存储系统中。
例如,使用 distcp 命令将数据从生产集群的 HDFS 复制到备份集群的 HDFS。
对于其他服务的数据(如 Hive 的元数据存储在 MySQL 数据库中),可使用相应的数据库备份工具(如 mysqldump)进行备份。
- 配置备份
Cloudera Manager 提供了导出配置功能,可以将集群的配置信息(包括服务配置、主机配置、用户权限配置等)导出为一个 XML 文件。
在 Cloudera Manager 的 Web 界面中,进入 “管理” 菜单,选择 “导出配置” 选项,选择要导出的配置范围(如整个集群、特定服务等),然后保存导出的配置文件。
(2)恢复集群
- 数据恢复
HDFS 的数据,可从备份的 HDFS 集群或存储系统中使用 distcp 命令将数据恢复到生产集群的 HDFS 中。
对于其他服务的数据,使用相应的数据库恢复工具(如 mysql)将备份的数据库数据恢复到目标数据库中。
- 配置恢复
在 Cloudera Manager 中,进入 “管理” 菜单,选择 “导入配置” 选项,选择之前导出的配置文件进行导入。根据导入的配置文件,Cloudera Manager 会自动更新集群的配置信息,包括服务配置、主机配置等。
- 验证恢复结果
完成数据和配置的恢复后,需要对集群进行全面的验证,确保数据一致性和完整性,以及服务的正常运行。可通过运行一些测试任务(如 MapReduce 作业、Hive 查询等)来验证集群的功能是否正常。
3.3 性能优化方面
(1)如何优化 Cloudera 管理的 Hadoop 集群的性能?
优化集群性能可从多个方面入手,如硬件资源、服务配置、数据管理等。以下是一些常见的优化策略:
-
硬件资源优化
① 合理分配资源 :根据集群用途(如计算密集型、存储密集型)合理分配 CPU、内存和磁盘资源。如: 需要大量计算的任务(如 MapReduce 或 Spark),要有足够的 CPU 和内存资源; 存储密集型任务(如 HDFS 数据存储),应优化磁盘 I/O 性能。② 使用 SSD 磁盘 :对于需要高 I/O 性能的场景(如 Impala 的缓存数据存储),可以使用 SSD 磁盘来提高读写速度。
③ 网络优化 :确保集群的网络带宽足够,避免网络瓶颈。可使用高速网络(如 10Gbps 或更高)来提高数据传输效率。
Impala —— 开源的分布式 SQL 查询引擎,允许用户使用类似SQL的查询语言直接查询存储在 Hadoop 中的数据,而无需将数据移动到传统的关系数据库中。
主要特性:性能高(用 Hadoop 的计算能力,能快速执行大规模数据查询);支持实时查询;无缝集成Hadoop 生态系统;减少数据移动的需求,降本增效。
-
服务配置优化
① HDFS 配置优化 :a.副本数量 :根据数据的重要性和可用性需求,合理设置 HDFS 副本数量(默认为 3)。对于非关键数据,可以减少副本数量以节省存储空间。 b.块大小 :根据数据的访问模式调整 HDFS 块大小(默认为 128MB)。对于大文件,可以增加块大小以减少元数据管理开销;对于小文件,可以保持默认值。 c.内存分配 :为 NameNode 和 DataNode 分配足够的内存,确保它们能够高效运行。② YARN 配置优化 :
a.资源分配 :合理配置 YARN 的资源分配策略(如 Capacity Scheduler 或 Fair Scheduler),确保不同队列之间的资源分配公平且高效。 b.内存和 CPU 配置 :根据节点的硬件资源,合理设置每个节点的内存和 CPU 配置。例如,设置 yarn.nodemanager.resource.memory-mb 和 yarn.nodemanager.resource.cpu-vcores 参数。 c.容器大小 :根据任务的需求,调整容器的内存和 CPU 配置。例如,对于内存密集型任务,可以增加容器的内存分配。③ MapReduce 配置优化 :
a.内存分配 :根据任务的需求,调整 Map 和 Reduce 任务的内存分配。例如,设置 mapreduce.map.memory.mb 和 mapreduce.reduce.memory.mb 参数。 b.任务并行度 :根据数据量和集群资源,调整 Map 和 Reduce 任务的并行度。例如,设置 mapreduce.job.reduces 参数。 c.数据压缩 :在 MapReduce 任务中使用数据压缩(如 Snappy 或 Gzip),减少数据传输和存储开销。④ Hive 配置优化 :
a.内存分配 :为 Hive 的执行引擎(如 Tez 或 MapReduce)分配足够的内存。例如,设置 hive.tez.container.size 参数。 b.查询优化 :使用分区表和索引优化查询性能。例如,为经常查询的列创建分区或索引。 c.数据存储格式 :选择合适的数据存储格式(如 Parquet 或 ORC),这些格式支持高效的列存储和压缩,可以显著提高查询性能。⑤ Impala 配置优化 :
a.内存分配 :为 Impala 分配足够的内存,确保其能够高效运行。如设置 impalad 的内存限制参数。 b.缓存策略 :合理配置 Impala 的缓存策略,将热点数据缓存到内存中,提高查询性能。 c.查询优化 :使用分区表和索引优化查询性能。如为经常查询的列创建分区或索引。⑥ 数据管理优化
a.数据分区 :对数据进行分区,将数据按时间、地区或其他逻辑划分,可以显著提高查询性能。 b.数据压缩 :使用数据压缩技术(如 Snappy、Gzip)减少数据存储空间和传输开销。 c.数据清理 :定期清理无用的数据和日志文件,释放存储空间并提高集群性能。⑦ 监控与调优
a.使用 CM 监控 :通过 CM 监控功能,实时查看集群的资源使用情况(如 CPU、内存、磁盘 I/O、网络带宽等),根据监控数据动态调优。 b.警告与优化 :设置合理的警告阈值,当资源使用接近瓶颈时,及时调整资源配置或优化任务。
补充:大数据存储格式 —— Parquet、Avro、ORC, 数据存储格式定义了数据的存储、读写方式,直接影响存储效率、查询性能和数据检索速度。数据存储主要是2种方式:行式(如 Avro)、列式存储(如 Parquet 和 ORC)。
- Parquet:支持多种压缩算法,如Snappy、Gzip和LZO。兼容 Impala、Drill、Arrow,支持Hadoop、Spark、Hive等平台。是数据湖架构(如Iceberg、Delta Lake)的首选格式,适合复杂数据结构和跨平台兼容性需求。
- ORC:主要用于Hadoop生态系统中的大数据处理和分析,与Hive深度集成。ORC的压缩率更高,主要用于数据仓库和大规模数据分析场景,特别适合需要事务性支持的数据仓库场景。
(2)举例说明如何通过 CM 的监控数据来发现性能瓶颈,并进行优化调整?
假如有一个运行 Hive 查询的 Hadoop 集群,通过 CM 监控数据发现查询性能较差。以下是通过监控数据发现性能瓶颈并进行优化的步骤:
-
查看监控数据
① 登录 CM Web 界面,查看 Hive 服务的监控数据。
② 分析资源使用情况a.CPU 使用率:若使用率接近 100%,说明 CPU 资源不足。可通过增加节点的 CPU 核心数或优化查询逻辑来解决。 b.内存使用率:若使用率接近 100%,说明内存资源不足。可通过增加节点的内存容量或调整内存分配参数来解决。 c.磁盘 I/O:若使用率较高,说明磁盘性能瓶颈。可通过优化数据存储格式(如使用 Parquet 或 ORC)或增加磁盘数量来解决。 d.网络带宽:若网络带宽使用率较高,说明网络瓶颈。可通过优化数据传输逻辑或升级网络设备来解决。 -
定位具体问题:若监控数据显示 Hive 查询的内存使用率较高,且查询响应时间较长。通过查看 Hive 的日志文件,发现 Hive 查询执行时频繁出现内存不足的错误。
-
优化调整:根据监控数据和日志分析结果,可采取如下优化措施 —— 调整 Hive 内存配置
① 调整参数,增加 Hive 查询的内存分配。如: a.调整 hive.tez.container.size 参数,将每个容器的内存从默认值(如 1GB)增加到 2GB。 b.调整 hive.tez.java.opts 参数,为 JVM 分配更多的堆内存。② 优化查询逻辑
a.使用分区表和索引优化查询性能。例如,为经常查询的列创建分区或索引。 b.优化 Hive SQL 查询语句,避免复杂的嵌套查询和大数据量的全表扫描。③ 数据存储优化 :
将数据存储格式从 TextFile 转换为 Parquet 或 ORC,这些格式支持高效的列存储和压缩,可以显著提高查询性能。 -
验证优化效果:优化完,再次运行 Hive 查询,通过 CM 监控数据验证优化效果。
① 查询响应时间 :查询响应时间是否显著缩短。
② 资源使用情况 :内存使用率是否降低,CPU 和磁盘 I/O 是否恢复正常。
通过以上步骤,可用 CM 监控数据发现性能瓶颈,通过调整配置和优化逻辑解决问题。
(3)查询性能优化方面,对于 Cloudera 的 SQL 引擎如 Impala 或 Hive,有哪些经验和技巧?
- Hive 查询性能优化
① 分区表:根据查询的常见条件(如时间、地区等)对表进行分区。查询时,指定分区条件可以减少扫描的数据量。
CREATE TABLE sales (
id INT,
amount INT,
date STRING
)
PARTITIONED BY (year INT, month INT);
SELECT * FROM sales WHERE year = 2025 AND month = 5;
② 索引:为经常查询的列创建索引。
CREATE INDEX idx_sales_date ON TABLE sales (date) AS 'COMPACT';
③ 优化数据存储格式:使用高效的存储格式(如 Parquet 或 ORC),这些格式支持列存储和数据压缩,可提高查询性能。
CREATE TABLE sales (
id INT,
amount INT,
date STRING
)
STORED AS PARQUET;
④ 调整内存配置:为 Hive 的执行引擎(如 Tez 或 MapReduce)分配足够的内存。
SET hive.tez.container.size=2048;
SET hive.tez.java.opts=-Xmx1536m;
⑤ 优化查询逻辑:避免复杂的嵌套查询和大数据量的全表扫描
- Impala 查询性能优化
可从数据存储、查询优化、资源分配等方面入手进行性能优化。
数据存储优化
① 用高效的数据格式 Parquet、ORC;
Parquet,列存储格式,支持高效的压缩和编码技术,能够显著提高查询性能。它是 Impala 推荐的数据存储格式。
STORED AS PARQUET;
ORC,也是一种高效的列存储格式,适合存储结构化数据,支持复杂的类型和高效的压缩。
STORED AS ORC;
② 数据分区 —— 分区表(可以看一下前面)根据查询的常见条件(如日期、地区等)对表进行分区,查询时指定分区条件;
③ 数据排序 —— 创建表时指定排序键,可以优化数据的存储顺序,提高查询性能。
CREATE TABLE my_table (
id INT,
name STRING,
amount DOUBLE
)
STORED AS PARQUET
SORTED BY (id);
④ 数据压缩 —— 选合适的压缩编码方式(如 Snappy、Gzip),可减少存储空间并提高 I/O 效率。
CREATE TABLE my_table (
id INT,
name STRING,
amount DOUBLE
)
STORED AS PARQUET
TBLPROPERTIES ('parquet.compression'='SNAPPY');
查询优化
① 优化查询语句
a. 避免全表扫描:尽量使用分区条件和索引,减少扫描的数据量。
b. 减少复杂查询:避免嵌套子查询和复杂的关联查询,尽量将复杂逻辑分解为多个简单查询。
② 使用物化视图:通过物化视图缓存查询结果。
CREATE MATERIALIZED VIEW sales_summary AS
SELECT year, month, SUM(amount) AS total_amount
FROM sales
GROUP BY year, month;
③ 缓存热点数据:将频繁查询的数据缓存到内存中。
INVALIDATE METADATA my_table;
REFRESH my_table;
资源分配优化
① 调整内存分配:根据节点的硬件资源,为 Impala 守护进程分配足够的内存。SET MEM_LIMIT=4G;
② 调整查询并发,根据集群的资源情况,合理设置并发查询数,避免过多的并发查询导致资源竞争。SET NUM_NODES=5;
③ 使用资源池,通过 CM 创建资源池,为不同的用户或应用分配不同的资源,确保资源的合理利用。
监控与调优
① 使用 CM 监控查询性能,如可通过 CM 的监控功能,进入 Impala 服务页面,查看 Impala 的查询性能指标(如 查询的执行时间、资源使用情况等),及时发现性能瓶颈。
② 分析查询计划,通过 EXPLAIN 命令查看查询计划,分析查询的执行路径,优化查询逻辑。
EXPLAIN SELECT * FROM sales WHERE year = 2023 AND month = 5 AND amount > 1000;
③ 调整配置参数:根据监控数据和查询计划,动态调整 Impala 的配置参数,如内存分配、并发查询数等。
SET MEM_LIMIT=4G;
SET NUM_NODES=5;