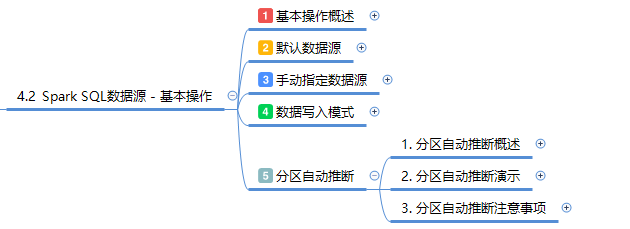
在本节实战中,我们学习了Spark SQL的分区自动推断功能,这是一种提升查询性能的有效手段。通过创建具有不同分区的目录结构,并在这些目录中放置JSON文件,我们模拟了一个分区表的环境。使用Spark SQL读取这些数据时,Spark能够自动识别分区结构,并将分区目录转化为DataFrame的分区字段。这一过程不仅展示了分区自动推断的便捷性,还说明了如何通过配置来控制分区列的数据类型推断。通过实际操作,我们加深了对Spark SQL分区管理的理解,并掌握了如何利用分区来优化数据处理流程,从而提高数据处理的效率和性能。

4.2.5 Spark SQL 分区自动推断
news2026/5/22 10:52:40
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2394774.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【图像处理入门】2. Python中OpenCV与Matplotlib的图像操作指南
一、环境准备
import cv2
import numpy as np
import matplotlib.pyplot as plt# 配置中文字体显示(可选)
plt.rcParams[font.sans-serif] [SimHei]
plt.rcParams[axes.unicode_minus] False二、图像的基本操作
1. 图像读取、显示与保存
使用OpenCV…
Spring Boot微服务架构(九):设计哲学是什么?
一、Spring Boot设计哲学是什么?
Spring Boot 的设计哲学可以概括为 “约定优于配置” 和 “开箱即用”,其核心目标是极大地简化基于 Spring 框架的生产级应用的初始搭建和开发过程,让开发者能够快速启动并运行项目…
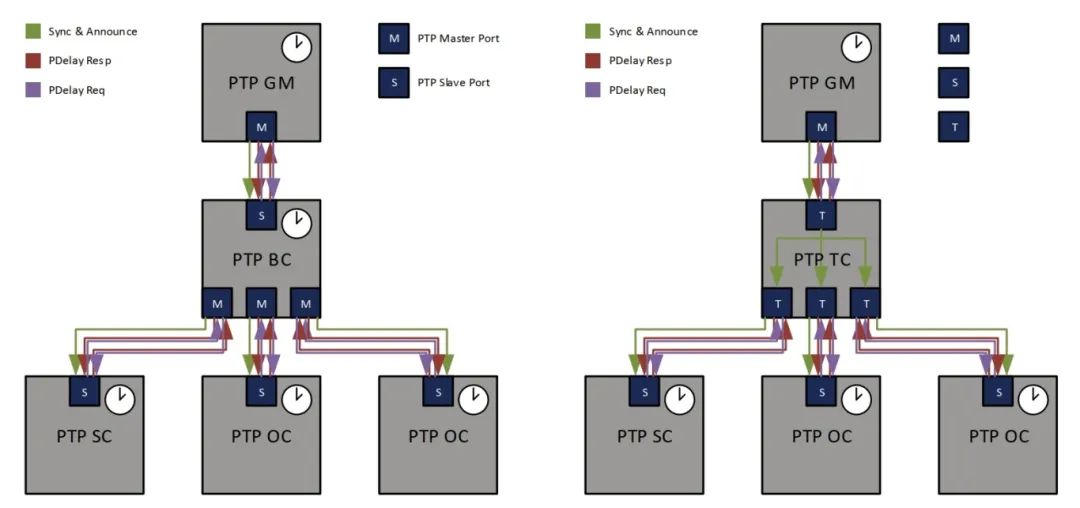
TC/BC/OC P2P/E2E有啥区别?-PTP协议基础概念介绍
前言
时间同步网络中的每个节点,都被称为时钟,PTP协议定义了三种基本时钟节点。本文将介绍这三种类型的时钟,以及gPTP在同步机制上与其他机制的区别
本系列文章将由浅入深的带你了解gPTP,欢迎关注
时钟类型
在PTP中我们将各节…
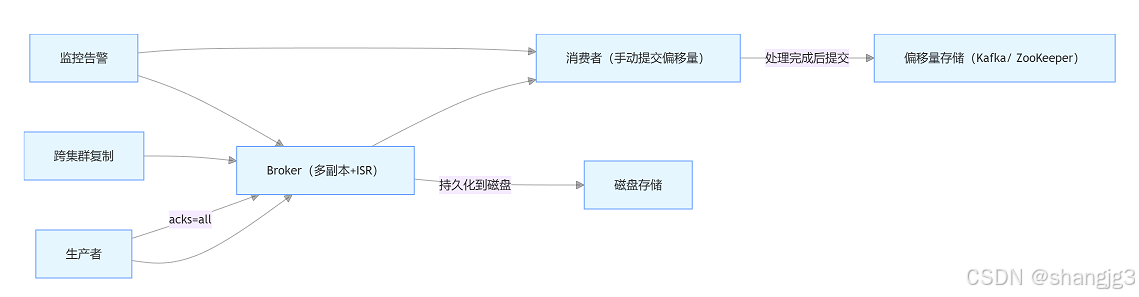
Kafka数据怎么保障不丢失
在分布式消息系统中,数据不丢失是核心可靠性需求之一。Apache Kafka 通过生产者配置、副本机制、持久化策略、消费者偏移量管理等多层机制保障数据可靠性。以下从不同维度解析 Kafka 数据不丢失的核心策略,并附示意图辅助理解。 一、生产者端:…
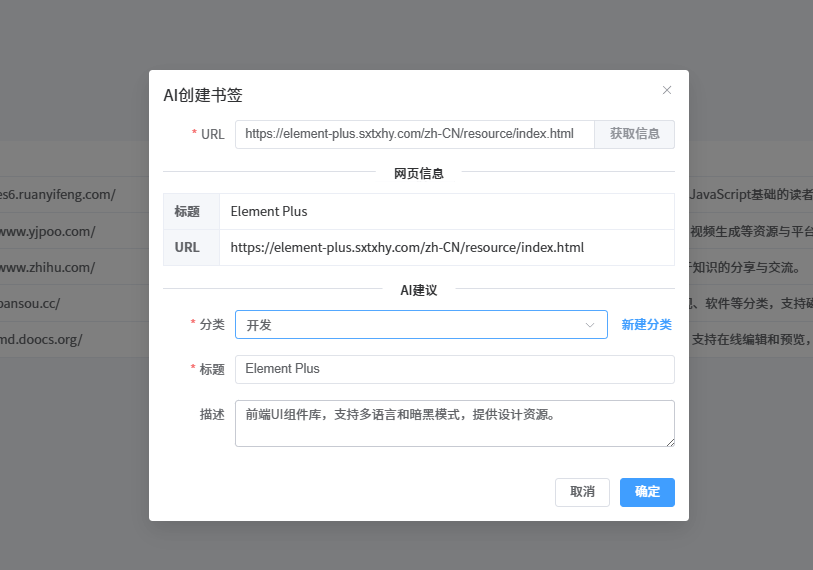
AI书签管理工具开发全记录(八):Ai创建书签功能实现
文章目录 AI书签管理工具开发全记录(八):AI智能创建书签功能深度解析前言 📝1. AI功能设计思路 🧠1.1 传统书签创建的痛点1.2 AI解决方案设计 2. 后端API实现 ⚙️2.1 新增url相关工具方法2.1 创建后端api2.2 创建crea…
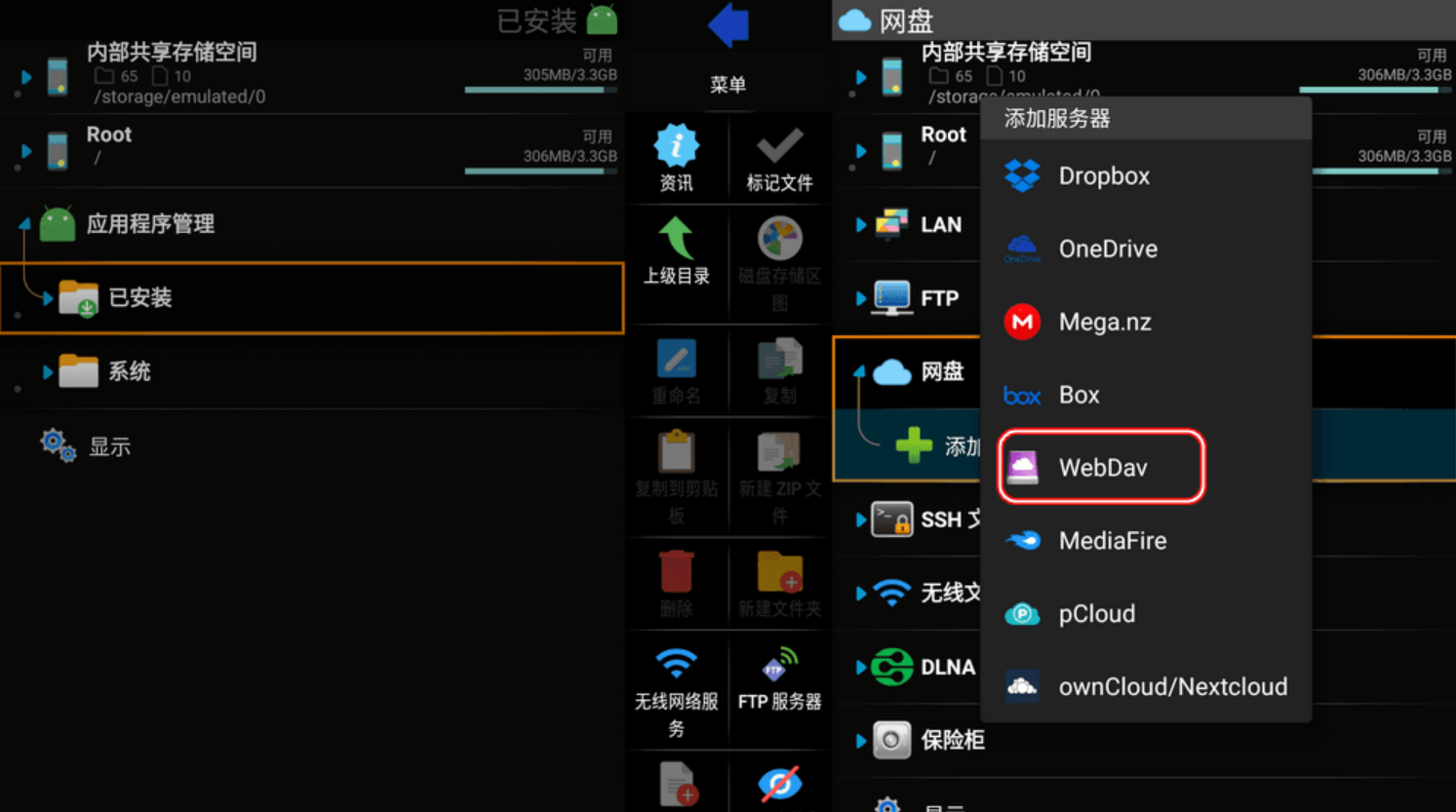
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用
X-plore v4.43.05 强大的安卓文件管理器-MOD解锁高级版 手机平板/电视TV通用 应用简介: X-plore 是一款强大的安卓端文件管理器,它可以在电视或者手机上管理大量媒体文件、应用程序。…

使用多Agent进行海报生成的技术方案及评估套件-P2P、paper2poster
最近字节、滑铁卢大学相关团队同时放出了他们使用Agent进行海报生成的技术方案,P2P和Paper2Poster,传统方案如类似ppt生成等思路,基本上采用固定的模版,提取相关的关键元素进行模版填充,因此,海报生成的质量…
Redis--缓存工具封装
经过前面的学习,发现缓存中的问题,无论是缓存穿透,缓存雪崩,还是缓存击穿,这些问题的解决方案业务代码逻辑都很复杂,我们也不应该每次都来重写这些逻辑,我们可以将其封装成工具。而在封装的时候…

python:在 PyMOL 中如何查看和使用内置示例文件?
参阅:开源版PyMol安装保姆级教程
百度网盘下载 提取码:csub
pip show pymol 简介: PyMOL是一个Python增强的分子图形工具。它擅长蛋白质、小分子、密度、表面和轨迹的3D可视化。它还包括分子编辑、射线追踪和动画。
可视化示例:打开 PyM…
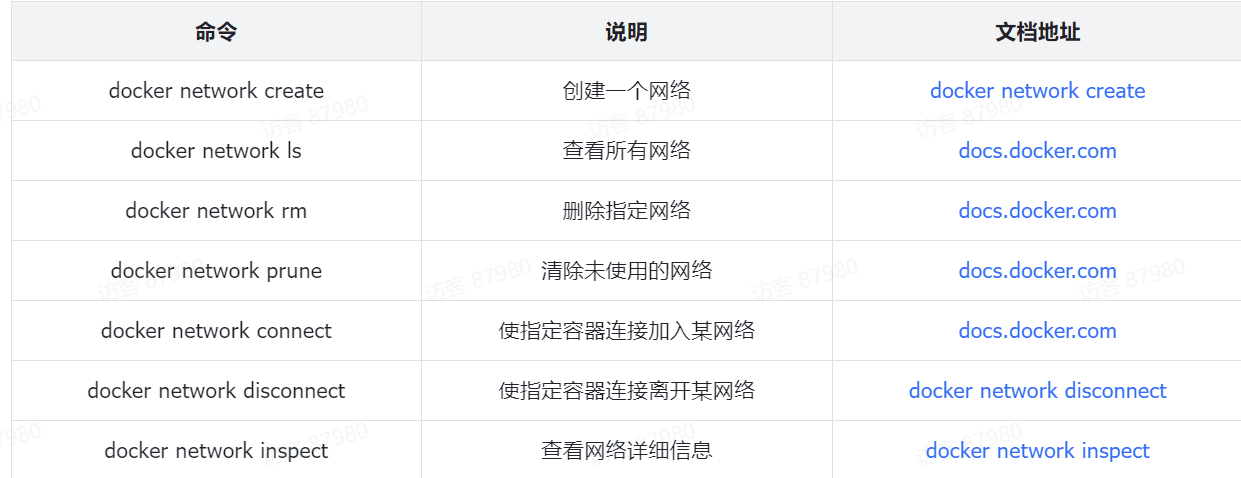
SpringCloud——Docker
1.命令解读
docker run -d
解释:创建并运行一个容器,-d则是让容器以后台进程运行
--name mysql
解释: 给容器起个名字叫mysql
-p 3306:3306
解释:-p 宿主机端口:容器内端口,设置端口映射
注意:
1、…
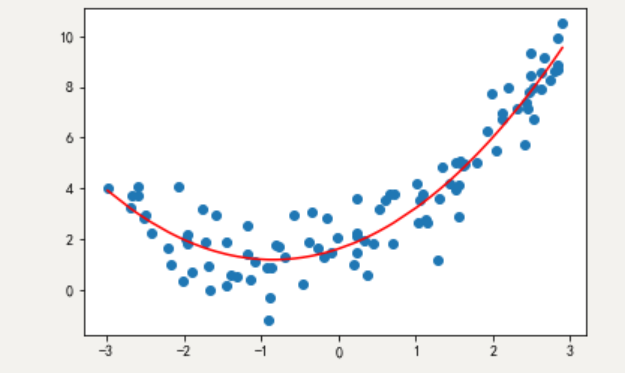
机器学习:欠拟合、过拟合、正则化
本文目录: 一、欠拟合二、过拟合三、拟合问题原因及解决办法四、正则化:尽量减少高次幂特征的影响(一)L1正则化(二)L2正则化(三)L1正则化与L2正则化的对比 五、正好拟合代码…

运用集合知识做斗地主案例
方法中可变参数
一种特殊形参,定义在方法,构造器的形参列表里,格式:数据类型...参数名称;
可变参数的特点和好处
特点:可以不传数据给它;可以传一个或者同时传多个数据给它;也可以…

《HelloGitHub》第 110 期
兴趣是最好的老师,HelloGitHub 让你对开源感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…

使用 Shell 脚本实现 Spring Boot 项目自动化部署到 Docker(Ubuntu 服务器)
使用 Shell 脚本实现 Spring Boot 项目自动化部署到 Docker(Ubuntu 服务器) 在日常项目开发中,我们经常会将 Spring Boot 项目打包并部署到服务器上的 Docker 环境中。为了提升效率、减少重复操作,我们可以通过 Shell 脚本实现自动…

day023-网络基础与OSI七层模型
文章目录 1. 网络基础知识点1.1 网络中的单位1.2 查看实时网速:iftop1.3 交换机、路由器 2. 路由表2.1 查看路由表的命令2.2 路由追踪命令 3. 通用网站网络架构4. 局域网上网原理-NAT5. 虚拟机上网原理6. 虚拟机的网络模式6.1 NAT模式6.2 桥接模式6.3 仅主机模式 7.…
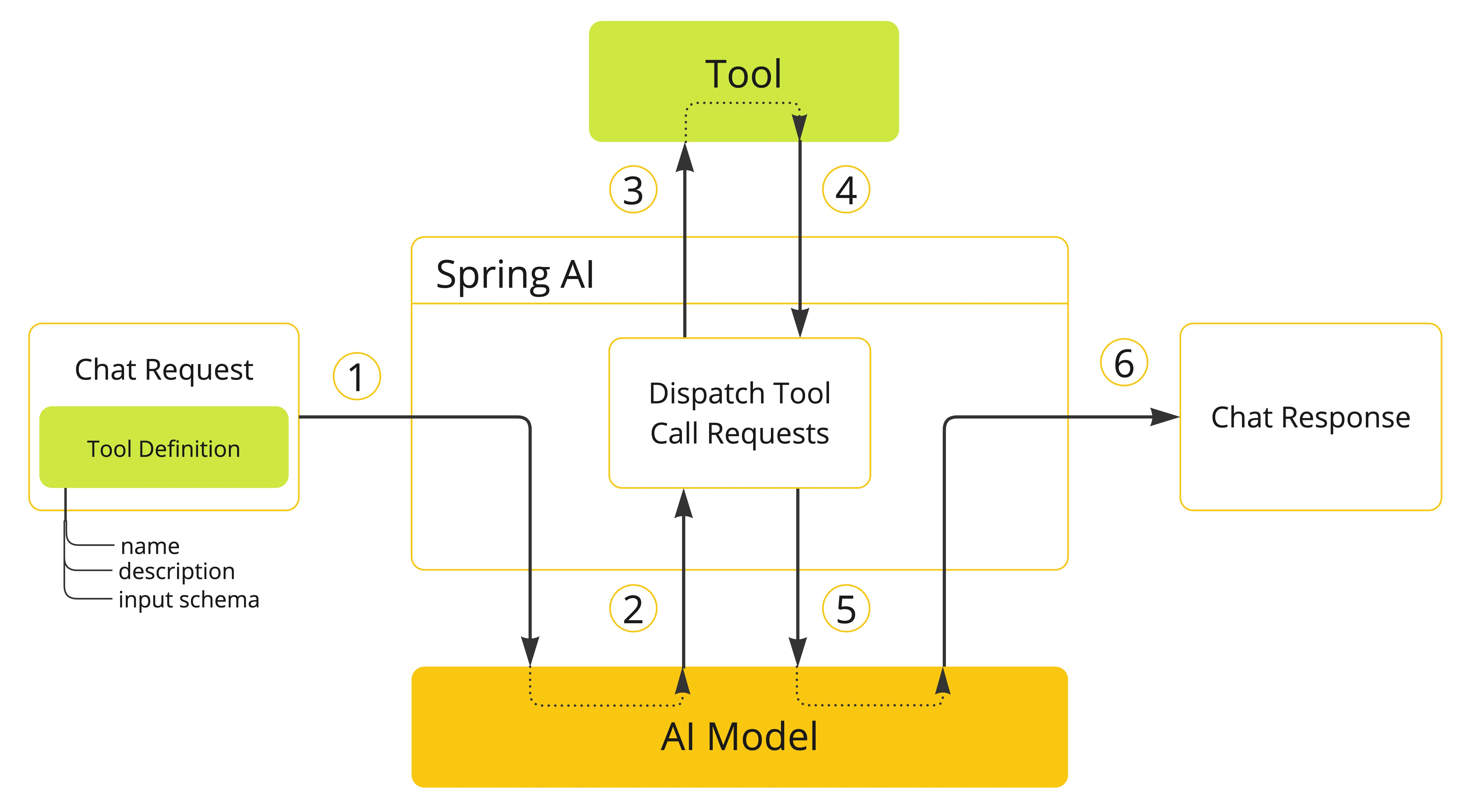
SpringAI系列4: Tool Calling 工具调用 【感觉这版本有bug】
前言:在最近发布的 Spring AI 1.0.0.M6 版本中,其中一个重大变化是 Function Calling 被废弃,被 Tool Calling 取代。Tool Calling工具调用(也称为函数调用)是AI应用中的常见模式,允许模型通过一组API或工具…

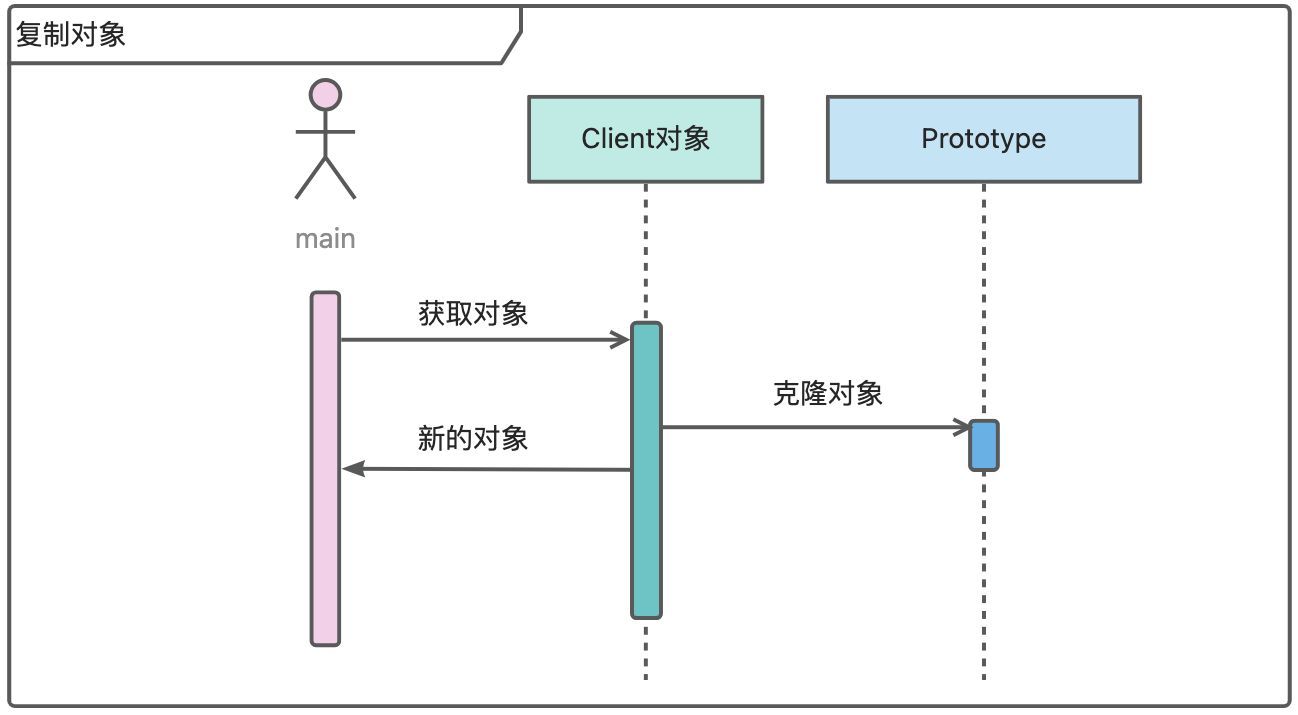
设计模式——原型设计模式(创建型)
摘要
本文详细介绍了原型设计模式,这是一种创建型设计模式,通过复制现有对象(原型)来创建新对象,避免使用new关键字,可提高性能并简化对象创建逻辑。文章阐述了其优点,如提高性能、动态扩展和简…
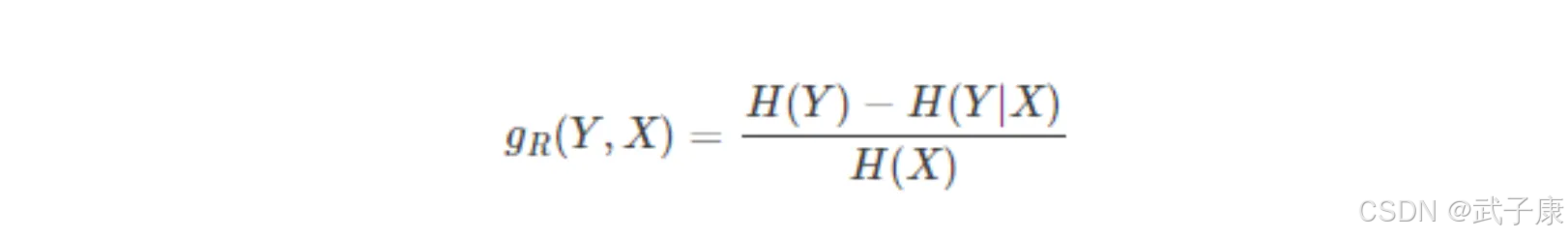
大数据-273 Spark MLib - 基础介绍 机器学习算法 决策树 分类原则 分类原理 基尼系数 熵
点一下关注吧!!!非常感谢!!持续更新!!!
大模型篇章已经开始!
目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 FigmaCursor 自动设计原型
Java篇开…