概括
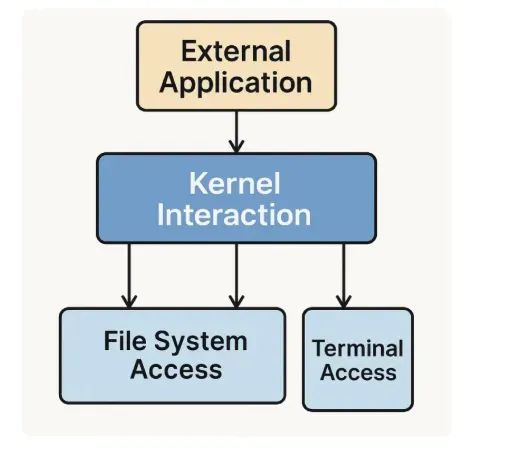
在这篇文章, 我将介绍一种Tiled Light 变体,主要针对AMD Graphics Core Next(GCN)架构进行优化,我们的方法应用于游戏 古墓丽影:崛起 中,特别是我们在通过光列表生成和阴影贴图渲染之间交错进行异步计算来优化性能。光列表生成在同一计算核心中分2个步骤按照Tile进行:初步粗略步骤利用简单的屏幕空间轴对齐边界框(AABB)对任意光源进行交集测试,第二步骤是精细修建,通过对 Tile 中的每一个像素进行进一步的测试,判断3D空间中的点是否在光源的真实形状内。此外,我们还提出了一种高效的混合解决方案,结合了Tile 延迟光照和Tile 前向光照。
介绍
传统来说,实时延迟照明是使用 alpha 混合来一次累积一个灯光的照明贡献。它的主要优势在于能够将灯光分配和应用到代表光量内部三维空间点的像素上。另一方面,对于基本的前向光照模型,光照列表是根据网格实例和光照体之间的边界体交叉测试,在 CPU 上为每个网格实例建立的。这种方法通常会导致处理每个像素的光照数量大幅增加,尤其是对于大型网格,因为光照列表是网格实例在屏幕上占用的所有像素的共享列表。
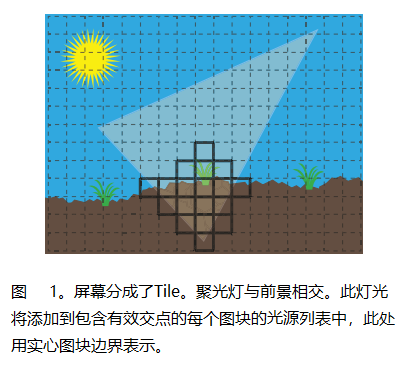
最近,随着DirectX 11的引入,基于计算的 Tile 光照成为了一种流行的延迟光照替代方案。Tile 光照通过将帧缓冲区表示为n×m的固定分辨率瓦片网格来工作。GPU用于生成每个Tile的光索引列表,包含重叠Tile屏幕边界的光源引用。光照过程从包含当前处理像素的Tile中提取光列表(见图1)。
这是基于计算的基本 Tile 照明方案的高级概述:
每块Tile:
- (a) 为每块tile在深度缓冲区中找到最小和最大深度。
- (b) 每个线程通过将光源的 bounding sphere 与 tile 边界进行相交测试来检测出光源的相交和不相交子集。
- (c) 将与Tile相交的光源索引存储在本地数据存储(LDS)中。
- (d) 最终列表可供所有线程进一步处理。
- 最近,出现了几种用于 tiled Lighting 平铺照明的方法,如AMD的 Forward + 平铺照明 [Harada et al. 12],其中的主要目的是摆脱传统的延迟照明。以充分利用EQAA。这种方法将Tile 按深度均匀的分割成单元,从而使其成为一个 N * M * L 的光照列表组成的3D网格。通过测试光的边界球与瓷砖平截头体的侧平面以及单元的近平面和远平面的对比来进行消隐的。另一个已知的变体是 Insomniacs 的Light Linked List [Bezrati 14],它提出了一种解决方案,即使用GPU上的链表来减少/管理 光照列表 的占用空间。另一种变体是(Clustered Deferred and Forward Shading)分簇延迟和前向着色 [Olsson et al. 12], 它通过分簇进一步降低了 Tile 占用率。这实现了将 Tile 更理想地划分为单元。
平铺照明的主要优点如下:
平铺延迟光照是单次处理,因为每个像素的光照通过循环访问存储在对应平铺中的光源列表来完成。这使得该方法在应对overlapping
光源时比传统的延迟光照更具弹性,因为GBuffer中的数据只被调用一次,且最终的颜色值只被写入帧缓冲区一次。
与传统延迟光照不同,平铺光照存在一种前向变体。原因在于,当我们绘制多边形网格时,可以在处理过程中从包含被着色像素的平铺中提取相同的光源列表(命中率高)。
使用平铺光照的另一个不太为人所知的优点是,光源列表的生成是异步计算的理想候选,这使得我们可以在帧更新过程中与其他不相关的图形工作交错进行该处理。
以往的方法,如 [Harada et al. 12] 和 [Olsson et al. 12],在每个平铺的光源列表中包含多余的光源,因为这些列表是基于简单的包围球相交测试生成的。所有先前的技术中还存在额外的冗余,因为单元格包含了大量未占用的空间。在AAA游戏中,我们的许多光源并非球形,实际上,我们必须支持几种不同特征的光源形状,如圆锥、胶囊和盒子。仅基于包围体和分区平铺边界构建列表,导致与最终精细修剪后的列表相比,光源列表中存在许多冗余。
我们发现,通过编写一个精简的专用计算着色器来执行精细修剪,我们能够获得显著的性能提升,因为用于光照的更复杂的着色器不再需要处理列表中的冗余光源。此外,光源列表的生成与实际光照的分离使得我们能够在渲染阴影贴图时以异步计算方式运行列表生成,实际上,这为我们提供了免费获得的精细修剪列表。
此外,我们的方法是平铺延迟光照和平铺前向光照的混合体。这使得我们能够通过一种更为硬件高效的窄GBuffer区使用延迟方法来为大多数像素进行光照,然后在需要材质特定光照模型的情况下,使用平铺前向光照进行处理。
我们的方法
此前关于tiled Lighting 的论文,例如 [Harada et al., 12] 和 [Olsson et al., 12],主要针对处理大量球形光源,通常处理1-2千个光源。此外,这些论文描述了设计用于处理光源在空间中相对理想分布的场景的算法。尽管我们的方法也能够处理大量光源,但我们发现在实际的游戏关卡中,摄像机视锥体内的光源数量通常不超过40-120个。在我们的情况下,我们经常遇到的是较少但较大的光源,这些光源占据了相同的空间。许多光源是为了在阴影贴图中获得良好的像素分布而设计的狭窄的大聚光灯。在这种情况下,使用包围球并不是一个好的表示方法。最终,如果没有额外的剔除,我们的光源列表会包含大量光源,其中有些光源不会影响任何瓦片像素。
在每帧中,我们接收到一组由网格和门户系统分类为可见(位于摄像机视锥内)的光源。对于屏幕上的每个瓦片,我们生成一个精细修剪的光源列表。只有当瓦片中的至少一个像素表示在3D空间中位于光源体积内的点时,才会将该光源包含在列表中。将所有瓦片中的像素与所有可见光源进行测试的成本过于高昂。为了解决这一问题,我们首先构建一个粗略的光源列表,其中包含与瓦片边界相交的光源的屏幕空间轴对齐包围盒(AABB)。瓦片边界通过它在屏幕上的xy区域和该瓦片区域内深度缓冲区的最小和最大深度来简单地定义。我们在GPU上确定每个可见光源的屏幕空间AABB。
该过程的伪代码如下所示:
-
每个摄像机:
a) 在CPU上找到与摄像机视锥体相交的光源。
b) 按形状对这组光源进行排序。
c) 在GPU上确定每个光源的屏幕空间紧密AABB,无论其形状如何。这是通过计算摄像机和光源的凸包之间的相交体积来完成的。我们进一步使用光源的包围球来约束AABB。
-
每个16 × 16像素的瓦片:
a) 对每个瓦片,在深度缓冲区中找到最小和最大深度。
b) 每个计算线程通过将光源的AABB与瓦片边界相交测试,处理一组不相交的光源子集。
c) 将与瓦片相交的光源索引存储在本地数据存储器(LDS)中。我们称之为粗略列表。
d) 在同一个计算核中,遍历粗略光源列表。i) 每个线程测试瓦片深度缓冲区的四个像素,判断这些像素是否位于光源的真实形状内。ii) 测试结果存储在由每个线程维护的位字段中,其中每个位代表相应的粗略光源。
e) 对所有位字段执行按位或(bitwise OR)操作,并使用它来生成精细修剪的光源列表。
精细修剪和光照过程中提前退出之间的区别在概念上非常微妙。然而,这种区别在两个方面显得尤为重要。首先,与用于光照的着色器相比,剔除的精简着色器消耗的资源较少,如我们将在下一节中所述,这对性能有很大影响。其次,通过异步计算,我们可以吸收大部分精细修剪的成本,其中包括循环处理冗余光源的成本。
实现细节
在接下来的讨论中,我们主要针对AMD GCN架构进行说明,尽管这些做法适用于任何现代GPU。现代GPU核心通过任务调度来隐藏延迟。我们将这些核心称为计算单元(CU)。所有工作都打包成波前进行处理。无论是计算、顶点着色、像素着色等,每个CU最多可以容纳40个波前,每个波前由64个线程组成。这些线程以锁步方式运行,类似于SSE4中的4宽锁步运行。资源池(如寄存器和本地存储LDS)在每个CU上是共享的,这意味着消耗的资源越多,每个CU能够容纳的任务就越少,从而导致GPU隐藏延迟的能力急剧下降。
事实证明,渲染阴影贴图和生成精细修剪的光源列表是一个很好的匹配。根据我们的计时,阴影贴图渲染在我们的游戏中通常需要2到4毫秒。此外,这是一个产生非常少的波前工作量的过程,主要依赖于扫描转换器和数据传输。原因在于阴影贴图渲染仅处理深度通道,这意味着对于不透明网格不会生成任何实际的像素着色工作。而生成精细修剪光源列表主要依赖于大量ALU密集型波前。因此,我们可以通过异步计算来吸收大部分生成列表的时间。
我们来详细描述一下算法步骤。首先,步骤1(a)是收集帧中所有可见的光源。我们通过CPU上的典型网格和门户系统来完成此操作。
在步骤1(b)中,我们在CPU上按光源的形状类型对可见光源进行排序。这样可以允许我们使用固定顺序的循环来处理光源,每个循环专门用于处理特定类型的光源。这在瓦片前向光照中尤为重要,因为在这种情况下,一个波前处理的64个像素通常不在同一个瓦片中。由于64个线程是锁步运行的,执行路径的分歧会导致效率降低。通过按类型排序光源,我们最大化了所有线程在执行路径上的一致性。在我们的案例中,球体/胶囊是一个类型/执行路径,锥形/楔形是另一个类型,最后是盒子。
接下来,在步骤1(c)中,我们为每个可见光源确定其屏幕空间AABB。作为输入,每个光源由一个定向包围盒(OBB)表示,且顶点具有非均匀缩放,允许我们更好地表示狭窄的聚光灯和楔形光源。为了确定光源的AABB,我们找到摄像机视锥和凸包的相交体积的点集。通过对缩放后的OBB的四边形进行视锥剪裁,并使用每个生成的扇形的最终点集来更新AABB。摄像机视锥中的任何八个点如果位于凸包内,也需要应用于AABB的拟合。最后,我们确定光源包围球的AABB,并将其与已建立的AABB相交作为最终结果。需要注意的是,尽管这一过程需要大量处理,但它仅针对每个摄像机进行一次,而不是针对每个瓦片执行。这项工作可以在CPU上完成,但我们选择在GPU上通过异步计算着色器完成。
在步骤2中,生成最终的每瓦片光源列表的工作被执行,下面描述了各个组成部分。步骤2中的所有部分都在每瓦片级别的一个计算内核中执行。由于瓦片大小为16×16像素,内核的调度通过以下线程组计数执行:(宽度+15)/16、(高度+15)/16和1。该内核声明为单个波前线程组:64×1×1。
首先,在步骤2(a)中,我们必须建立与线程组正在操作的瓦片相关联的屏幕空间AABB。64个线程中的每个线程读取瓦片中的四个独立深度值,并确定四个样本的最小值和最大值。接下来,通过HLSL的内置函数InterlockedMin()和InterlockedMax(),建立瓦片的全局最小值和最大值。
在步骤2(b)–(c)中,我们执行初始的粗略修剪测试。每个可见光源的屏幕空间AABB将被测试是否与瓦片的AABB相交,而不考虑光源的真实形状。每个线程处理一组不相交的光源子集,因此执行numVisibleLights/64次迭代。此外,使用单波前线程组允许我们在粗略测试过程中保持光源的顺序,因为64个线程是同步运行的。通过粗略测试的光源索引最终存储在LDS中。
值得注意的是,屏幕空间AABB对应于摄像机空间中的剪切子视锥体,如 图2所示。在 [Harada et al., 12] 和 [Olsson et al., 12] 的实现中,瓦片光照是通过将每个光源的包围球与瓦片关联的视锥体平面进行测试来实现的。然而,当我们已经知道光源的屏幕空间AABB时,可以更快地进行相同的测试。这也允许对某些光源类型(如聚光灯)进行更紧密的拟合,这样可以减少在精细修剪时的计算时间。此外,使用AABB进行测试还可以降低寄存器的使用量,因为在遍历光源时,我们不再需要在寄存器中保持瓦片的六个视锥平面。
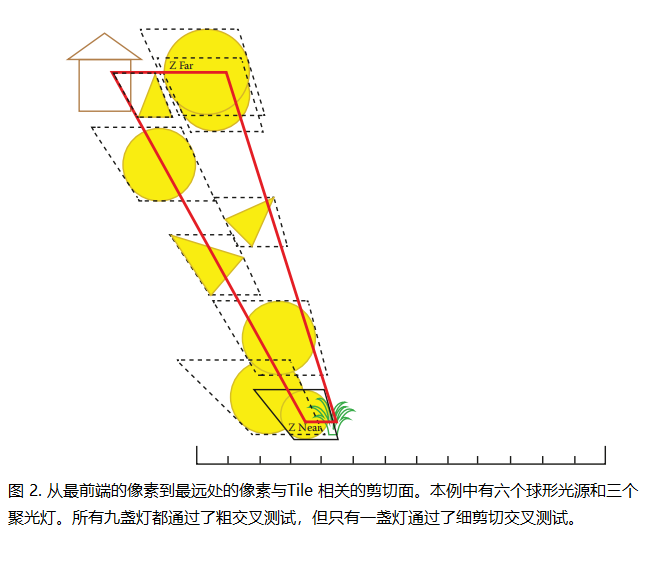
最后,在步骤2(d)–(e)中,我们执行精细修剪。精细修剪后的光源列表是粗略光源列表的子集。瓦片中的每个像素都被测试,判断其对应的3D空间点是否位于光源的真实体积内。包含一个或多个此类点的光源将被放入精细修剪光源列表中。每个线程负责测试瓦片16×16像素中的2×2个像素(对于半分辨率光照则是1×1个像素),并维护一个64位掩码,其中每个位表示相应光源的体积是否包含至少一个由该线程处理的四个点之一。一旦我们以这种方式处理了所有粗略光源,我们通过使用HLSL内置的InterlockedOr()指令来确定最终的64位掩码。最终,该位掩码用于从粗略光源列表中去除冗余项,并将最终的精细修剪光源列表写入内存。精细修剪的效果如图2所示。
引擎集成
为了在着色器中实现更大的灵活性,通常会使用宽G缓冲区来存储更多的参数。然而,这会消耗更多的内存,并给总线带来很大的压力。我们在早期决定我们的游戏必须以1920×1080的分辨率运行,因此我们决定使用预通道延迟渲染实现,这种方法在[Engel 09]中有描述,并使用窄G缓冲区。我们的G缓冲区包含一个深度缓冲区和以R8G8B8A8格式存储的法线和镜面反射指数(specular power)。镜面反射指数的符号位用于指示是否启用Fresnel效应。在Xbox One上,这样的精简占用允许我们充分利用快速的ESRAM。
我们的预通道渲染管线的各个阶段如 图3 左侧所示。几何体渲染到屏幕两次。第一次是法线-深度通道,生成深度缓冲区,包含世界空间法线和镜面反射指数。第二次几何体渲染到屏幕是复合通道,它是最后的阶段。这个阶段负责执行光照并结合光照效果。阴影贴图的渲染在法线-深度通道之后进行,而每瓦片光源列表的生成则作为异步计算任务来调度。下一阶段是延迟光照,它以全屏通道的形式运行。每个像素通过累加与该像素所属瓦片相关的光源列表中的光源贡献来完成光照。我们将最终的漫反射和镜面反射结果写入独立的渲染目标,这使我们在最后的复合通道中能够通过不同的纹理来调制它们。

为了在特定材料(如眼睛、皮肤和布料)上实现自定义光照,我们使用了瓦片前向光照。在这种情况下,光照在复合通道过程中进行,类似于延迟光照中处理瓦片光源列表的方式。这就带来了一个问题,因为我们在前向和延迟阶段都要为像素计算光照。为了解决这个问题,我们在光照为前向瓦片光照的每个像素上标记模板缓冲区(stencil buffer)。在延迟光照阶段,通过使用模板测试来跳过这些像素,从而避免对这些像素重复计算光照。
关于每瓦片光源列表的格式,有多种存储方式可供选择。最明显的选项是为整个屏幕分配一个缓冲区,每个瓦片固定消耗一些8位或16位的光源索引条目。使用8位索引只能允许屏幕上最多256个光源,而16位则提供了比我们实际需要的更大范围。为了实现更紧凑的内存占用,我们选择将列表存储为R10G10B10A2_UINT格式的块,其中每个10位分量存储一个光源的索引,而2位分量表示有多少个光源索引是活跃的。我们为每个瓦片存储8个这样的块,最终限制每个瓦片最多可包含24个精细修剪后的光源。正如之前提到的,在LDS中粗略列表最多允许64个光源。8个这样的块的总占用为每个瓦片32字节,相当于屏幕上每个像素1位。请注意,10位索引意味着每帧最多允许1024个光源与摄像机视锥相交。
在我们的实现中,我们为直接光源和探针光源分别使用了独立的光源列表,每个列表每瓦片的限制同样为24个光源。需要注意的是,光源列表的生成只执行一次。这是可能的,因为在步骤2(e)执行期间,在计算侧可能会临时存在多达64个精细修剪后的光源。随后,在这一步中我们将这些光源按指定的光源列表分类存储在LDS中。
正如在介绍中提到的,瓦片光照实现中常见的做法是沿深度进一步将瓦片划分为多个单元(cells),如[Olsson et al., 12]中所描述的。这会进一步增加内存占用,因为每个单元都要存储一个独立的光源列表。在延迟光照过程中,另一个问题是每个线程可能会从与波前中其他线程不同的单元中获取光源列表。这迫使我们将光源属性加载到向量寄存器中,而不是标量寄存器中。正如前一节所述,这降低了我们在每个CU中填充更多波前的能力,从而降低了我们在GPU上隐藏延迟的能力。最终,我们发现精细修剪后的光源列表在实际应用中已经移除了大部分冗余,因此不需要再进一步划分瓦片单元。这一点从图2中可以看出,并且在下一节的热图中也得到了体现。
使用我们的方法的一个限制是,生成的光源列表仅适用于写入深度缓冲区的不透明表面。在我们的场景中,大多数透明效果是占据相同局部空间的多层粒子效果。我们得出的结论是,逐像素为这些效果计算光照的代价太高,因此我们决定使用顶点光照来处理这些效果。
对于常规的基于网格的透明表面,我们决定使用传统的前向光照,在每个网格上基于包围体积相交在CPU上生成光源列表。由于我们的透明表面是按材质排序的,因此这些网格并不大,因此不会从瓦片光源列表中受益太多。此外,我们支持光源组,允许美术人员手动从传统的前向光照物体的光源列表中移除特定光源。这个特性使他们能够修剪列表,只保留最重要的与透明表面相交的光源。
结果
在本节中,我们展示了一个内部场景,以1920×1080的分辨率运行,并启用和禁用精细剪枝。图4显示了粗略剔除的结果。粗略列表生成需要0.5毫秒,并异步运行。图5显示了精细剪枝后的结果,这在列表生成中需要1.7毫秒。然而,由于异步计算,成本被很好地隐藏了。图6中的热图指示了图4和5中每个图块中光源的占用率。我们可以看到,没有精细剪枝的光源计数在几乎每个图块中都明显更高。正如预期的那样,我们看到延迟照明的执行时间显著下降,从5.4毫秒降至启用精细剪枝后的1.4毫秒。

方法概述
我们提出了一种新的图块照明变体,它在同一个计算内核中分两步执行光源列表生成。初始粗略传递基于简单的屏幕空间AABB边界体积交叉测试,无论光源类型如何,都在本地存储中生成光源列表。第二步是精细剪枝,它对粗略列表执行进一步测试,测试图块中的每个像素是否位于光源的真实形状内。包含一个或多个此类点的光源被放入精细剪枝列表中,并写入内存。我们发现,在实践中,这个过程显著减少了每个图块的光源数量。
异步计算
在AMD GCN架构上,仅深度传递不透明网格为GPU核心生成的工作非常少。我们利用这一事实,通过在渲染阴影贴图时交织粗略和精细剪枝步骤的工作来隐藏大部分综合成本,从而免费获得无冗余光源列表。
光源列表存储
虽然支持多种光源类型,但光源列表的最终占用空间为每个像素1位,每个图块最多24个精细剪枝光源。
混合渲染方法
最后,提出了一种在图块延迟渲染和图块前向渲染之间的高效混合方法,其中图块延迟照明作为模板测试的全屏传递,以避免对被图块前向材质照亮的像素进行两次照明。为了进一步加速图块前向渲染,我们按固定顺序将光源列表按类型排序。这使得波前中所有像素处理相同光源循环的机会最大化。
参考文献
-
-
[ Bezrati 14 ] Abdul Bezrati. “Real-Time Lighting via Light Linked List.” Paper presented at SIGGRAPH, Vancouver, Canada, August 12–14, 2014.
-
[ Engel 09 ] Wolfgang Engel. “The Light Pre-Pass Renderer: Renderer Design for Efficient Support of Multiple Lights.” SIGGRAPH Course: Advances in Real Time Rendering in 3D Graphics and Games, New Orleans, LA, August 3, 2009.
-
[ Harada et al. 12 ] Takahiro Harada, Jay McKee, and Jason C. Yang. “Forward+: Bringing Deferred Lighting to the Next Level.” Eurographics Short Paper, Cagliari, Italy, May 13–18, 2012.
-
[ Olsson et al. 12 ] Ola Olsson, Markus Billeter, and Ulf Assarsson. “Clustered Deferred and Forward Shading.” Paper presented at High Performance Graphics, Paris, France, June 25–27, 2011