目录
进程地址的引入
进程地址空间基础原理
区域划分的本质
如何理解进程地址空间
越界访问的本质
进一步理解写时拷贝
重谈 fork 返回值
结语
进程地址的引入
我们先来看一段代码:
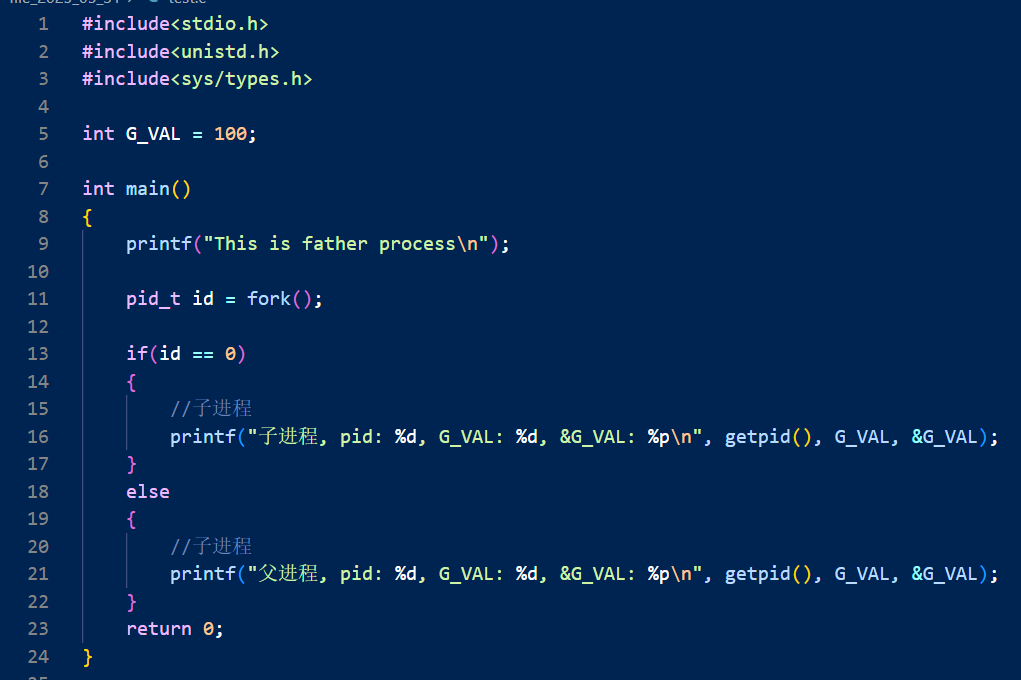
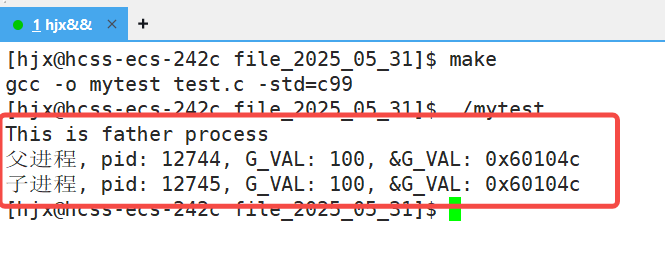
首先我们可以看到,父进程和子进程是可以同时可以看到一个变量的,这也很正常,因为子进程的数据最开始就是从父进程那里来的
但是我们现在再来看一个代码:
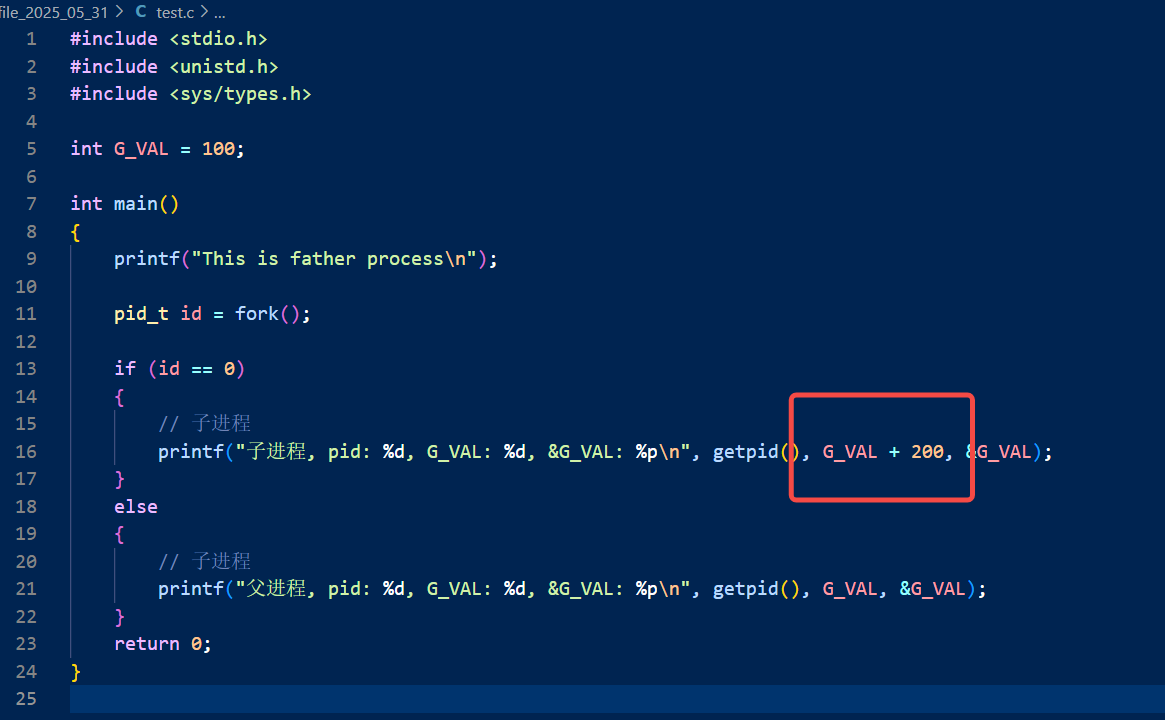
唯一的改动在这里,接下来我们来看一下结果:
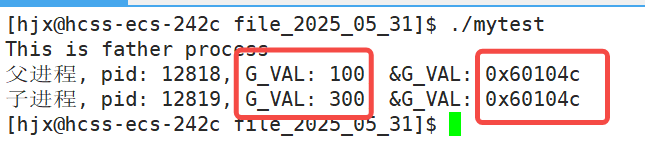
这对吗?注意看,这上面两个变量的地址是一样的,但是两个变量的值却是不一样的,这不对啊!!
不知道各位有没有想起我们在学习进程的时候,最开始学到的一个函数,叫做fork,这个函数的返回值也是可以同时返回给同一个参数,但是当时我们就说,这是由于有两个不同的进程,但是我们没有就着那个变量来谈
但是就用最基础的知识来讲,我们就有理由怀疑,这两个变量并不是同一个变量,并且这两个地址也不是同一个地址
事实也确实如此,这就是我们接下来要讲解的——进程地址空间
进程地址空间基础原理
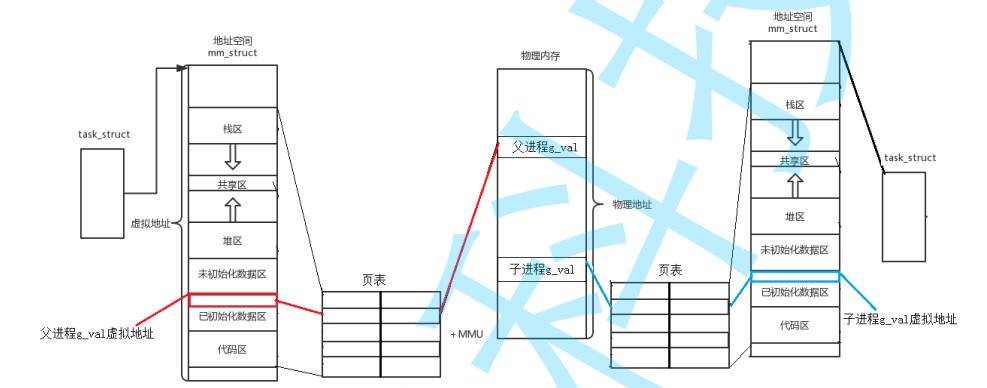
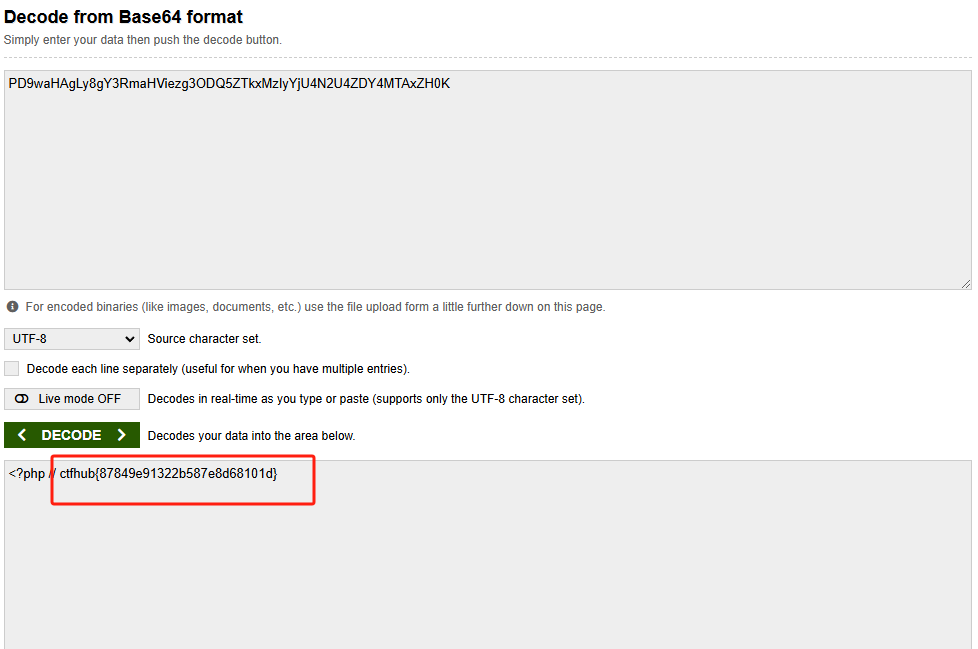
我们先来看这样一张图
实际在我们的系统中,进程和内存之间,在逻辑上并不是紧紧相连的
我们进程中的数据,都是要先被放进一个叫做地址空间的地方上,而我们上面G_VAL的地址,其实就是这里的地址空间的地址
接着还有一个页表,页表负责映射地址空间的地址与物理内存的地址(比如左边是虚拟地址,我们在页表中就可以根据这个虚拟地址查询到某个变量在物理内存中具体被存放在哪里)
我们现在将上面这张图拆开来进行讲解:
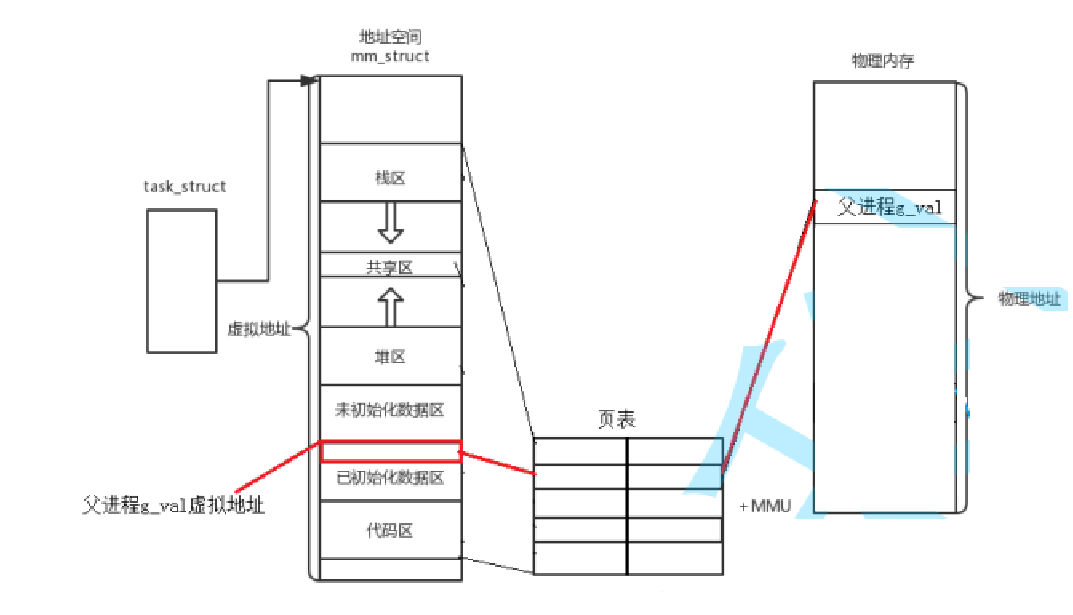
今天我们有一个父进程,然后这个父进程有自己的进程地址空间,也有页表
现在父进程里面有一个变量,叫做G_VAL,值是100
注意,比如这个时候我们的代码实际是保存在物理内存中的
现在我们对这个父进程执行fork操作,那么就有了所谓子进程:
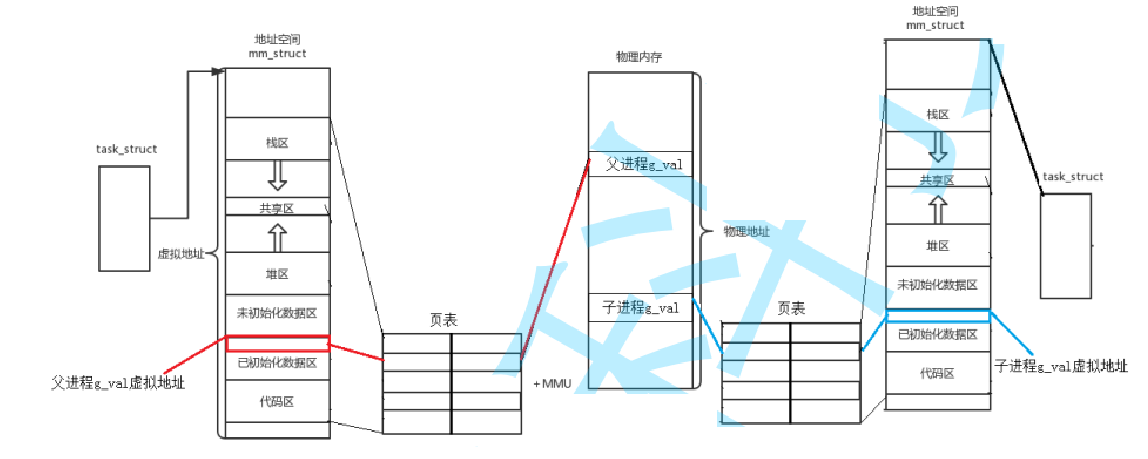
子进程也是一个进程,他也需要自己的进程地址空间和页表
子进程一开始什么都没有,但是他会直接将父进程的数据全部拷贝一遍(不包括代码,像代码这些只需要在物理内存保存一份,所有人都能看到就行了),包括变量G_VAL的值,在页表中与物理内存的映射,原原本本的全部拷贝一份(但是代码是没有拷贝的,因为这个是只读的,直接看父进程的就好了)
这个时候,我们的子进程就做到了,能和父进程“看到”一样的数据
G_VAL会在进程地址空间中有一个虚拟地址,经过页表映射,在物理内存上就能找到真实存放的位置
但是如果我们现在对G_VAL进行修改,那么写时拷贝就发生了,由于前面虽然是两个不同的进程,但是在物理内存上看到的本质上是同一个
这时候我们子进程想要修改这个变量,那么内存就只能再开辟一段空间,来存放一个新的变量,虽然这个变量也叫做G_VAL
但是,我们的虚拟地址并不会改变,因为没有改变的必要,页表倒是需要变一变,只不过虚拟地址那一部分不变,变的只是映射到物理内存的那个地址
所以这也就是为什么,我们在代码中看到的同一个地址,同一个变量,不同的值
本质上,那些都是虚拟地址,但是在内存中,这是两个完全不一样的值(如果没有修改值,没有发生写实拷贝的话那就是同一个值)
接下来我们可能会有两个疑问:
1. 子进程到了修改的时候才发生写实拷贝,效率怎么听起来会慢一点啊?
其实是不会的,因为如果这个变量没有改变的话,那我们就连拷贝都不需要,就算是发生了修改,那如果一开始就开辟空间,和要改了才开辟,其实就只是今天写作业和明天写作业的区别,到头来都是要写的
但是如果学校老师不检查的话,那甚至这个作业都可以不写(只是举例,思想上不倡导哈)
2. 为什么不在最开始的时候,将所有的数据都拷贝给子进程,不是说进程是相互独立的吗?
这个其实也没得说,像代码,环境变量等等,这些东西,大家看到的都是同一个,何必要全部拷贝呢?能省空间就省空间嘛,内存的空间也不是这么浪费的
区域划分的本质
如下图(其实还是上面的图的一部分):
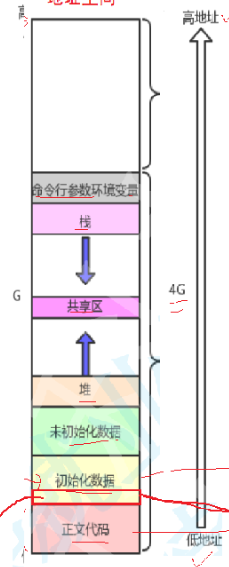
我们会看到,进程地址空间是被划分成了一个个小位置的,比如栈区、堆区、静态区这些
先来说说为什么要这么分,他的意义是什么
试想一下,如果我们没有进程地址空间的话,那么我们的变量将会直接在内存上开辟,先不谈安全问题(比如越界访问),如果直接在内存上开辟,我们的变量在内存上的地址是否就要被记录下来,这样我们下一次才能找到这个变量并且进行使用
但是如果今天我不止一个变量,我有一百个,一千个变量,那么每一个变量我都只能一个一个记下来,这样,其实不是很好
但是现在我们有了进程地址空间中的区域划分,比如你这个变量是一个常量,是一个变量,是一个什么什么变量,你就放在对应的空间里面
这样我们下次要找的话,你这个变量就一定在某一段区域内,相对来说就好管得多
(当然这只是进程地址空间的其中一个好处)
我们来看看内核是怎么写的:

本质上,区域的划分就是存在PCB(task_struct)中的一个struct变量(mm_struct)中的一个个字段,仅此而已
如何理解进程地址空间
假如你是一个富豪,你有10亿美金的财产,现在你有五个私生子
你对每一个私生子都说,你有10个亿,等我不在了这钱全是你的
那么这时,每一个私生子都会想着,富豪只有他 / 她一个孩子,这时候你有用钱的需要,你就和富豪说,如果条件可行,那就运行,如果不对劲,那就驳回
对于内存也是,每一个进程都会认为自己面对的内存是完整的物理内存(进程地址空间)
这时候如果想要开辟物理空间了,那就提交申请给内存,这时候内存就会帮你开辟空间并将结果返回给你
意义是什么
第一、我们能保证进程之间是互相独立的
第二、能有效保护内存,如果说进程中有越界行为,他是碰不到内存的,在虚拟地址空间这里就被驳回了
第三、简化内存管理,进程看到的是连续的虚拟地址空间,实际物理内存可以零散分布(通过页表映射)
第四、高效的进程切换,比如10个进程运行同一程序,代码段只需一份物理内存,通过页表映射到各进程的相同虚拟地址
等等,还有很多原因这里就不一一列举了
越界访问的本质
现在再来看这个问题,就明朗多了
首先我们的变量地址都是被放在页表中一一映射的
现在我们突然来了一个不在这里面的地址,也就是越界访问
那么在页表里面查不到对应的信息,那么就会发现这个是错的,那么系统自然就会将这个请求直接驳回,然后执行某些操作,比如将这个进程直接kill掉,太危险了
进一步理解写时拷贝
首先我们还需要引入一个概念,那是和页表有关的,其实我们前面也学过,就是权限
是的,页表里面也是有权限的
所以我们现在看回这么一串代码:char* a = "hello world";
在我们之前的认知里,他是不能被修改的,因为他是一个常量
那么现在再来看,为什么不能修改?这是因为页表里面的权限,就直接设置了这个变量是只读的,如果你要写,那就直接驳回请求,所以我们才没办法修改
那么现在再来看看写时拷贝
首先,我们一开始所有的变量都是只读的
但是今天我们有一个变量G_VAL,现在我们对他进行修改,这时候就发生错误了
但是,操作系统面对错误之前,还会干一件事情,那就是先检查:
1. 是不是数据之前没放进物理内存里面(缺页中断)
2. 是否是需要写时拷贝
3. 异常处理
说实话这个是非常厉害的,现在我们的系统识别到了,你是想写时拷贝,所以就给你开空间,变页表等等,这也就是我们所谓写时拷贝的本质了
重谈 fork 返回值
现在我们再来看fork的返回值,相信你会变得非常熟悉:
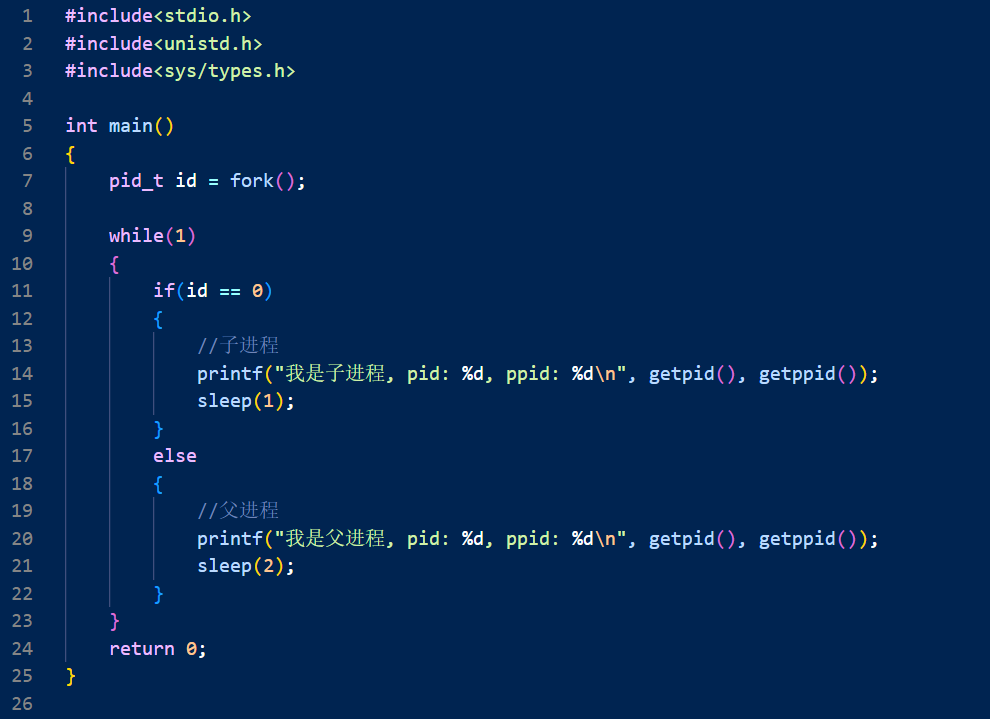
来看这张图,里面的 id 不就是一个变量吗,在fork的逻辑中,当子进程被创造出来的时候,数据拷贝自原有的父进程
接着就是父进程id的值给一份给子进程
但是这个时候fork函数要return了,本质上,这就是写时拷贝
所以物理内存中又开辟了一段空间,给一个名字同样叫做id的变量放进了不同于另一个id的值
最后进程的页表中,关于物理地址映射的那一部分被修改
至此,我们的fork返回值,为什么可以同时给给两个值给 “同一个” 变量的话题,就讲完了
结语
这篇文章到这里就结束啦!!~( ̄▽ ̄)~*
如果觉得对你有帮助的,可以多多关注一下喔