目录
一、分组延时、丢失
1. 节点处理延时:
2. 排队延时:
3. 传输延时:
4. 传播延时:
5. 节点延时
6. 排队延时
7. 分组丢失
二、吞吐量
三、总结
(一)分组延时
1. 处理延时(Processing Delay)
2. 排队延时(Queuing Delay)
3. 传输延时(Transmission Delay)
4. 传播延时(Propagation Delay)
📌 总延时:
(二)分组丢失
1. 主要原因
2. 影响与应对
3. 丢包率(Loss Rate)
(三)吞吐量(Throughput)
1. 两种定义
2. 瓶颈带宽(Bottleneck Bandwidth)
3. 实际吞吐量影响因素
4. 吞吐量计算示例
(四)关键知识关联
一、分组延时、丢失
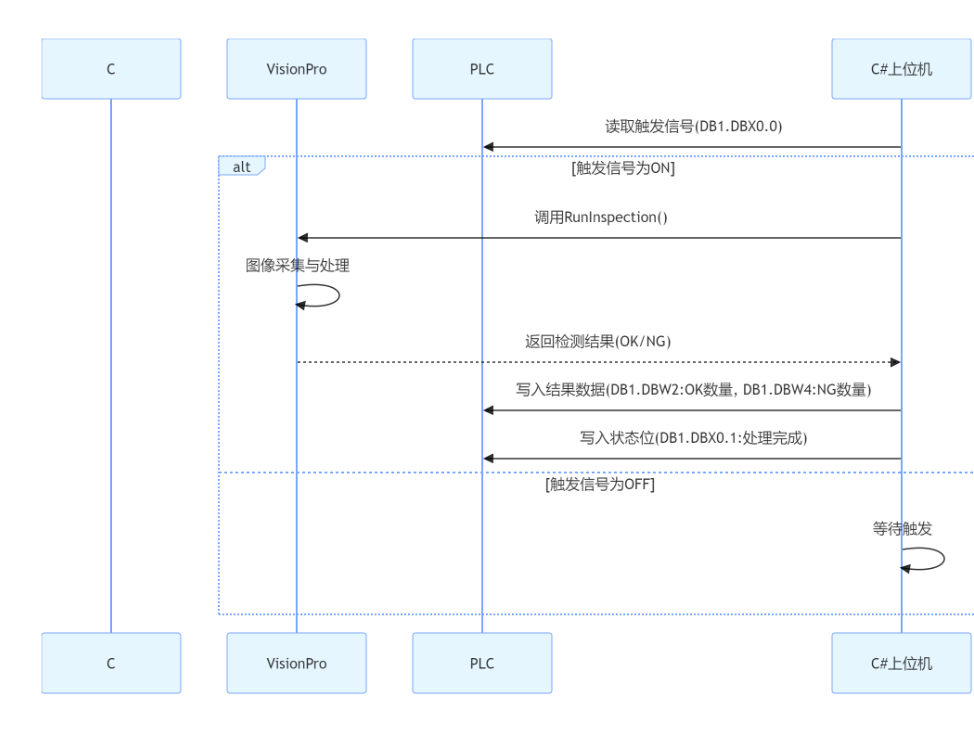
分组丢失和延时是怎样发生的?
在路由器缓冲区的分组队列
☐ 分组到达链路的速率超过了链路输出的能力
☐ 分组等待排到队头、被传输
四种分组延时
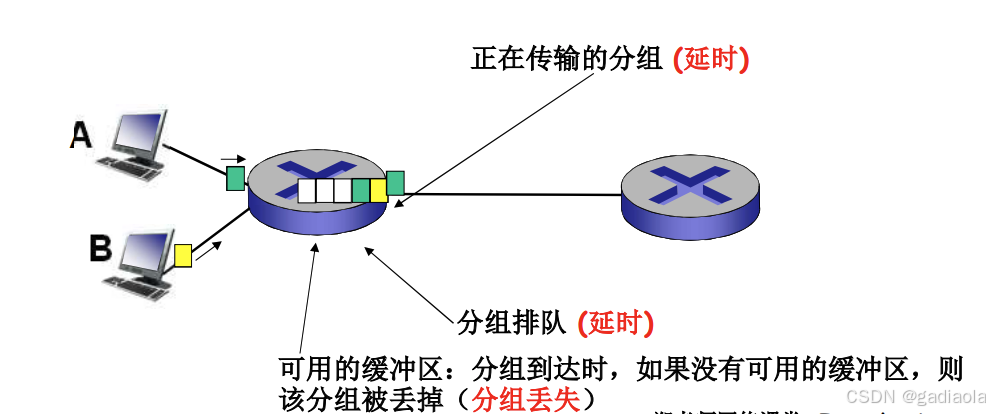
1. 节点处理延时:
- 检查 bit 级差错
- 检查分组首部和决定将分组导向何处
2. 排队延时:
- 在输出链路上等待传输的时间
- 依赖于路由器的拥塞程度
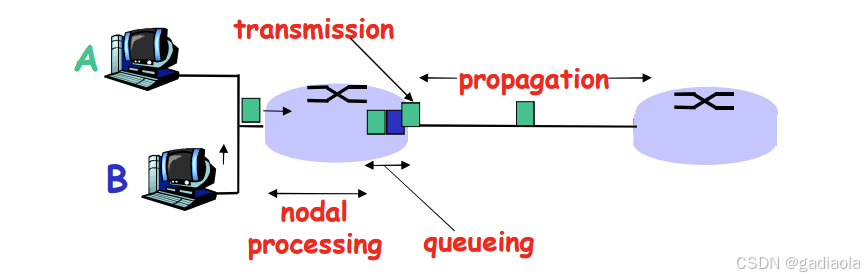
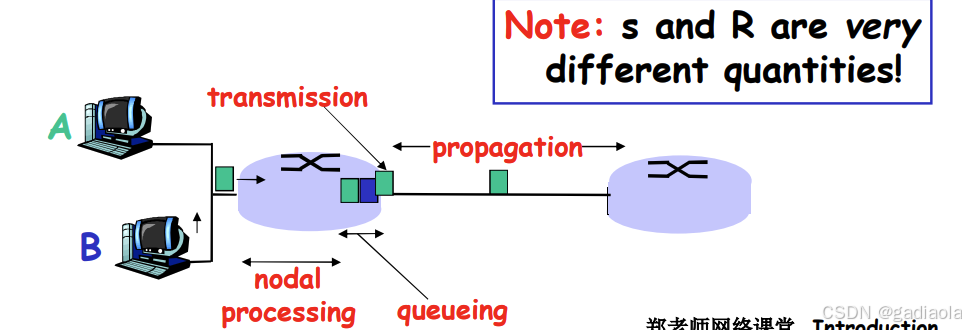
3. 传输延时:
- R = 链路带宽 (bps)
- L = 分组长度 (bits)
- 将分组发送到链路上的时间 = L/R
- 存储转发延时
4. 传播延时:
- d = 物理链路的长度
- s = 在媒体上的传播速度 (~2×10⁸ m/sec)
- 传播延时 = d/s
车队类比
- 汽车以 100 km/hr 的速度传播
- 收费站服务每辆车需 12s (传输时间)
- 汽车~bit; 车队~分组
- Q: 在车队在第二个收费站排列好之前需要多长时间?
- 即:从车队的第一辆车到达第一个收费站开始计时,到这个车队的最后一辆车离开第二个收费站,共需要多少时间
- 将车队从收费站输送到公路上的时间 = 12*10 = 120s
- 最后一辆车从第一个收费站到第二个收费站的传播时间:100km/(100km/hr)= 1 hr
- A: 62 minutes
- 汽车以 1000 km/hr 的速度传播汽车
- 收费站服务每辆车需 1 分钟
- Q: 在所有的汽车被第一个收费站服务之前,汽车会到达第二个收费站吗?
- Yes!7 分钟后,第一辆汽车到达了第二个收费站,而第一个收费站仍有 3 辆汽车
- 在整个分组被第一个路由器传输之前,第一个比特已经到达了第二个路由器!

5. 节点延时
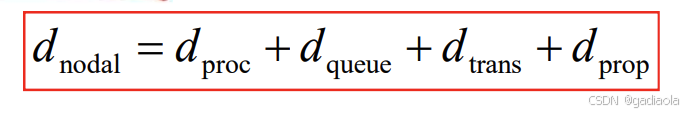
- d-proc = 处理延时
- 通常是微秒数量级或更少
- d-queue = 排队延时
- 取决于拥塞程度
- d-trans = 传输延时
- = L/R,对低速率的链路而言很大(如拨号),通常为微秒级到毫秒级
- d-prop = 传播延时
- 几微秒到几百毫秒
6. 排队延时
- R = 链路带宽 (bps)
- L = 分组长度 (bits)
- a = 分组到达队列的平均速率
流量强度 = La/R
- La/R ~ 0: 平均排队延时很小
- La/R -> 1: 延时变得很大
- La/R > 1: 比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋向无穷大!
设计系统时流量强度不能大于 1!
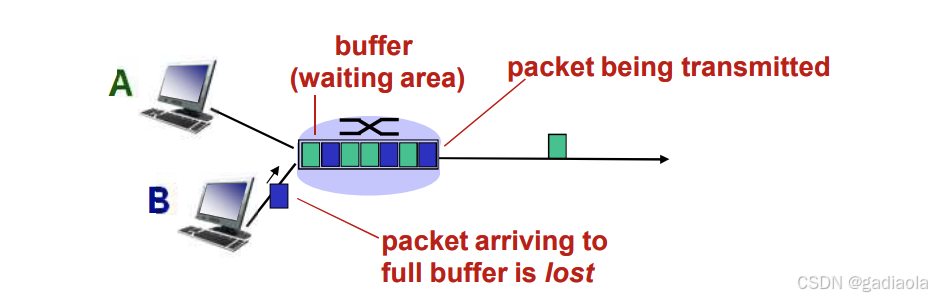
7. 分组丢失
- 链路的队列缓冲区容量有限
- 当分组到达一个满的队列时,该分组将会丢失
- 丢失的分组可能会被前一个节点或源端系统重传,或根本不重传
二、吞吐量
- 吞吐量:在源端和目标端之间传输的速率(数据量 / 单位时间)
- 瞬间吞吐量:在一个时间点的速率
- 平均吞吐量:在一个长时间内平均值
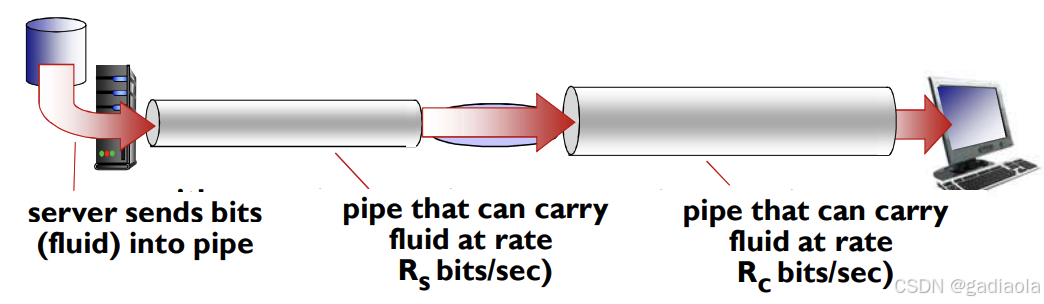
Rs < Rc 端到端平均吞吐是多少?---------------------Rs

Rs > Rc 端到端平均吞吐是多少?---------------------Rc

瓶颈链路:
端到端路径上,限制端到端吞吐的链路。
其他节点都不传输,吞吐量min{Rs,Rc}。
端到端平均吞吐=min{R1,R2 ,…,Rn }

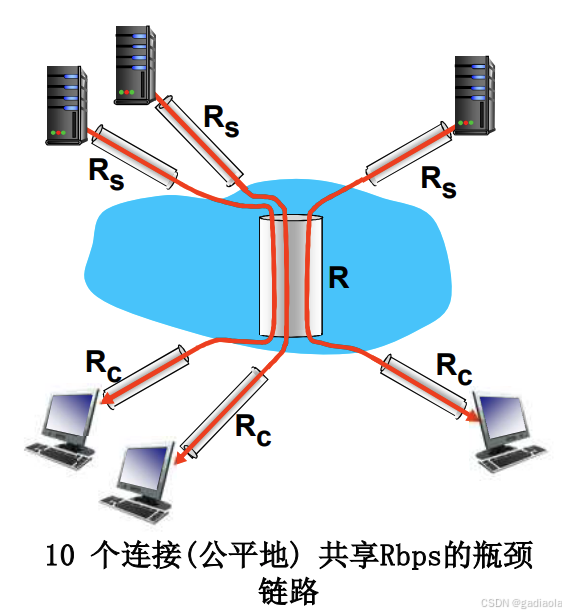
吞吐量:互联网场景
- 链路上的每一段实际可用带宽 Ri ’ = ?
- 端到端吞吐量:min{ Ri ’ }
- 每个连接上的端到端吞吐:min(Rc ,Rs ,R/10)
- 实际上:Rc 或者 Rs 经常是瓶颈
三、总结
(一)分组延时
指数据分组从源主机发送到目的主机所经历的总时间。由四部分构成:
1. 处理延时(Processing Delay)
- 定义:路由器/交换机检查分组头部、决定转发路径、检查比特错误等处理时间。
- 影响因素:硬件性能、路由算法复杂度、安全检查(如防火墙)。
- 典型值:微秒级(μs)。
2. 排队延时(Queuing Delay)
- 定义:分组在输出队列中等待链路空闲的时间。
- 关键公式:
- 平均排队延时 ≈
(流量强度) / (1 - 流量强度)
流量强度 = 分组到达速率 / 链路输出速率- 当流量强度 → 1 时,延时趋近无穷大。
- 影响因素:流量突发性、队列调度策略(FIFO、优先级队列)。
3. 传输延时(Transmission Delay)
- 定义:将分组所有比特推送到链路上的时间。
- 公式:
传输延时 = 分组长度 (L) / 链路带宽 (R)
- 例:1KB 分组,1Gbps 链路 → 延时 = 8μs。
4. 传播延时(Propagation Delay)
- 定义:比特在物理介质中传播的时间。
- 公式:
传播延时 = 距离 (d) / 传播速度 (s)
- 传播速度
s:光纤中 ≈ 2×10⁸ m/s(真空中光速的2/3)。📌 总延时:
总延时 = 处理延时 + 排队延时 + 传输延时 + 传播延时
(二)分组丢失
分组在传输过程中未能到达目的地的现象。
1. 主要原因
- 路由器队列溢出:当流量强度 > 1 时,队列满导致后续分组被丢弃。
- 链路错误:物理介质干扰(如无线网络)、比特错误(CRC校验失败)。
- 路由问题:路由表错误导致分组进入“黑洞”。
2. 影响与应对
- TCP 的应对机制:
- 超时重传(RTO)
- 快速重传(收到3个重复ACK)
- 拥塞控制(如 Tahoe、Reno 算法)
- UDP 无恢复机制:需应用层处理(如实时音视频的冗余编码)。
3. 丢包率(Loss Rate)
- 公式:
丢包率 = 丢失分组数 / 发送分组总数- 典型要求:语音通话 <1%,视频流 <5%。
(三)吞吐量(Throughput)
单位时间内通过网络的有效数据量。
1. 两种定义
- 瞬时吞吐量:某一时刻的速率(bps)。
- 平均吞吐量:一段时间内的平均速率(bps)。
2. 瓶颈带宽(Bottleneck Bandwidth)
- 定义:端到端路径中带宽最小的链路速率。
- 公式(N条链路串联):
端到端吞吐量 = min{R1, R2, ..., RN}- 示例:
- 服务器 → 路由器1:100Mbps
- 路由器1 → 路由器2:10Mbps
- 路由器2 → 客户端:1Gbps
- 实际吞吐量 = 10Mbps
3. 实际吞吐量影响因素
- 网络拥塞程度
- 协议开销(TCP头部、ACK确认)
- 接收端窗口大小(TCP流量控制)
4. 吞吐量计算示例
- 文件大小
F,传输时间T→ 吞吐量 =F / T- 若多用户共享链路:公平共享时每个用户获得
R/N(R为总带宽,N为用户数)。
(四)关键知识关联
概念 核心影响因素 典型优化方法 延时 传播距离、链路带宽、队列长度 CDN、协议优化(QUIC)、优先级调度 丢失 队列溢出、信道错误 增大缓冲区、前向纠错(FEC) 吞吐量 瓶颈带宽、并发连接数 多路径传输(MPTCP)、负载均衡 延时 vs 吞吐量权衡:
- 低延时:需小队列(但易丢包)
- 高吞吐量:需大窗口(但增加排队延时)
- TCP拥塞控制(如BBR算法)旨在平衡二者。
完结撒花🎉