select … for update
参考:https://www.cnblogs.com/goloving/p/13590955.html
select for update是一种常用的加锁机制,它可以在查询数据的同时对所选的数据行进行锁定,避免其他事务对这些数据行进行修改。
比如涉及到金钱、库存等。一般这些操作都是很长一串并且是开启事务的。如果库存刚开始读的时候是1,而立马另一个进程进行了update将库存更新为0了,而事务还没有结束,会将错的数据一直执行下去,就会有问题。所以需要for upate 进行数据加锁防止高并发时候数据出错。
排他锁的申请前提是需要:没有其他线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞。
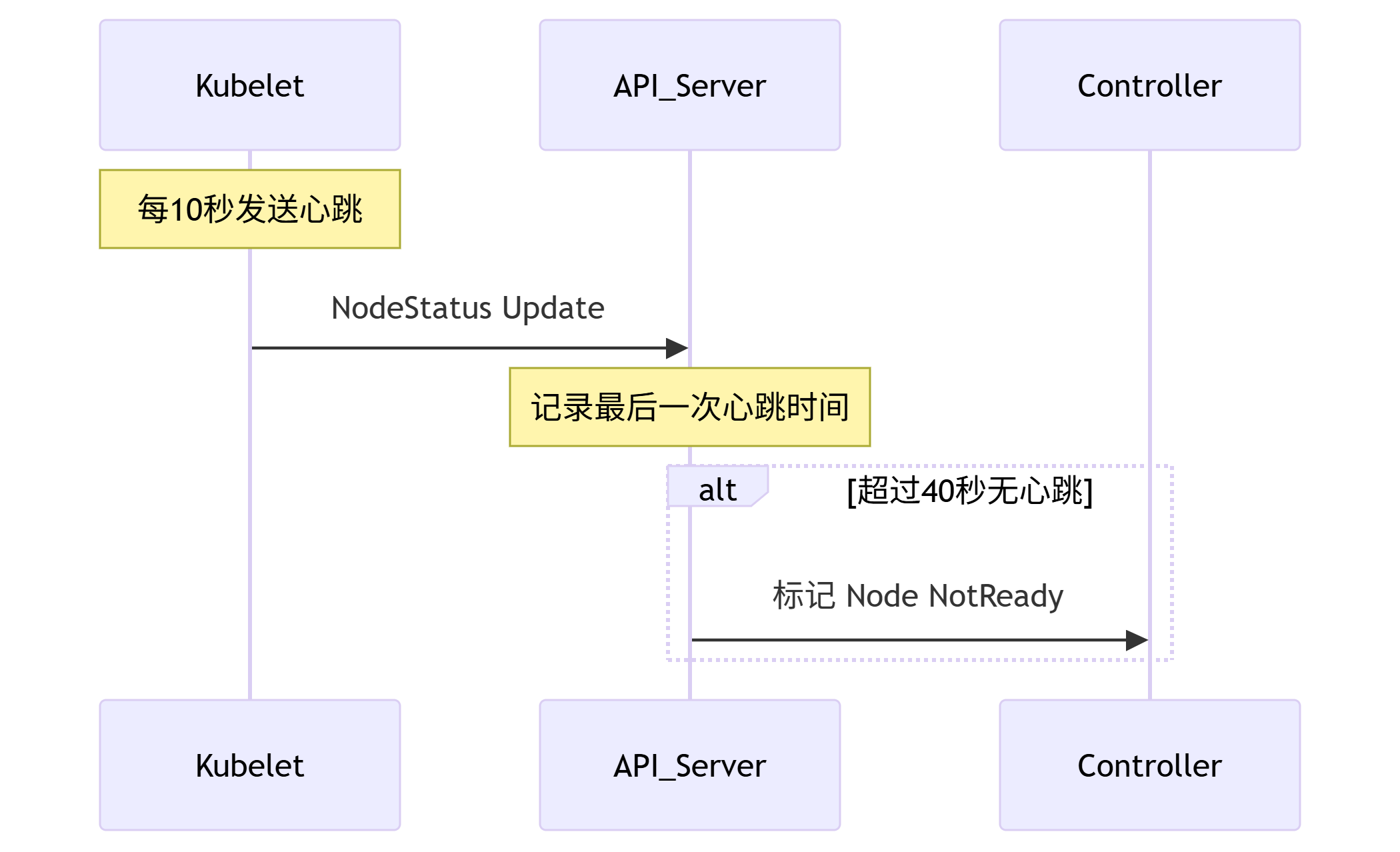
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。
排他锁包含行锁、表锁。
1、InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。无主键或主键不明确或无索引,表锁;明确指定主键或索引,且有数据,行锁;无数据,则无锁。
2、由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。
3、当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
4、即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
5、检索值的数据类型与索引字段不同,虽然MySQL能够进行数据类型转换,但却不会使用索引,从而导致InnoDB使用表锁。通过用explain检查两条SQL的执行计划,我们可以清楚地看到了这一点。
例子
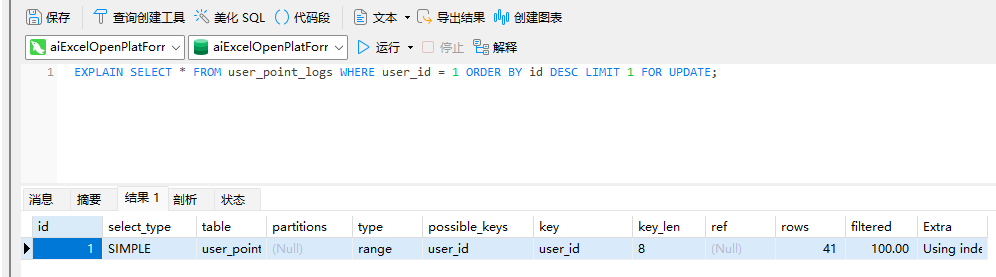
锁user_id 索引
BEGIN;
SELECT * FROM user_point_logs WHERE user_id = 1 ORDER BY id DESC FOR UPDATE;
INSERT INTO user_point_logs (user_id, change_type, scene, change_points, balance) VALUES (1, 1, "", 0, 0);
COMMIT;
并发时
BEGIN
> OK
> 查询时间: 0.02s
SELECT * FROM user_point_logs WHERE user_id = 1 ORDER BY id DESC FOR UPDATE
> Affected rows: 0
> 查询时间: 0.024s
SELECT SLEEP(15)
> OK
> 查询时间: 15.023s
INSERT INTO user_point_logs (user_id, change_type, scene, change_points, balance) VALUES (1, 1, "", 0, 0)
> 1213 - Deadlock found when trying to get lock; try restarting transaction
> 查询时间: 0.022s
出现相互死锁
BEGIN
> OK
> 查询时间: 0.024s
SELECT * FROM user_point_logs WHERE user_id = 1 ORDER BY id DESC FOR UPDATE
> Affected rows: 0
> 查询时间: 13.025s
INSERT INTO user_point_logs (user_id, change_type, scene, change_points, balance) VALUES (1, 1, "", 0, 0)
> Affected rows: 1
> 查询时间: 0.026s
COMMIT
> OK
> 查询时间: 0.031s
BEGIN;
SELECT * FROM user_point_logs WHERE user_id = 1 ORDER BY id DESC LIMIT 1 FOR UPDATE;
SELECT SLEEP(15);
INSERT INTO user_point_logs (user_id, change_type, scene, change_points, balance) VALUES (1, 1, "", 0, 0);
COMMIT;
BEGIN
> OK
> 查询时间: 0.021s
SELECT * FROM user_point_logs WHERE user_id = 1 ORDER BY id DESC LIMIT 1 FOR UPDATE
> Affected rows: 0
> 查询时间: 0.023s
SELECT SLEEP(15)
> OK
> 查询时间: 15.021s
INSERT INTO user_point_logs (user_id, change_type, scene, change_points, balance) VALUES (1, 1, "", 0, 0)
> Affected rows: 1
> 查询时间: 0.022s
COMMIT
> OK
> 查询时间: 0.095s
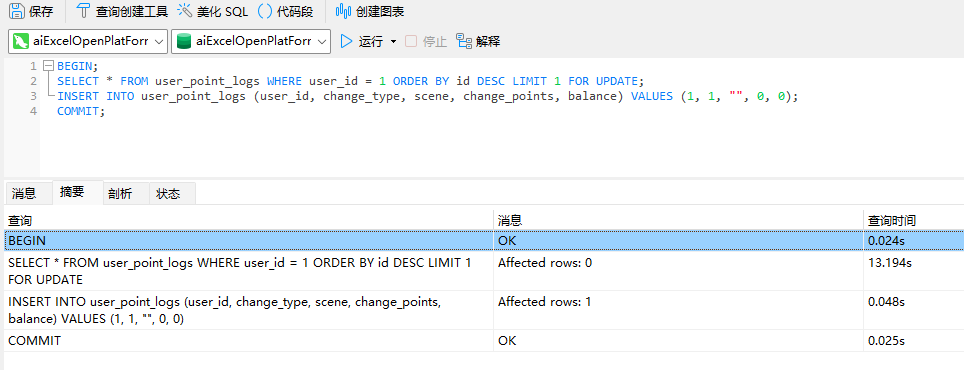
后一个事务没有查询结果,可能由于事务的可重复读的隔离级别? 不太懂,欢迎佬评论区指点~
为什么线程消耗比协程大,具体体现在哪些方面
目前主流语言基本上都选择了多线程作为并发设施,与线程相关的概念就是抢占式多任务(Preemptive multitasking),而与协程相关的是协作式多任务。
不管是进程还是线程,每次阻塞、切换都需要陷入系统调用(system call),先让CPU跑操作系统的调度程序,然后再由调度程序决定该跑哪一个进程(线程)。
- 内存占用 1-8MB 2KB
- 上下文切换
- 同步与锁:互斥 channel
- 调度机制 :抢占式 GMP
生产中哪些服务用的 进程、线程,为什么要这么做,有什么好处

网络爬虫、高性能计算等等
可重复读能解决幻读吗,为什么



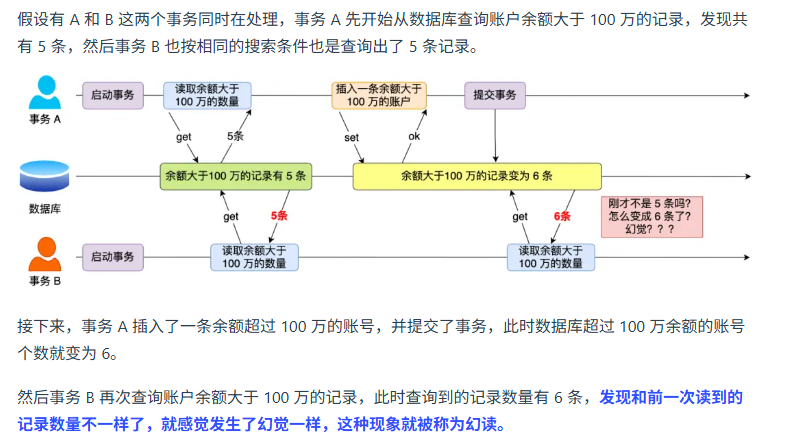
出现幻读
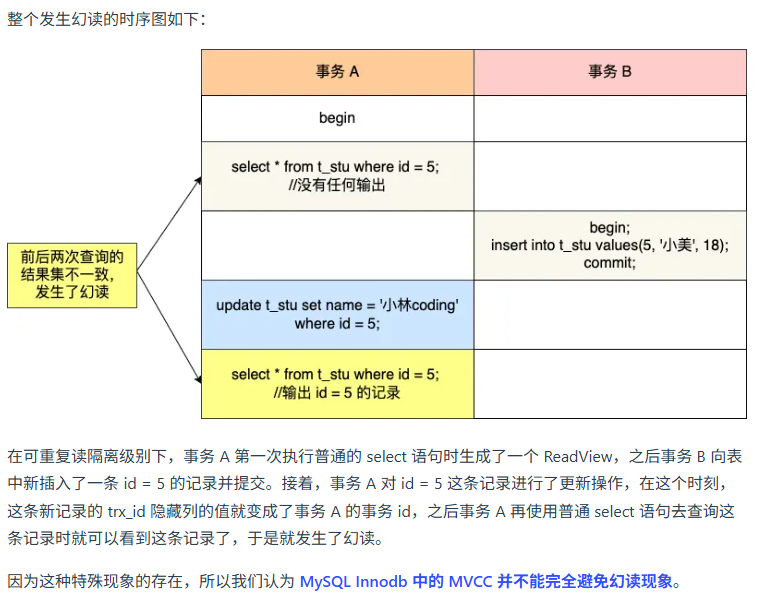

http1.0 - http3.0 改进,优缺点
- http1.0:短连接
- http1.1:长连接改善性能开销,支持管道;
- http2.0:头部压缩消除重复部分,二进制增加传输效率,并发传输多个stream复用一条tcp连接但接收时TCP会阻塞,服务器推送
- http3.0:无队头阻塞QUIC多个流,QUIC包含TLS握手1RTT建立连接,连接迁移防止切换网络时断开连接(四元组->连接ID)
程序从加载到运行的过程
1. 用户触发执行
- 方式:通过命令行输入、图形界面双击或脚本调用。
- 系统检查:操作系统验证文件存在性、用户权限(执行权限)及文件完整性。
2. 创建新进程
- 进程控制块(PCB):操作系统分配PCB,存储进程状态、PID、优先级等信息。
- 虚拟地址空间:为进程分配独立的虚拟内存空间,确保隔离性。
3. 加载可执行文件
- 文件格式解析:解析ELF(Linux)或PE(Windows)等格式,提取代码段(.text)、数据段(.data)、BSS段(.bss)等信息。
- 内存映射:
- 代码段:只读属性,映射到固定或随机地址(ASLR启用时)。
- 数据段:可读写,包含已初始化全局变量。
- BSS段:分配内存并初始化为零,无需磁盘内容。
- 按需分页:物理内存延迟分配,触发缺页中断时加载所需页。
4. 初始化运行时环境
- 栈分配:设置栈指针(SP),分配栈空间(局部变量、函数调用)。
- 堆初始化:通过brk/sbrk或mmap分配堆空间,供动态内存分配(如malloc)。
- 全局变量:.data段数据载入内存,.bss段清零。
- 环境变量与参数:将命令行参数(argv)和环境变量压栈或存入特定寄存器。
5. 执行初始化代码
- 入口点:控制权转至_start(由C运行时库定义),而非直接跳转到main。
- C运行时(CRT)初始化:
- 调用全局构造函数(C++静态对象)。
- 初始化标准I/O流(stdin/stdout/stderr)。
- 设置线程局部存储(TLS)。
- 参数传递:准备argc、argv并调用main函数。
6. 程序执行
- 主函数运行:执行main函数逻辑,处理用户代码。
- 系统调用:通过中断或syscall指令请求操作系统服务(如文件操作、网络通信)。
- 异常处理:信号处理、缺页中断等由操作系统接管。
流程图概览
用户触发 → 权限检查 → 创建进程 → 加载ELF/PE → 动态链接 → 初始化运行时 → 执行main → 终止清理
zookeeper、mysql、redis 、etcd 怎么实现分布式锁,各有什么优缺点,生产中一般用那个
1. Zookeeper 分布式锁
实现原理
- 临时顺序节点 + Watcher 机制:
客户端在指定父节点(如/lock)下创建临时顺序节点(如/lock/seq-000000001),若自身节点序号最小则获取锁;否则监听前一个节点的删除事件,触发重新判断锁归属。 - 自动释放:会话断开或客户端崩溃时,临时节点自动删除,避免死锁。
优点
- 强一致性:基于 ZAB 协议,保证数据强一致性。
- 公平锁:顺序节点天然支持公平性,避免饥饿问题。
- 可靠性高:自动释放锁机制完善,无死锁风险。
缺点
- 性能较低:频繁的节点创建、监听和事件回调导致延迟较高。
- 复杂度高:需维护 Zookeeper 集群,运维成本较高。
2. MySQL 分布式锁
实现原理
- 乐观锁/悲观锁:
- 乐观锁:通过版本号字段实现,更新时判断版本号是否匹配。
- 悲观锁:使用
SELECT ... FOR UPDATE或行级锁,限制并发访问。
优点
- 实现简单:无需额外中间件,适合已有 MySQL 的场景。
缺点
- 性能差:高并发下频繁操作数据库易成瓶颈。
- 可靠性低:死锁检测困难,需手动处理锁超时。
- 扩展性差:主从架构下同步延迟可能导致锁失效。
3. Redis 分布式锁
实现原理
- SETNX + EXPIRE:通过
SET key value NX PX 30000原子命令加锁,设置过期时间避免死锁。 - Redisson 框架:封装锁续期、可重入等逻辑,支持 RedLock 算法(多节点容错)。
优点
- 高性能:基于内存操作,支持高并发场景。
- 易用性高:结合 Redisson 实现简单,社区支持完善。
缺点
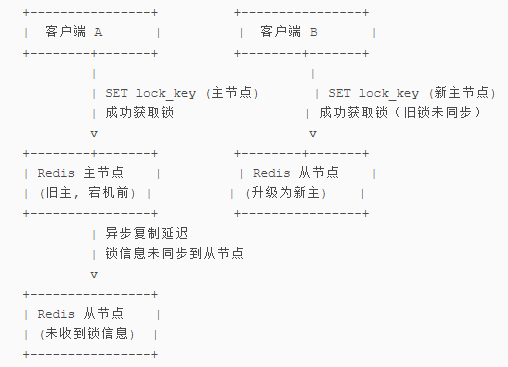
- 弱一致性:主从切换时可能导致锁失效(AP 特性)。
- 锁续期复杂:需额外处理锁超时与业务执行时间的平衡。
- RedLock 争议:部分场景下仍存在安全性问题(如时钟漂移)。
4. Etcd 分布式锁
实现原理
- 租约(Lease) + 临时键:客户端创建带租约的临时键,通过 Revision 机制判断是否为最小键,监听前一个键的删除事件。
- 心跳续约:定期续约防止租约过期,崩溃时自动释放锁。
优点
- 强一致性:基于 Raft 协议,数据强一致。
- 可靠性高:自动释放锁,避免死锁。
缺点
- 性能中等:低于 Redis,但高于 Zookeeper。
- 复杂度高:需管理租约和监听逻辑,实现成本较高。
生产环境选型建议
-
Redis:
- 适用场景:高并发、对一致性要求不严格的场景(如秒杀、缓存更新)。
- 推荐工具:Redisson 框架,支持锁续期和 RedLock 算法。
-
Zookeeper/Etcd:
- 适用场景:强一致性要求的场景(如金融交易、配置管理)。
- 推荐工具:Zookeeper 用 Curator 框架;Etcd 用 Jetcd 或官方 SDK。
-
MySQL:
- 适用场景:低并发、无其他中间件的简单系统。
总结
- 性能优先选 Redis:适用于大多数高并发场景,需结合业务兜底(如幂等性处理)。
- 强一致选 Zookeeper/Etcd:适用于对可靠性要求极高的场景,如分布式协调服务。
- MySQL 慎用:仅作为临时方案或低并发场景的补充。
实现LRU算法
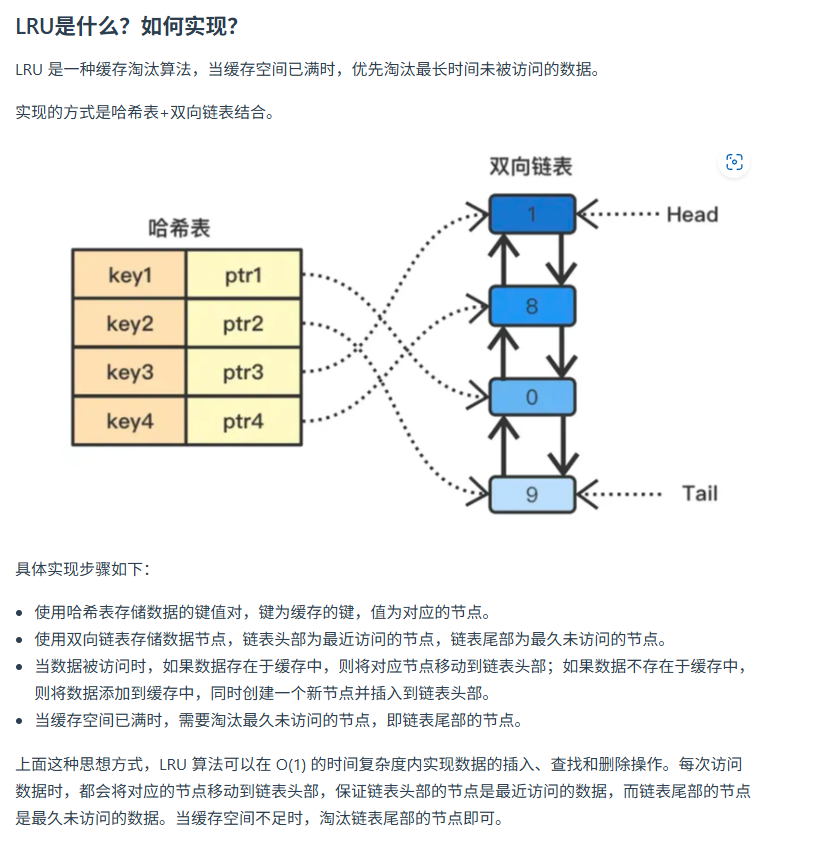
type LRUCache struct {
Cap int
List *list.List
Mp map[int]*list.Element
}
type node struct{
key, value int
}
func Constructor(capacity int) LRUCache {
return LRUCache{capacity, list.New(), map[int]*list.Element{}}
}
func (this *LRUCache) Get(key int) int {
item := this.Mp[key]
if item==nil{
return -1
}
this.List.MoveToFront(item)
return item.Value.(node).value
}
func (this *LRUCache) Put(key int, value int) {
item := this.Mp[key]
if item!=nil{
item.Value = node{key, value}
this.List.MoveToFront(item)
}else{
this.Mp[key] = this.List.PushFront(node{key, value})
this.List.MoveToFront(this.Mp[key])
if len(this.Mp)>this.Cap{
delete(this.Mp, this.List.Remove(this.List.Back()).(node).key)
}
}
}
/**
* Your LRUCache object will be instantiated and called as such:
* obj := Constructor(capacity);
* param_1 := obj.Get(key);
* obj.Put(key,value);
*/