(1)层次化索引
1.创建带层次化索引的df
第一种,直接创建
import pandas as pd
import numpy as np
data = pd.Series(np.random.randn(9),
index = [['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
print(data)
# a 1 -0.641606
# 2 0.417681
# 3 -1.403780
# b 1 0.048346
# 3 1.171691
# c 1 0.911963
# 2 0.907681
# d 2 -0.919932
# 3 0.852891
# dtype: float64
print(data.index)
# MultiIndex([('a', 1),
# ('a', 2),
# ('a', 3),
# ('b', 1),
# ('b', 3),
# ('c', 1),
# ('c', 2),
# ('d', 2),
# ('d', 3)],
# )第二种,先用pd.MultiIndex.from_arrays()创建MultiIndex对象,再赋值给dataframe的索引
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]], names=['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names=['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=index,
columns=columns)
'''
行两层索引:第一层名为key1,第2层名为key2
列两层索引:第一层名为state,第2层名为color
'''
print(frame)
'''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
'''2.访问带层次化索引的df
dataframe的层次化索引
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]], names = ['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names = ['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index = index,
columns = columns)
print(frame)
# state Ohio Colorado
# color Green Red Green
# key1 key2
# a 1 0 1 2
# 2 3 4 5
# b 1 6 7 8
# 2 9 10 11
print("访问行")
print(frame.loc["a"])
print(frame.loc["a": "b"])
print(frame.loc[["a", "b"]])
print("访问列")
print(frame["Ohio"])
print(frame[["Ohio","Colorado"]])
print("访问多行多列")
# 就是访问行和访问列的结合
print(frame.loc["a"]["Ohio"])
print(frame[["Ohio","Colorado"]].loc["a":"b"])3.交换层次顺序
交换层次化索引的顺序:df.swaplevel()
最外层level = 0,紧接着level = 1
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
names=['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names=['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=index,
columns=columns)
print(frame)
'''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
'''
print("\n交换不同level的行")
print("\n", frame.swaplevel('key1', 'key2'))
print("\n", frame.swaplevel('key1', 'key2', axis=0))
print("\n交换不同level的列")
print("\n", frame.swaplevel('state', 'color', axis = 1))
print("\n用默认索引交换")
print("\n", frame.swaplevel(i=0, j=1, axis=1))4.按某一层索引进行排序
主要用sort_index方法,比如行索引有两层,可以按行的第1层索引来排序,也可以根据行的第2层索引来排序,或者先根据第1层,第1层相同的再根据第2层。
import pandas as pd
import numpy as np
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
names=['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names=['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=index,
columns=columns)
print(frame)
'''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
b 1 6 7 8
2 9 10 11
'''
print("\n对行,按level 1排序,这里就是按key2排序")
print(frame.sort_index(level=1))
'''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
b 1 6 7 8
a 2 3 4 5
b 2 9 10 11
'''
print("\n对列,按level 1排序,默认升序")
print(frame.sort_index(level=1, axis=1))
print("\n对行,按level 1排序,降序")
print(frame.sort_index(level=1, ascending=False))
print("\n对行,先对level 1 降序,再对level 0 降序")
print(frame.sort_index(level=[1, 0], ascending=False))
print("\n对行,先对level 1 降序,再对level 0 升序")
print(frame.sort_index(level=[1, 0], ascending=[False, True]))还可以配合key参数实现自定义排序函数
import pandas as pd
import numpy as np
print("\n用参数key根据指定函数排序")
index = pd.MultiIndex.from_arrays([['a', 'a', 'B', 'B'], [1, 2, 1, 2]],
names=['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names=['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=index,
columns=columns)
print(frame)
''''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
B 1 6 7 8
2 9 10 11
'''
print("\n正常按升序排序")
print(frame.sort_index(level=0))
print("\n现在用key参数,实现无论大小写按自身的小写排序")
print(frame.sort_index(level=0, key=lambda x: x.str.lower()))
'''
state Ohio Colorado
color Green Red Green
key1 key2
a 1 0 1 2
2 3 4 5
B 1 6 7 8
2 9 10 11
'''
print("\n注意在py3.7版本下,没有key参数,运行会报错,3.6版本可以实现")
# help(frame.sort_index)5.按某一层索引进行统计
index = pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
names = ['key1', 'key2'])
columns = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],
names = ['state', 'color'])
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index = index,
columns = columns)
print(frame)
# state Ohio Colorado
# color Green Red Green
# key1 key2
# a 1 0 1 2
# 2 3 4 5
# b 1 6 7 8
# 2 9 10 11
print(frame.sum(level = 'key2'))
print(frame.sum(level = 'key2', axis = 0))
print(frame.sum(level = 'color', axis = 1))6.行列索引转化
pdobj.unstack():将某一层次行变为列的某一层次(行转列)
pdobj.stack():将某一层次列变为行的某一层次(列转行)
重要参数:
level:转化指定的层
dropna:转化时是否删除空值
- 默认将最内层索引进行转化
- 默认转化到另一方的最内层
import pandas as pd
import numpy as np
data = pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
print(data)
'''
a 1 0.809003
2 1.125689
3 -1.234327
b 1 0.685297
3 0.431967
c 1 -1.396598
2 -0.779780
d 2 1.090197
3 1.182934
dtype: float64
'''
print("\nunstack 时,不存在的值将会为 NaN")
print("层次化的Series进行unstack 时,会变为dataframe")
print(data.unstack())
'''
1 2 3
a 0.809003 1.125689 -1.234327
b 0.685297 NaN 0.431967
c -1.396598 -0.779780 NaN
d NaN 1.090197 1.182934
'''
print("\nstack 时,空值会默认被去掉")
print("列只有一层的dataframe进行stack 时,会变为Series")
print(data.unstack().stack())
'''
a 1 0.809003
2 1.125689
3 -1.234327
b 1 0.685297
3 0.431967
c 1 -1.396598
2 -0.779780
d 2 1.090197
3 1.182934
dtype: float64
'''
print("\n行只有一层的dataframe进行unstack 时,会变为Series")
print(data.unstack().unstack())
'''
1 a 0.809003
b 0.685297
c -1.396598
d NaN
2 a 1.125689
b NaN
c -0.779780
d 1.090197
3 a -1.234327
b 0.431967
c NaN
d 1.182934
dtype: float64
'''行和列均层次化的 dataframe的 unstack()和 stack(),默认最内层到最内层
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']])
print(frame)
print("\n行到列\n", frame.unstack())
print("\n列到行\n", frame.stack())用level参数将指定层进行转化,注意最外层是level = 0
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']])
print(frame)
print("\n行到列\n", frame.unstack(level=0))
print("\n列到行\n", frame.stack(level=0))如果层次化索引有名字,也可以按名字转化
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']])
frame.index.names = ['row1', 'row2']
frame.columns.names = ['state', 'color']
print(frame)
print("\n行到列\n", frame.unstack("row1"))
print("\n列到行\n", frame.stack("state"))
用dropna参数设定是否删除空值
import pandas as pd
import numpy as np
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],
columns=[['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']])
frame.index.names = ['row1', 'row2']
frame.columns.names = ['state', 'color']
print(frame)
print("\n行到列\n", frame.unstack("row1"))
print("\n列到行\n", frame.stack("state"))
print("用dropna参数设定是否删除空值")
data = pd.Series(np.random.randn(9),
index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],
[1, 2, 3, 1, 3, 1, 2, 2, 3]])
print(data)
print("\n行到列\n", data.unstack())
print("\n先行到列,然后列到行,过滤空值\n", data.unstack().stack()) # 默认过滤空值
print("\n先行到列,然后列到行,不过滤空值\n", data.unstack().stack(dropna=False)) # 不过滤空值(2)数据透视表
df.pivot():将df某三列生成数据透视表
作用:将dataframe的某三列做成“数据透视表”
df.pivot(indexName, columnName[, valuesName])
三个参数:行索引名字、列名、值名
import numpy as np
import pandas as pd
data = {"date":["11","12","13","14","15","16","17","18","19","20","21","22"],
"item": ['gdp', 'fdi', 'pop', 'k']*3,
"money":np.arange(12)}
df = pd.DataFrame(data)
print(df)
'''
date item money
0 11 gdp 0
1 12 fdi 1
2 13 pop 2
3 14 k 3
4 15 gdp 4
5 16 fdi 5
6 17 pop 6
7 18 k 7
8 19 gdp 8
9 20 fdi 9
10 21 pop 10
11 22 k 11
'''
pivoted = df.pivot('date', 'item', 'money')
print(pivoted)
'''
item fdi gdp k pop
date
11 NaN 0.0 NaN NaN
12 1.0 NaN NaN NaN
13 NaN NaN NaN 2.0
14 NaN NaN 3.0 NaN
15 NaN 4.0 NaN NaN
16 5.0 NaN NaN NaN
17 NaN NaN NaN 6.0
18 NaN NaN 7.0 NaN
19 NaN 8.0 NaN NaN
20 9.0 NaN NaN NaN
21 NaN NaN NaN 10.0
22 NaN NaN 11.0 NaN
'''pd.melt():将df变为三列
将dataframe变为只有三列的dataframe,就是“数据透视表”那三个变量
pd.melt(frame:'DataFrame', id_vars=None, value_vars=None,
var_name=None, value_name='value', col_level=None, ignore_index:bool=True)
import numpy as np
import pandas as pd
df = pd.DataFrame({'key': ['foo', 'bar', 'xxx'],
'A': [1, 2, 3],
'B': [4, 5, 6],
'C': [7, 8, 9]})
print(df)
'''
key A B C
0 foo 1 4 7
1 bar 2 5 8
2 xxx 3 6 9
'''
print("\n①一个分组 + 默认所有值变量")
melted = pd.melt(df, ['key'])
print(melted)
'''
key variable value
0 foo A 1
1 bar A 2
2 xxx A 3
3 foo B 4
4 bar B 5
5 xxx B 6
6 foo C 7
7 bar C 8
8 xxx C 9
'''
print("\n②一个分组 + 特定变量")
result = pd.melt(df, id_vars=['key'], value_vars=['A', 'B'])
print(result)
'''
key variable value
0 foo A 1
1 bar A 2
2 xxx A 3
3 foo B 4
4 bar B 5
5 xxx B 6
'''pd.pivot_table():生成数据透视表(推荐)
函数原型与参数
pd.pivot_table(data,
values=None,
index=None,
columns=None,
aggfunc='mean',
fill_value=None,
margins=False,
dropna=True,
margins_name='All'
)种使用方法:
- 对象方法:dataframe.pivot_table(*args)
- 顶级方法:pd.pivot_table(dataframe, *args)
常用参数:
- values
- index
- columns
- aggfunc
用法讲解
读取哈登篮球数据
data = pd.read_csv(r'D:\PythonData\James_Harden.csv')
print(data)
①index参数用法:将某个列变量变为行索引。多个列名的列表表示层次化索引
例子a.查看哈登对阵不同对手的数据情况
result = pd.pivot_table(data, index = [u'对手'])
print(result.tail())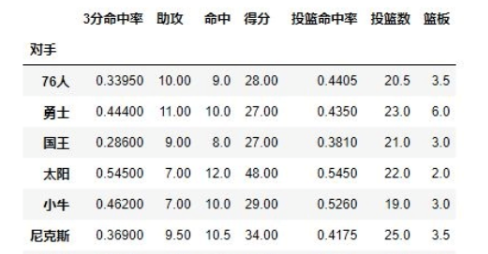
例子b.查看哈登对阵不同对手同时在不同主客场下的数据
result = pd.pivot_table(data, index = [u'对手', u'主客场'])
print(result.head(10))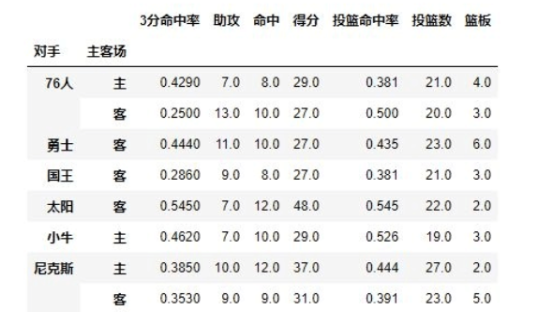
例子c.交换对手和主客场的顺序
result = pd.pivot_table(data, index = [u'主客场', u'对手'])
print(result)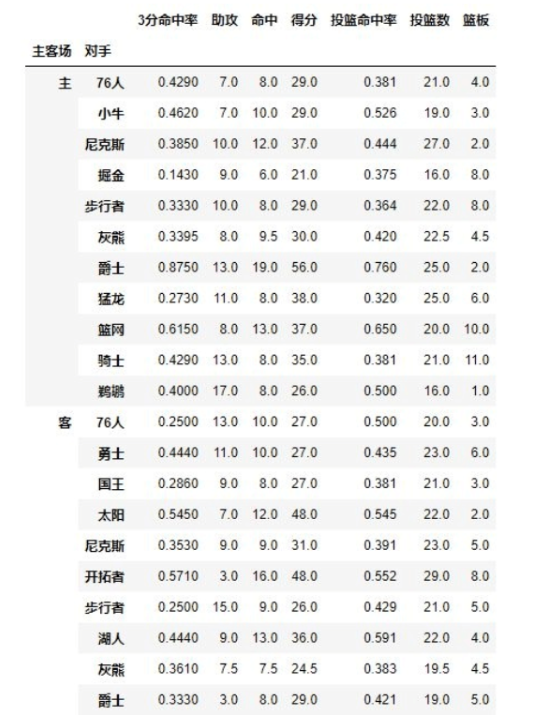
②values 参数用法:设置展示哪些值变量,默认展示所有的值
比如我们这里只需要 james harden 在主客场和不同胜负情况下的得分、篮板与助攻三项数据
result = pd.pivot_table(data,
index=[u'主客场', u'胜负'],
values=[u'得分', u'篮板', u'助攻'])
print(result) # 这里默认对聚合数据进行平均值计算
# 比如下面结果显示哈登在主场赢的情况下平均助攻是10.55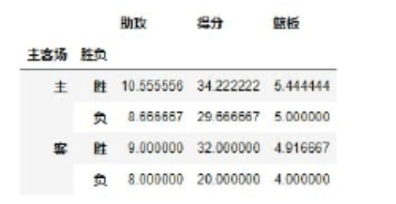
③aggfunc 参数:设置对聚合数据的计算方式,默认是 mean 求均值
比如我们这里既要看平均数据,也要看求和数据
result = pd.pivot_table(data,
index = [u'主客场', u'胜负'],
values = [u'得分', u'篮板', u'助攻'],
aggfunc = [np.sum, np.mean])
print(result)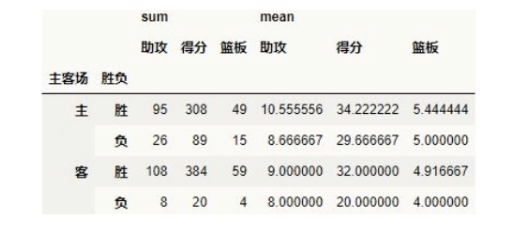
④columns 参数:比如要展示的数据行索引为主客场,列索引为不同对手,值为得分
result = pd.pivot_table(data,
index = [u'主客场'],
columns = [u'对手'],
values = [u'得分'],
aggfunc = [np.sum]
)
print(result)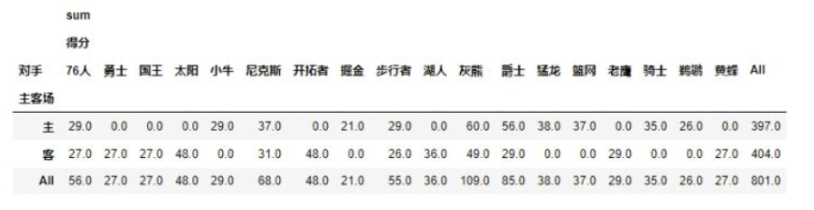
⑤fill_value 参数:将空值填充为指定值
result = pd.pivot_table(data,
index = [u'主客场'],
columns = [u'对手'],
values = [u'得分'],
aggfunc = [np.sum],
fill_value = 0
)
print(result)⑥margins 参数:布尔参数,是否进行求和汇总
result = pd.pivot_table(data,
index = [u'主客场'],
columns = [u'对手'],
values = [u'得分'],
aggfunc = [np.sum],
fill_value = 0,
margins = True
)
print(result)⑦aggfunc 也可以使用 dict 类型,使得对不同的值变量进行不同的运算操作
result = pd.pivot_table(data,
index = [u'对手',u'胜负'],
columns = [u'主客场'],
values = [u'得分',u'助攻',u'篮板'],
aggfunc = {u'得分':np.mean, u'助攻':[min, max, np.mean]},
fill_value = 0
)
print(result)
# 这里就是助攻求 min,max 和 mean,得分求 mean, 而篮板没有显示(3)数据合并
1.pd.merge() 横向合并
基本参数:
- left:参与合并的左侧dataframe
- right:参与合并的右侧dataframe
- how:以何种方式合并。交集'inner', 并集'outer', 左侧'left', 右侧'right'。默认交集。比如left有A, B, C三个列名,right有B, C, D三列,若按字段B, C来合并,则how交集的意思就是对B, C的组合值相等的数据进行合并,比如left有10行数据,right有20行数据,left和right有5行数据的B, C组合值相等,则合并后就是这5行数据,列名是取left和right的并集
- on:参与合并的字段。默认按left和right列名的交集。on交集的意思根据列名的交集来进行数据合并,比如left有A, B, C三个列名,right有B, C, D三列,则交集为B, C。
- left_on和left_index:left_on指定left参与合并的列名,left_index布尔变量是否将left的行索引index用作参与合并的列名。两者使用一个即可。
- right_on和right_index:right_on指定right参与合并的列名,right_index布尔变量是否将right的行索引index用作参与合并的列名。两者使用一个即可。
- sort:根据连接键对合并后的数据排序,默认为True。
- suffixes:字符串值元组,用于追加到重叠列名的末尾,默认是('_x', '_y')。例如,如果左右两个dataframe都有名为data的列(注意data不是用来合并的列),则结果中就会出现'data_x'和'data_y'。
①默认按公共关键字进行横向合并,index 重新按 0,1,2,..,N-1 索引
import numpy as np
import pandas as pd
left = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'], 'data1': range(7)})
right = pd.DataFrame({'key': ['a', 'b', 'd'], 'data2': range(3)})
print(left)
print(right)
print(pd.merge(left, right))②on参数指定共有键名进行合并
print(pd.merge(left, right, on='key'))
left = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'], 'data': range(7)})
right = pd.DataFrame({'key': ['a', 'b', 'd'], 'data': range(3)})
print(left)
print(right)
print(pd.merge(left, right, on="key"))
# key data_x data_y
# 0 b 0 1
# 1 b 1 1
# 2 b 6 1
# 3 a 2 0
# 4 a 4 0
# 5 a 5 0
print("根据多个键进行合并")
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],
'key2': ['one', 'two', 'one'],
'lval': [1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval': [4, 5, 6, 7]})
print(left)
print(right)
print(pd.merge(left, right, on=['key1', 'key2']))③left_on和right_on 参数指定左右键名进行合并
left = pd.DataFrame({'lkey': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],
'data1': range(7)})
right = pd.DataFrame({'rkey': ['a', 'b', 'd'],
'data2': range(3)})
print(pd.merge(left, right, left_on='lkey', right_on='rkey'))④how 参数根据指定键名的交/并/左/右集纵向合并
print(pd.merge(left, right, left_on='lkey', right_on='rkey', how="outer"))⑤多对多合并:笛卡尔积:A×B={(x, y)|x∈A∧y∈B}
# 多指的是关键字有重复项,多对多指的是要合并的两个 dataframe 的关键字都有重复项
left = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
'data1': range(6)})
right = pd.DataFrame({'key': ['a', 'b', 'a', 'b', 'd'],
'data2': range(5)})
print(pd.merge(left, right, on='key'))
print(pd.merge(left, right, on='key', how='left'))⑥suffixes 参数给合并后的相同列名添加不同后缀,方便区分
left = pd.DataFrame({'key1': ['foo', 'foo', 'bar'],
'key2': ['one', 'two', 'one'],
'lval': [1, 2, 3]})
right = pd.DataFrame({'key1': ['foo', 'foo', 'bar', 'bar'],
'key2': ['one', 'one', 'one', 'two'],
'rval': [4, 5, 6, 7]})
print(pd.merge(left, right, on='key1')) # suffixes 默认是加'_x'和'_y'
print(pd.merge(left, right, on='key1', suffixes=["_left", "_right"]))⑦left_index 和 right_index 参数是否指定行索引参与合并
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b'])
print(pd.merge(left1, right1, left_on='key', right_index=True))
print(pd.merge(left1, right1, left_on='key', right_index=True, how='outer'))⑧left_index 和 right_index 用层次化索引合并
left = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],
'key2': [2000, 2001, 2002, 2001, 2002],
'data': np.arange(5.)})
right = pd.DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2'])
print(pd.merge(left, right, left_on=['key1', 'key2'], right_index = True))⑨左右都用层次化的行索引作为键进行合并
left = pd.DataFrame(np.arange(18).reshape((6, 3)),
index=[['xxxxx', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2', 'event3'])
right = pd.DataFrame(np.arange(12).reshape((6, 2)),
index=[['Nevada', 'Nevada', 'Ohio', 'Ohio', 'Ohio', 'Ohio'],
[2001, 2000, 2000, 2000, 2001, 2002]],
columns=['event1', 'event2'])
print(pd.merge(left, right, how='outer', left_index=True, right_index=True))
2.df1.join(df2, df3) 横向合并
on参数:指定合并的键名
how参数:指定合并方式。交集'inner', 并集'outer', 左侧'left', 右侧'right'。默认'left'。
import pandas as pd
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],
index = ['a', 'c', 'e'],
columns = ['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index = ['b', 'c', 'd', 'e'],
columns = ['Missouri', 'Alabama'])
print("默认用行索引,默认how = 'left'")
print(left2)
print(right2)
print(left2.join(right2))
print(left2.join(right2, how = 'outer'))
print("按指定列名合并")
print("若一方没有该列名,则用行索引进行匹配")
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],
'value': range(6)})
right1 = pd.DataFrame({'group_val': [3.5, 7, 9]}, index = ['a', 'b', 'e'])
print(left1.join(right1, on = 'key'))
print("将三个及以上的 pd 对象合并")
left2 = pd.DataFrame([[1., 2.], [3., 4.], [5., 6.]],
index = ['a', 'c', 'e'],
columns = ['Ohio', 'Nevada'])
right2 = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [13, 14]],
index = ['b', 'c', 'd', 'e'],
columns = ['Missouri', 'Alabama'])
another = pd.DataFrame([[7., 8.], [9., 10.], [11., 12.], [16., 17.]],
index=['a', 'c', 'e', 'f'],
columns=['New York','Oregon'])
print(left2.join([right2, another]))
print(left2.join([right2, another], how = 'outer'))3.df1.combine_first(df2) 横向合并
注意:行索引和列名都取并集,前者有数取前者,否者取后者,都没有取空
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'gdp': [1., np.nan, 5., np.nan],
'pop': [np.nan, 2., np.nan, 6.],
'fdi': range(2, 18, 4)},
index = ["a", "b", "c", "d"])
df2 = pd.DataFrame({'gdp': [5., 4., np.nan, 3., 7.],
'fdi': [np.nan, 3., 4., 6., 8.]},
index = ["a", "b", "c", "d", "e"])
print(df1)
# gdp pop fdi
# a 1.0 NaN 2
# b NaN 2.0 6
# c 5.0 NaN 10
# d NaN 6.0 14
print(df2)
# gdp fdi
# a 5.0 NaN
# b 4.0 3.0
# c NaN 4.0
# d 3.0 6.0
# e 7.0 8.0
print(df1.combine_first(df2))
# fdi gdp pop
# a 2.0 1.0 NaN
# b 6.0 4.0 2.0
# c 10.0 5.0 NaN
# d 14.0 3.0 6.0
# e 8.0 7.0 NaN类似于这个函数 np.where(pd.isnull(a), b, a)
a = pd.Series([np.nan, 2.5, np.nan, 3.5, 4.5, np.nan],
index = ['f', 'e', 'd', 'c', 'b', 'a'])
b = pd.Series(np.arange(len(a), dtype=np.float64),
index = ['f', 'e', 'd', 'c', 'b', 'a'])
b[-1] = np.nan
print(a)
print(b)
result = np.where(pd.isnull(a), b, a)
print(type(result)) # <class 'numpy.ndarray'>
print(result)4.pd.concat() 可横向合,也可纵向合并
参数:
- objs:参与合并的pd对象。多个对象用列表。
- axis:设置合并方向。默认axis=0,纵向合并。axis=1则是横向合并。
- join:合并方式。默认并集'outer',还可以是交集'inner'。
- keys:在合并时创建层次化索引。比如合并3个对象,可以keys = ["name1", "name2", "name3"]。
- names:给层次化索引取名字
- ignore_index:布尔变量。True就是不保留连接轴上的索引,也就是将结果的索引变为默认索引。
①默认纵向合并
s1 = pd.Series([0,1], index = ['a', 'b'])
s2 = pd.Series([2,3,4], index = ['c', 'd', 'e'])
s3 = pd.Series([5,6], index = ['f', 'g'])
print(pd.concat([s1, s2, s3]))②横向合并
print(pd.concat([s1,s2,s3], axis = 1))
# 0 1 2
# a 0.0 NaN NaN
# b 1.0 NaN NaN
# c NaN 2.0 NaN
# d NaN 3.0 NaN
# e NaN 4.0 NaN
# f NaN NaN 5.0
# g NaN NaN 6.0
# 横向合并的index、columns分别是合并对象的并集
df1 = pd.DataFrame([[1,2,3],[4,5,6],[7,8,9]],
index = ['行1', '行2','行3'],
columns=['列1', '列2', '列3']
)
print(df1)
df2 = pd.DataFrame([[11,22,33],[44,55,66],[77,88,99]],
index = ['a', 'b','c'],
columns=['x', 'y', 'z']
)
print(df2)
print(pd.concat([df1, df2], axis = 1))
# 列1 列2 列3 x y z
# 行1 1.0 2.0 3.0 NaN NaN NaN
# 行2 4.0 5.0 6.0 NaN NaN NaN
# 行3 7.0 8.0 9.0 NaN NaN NaN
# a NaN NaN NaN 11.0 22.0 33.0
# b NaN NaN NaN 44.0 55.0 66.0
# c NaN NaN NaN 77.0 88.0 99.0③用join 参数设置合并方式
s1 = pd.Series([0,1], index = ['a', 'b'])
s2 = pd.Series([2,3,4], index = ['c', 'd', 'e'])
s3 = pd.Series([5,6], index = ['f', 'g'])
s4 = pd.concat([s1, s3])
print(pd.concat([s1, s4], axis = 1))
print(pd.concat([s1, s4], axis = 1,join = 'inner'))④使用keys 参数在合并时创建层次化索引
# a.为 series 的情况
s1 = pd.Series([0,1], index = ['a', 'b'])
s2 = pd.Series([2,3,4], index = ['c','d','e'])
s3 = pd.Series([5,6], index = ['f','g'])
result1 = pd.concat([s1, s2, s3], keys = ['one', 'two', 'three'])
print(result1) # 成为行索引的最外层
# one a 0
# b 1
# two c 2
# d 3
# e 4
# three f 5
# g 6
# dtype: int64
result2 = pd.concat([s1, s2, s3], axis = 1, keys = ['one', 'two', 'three'])
print(result2) # 成为列索引的最外层
# one two three
# a 0.0 NaN NaN
# b 1.0 NaN NaN
# c NaN 2.0 NaN
# d NaN 3.0 NaN
# e NaN 4.0 NaN
# f NaN NaN 5.0
# g NaN NaN 6.0
# b.为 dataframe 的情况
df1 = pd.DataFrame(np.arange(6).reshape(3, 2),
index = ['a', 'b', 'c'],
columns = ['one', 'two'])
df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2),
index = ['a', 'c'],
columns = ['three', 'four'])
print(pd.concat([df1, df2], axis = 1, keys = ['level1','level2']))
print(pd.concat({'level1': df1, 'level2': df2}, axis = 1)) # 用传入字典实现相同效果
# level1 level2
# one two three four
# a 0 1 5.0 6.0
# b 2 3 NaN NaN
# c 4 5 7.0 8.0⑤用names 参数给层次化索引取名字
print(pd.concat([df1, df2], axis = 1, keys = ['level1', 'level2'],
names = ['列', '行']))⑥用ignore_index 参数不保留连接轴上的索引,也就是将结果的索引变为默认索引
df1 = pd.DataFrame(np.arange(12).reshape(3,4), columns = ['a', 'b', 'c', 'd'], index = ['one', 'two', 'three'])
df2 = pd.DataFrame(np.arange(12,18).reshape(2,3), columns = ['b', 'd', 'a'], index = ['one', 'two'])
print(pd.concat([df1, df2]))
print(pd.concat([df1, df2], ignore_index = True))(4)分组统计
1.dataframe.groupby() 分组函数
import numpy as np
import pandas as pd
print("====加载数据====")
iris = pd.read_csv(r'D:\PythonData\testdata\iris.csv', header = 0)
# header 默认值为 0,将第 0 行作为标题行
print(iris.head())
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
print(iris.info())
print(iris.species.value_counts())
print("====分组====")
s = iris.groupby('species')
print(type(s)) # pandas.core.groupby.generic.DataFrameGroupBy
# 查看分组的详细信息
print(type(s.groups)) # 是个字典
print(s.groups) # 每个键值为一组,键为组名,值为index的集合
for key in s.groups:
print(s.groups[key])
print(list(s.groups[key]))2.使用自带统计函数进行分组统计
基本用法
# 求每个组每列的最大值
print(iris.groupby('species').max())
'''
sepal_length sepal_width petal_length petal_width
species
setosa 5.8 4.4 1.9 0.6
versicolor 7.0 3.4 5.1 1.8
virginica 7.9 3.8 6.9 2.5
'''
# 求每个组内花萼这一列的平均值
print(iris.groupby('species').sepal_width.mean())
'''
species
setosa 3.428
versicolor 2.770
virginica 2.974
Name: sepal_width, dtype: float64
'''处理数据示例:先合并数据,然后分组统计
import pandas as pd
df_buyXZ = pd.read_csv('D:\data\xz_data.csv')
df_buySC = pd.read_csv('D:\data\sc_data.csv')
print(df_buyXZ)
'''
Ticker Direction Quantity
0 300716.SZ 1 2000
1 600774.SH 1 2300
2 000599.SZ 1 6700
3 603711.SH 1 300
4 603948.SH 1 200
5 000902.SZ 1 600
'''
print(df_buySC)
'''
Ticker Direction Quantity
0 300716.SZ 1 1900
1 600774.SH 1 2300
2 000951.SZ 1 4100
3 603711.SH 1 300
4 603948.SH 1 200
5 601866.SH 1 23100
6 000902.SZ 1 600
'''
frame_buy = [df_buyXZ, df_buySC]
df_buy = pd.concat(frame_buy)
print(df_buy)
'''
Ticker Direction Quantity
0 300716.SZ 1 2000
1 600774.SH 1 2300
2 000599.SZ 1 6700
3 603711.SH 1 300
4 603948.SH 1 200
5 000902.SZ 1 600
0 300716.SZ 1 1900
1 600774.SH 1 2300
2 000951.SZ 1 4100
3 603711.SH 1 300
4 603948.SH 1 200
5 601866.SH 1 23100
6 000902.SZ 1 600
'''
group_buy = df_buy.groupby('Ticker')[['Quantity']].sum()
print(group_buy)
'''
Quantity
Ticker
000599.SZ 6700
000902.SZ 1200
000951.SZ 4100
300716.SZ 3900
600774.SH 4600
601866.SH 23100
603711.SH 600
603948.SH 400
'''
group_buy.reset_index(inplace=True)
print(group_buy)
'''
Ticker Quantity
0 000599.SZ 6700
1 000902.SZ 1200
2 000951.SZ 4100
3 300716.SZ 3900
4 600774.SH 4600
5 601866.SH 23100
6 603711.SH 600
7 603948.SH 400
'''
group_buy['Direction'] = 1
print(group_buy)
'''
Ticker Quantity Direction
0 000599.SZ 6700 1
1 000902.SZ 1200 1
2 000951.SZ 4100 1
3 300716.SZ 3900 1
4 600774.SH 4600 1
5 601866.SH 23100 1
6 603711.SH 600 1
7 603948.SH 400 1
'''
df_buy = group_buy[['Ticker', 'Direction', 'Quantity']]
print(df_buy)处理数据示例:分组后指定列求和以及其它列保留首次值
如果你想在求和后只保留每个组内的第一次出现的内容,可以使用 groupby 后的 first 方法。下面是一个例子:
import pandas as pd
data = {
'Category': ['A', 'B', 'A', 'B', 'A', 'B'],
'Value': [10, 20, 30, 40, 50, 60],
'OtherColumn': ['X', 'Y', 'X', 'Y', 'X', 'Y']
}
df = pd.DataFrame(data)
# 先对 'Category' 列进行分组,对'Value'列求和,对其它列使用 first 方法
result = df.groupby('Category').agg({'Value': 'sum', 'OtherColumn': 'first'}).reset_index()
print(result)
"""
Category Value OtherColumn
0 A 90 X
1 B 120 Y
"""3.df.groupby().agg() 使用自定义统计函数
# 定义一个求最大与最小值差值的函数:
def range_iris(arr): # 输入的参数为一个 series
return arr.max() - arr.min() # 返回一个数
print(iris.groupby('species').agg(range_iris))
'''
sepal_length sepal_width petal_length petal_width
species
setosa 1.5 2.1 0.9 0.5
versicolor 2.1 1.4 2.1 0.8
virginica 3.0 1.6 2.4 1.1
'''4.dataframe.groupby().apply() 元素级函数操作
- 前面agg那里自定义函数会对每组的每一列进行函数,然后每列得到一个值,像前面的在setosa种类下,sepal_length列的平均值,sepal_width列的平均值,petal_length列的平均值等
- 现在用apply,在这里,自定义的函数需要将每个组作为参数,而不是前面每个组的每个列作为参数,至于返回类型,取决于函数实现,既可以返回一个值,也可以返回一个其它复杂对象,比如返回一个dataframe,只需要自己在自定义函数里面设置即可
print(iris.head())
# sepal_length sepal_width petal_length petal_width species
# 0 5.1 3.5 1.4 0.2 setosa
# 1 4.9 3.0 1.4 0.2 setosa
# 2 4.7 3.2 1.3 0.2 setosa
# 3 4.6 3.1 1.5 0.2 setosa
# 4 5.0 3.6 1.4 0.2 setosa
def bigger_x(df, varName, x = 5):
# bigger_x作为apply需传入自定义函数,在设计时需将每个组作为参数传入
# 每一组就是一个df
result = df[df[varName] > x]
return result # 这里设置返回对象为一个dataframe
result = iris.groupby('species').apply(bigger_x, varName = 'sepal_length')
# 以上操作每个组经过bigger_x函数后会获得一个fataframe
# 然后apply将这些结果合并成一个多级索引的DataFrame
# DataFrame会保留原始索引作为第二级索引,分组键(species)作为外层索引,像下面这样
print(result)
'''
sepal_length sepal_width petal_length petal_width species
species original_index
setosa 5 5.0 3.6 1.4 0.2 setosa
versicolor 51 7.0 3.2 4.7 1.4 versicolor
52 6.4 3.2 4.5 1.5 versicolor
53 6.9 3.1 4.9 1.5 versicolor
virginica 100 5.9 3.0 5.1 1.8 virginica
101 6.3 3.3 6.0 2.5 virginica
102 5.8 2.7 5.1 1.9 virginica
'''
result2 = result.count(level = 0) # 对每个组进行非空值的计数
# level = 0就是对行的最外层进行统计
print(result2)end