畅游Diffusion数字人(0):专栏文章导航
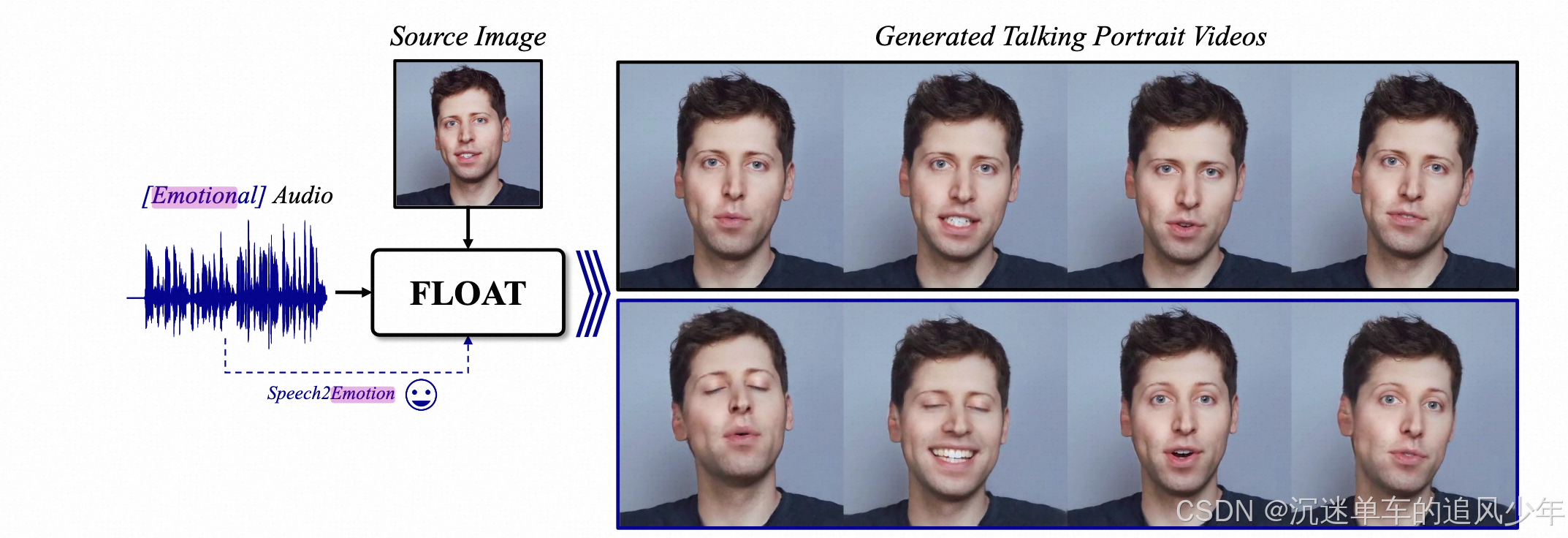
前言:仅从音频生成此类运动极具挑战性,因为它在音频和运动之间存在一对多的相关性。运动视频的情绪是多元化的选择,之前的工作很少考虑情绪化的数字人生成。今天解读一个最新的工作FLOAT,可以生成制定情绪化的数字人视频。
目录
贡献概述
动机
相关工作
方法详解
情感控制
贡献概述
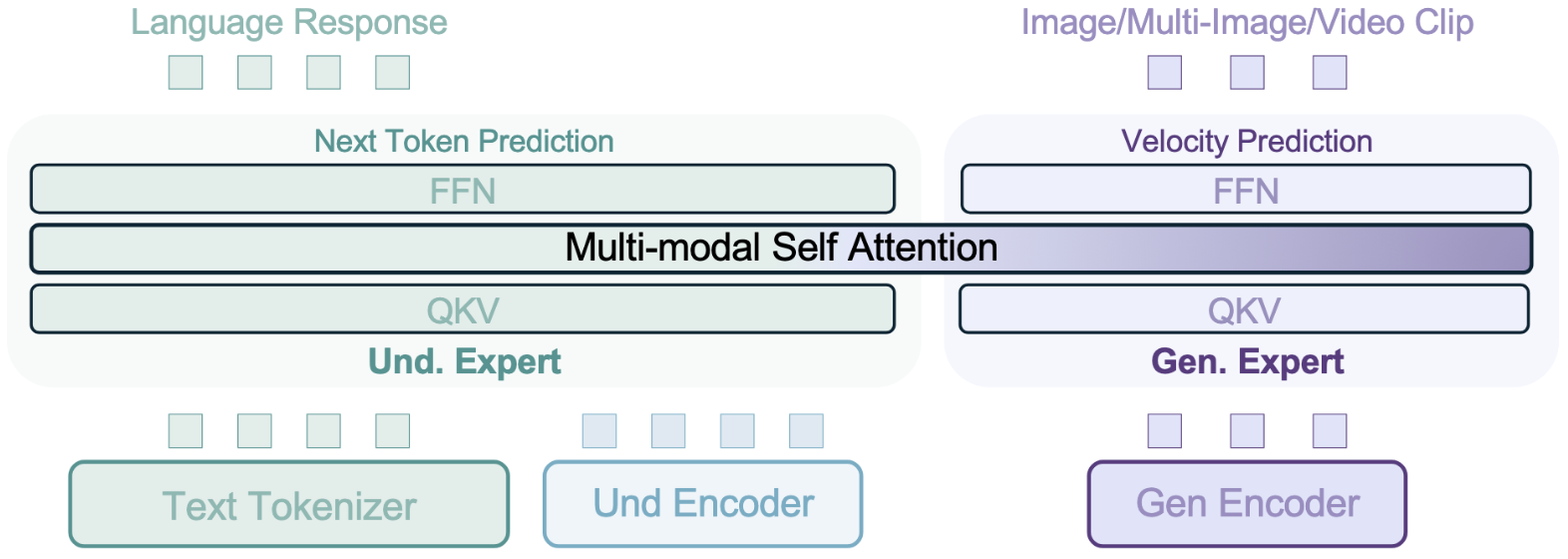
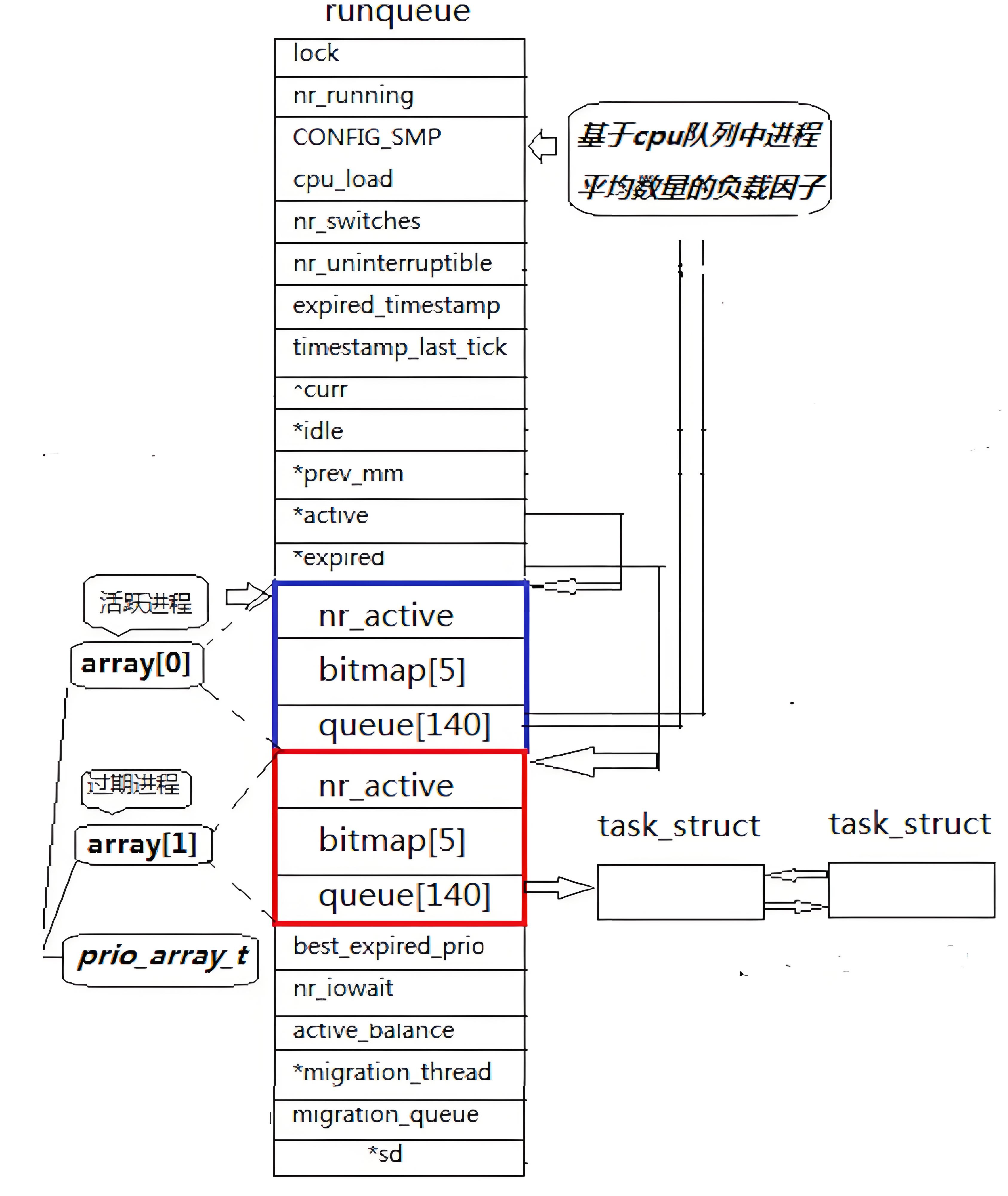
一种基于流匹配生成模型的音频驱动的会说话肖像视频生成方法。我们将生成建模从基于像素的潜在空间转变为学习的运动潜在空间,从而能够高效设计时间一致的运动。为了实现
畅游Diffusion数字人(0):专栏文章导航
前言:仅从音频生成此类运动极具挑战性,因为它在音频和运动之间存在一对多的相关性。运动视频的情绪是多元化的选择,之前的工作很少考虑情绪化的数字人生成。今天解读一个最新的工作FLOAT,可以生成制定情绪化的数字人视频。
目录
贡献概述
动机
相关工作
方法详解
情感控制
一种基于流匹配生成模型的音频驱动的会说话肖像视频生成方法。我们将生成建模从基于像素的潜在空间转变为学习的运动潜在空间,从而能够高效设计时间一致的运动。为了实现
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2385796.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!





![[Datagear] 实现按月颗粒度选择日期的方案](https://i-blog.csdnimg.cn/direct/5284c53117354d94bcd70f909073a961.png)