Lora-Tuning
什么是Lora微调?
LoRA(Low-Rank Adaptation) 是一种参数高效微调方法(PEFT, Parameter-Efficient Fine-Tuning),它通过引入低秩矩阵到预训练模型的权重变换中,实现无需大规模修改原模型参数即可完成下游任务的微调。即你微调后模型的参数 = 冻结模型参数 + Lora微调参数。
什么是微调?
在早期的机器学习中,构建一个模型并对其进行训练是可行的。但到了深度学习阶段,模型的参数量大且训练的数据多,因此要从0到1训练一个模型是非常耗时和耗资源的过程。
训练,在其最简单的意义上。您将一个未经训练的模型,提供给它数据,并获得一个高性能的模型。
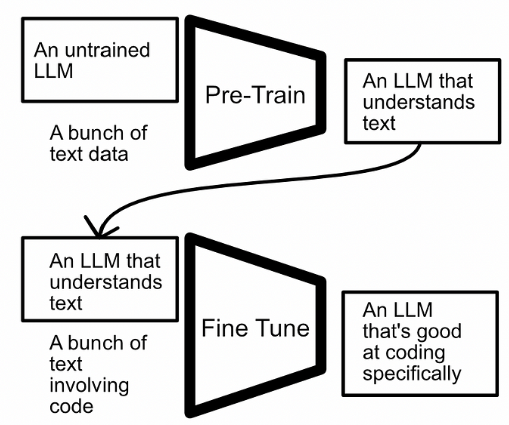
对于简单问题来说,这仍然是一种流行的策略,但对于更复杂的问题,将训练分为两个部分,即“预训练”和“微调”,可能会很有用。总体思路是在一个大规模数据集上进行初始训练,并在一个定制的数据集上对模型进行优化。
最基本的微调形式 是使用与预训练模型相同的过程来微调新数据上的模型。例如,您可以在大量的通用文本数据上训练模型,然后使用相同的训练策略,在更具体的数据集上微调该模型。
目前的话,在深度学习中,你所用的预训练的模型就是别人从0到1训练好给你用的,你后面的基于特定数据集所做的训练其实是基于已有模型参数的基础上去进行微调。
那在深度学习阶段,这种方式消耗GPU的程度还可以接收,那到了LLM阶段,如果想通过微调全部参数来微调上一个已预训练好的没有冻结参数模型的话,那消费的GPU就不是一个量级上的,因此Lora就是针对LLM微调消耗资源大所提出优化方案。
Lora的思想
“低秩适应”(LoRA)是一种“参数高效微调”(PEFT)的形式,它允许使用少量可学习参数对大型模型进行微调 。LoRA改善微调的几个关键点:
- 将微调视为学习参数的变化(
),而不是调整参数本身(
)。
- 通过删除重复信息,将这些变化压缩成较小的表示。
- 通过简单地将它们添加到预训练参数中来“加载”新的变化。
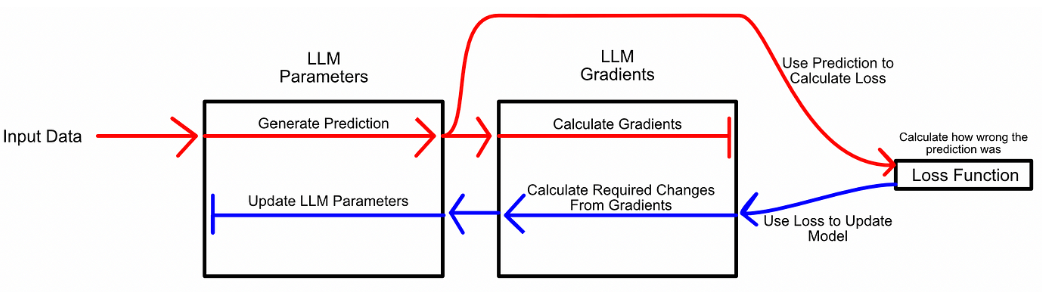
正如之前讨论的,微调的最基本方法是迭代地更新参数。就像正常的模型训练一样,你让模型进行推理,然后根据推理的错误程度更新模型的参数(反向传播)。
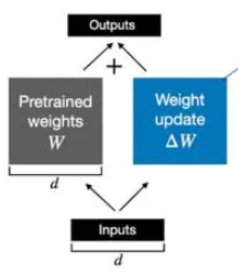
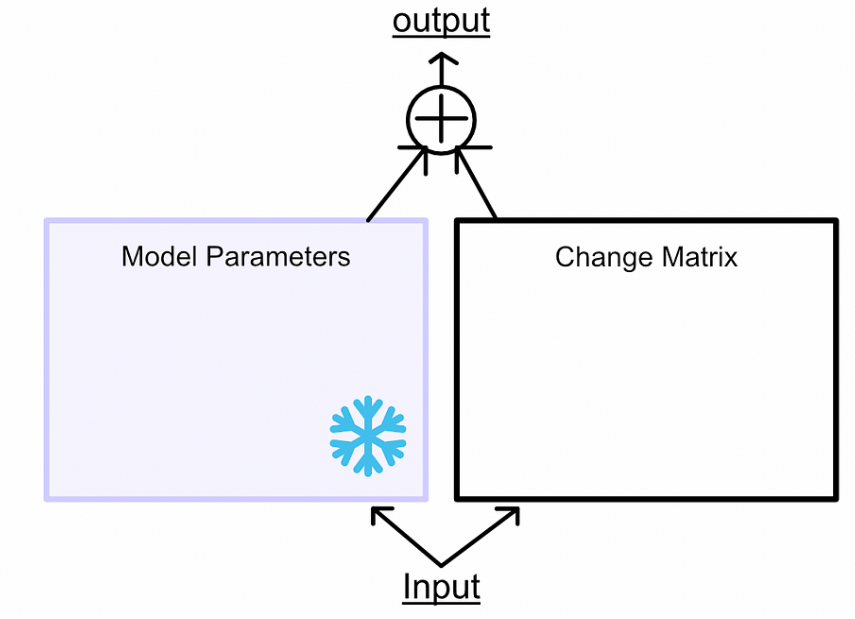
与其将微调视为学习更好的参数,LoRA 将微调视为学习参数变化:冻结模型参数,然后学习使模型在微调任务中表现更好所需的这些参数的变化。类似于训练,首先让模型推理,然后根据error进行更新。但是,不更新模型参数,而是更新模型参数的变化。如下面所示,蓝色箭头反向传播只是去微调模型所需要的参数变化,没有去微调模型原有的参数。
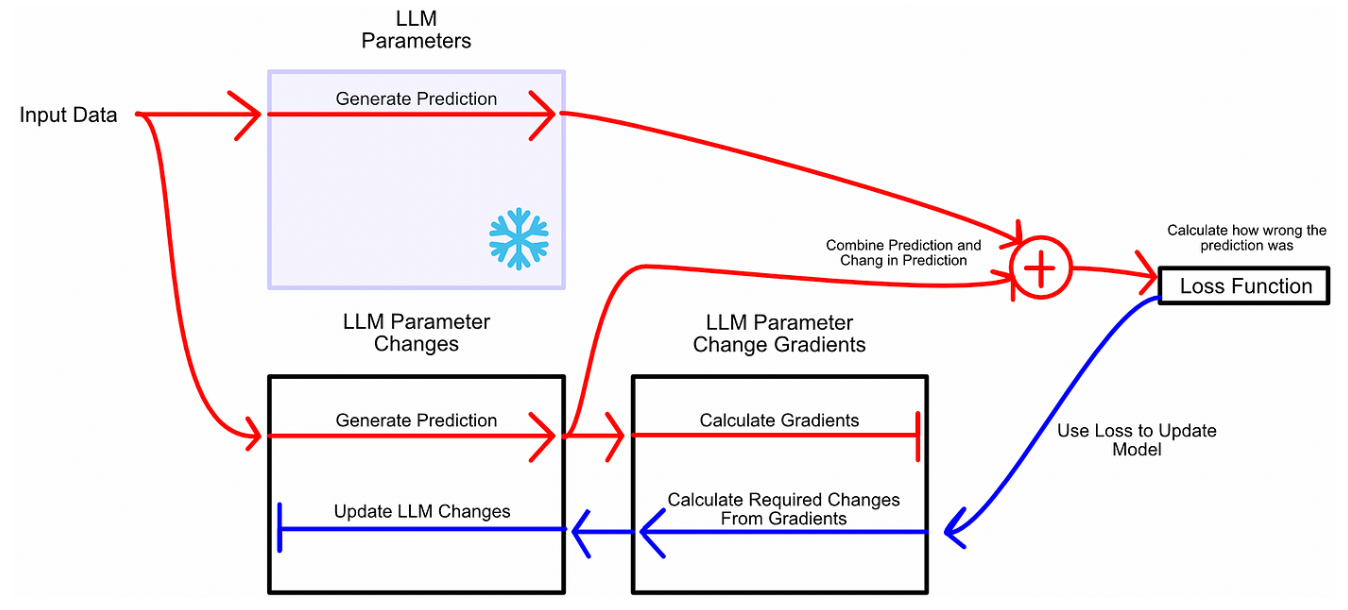
在微调的过程中可以不去微调W,去微调来捕捉
所需要进行的参数变化,那随后二者相加就得到了微调后模型的参数。
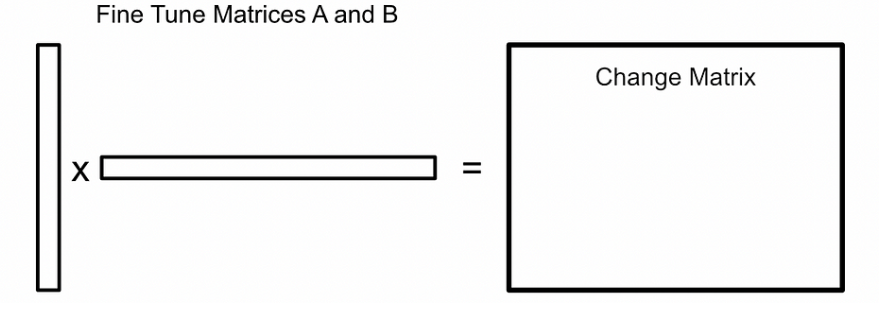
那Lora体现的降低资源在哪?如如果形状为[ 1000, 200 ] 的话,那如果我去微调原模型参数的话,那需要微调的参数有 1000 * 200 = 200,000。聪明的你可能想到了,那我去微调获得参数的变化不也是一个[ 1000, 200 ]的矩阵,不然后面矩阵怎么相加。这就是Lora的巧妙之处,它将所需微调的
矩阵分解为低秩表示,你在这个过程不需要显示计算
,只需要学习
的分解表示。比如
= [ 1000, 200 ] 可以被划分为 [1000, 1] * [1, 200],那这样的话所需要微调的参数就只有1000+200=1200,与200,000比的话,我们就可以明显看出来Lora节省计算资源的秘密了。

补充:
- 那Lora为什么是低秩?首先我们要明确矩阵的秩的概念,矩阵秩在我们学线性代数中存在的概念,其定义为:矩阵中行(或列)向量线性无关的最大数量。换句话说,换句话说,矩阵的秩表示其可以提供多少个独立的信息维度。如果秩越大,表示矩阵的行(列)越独立,它们不能被其他另外的行(列)进行线性表示获得;相反,如果秩越小,那么表示矩阵的行(列)独立程度低,那么我可以根据其中所有独立的行(列)来得到矩阵所有的行(列)。
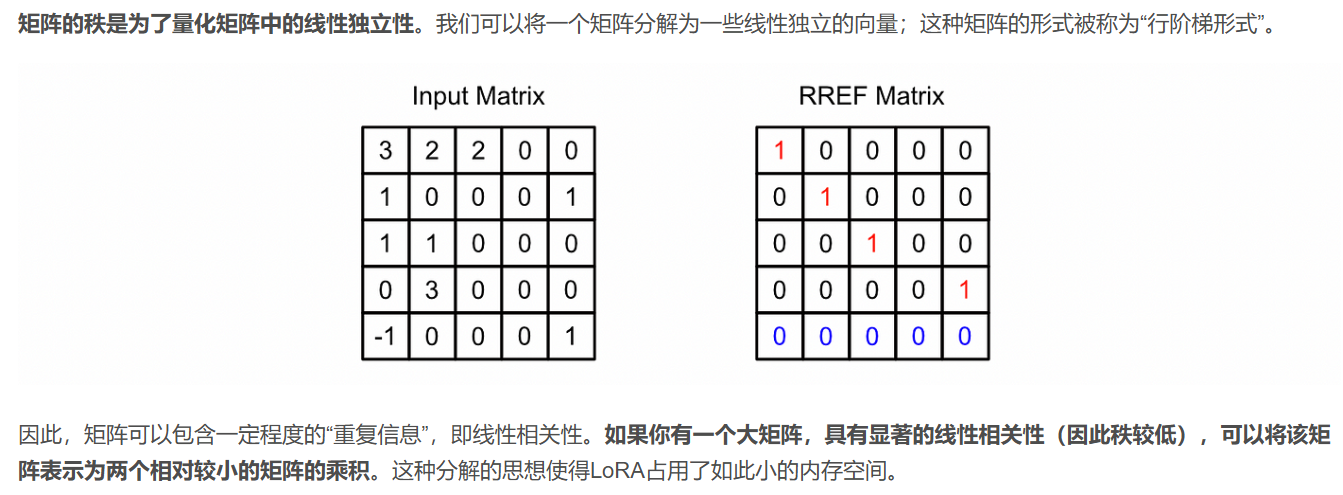
- 为什么要谈到秩?就是因为你
Lora微调的过程
- 首先冻结模型参数。使用这些参数进行推理,但不会更新它们。然后创建两个矩阵,当它们相乘时,它们的大小将与我们正在微调的模型的权重矩阵的大小相同。在一个大型模型中,有多个权重矩阵,为每个权重矩阵创建一个这样的配对。
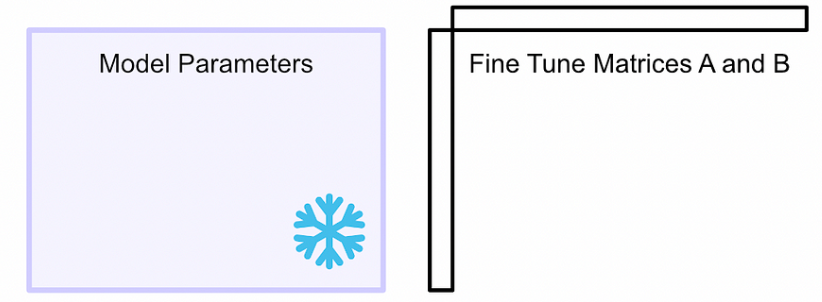
- LoRA将这些矩阵称为矩阵“A”和“B”。这些矩阵一起代表了LoRA微调过程中的可学习参数。
- 将输入通过冻结的权重和变化矩阵传递。
- 根据两个输出的组合计算损失,然后根据损失更新矩阵A和B。
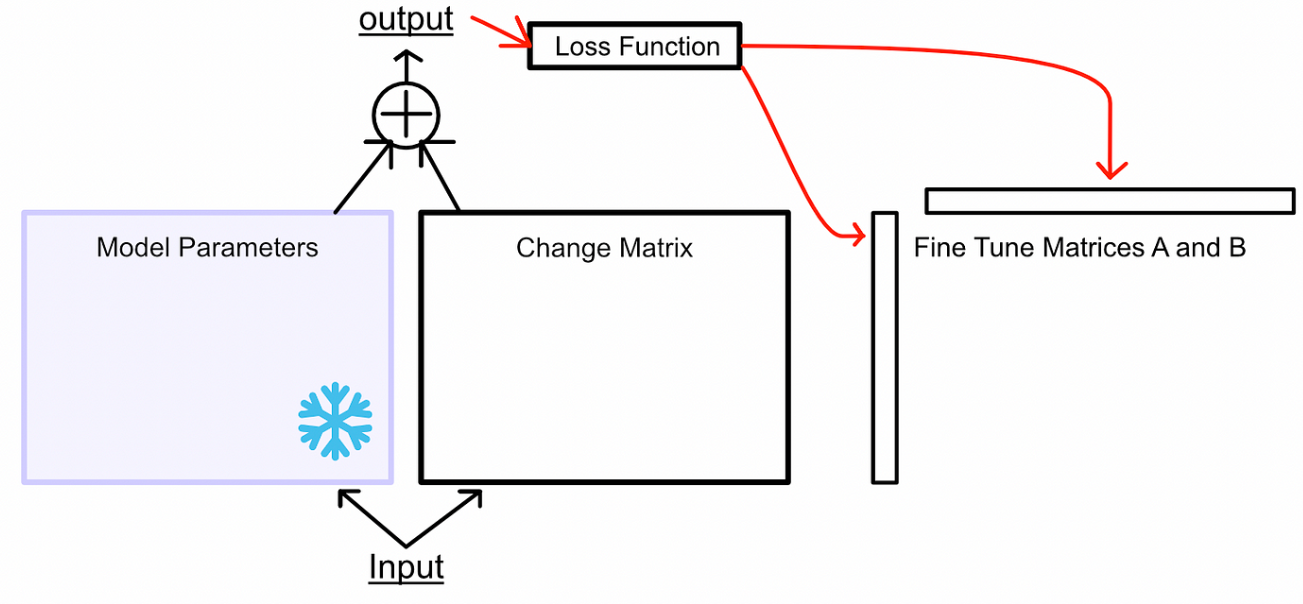
这些变化矩阵是即时计算的,从未被存储,这就是为什么LoRA的内存占用如此小的原因。实际上,在训练期间只存储模型参数、矩阵A和B以及A和B的梯度。
。
当我们最终想要使用这个微调模型进行推断时,我们只需计算变化矩阵,并将变化添加到权重中。这意味着LoRA不会改变模型的推断时间

Lora在Transformer的应用
在大模型中(如BERT、GPT-3),全参数微调需要对模型的所有参数进行更新,代价非常高,尤其是当模型规模达到数十亿甚至百亿参数时。
例如
- 通常,在Transformer的多头自注意力层中,密集网络(用于构建Q、K和V)的深度只有1。也就是说,只有一个输入层和一个由权重连接的输出层。
-
这些浅层密集网络是Transformer中大部分可学习参数,非常非常大。可能有超过100,000个输入神经元连接到100,000个输出神经元,这意味着描述其中一个网络的单个权重矩阵可能有10B个参数。因此,尽管这些网络的深度只有1,但它们非常宽,因此描述它们的权重矩阵非常大。
LoRA 认为:
神经网络中某些层的权重矩阵(如自注意力中的
,
,
,
)在特定任务微调时,其更新矩阵是低秩的。
因此,LoRA不直接更新原始大权重矩阵 W,而是将权重的变化用一个低秩矩阵来表达,从而减少需要训练的参数数量。
Lora Rank
LoRA有一个超参数,称为Rank,它描述了用于构建之前讨论的变化矩阵的深度。较高的值意味着更大的和矩阵,这意味着它们可以在变化矩阵中编码更多的线性独立信息。(联想矩阵的秩)
“r"参数可以被视为"信息瓶颈”。较小的r值意味着A和B可以用更小的内存占用编码较少的信息。较大的r值意味着A和B可以编码更多的信息,但内存占用更大。(100张1块钱,就能够表达一张100块钱,那你给我更多我钱我也愿意啊,能让我住豪宅开跑车我也愿意啊(doge))。
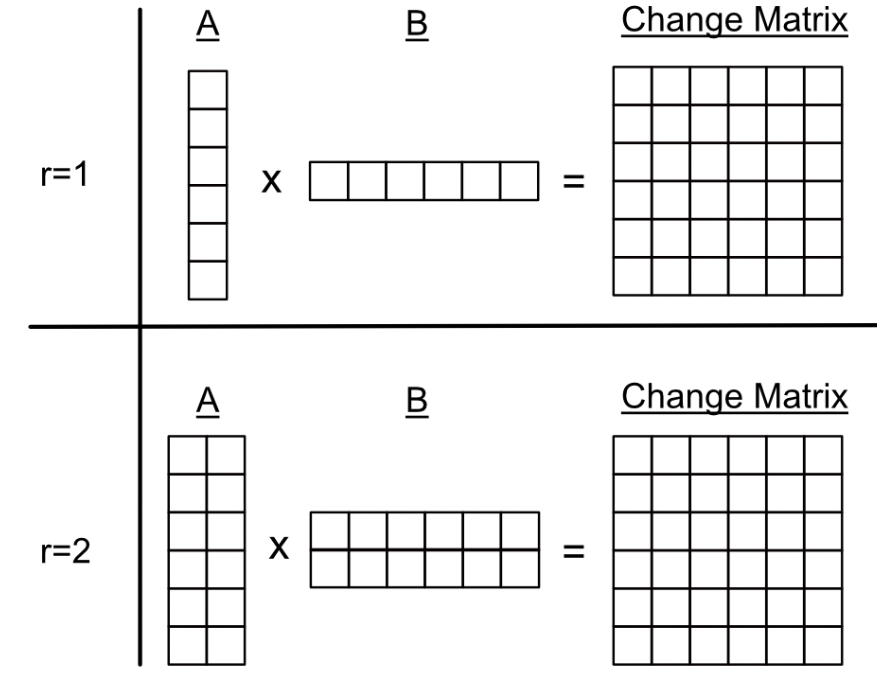
一个具有r值等于1和2的LoRA的概念图。在这两个例子中,分解的A和B矩阵导致相同大小的变化矩阵,但是r=2能够将更多线性独立的信息编码到变化矩阵中,因为A和B矩阵中包含更多信息。
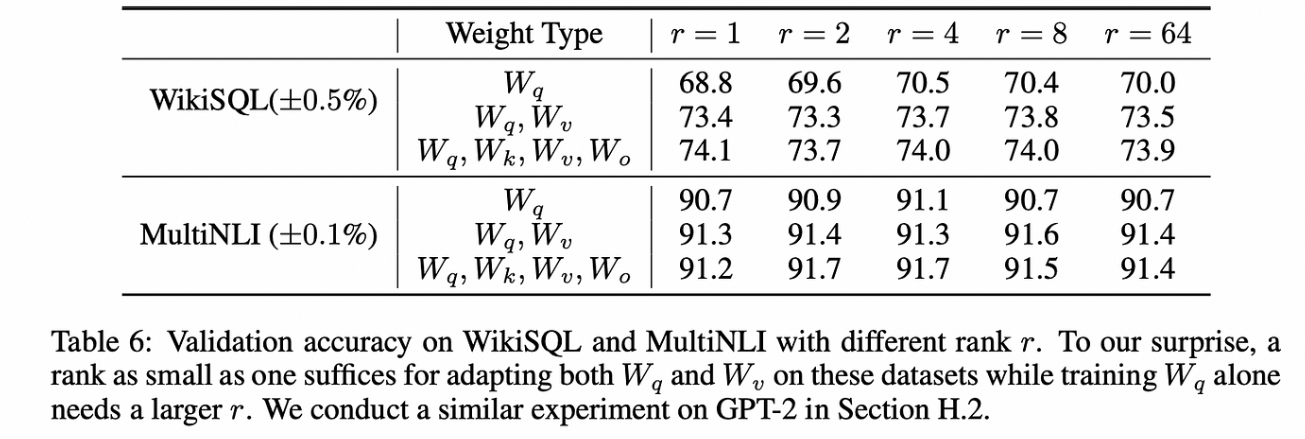
事实证明,LoRA论文所做的核心假设,即模型参数的变化具有低隐式秩(即你用较少独立的行(列)来表示一个完整的矩阵是可行的),是一个相当强的假设。微软(LoRA的出版商)的人员尝试了一些值,并发现即使是秩为一的矩阵也表现出色。
LoRA论文中建议:当数据与预训练中使用的数据相似时,较低的r值可能就足够了。当在非常新的任务上进行微调时,可能需要对模型进行重大的逻辑更改,这时可能需要较高的r值。(遇到新的问题,需要更多信息来辅助判断)
图源:【大模型微调】LoRA — 其实大模型微调也没那么难!_lora微调-CSDN博客
Prefix-Tuning
P-Tuning
Lora Tuning 是针对 encoding部分的微调,而在P-tuning中是针对embedding的微调。
什么是P-tuning?
P-Tuning,它是一种微调大语言模型(Large Language Model, LLM)的方法。与传统的全参数微调(Fine-tuning)不同,P-Tuning 只在模型输入层或中间层插入可学习的“Prompt Embeddings”(也称 Prompt Tokens/Prefix 等),从而极大减少微调参数量。其核心思想可以归纳为:
- 冻结(freeze)大部分或全部原始模型参数
- 引入少量可训练的参数(Prompt Embeddings)
- 通过梯度反向传播仅更新这部分可训练参数
即通过学习连续的、可训练的“软提示”(soft prompts)来引导预训练模型完成下游任务,而不是像传统微调那样直接修改或微调模型的全部参数。模型在训练过程中会将这些 Prompt Embeddings 拼接到原输入或模型内部隐藏层的输入里,从而让预训练模型更好地针对任务进行表征/生成。因为只训练这部分 Prompt Embeddings,而模型的主体参数并未改变,所以对硬件资源和训练数据需求更小,微调速度也更快。
两阶段对比,Prompt Tuning v.s. P Tuning
第一阶段,Prompt Tuning
冻结主模型全部参数,在训练数据前加入一小段Prompt,只训练Prompt的表示层,即一个Embedding模块。论文实验表明,只要模型规模够大,简单加入 Prompt tokens 进行微调,就能取得很好的效果。
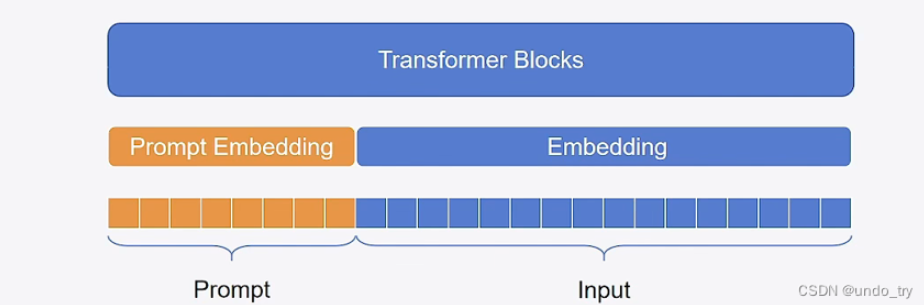
第二阶段,在Prompt Tuning的基础上,对 Prompt部分 进行进一步的encoding计算,加速收敛。具体来说,PEFT中支持两种编码方式,一种是LSTM,一种是MLP。与Prompt-Tuning不同的是,Prompt的形式只有Soft Prompt。
硬提示(Hard Prompt):离散的、人工可读的; 软提示(Soft Prompt):连续的、可训练的。
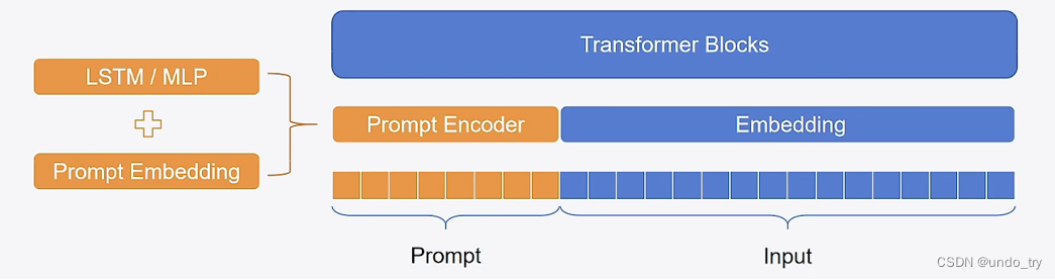
总结:P Tuning将Prompt转换为可以学习的Embedding层,并用MLP+LSTM的方式来对Prompt Embedding进行一层处理。
- 相比Prefix Tuning,P Tuning仅限于输入层,没有在每一层都加virtual token ◦
- 经过预训练的LM的词嵌入已经变得高度离散,如果随机初始化virtual token,容易优化到局部最优值,而这些virtual token理论是应该有相关关联的。因此,作者通过实验发现用一个prompt encoder来编码会收敛更快,效果更好。即用一个LSTM+MLP去编码这些virtual token以后,再输入到模型。
- 作者在实验中发现,相同参数规模,如果进行全参数微调,Bert的在NLU(自然语言理解)任务上的效果,超过GPT很多;但是在P-Tuning下,GPT可以取得超越Bert的效果。
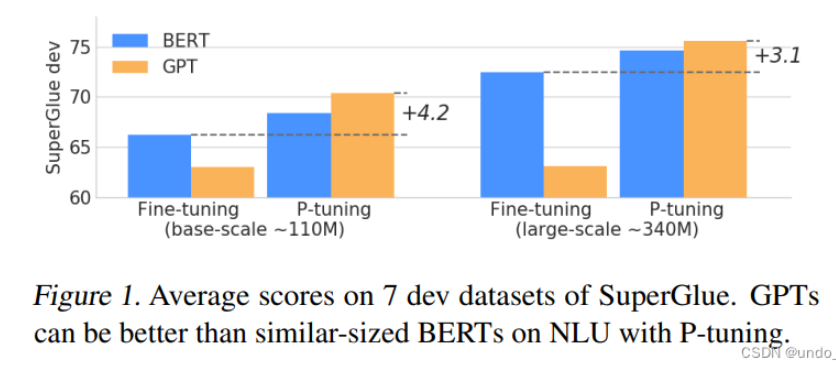
图源:参数高效微调PEFT(二)快速入门P-Tuning、P-Tuning V2-CSDN博客
P-tuning v.s. Prompt Engineering
Prompt Engineering 是人工提示工程,属于离散提示。它的做法是通过精心设计的自然语言提示(例如“请完成这个句子:...”)可以诱导模型完成任务,而无需微调。但这需要手动设计和筛选提示,效率低下且效果不稳定。
而P-tuning 则在这两者之间找到了一个平衡点。它的核心思想是:
- 不再使用离散的、人工设计的自然语言提示。
- 引入一小段可训练的连续向量(soft prompt)作为模型输入的前缀或嵌入,而不是直接修改模型的内部参数。
- 在训练过程中,只优化这部分软提示的参数,而冻结预训练模型的绝大部分参数。
P-tuning与Prompt Engineering的区别,关键就在你提示的语言是什么类型的,Prompt Engineering所使用的提示语言是人类语言,而P-tuning所使用的提示语言是我们给预训练模型“悄悄地”加上的一段“指令”,这段指令不是用人类语言写成的,而是模型自己“学出来”的最有效的连续向量,能够最大化地引导模型在特定任务上给出正确的输出。
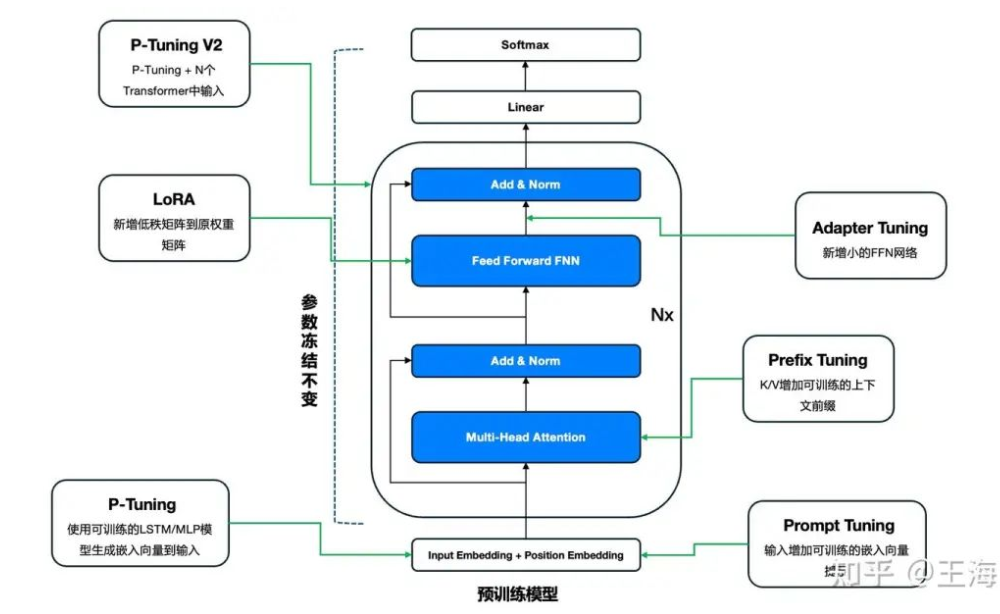
一张图总结各种Tuning