官方:Ultralytics YOLO11 -Ultralytics YOLO 文档
1、安装 Anaconda
Anaconda安装与使用_anaconda安装好了怎么用python-CSDN博客
2、 创建虚拟环境
安装好 Anaconda 后,打开 Anaconda 控制台
创建环境
conda create -n yolov11 python=3.10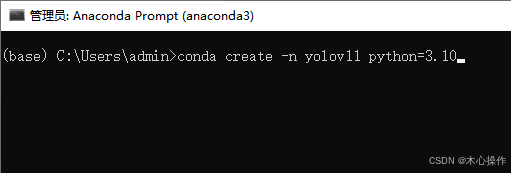
创建完后,进入环境
conda activate yolov11 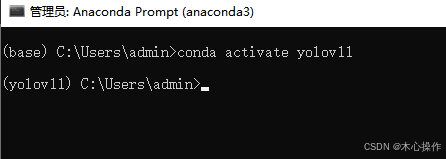
安装依赖
pip install torch==2.0.0+cu118 torchvision==0.15.1+cu118 --extra-index-url https://download.pytorch.org/whl/cu118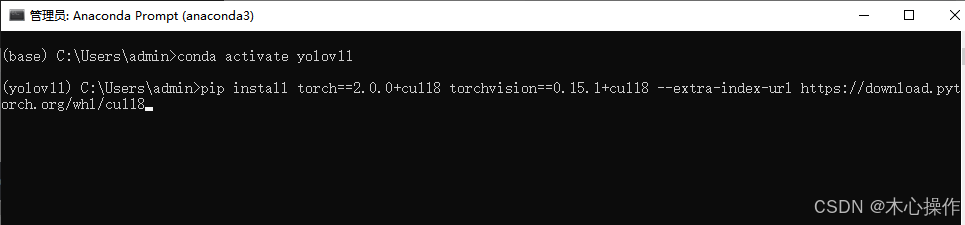
安装 ultralytics 库
pip install ultralytics安装低版本 numpy
pip install numpy==1.26.43、下载 YOLOv11 源码
GitHub - ultralytics/ultralytics at v8.3.143
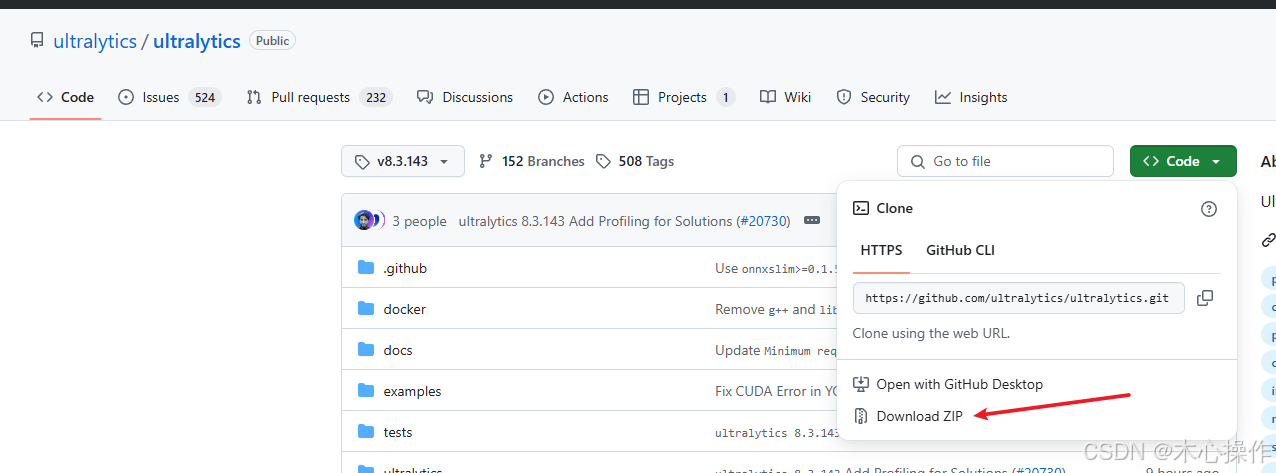
下载后解压,用 PyCharm 打开源码,选择前面创建的环境
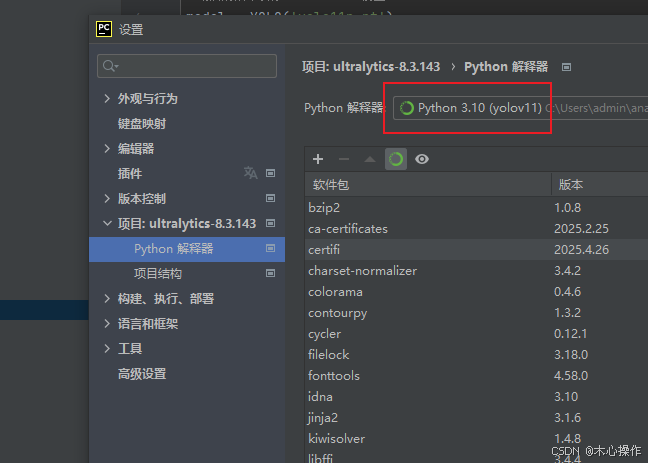
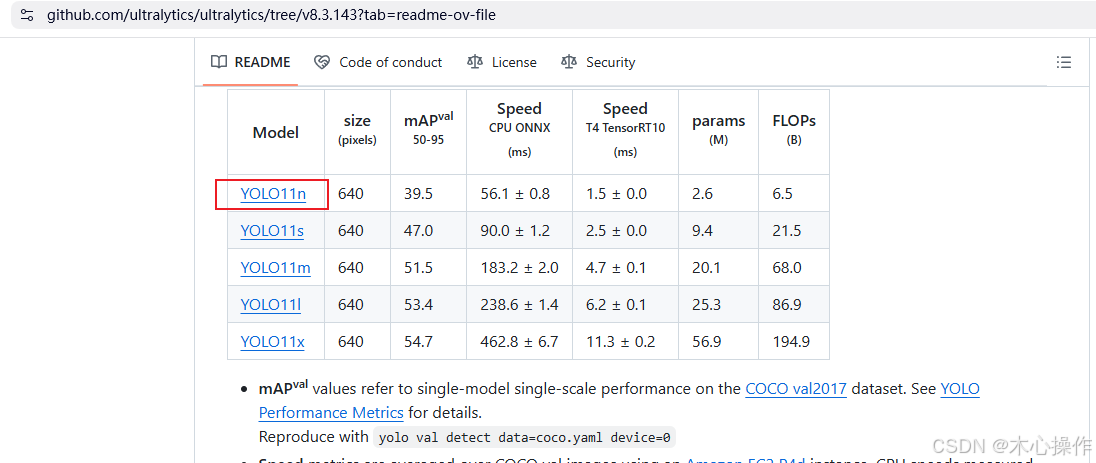
下载 YOLO11 模型,放到项目根目录
在项目根目录创建一个 test.py 文件;cat.png 是一张猫咪图片(可以在百度随便搜一张)下载后放到一起
from ultralytics import YOLO
# 加载预训练的 YOLOv11n 模型
model = YOLO('yolo11n.pt')
source = 'cat.png'
results = model.predict(source)
for i, r in enumerate(results):
r.show()
运行 test.py
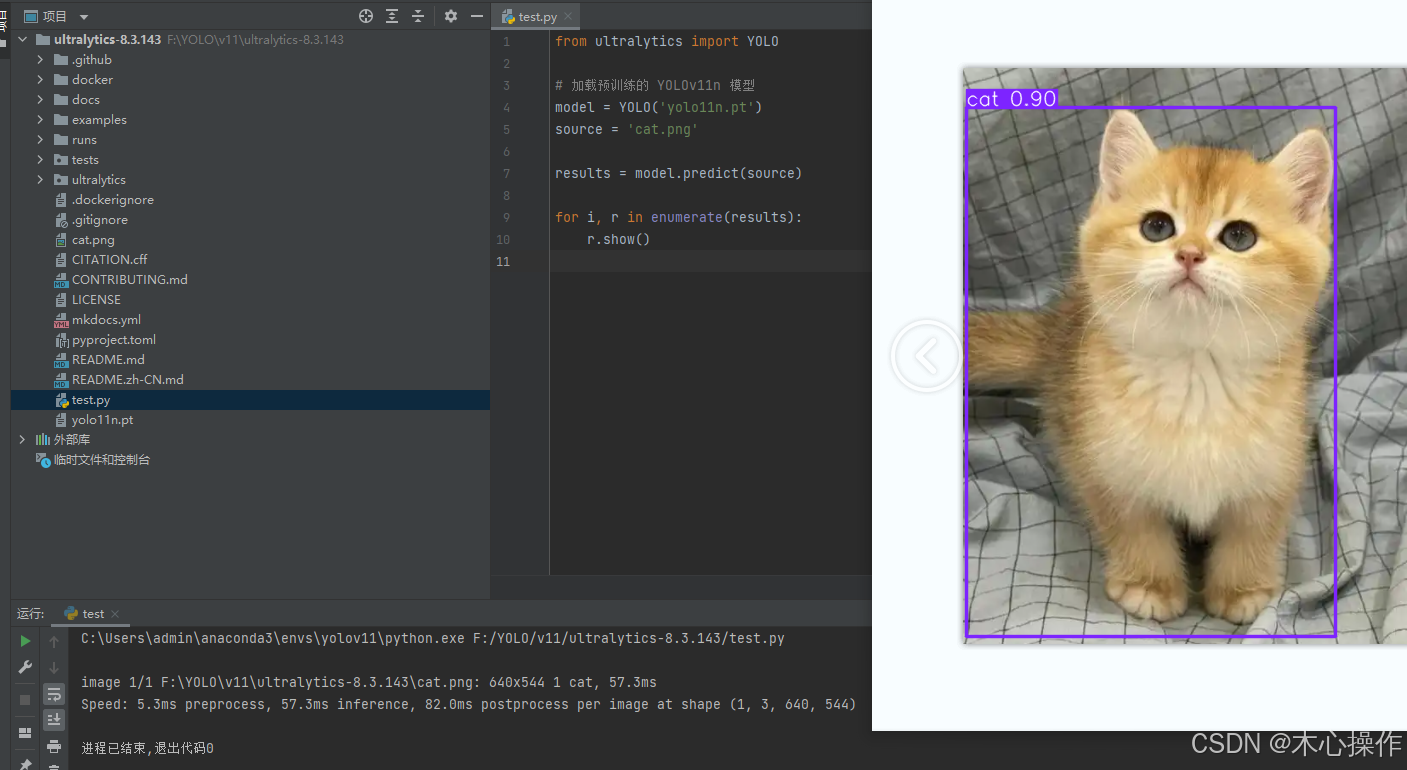
运行成功,代表环境也没问题
3.1、运行遇到问题
如运行中遇到问题,可参考此博主的文章走一遍:
目标检测:YOLOv11(Ultralytics)环境配置,适合0基础纯小白,超详细-CSDN博客
4、训练自己的模型
4.1、安装 labelimg 工具
新建一个虚拟环境,命名 labelimg,python版本3.8
conda create -n labelimg python=3.8 
进入环境
conda activate labelimg 
安装 labelimg 包
pip install labelimg
安装好后启动 labelimg
labelimg
启动后会弹出一个窗口
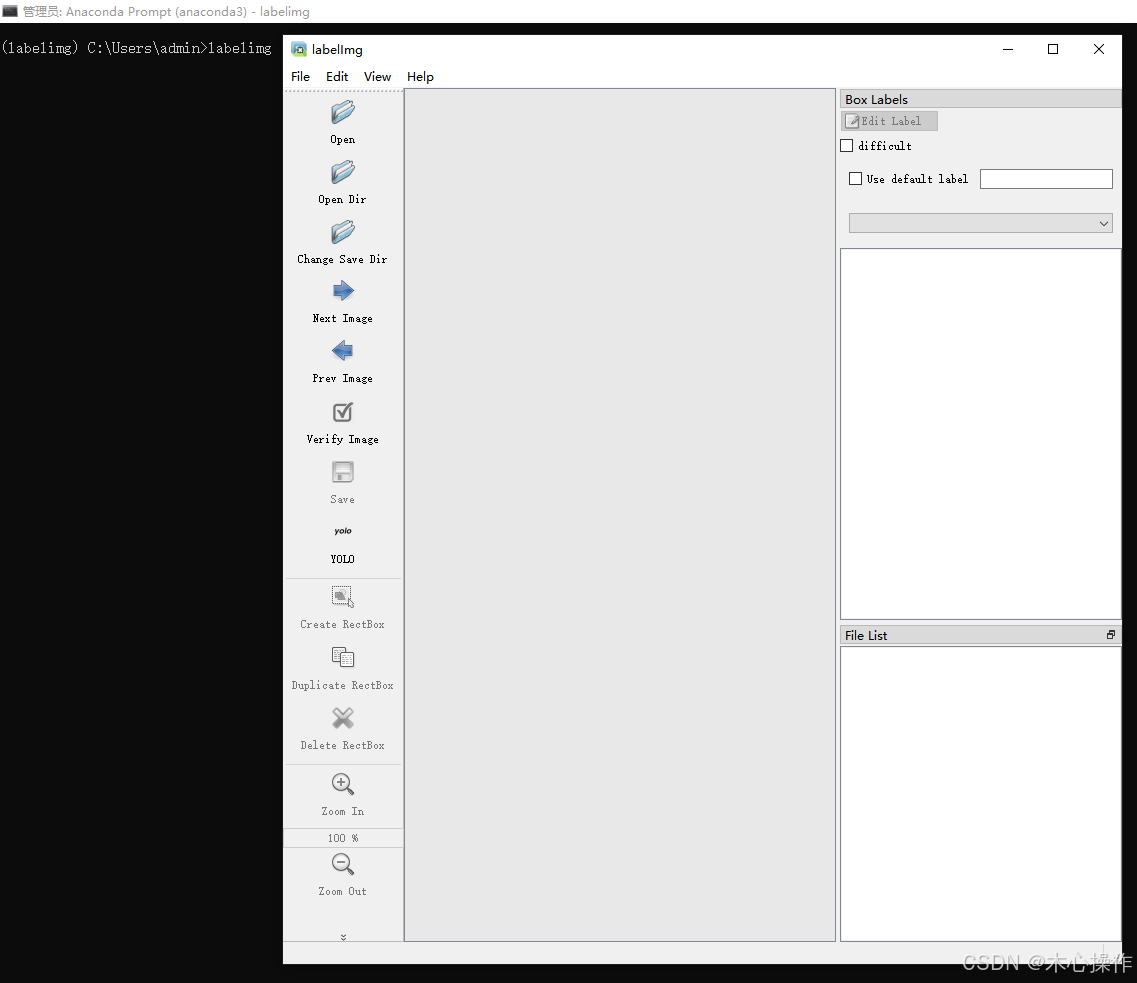
4.2、准备数据
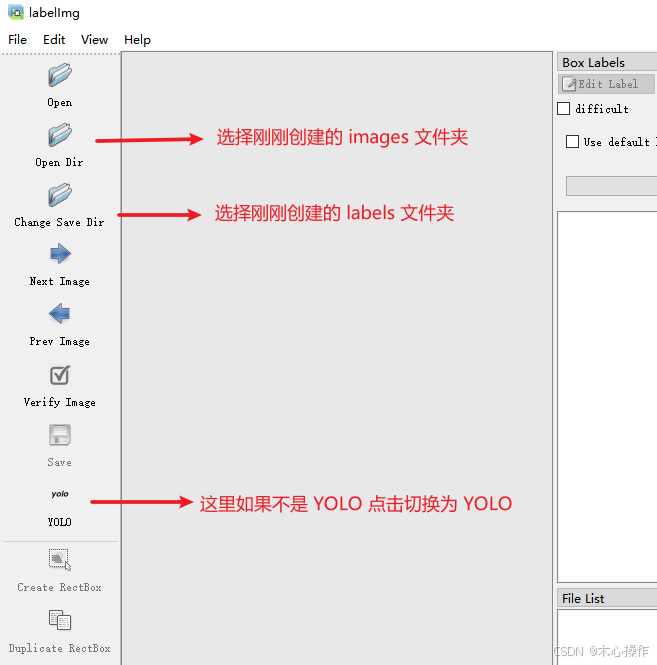
在根目录创建一个 data 文件夹,里面分别创建 images、labels
在 images 里面放入要训练的图片
4.3、标注数据
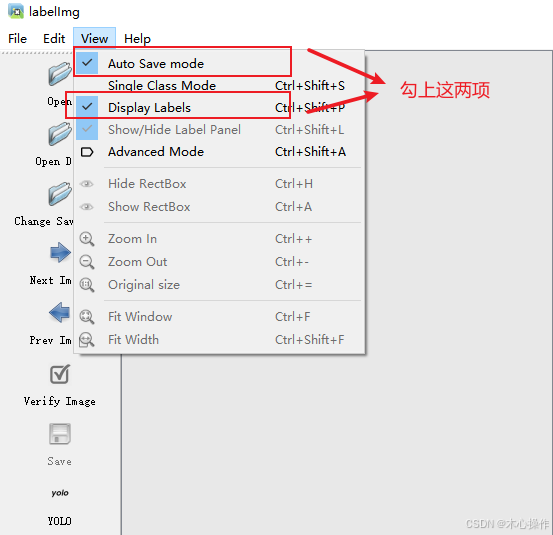
设置 labelimg
常用快捷键
W:调出标注十字架
A:切换到上一张图片
D:切换到下一张图片
Delete :删除标注框按 W 键开始标注,标注后输入分类名称(输入一次后,后面可以直接选择对应分类即可),按 ok 保存后,按 D 键切换下一张需要标注的图片
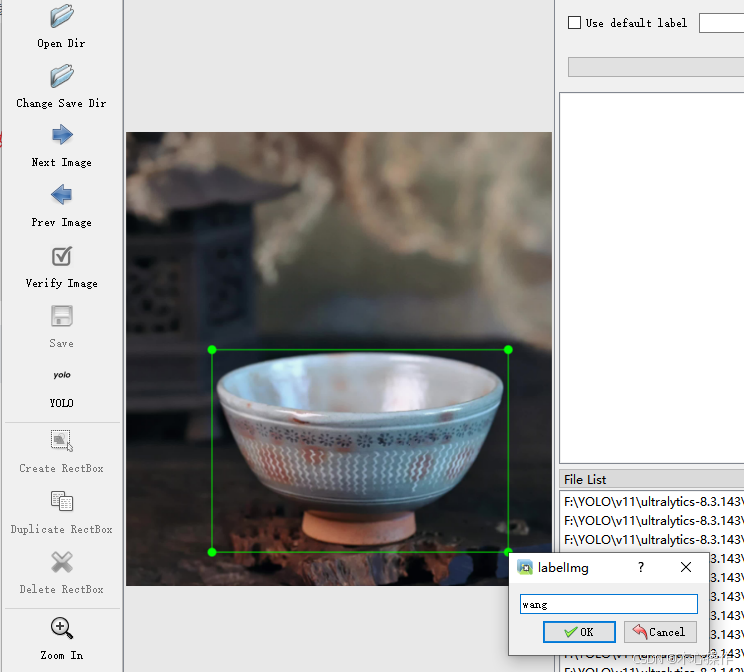
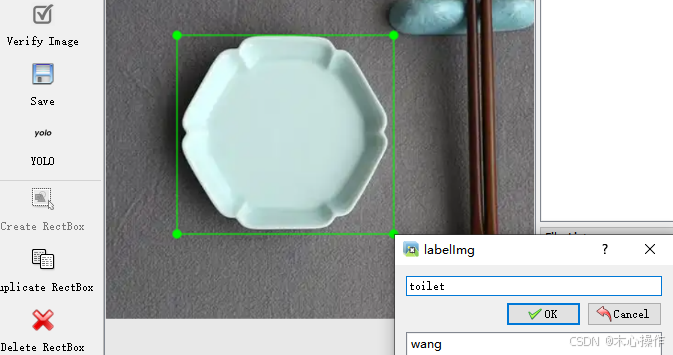
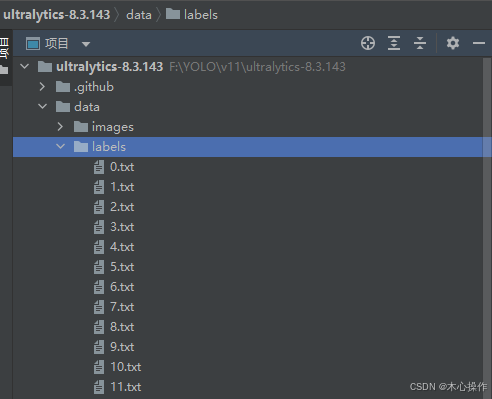
全部标注后,在 labels 文件夹里面可以查看已标注的数据,名称与图片是对应的
4.4、划分数据集
创建一个 data_split.py
data_split.py 代码
import os
import random
import shutil
def split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2):
# 创建训练集和验证集文件夹
train_images_folder = os.path.join(output_folder, 'train', 'images')
train_labels_folder = os.path.join(output_folder, 'train', 'labels')
val_images_folder = os.path.join(output_folder, 'val', 'images')
val_labels_folder = os.path.join(output_folder, 'val', 'labels')
os.makedirs(train_images_folder, exist_ok=True)
os.makedirs(train_labels_folder, exist_ok=True)
os.makedirs(val_images_folder, exist_ok=True)
os.makedirs(val_labels_folder, exist_ok=True)
# 获取所有图像文件列表
images = [f for f in os.listdir(input_image_folder) if f.endswith('.jpg') or f.endswith('.png')]
# 随机打乱图像文件列表
random.shuffle(images)
# 计算验证集的数量
val_size = int(len(images) * test_ratio)
# 划分验证集和训练集
val_images = images[:val_size]
train_images = images[val_size:]
# 复制验证集图像和标签
for image in val_images:
label = os.path.splitext(image)[0] + '.txt'
if os.path.exists(os.path.join(input_label_folder, label)):
shutil.copy(os.path.join(input_image_folder, image), os.path.join(val_images_folder, image))
shutil.copy(os.path.join(input_label_folder, label), os.path.join(val_labels_folder, label))
else:
print(f"Warning: Label file {label} not found for image {image}")
# 复制训练集图像和标签
for image in train_images:
label = os.path.splitext(image)[0] + '.txt'
if os.path.exists(os.path.join(input_label_folder, label)):
shutil.copy(os.path.join(input_image_folder, image), os.path.join(train_images_folder, image))
shutil.copy(os.path.join(input_label_folder, label), os.path.join(train_labels_folder, label))
else:
print(f"Warning: Label file {label} not found for image {image}")
input_image_folder = 'data/images' # 图片路径
input_label_folder = 'data/labels' # 标签路径
output_folder = 'datasets' # 输出目录
split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2)
运行 data_split.py 会生成一个 datasets 目录,里面存放着划分后的数据集
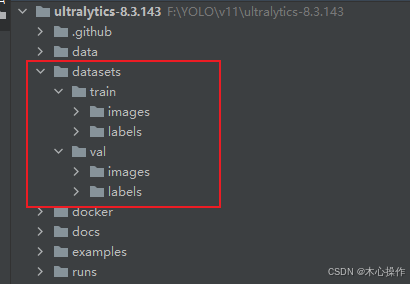
4.5、训练准备
创建一个 data.yaml 文件
data.yaml 内容
train:前面数据划分里面 train 下面的 images 目录
val:前面数据划分里面 val 下面的 images 目录
nc:所有分类数量
names:所有分类名称
train: F:/YOLO/v11/ultralytics-8.3.143/datasets/train/images # train images (relative to 'path') 128 images
val: F:/YOLO/v11/ultralytics-8.3.143/datasets/val/images # val images (relative to 'path') 128 images
nc: 2
# Classes
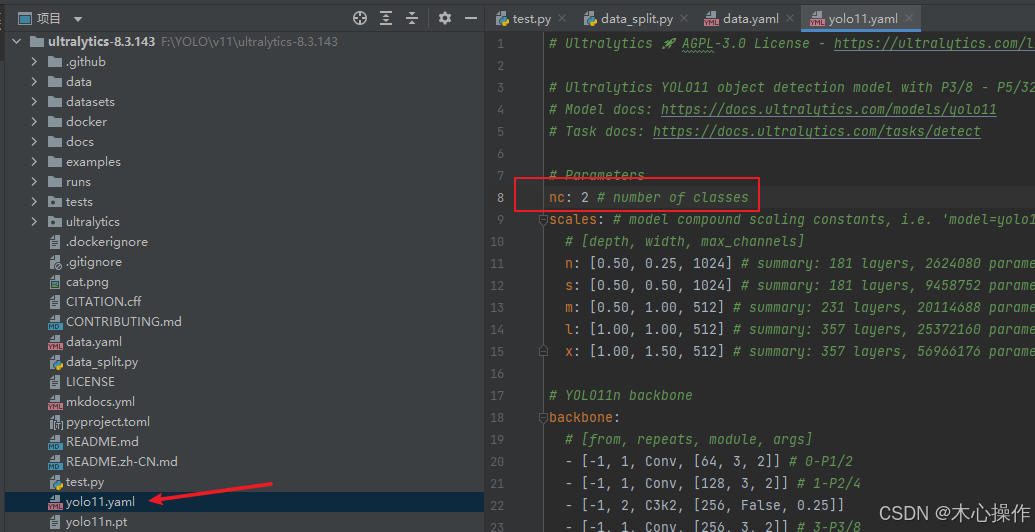
names: [ 'wang', 'toilet' ]找到源码里面的 yolo11.yaml 复制一份到根目录
修改 yolo11.yaml 里面的 nc 数量与前面的分类数量一致
4.6、开始训练
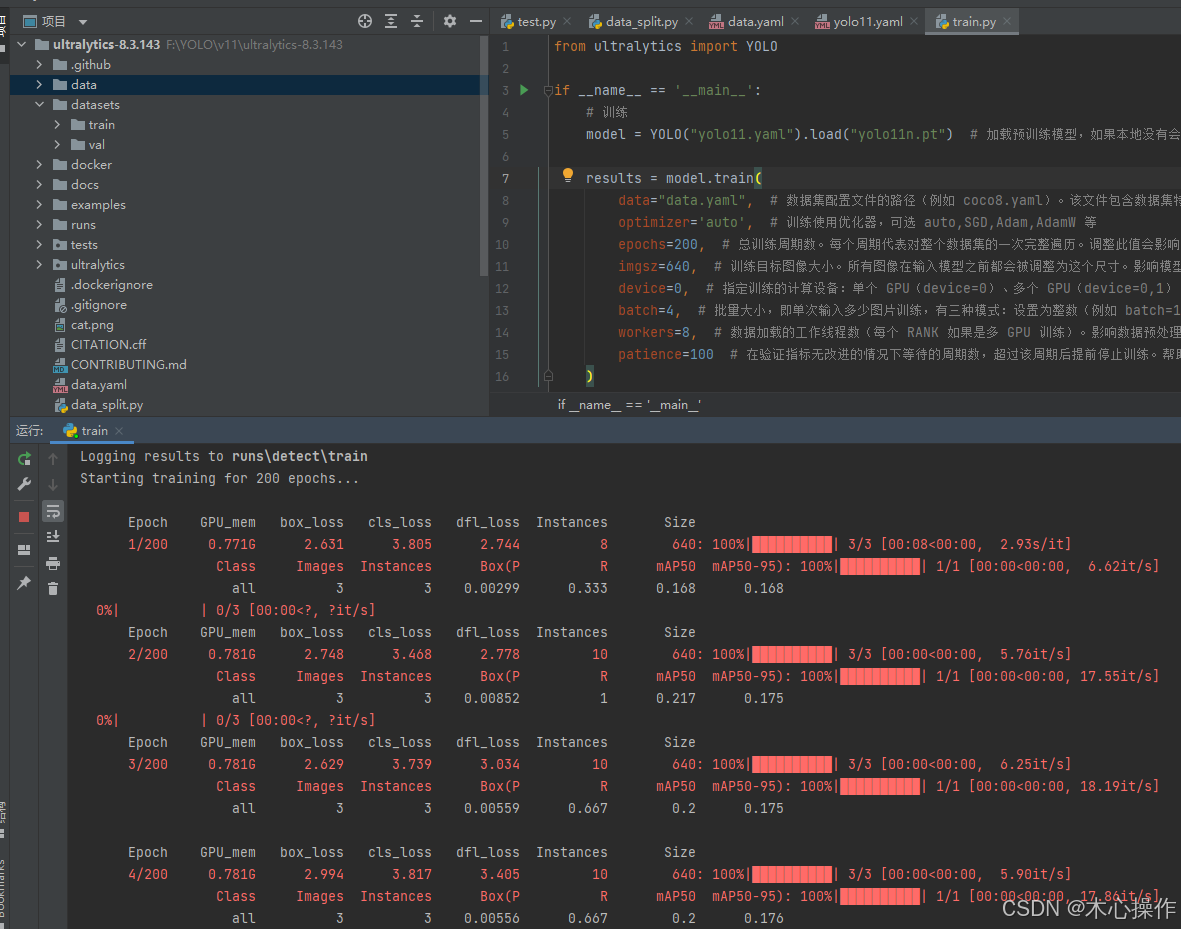
创建一个 train.py
train.py 代码
from ultralytics import YOLO
if __name__ == '__main__':
# 初始训练
model = YOLO("yolo11.yaml").load("yolo11n.pt") # 加载预训练模型,如果本地没有会自动下载
results = model.train(
data="data.yaml", # 数据集配置文件的路径(例如 coco8.yaml)。该文件包含数据集特定的参数,包括训练和验证数据的路径、类名和类数。
optimizer='auto', # 训练使用优化器,可选 auto,SGD,Adam,AdamW 等
epochs=200, # 总训练周期数。每个周期代表对整个数据集的一次完整遍历。调整此值会影响训练时长和模型性能。
imgsz=640, # 训练目标图像大小。所有图像在输入模型之前都会被调整为这个尺寸。影响模型精度和计算复杂度。
device=0, # 指定训练的计算设备:单个 GPU(device=0)、多个 GPU(device=0,1)、CPU(device=cpu),或 Apple Silicon 的 MPS(device=mps)。
batch=4, # 批量大小,即单次输入多少图片训练,有三种模式:设置为整数(例如 batch=16),自动模式为60% GPU内存利用率(batch=-1),或指定利用率的自动模式(batch=0.70)。
workers=8, # 数据加载的工作线程数(每个 RANK 如果是多 GPU 训练)。影响数据预处理和输入模型的速度,尤其在多 GPU 设置中非常有用。
patience=100 # 在验证指标无改进的情况下等待的周期数,超过该周期后提前停止训练。帮助防止过拟合,当性能停滞时停止训练。
)
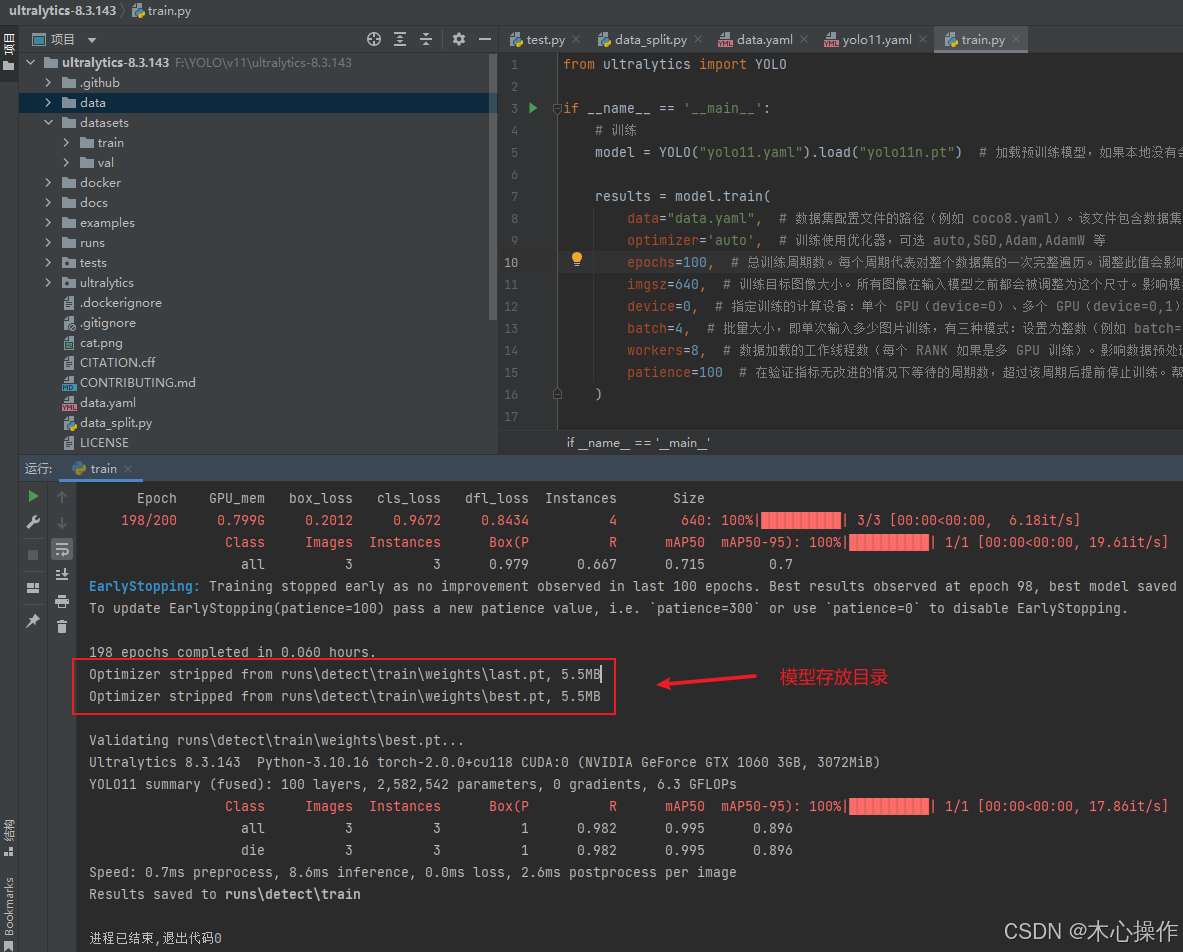
运行 train.py 开始训练
训练完后,可以看到模型所在目录
4.7、使用模型
创建一个 predict.py
predict.py 代码
from ultralytics import YOLO
# 加载前面训练的模型
model = YOLO('runs/detect/train/weights/best.pt')
img_list = ['data/images/1.png']
for img in img_list:
# 运行推理,并附加参数 save:是否保存文件
model.predict(img, save=True, conf=0.5, )
运行 predict.py 开始评估
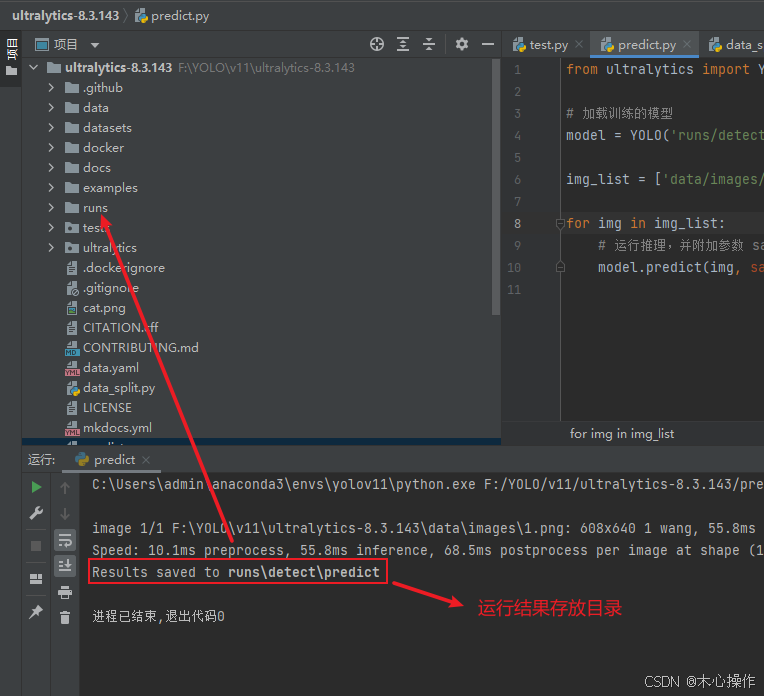
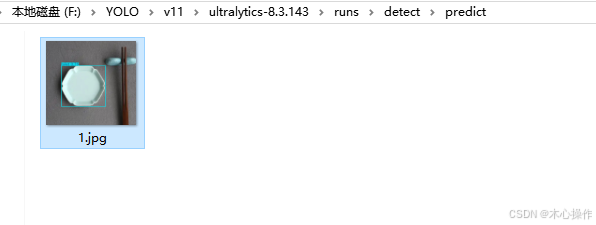
可以进入目录查看结果
参考
yolov8训练自己的数据集(简单最快上手版)-CSDN博客
超详细目标检测:YOLOv11(ultralytics)训练自己的数据集,新手小白也能学会训练模型,手把手教学一看就会-CSDN博客
YOLOv11来了,使用YOLOv11训练自己的数据集和推理(附YOLOv11网络结构图)-CSDN博客
5、训练分割模型
5.1、安装 labelme 工具
pip install labelme
启动 labelme 工具
labelme
如启动中遇到报错,可问 AI 或参考:
lableme 标图 训练 labelme标注技巧_clghxq的技术博客_51CTO博客
5.2、准备数据
在根目录创建一个 data-seg 文件夹,里面分别创建 images、json、labels
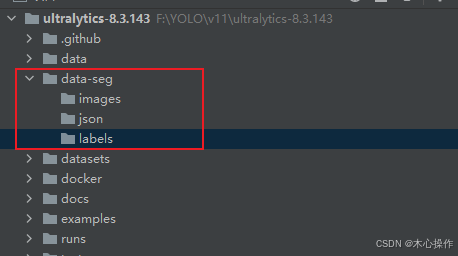
在 images 里面放入要训练的图片
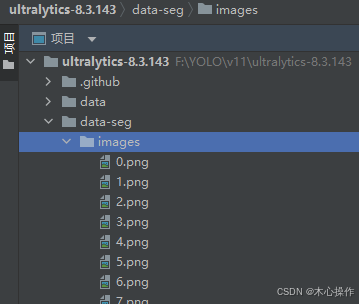
5.3、标注数据
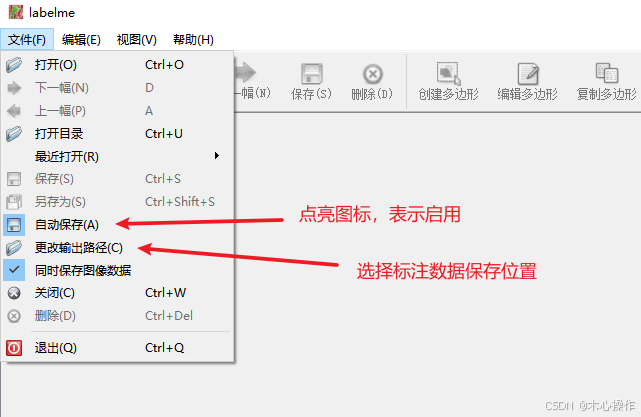
设置 labelme
输出路径选择前面创建的 json 文件夹
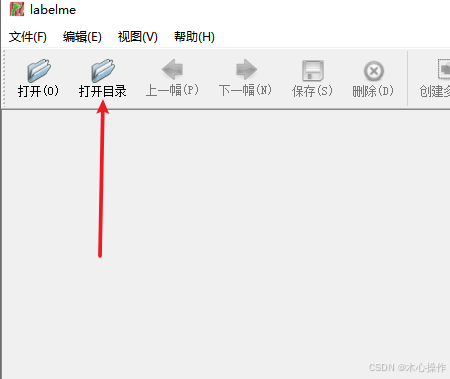
打开目录选择前面创建的 images 文件夹,打开目录后再选一下前面的 输出路径
选择创建多边形,开始标注
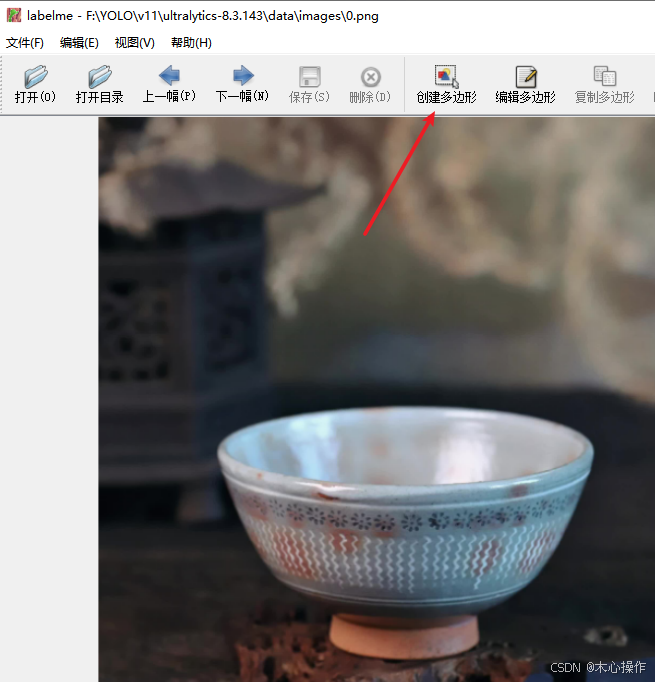
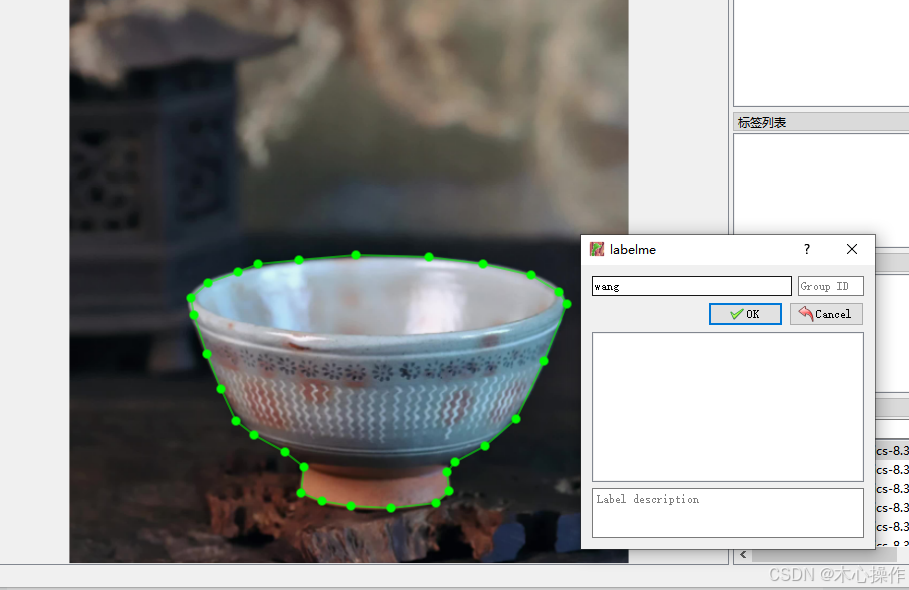
标注完后(首尾相连),点击上面的菜单【下一幅】
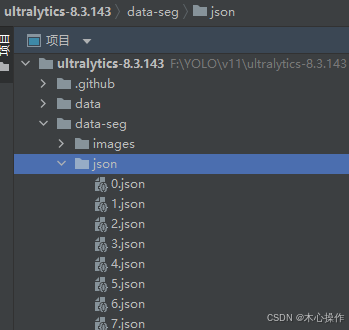
全部标注完后,在 json 目录查看
5.4、数据转换
创建一个 label_format-seg.py;
也可以使用【4.4】步骤的代码,修改目录即可;此处为防止搞混,单独创建
label_format-seg.py 代码
import json
import os
label_to_class_id = {
"wang": 0, # 从0开始
"toilet": 1,
# 其他类别...
}
def convert_labelme_json_to_yolo(json_file, output_dir):
try:
with open(json_file, 'r') as f:
labelme_data = json.load(f)
img_width = labelme_data["imageWidth"]
img_height = labelme_data["imageHeight"]
file_name = os.path.splitext(os.path.basename(json_file))[0]
txt_path = os.path.join(output_dir, f"{file_name}.txt")
with open(txt_path, 'w') as txt_file:
for shape in labelme_data['shapes']:
label = shape['label']
points = shape['points']
if not points:
continue
class_id = label_to_class_id.get(label)
if class_id is None:
print(f"Warning: 跳过未定义标签 '{label}'")
continue
# 检查多边形是否闭合
if points[0] != points[-1]:
points.append(points[0])
normalized = [(x / img_width, y / img_height) for x, y in points]
line = f"{class_id} " + " ".join(f"{x:.6f} {y:.6f}" for x, y in normalized)
txt_file.write(line + "\n")
except Exception as e:
print(f"处理文件 {json_file} 时出错: {str(e)}")
if __name__ == "__main__":
json_dir = "data-seg/json" # labelme标注存放的目录
output_dir = "data-seg/labels" # 输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for json_file in os.listdir(json_dir):
if json_file.endswith(".json"):
json_path = os.path.join(json_dir, json_file)
convert_labelme_json_to_yolo(json_path, output_dir)
运行 label_format-seg.py
5.5、划分数据集
创建一个 data_split-seg.py
data_split-seg.py 代码
import os
import random
import shutil
def split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2):
# 创建训练集和验证集文件夹
train_images_folder = os.path.join(output_folder, 'train', 'images')
train_labels_folder = os.path.join(output_folder, 'train', 'labels')
val_images_folder = os.path.join(output_folder, 'val', 'images')
val_labels_folder = os.path.join(output_folder, 'val', 'labels')
os.makedirs(train_images_folder, exist_ok=True)
os.makedirs(train_labels_folder, exist_ok=True)
os.makedirs(val_images_folder, exist_ok=True)
os.makedirs(val_labels_folder, exist_ok=True)
# 获取所有图像文件列表
images = [f for f in os.listdir(input_image_folder) if f.endswith('.jpg') or f.endswith('.png')]
# 随机打乱图像文件列表
random.shuffle(images)
# 计算验证集的数量
val_size = int(len(images) * test_ratio)
# 划分验证集和训练集
val_images = images[:val_size]
train_images = images[val_size:]
# 复制验证集图像和标签
for image in val_images:
label = os.path.splitext(image)[0] + '.txt'
if os.path.exists(os.path.join(input_label_folder, label)):
shutil.copy(os.path.join(input_image_folder, image), os.path.join(val_images_folder, image))
shutil.copy(os.path.join(input_label_folder, label), os.path.join(val_labels_folder, label))
else:
print(f"Warning: Label file {label} not found for image {image}")
# 复制训练集图像和标签
for image in train_images:
label = os.path.splitext(image)[0] + '.txt'
if os.path.exists(os.path.join(input_label_folder, label)):
shutil.copy(os.path.join(input_image_folder, image), os.path.join(train_images_folder, image))
shutil.copy(os.path.join(input_label_folder, label), os.path.join(train_labels_folder, label))
else:
print(f"Warning: Label file {label} not found for image {image}")
input_image_folder = 'data-seg/images' # 图片路径
input_label_folder = 'data-seg/labels' # 标签路径
output_folder = 'datasets-seg' # 输出目录
split_dataset(input_image_folder, input_label_folder, output_folder, test_ratio=0.2)
运行 data_split-seg.py
5.6、训练准备
创建一个 data-seg.yaml 文件,与【4.5】一样步骤
train: F:/YOLO/v11/ultralytics-8.3.143/datasets-seg/train/images # train images (relative to 'path') 128 images
val: F:/YOLO/v11/ultralytics-8.3.143/datasets-seg/val/images # val images (relative to 'path') 128 images
nc: 2
# Classes
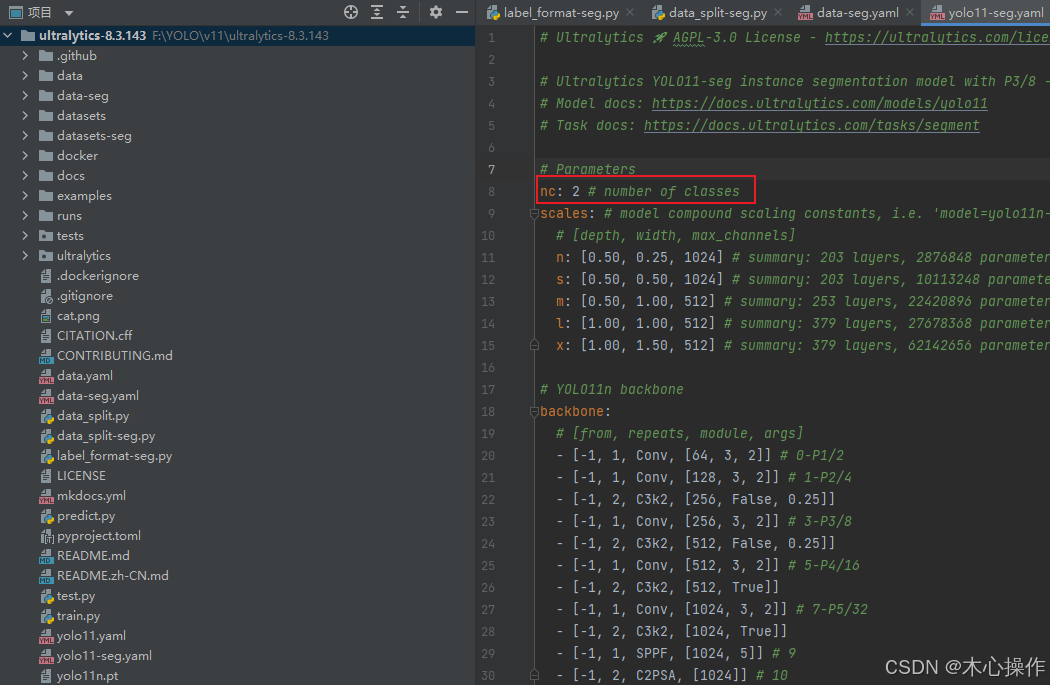
names: [ 'wang', 'toilet' ]找到源码里面的 yolo11-seg.yaml 复制一份到根目录
修改 yolo11-seg.yaml 里面的 nc 数量与分类数量一致
5.7、开始训练
下载 YOLO11n-seg 放到根目录
这个下载地址是 github (偶尔需要代理才能访问)
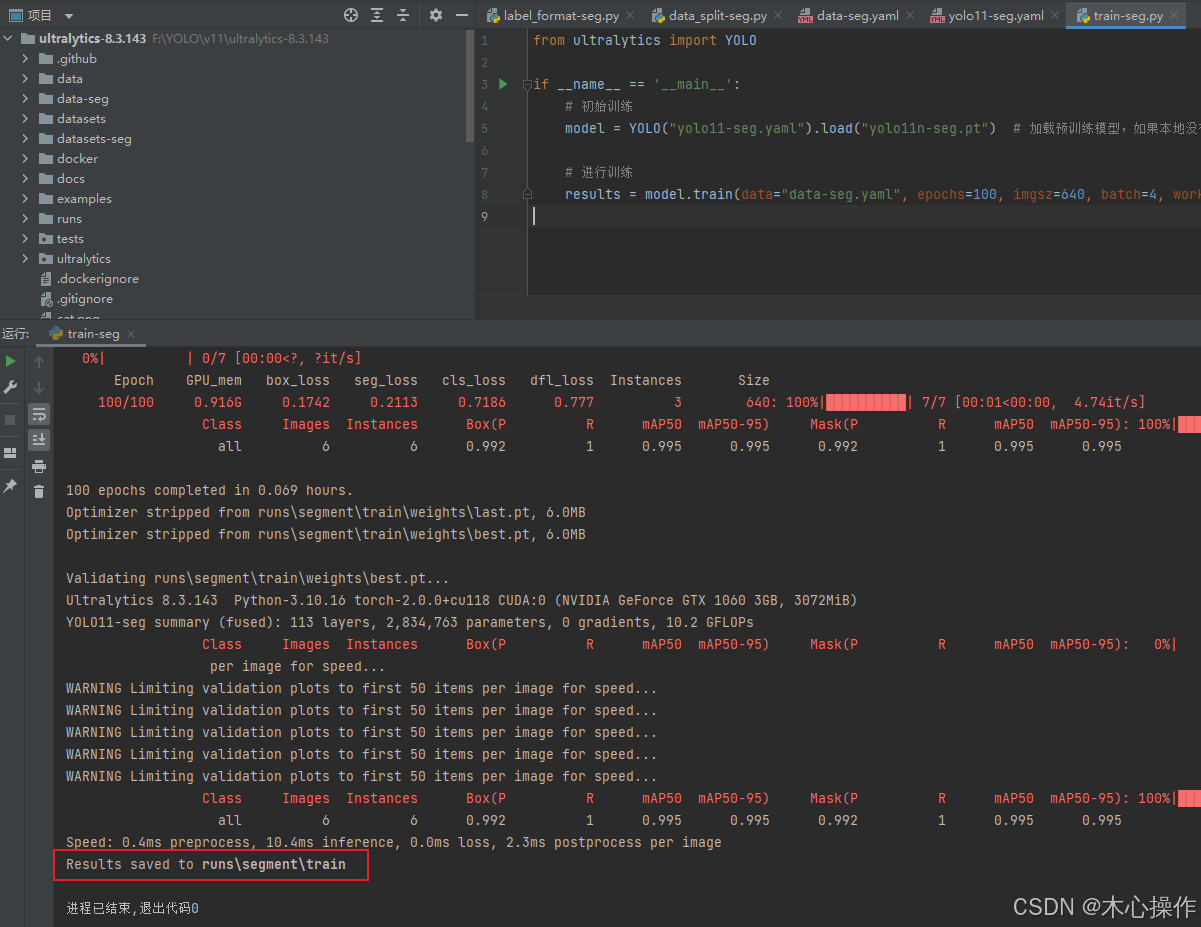
创建一个 train-seg.py
from ultralytics import YOLO
if __name__ == '__main__':
# 初始训练
model = YOLO("yolo11-seg.yaml").load("yolo11n-seg.pt") # 加载预训练模型,如果本地没有会自动下载
# 进行训练
results = model.train(data="data-seg.yaml", epochs=100, imgsz=640, batch=4, workers=8)
训练完成后模型所在位置
5.8、使用模型
创建 predict-seg.py
from ultralytics import YOLO
# 加载训练的模型
model = YOLO('runs/segment/train/weights/best.pt')
img_list = ['data/images/1.png']
for img in img_list:
# 运行推理,并附加参数 save:是否保存文件 retina_masks:返回高分辨率分割掩码
model.predict(img, save=True, conf=0.5, retina_masks=True)
评估运行结果

predict-seg-info.py 获取识别信息方法
from ultralytics import YOLO
import numpy as np
import cv2
# 加载训练的模型
model = YOLO('runs/segment/train/weights/best.pt')
results = model.predict(source="data/images/1.png", retina_masks=True)
for result in results:
if not hasattr(result, 'masks') or result.masks is None:
continue
img = result.orig_img.copy()
orig_h, orig_w = result.orig_shape
print(f'宽:{orig_w},高:{orig_h}')
masks = result.masks
boxes = result.boxes
for index, (mask, box) in enumerate(zip(masks, boxes)):
# 获取检测框坐标
x1, y1, x2, y2 = map(int, box.xyxy[0].cpu().numpy())
print(f"目标 {index + 1} 边框坐标: ({x1}, {y1}) ({x2}, {y2})")
width = x2 - x1
height = y2 - y1
# 计算实例中心点
center_x = int((x1 + x2) / 2)
center_y = int((y1 + y2) / 2)
# 绘制边界框和中心点
cv2.rectangle(img, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
cv2.circle(img, (center_x, center_y), 5, (0, 0, 255), -1)
# 显示宽高和中心点信息
info_text = f"W:{width:.1f} H:{height:.1f} Center:({center_x},{center_y})"
cv2.putText(img, info_text, (int(x1), int(y1) - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)
# 绘制中心点到边界框的线
cv2.line(img, (x1 + 5, center_y), (center_x - 10, center_y), (255, 0, 0), 2)
cv2.line(img, (x2 - 5, center_y), (center_x + 10, center_y), (255, 0, 0), 2)
# 绘制掩膜轮廓
mask_xy = mask.xy[0]
print(f"目标 {index + 1} 轮廓点数: {len(mask_xy)}") # 每个目标的轮廓点数量
print(f'目标 {index + 1} 轮廓面积:', cv2.contourArea(mask_xy)) # 计算轮廓面积
contours = [np.array(mask_xy, dtype=np.int32)] # 转换为int32类型
img = cv2.drawContours(img, contours, -1, (0, 255, 0), 2) # 绘制轮廓
# 绘制掩膜区域
mask_data = mask.data.cpu().numpy()
mask_data = (mask_data > 0.5).astype(np.uint8)
mask_resized = cv2.resize(mask_data[0], (orig_w, orig_h), interpolation=cv2.INTER_NEAREST) # 调整掩膜尺寸
new_img = img.copy()
y_coords, x_coords = np.where(mask_resized == 1)
print(f'掩膜点数:', len(y_coords))
for x, y in zip(x_coords, y_coords):
cv2.circle(new_img, (x, y), 1, (255, 0, 0), -1)
alpha = 0.6
cv2.addWeighted(img, alpha, new_img, 1 - alpha, 0, img)
cv2.imshow('result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
训练参数
配置 -Ultralytics YOLO 文档
预测参数
配置 -Ultralytics YOLO 文档
labelme使用参考
labelme使用-CSDN博客