微服务架构实战:Eureka服务注册发现与Ribbon负载均衡详解
- 一 . 服务调用出现的问题
- 二 . EureKa 的作用
- 三 . 服务注册
- 3.1 搭建 EureKaServer
- ① 创建项目 , 引入 spring-cloud-starter-netflix-eureka-server 的依赖
- ② 编写启动类 , 添加 @EnableEurekaServer 注解
- ③ 添加 application.yml 文件 , 编写相关配置
- 3.2 服务注册
- ① 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
- ② 在各自的 application.yml 中 , 编写相关配置
- ③ 给各自的微服务起一个名称
- ④ 启动多个 EureKa 客户端
- 四 . 服务发现
- 五 . Ribbon 负载均衡
- 5.1 负载均衡流程
- 5.2 负载均衡原理
- 5.3 负载均衡策略
- ① 代码方式
- ② 配置文件方式
- 5.4 懒加载
- 5.5 小结
在微服务架构中,服务间的稳定调用是核心挑战之一。传统的RestTemplate直接调用存在单点故障、集群路由选择困难、服务健康状态难以感知等问题。如何实现服务的动态发现?如何优雅地管理多实例负载均衡?本文将深入剖析Spring Cloud中的Eureka服务注册中心与Ribbon负载均衡组件,通过实战演示如何解决服务治理的核心痛点,构建高可用的微服务通信体系。
本专栏的内容均来自于 B 站 UP 主黑马程序员的教学视频,感谢你们提供了优质的学习资料,让编程不再难懂。
专栏地址 : https://blog.csdn.net/m0_53117341/category_12835102.html

一 . 服务调用出现的问题
我们当前使用的是 RestTemplate 来让 order-service 调用 user-service , 那这里其实是存在问题的
我们目前的两个服务都是单节点的 , 如果 user-service 挂掉了 , order-service 就会调用失败 , 也会影响到 order-service .
那如果后续搭建 user-service 集群的话 , 我们到底访问哪一台 user-service 机器呢 ?
也就是服务消费者该如何获取服务提供者的地址信息 ?
那如果有多个服务提供者 , 消费者该如何选择呢 ? 是通过负载均衡策略还是其他策略呢 ?
消费者如何得知服务提供者的健康状态呢 ?
那综合这几点考虑 , 我们应该把节点信息都放到一个统一的位置进行管理 , 那这个统一的位置就是 EureKa .
二 . EureKa 的作用
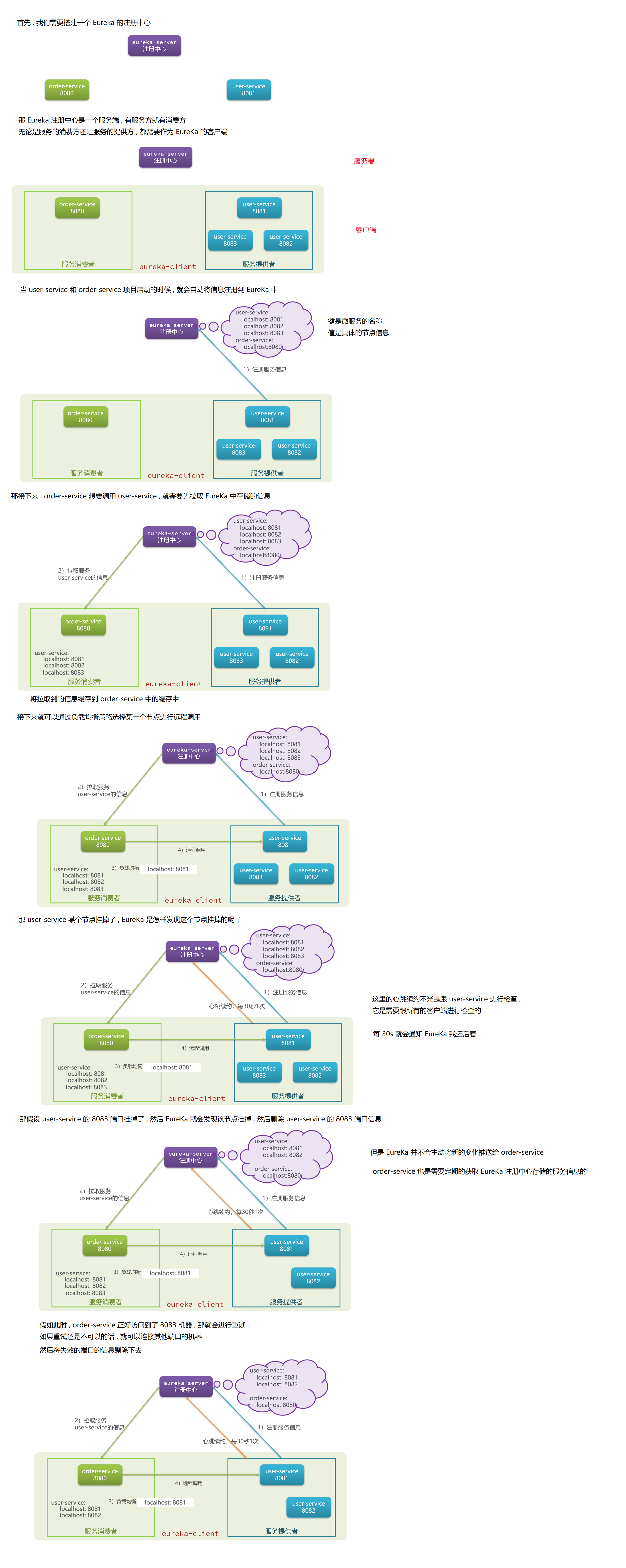
那整体来看 , EureKa 的作用就是服务注册、服务发现、状态监控这三点
那我们重新来看上面的三个问题
服务消费者该如何获取服务提供者的地址信息 ?
- 服务的提供者在启动的时候 , 就需要向 EureKa 注册自己的信息
- EureKa 保存每个服务的信息
- 消费者根据服务名称向 EureKa 拉取提供者的信息
前提 : 必须是已经上传到 EureKa 的服务 , 才能拉取别人的信息
如果有多个服务提供者 , 消费者该如何选择呢 ?
服务消费者利用负载均衡算法 , 从服务列表中挑选一个
消费者如何得知服务提供者的健康状态呢 ?
- 服务提供者会每隔 30s 就向 EureKaServer 发送心跳请求 , 报告健康状态
- EureKa 会更新服务列表信息 , 心跳不正常的就会被剔除掉
- 消费者需要主动拉取最新的消息
小结 :
在 EureKa 架构中 , 微服务角色有两类 :
- EureKaServer : 服务端 , 注册中心
- 记录服务信息
- 进行心跳监控
- EureKaClient : 客户端
- Provider : 服务提供者 (user-service)
- 启动的时候主动注册自己的信息到 EureKaServer
- 每隔 30s 向 EureKaServer 发送心跳
- consumer : 服务消费者 (order-service)
- 启动的时候主动注册自己的信息到 EureKaServer
- 每隔 30s 向 EureKaServer 发送心跳
- 根据服务名称从 EureKaServer 拉取服务列表
- 基于拉取下来的服务列表做负载均衡策略 , 选择一个微服务进行远程调用
- Provider : 服务提供者 (user-service)
三 . 服务注册
基本流程如下 :
- 搭建 EureKaServer
- 将 user-service 和 order-service 都注册到 EureKa 中
- 在 order-service 中完成服务拉取 , 然后通过负载均衡挑选一个服务 , 来去实现远程调用
那我们分别来看
3.1 搭建 EureKaServer
① 创建项目 , 引入 spring-cloud-starter-netflix-eureka-server 的依赖
首先 , 我们创建一个新的模块
那接下来就可以在该模块的 pom.xml 中引入依赖了
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
那这里是不需要指定版本的 , 因为我们在父模块已经指定过了
那这个依赖 , 下载起来还是比较耗时的 , 稍加等待
② 编写启动类 , 添加 @EnableEurekaServer 注解
这个功能需要安装插件 :
[番外 1 : JBLSpringBootAppGen 的安装](https://www.yuque.com/jialebihaitao/study/wduur42qulhwgd48?singleDoc# 《番外 1 : JBLSpringBootAppGen 的安装》)
然后在启动类上添加 @EnableEurekaServer 注解
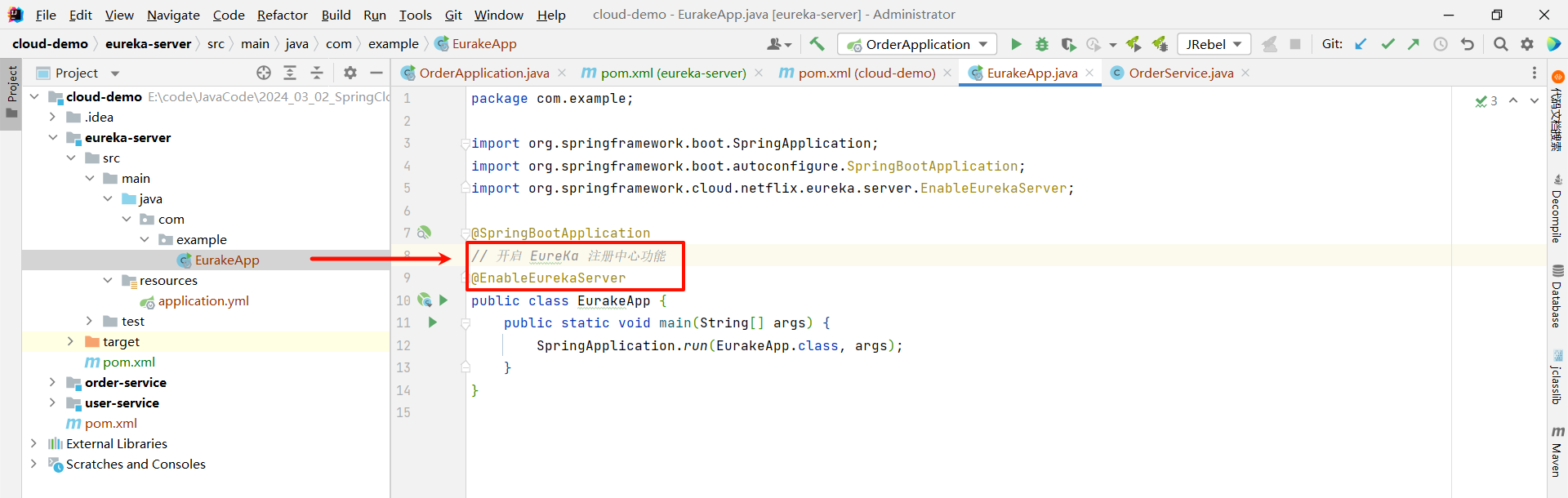
package com.example;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
// 开启 EureKa 注册中心功能
@EnableEurekaServer
public class EurakeApp {
public static void main(String[] args) {
SpringApplication.run(EurakeApp.class, args);
}
}
③ 添加 application.yml 文件 , 编写相关配置
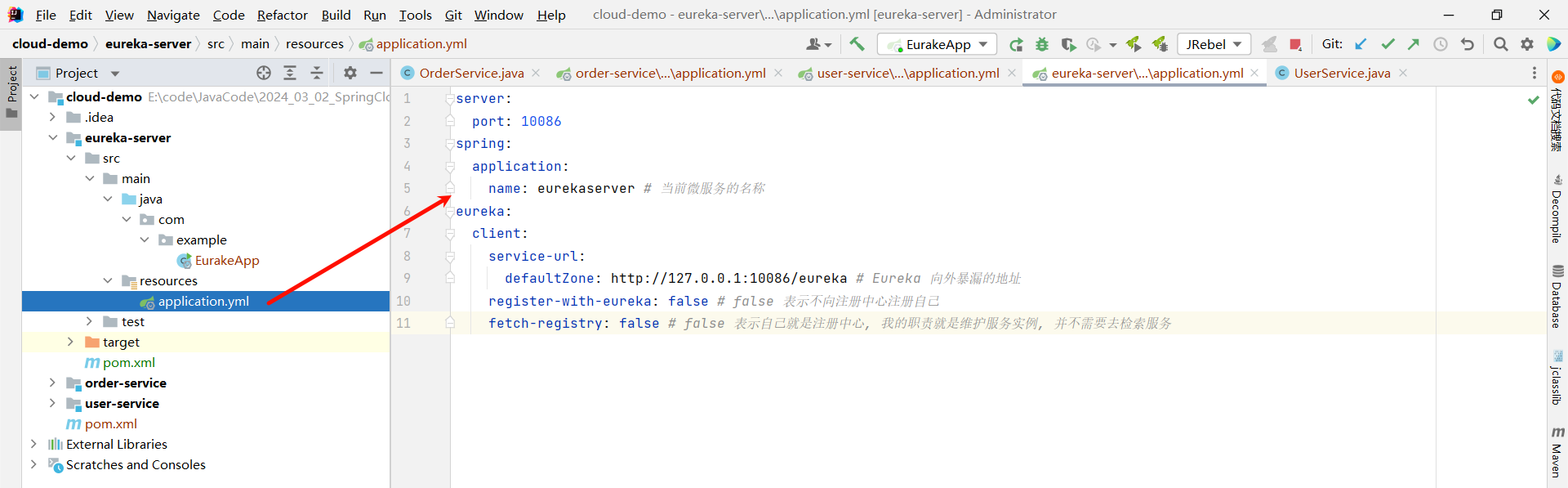
server:
port: 10086
spring:
application:
name: eurekaserver # 当前微服务的名称
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址
register-with-eureka: false # false 表示不向注册中心注册自己
fetch-registry: false # false 表示自己就是注册中心, 我的职责就是维护服务实例, 并不需要去检索服务
那接下来 , 我们可以启动一下 , 看一下能否正常运行
访问 http://127.0.0.1:10086/
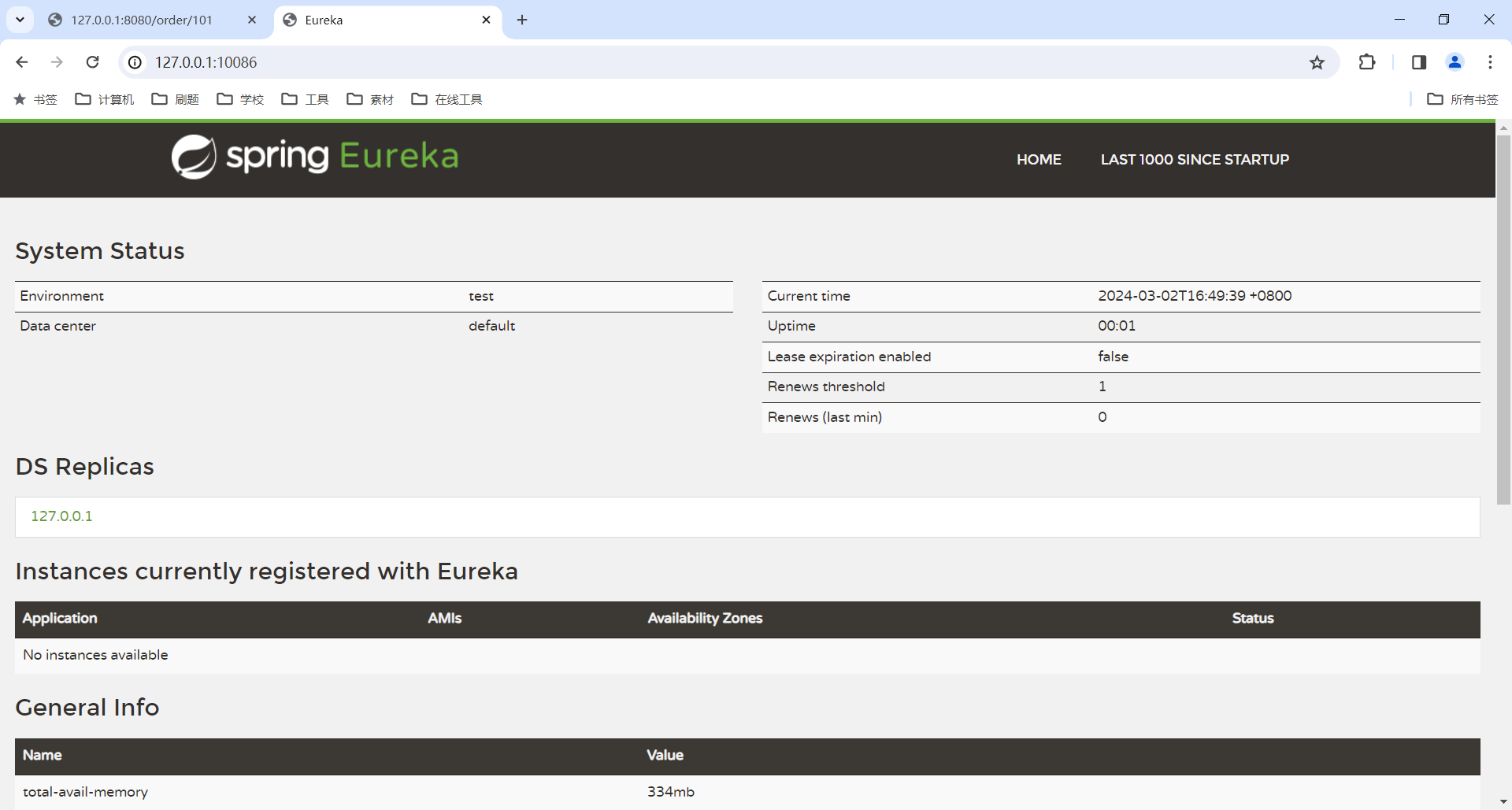
我们重点关注 Instances currently registered with Eureka 这个位置 , 他代表当前已经注册到 Eureka 注册中心的服务 , 那目前还没有任何实例注册到注册中心中
3.2 服务注册
将服务注册到 EureKaServer 的步骤如下 :
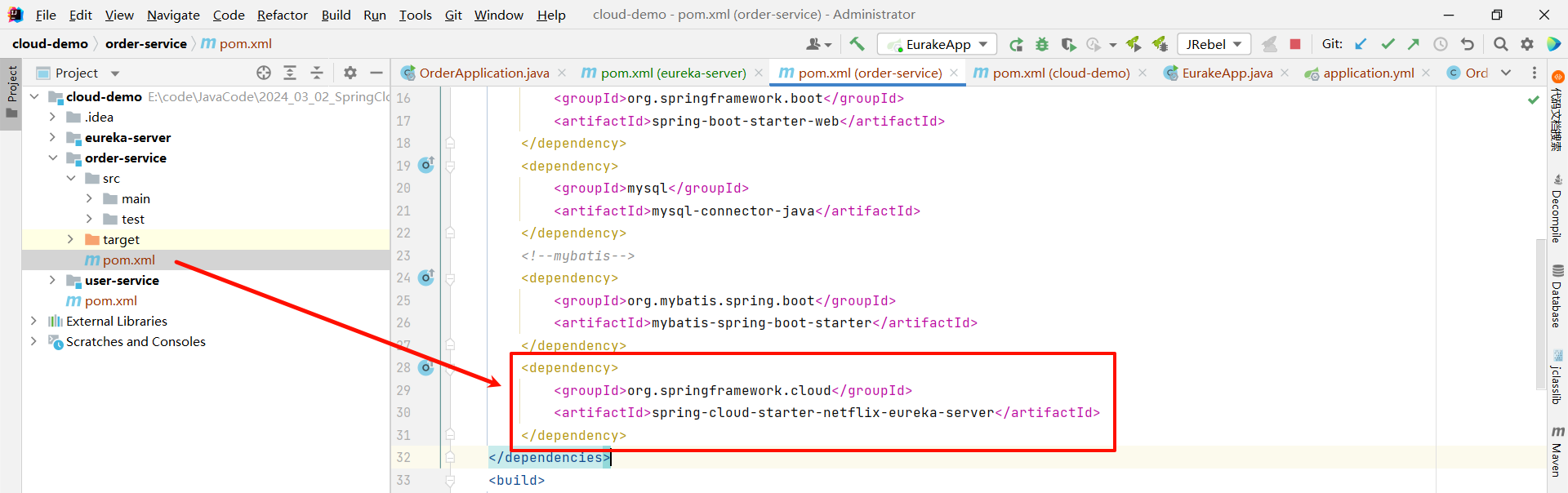
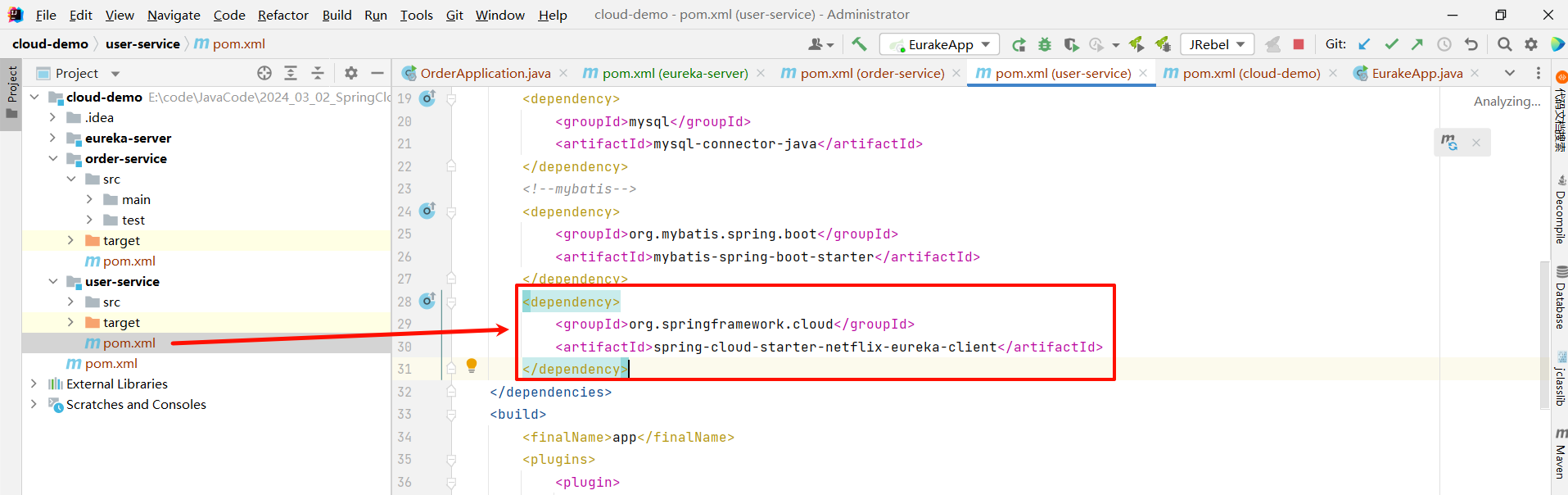
- 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
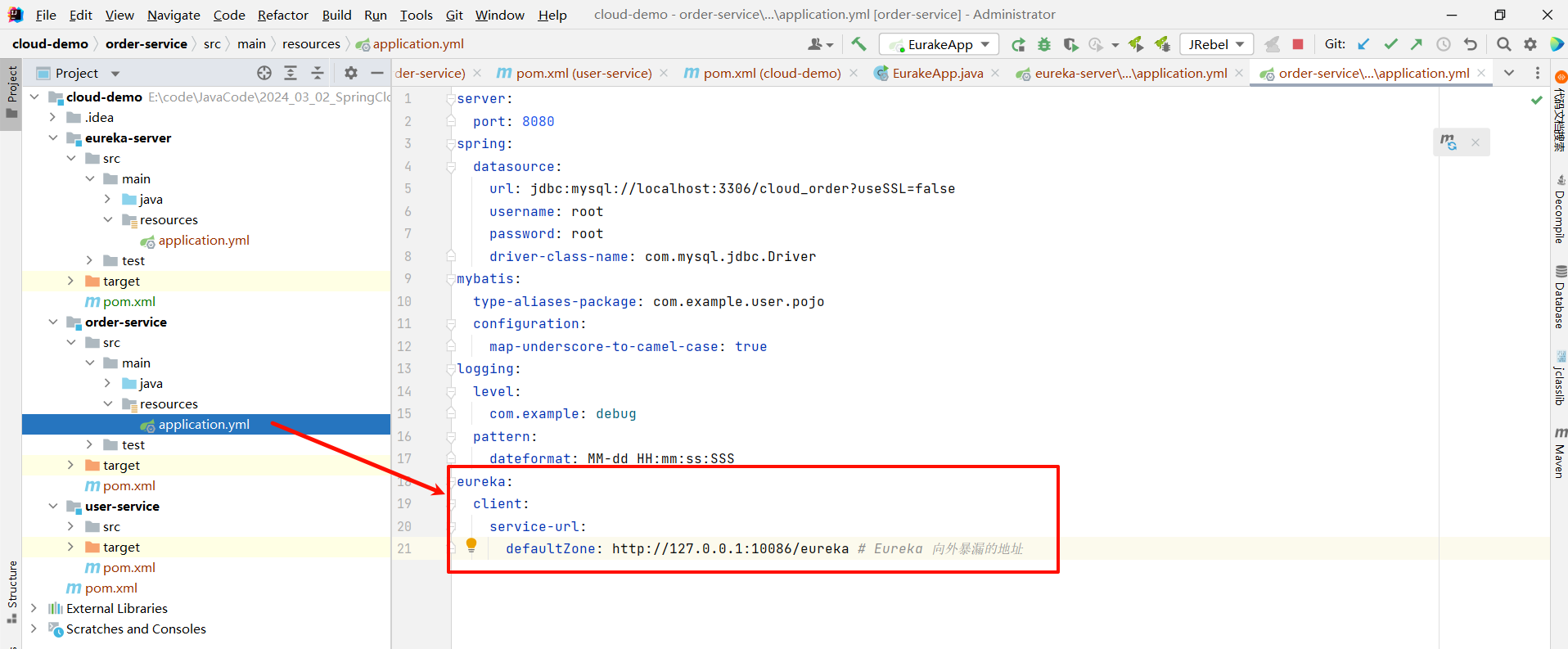
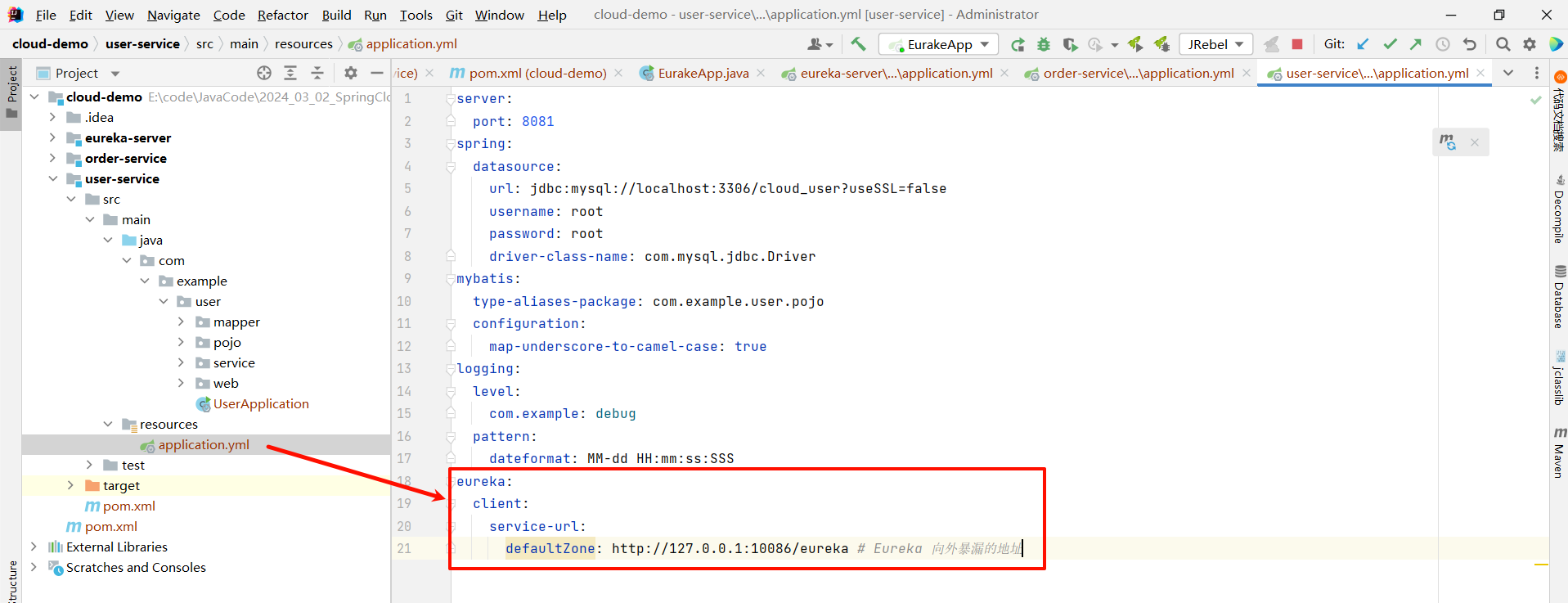
- 在各自的 application.yml 中 , 编写相关配置
① 在 EureKa 的客户端项目中引入 spring-cloud-starter-netflix-eureka-client 的依赖
将下面的依赖粘贴到 user-service 和 order-service 服务中的 pom.xml 中
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
② 在各自的 application.yml 中 , 编写相关配置
将这段配置粘贴到 user-service 和 order-service 的 application.yml 中
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址
③ 给各自的微服务起一个名称
那我们需要给 user-service 和 order-service 的微服务起一个名称 , 不然到时候观察 EureKa 注册中心的时候 , 我们并不知道哪个是 user-service , 哪个是 order-service
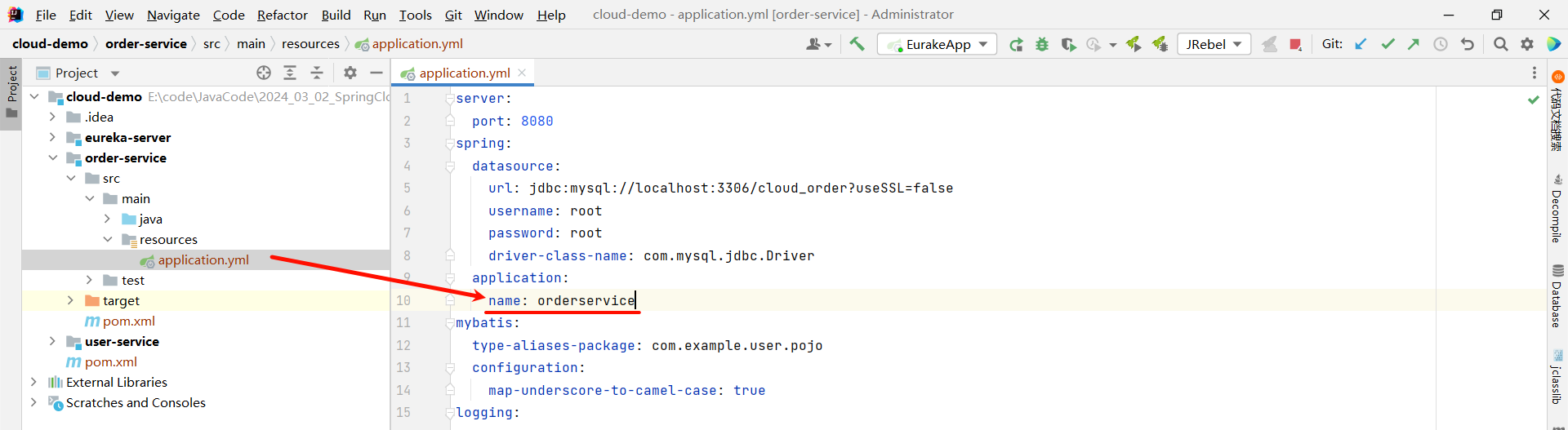
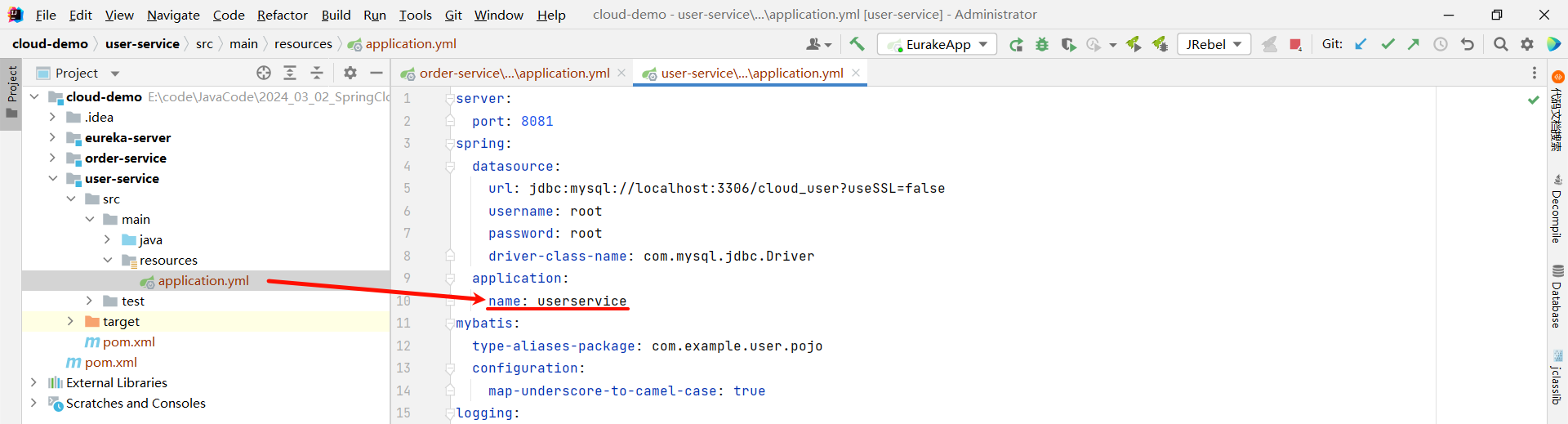
server:
port: 8080
spring:
datasource:
url: jdbc:mysql://localhost:3306/cloud_order?useSSL=false
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
application:
name: userservice
mybatis:
type-aliases-package: com.example.user.pojo
configuration:
map-underscore-to-camel-case: true
logging:
level:
com.example: debug
pattern:
dateformat: MM-dd HH:mm:ss:SSS
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka # Eureka 向外暴漏的地址
那这时候 , 我们重启 user-service 和 order-service , 就会自动将自身信息注册到 EureKa 中了
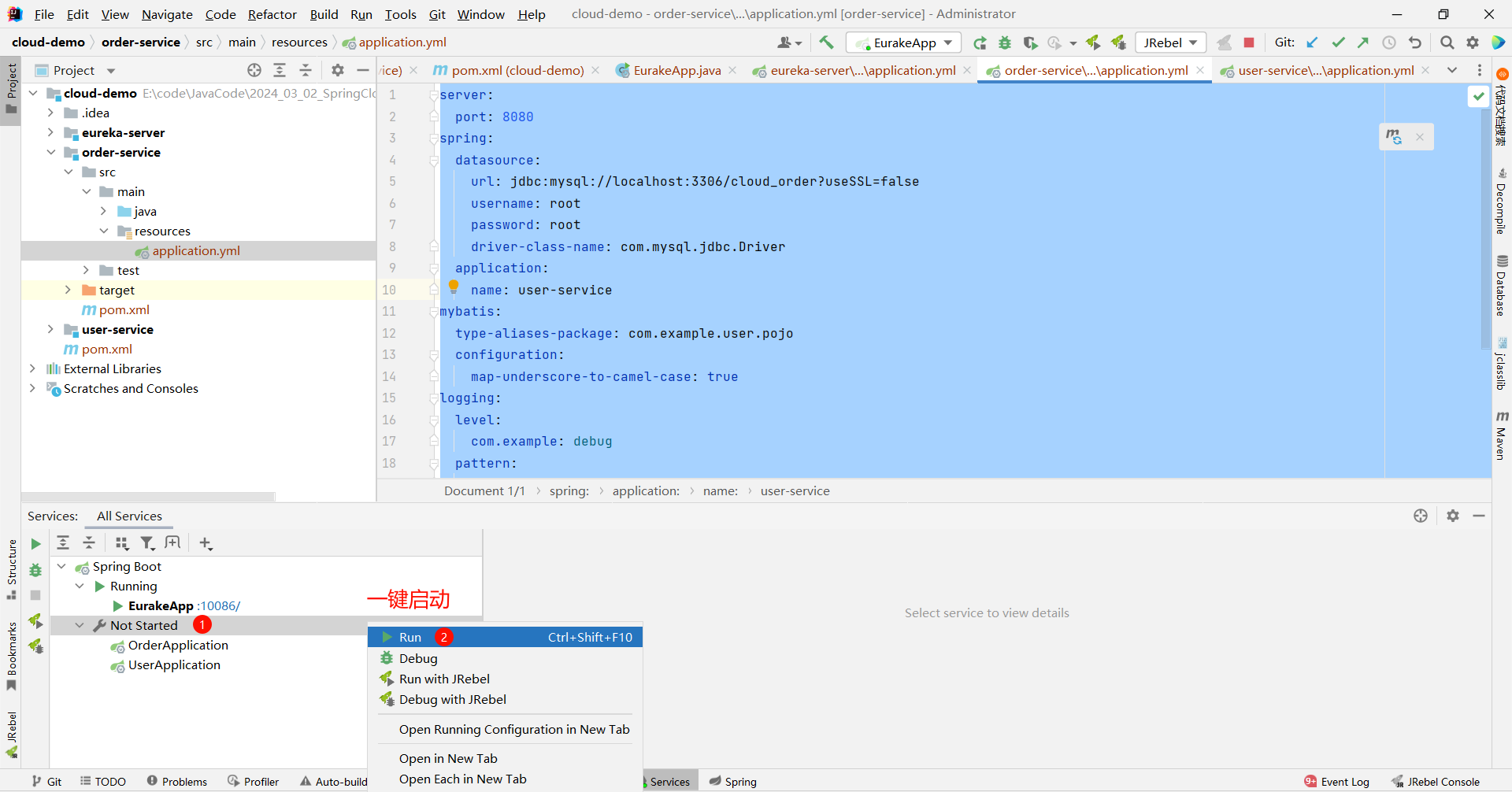
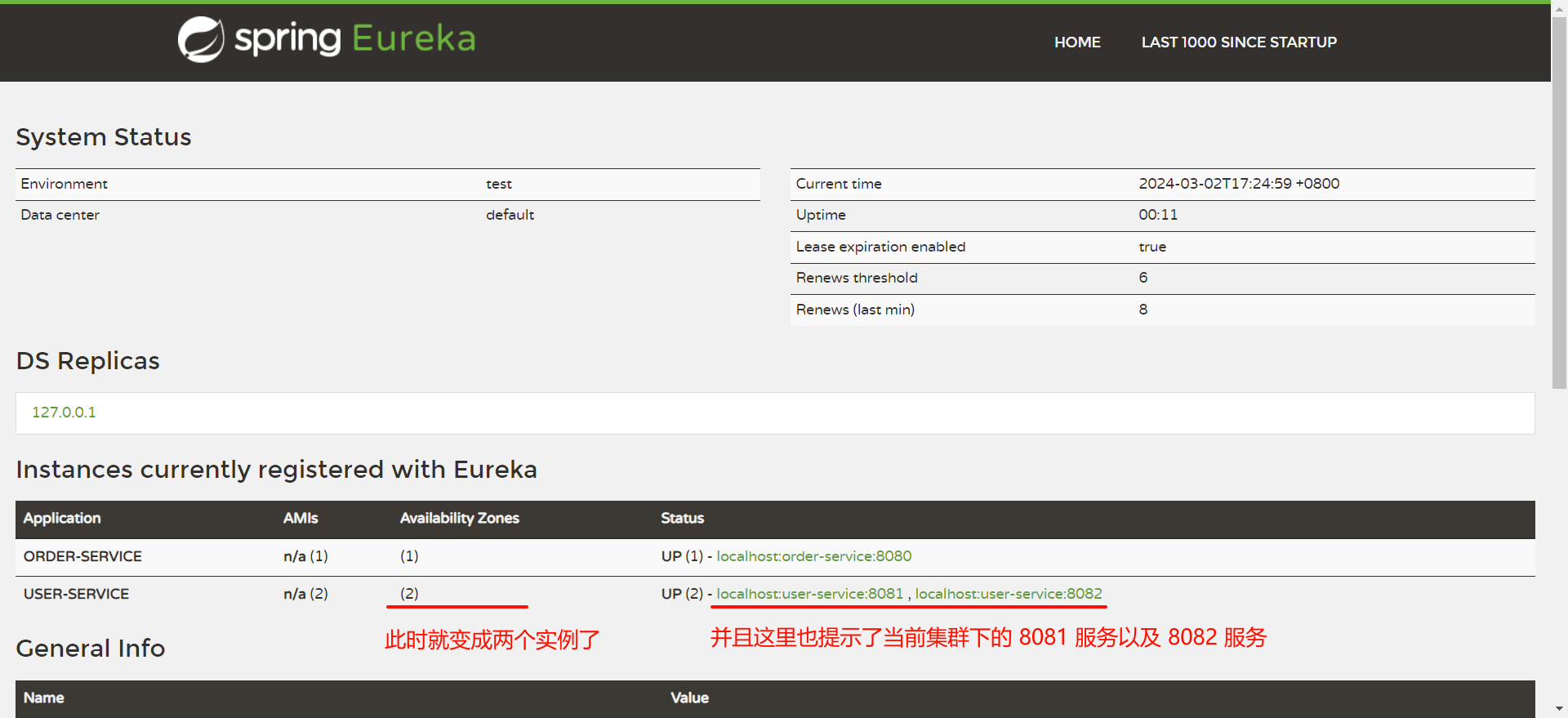
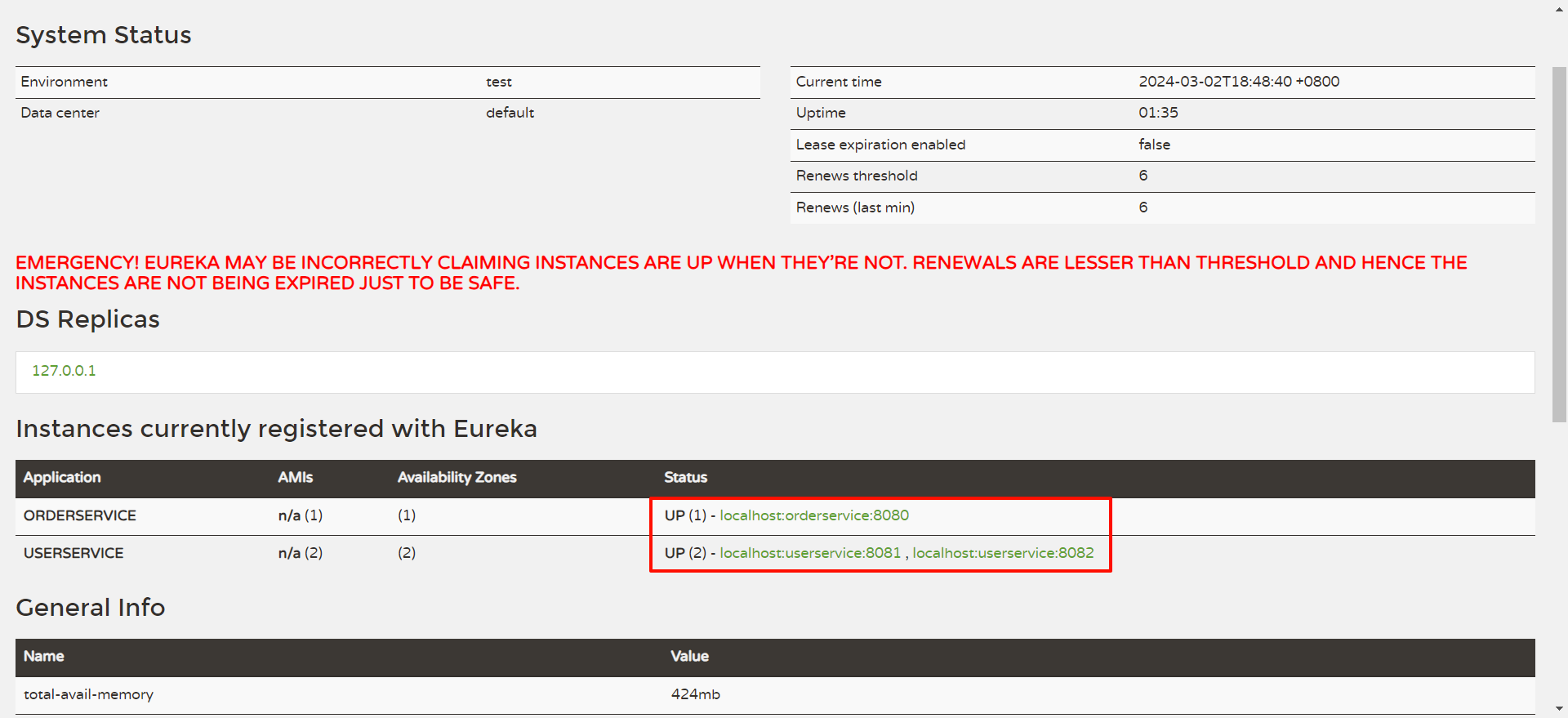
我们回到 EureKa 注册中心看一下 , 此时两个服务已经成功注册
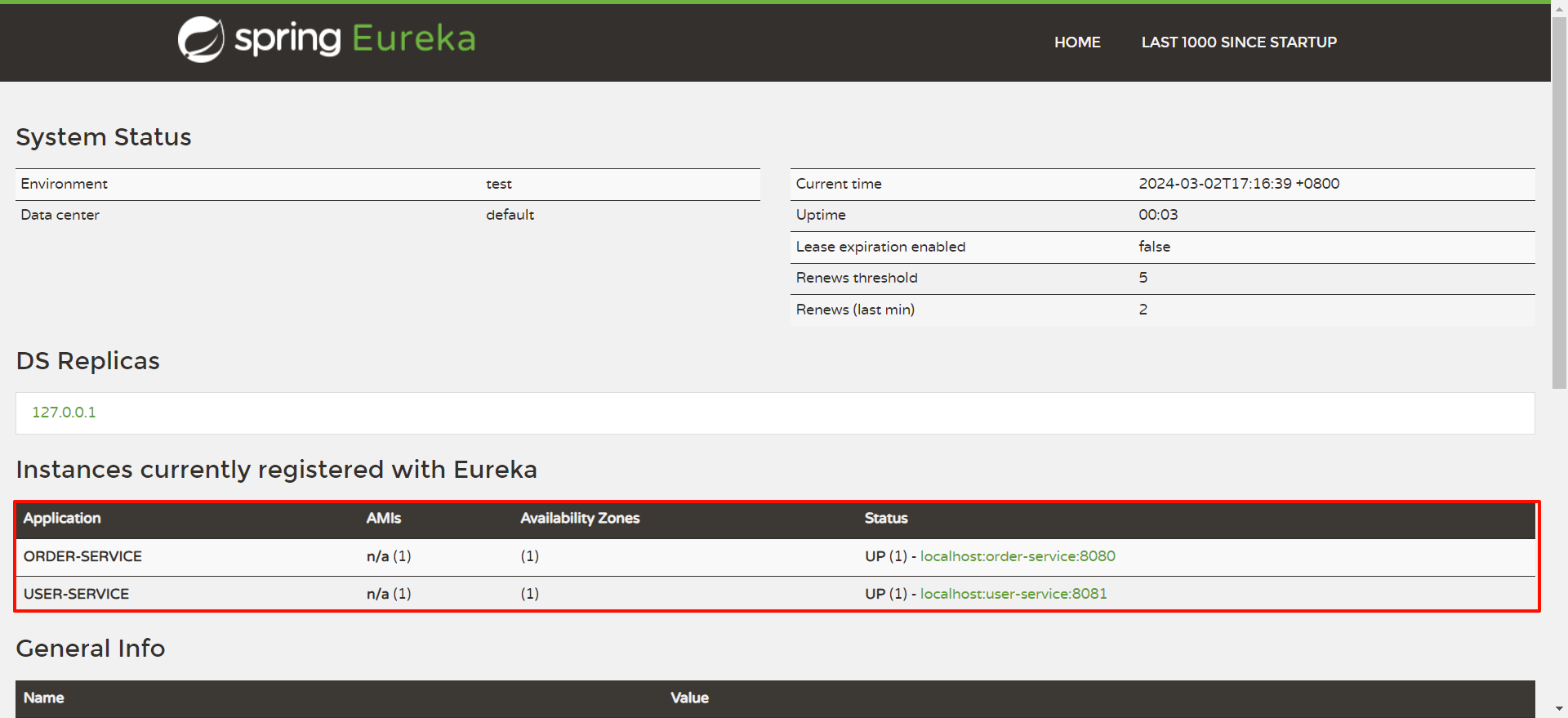
那也有可能在页面 , 会有一个大大的红色警报

他其实并不是报错 , 只是 Eureka 认为 , 当你的实例只有一个节点的时候 , 这个服务就很危险了 .
也就是你对应的服务只启动了一份 .
④ 启动多个 EureKa 客户端
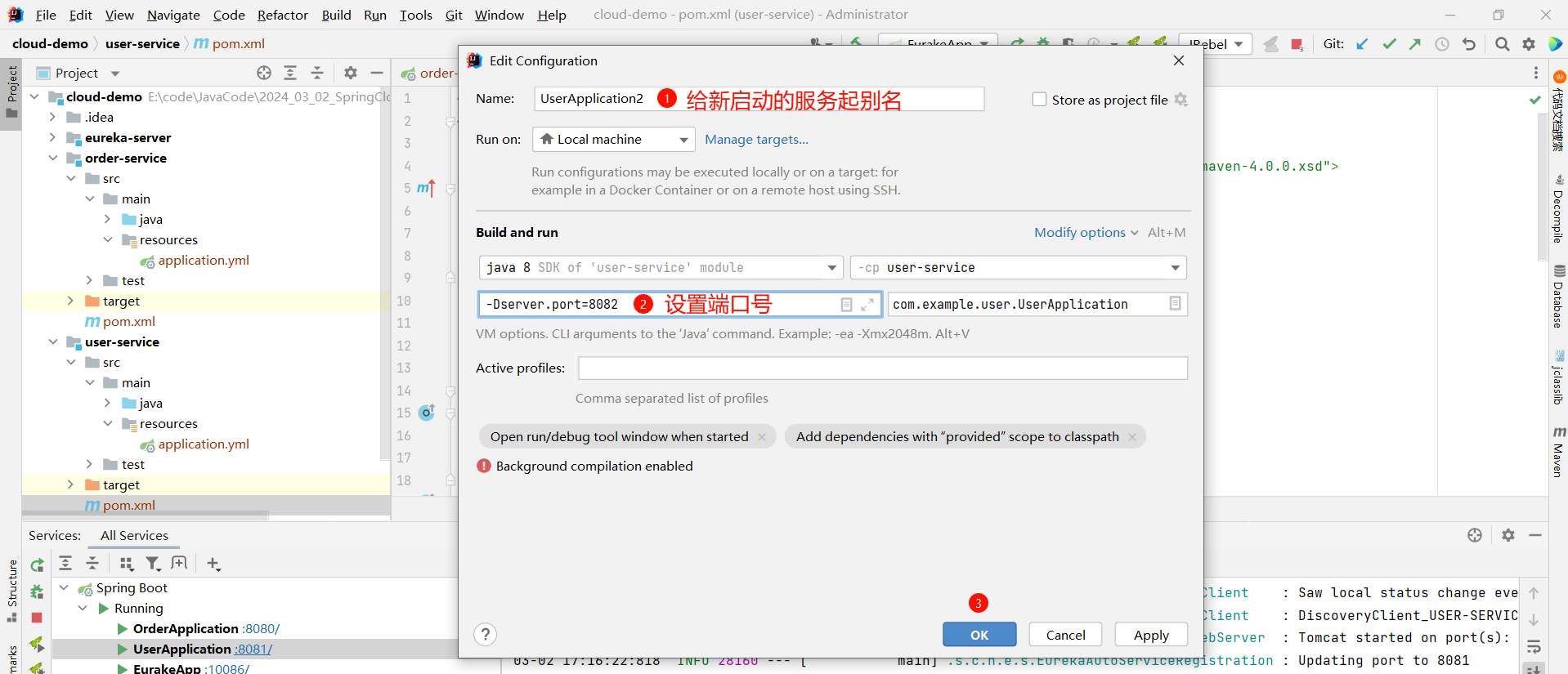
-Dserver.port=8082
那接下来 , 我们启动新的 user-service 服务
然后回到 EureKa 控制中心看一下
四 . 服务发现
虽然我们已经把 user-service 服务和 order-service 服务注册到 EureKa 中了 , 但是我们在访问这两个接口的时候 , 还需要访问固定的 IP

那这是因为我们在代码中已经将端口号写死了
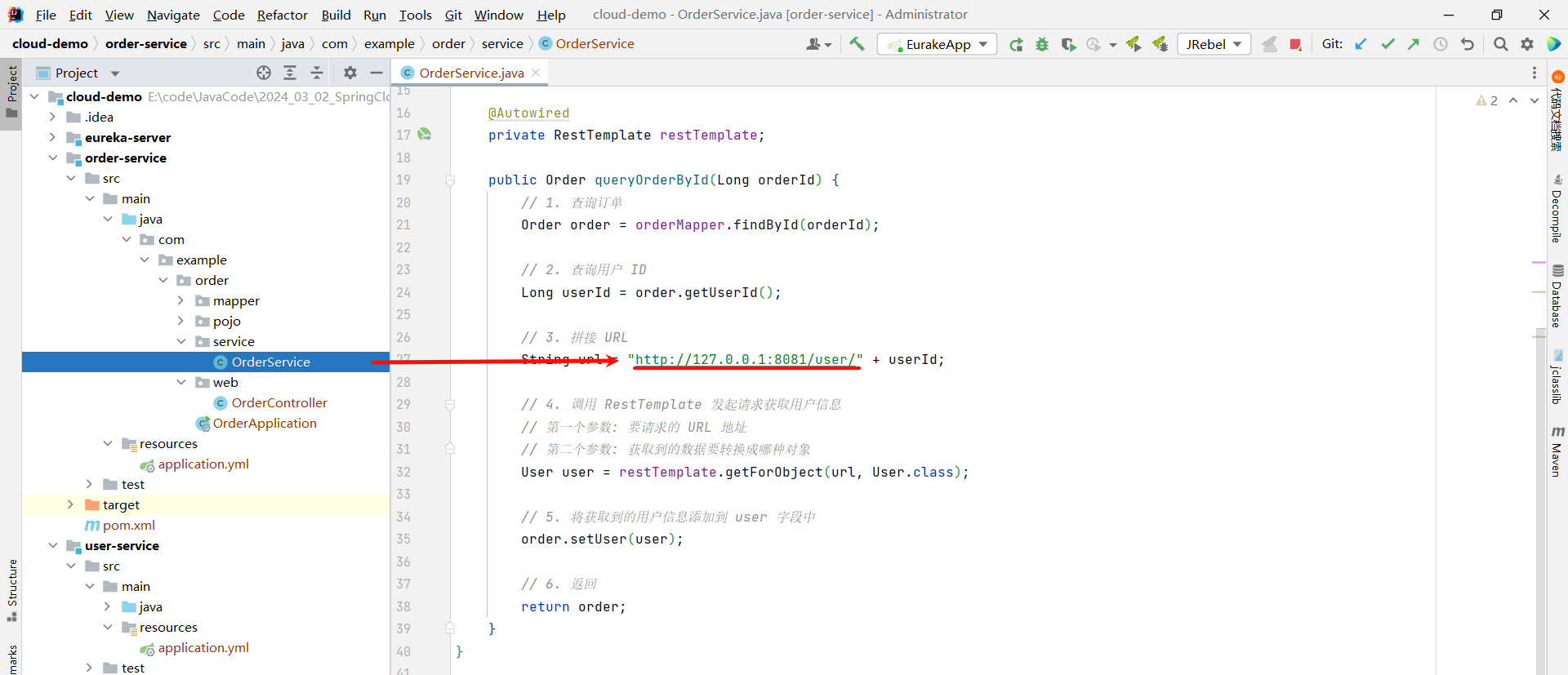
那这样的话 , 即使 user-service 服务搭建了集群 , 我们也只能访问到固定的 8081 端口的服务 , 所以我们需要更换一下写法
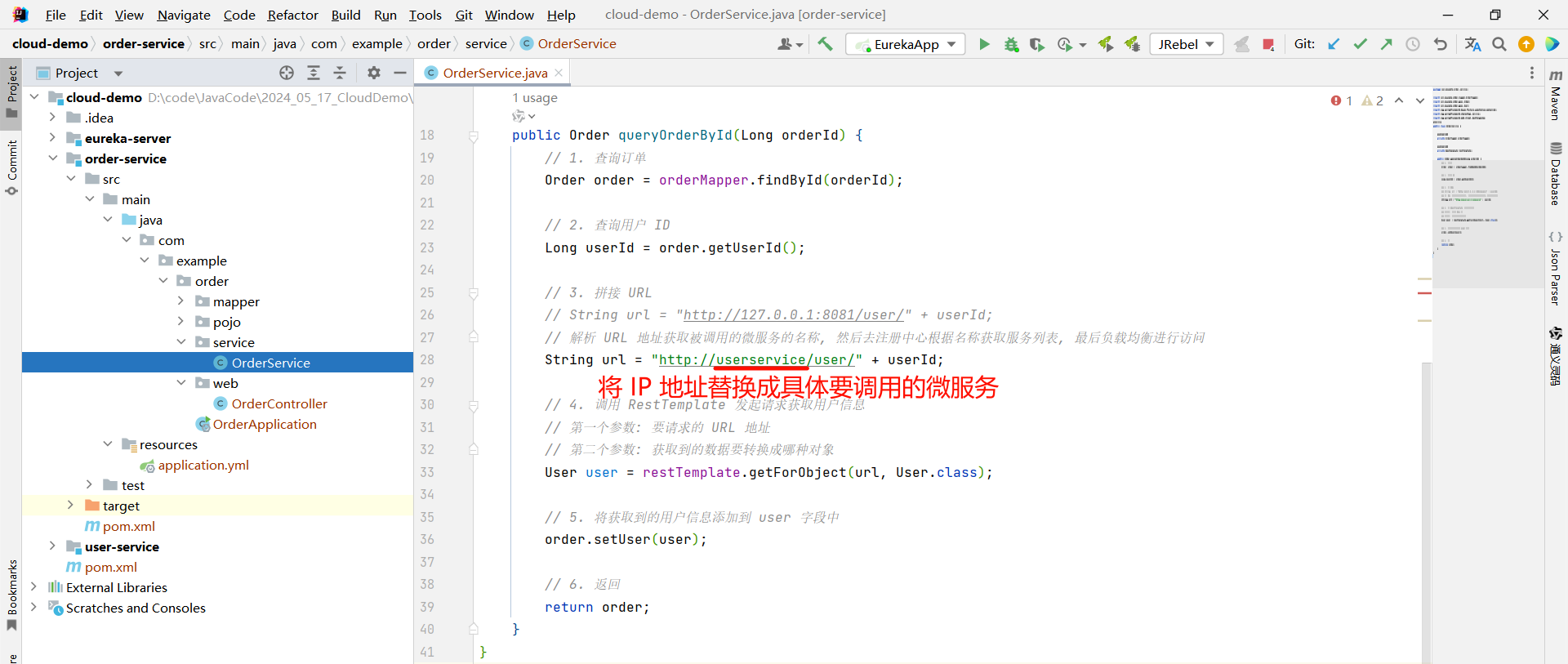
package com.example.order.service;
import com.example.order.mapper.OrderMapper;
import com.example.order.pojo.Order;
import com.example.order.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.web.client.RestTemplate;
@Service
public class OrderService {
@Autowired
private OrderMapper orderMapper;
@Autowired
private RestTemplate restTemplate;
public Order queryOrderById(Long orderId) {
// 1. 查询订单
Order order = orderMapper.findById(orderId);
// 2. 查询用户 ID
Long userId = order.getUserId();
// 3. 拼接 URL
// String url = "http://127.0.0.1:8081/user/" + userId;
// 解析 URL 地址获取被调用的微服务的名称, 然后去注册中心根据名称获取服务列表, 最后负载均衡进行访问
String url = "http://userservice/user/" + userId;
// 4. 调用 RestTemplate 发起请求获取用户信息
// 第一个参数: 要请求的 URL 地址
// 第二个参数: 获取到的数据要转换成哪种对象
User user = restTemplate.getForObject(url, User.class);
// 5. 将获取到的用户信息添加到 user 字段中
order.setUser(user);
// 6. 返回
return order;
}
}
要注意这个位置需要跟要调用的服务的 application.yml 进行对齐
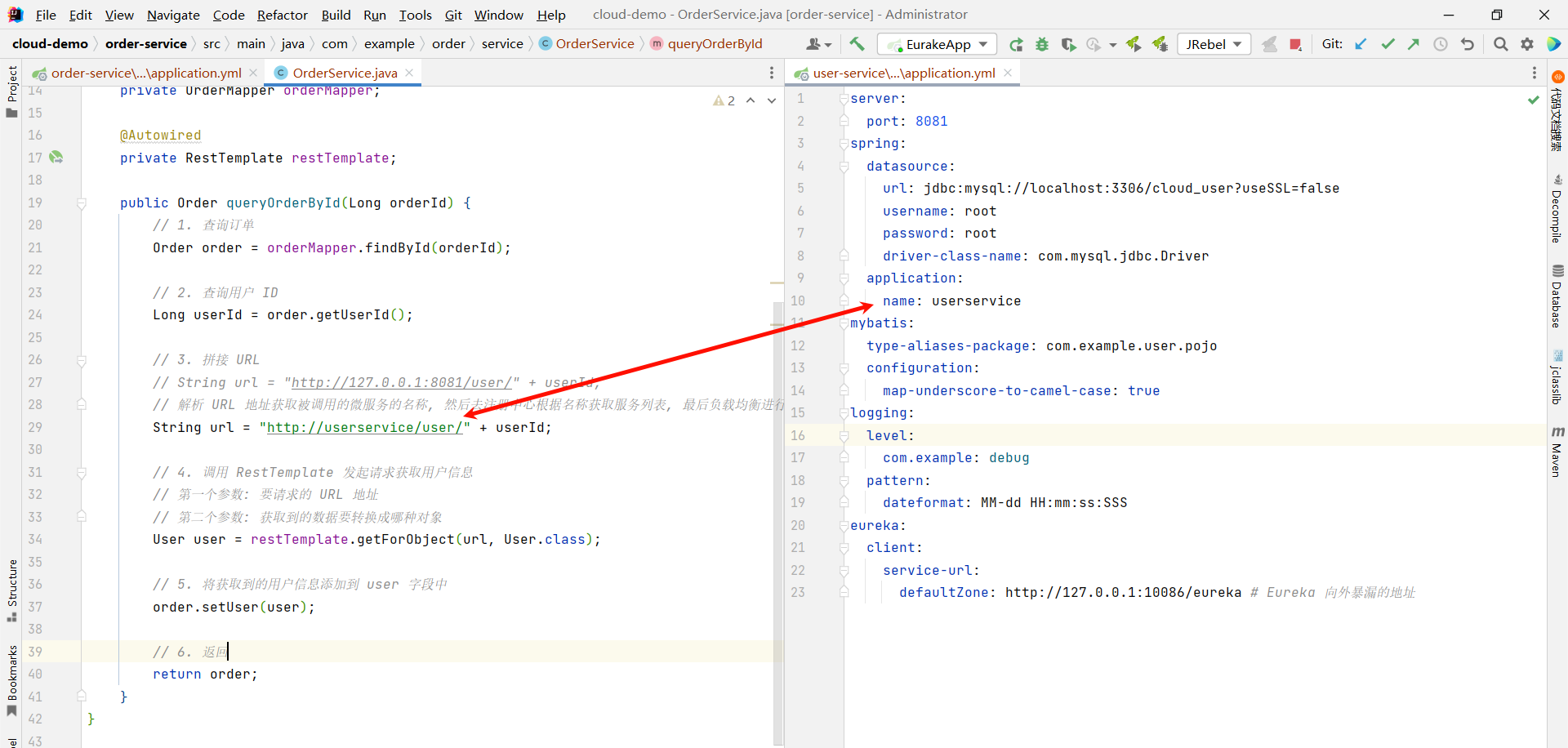
那为了演示负载均衡的效果 , 我们还需要修改一些内容
我们可以将配置文件中的端口号读取出来 , 然后设置到用户名部分 , 这样我们就能通过页面来看到端口号的变化
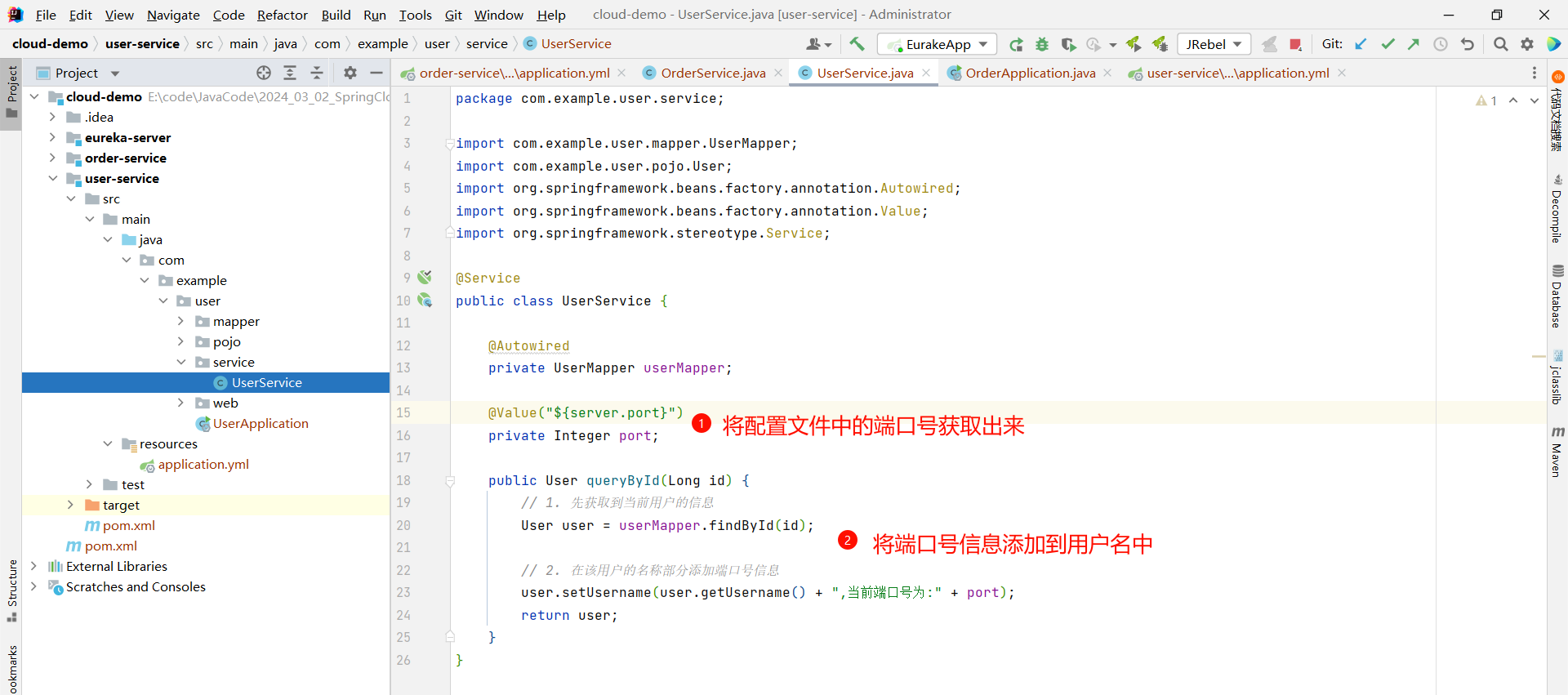
package com.example.user.service;
import com.example.user.mapper.UserMapper;
import com.example.user.pojo.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Value("${server.port}")
private Integer port;
public User queryById(Long id) {
// 1. 先获取到当前用户的信息
User user = userMapper.findById(id);
// 2. 在该用户的名称部分添加端口号信息
user.setUsername(user.getUsername() + ",当前端口号为:" + port);
return user;
}
}
重启 order-service 与 user-service 服务
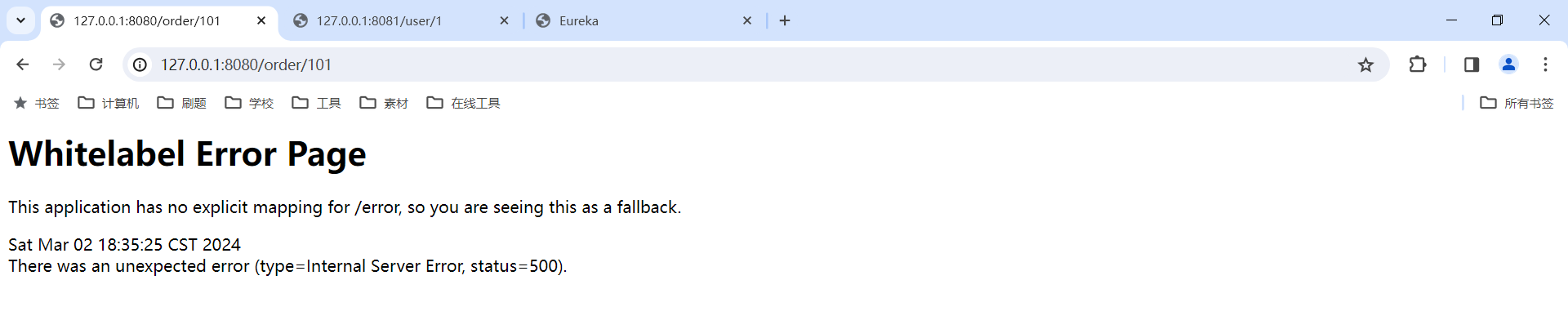
那这次我们再访问 order-service 服务 , 发现报错了
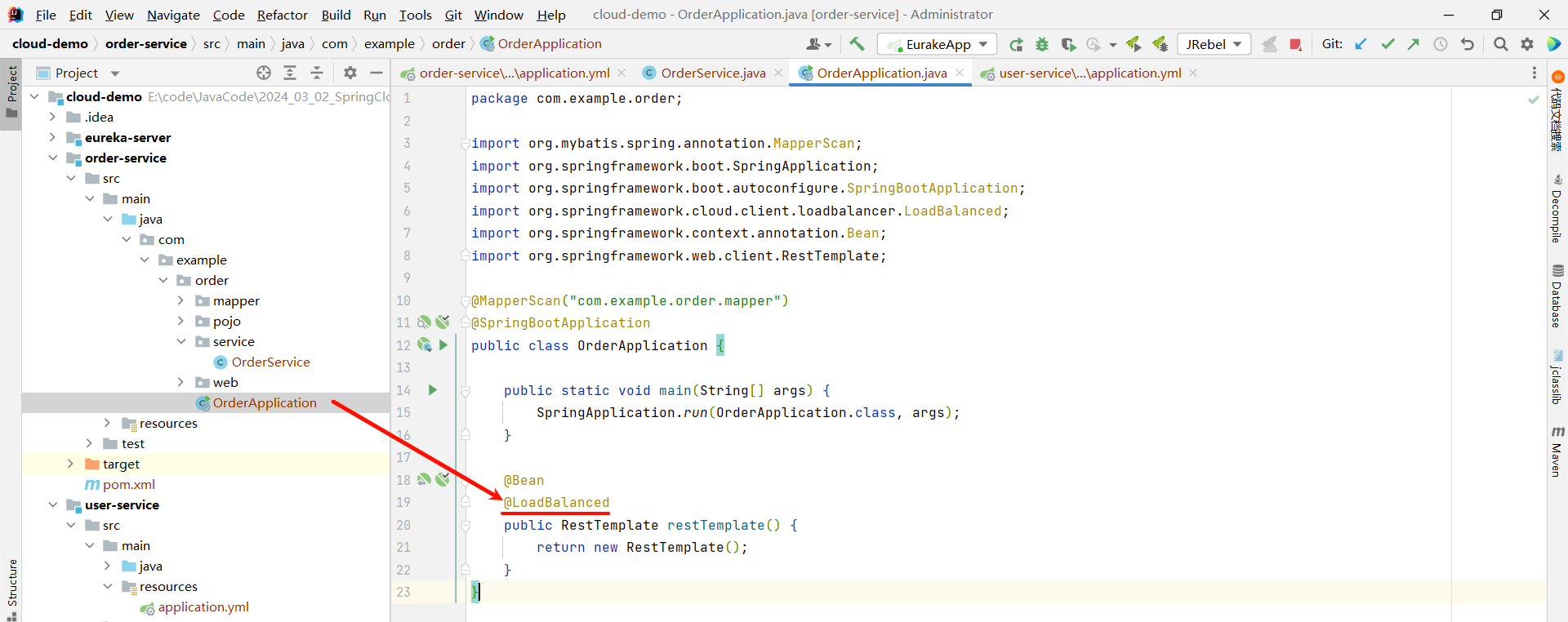
这是因为我们还需要在 order-service 项目的启动类 OrderApplication 中的 RestTemplate 添加负载均衡注解
package com.example.order;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("com.example.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
@LoadBalanced // 开启负载均衡注解
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
这次我们重新运行
我们注意端口号的变化 , 这样就达到了负载均衡的效果 .

小结 :
- 搭建 EurekaServer
- 引入 eureka-server 依赖
- 在当前服务启动类中添加 @EnableEurekaServer 注解
- 在 application.yml 中配置 eureka 地址
- 服务注册
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 服务发现
- 引入 eureka-client 依赖
- 在 application.yml 中配置 eureka 地址
- 给 RestTemplate 添加 @LoadBalanced 注解
- 用服务提供者的服务名称来去远程调用
五 . Ribbon 负载均衡
5.1 负载均衡流程
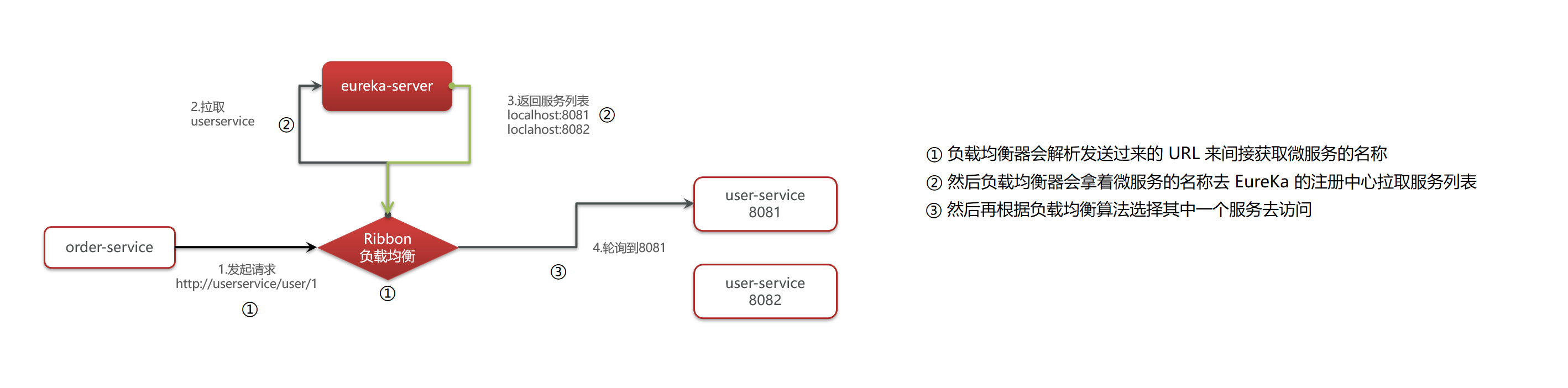
5.2 负载均衡原理
首先 , 我们全局搜索 LoadBalancerInterceptor 类

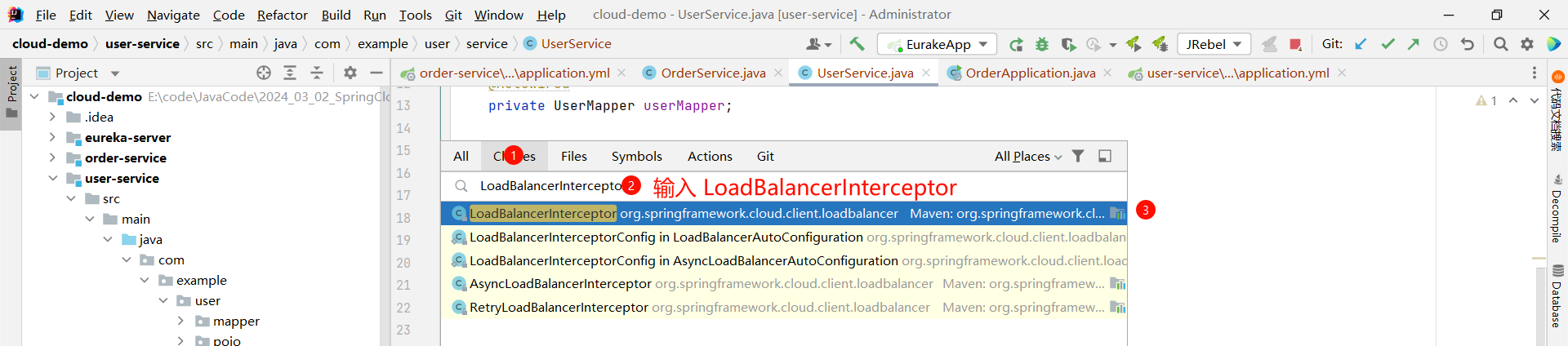
然后在下面的 intercept 方法打个断点
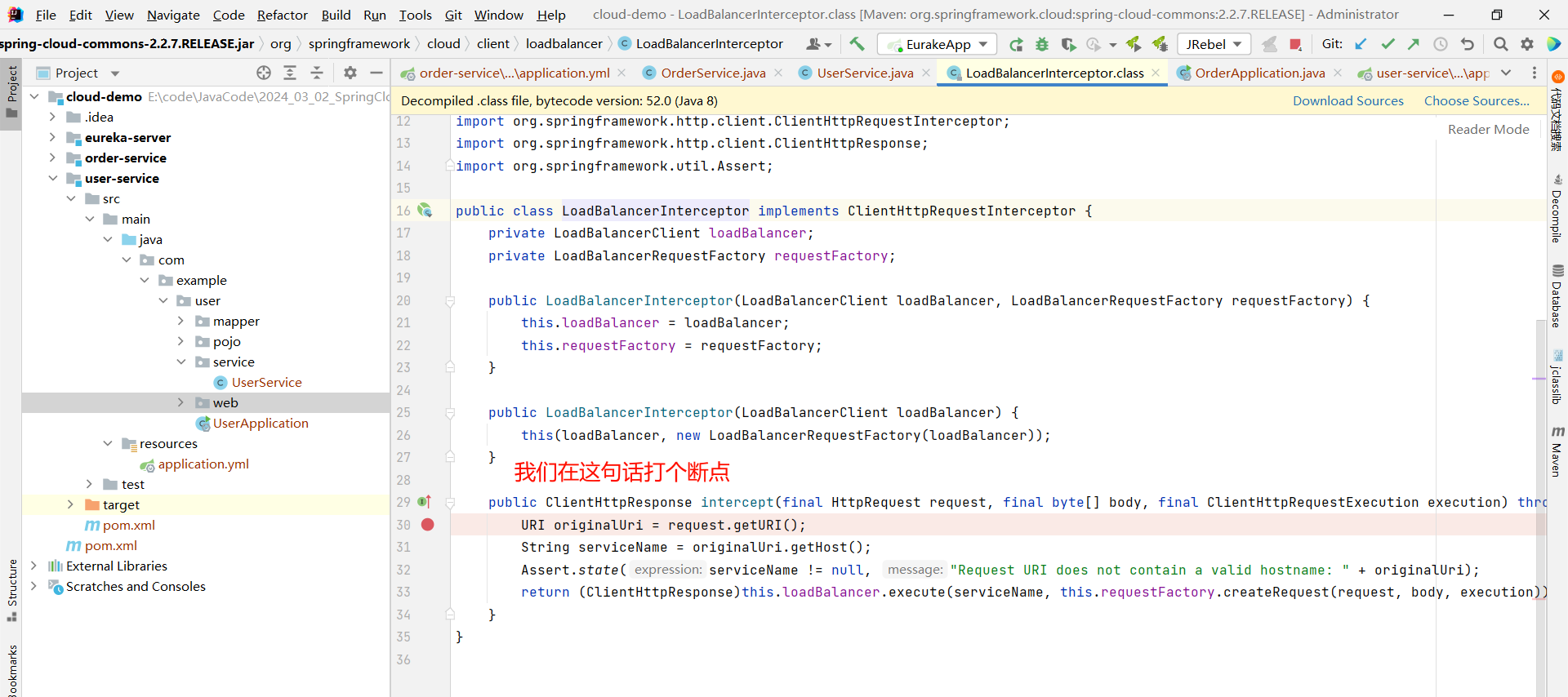
之后让 order-service 以 Debug 的方式运行
此时刷新页面 , 就会被 intercept 方法拦截
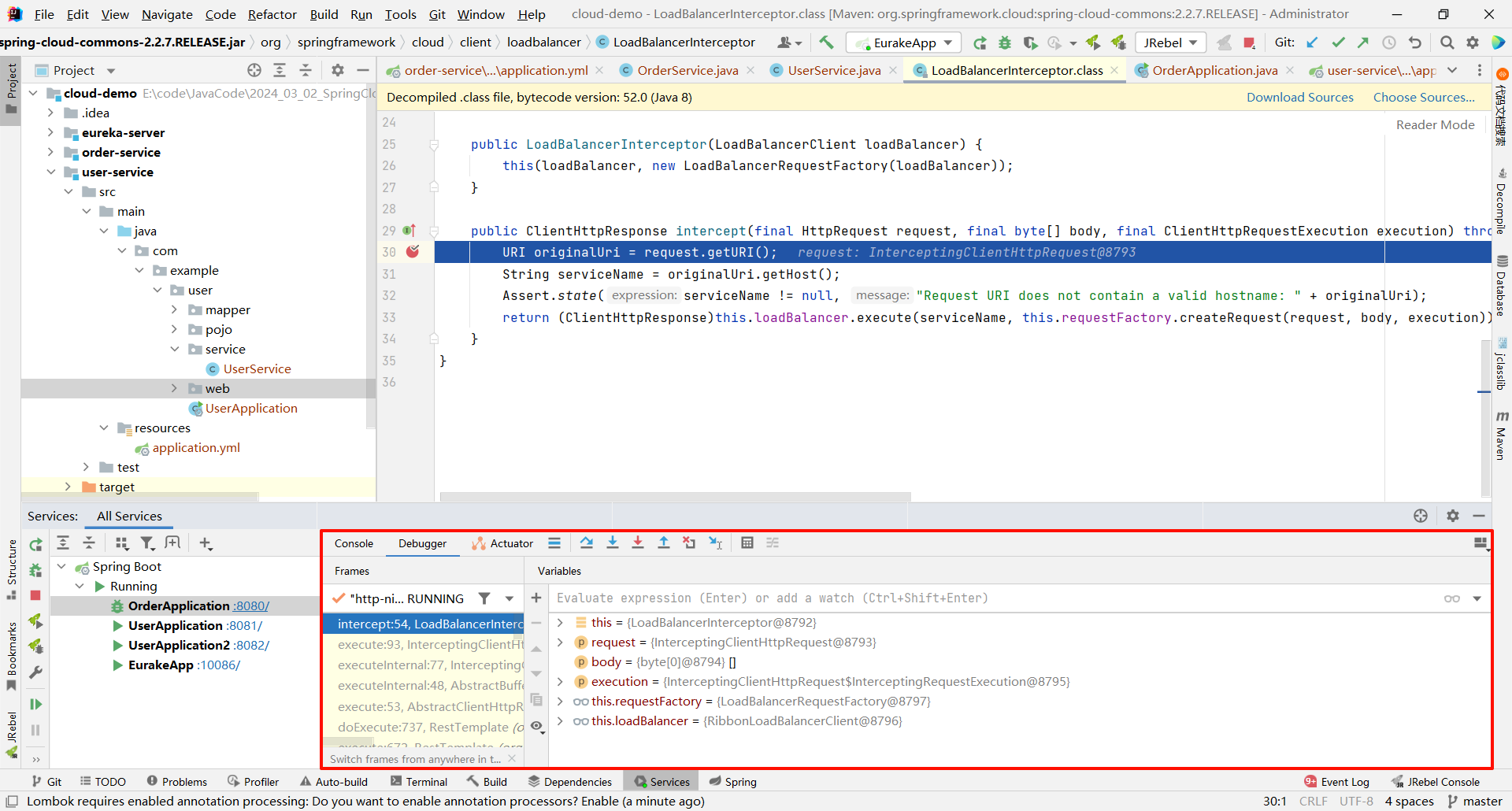
然后我们向下执行 , 发现成功获取到了我们指定的 URL
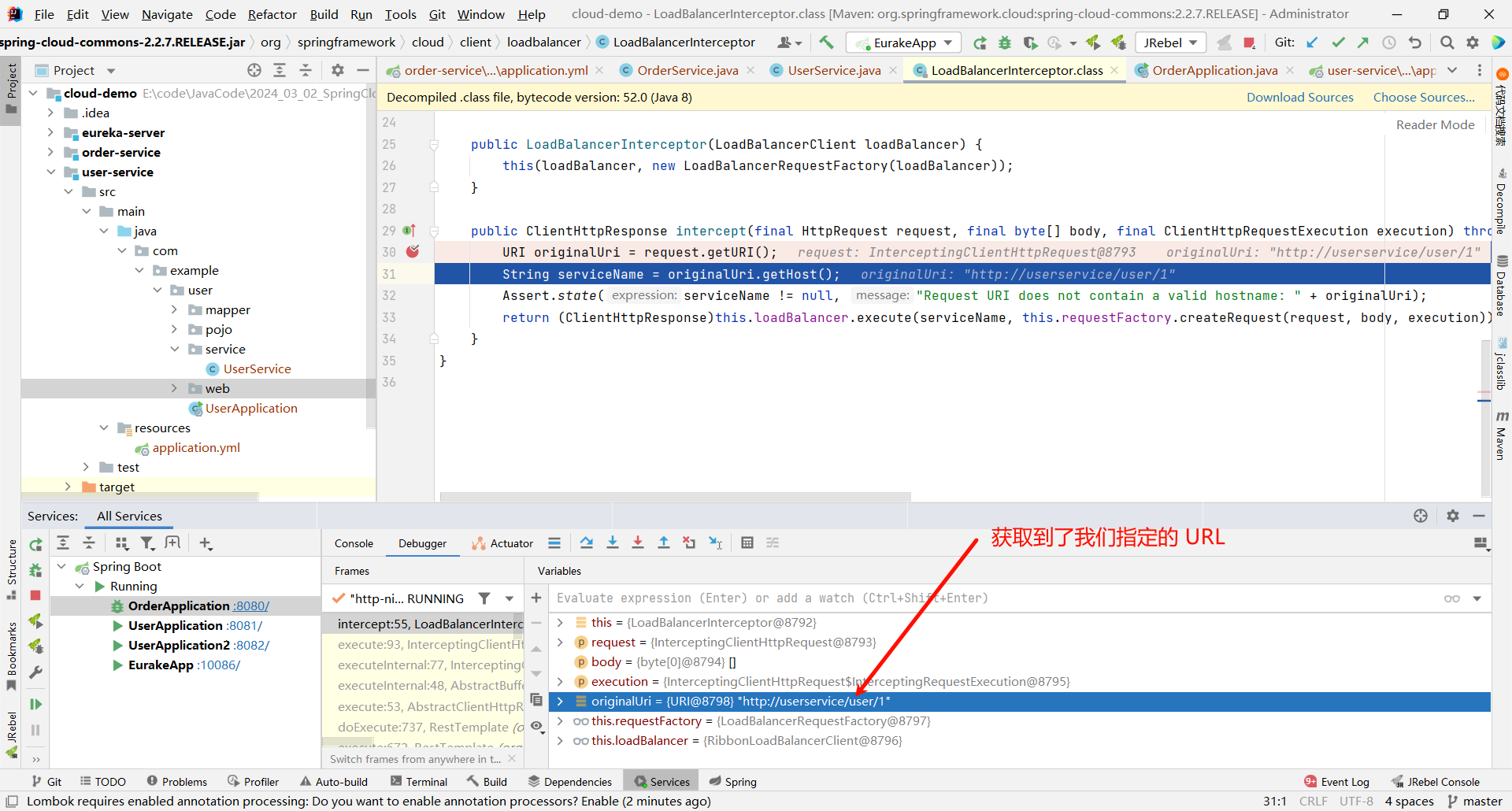
然后再往下执行
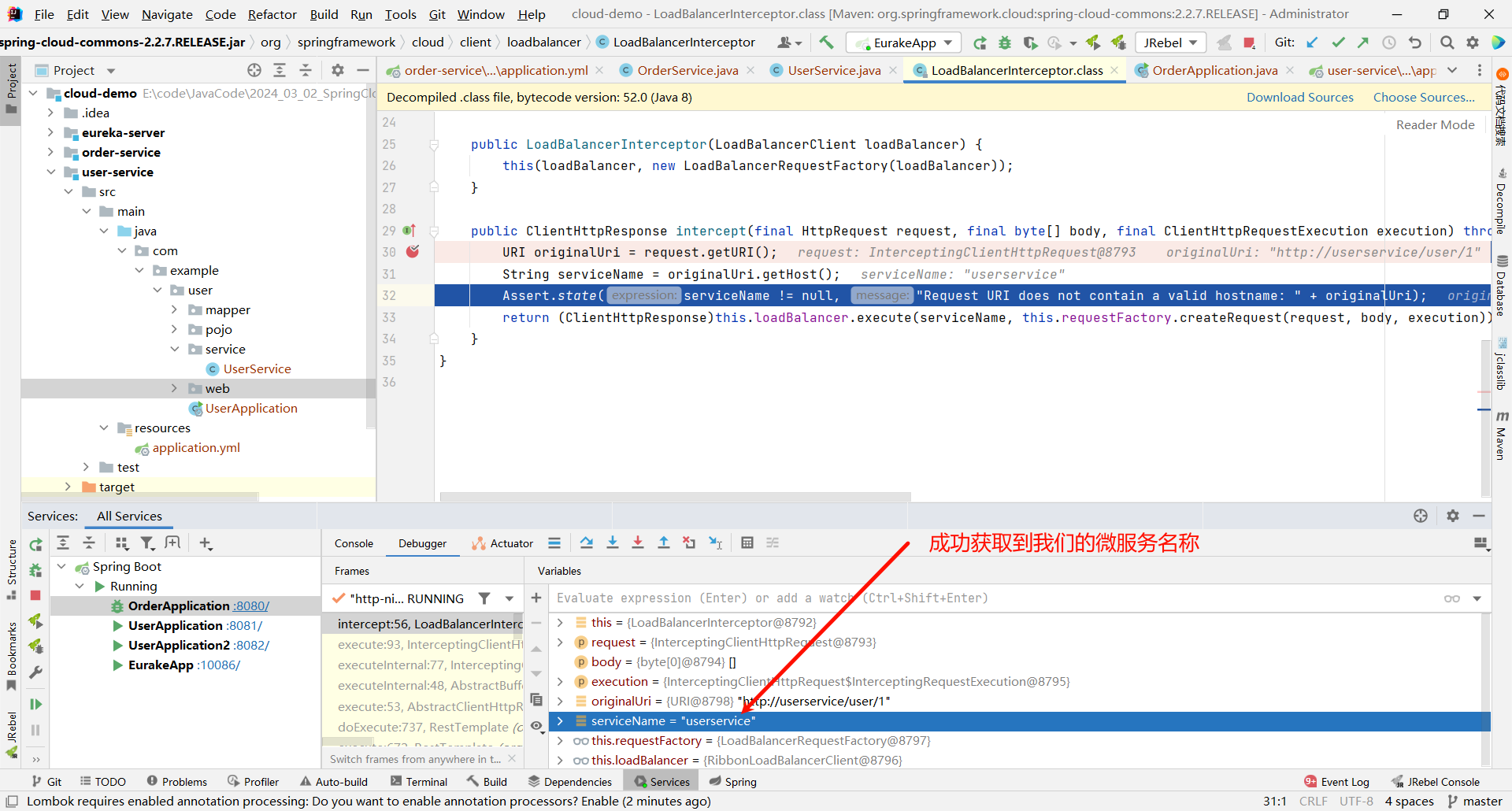
那接下来就是 execute 方法了 , 他的目的肯定是从注册中心获取服务列表 , 我们可以继续深入源码
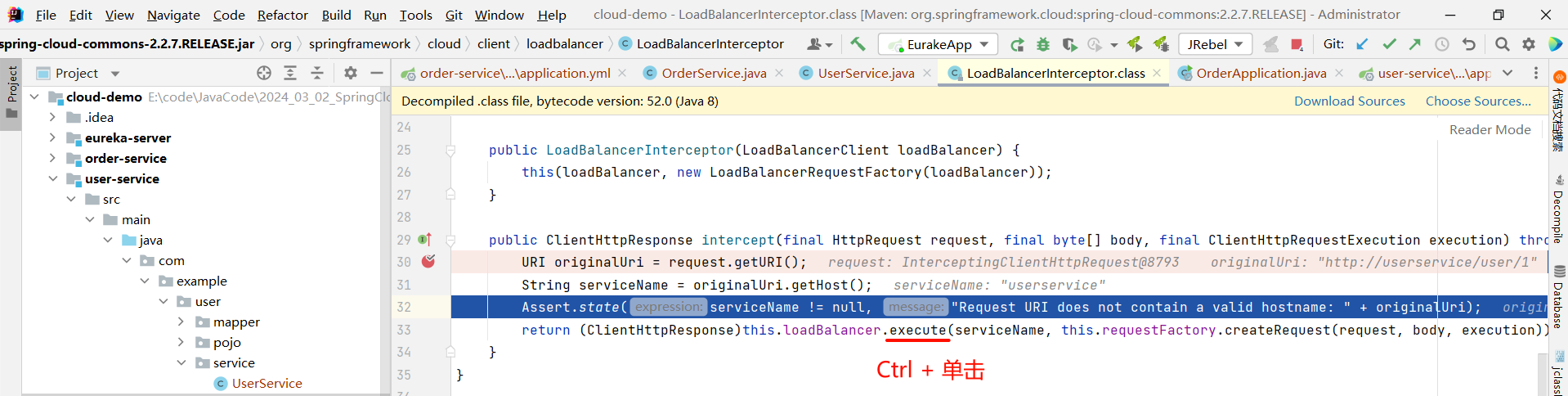
然后我们要看这个接口具体的实现
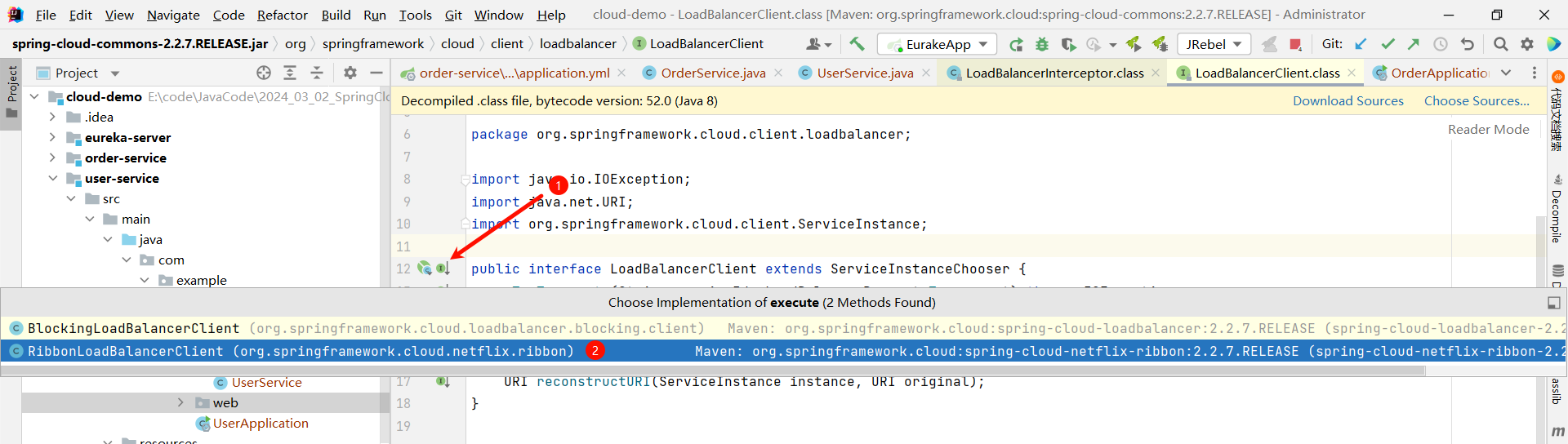
然后在这个方法上添加一个端点 , 看能否执行到这里
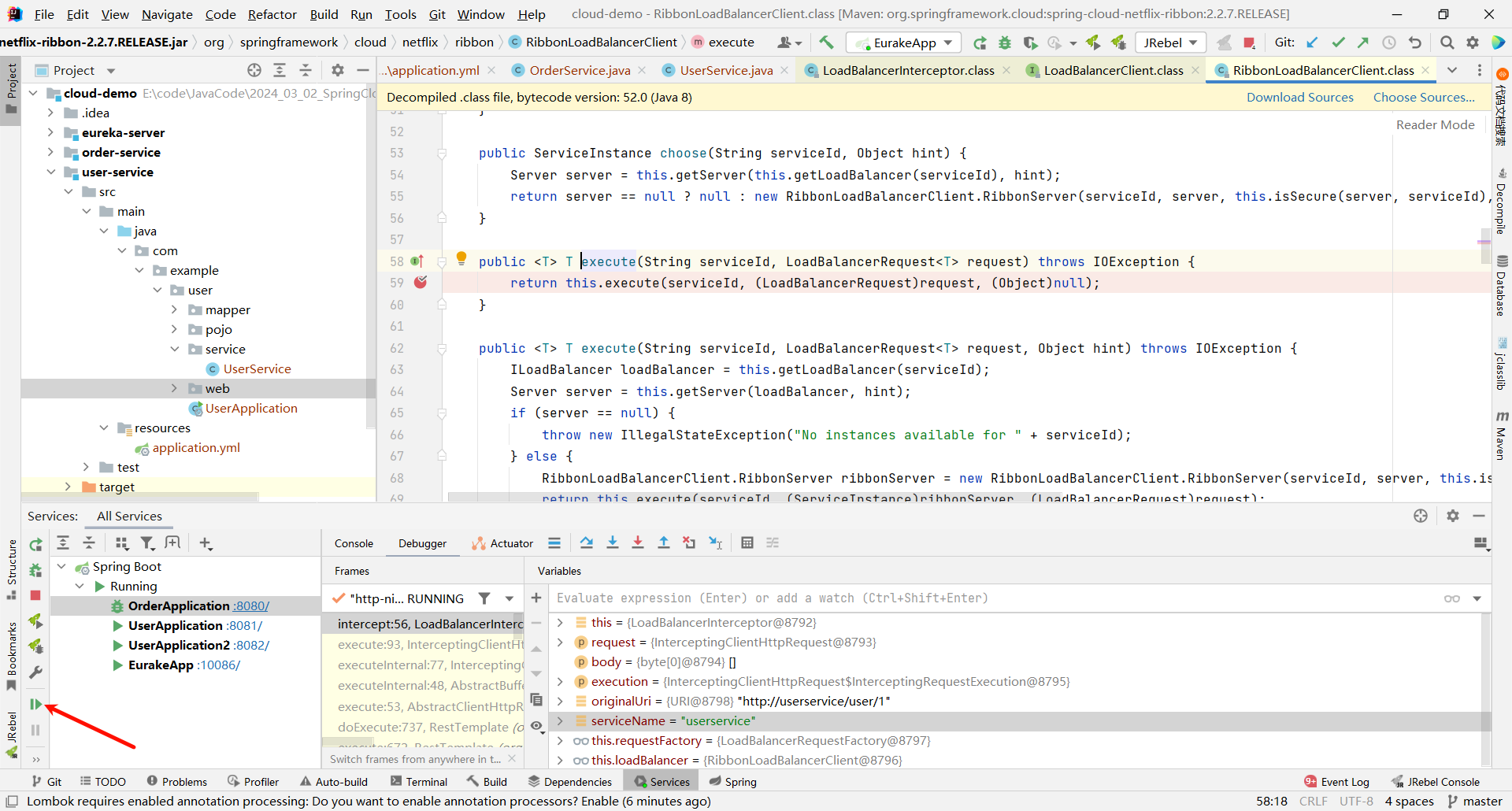
我们发现 , 确实跳转过来了
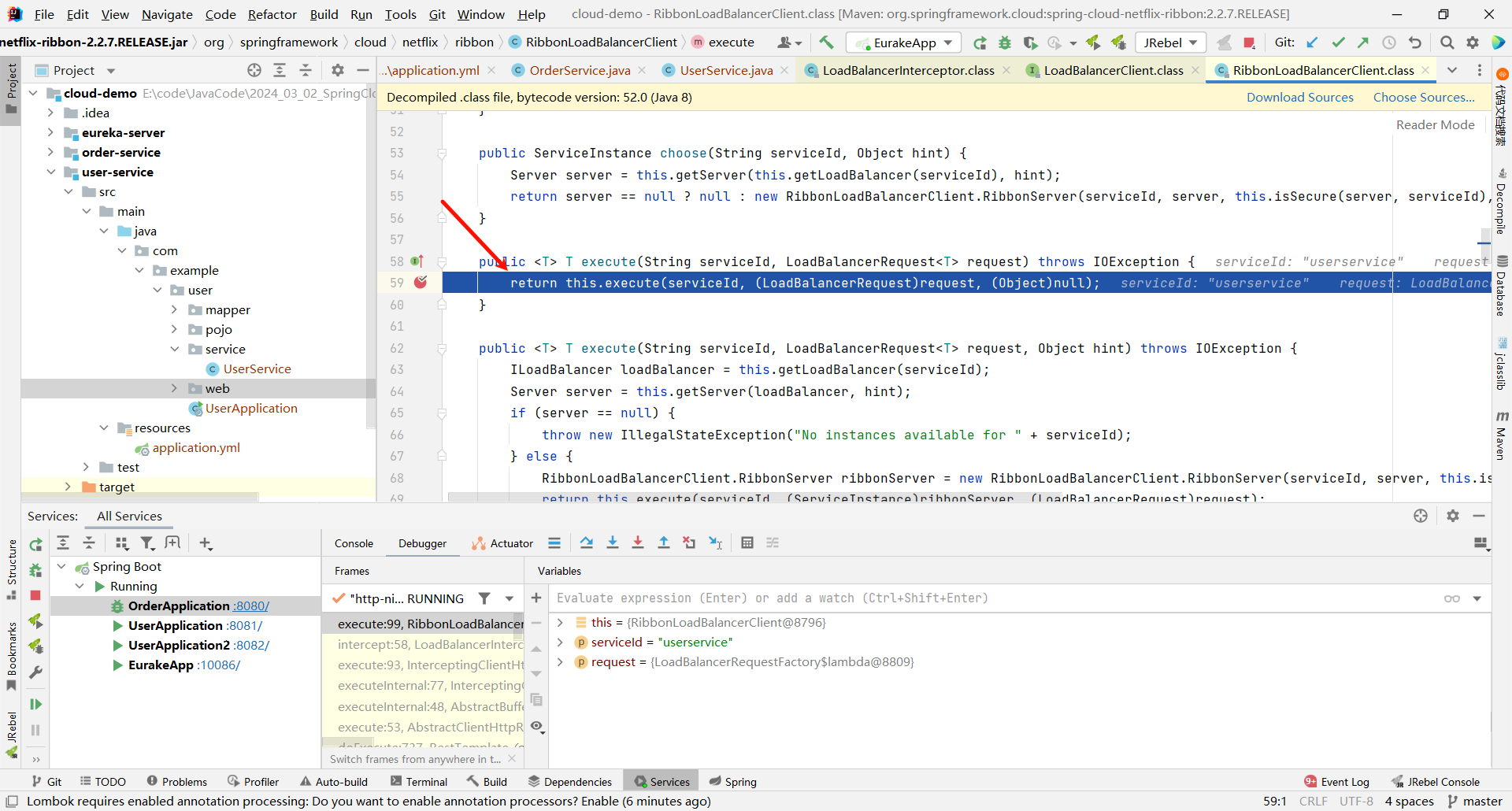
那这个方法是一个重载的方法 , 他还需要继续向下调用 , 那我们就在他的重载方法的位置再打一个断点
将刚刚添加的这个 execute 断点取消
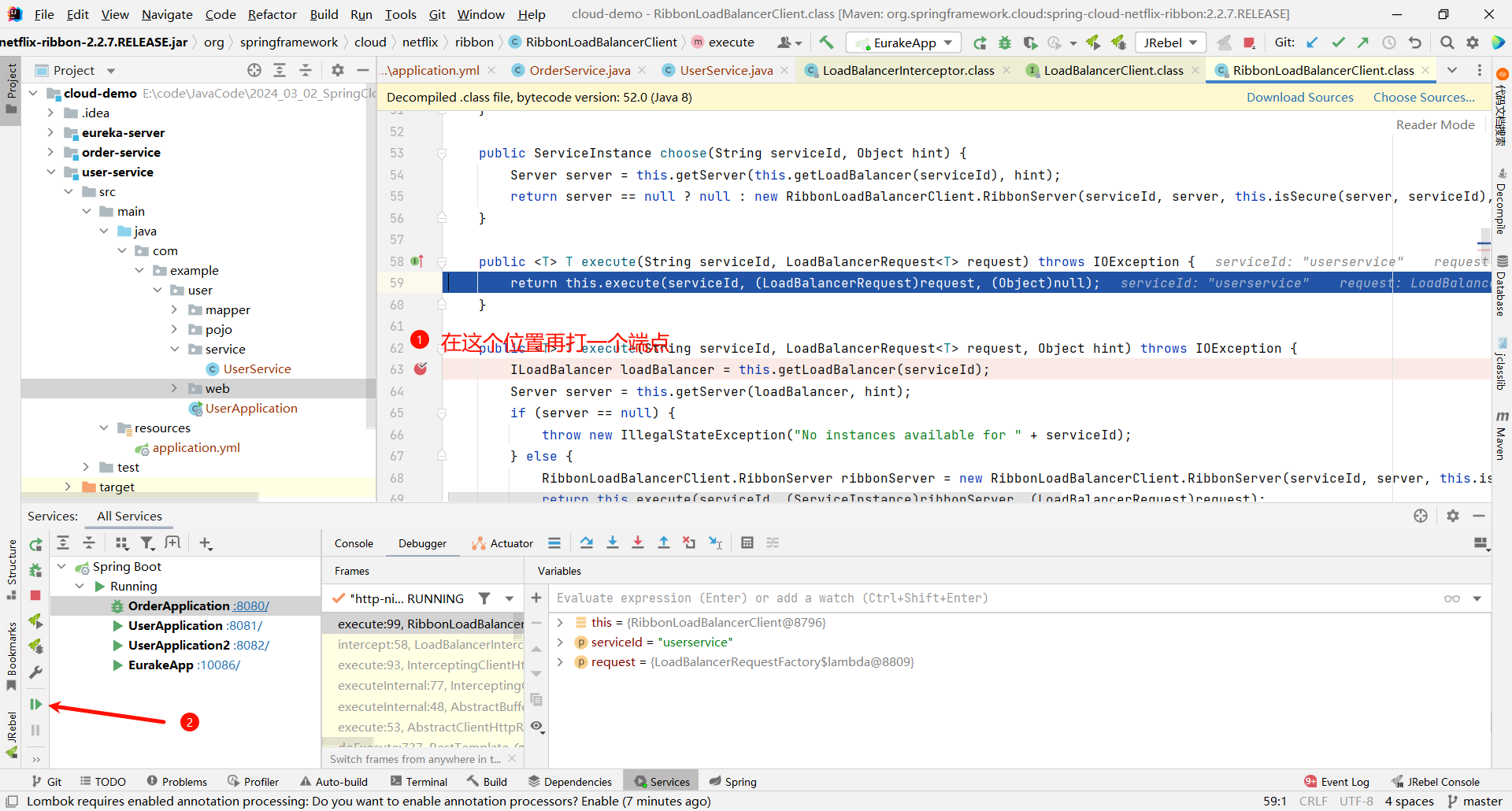
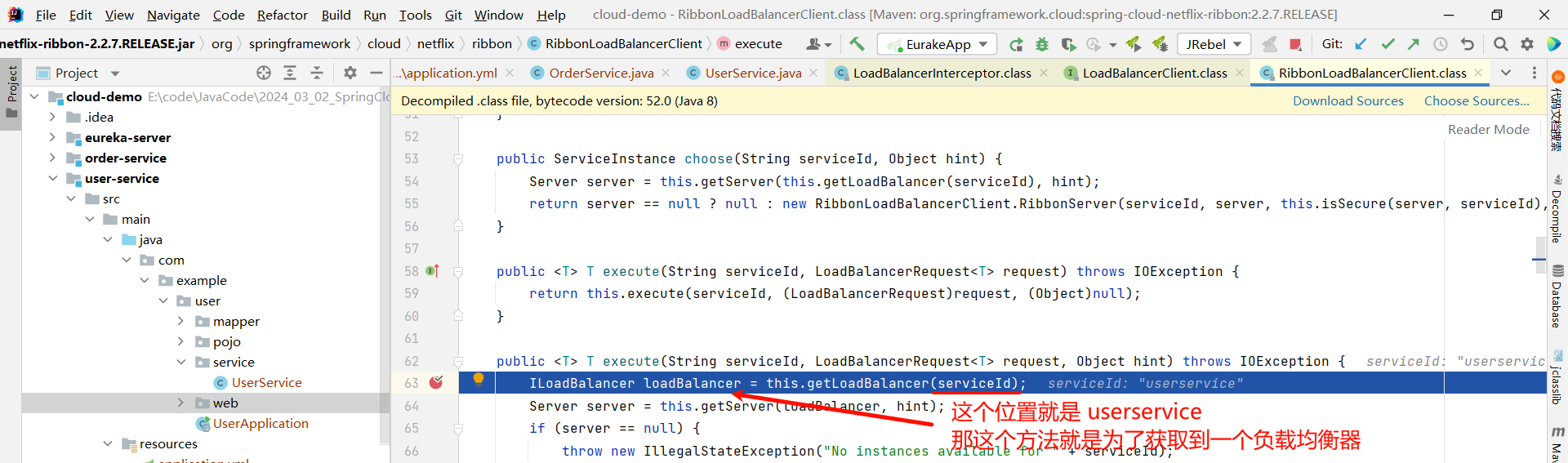
继续向下执行 , 我们看一下 ILoadBalancer 是什么内容
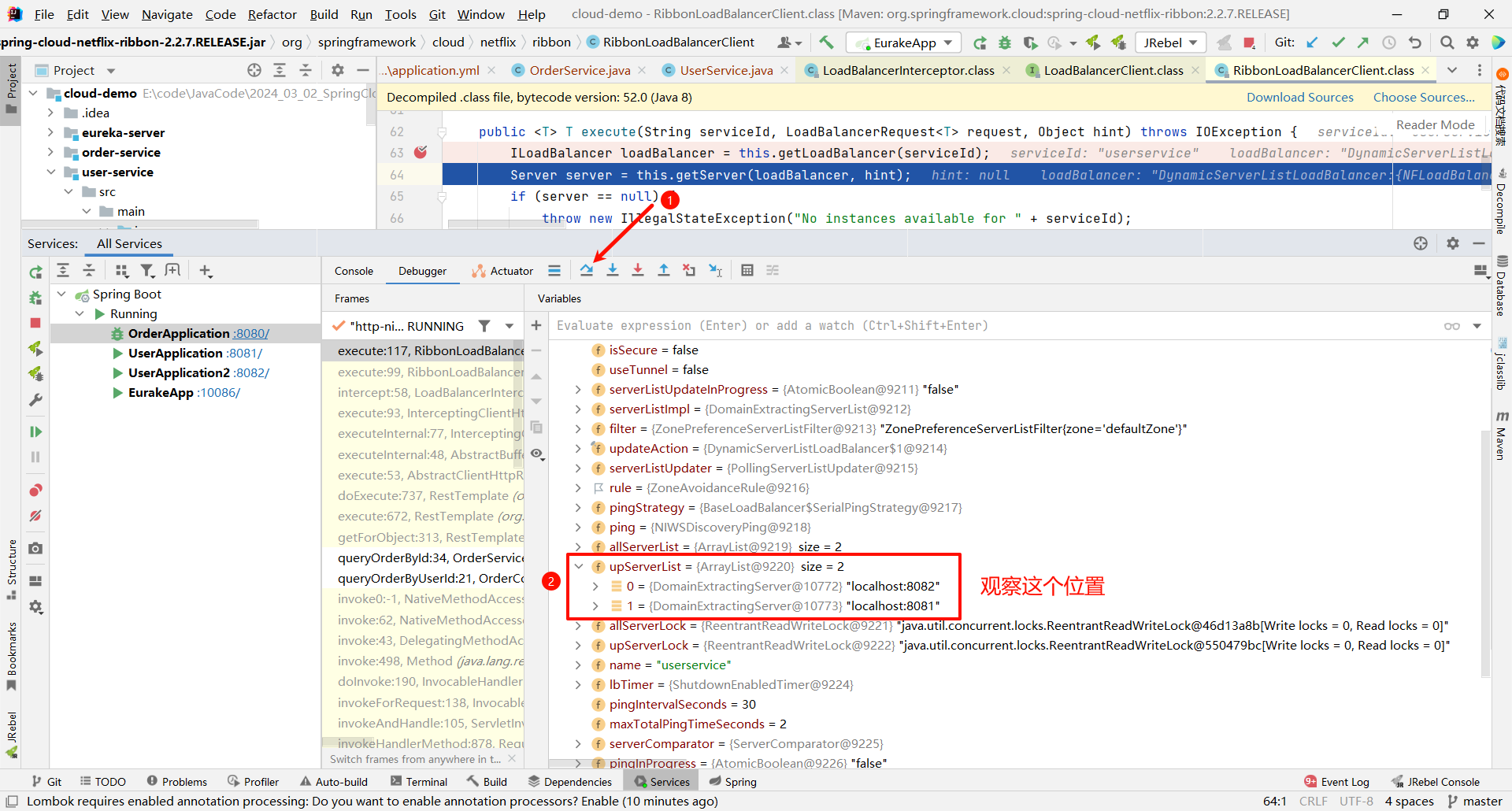
那这个 up 好像有点眼熟 , 这个 up 就代表可用节点的意思
那上面的 allServerList 指的就是所有节点
假如我们总共有三个节点 , 但是有一个节点挂了 . 那 allServerList 就是 3 , upServerList 就是 2
那下面的 getServer 方法就是按照某种策略来去获取某个节点
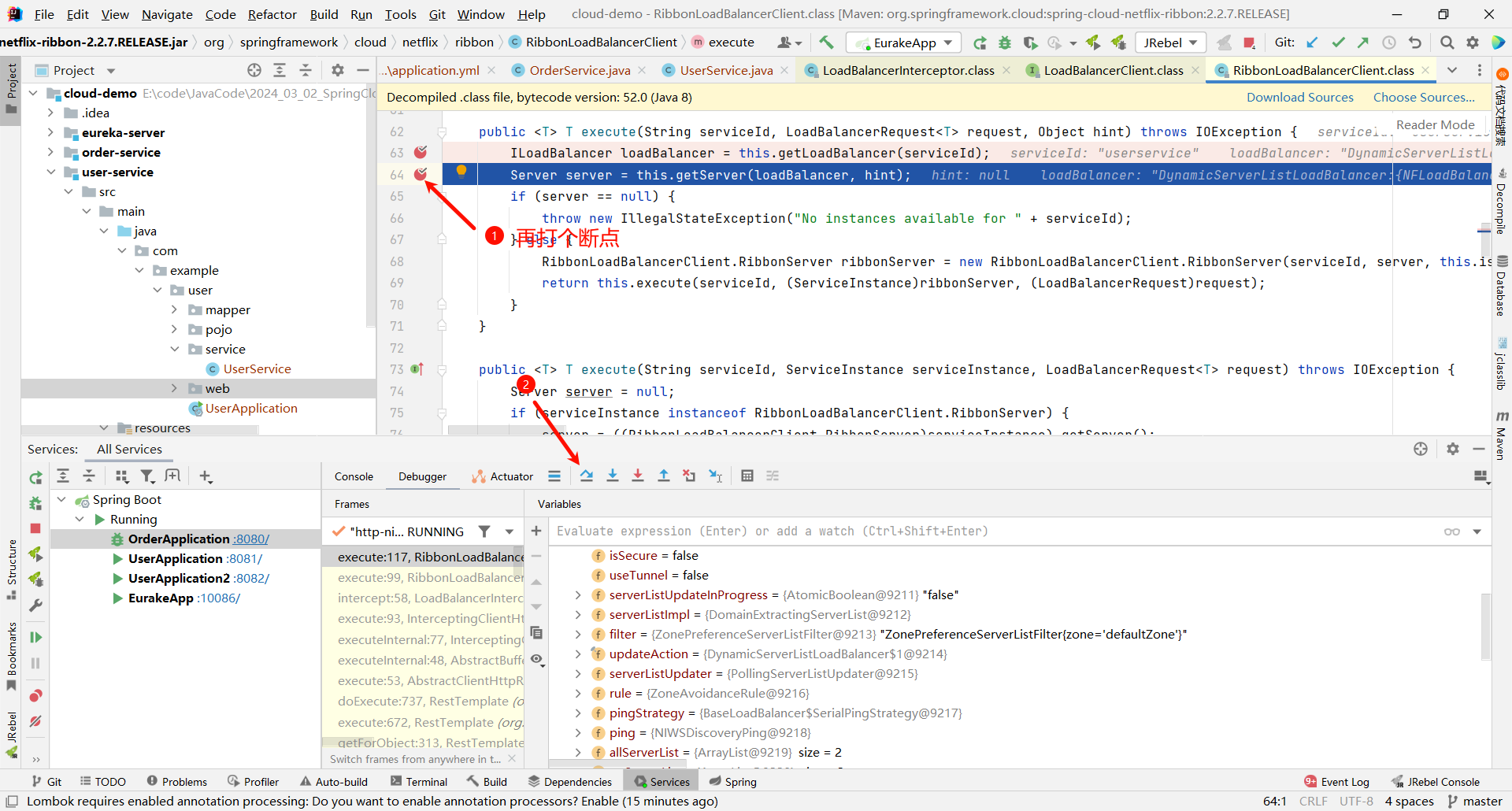
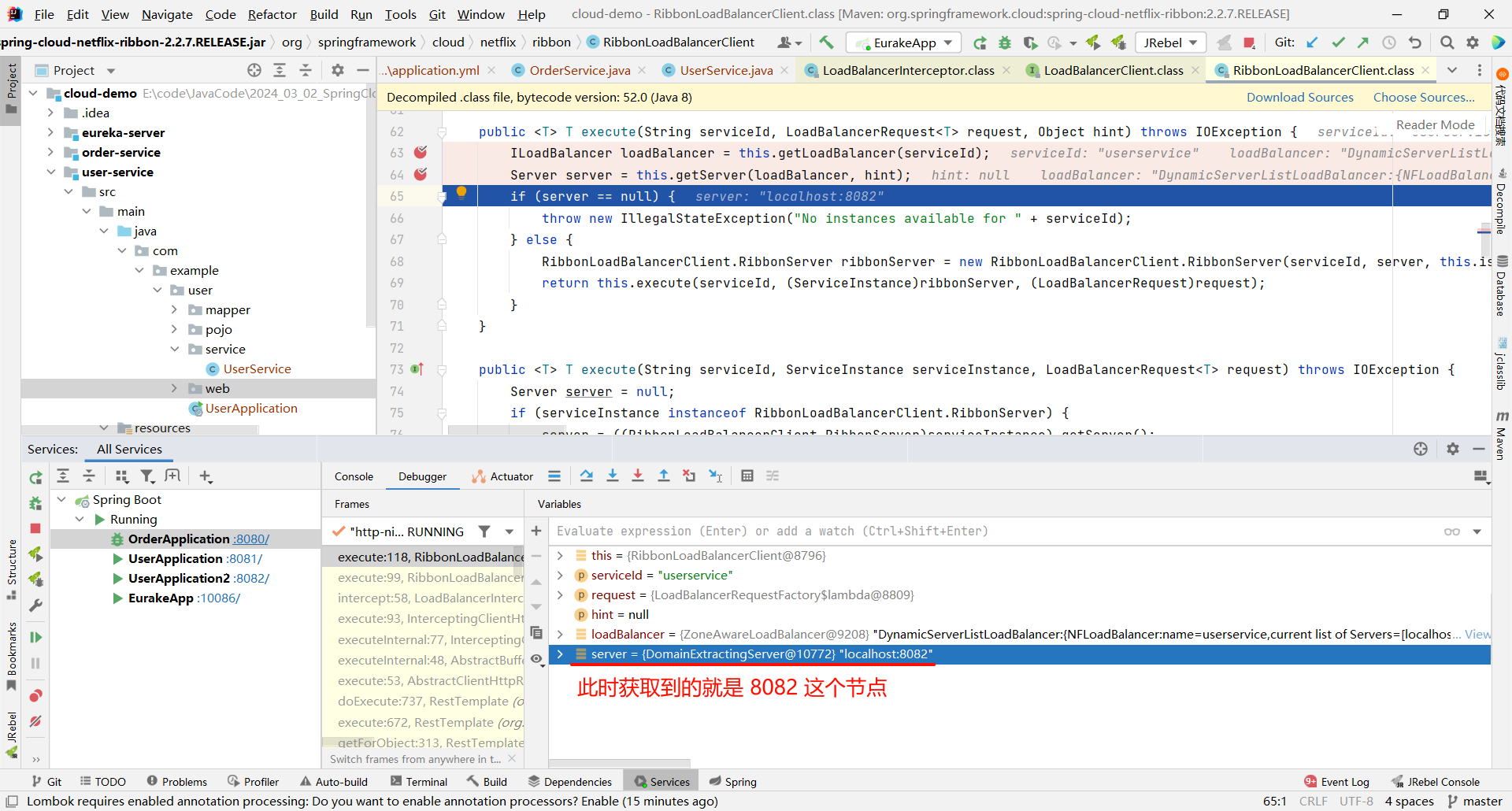
那我们还可以继续深入 getServer 方法
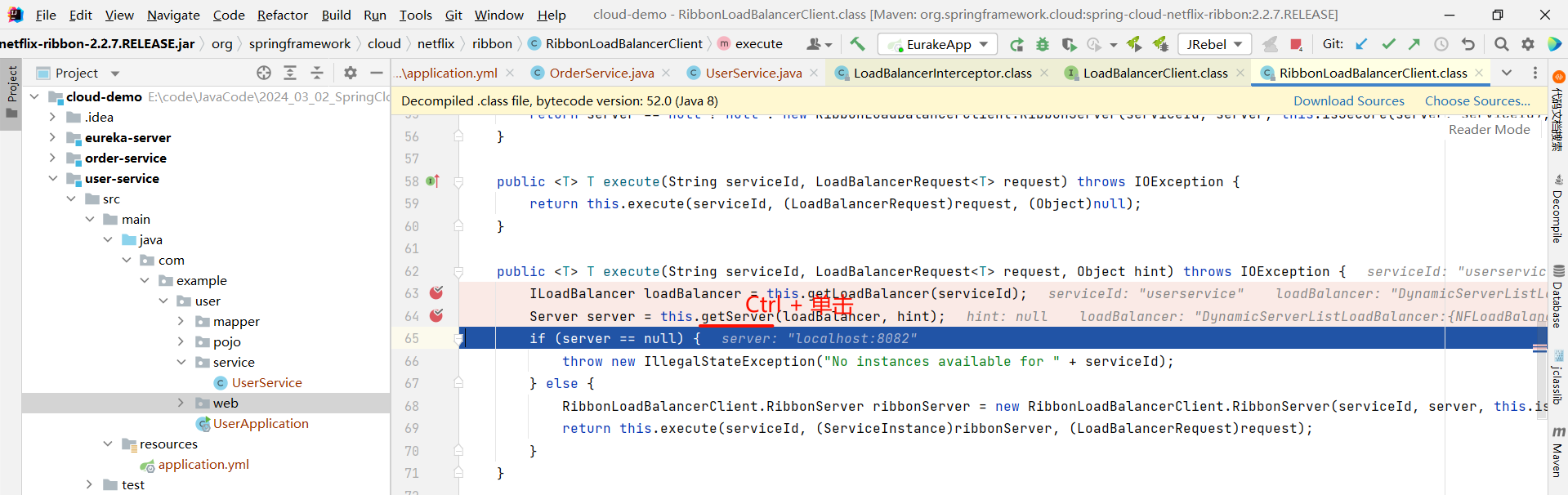
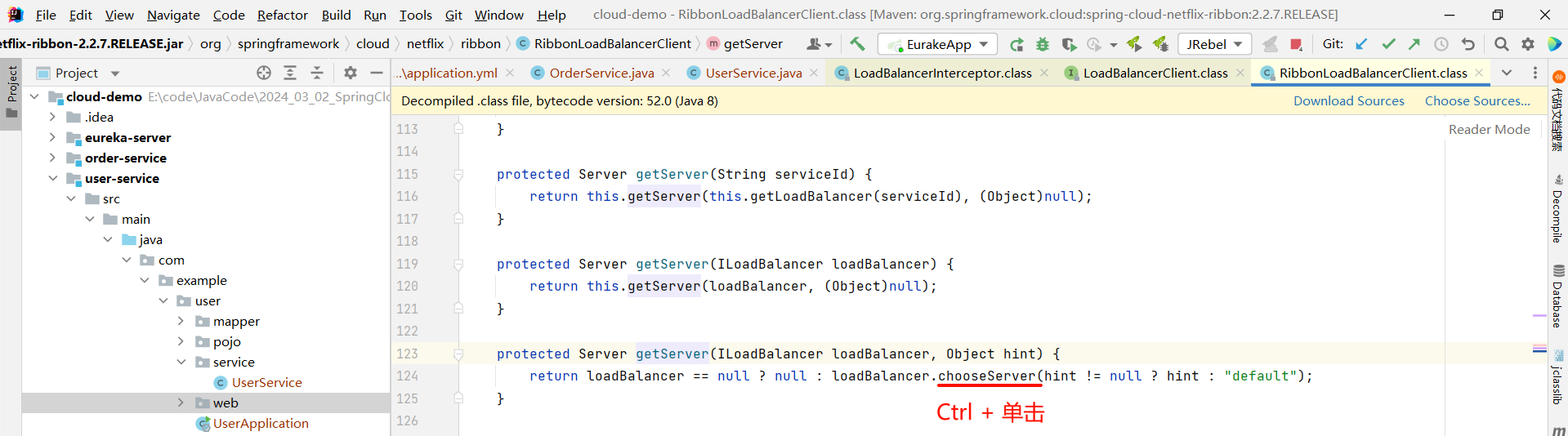
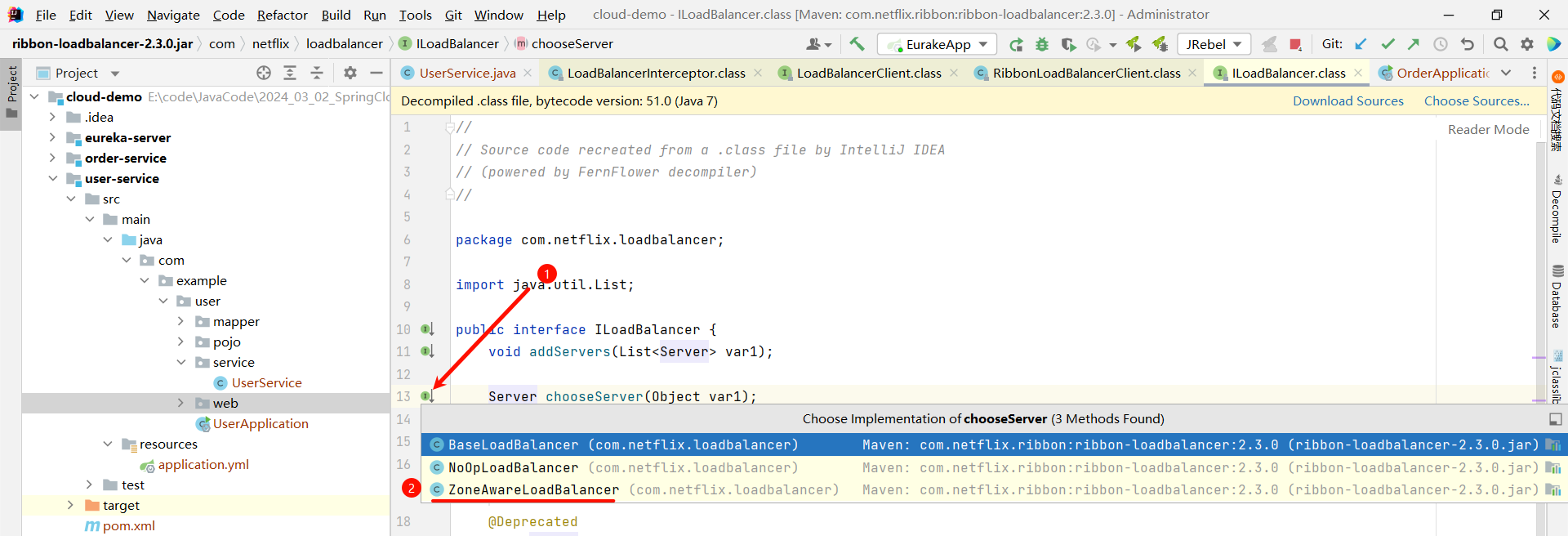
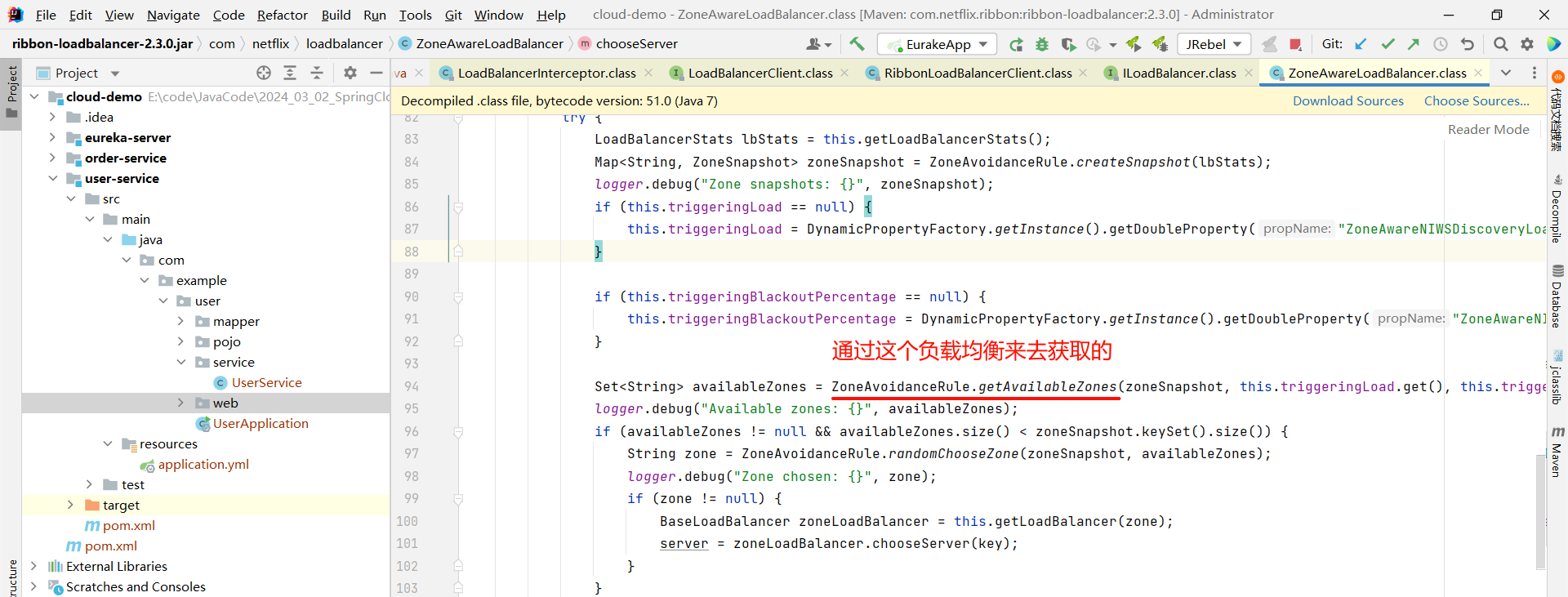
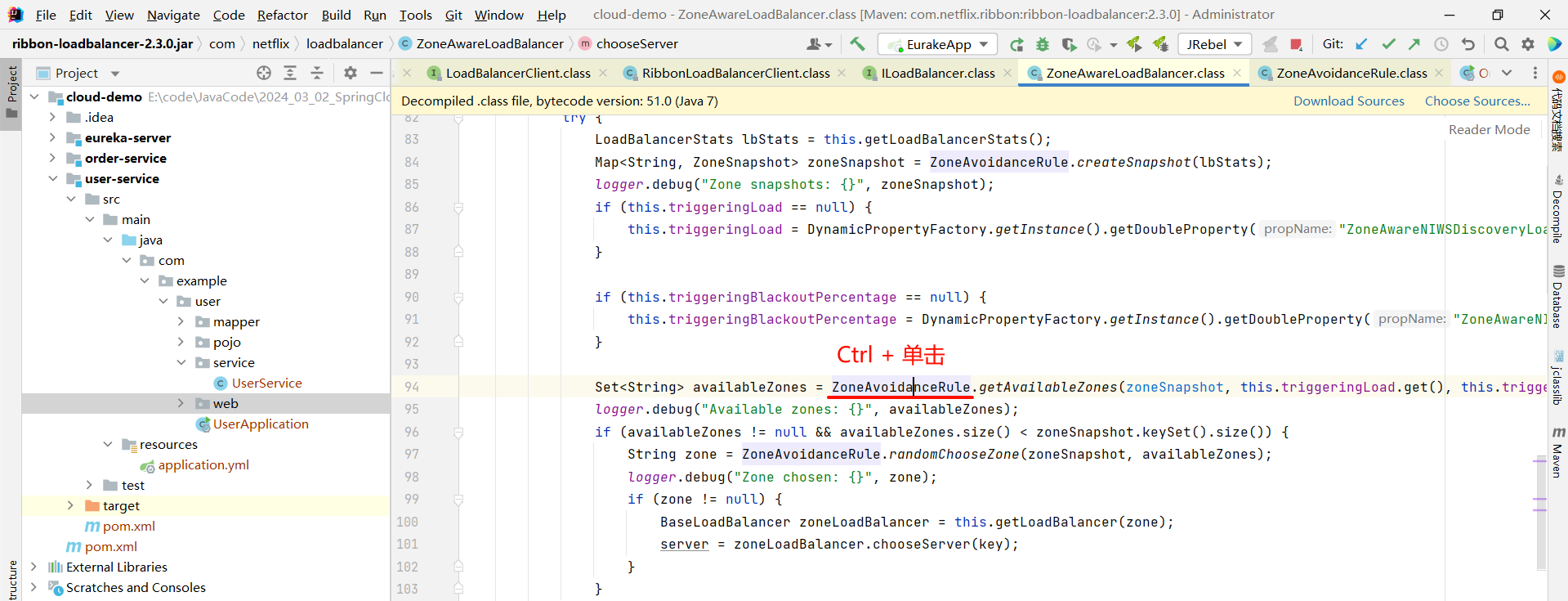
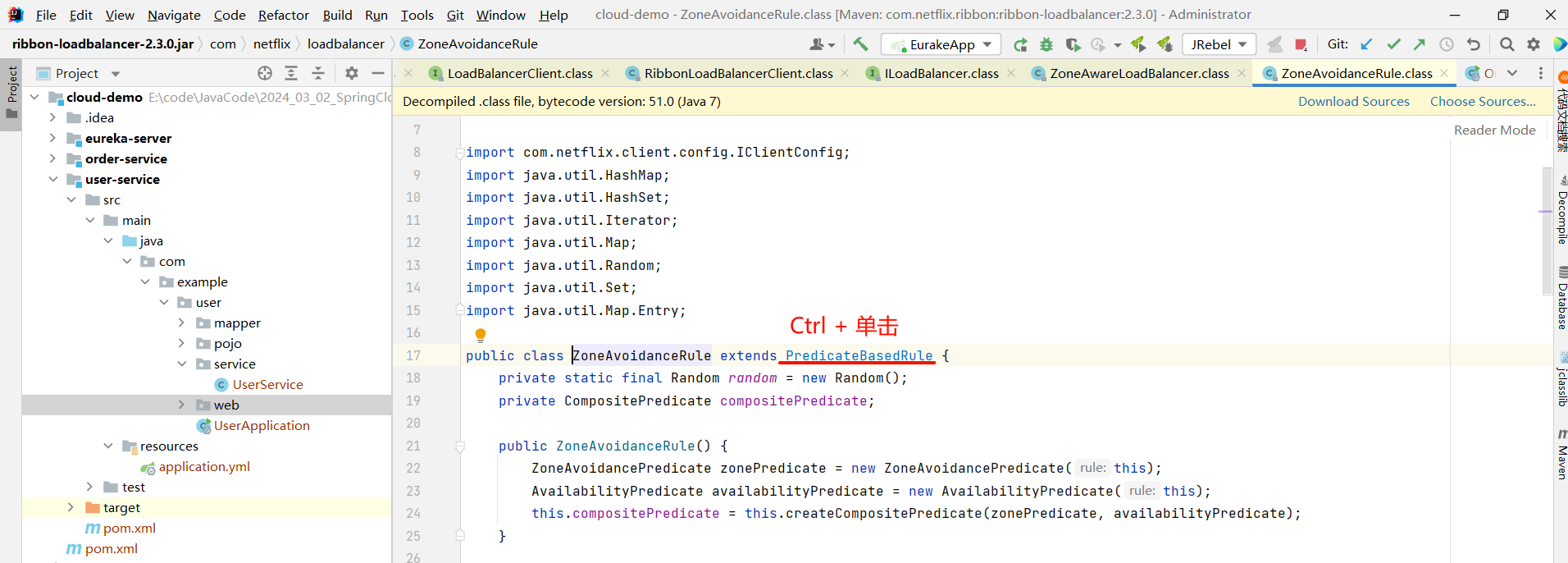
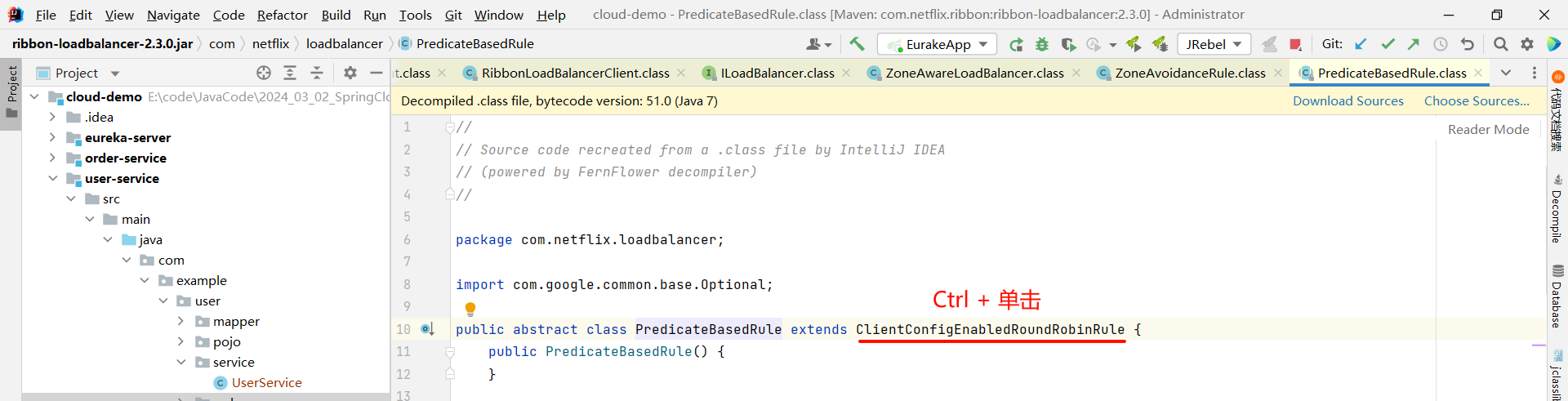
然后我们就找到了负责均衡的最顶层接口
5.3 负载均衡策略
那分析了源码之后 , 我们就可以来看一下整个负载均衡的框图
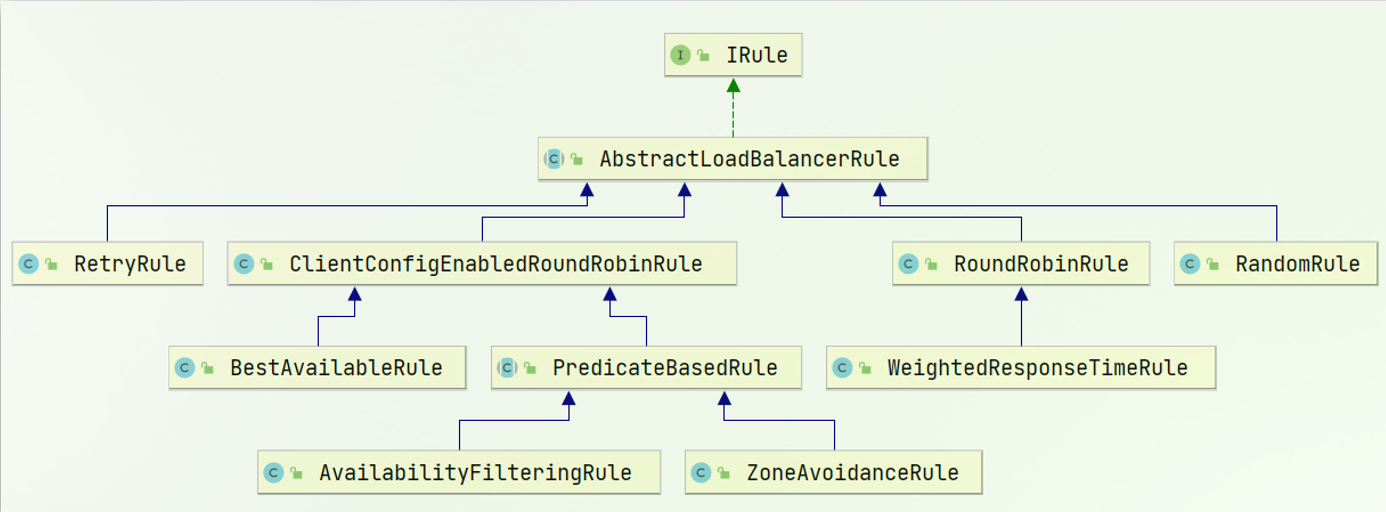
其中 , IRule 是最顶层的接口 , 这里面我们还比较眼熟的是 ZoneAvoidanceRule 这个规则 , 他是负载均衡策略默认的规则 .
那其他我们不认识的 , 其实也是负载均衡的策略 , 我们可以大概看一下
| 内置负载均衡规则类 | 规则描述 |
|---|---|
| RoundRobinRule | 简单轮询服务列表来选择服务器 |
| AvailabilityFilteringRule | 对以下两种服务器进行忽略 : (1)在默认情况下 , 这台服务器如果 3 次连接失败 , 那这台服务器就会被设置为“短路”状态 . 短路状态将持续 30 秒 , 如果 30s 之后再次连接失败 , 短路的持续时间就会几何级地增加 (30s -> 60s -> 90s …) (2)如果一个服务器的并发连接数过高 , 就会忽略该节点 . |
| WeightedResponseTimeRule | 服务器响应时间越长 , 这个服务器的权重就越小 , 被选中的可能性就越低 |
| ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择 , 如果当前节点在北京 , 那也会选择北京的节点进行连接而不是选择上海的节点 . |
| BestAvailableRule | 忽略那些短路的服务器 , 并选择并发数较低的服务器 |
| RandomRule | 随机选择一个可用的服务器 |
| RetryRule | 重试机制 |
那通过定义 IRule 可以实现修改负载均衡的规则 , 有两种方式
① 代码方式
在 order-service 中的启动类下 , 定义一个新的 IRule 覆盖掉本来的配置 (秉持谁用谁配置的原则 , order-service 需要调用 user-service , 就需要 order-service 进行配置)
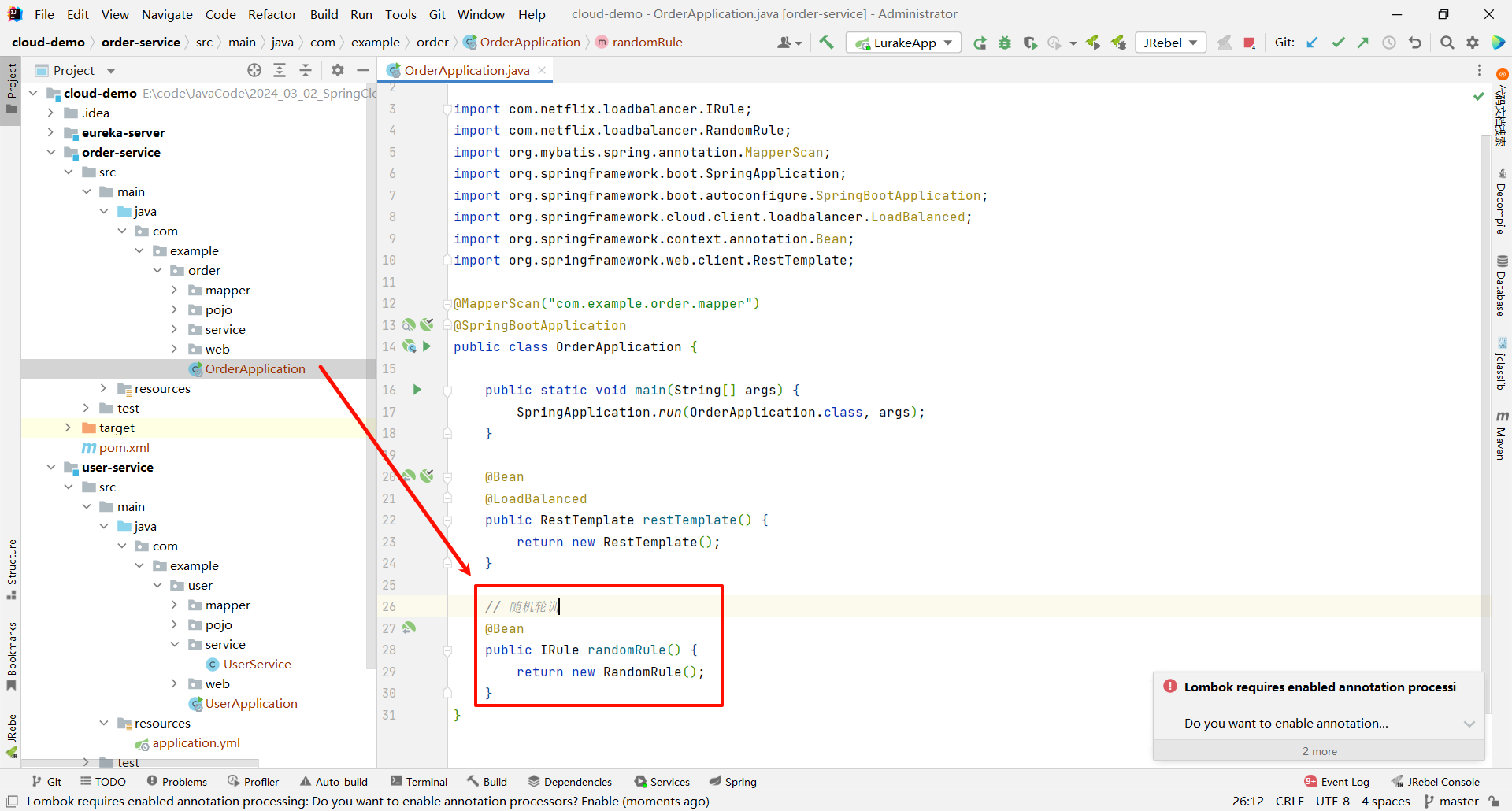
package com.example.order;
import com.netflix.loadbalancer.IRule;
import com.netflix.loadbalancer.RandomRule;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("com.example.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
// 随机轮训
@Bean
public IRule randomRule() {
return new RandomRule();
}
}
接下来 , 我们重启 order-service , 看一下是否还按照轮训的方式访问
我们注意端口号的变化



并不是完全按照 81 -> 82 -> 81 这样轮训的方式获取的了 .
② 配置文件方式
在 order-service 的 application.yml 文件中 , 添加新的配置也可以去修改规则
userservice: # 给某个微服务配置负载均衡规则, 这里是 userservice 服务
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
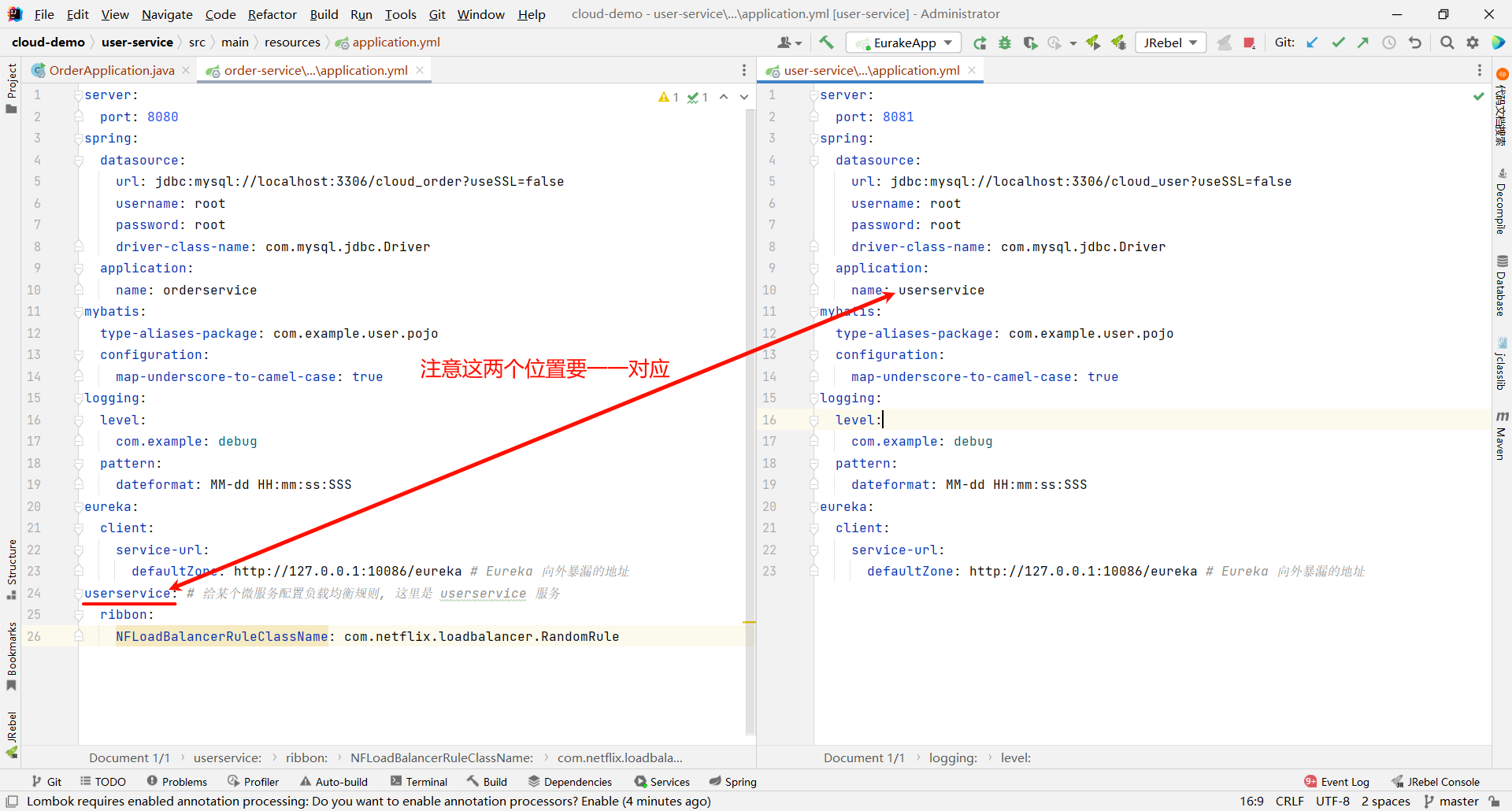
那我们可以重新运行一下
将刚才代码的方式注释掉



这次访问的都是 8082 端口了
5.4 懒加载
那我们的 order-service 需要访问 user-service 的节点 , 那 order-service 就需要向 EureKa 的注册中心获取服务列表 , 那这个服务列表是什么时候获取的呢 ?
是调用的时候采取获取 , 还是服务刚启动的时候就获取服务列表呢 ?
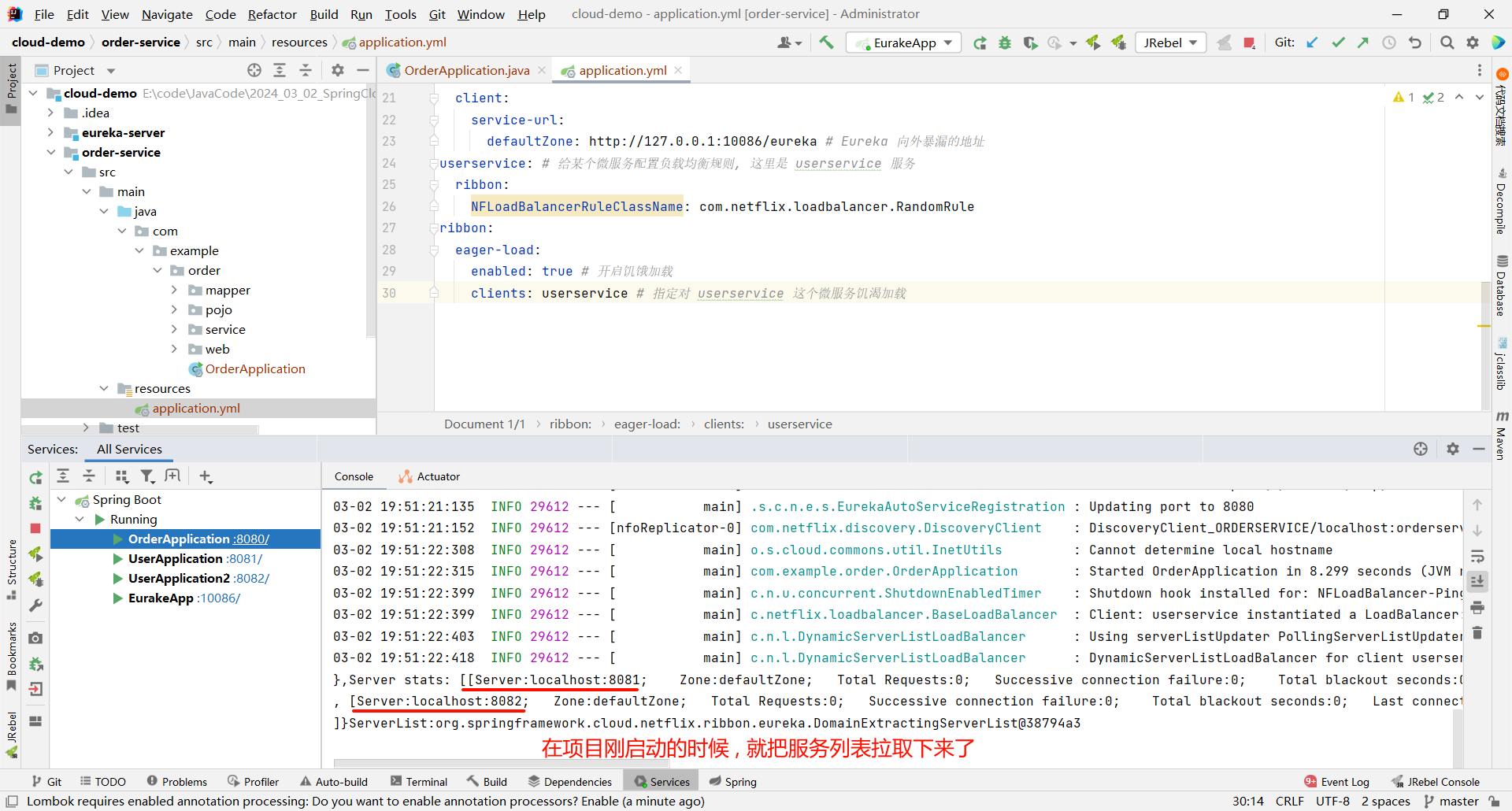
那 Ribbon 默认是懒加载 , 只有第一次访问的时候才会去创建 LoadBalanceClient . 我们可以设置成饥饿加载 , 在项目启动的时候就创建 LoadBalanceClient , 这样就降低了第一次访问的耗时时长 .
我们可以通过配置文件开启饥饿加载 .
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients: userservice # 指定对 userservice 这个微服务饥渴加载
如果对多个服务开启饥饿加载的话 , 可以使用列表的形式
ribbon:
eager-load:
enabled: true # 开启饥饿加载
clients:
- userservice # 指定对 userservice 这个微服务饥渴加载
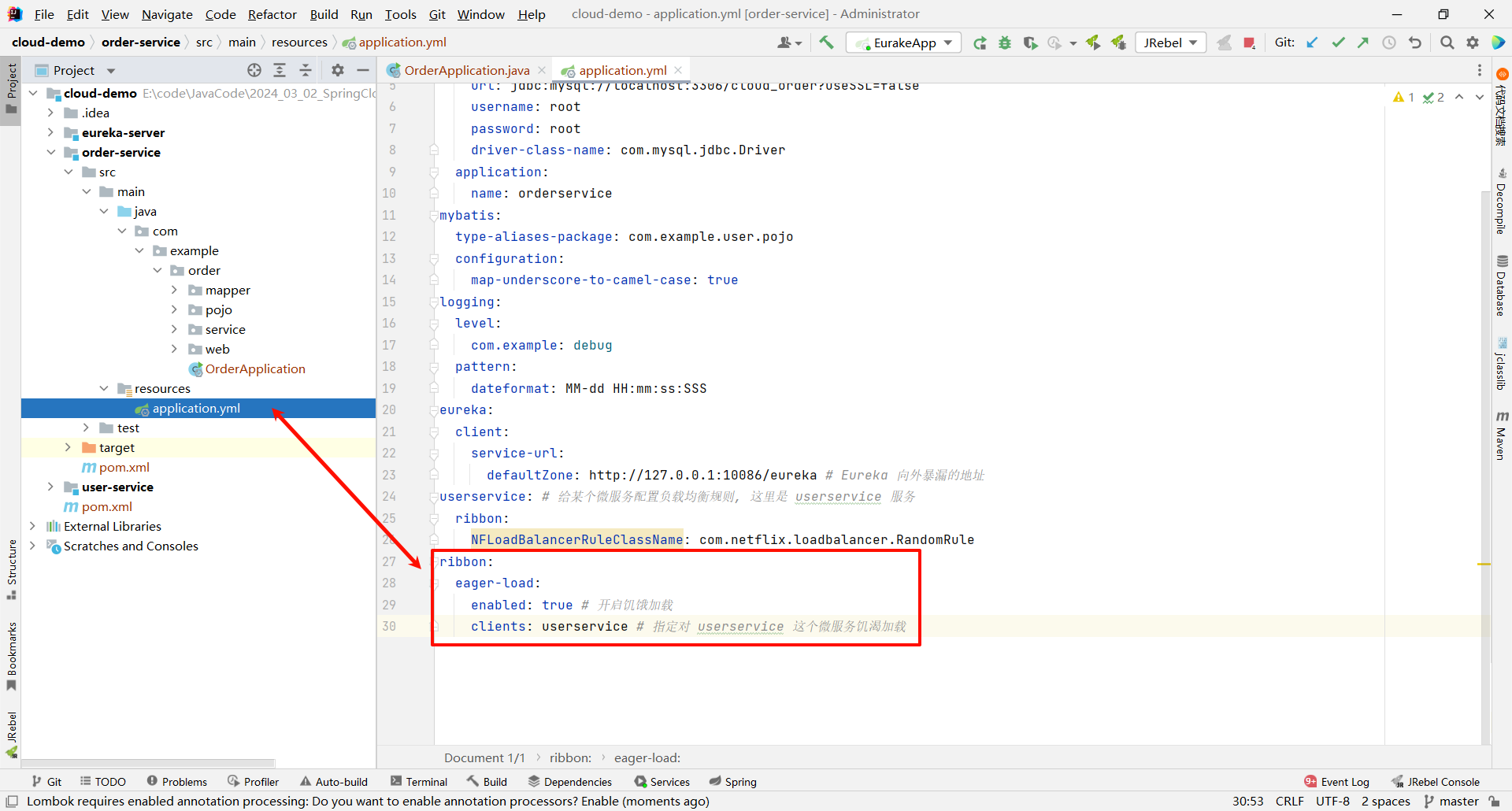
那我们重新启动一下 , 就能够在控制台发现一些蛛丝马迹了
5.5 小结
- Ribbon 负载均衡规则
- 规则接口是 IRule
- 默认实现是 ZoneAvoidanceRule , 根据 zone (地区) 选择服务列表 , 然后轮询
- 负载均衡自定义方式
- 代码方式 : 配置灵活 , 但修改时需要重新打包发布
- 配置方式 : 直观、方便 , 无需重新打包发布 , 在配置中心统一配置即可 , 但是无法做全局配置
- 饥饿加载
- 开启饥饿加载 : 设置 ribbon.eager-load.enabled 为 true
- 指定饥饿加载的微服务名称 : 将需要饥饿加载的微服务添加到 ribbon.eager-load.clients 中